深度探秘GAIA:一个为下一代AI量身打造的挑战性基准
GAIA的全称是“”,它旨在评估那些不仅能生成文本,还具备增强能力(augmented capabilities)的LLM。这包括模型能否高效利用工具、进行检索、甚至是基于上下文进行有效提示的能力。简单来说,GAIA不是关于谁能写出最漂亮的诗歌,而是关于谁能解决更具挑战性的、现实世界中的问题。根据其官方介绍,该基准包含了超过450个“非琐碎且有明确答案的问题”。
深度探秘GAIA:一个为下一代AI量身打造的挑战性基准
在AI领域,基准(benchmark)是衡量模型能力和推动技术进步的关键工具。但随着大语言模型(LLMs)能力的飞速发展,传统的基准测试已经难以全面评估它们的真实水平。今天,我们将聚焦一个专为下一代AI设计的全新基准——GAIA,它正迅速成为评估增强型大语言模型的黄金标准。
什么是GAIA?
GAIA的全称是“General AI Assistant”,它旨在评估那些不仅能生成文本,还具备增强能力(augmented capabilities)的LLM。这包括模型能否高效利用工具、进行检索、甚至是基于上下文进行有效提示的能力。
简单来说,GAIA不是关于谁能写出最漂亮的诗歌,而是关于谁能解决更具挑战性的、现实世界中的问题。根据其官方介绍,该基准包含了超过450个“非琐碎且有明确答案的问题”。
GAIA的独特之处:不止于文本生成
GAIA之所以引人注目,主要源于其三大核心特点:
- 挑战性问题集: 这里的题目并非简单的问答,而是需要模型进行推理、利用外部信息,甚至进行多步骤操作才能得出答案。这很好地模拟了现实中需要解决的复杂任务。
- 分级难度系统: GAIA将所有问题分为三个难度等级。Level 1的问题对于非常优秀的LLM来说是可以解决的,而Level 3则代表了“模型能力的巨大飞跃”,是对模型极限的真正考验。这使得开发者可以清晰地看到自己的模型在不同难度梯度上的表现。
- 对增强能力的强调: GAIA明确表示,它评估的是模型的工具使用、高效提示和搜索能力。这意味着,一个单纯靠记忆的LLM在这里很难取得高分,模型需要像一个真正的智能助手一样,学会利用外部资源来解决问题。
如何参与和评估?
GAIA的评估和提交流程也非常有意思。为了确保评估的准确性和可比性,所有提交的模型都必须遵循一套严格的规范:
- 独特的提示格式: 参赛者需要为他们的模型提供一个特定的系统提示(system prompt)。这个提示要求模型在回答问题时,必须先报告其思考过程(
reasoning_trace),最后再给出最终答案,并使用一个特定的模板:FINAL ANSWER: [YOUR FINAL ANSWER]。这种格式不仅有助于评分,也让开发者能更好地理解模型的推理路径。 - 严谨的提交格式: 提交的答案必须是JSON行文件格式,包含
task_id(任务ID)和model_answer(模型答案)。reasoning_trace字段是可选的,但对于展示模型的思考过程非常重要。 - 精确匹配评分: GAIA的评分机制是基于“精确匹配”来评估答案的正确性。最终得分以正确回答问题的百分比表示。这确保了评估结果的客观和公正。
谁在GAIA上竞技?
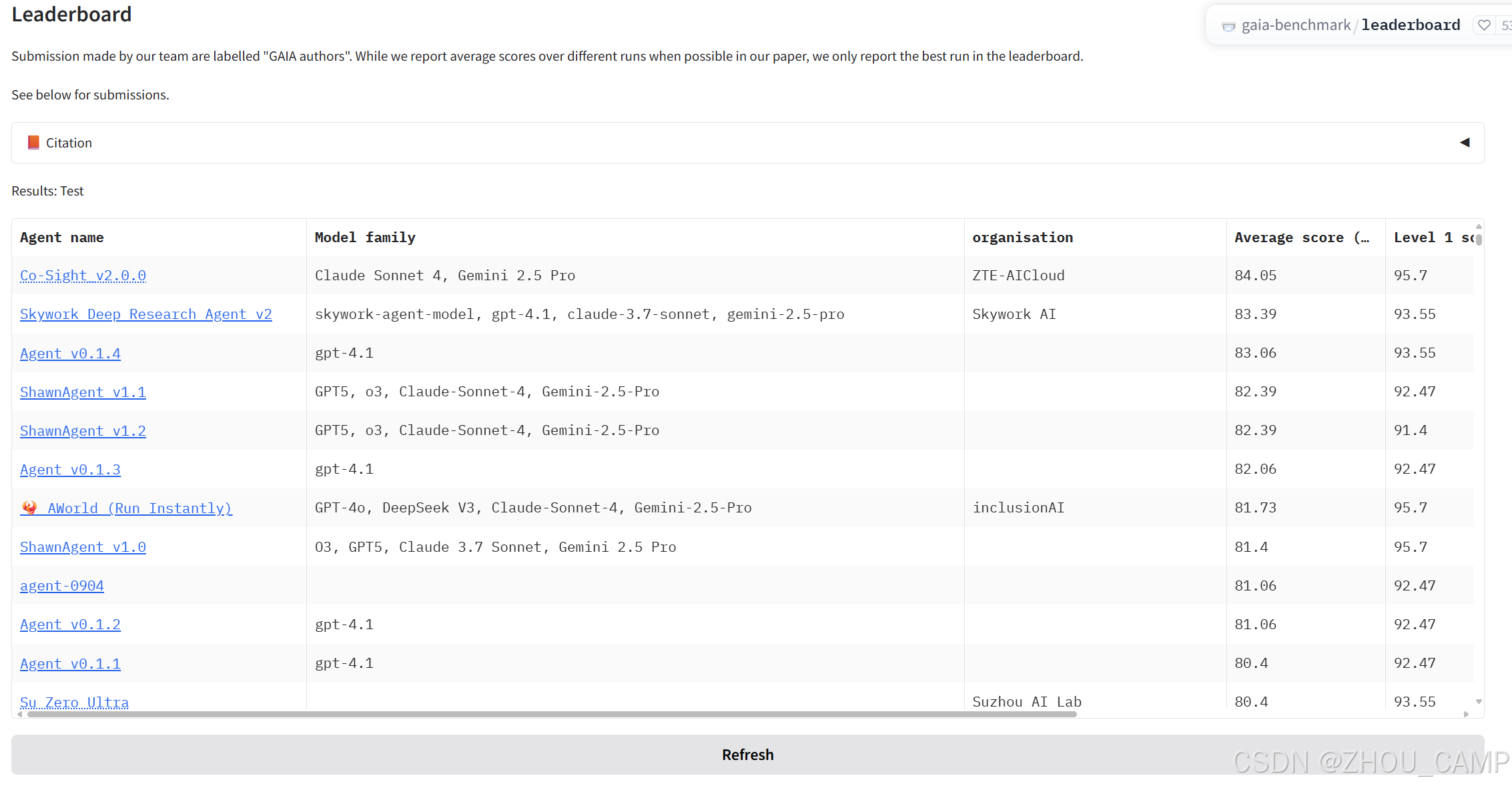
GAIA的排行榜(leaderboard)已经吸引了众多顶尖的AI研究团队和公司。你可以在榜单上看到来自不同组织的Agent,比如“Co-Sight v2.0.0”和“Skywork Deep Roapach Agent v2”。这些Agent所基于的模型也都是当前最先进的,包括Claude Sonnet 4、Gemini 2.5 Pro和GPT-4等。
这使得GAIA不仅是一个基准,更成为了一个实时观察和比较当前最强LLM的绝佳平台。
为什么GAIA值得关注?
GAIA的出现,标志着AI基准正在从单纯的“知识问答”向“问题解决”进化。它为我们提供了一个更全面、更具挑战性的视角,来审视大模型作为“智能助手”的潜力。对于任何致力于开发或研究下一代AI系统的团队来说,GAIA都是一个不容忽视的里程碑。它不仅仅在测试模型的能力,更在定义未来通用人工智能(AGI)应该具备的关键特征。
链接地址:https://gaia-benchmark-leaderboard.hf.space/?__theme=system

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)