paimon实时数据湖教程-分桶详解
文章摘要: Paimon的分桶机制通过哈希函数优化数据存储和查询性能,主要提供五种分桶模式:1)HASH_FIXED固定哈希分桶,适合数据量可预测的场景;2)HASH_DYNAMIC动态哈希分桶,自适应数据量变化;3)CROSS_PARTITION跨分区动态分桶,优化分区表全局分布;4)BUCKET_UNAWARE无感知分桶,适合小数据量表;5)POSTPONE_MODE延迟分桶,提升实时写入性能
免费教学视频
1 概述回顾
Paimon 的分桶(Bucketing)是一种优化数据存储和查询性能的机制。它通过将数据根据某个或某几个列的哈希值分散到不同的物理文件中,从而在以下几个方面带来好处:
-
提高查询效率:
-
等值查询: 当查询条件包含分桶列的等值过滤时,Paimon 可以直接定位到包含目标数据的小部分文件,而无需扫描整个表,大大减少了 I/O。
-
Join 优化: 在进行 Join 操作时,如果两个表都按照 Join Key 进行了分桶,并且桶的数量一致,那么 Paimon 可以在相同桶之间进行局部 Join,减少数据混洗(Shuffle),提高 Join 性能。
-
-
数据倾斜缓解: 分桶有助于将数据均匀地分布在不同的桶中,避免某个分区或文件过大,导致处理延迟或资源瓶颈。
-
小文件问题缓解: 在没有分桶的情况下,数据可能会被写入大量的小文件中,导致文件系统和元数据管理开销增大。分桶可以在一定程度上控制每个桶中的文件数量,缓解小文件问题。
分桶的原理
Paimon 的分桶是基于哈希函数实现的。当数据写入表时,会根据指定的分桶列计算其哈希值,然后将哈希值映射到预先定义好的桶(Bucket)中。每个桶对应一个或多个物理文件。
分桶的生命周期
-
写入阶段: 数据根据分桶列的哈希值被路由到不同的桶,并写入到该桶对应的文件中。
-
查询阶段:
-
如果查询条件包含分桶列,查询优化器可以利用分桶信息,只读取相关的桶文件。
-
如果进行 Join 操作,并且满足分桶 Join 的条件,则可以进行优化。
-
Paimon 分桶设置方式
Paimon 分桶主要在创建表时进行设置。以下是设置分桶的几种主要方式及其示例:
-
单列分桶
这是最常见的分桶方式,根据一个列的值进行哈希分桶。
CREATE TABLE user_logs (
log_id BIGINT,
user_id BIGINT,
event_time TIMESTAMP,
action STRING
) WITH (
'bucket' = 'user_id',
'bucket-num' = '10'
);-
'bucket' = 'user_id':指定user_id列作为分桶列。 -
'bucket-num' = '10':指定总共有 10 个桶。Paimon 会将user_id的哈希值模 10,将数据分配到 0 到 9 这 10 个桶中。
2 多列分桶 (Composite Bucketing)
当需要根据多个列的组合进行分桶时,可以使用多列分桶。这在查询条件经常涉及这些列的组合时非常有用。
CREATE TABLE order_items (
order_id BIGINT,
product_id INT,
user_id BIGINT,
quantity INT,
price DECIMAL(10, 2)
) WITH (
'bucket' = 'order_id, product_id',
'bucket-num' = '20'
);-
'bucket' = 'order_id, product_id':指定order_id和product_id组合作为分桶列。Paimon 会对这两个列的值进行组合哈希。
3 分区表的分桶
Paimon 支持分区表和分桶表的组合使用。分区通常用于根据时间等维度进行大粒度的物理数据隔离,而分桶则在每个分区内部进一步细化数据分布。
CREATE TABLE daily_sales (
sale_id BIGINT,
product_id INT,
customer_id BIGINT,
sale_date DATE,
amount DECIMAL(10, 2)
) PARTITIONED BY (sale_date) WITH (
'bucket' = 'customer_id',
'bucket-num' = '5'
);-
PARTITIONED BY (sale_date):表首先根据sale_date列进行分区。 -
在每个
sale_date分区内部,数据再根据customer_id列分桶,每个分区有 5 个桶。
4 不分桶 (No Bucketing)
如果你认为分桶带来的收益不明显,或者数据量不大,也可以选择不分桶。默认情况下 Paimon 是不分桶的。
CREATE TABLE simple_data (
id BIGINT,
value STRING
) WITH (
-- 不指定 'bucket' 参数,或者显式设置为空
'bucket-num' = '-1' -- 或者不设置 'bucket-num'
);-
不指定
'bucket'参数,或者将'bucket-num'设置为-1,表示不分桶。Paimon 会使用默认的单文件或根据写入模式进行文件管理。
2 Paimon 分桶模式详解
从一个flink写作业开始
package com.ao.apis;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.paimon.catalog.Catalog;
import org.apache.paimon.catalog.Identifier;
import org.apache.paimon.flink.FlinkCatalogFactory;
import org.apache.paimon.flink.sink.FlinkSinkBuilder;
import org.apache.paimon.options.Options;
import org.apache.paimon.table.Table;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.Row;
/**
* @tel 17710299606
* @Author: 行哥
* @Description:
* 1 flink - source获取数据流
* 2 将数据写入到paimon中
* paimon能保证数据的一致性
* 借助flink的checkpoint机制 , 实现两阶段提交
* 所以要开启checkpoint机制 , 如果不开启, 两阶段只能实现第一个预写阶段, 永远不会收到提交的信号 ,
* 所以数据不会写入
*
*/
public class FlinkWriteData {
public static void main(String[] args) throws Exception {
// 1 获取flink的运行环境
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
see.setParallelism(1) ;
// 开启checkpoint
see.enableCheckpointing(5000) ;
see.getCheckpointConfig().setCheckpointStorage("file:///D://chk-01");
// 2 接受数据 id,name,age,city
// 1,zss,23,BJ
DataStreamSource<String> dataStreamSource = see.socketTextStream("linux01", 8989);
MapFunction<String, Row> mapFunction = new MapFunction<String, Row>() {
@Override
public Row map(String line) throws Exception {
String[] arr = line.split(",");
// 第一个参数 操作表示 +I -U +U -D
Row row = Row.of(Integer.valueOf(arr[0]), arr[1], Integer.valueOf(arr[2]), arr[3]);
//return Row.ofKind(RowKind.INSERT, Integer.valueOf(arr[0]), arr[1], Integer.valueOf(arr[2]), arr[3]);
return row ;
}
};
// 3 对数据流进行加工 加工乘Row
SingleOutputStreamOperator<Row> data = dataStreamSource.map(mapFunction);
// 4 根据数据结构 封装对应的数据类型
DataType dataType = DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.INT()),
DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("age", DataTypes.INT()),
DataTypes.FIELD("city", DataTypes.STRING())
);
// 5 获取表
Options options = new Options();
options.set("warehouse" , "./api_file_catalog");
Catalog catalog = FlinkCatalogFactory.createPaimonCatalog(options);
Table table = catalog.getTable(Identifier.create("ods", "tb_user"));
// 写出数据 sink
// 参数 表对象
// 参数 1 数据流 row 2 输入数据的数类型(字段)
FlinkSinkBuilder sinkBuilder = new FlinkSinkBuilder(table).forRow(data, dataType);
sinkBuilder.build();
see.execute();
}
}代码 74行中的buid, 构建一个sink进行数据写出 ,所以源代码从这里开始
在build方法中有如下代码 ; 不同的分桶模式不同的处理方式
BucketMode bucketMode = table.bucketMode();
switch (bucketMode) {
case POSTPONE_MODE: // 1 延迟分桶模式
return buildPostponeBucketSink(input);
case HASH_FIXED: // 2 最基本的 Hash分桶
return buildForFixedBucket(input);
case HASH_DYNAMIC: // 3 动态hash分桶
return buildDynamicBucketSink(input, false);
case CROSS_PARTITION: // 4 跨分区动态分桶
return buildDynamicBucketSink(input, true);
case BUCKET_UNAWARE: //5 无感知分桶 / 不分桶
return buildUnawareBucketSink(input);
default:
throw new UnsupportedOperationException("Unsupported bucket mode: " + bucketMode);
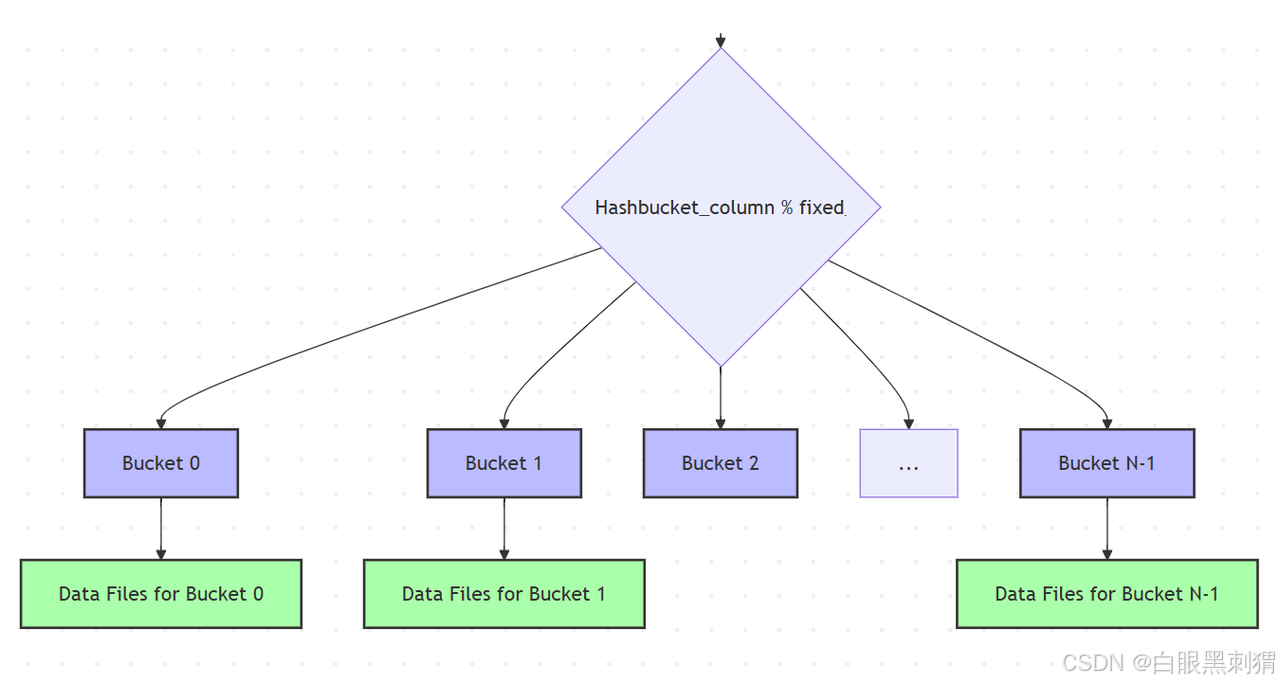
}1. HASH_FIXED (固定哈希分桶)
-
特点: 这是 Paimon 最经典和常见的分桶模式。在创建表时,需要显式指定分桶列(
bucket)和固定数量的桶(bucket-num)。数据根据分桶列的哈希值模上桶数量,被固定地分配到预设的桶中。 -
适用场景:
-
数据量相对稳定或可预测: 当你对表的数据量有一个大致的预期,并且知道哪些列经常用于过滤或 Join 时,这种模式非常高效。
-
等值查询和 Join 优化: 这种模式能最大化地利用分桶机制,快速定位数据,提升查询性能。
-
数据倾斜可控: 如果分桶列的基数足够高且分布均匀,可以有效避免数据倾斜。
-
-
优点: 查询效率高,数据分布均匀(在理想情况下),Join 优化效果好。
-
缺点: 桶数量固定后,难以动态调整。如果数据量增长远超预期,可能导致每个桶文件过大;如果数据量减少,可能导致小文件问题。
-
设置方式:
CREATE TABLE my_table (
id BIGINT,
name STRING,
ts TIMESTAMP
) WITH (
'bucket' = 'id',
'bucket-num' = '100' -- 固定100个桶
);
2. HASH_DYNAMIC (动态哈希分桶)
-
特点: 在这种模式下,你仍然需要指定分桶列(
bucket),但不需要预先指定桶的数量。Paimon 会根据写入的数据量和数据分布情况,动态地创建和管理桶。当一个桶的数据量达到某个阈值时,可能会分裂成更多的桶,或者通过 Compact 操作合并小桶。 -
适用场景:
-
数据量变化大且难以预测: 特别适合那些数据量会急剧增长或收缩的表。
-
避免小文件和巨无霸文件: 动态调整桶的数量有助于 Paimon 更好地管理文件大小,避免极端情况。
-
对写入性能有较高要求: 避免了固定桶模式下因桶数量不当导致的文件管理问题。
-
-
优点: 灵活性高,自适应数据变化,无需手动调整桶数量。
-
缺点: 相比
HASH_FIXED,查询时可能需要更多的元数据查找,因为桶的映射关系是动态的。 -
设置方式:
CREATE TABLE my_dynamic_table (
id BIGINT,
value STRING,
dt DATE
) WITH (
'bucket' = 'id',
'bucket-num' = '-1' -- 或者不设置 'bucket-num',这是动态桶的标志
);实际上,'bucket-num' 设置为 -1 通常表示动态桶。
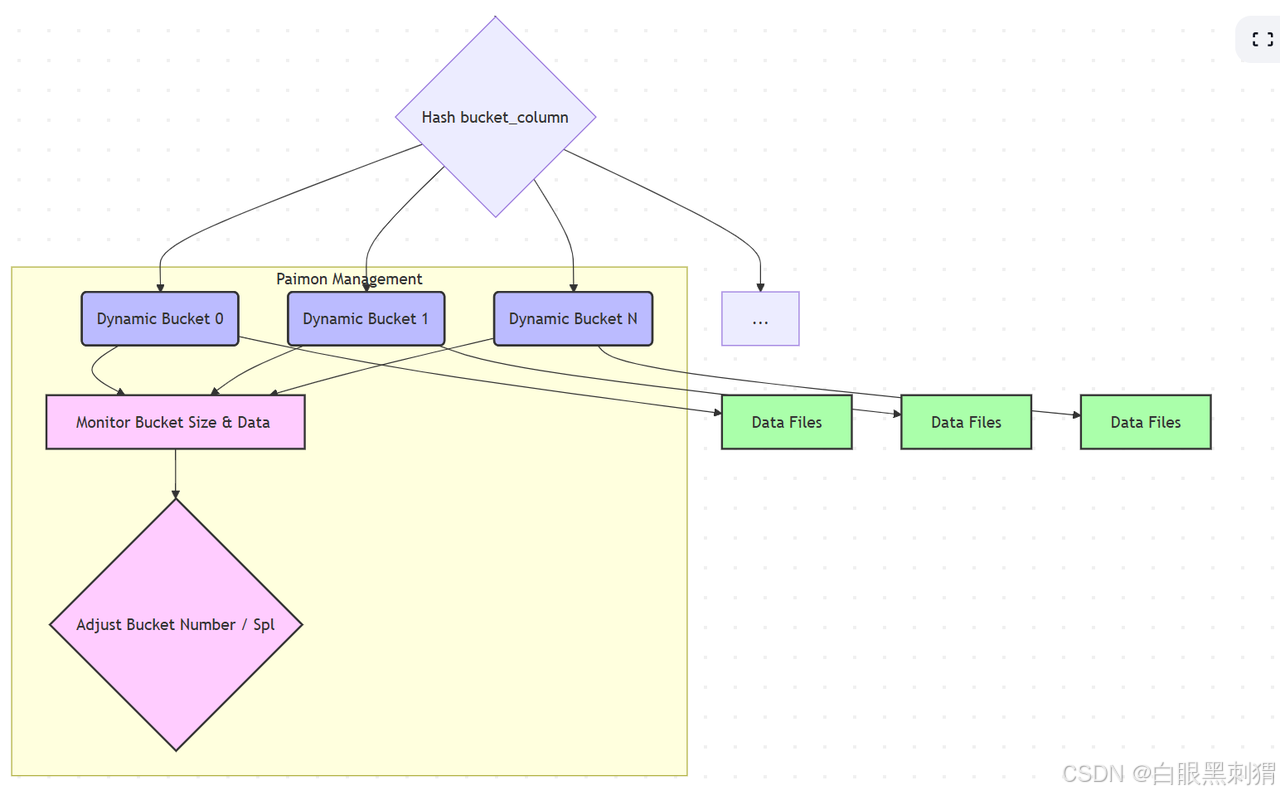
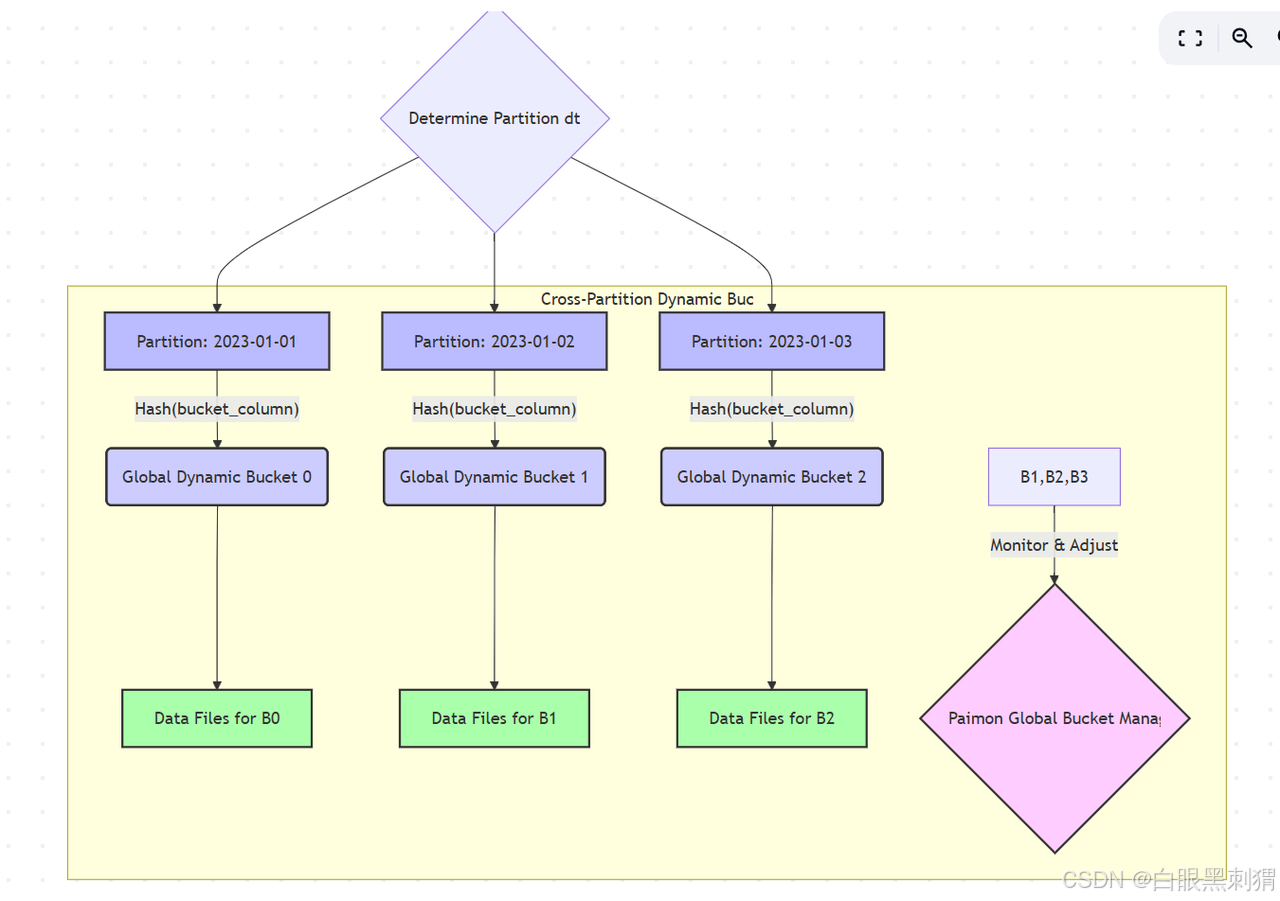
3. CROSS_PARTITION (跨分区动态分桶)
-
特点: 这是
HASH_DYNAMIC的一个变种,主要应用于分区表。通常,动态分桶是在每个分区内部独立进行的。而CROSS_PARTITION模式意味着 Paimon 会跨越不同的分区来考虑桶的分配和管理。这在处理跨分区聚合或 Join 场景时可能更有利。具体实现上可能涉及更复杂的全局桶管理策略。 -
适用场景:
-
分区表,但希望桶的全局分布更均匀: 某些情况下,即使是分区表,也希望避免某个分区内因数据量变化导致桶数量不合理。
-
跨分区操作优化: 在一些需要跨越多个分区进行分析或 Join 的场景下,这种模式可能提供额外的优化空间。
-
-
优点: 结合了分区的逻辑隔离和动态桶的灵活性,且桶的分布可能在全局层面更优。
-
缺点: 管理复杂度可能更高,对 Paimon 内部实现依赖较大。
-
设置方式: 这通常是通过在表的
WITH属性中设置特定的参数来启用,例如:
CREATE TABLE my_cross_partition_table (
id BIGINT,
value STRING,
dt DATE
) PARTITIONED BY (dt) WITH (
'bucket' = 'id',
'bucket-num' = '-1', -- 动态桶的标志
'bucket-mode' = 'cross-partition' -- 明确指定跨分区模式
);注意:'bucket-mode' 是 Paimon 的一个配置项,对应代码中的 BucketMode 枚举。
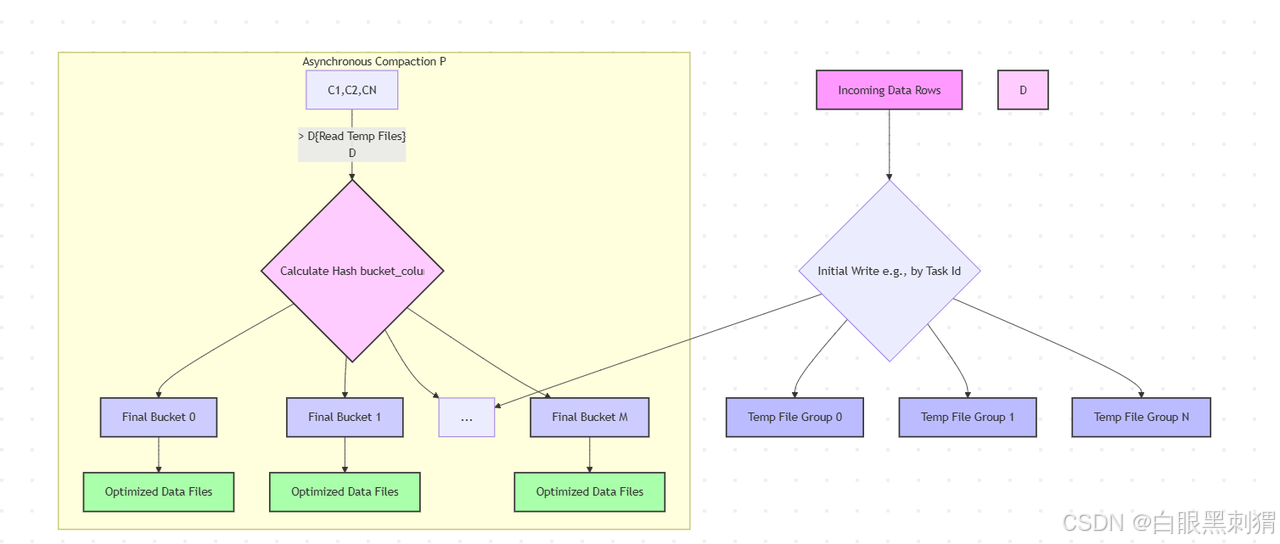
示意图:
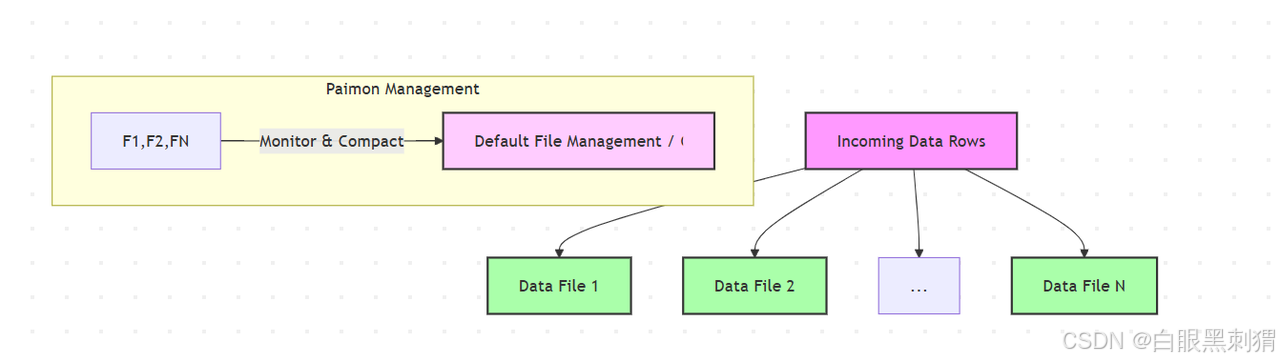
4. BUCKET_UNAWARE (无感知分桶 / 不分桶)
-
特点: 这种模式表示表不进行任何显式分桶。数据不会根据某个列的哈希值分散到不同的逻辑桶中。Paimon 会将数据写入到默认的文件组织结构中,通常是按照 Flink 作业的 Task 并行度或根据写入时间生成的文件。
-
适用场景:
-
小数据量表: 对于数据量不大,或者查询不依赖于分桶优化就能满足性能要求的表。
-
日志或事件流: 如果主要按写入时间或某个顺序进行全表扫描,分桶的收益可能不明显,甚至可能引入额外的哈希计算开销。
-
作为临时表或中间结果表: 在一些 ETL 流程中,可能不需要对所有中间结果表进行精细的分桶。
-
-
优点: 写入简单,没有分桶的计算开销和管理复杂性。
-
缺点: 无法享受分桶带来的查询优化和 Join 性能提升。在数据量大时,可能会有全表扫描、小文件过多或大文件性能瓶颈的问题。
-
设置方式: 不指定
bucket参数,或将bucket-num设置为-1且不指定bucket-mode为动态。
CREATE TABLE my_unaware_table (
id BIGINT,
data STRING
) WITH (
-- 不指定 'bucket' 和 'bucket-num',默认即为 BUCKET_UNAWARE
-- 或者显式设置 'bucket-mode' = 'bucket-unaware'
);
5. POSTPONE_MODE (延迟分桶模式)
-
特点: 这是一个比较特殊的模式,通常用于优化实时写入场景。在这种模式下,数据在写入时不会立即进行哈希分桶。而是先将数据写入一个临时的、不分桶的区域(例如,通过写入任务的并行度来组织文件)。分桶操作会在后续的 Compact 过程中异步进行,将数据从临时区域重新组织并分发到正确的桶中。
-
适用场景:
-
高吞吐量实时写入: 当写入的数据量非常大且对写入延迟要求极高时,可以减少写入路径上的哈希计算和文件路由开销。
-
批流一体场景: 流式写入时快速写入,后续批处理或 Compaction 任务负责分桶和优化。
-
写入高峰期: 避免在写入高峰期引入复杂的哈希计算和桶管理。
-
-
优点: 写入延迟低,吞吐量高。
-
缺点: 查询时,在数据未完全 Compact 之前,可能无法充分利用分桶的优势。需要额外的 Compact 任务来保证数据的最终分桶状态。
-
设置方式:
CREATE TABLE my_postpone_table (
id BIGINT,
value STRING,
ts TIMESTAMP
) WITH (
'bucket' = 'id',
'bucket-num' = '50', -- 仍然需要指定桶的数量,但分桶是延迟执行的
'bucket-mode' = 'postpone' -- 明确指定延迟分桶模式
);
总结与选择建议
| BucketMode | 特点 | 优点 | 缺点 | 适用场景 |
| HASH_FIXED | 固定桶数,哈希分桶 | 查询高效,Join 优化 | 难调整,易小文件或巨无霸文件 | 数据量可预测,查询过滤条件固定 |
| HASH_DYNAMIC | 动态调整桶数,哈希分桶 | 自适应数据量,避免文件极端大小 | 元数据管理稍复杂 | 数据量变化大,无法预测 |
| CROSS_PARTITION | 跨分区动态分桶,全局优化桶分布 | 桶的全局分布更均匀,可能利于跨分区操作 | 复杂度高 | 分区表,需要全局桶分布优化 |
| BUCKET_UNAWARE | 不分桶 | 写入简单,无分桶开销 | 无查询优化,易小文件或大文件问题 | 小数据量表,日志表,中间结果表 |
| POSTPONE_MODE | 延迟分桶,写入时无分桶,Compaction 时分桶 | 实时写入低延迟,高吞吐量 | 查询优化有延迟,依赖 Compaction 任务 | 高吞吐量实时写入,批流一体场景 |
在实际使用中,你需要根据表的具体特点、数据量、写入模式、查询需求以及对性能的要求,权衡利弊,选择最适合的 BucketMode。对于大部分 OLAP 场景,HASH_FIXED 或 HASH_DYNAMIC 是常用的选择。对于极致的实时写入,POSTPONE_MODE 可以提供更好的写入性能。
3 源码分析
入口
// 参数 1 数据流 row 2 输入数据的数类型(字段)
FlinkSinkBuilder sinkBuilder = new FlinkSinkBuilder(table).forRow(data, dataType);
sinkBuilder.build();
see.execute();
//----------------------------------------------------------
public DataStreamSink<?> build() {
setParallelismIfAdaptiveConflict();
input = trySortInput(input);
DataStream<InternalRow> input = mapToInternalRow(this.input, table.rowType());
if (table.coreOptions().localMergeEnabled() && table.schema().primaryKeys().size() > 0) {
SingleOutputStreamOperator<InternalRow> newInput =
input.forward()
.transform(
"local merge",
input.getType(),
new LocalMergeOperator.Factory(table.schema()));
forwardParallelism(newInput, input);
input = newInput;
}
BucketMode bucketMode = table.bucketMode();
switch (bucketMode) {
case POSTPONE_MODE:
return buildPostponeBucketSink(input);
case HASH_FIXED:
return buildForFixedBucket(input);
case HASH_DYNAMIC:
return buildDynamicBucketSink(input, false);
case CROSS_PARTITION:
return buildDynamicBucketSink(input, true);
case BUCKET_UNAWARE:
return buildUnawareBucketSink(input);
default:
throw new UnsupportedOperationException("Unsupported bucket mode: " + bucketMode);
}
}
//-----------------------------------------------------------------------
protected DataStreamSink<?> buildForFixedBucket(DataStream<InternalRow> input) {
int bucketNums = table.bucketSpec().getNumBuckets();
if (parallelism == null
&& bucketNums < input.getParallelism()
&& table.partitionKeys().isEmpty()) {
// For non-partitioned table, if the bucketNums is less than job parallelism.
LOG.warn(
"For non-partitioned table, if bucketNums is less than the parallelism of inputOperator,"
+ " then the parallelism of writerOperator will be set to bucketNums.");
parallelism = bucketNums;
}
DataStream<InternalRow> partitioned =
partition(
input,
new RowDataChannelComputer(table.schema(), logSinkFunction != null),
parallelism);
FixedBucketSink sink = new FixedBucketSink(table, overwritePartition, logSinkFunction);
return sink.sinkFrom(partitioned);
}
//-----------------------------------------------------------------------------------
@Override
public int channel(InternalRow record) {
extractor.setRecord(record);
// 获取分区 获取分桶
return channel(extractor.partition(), extractor.bucket());
}
//------------------------------------------------------------------------------
public interface KeyAndBucketExtractor<T> {
Logger LOG = LoggerFactory.getLogger(KeyAndBucketExtractor.class);
void setRecord(T record);
BinaryRow partition();
int bucket();
BinaryRow trimmedPrimaryKey();
BinaryRow logPrimaryKey();
static int bucketKeyHashCode(BinaryRow bucketKey) {
assert bucketKey.getRowKind() == RowKind.INSERT;
return bucketKey.hashCode();
}
static int bucket(int hashcode, int numBuckets) {
assert numBuckets > 0;
return Math.abs(hashcode % numBuckets);
}
} 去看具体的实现类
//-------------------------------------------------------------------------
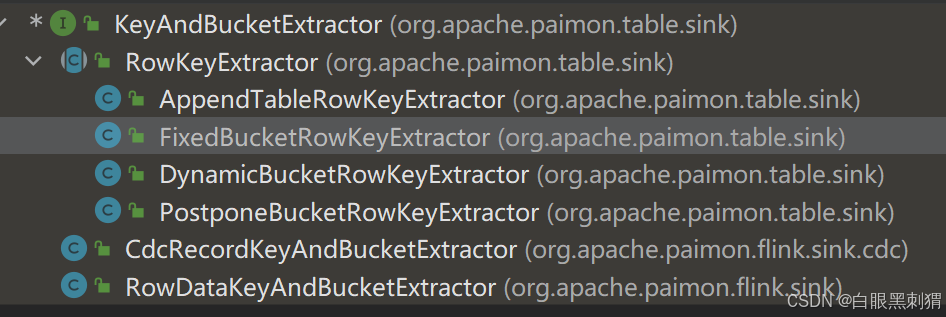
private BinaryRow bucketKey() {
if (sameBucketKeyAndTrimmedPrimaryKey) {
return trimmedPrimaryKey();
}
if (reuseBucketKey == null) {
reuseBucketKey = bucketKeyProjection.apply(record);
}
return reuseBucketKey;
}
@Override
public int bucket() {
BinaryRow bucketKey = bucketKey();
if (reuseBucket == null) {
reuseBucket =
KeyAndBucketExtractor.bucket(
KeyAndBucketExtractor.bucketKeyHashCode(bucketKey), numBuckets);
----> 将两个参数传递给接口中处理
}
return reuseBucket;
}
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)