用100条数据微调大模型Llama2-7B源码解析——李宏毅大模型2025作业5
本文介绍了一个使用LoRA微调LLaMA2-7B模型的完整流程。首先进行环境准备与安装,加载预训练模型。然后添加LoRA适配器,将可训练参数从67.78亿降至399.8万(仅0.59%)。模型训练采用SFTTrainer,设置LoRA超参数并进行监督微调。最后进行模型推理评估和权重保存。
目标:微调 LLaMA2-7B 模型
使用数据: 从Alpaca 52k dataset.中抽取100条数据。
一、 代码结构简述
这个 Notebook 的整体结构遵循一个标准的机器学习项目流程:
-
环境准备与安装:
- 检查 GPU 可用性 ( !nvidia-smi )。
- 安装所有必需的 Python 库,如 unsloth , transformers , torch , peft , trl 等。(环境很容易遇到冲突,注意版本)
- 克隆外部代码仓库。
-
模型和分词器加载:
- 使用 unsloth 的 FastLanguageModel 加载预训练的 LLaMA2-7B 模型。这里利用了 4-bit 量化 ( load_in_4bit=True ) 以节省显存。
- 加载对应的分词器 ( tokenizer )。
-
数据预处理 :
- 加载 huggingface 上的 alpaca 数据集。
- 定义一个格式化函数,将原始数据转换为模型训练所需的对话格式(ShareGPT 格式)。
- 数据筛选与探索: 这部分代码加载了数据集,计算了每个对话的长度,并按长度进行了排序。 这是您需要重点关注和修改的部分,目的是从5万多条数据中挑选出最有效的100条用于训练。
- 数据格式化与模板应用: 选择了100条数据后,将其格式化,并应用模型的聊天模板。
-
模型微调 :
- 使用 get_peft_model 为模型添加 LoRA 适配器,并进行相关配置(如 r , lora_alpha , target_modules 等)。
- 配置 SFTTrainer (Supervised Fine-tuning Trainer),设置训练参数,如优化器、学习率、训练步数等。
- 调用 trainer.train() 开始训练。
-
推理与评估:
- 模型推理: 在训练完成后,使用 model.generate 或 pipeline 对新的指令进行推理,以检验微调效果。
- 模型保存: 将训练好的 LoRA 适配器权重保存到本地。
- 模型加载与合并 (可选): 演示了如何加载保存的适配器并与基座模型合并,以便于后续部署。
二、 具体代码
以下代码请用jupyter!
1. 环境准备与安装
!nvidia-smi
可以看到这里用的是一块Tesla T4 GPU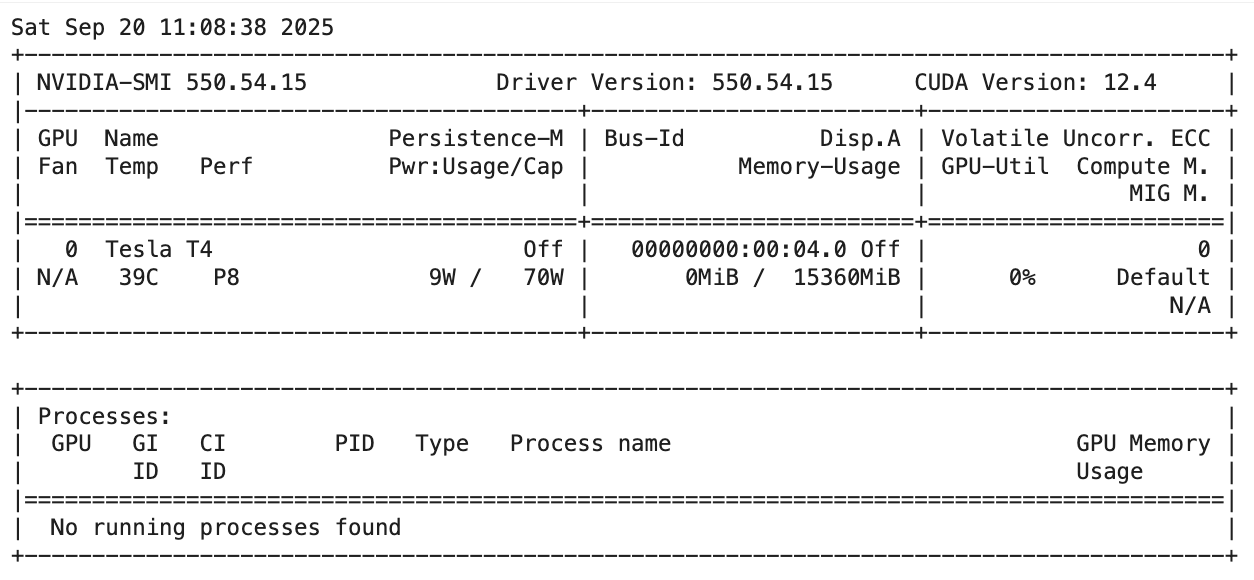
安装环境
%%capture
# Temporarily as of Jan 31st 2025, Colab has some issues with Pytorch
# Using pip install unsloth will take 3 minutes, whilst the below takes <1 minute:
!pip install --no-deps bitsandbytes==0.41.0 accelerate==0.21.0 xformers==0.0.20 peft==0.5.0 trl==0.7.4 triton
!pip install --no-deps cut_cross_entropy
!pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
!pip install unsloth[cu121]==2023.10.26 # Try an older, potentially more stable unsloth version
!pip install transformers==4.34.0 # Use transformers version compatible with older unsloth/peft
gitclone作业数据
!git clone https://github.com/ericsunkuan/ML_Spring2025_HW5.git
注意,这里的环境非常容易冲突,可能后续需要更换环境,可以用以下代码打印出最终的环境
import sys
print(sys.version)
import transformers, trl, torch
print("transformers:", transformers.__version__)
print("trl:", trl.__version__)
print("torch:", torch.__version__)
2. 模型和分词器加载
这里的参数,重点说下
- load_in_4bit:True 含义为4位量化,4位量化可以减少模型占用的内存和显存,但是更容易引发环境冲突。因此,此处我设置为False避免环境冲突。
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = False # Use 4bit quantization to reduce memory usage. Can be False.
加载模型,使用 unsloth 的 FastLanguageModel 加载预训练的 LLaMA2-7B 模型。这里大概需要10分钟,更详细的解读见我上一篇文章大模型微调之 用LoRA微调Llama2(附代码)
### Changing the model here is forbidden !
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Llama-2-7b-bnb-4bit", ### Do not change the model for any other models or quantization versions
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)

使用 get_peft_model 为模型添加 LoRA 适配器,并进行相关配置(如 r , lora_alpha , target_modules 等)。
################# TODO : Tweak the LoRA adapter hyperparameters here. #####################
model = FastLanguageModel.get_peft_model(
model,
r = 16, ### TODO : Choose any number > 0 ! Common values are 4, 8, 16, 32, 64, 128. Higher ranks allow more expressive power but also increase parameter count.
lora_alpha = 16, ### TODO : Choose any number > 0 ! Suggested 4, 8, 16, 32, 64, 128
################# TODO ####################################################################
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
跑出来的日志见截图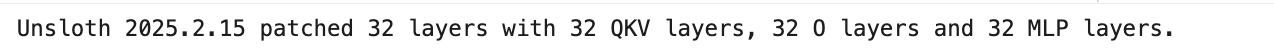
加了lora后,需要调整的参数从67.78亿,下降到了399.8万,只需要调整原始参数的0.59%
trainable, total = 0, 0
for n, p in model.named_parameters():
total += p.numel()
if p.requires_grad:
trainable += p.numel()
print(f"Trainable params: {trainable/1e6:.2f}M / {total/1e6:.2f}M "
f"({100*trainable/total:.2f}%)")

为一个分词器(tokenizer)配置一个特定的聊天模板(chat template),并定义一个函数,该函数能利用这个模板将对话数据转换成模型训练所需的格式化字符串。
from unsloth.chat_templates import get_chat_template
tokenizer = get_chat_template(
tokenizer,
chat_template = "llama-3.1", ### Use llama-3.1 template for better performance here
)
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = [tokenizer.apply_chat_template(convo, tokenize = False, add_generation_prompt = False) for convo in convos]
return { "text" : texts, }
pass
3.数据预处理
- 加载数据集dataset
- 为dataset加载一个text字段,提取数据中assistant对象的回答
- def compute_conversation_length(example): …
- 定义了一个计算对话长度的函数,默认实现是统计对话中所有消息的 总词数 。
- 简单排序方法sorted_dataset_simple_list,将整个数据集按对话长度从短到长(升序)进行排序。
- 高级排序方法advanced_sort_key,定义了一个更复杂的排序函数。这里的默认实现是结合了 对话长度 和数据本身带有的 score 字段,并给 score 赋予了远高于长度的权重。
- 排序是为了对比,哪种排序方法,能找到更适合微调的数据
from datasets import load_dataset, Dataset, load_from_disk
# Load the dataset from Hugging Face
dataset = load_from_disk("/content/ML_Spring2025_HW5/fastchat_alpaca_52k")
# ---------------------------
# Add a "text" field to each example
# ---------------------------
# This function extracts the first assistant message from the conversation
def add_text_field(example):
# Extract the first message where role == 'assistant'
assistant_texts = [msg["content"] for msg in example["conversations"] if msg["role"] == "assistant"]
text = assistant_texts[0] if assistant_texts else ""
return {"text": text}
# Map the function over the dataset to add the "text" column.
dataset = dataset.map(add_text_field)
# Print the dataset structure to confirm the new feature.
print(dataset)
# ---------------------------
#################### TODO : Define a helper function for computing conversation length ###############
# The default "conversation length" here refers to the length of the input (human) and output (gpt), you can modify it at your will
def compute_conversation_length(example):
# Compute total word count across all messages in the 'conversations' field
return sum(len(message["content"].split()) for message in example["conversations"])
#################### TODO ############################################################################
# ---------------------------
# Simple Sorting Method (Default)
# ---------------------------
# Sort the dataset from shortest to longest conversation (by word count)
sorted_dataset_simple_list = sorted(dataset, key=compute_conversation_length, reverse=True)
# Convert back to a Dataset object
sorted_dataset_simple = Dataset.from_list(sorted_dataset_simple_list)
print("\nTop examples sorted by simple conversation length:")
for entry in sorted_dataset_simple.select(range(5)):
print(f"ID: {entry['id']}, Conversation Length: {compute_conversation_length(entry)}")
# ---------------------------
############## Advanced Sorting Method (TODO : Modify the sorting key ##################
# ---------------------------
# Default : Sorting based on Combining conversation length with the 'score' field using a weighted sum.
# Here, we multiply the score by 10 and add it to the conversation length.
def advanced_sort_key(example):
conversation_len = compute_conversation_length(example)
score = example["score"]
return 1e-5 * conversation_len + score * 1
####################################### TODO ###########################################
sorted_dataset_advanced_list = sorted(dataset, key=advanced_sort_key, reverse=True)
# Convert back to a Dataset object
sorted_dataset_advanced = Dataset.from_list(sorted_dataset_advanced_list)
print("\nTop examples sorted by advanced key (combination of conversation length and score):")
for entry in sorted_dataset_advanced.select(range(5)):
print(f"ID: {entry['id']}, Advanced Key Value: {advanced_sort_key(entry)}")
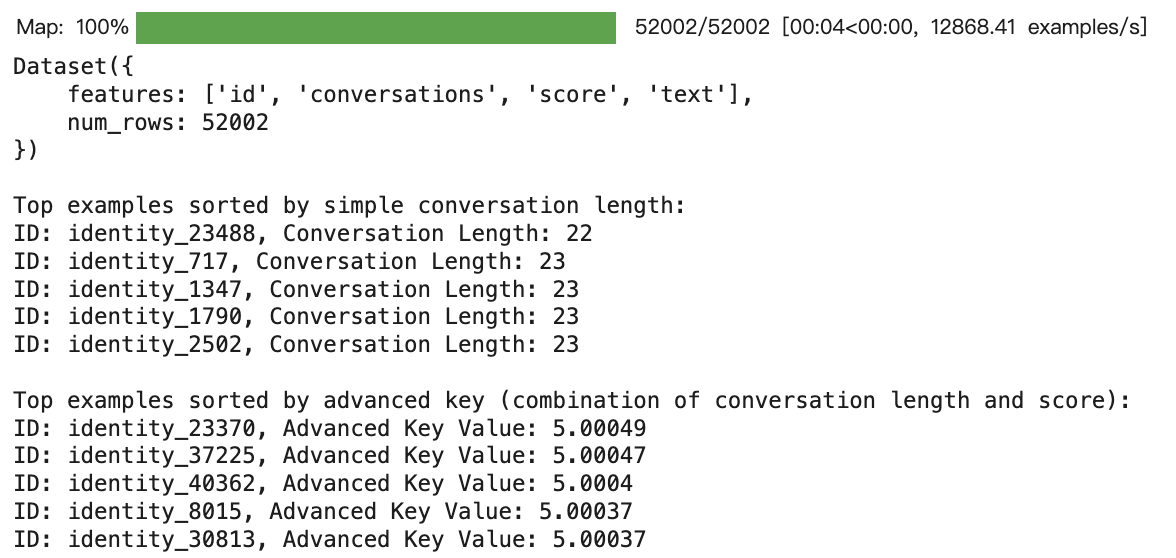
看一眼advanced key第一高的数据,长什么样子。
选择100条数据,可以选择简单排序或是改进排序
################# TODO : select the simple or advanced dataset for training ##############
dataset_used = "sorted_dataset_simple" #sorted_dataset_advanced
################# TODO ###################################################################
if dataset_used == "sorted_dataset_simple":
train_dataset = sorted_dataset_simple.select(range(0,100)) ### You can also select from the middle, e.g. sorted_dataset_simple.select(range(50,150))
else:
train_dataset = sorted_dataset_advanced.select(range(0,100))
from unsloth.chat_templates import standardize_sharegpt
train_dataset = standardize_sharegpt(train_dataset)
train_dataset = train_dataset.map(formatting_prompts_func, batched = True,)
4.模型微调
这段代码的核心作用是 配置和初始化一个 SFTTrainer (Supervised Fine-tuning Trainer) 。这个 Trainer 是 trl 库提供的核心工具,它封装了使用 transformers 库进行模型监督式微调的绝大部分复杂逻辑,让您可以用更简洁的代码来启动、监控和管理训练过程。
代码可以分为三个主要部分:导入库、定义超参数配置、实例化 SFTTrainer 。
- 1.导入必要的库:
- SFTTrainer : 用于监督式微调的主要训练器类。
- TrainingArguments : 一个数据类,用于封装所有训练相关的配置,如学习率、批大小、优化器等。
- DataCollatorForSeq2Seq : 一个辅助类,用于将多个训练样本智能地打包成一个批次(batch),它会负责处理填充(padding)等细节。
- is_bfloat16_supported : Unsloth 提供的工具函数,用于检测当前硬件是否支持 bfloat16 精度,这是一种比 float16 更适合深度学习的半精度浮点格式。
- 2.定义训练超参数 ( training_config ):
- 这是一个 核心的 TODO 区域 ,代码将所有重要的训练超参数集中存放在一个名为 training_config 的字典中。这样做的好处是方便您集中修改和管理,而不用在 TrainingArguments 的长长参数列表中寻找。
- 注释明确提示您,您可以在这里“Tweak”(微调)这些参数来探索最佳的训练效果。
- 3.实例化 SFTTrainer :
- 这是代码的最终目的。它创建了一个 trainer 对象,这个对象已经准备好,只需要调用 trainer.train() 就可以开始训练了。
- 它将模型、分词器、数据集以及上面定义的所有训练配置整合在一起。
from trl import SFTTrainer
from transformers import TrainingArguments, DataCollatorForSeq2Seq
from unsloth import is_bfloat16_supported
################# TODO : Tweak the training hyperparameters here. #####################
training_config = {
"per_device_train_batch_size": 2,
"gradient_accumulation_steps": 4,
"warmup_steps": 10,
"num_train_epochs": 2,
"learning_rate": 2e-4,
"optim": "adamw_8bit",
"weight_decay": 0.01,
"lr_scheduler_type": "linear",
"seed": 3407, ### Do not modify the seed for reproducibility
}
################# TODO #################################################################
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = train_dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
data_collator = DataCollatorForSeq2Seq(tokenizer = tokenizer),
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = training_config["per_device_train_batch_size"],
gradient_accumulation_steps = training_config["gradient_accumulation_steps"],
warmup_steps = training_config["warmup_steps"],
num_train_epochs = training_config["num_train_epochs"], # Set this for 1 full training run.
# max_steps = 60,
learning_rate = training_config["learning_rate"],
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = training_config["optim"],
weight_decay = training_config["weight_decay"],
lr_scheduler_type = training_config["lr_scheduler_type"],
seed = training_config["seed"],
output_dir = "outputs",
report_to = "none", # Use this for WandB etc
),
)
# 让模型只为“答案”负责,不为问题负责
from unsloth.chat_templates import train_on_responses_only
trainer = train_on_responses_only(
trainer,
instruction_part = "<|start_header_id|>user<|end_header_id|>\n\n",
response_part = "<|start_header_id|>assistant<|end_header_id|>\n\n",
)
trainer_stats = trainer.train()
# 可以尝试用简单和高级的数据分别训练模型
############## TODO : Curriculum Training ######################
### E.g.
### Step 1. Train on sorted_dataset_simple
### Step 2. Train on sorted_dataset_advanced
参数说明:
training_config 字典中的参数
- per_device_train_batch_size: 2
- 含义: 每个 GPU 设备在一次训练迭代中处理的样本数量。这里设置为 2。
- gradient_accumulation_steps: 4
- 含义: 梯度累积步数。它会让模型连续进行 4 次前向传播和反向传播(计算梯度),但先不更新模型权重,而是将这 4 次的梯度累积起来,然后用累积的梯度进行一次权重更新。
- 作用: 这是一种在显存有限的情况下,模拟更大批次大小(Effective Batch Size)的技巧。这里的等效批次大小为 2 * 4 = 8 。
- warmup_steps: 10
- 含义: 预热步数。在训练开始的前 10 步,学习率会从一个很小的值逐渐增加到设定的初始学习率 2e-4 。
- 作用: 有助于训练初期的稳定性,防止模型因初始学习率过大而产生梯度爆炸。
- num_train_epochs: 2
- 含义: 训练轮次。整个训练数据集将被完整地遍历 2 次。
- learning_rate: 2e-4
- 含义: 学习率。这是优化器更新模型权重的步长。 2e-4 (即 0.0002) 是 LoRA 微调中一个常用的值。
- optim: “adamw_8bit”
- 含义: 优化器类型。这里使用的是 8-bit 版本的 AdamW 优化器,它通过将优化器状态以 8-bit 存储来显著减少显存占用。
- weight_decay: 0.01
- 含义: 权重衰减。一种正则化技术,用于防止模型过拟合,通过在损失函数中添加一个与权重大小相关的惩罚项来实现。
- lr_scheduler_type: “linear”
- 含义: 学习率调度器类型。这里设置为 “linear”,意味着学习率在预热阶段后,会随着训练步数的增加而线性下降,直到训练结束时降为 0。
- seed: 3407
- 含义: 随机种子。用于固定所有随机操作(如权重初始化、数据打乱等),以确保每次运行代码的结果都是完全一样的,便于复现实验结果。注释提醒您不要修改它以保证可复现性。
SFTTrainer 初始化参数
- model : 您要微调的模型对象。
- tokenizer : 与模型配套的分词器。
- train_dataset : 经过预处理的训练数据集。
- dataset_text_field: “text” : 告诉 Trainer 在数据集中名为 “text” 的列里查找需要训练的文本内容。
- max_seq_length : 模型能处理的最大序列长度。超过这个长度的文本会被截断。
- data_collator : 指定如何将样本打包成批次,这里使用了 DataCollatorForSeq2Seq 。
- dataset_num_proc: 2 : 使用 2 个 CPU 进程来并行处理数据集,以加快预处理速度。
- packing: False : 是否启用序列打包。打包可以将多个短序列合并成一个长序列,以提高 GPU 利用率,对于短文本任务可以极大加速训练。这里设置为 False 。
- args : 最重要的参数之一,它接收一个 TrainingArguments 对象,其中包含了所有底层的训练配置。
- fp16 / bf16 : 自动混合精度训练。代码通过 is_bfloat16_supported() 自动选择硬件支持的最佳精度(优先 bf16 ),可以大幅加速训练并减少显存占用。
- logging_steps: 1 : 每训练 1 步就记录一次日志(如 loss)。
- output_dir: “outputs” : 指定保存训练检查点(checkpoints)和最终模型文件的目录。
- report_to: “none” : 指定将训练报告发送到哪里。 “none” 表示不发送,如果设置为 “wandb” ,则会与 Weights & Biases 工具集成,进行实验跟踪。
5.推理与评估
这个函数是一个 解析器(Parser) ,专门用于处理和清洗集成了特定聊天模板(如 Llama-3 模板)的语言模型输出。在进行模型推理和评估时,您会用它来处理模型返回的原始字符串,以便得到一个干净、可读的答案,方便进行后续的展示或评测。
def parse_true_output(text):
"""
Extracts the true assistant output from the decoded model output.
It looks for the assistant header token:
"<|start_header_id|>assistant<|end_header_id|>\n\n"
and extracts everything after it until the first occurrence of "<|eot_id|>".
If the assistant header is not found, it falls back to the last occurrence
of "<|end_header_id|>\n\n". If "<|eot_id|>" is not found, the extraction
continues until the end of the string.
"""
assistant_header = "<|start_header_id|>assistant<|end_header_id|>\n\n"
start_index = text.find(assistant_header)
if start_index != -1:
start_index += len(assistant_header)
else:
# Fallback: use the last occurrence of the generic header ending
generic_header = "<|end_header_id|>\n\n"
start_index = text.rfind(generic_header)
if start_index != -1:
start_index += len(generic_header)
else:
start_index = 0
end_index = text.find("<|eot_id|>", start_index)
if end_index == -1:
end_index = len(text)
return text[start_index:end_index].strip()
这段代码的核心目标是: 使用刚刚微调好的模型,对一个独立的测试数据集( test_set_evol_instruct_150.json )进行推理(Inference),生成模型的回答,并将这些回答保存到一个名为 pred.json 的文件中,以便后续进行评估或提交。
from unsloth.chat_templates import get_chat_template
import json
from datetime import datetime
# 为分词器设置正确的聊天模板
tokenizer = get_chat_template(
tokenizer,
chat_template = "llama-3.1",
)
# 开启Unsloth的快速推理模式
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
# Load the test set JSON file (without GPT responses)
with open("/content/ML_Spring2025_HW5/test_set_evol_instruct_150.json", "r") as infile:
test_data = json.load(infile)
# Dictionary to store inference results
inference_results = {}
# Loop over each data entry in the test set
# 遍历测试集中的每个数据条目
for index,entry in enumerate(test_data):
entry_id = entry.get("id", "unknown_id")
# Build the messages list from the human conversation entries
# (Test set is expected to have only "human" messages)
messages = []
for conv in entry.get("conversations", []):
if conv.get("from") == "human":
messages.append({"role": "user", "content": conv.get("value", "")})
else:
messages.append({"role": "assistant", "content": conv.get("value", "")})
# Create inputs using the chat template (required for generation)
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True, # Must add for generation
return_tensors="pt",
).to("cuda")
################# TODO : Tweak Decoding Parameters here. #####################
# Generate model outputs
outputs = model.generate(
input_ids=inputs,
do_sample=True,
max_new_tokens=100,
use_cache=True,
temperature=1.5,
top_p = 0.9,
top_k = 30,
)
################# TODO ##########################################################
# Decode the generated tokens
decoded_outputs = tokenizer.batch_decode(outputs)
# Parse each output to extract the true assistant response
parsed_outputs = [parse_true_output(output) for output in decoded_outputs]
# Store the result for the current entry
inference_results[entry_id] = {
"input": messages,
"output": parsed_outputs
}
print(f"Inference completed for entry {entry_id}")
#Write the inference results to the prediction JSON file
with open(f"pred.json", "w") as outfile:
json.dump(inference_results, outfile, indent=4)
with open(f"training_config.json", "w") as outfile:
json.dump(training_config, outfile, indent=4)
from google.colab import files
files.download('/content/pred.json')
print("Inference completed for all entries in the test set.")
6.模型保存与加载
模型保存
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")
模型加载
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "lora_model", # The folder path containing of the folder that contains adapter_model.safetensors, adapter_config.json and README.md
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
– 声明–
TAT 谷歌colab只有12小时免费GPU,跑上篇的时候已经薅完了,这一篇跑不出了哭死。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)