小支同学的学习笔记:魔乐 GeekDay 模型推理适配工作坊(团队赛第三)
《vLLM Ascend迁移实操指南》摘要 本文详细记录了vLLM Ascend大模型推理适配工作坊的技术流程。从前期准备(申请NPU算力、场地网络配置)到环境搭建(镜像选择、依赖安装、环境校验),再到模型推理部署的三种方式(交互式终端、在线API、离线脚本),最后是模型上传魔乐社区的方法。重点包括:必须选择特定镜像,正确处理Git LFS大文件,配置inference.yaml文件,以及注意不同
日期:2025 年 9 月 21 日
主题:vLLM Ascend 迁移实操(大模型推理适配)
📢 前期准备:工作坊信息与基础资源
- 实操文档:参考CSDN 博客。
- 场地网络:冠生园五楼无线,账号GSY-HYZX,密码bjgs145802
- 关联社区:可加入 “北京朝阳 AI 社区” 获取更多资源
一、环境配置:从空间创建到依赖安装
1. 体验空间创建(核心步骤)
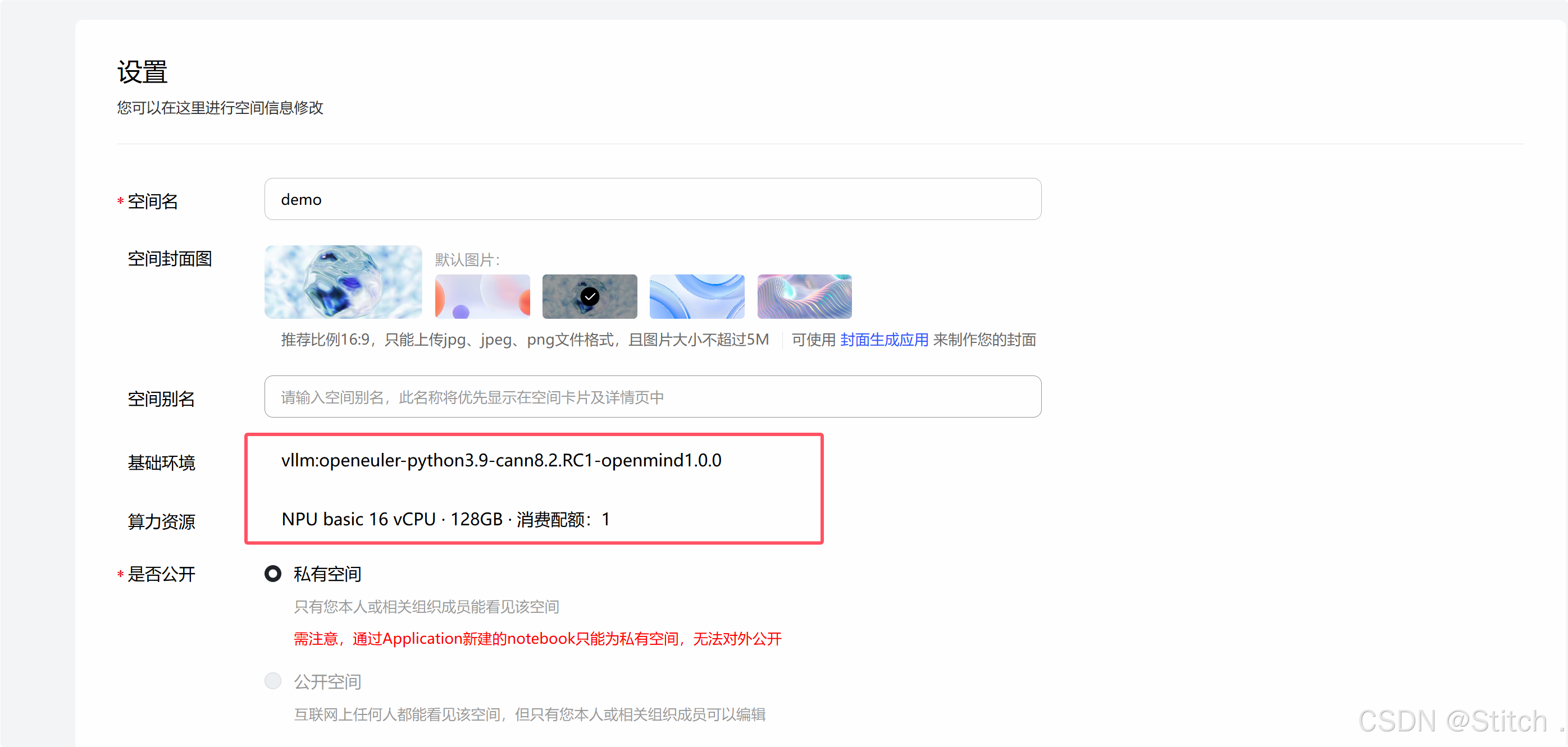
- 镜像选择:必须选vllm:openeuler-python3.9-cann8.2.RC1-openmind1.0.0,确保勾选 NPU 算力资源。
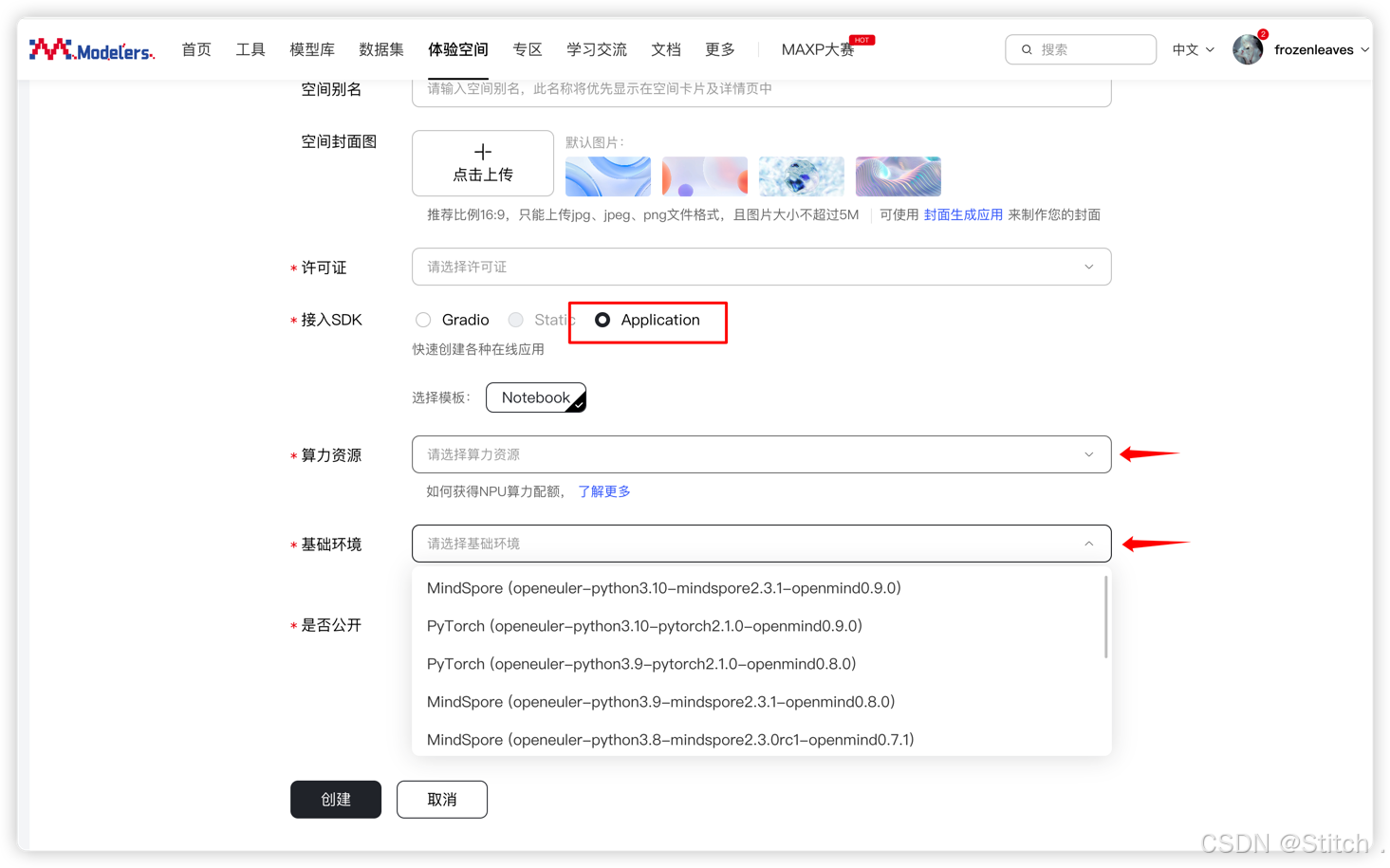
- 接入与许可:接入 SDK 选Application,许可证随意(示例用apache-2.0)。
- 进入方式:容器启动后,打开空间应用,
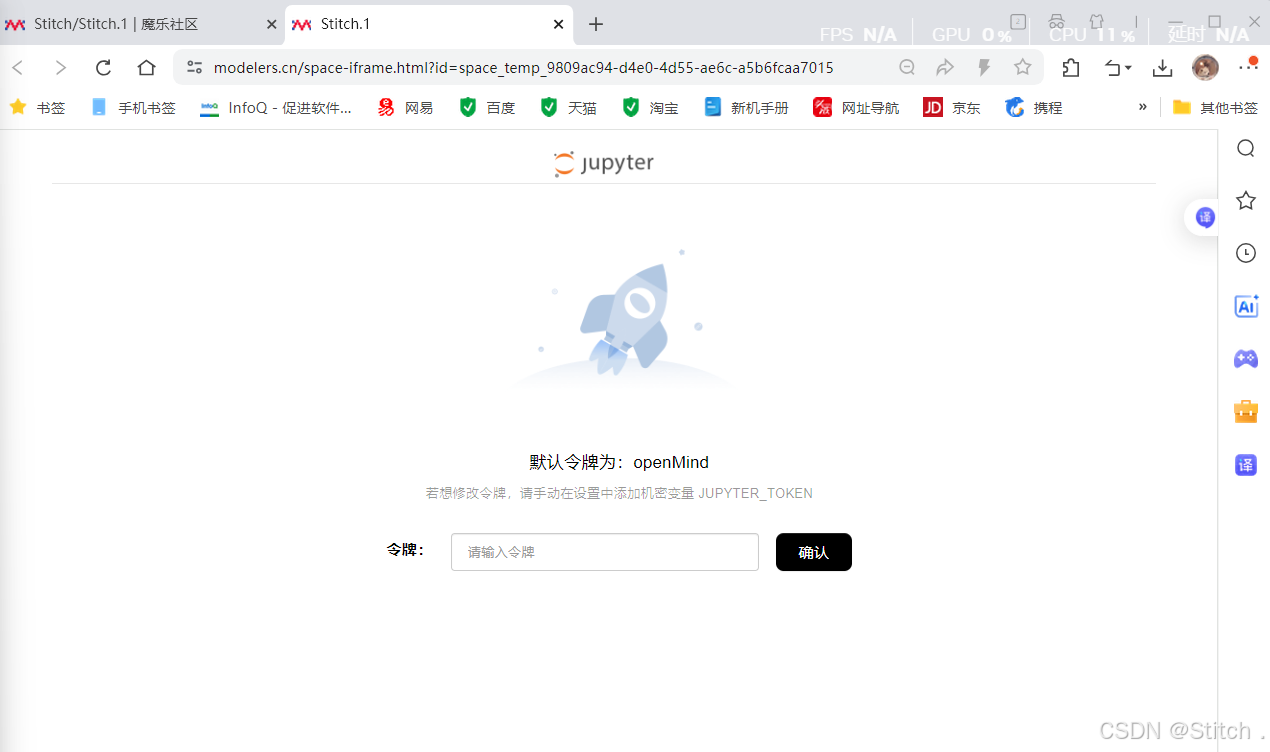
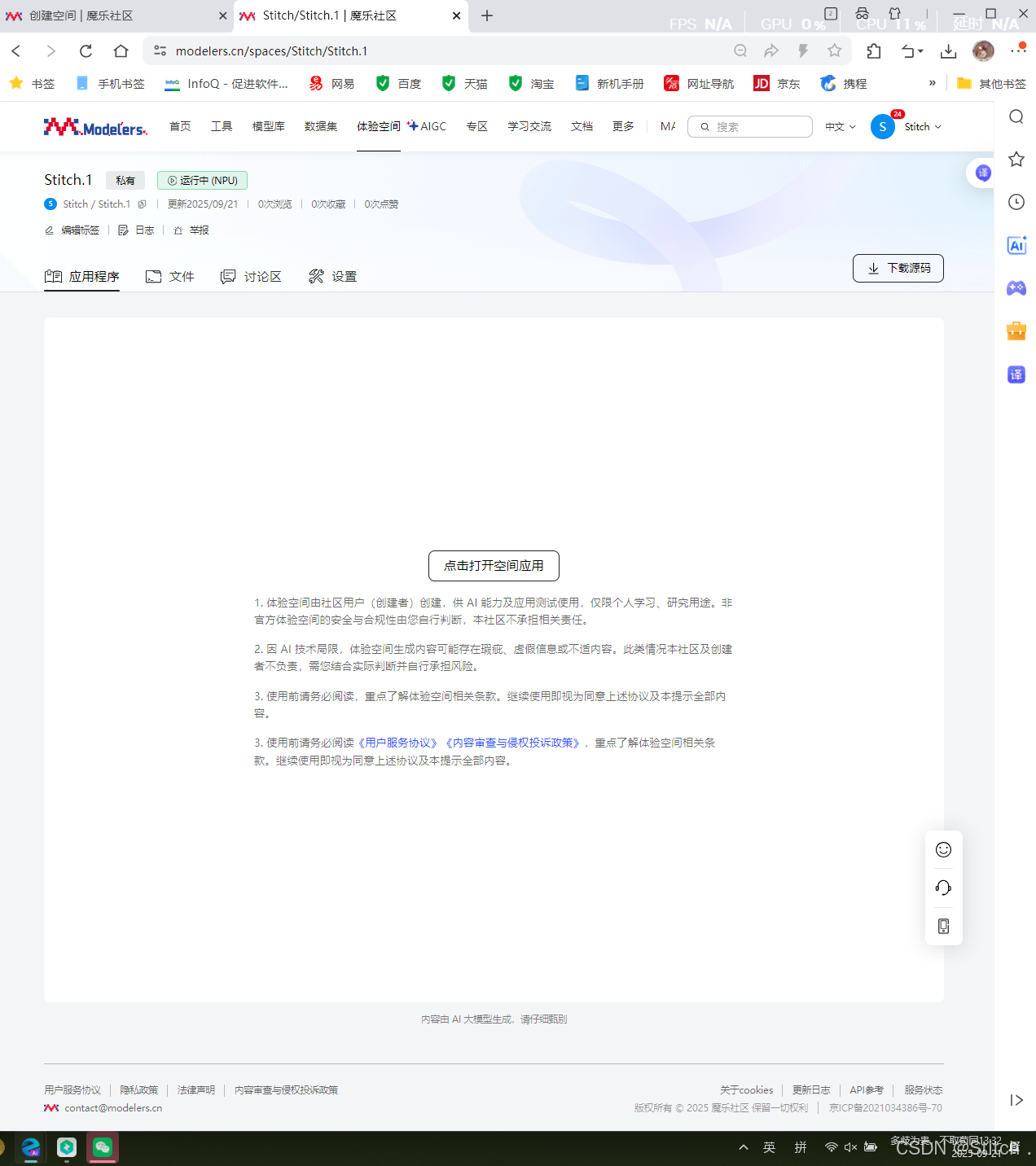 输入界面提示的令牌进入 jupyter lab,
输入界面提示的令牌进入 jupyter lab, - (默认令牌为:openMind,若想修改令牌,请手动在设置中添加机密变量 JUPYTER_TOKEN )
 后续操作(除文件传输)均在 “新建终端” 中完成。
后续操作(除文件传输)均在 “新建终端” 中完成。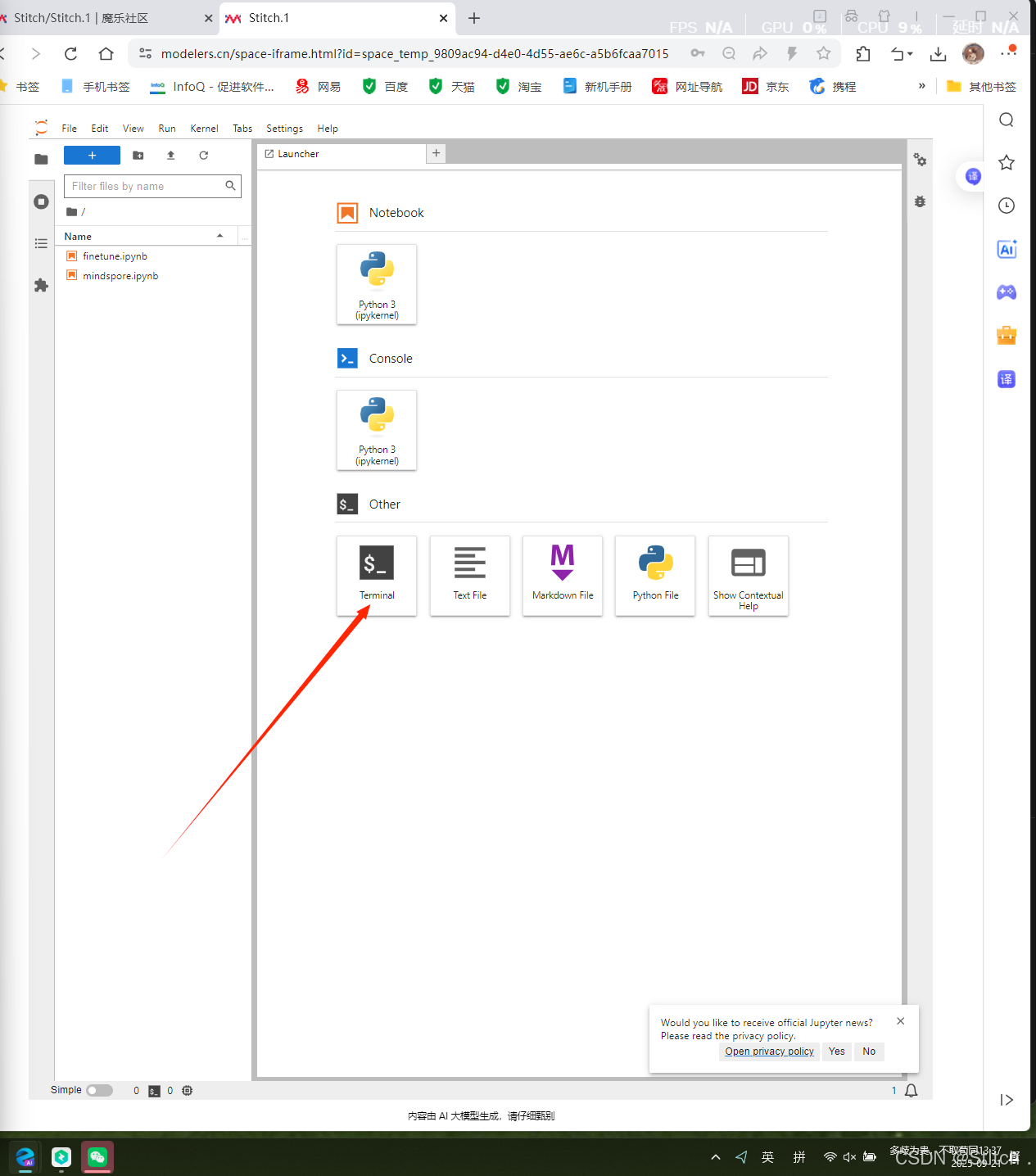 点击后界面:
点击后界面:
2. 依赖包安装(仅补装缺失部分)
基础镜像已含vllm和vllm-ascend,只需安装llama factory,步骤如下:
pip list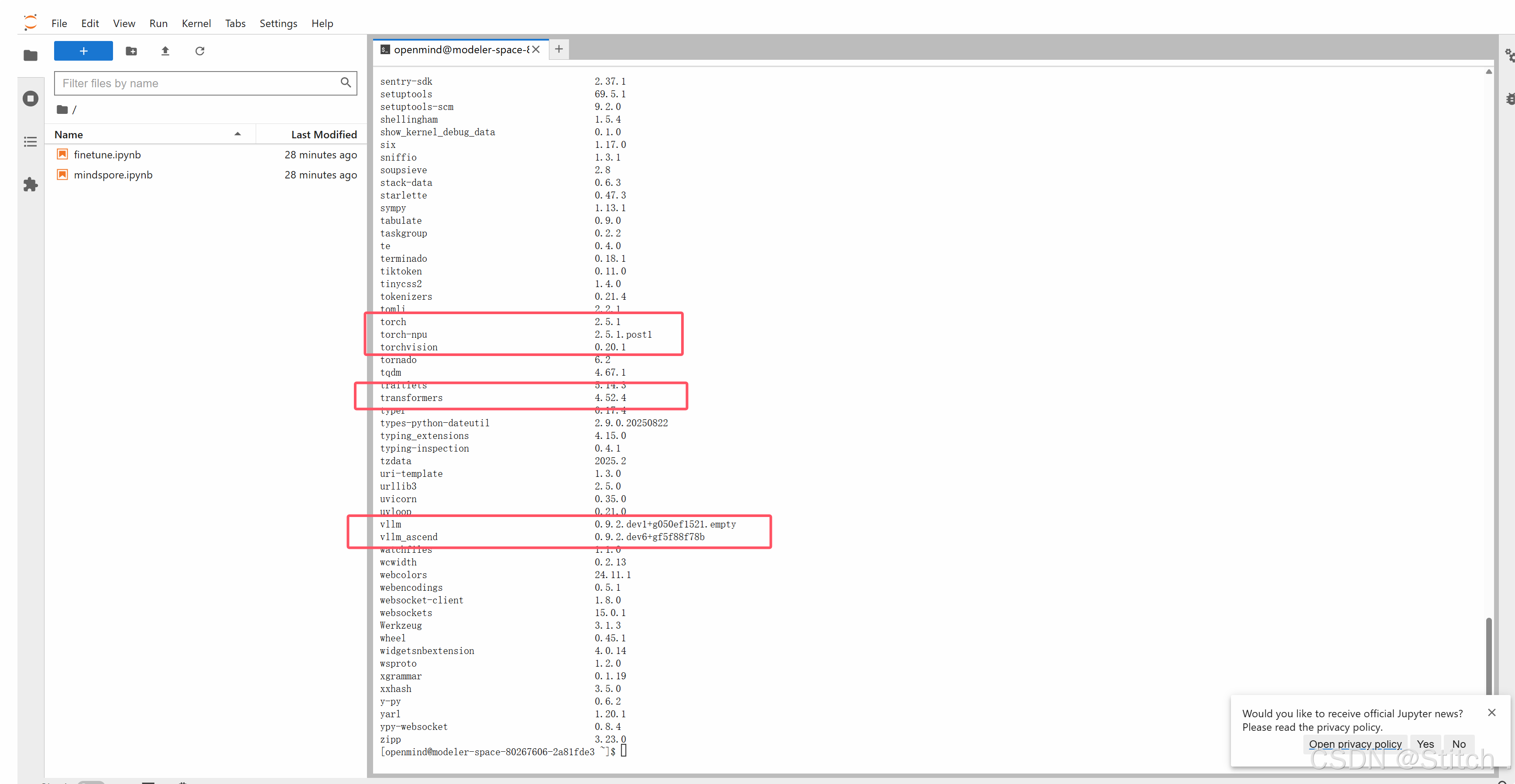
# 配置pip源
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 源码安装llama factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
# 如果无法访问GitHub,可以通过如下镜像链接获取源码
# git clone http://git.lcx.ac.cn:3000/frozenleaves/LLaMA-Factory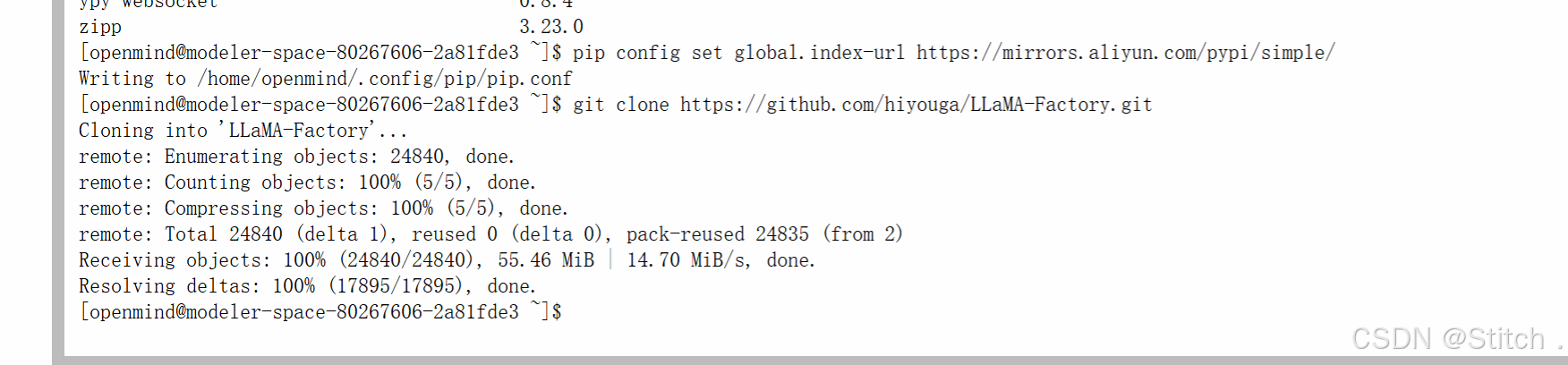
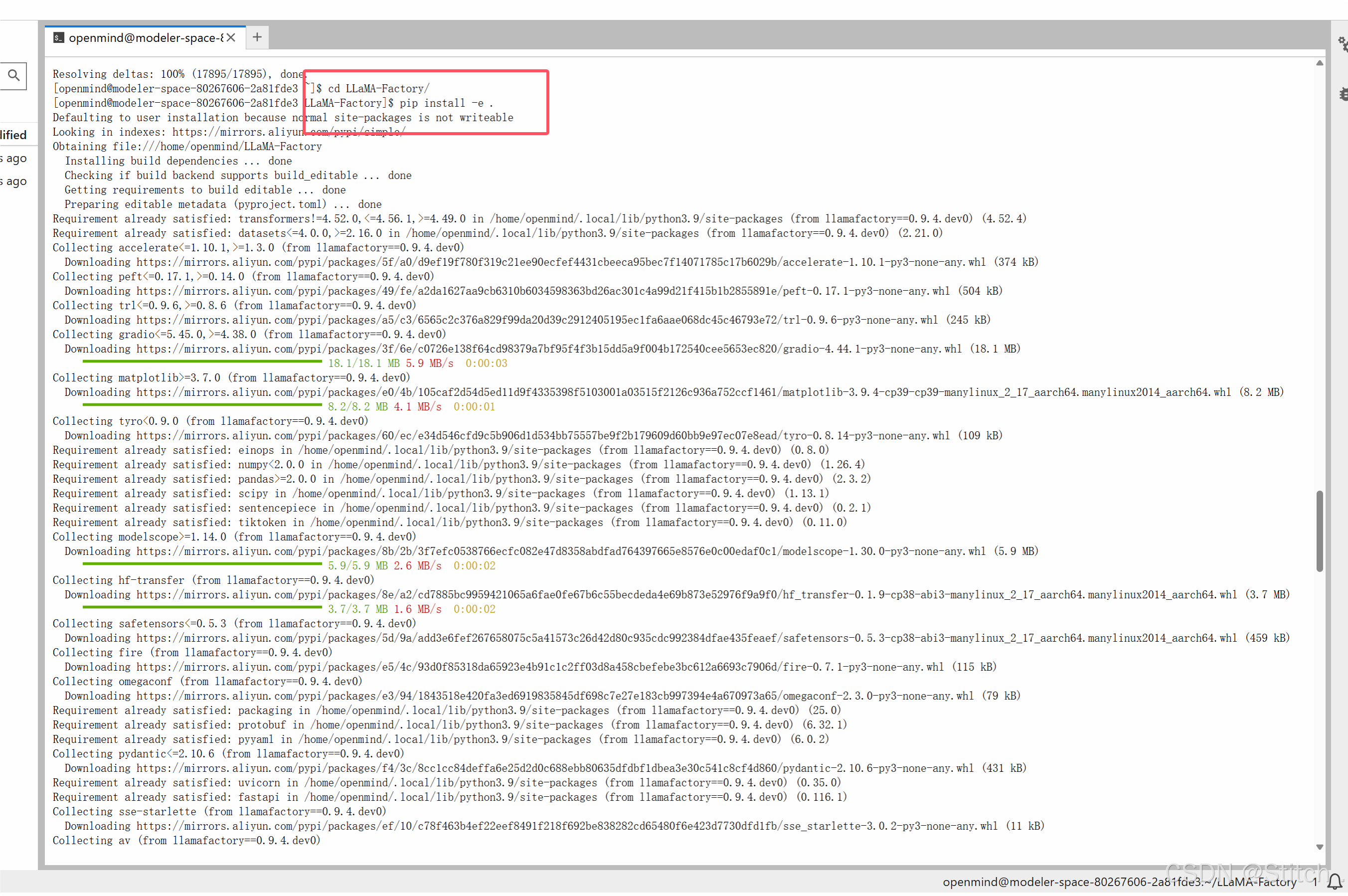
3. 环境校验(确保所有依赖可用)
- 第一步:加载 CANN 包(新终端启动必须执行):
source ~/Ascend/ascend-toolkit/set_env.sh
source ~/Ascend/nnal/asdsip/set_env.sh
source ~/Ascend/nnal/atb/set_env.sh
- 第二步:校验核心包:启动 python 交互终端,输入以下命令,
无报错且torch.npu.is_available()返回True即正常:import torch import torch_npu import vllm import vllm_ascend torch.npu.is_available() # 预期输出True
Python 3.9.9 (main, Sep 10 2025, 15:09:00)
[GCC 10.3.1] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
/home/openmind/.local/lib/python3.9/site-packages/torch_npu/__init__.py:298: UserWarning: On the interactive interface, the value of TASK_QUEUE_ENABLE is set to 0 by default. Do not set it to 1 to prevent some unknown errors
warnings.warn("On the interactive interface, the value of TASK_QUEUE_ENABLE is set to 0 by default. \
>>> import torch_npu
>>> import vllm
INFO 09-16 19:29:33 [importing.py:17] Triton not installed or not compatible; certain GPU-related functions will not be available.
WARNING 09-16 19:29:33 [importing.py:29] Triton is not installed. Using dummy decorators. Install it via `pip install triton` to enable kernel compilation.
INFO 09-16 19:29:36 [__init__.py:39] Available plugins for group vllm.platform_plugins:
INFO 09-16 19:29:36 [__init__.py:41] - ascend -> vllm_ascend:register
INFO 09-16 19:29:36 [__init__.py:44] All plugins in this group will be loaded. Set `VLLM_PLUGINS` to control which plugins to load.
INFO 09-16 19:29:36 [__init__.py:235] Platform plugin ascend is activated
WARNING 09-16 19:29:39 [_custom_ops.py:22] Failed to import from vllm._C with ModuleNotFoundError("No module named 'vllm._C'")
>>> import vllm_ascend
>>> torch.npu.is_available()
File "<stdin>", line 1
torch.npu.is_available()
IndentationError: unexpected indent
>>> torch.npu.is_available()
True
>>> 
- 第三步:校验 llama factory:在 LLaMA-Factory 目录下执行llamafactory-cli env,
可查看版本(示例 0.9.4.dev0)、NPU 类型(Ascend910B2)等信息。[openmind@modeler-space-80267606-2a81fde3 LLaMA-Factory]$ llamafactory-cli env INFO 09-16 19:31:25 [importing.py:17] Triton not installed or not compatible; certain GPU-related functions will not be available. WARNING 09-16 19:31:25 [importing.py:29] Triton is not installed. Using dummy decorators. Install it via `pip install triton` to enable kernel compilation. INFO 09-16 19:31:25 [__init__.py:39] Available plugins for group vllm.platform_plugins: INFO 09-16 19:31:25 [__init__.py:41] - ascend -> vllm_ascend:register INFO 09-16 19:31:25 [__init__.py:44] All plugins in this group will be loaded. Set `VLLM_PLUGINS` to control which plugins to load. INFO 09-16 19:31:25 [__init__.py:235] Platform plugin ascend is activated WARNING 09-16 19:31:30 [_custom_ops.py:22] Failed to import from vllm._C with ModuleNotFoundError("No module named 'vllm._C'") - `llamafactory` version: 0.9.4.dev0 - Platform: Linux-4.19.90-2102.2.0.0068.3.ctl2.aarch64-aarch64-with-glibc2.34 - Python version: 3.9.9 - PyTorch version: 2.5.1 (NPU) - Transformers version: 4.52.4 - Datasets version: 2.21.0 - Accelerate version: 1.10.1 - PEFT version: 0.17.1 - TRL version: 0.9.6 - NPU type: Ascend910B2 - CANN version: 8.2.RC1 - vLLM version: 0.9.2.dev1+g050ef1521 - Git commit: 2b27283ba0566eda9ec7ac335642807189c87e70 - Default data directory: detected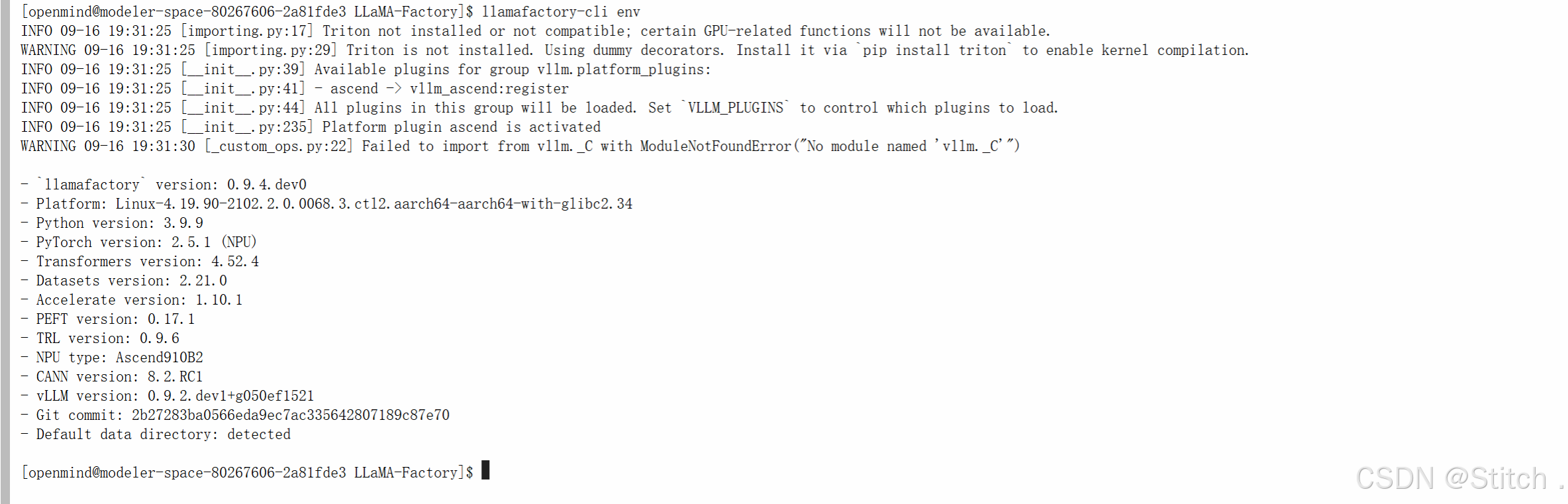
二、模型推理部署:三种推理方式实操
1. 权重下载(关键:处理 LFS 大文件)
- 先克隆模型仓库(示例为 Qwen2.5-VL 和 InternVL3_5):
git clone https://modelers.cn/PyTorch-NPU/Qwen2.5-VL-3B-Instruct.git git clone https://modelers.cn/Intern/InternVL3_5-1B.git
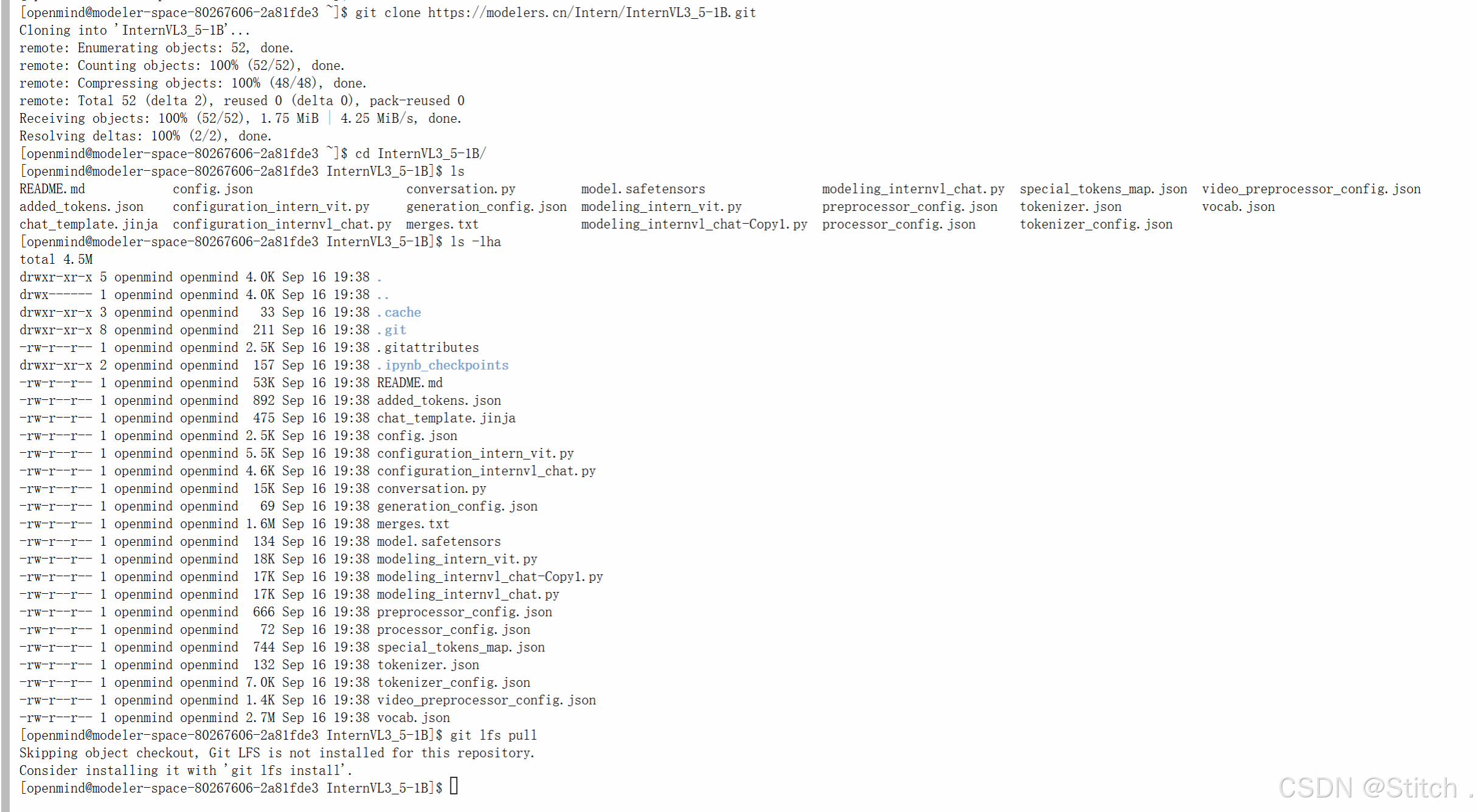
- 进入每个仓库根目录,执行以下命令拉取大文件(否则权重不完整):
git lfs install git lfs pull - 更多的模型可以在魔乐社区模型库下载
2. 交互式终端推理(需配置 yaml 文件)
- 第一步:创建inference.yaml配置文件,内容如下:
# inference.yaml
model_name_or_path: /home/openmind/Qwen2.5-VL-3B-Instruct/
template: qwen2_vl
infer_backend: vllm # choices: [huggingface, vllm]
trust_remote_code: true
infer_dtype: bfloat16
vllm_gpu_util: 0.9
vllm_enforce_eager: true
vllm_maxlen: 2048
- 第二步:启动交互终端:
llamafactory-cli chat inference.yaml
3. 在线推理(两种后端可选)
- vllm 后端(推荐,速度更快):
API_PORT=8000 llamafactory-cli api inference.yaml infer_backend=vllm vllm_enforce_eager=true - huggingface 后端:
API_PORT=8000 llamafactory-cli api inference.yaml infer_backend=huggingface - 注意:InternVL3_5 系列模型用 llama factory 部署有 bug,建议直接用 vllm 启动服务:
vllm serve /home/openmind/Qwen2.5-VL-3B-Instruct/ --port 8000 --max-model-len 16384 --dtype bfloat16- 测试在线推理:用 curl 发 post 请求(示例问图片内容):
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/home/openmind/Qwen2.5-VL-3B-Instruct/", "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": [ {"type": "image_url", "image_url": {"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/qwen.png"}}, {"type": "text", "text": "What is the text in the illustrate?"} ]} ] }'
4. 离线推理(用 vllm 库写脚本)
- 创建infer.py脚本,核心注意模型占位符差异(Qwen2.5-VL 用<|image_pad|>,InternVL3_5 用<image>):
from vllm import LLM import PIL # 1. 初始化模型(路径按实际调整) llm = LLM(model="/home/openmind/Qwen2.5-VL-3B-Instruct/", dtype='bfloat16', gpu_memory_utilization=0.7, enforce_eager=True, max_model_len=15565) # 2. 准备prompt和图片(注意占位符) prompt = "user:\n<|image_pad|>这张图片是什么" # Qwen2.5-VL专用 image = PIL.Image.open("/home/openmind/LLaMA-Factory/data/mllm_demo_data/1.jpg") # 图片路径 # 3. 执行推理并输出 outputs = llm.generate({ "prompt": prompt, "multi_modal_data": {"image": image}, }) for o in outputs: print(o.outputs[0].text) - 更多样例:参考vllm 官方文档。
三、模型上传:分享至魔乐社区
1. 创建模型仓库
- 进入魔乐社区个人中心,点击 “创建模型”,按提示填写基本信息(如名称、描述),完成后生成空仓库。
2. 上传权重文件(Git 工具)
- 第一步:创建访问令牌:在个人中心生成 “write” 权限的令牌,保存好(后续 push 需用)。
- 第二步:克隆仓库并上传文件:
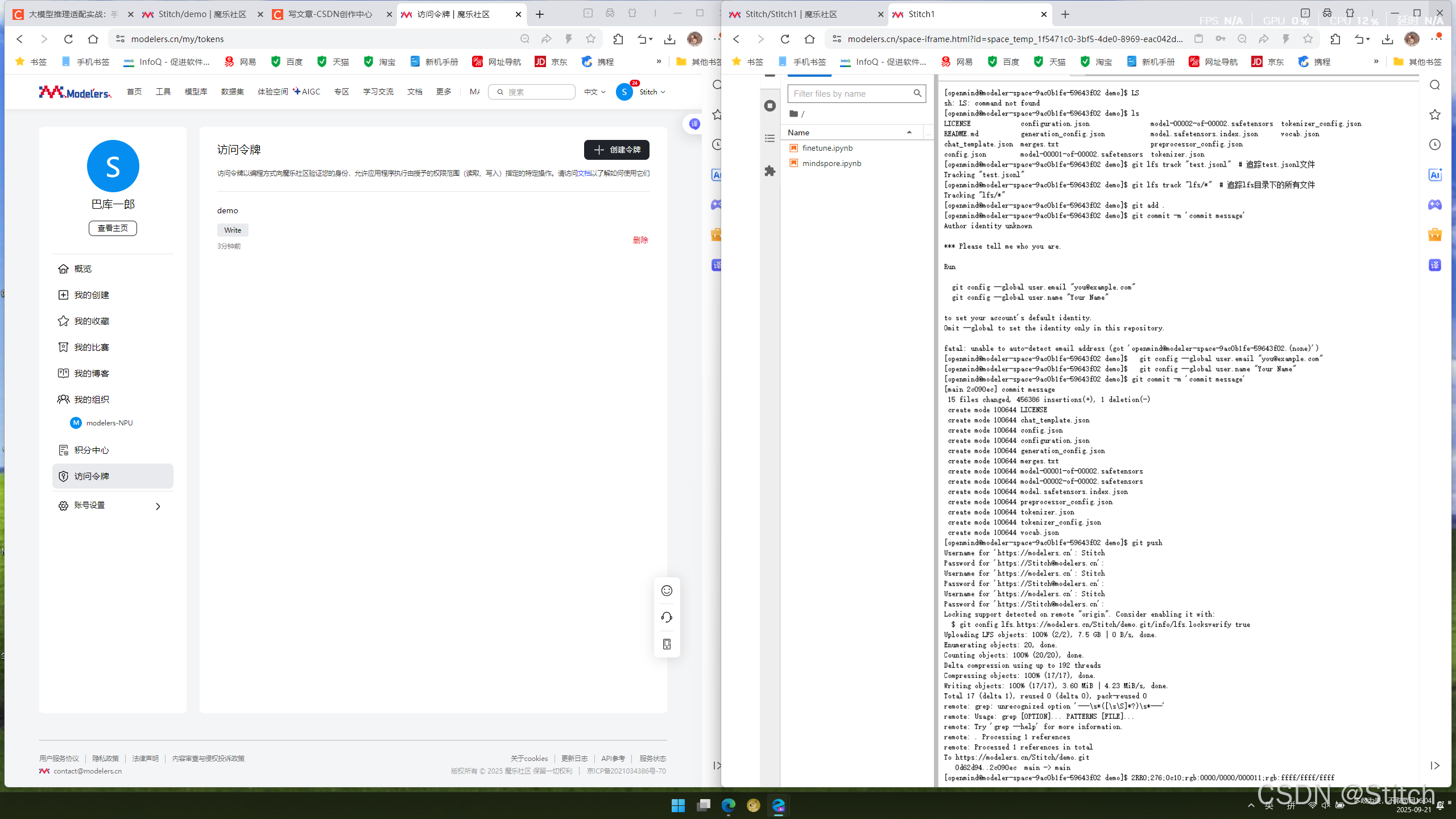
# 1. 克隆自己的空仓库(替换为实际仓库链接) git clone https://modelers.cn/frozenleaves/Qwen2.5-VL-3B-Instruct.git # 2. 进入目录,复制权重文件到该目录 cd Qwen2.5-VL-3B-Instruct/ # cp 本地权重路径/* ./ (复制权重) # 3. 配置LFS追踪大文件(避免上传失败) git lfs track "*.7z" "*.bin" "*.bz2" "*.ckpt" "*.h5" "*.lfs.*" "*.mlmodel" "*.model" "*.npy" "*.npz" "*.onnx" "*.pb" "*.pickle" "*.pkl" "*.pt" "*.pth" "*.rar" "*.safetensors" "saved_model/**/*" "*.tar.*" "*.tar" "*.tgz" "*.zip" "*tfevents*" "*.gz" # 4. 提交并推送(密码处输入之前创建的令牌) git add . git commit -m "init commit" # 提交备注 git push
- 后续更新:重复git add .、git commit、git push即可。
结语
历时数日的魔乐 GeekDay 模型推理适配工作坊圆满落幕,在这场聚焦 vLLM Ascend 迁移实操的技术盛宴中,我们团队凭借扎实的技术积累与高效的协作配合,成功斩获团队赛第三名的佳绩。这份荣誉不仅是对我们技术能力的肯定,更是对整个实操过程中每一步探索与突破的最佳见证。
回顾本次工作坊,从前期申请 NPU 算力组织、熟悉魔乐社区构建空间,到一步步完成环境配置 —— 精准选择镜像、补装依赖包、细致校验环境,再到深入开展模型推理部署,尝试交互式终端推理、在线推理、离线推理三种方式,最后顺利将模型上传至魔乐社区实现成果分享,每一个环节都凝聚着团队成员的汗水与智慧。我们曾为解决 Git LFS 大文件拉取问题反复尝试,也曾为调试推理脚本中的模型占位符差异深入研究,正是这些不断克服困难的过程,让我们对 vLLM Ascend 迁移实操有了更深刻的理解与掌握。
此次工作坊的经历,不仅让我们提升了大模型推理适配的技术水平,更让我们感受到了团队协作的强大力量。同时,也要感谢魔乐社区提供的优质资源与平台,以及 “北京朝阳 AI 社区” 带来的额外支持,为我们的学习与实践创造了良好条件。
未来,我们将带着本次工作坊的收获与荣誉,继续在大模型技术领域深耕细作,不断探索更多技术可能性,将所学知识应用到实际项目中,为人工智能技术的发展贡献自己的一份力量。也期待在未来的技术交流活动中,能与更多同行相互学习、共同进步!




有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)