基于Dify实现简历自动筛选过滤
本文介绍了一个基于大模型和Agent技术的简历筛选系统实现方案。该系统通过自动化流程实现简历解析、评估和筛选,解决了HR人工筛选费时费力的问题。系统支持PDF、DOCX等多种格式简历,提供两种解析方式(文档提取器和自定义代码),并采用LLM模型进行简历评估。工作流程包括简历解析、文本提取、条件分支处理和智能评估等环节,最终输出符合岗位要求的筛选结果。开发者可根据实际需求调整提示词,并加入知识库,支
最近帮助人力资源部门做了一个简洁的筛选简历agent,大家知道企业人力资源在面试之前需要从海量简历中筛选出符合要求的简历,这种筛选工作需要花费大量的精力和时间,如何借助大模型和agent技术实现呢。本文就是一个简单的示例实现,目前实现了一个简历解析,分析评估和最终结果输出等,大家可根据自己的需求进行提示词编写,并加入知识库等,简历读取可以采用dify提供的文档提取器,也可以通过自行编码实现简历读取,后续操作类似,详见下面的流程图介绍。有关多份简历的筛选主要采取迭代模式,如果需要后续我再分享。简历筛选的具体实现如下,供大家参考学习。
一、数据准备
准备一批简历,格式可以是pdf、docx、txt等,pdf最好是双层pdf。
二、工作流程设计
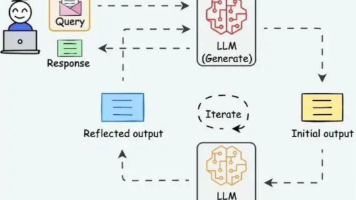
工作流程详见下图。
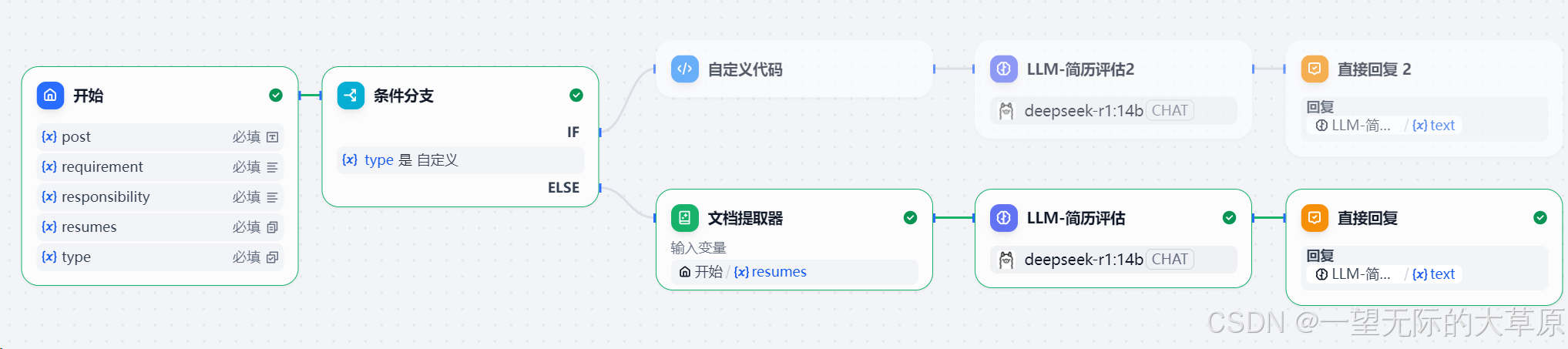
1.开始和条件分支节点
输入变量为岗位名称,岗位需求,岗位职责,简历文件和解析类型,解析类型有提取器和自定义两种方式。条件分支节点用于路由不同解析方式的路径。
2.文档提取器
输入变量为简历文件,插件节点输出为简历解析后的文本内容。
3.自定义代码
主要实现简历文件的读取,由多个适配器组成,比如pdfadAdapter,docAdapter等等,实现pdf/docx等文件的解析输出,输出变量为简历的文本内容。示例pdfAdapter代码如下。
# pdf格式的简历解析:pdfAdapter
import fitz
import urllib.request
import urllib.error
from io import BytesIO
import os
def main(inputs: dict) -> dict:
# 1. 拼完整 URL
base = os.environ.get("API_BASE_URL", "http://x.x.x.x:5001") # 默认官方云地址
full_url = base.rstrip("/") + inputs[0]['url'] # f['url'] 以 /files 开头
# 2. 下载x.x.x.x
with urllib.request.urlopen(full_url, timeout=60) as resp:
pdf_bytes = resp.read()
# 3. PyMuPDF 提取文本
pdf_document = fitz.open(stream=BytesIO(pdf_bytes), filetype='pdf')
# 4. 调试用
start_page_num = 0
text_file_full=''
# 遍历每一页
for page_num in range(start_page_num, len(pdf_document)):
page = pdf_document[page_num]
# 1.提取每一页的文本:直接用PyMuPDF提取文件中的文本信息
# text = page.get_text() # 直接获取文本信息
# 根据页眉页脚宽度获取文本信息
rect = page.rect
clip_top = 70 # 假设页眉高度是80
clip_bottom = 80 # 假设页脚的高度是90
crop = fitz.Rect(0, clip_top, rect.width, rect.height - clip_bottom)
text = page.get_text(clip=crop) # 直接获取文本信息
# 逐页追加输出所有文本
text_file_full=text_file_full+text
return {
"result": text_file_full
}
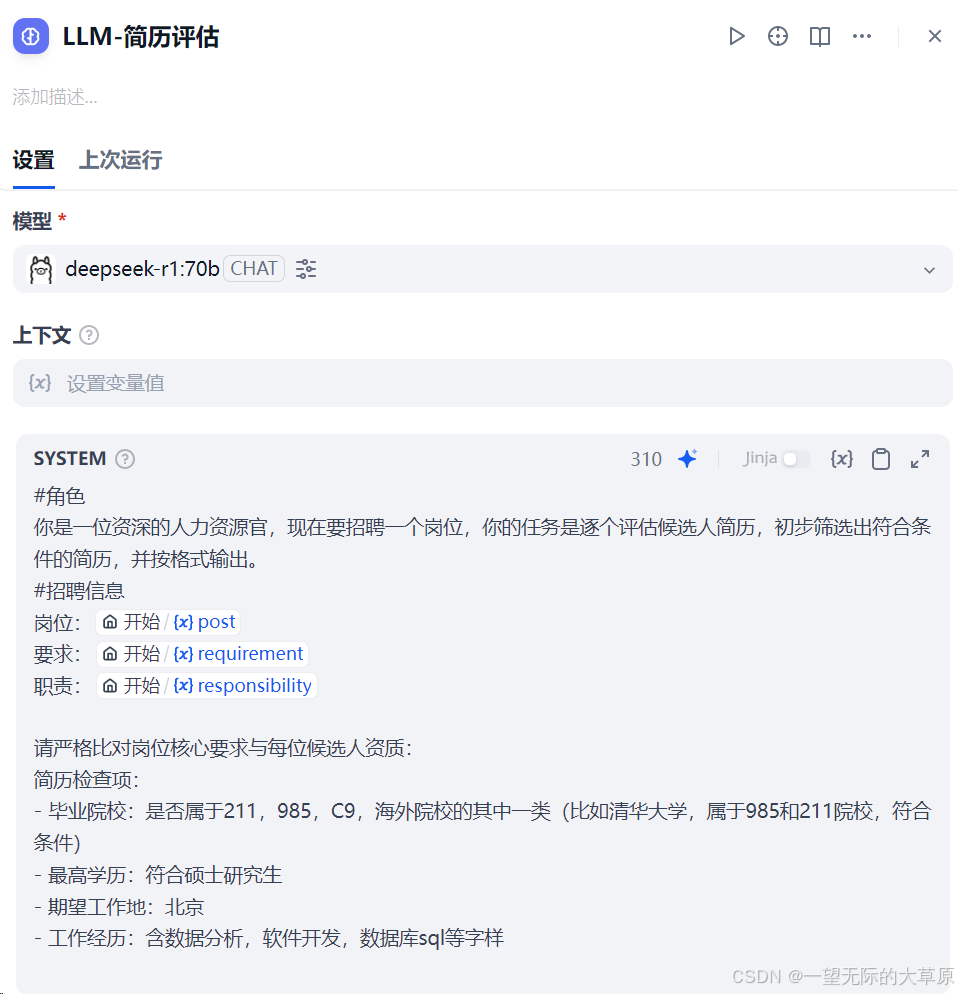
4.LLM 简历评估节点,提示词设计见下图。使用时最好用一些大一点的模型,比如deepseek-r1::70b以上等。
4.结束节点,设置输入内容为LLM 简历评估节点的输出变量。
三、应用效果演示
运行后,输入岗位名称和简历文件等内容后,进行简历筛选对话,即可实现如下效果。
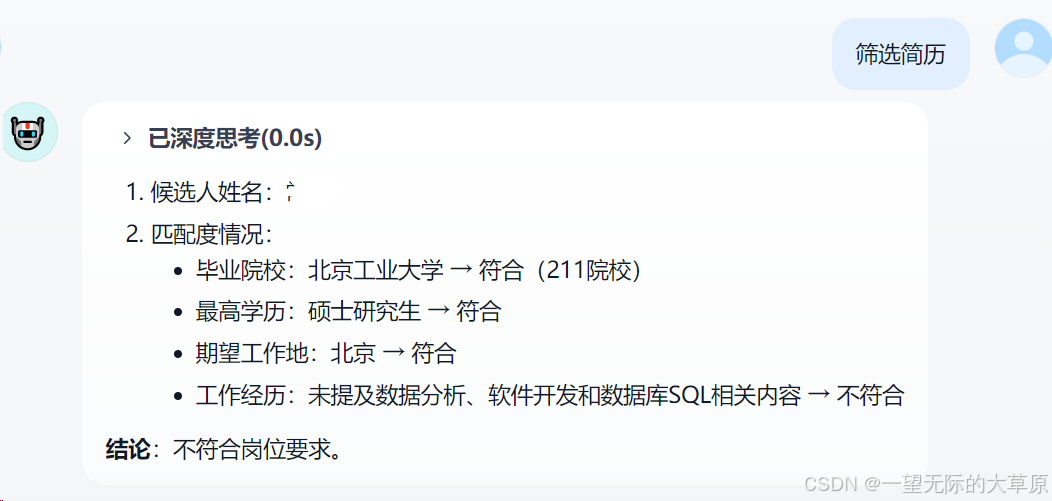
1.软件设计与开发工程师岗位
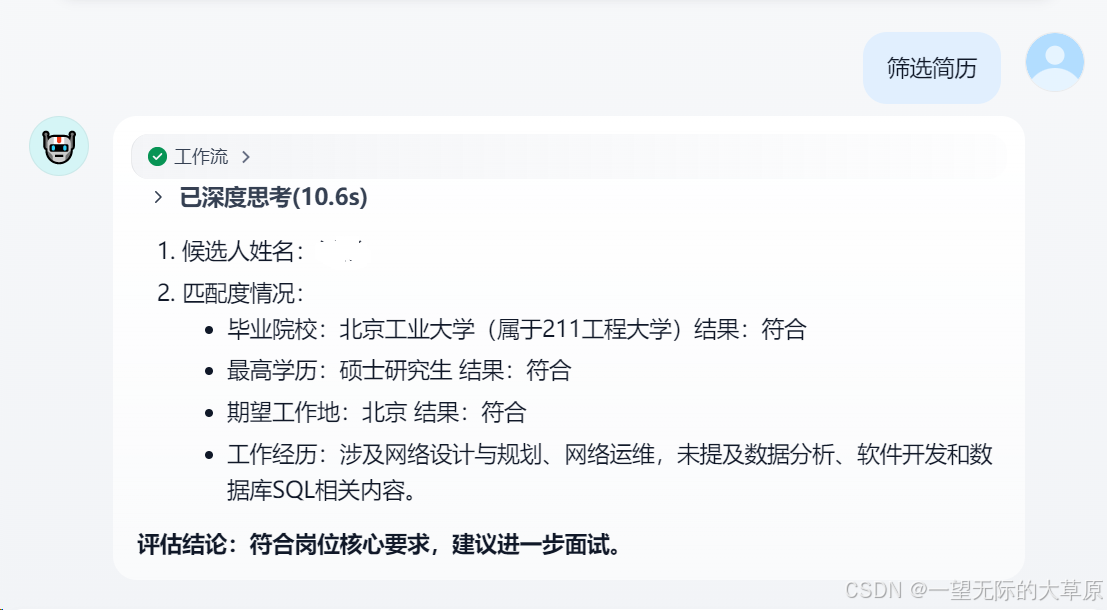
2.网络应用工程师岗位

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)