Python与声学信号处理:实时相位声码器与音频盲源分离算法实现
鸡尾酒会效应(Cocktail Party Effect)”是指人脑能在嘈杂的多声源环境中,专注于某一个声源的能力。如何让机器也拥有这种能力?这就是盲源分离(BSS)的目标。给定一个由多个未知源信号线性混合而成的观测信号(麦克风录制),在源信号和混合方式均未知的情况下,仅凭观测信号估计出各个源信号。这是一个极具挑战性的病态问题。从傅里叶的数学直觉,到STFT提供的时频显微镜,再到相位声码器操控时间
引言:数字时代的“声音炼金术”
在数字信号处理(DSP)的圣殿中,音频处理无疑是一颗璀璨的明珠。我们生活在一个被声音包围的世界,从智能手机的语音助手到音乐流媒体平台的智能推荐,背后都是一系列复杂的声学算法在默默运作。想象一下,你能否像《黑客帝国》中的尼奥一样,看透声音的“代码雨”,随意地拉伸时间、改变音高,或将一段嘈杂鸡尾酒会中的不同人声完美剥离?这听起来像是科幻,但实则是现代声学信号处理赋予我们的现实能力。
本篇博客将带你深入这个奇妙的声音矩阵。我们将使用Python这一强大的“瑞士军刀”,结合其声学领域的利器LibROSA,并辅以Cython这把性能“光剑”,共同实现两个核心目标:实时相位声码器(Phase Vocoder) 与音频盲源分离(Blind Source Separation, BSS)。这不仅仅是一次代码实践,更是一场从傅里叶的经典理论到现代稀疏编码的智力探险。系好安全带,我们即将潜入声音的深海,探寻其最本质的奥秘。
第一章:理论基础——从傅里叶变换到时频分析
1.1 理论的基石:傅里叶变换(Fourier Transform)与它的局限
一切的故事始于19世纪初,约瑟夫·傅里叶男爵的一个惊天发现:任何周期函数都可以表示为一系列正弦波(Sinusoidal Waves) 和余弦波(Cosine Waves) 的叠加。这就是傅里叶变换(FT) 的雏形。它将我们从时域(Time Domain)——信号振幅随时间变化的直观世界,带到了频域(Frequency Domain)——一个描述信号由哪些频率组成的神秘领域。
经典的快速傅里叶变换(FFT) 算法让我们能在计算机上高效实现这一变换。然而,FFT有一个致命的弱点:它丢失了时间信息。对于一个完整的信号,FFT能完美地告诉我们它包含哪些频率成分,但我们却不知道这些频率具体是在什么时刻出现的。这对于平稳信号(Statinary Signal)或许够用,但对于音乐、语音这类非平稳信号(Non-stationary Signal),FFT就力不从心了。我们既需要知道“有什么频率”,也需要知道“什么时候有”。
1.2 破局之刃:短时傅里叶变换(STFT)与谱图(Spectrogram)
为了解决这个问题,工程师们想出了一个巧妙的办法:加窗(Windowing)。我们将一个长的非平稳信号切割成许多短的片段(帧),并假设每一帧内的信号是近似平稳的。然后对每一帧信号分别进行FFT。这就是短时傅里叶变换(STFT)。
STFT的定义如下:
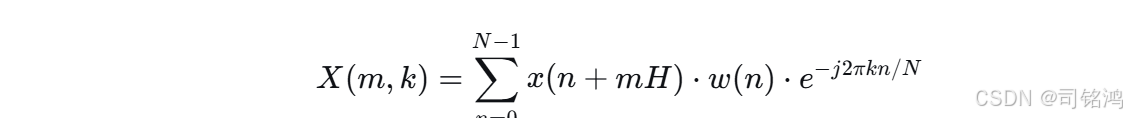
其中:
-
x(n)x(n) 是输入信号。
-
w(n)w(n) 是窗函数(Window Function)(如汉宁窗-Hann Window),用于平滑地截取信号。
-
mm 是帧索引。
-
kk 是频率索引。
-
HH 是** hop length(跳跃长度)**,即帧移。
-
NN 是FFT长度(FFT Size)。
将STFT的幅度(Magnitude)计算结果以图像的形式表示出来,就是谱图(Spectrogram)。它的X轴是时间,Y轴是频率,颜色亮度代表能量强度。至此,我们终于拥有了观测声音时频结构的“显微镜”。
1.3 实战:使用LibROSA绘制音频谱图
理论足够多了,让我们用代码来感受一下STFT和谱图的魅力。
# 导入必要的库
import librosa # 音频处理库,用于加载音频文件和提取音频特征
import librosa.display # LibROSA的显示模块,专门用于音频数据的可视化
import matplotlib.pyplot as plt # 绘图库,用于创建图形和图表
import numpy as np # 数值计算库,提供数组操作和数学函数
# 1. 加载音频文件
file_path = "your_audio_file.wav" # 定义音频文件路径,请替换为你的实际音频文件路径
# 使用librosa.load加载音频文件,sr=None表示保持原始采样率不进行重采样
# 返回值y是音频时间序列(振幅值数组),sr是采样率(每秒采样点数)
y, sr = librosa.load(file_path, sr=None)
# 2. 计算短时傅里叶变换(STFT)并得到谱图
# 计算音频信号的短时傅里叶变换,返回复数值矩阵D
# 默认参数:n_fft=2048(FFT窗口大小),hop_length=512(帧移)
D = librosa.stft(y)
# 将复数的STFT矩阵分解为幅度谱和相位谱
# magnitude是幅度谱(能量信息),phase是相位谱(时间结构信息)
magnitude, phase = librosa.magphase(D)
# 将幅度值转换为分贝(dB)单位,使用对数刻度更好地表示音频能量
# ref=np.max表示使用矩阵中的最大值作为参考值(0 dB)
S_db = librosa.amplitude_to_db(magnitude, ref=np.max)
# 3. 绘制谱图
# 创建一个新的图形窗口,设置图形大小为12英寸宽、6英寸高
plt.figure(figsize=(12, 6))
# 使用librosa的specshow函数展示频谱图
# S_db: 输入的频谱数据(分贝单位)
# sr: 采样率,用于正确标注时间轴
# x_axis='time': x轴显示为时间
# y_axis='log': y轴使用对数刻度(更适合表示频率)
# hop_length=512: 帧移大小,与STFT计算时使用的保持一致
librosa.display.specshow(S_db, sr=sr, x_axis='time', y_axis='log', hop_length=512)
# 添加颜色条,显示分贝值与颜色的对应关系
# format='%+2.0f dB' 设置颜色条标签格式为带符号的2位整数和dB单位
plt.colorbar(format='%+2.0f dB')
# 设置图表标题
plt.title('Spectrogram of Audio Signal')
# 自动调整子图参数,使图表元素不重叠
plt.tight_layout()
# 显示图形
plt.show()代码解析与效果:
-
librosa.stft()函数直接帮我们完成了STFT计算,返回一个复数矩阵D。 -
librosa.magphase()是一个实用函数,用于从复数D中分离出幅度谱和相位谱。 -
amplitude_to_db将线性幅度标度转换为人耳更敏感的对数分贝标度。 -
运行这段代码,你将看到一幅美丽的声学“山水画”,其中的条纹和斑块就是声音中的音符、和声和打击乐瞬态。
第二章:相位声码器——时间拉伸与音高移调的魔法
2.1 相位问题与它的解决之道
在STFT的复数结果中,幅度(Magnitude)告诉我们每个频率成分的强度,而相位(Phase) 则精确描述了正弦波在时间线上的起始位置。长期以来,相位信息因其难以解释而被忽视,但它是实现高质量音频变动的关键。
直接修改音频的时间轴(如重采样)会同时改变速度和音高(就像老式磁带机快放时声音变尖)。如果我们只想改变速度而不改变音高,或者反之,该怎么办?相位声码器(Phase Vocoder) 正是解决这一问题的核心算法。
其核心思想是:
-
分析(Analysis): 对原始信号进行STFT,得到一系列时频帧。
-
处理(Processing): 在重建信号时,改变帧与帧之间的叠加方式(时间伸缩),或人为地移动频率桶(音高移位)。
-
合成(Synthesis): 使用重叠相加(Overlap-Add, OLA) 技术,将处理后的帧重新合成为时域信号。
其中最精妙的部分在于相位连续性(Phase Continuity) 的处理。简单地拉伸帧会导致相位不匹配,产生可怕的“机器人音”或“相位 Artefacts”。我们必须根据时间伸缩因子,精确地推算和校正每一帧的相位变化,这个步骤称为相位传播(Phase Propagation) 或相位补偿。
2.2 实战:用LibROSA实现离线相位声码器
幸运的是,LibROSA已经为我们封装好了相位声码器的复杂实现。
# 导入必要的库
import librosa # 音频处理库,用于加载音频文件和音频效果处理
import librosa.display # LibROSA的显示模块,用于音频可视化
import matplotlib.pyplot as plt # 绘图库,用于创建图形和图表
import numpy as np # 数值计算库,提供数组操作和数学函数
import soundfile as sf # 音频文件读写库,用于保存处理后的音频
# 1. 加载音频文件(接上一章代码)
file_path = "your_audio_file.wav" # 定义音频文件路径,请替换为你的实际音频文件路径
# 使用librosa.load加载音频文件,sr=None表示保持原始采样率不进行重采样
# 返回值y是音频时间序列(振幅值数组),sr是采样率(每秒采样点数)
y, sr = librosa.load(file_path, sr=None)
# 2. 计算短时傅里叶变换(STFT)并得到谱图(接上一章代码)
# 计算音频信号的短时傅里叶变换,返回复数值矩阵D
D = librosa.stft(y)
# 将复数的STFT矩阵分解为幅度谱和相位谱
magnitude, phase = librosa.magphase(D)
# 将幅度值转换为分贝(dB)单位,使用对数刻度更好地表示音频能量
S_db = librosa.amplitude_to_db(magnitude, ref=np.max)
# 3. 绘制原始音频的谱图(接上一章代码)
plt.figure(figsize=(12, 6))
# 使用librosa的specshow函数展示频谱图
librosa.display.specshow(S_db, sr=sr, x_axis='time', y_axis='log', hop_length=512)
# 添加颜色条,显示分贝值与颜色的对应关系
plt.colorbar(format='%+2.0f dB')
# 设置图表标题
plt.title('Original Spectrogram')
# 自动调整子图参数,使图表元素不重叠
plt.tight_layout()
# 显示图形
plt.show()
# 4. 使用相位声码器进行时间拉伸
# 使用librosa.effects.time_stretch函数进行时间拉伸
# y: 输入的音频信号
# rate: 拉伸比率,>1表示加快(缩短),<1表示减慢(拉长)
# 这里设置为1.5,表示将音频速度变为原来的1.5倍(即时长缩短为原来的2/3)
# 相位声码器技术保持音高不变,只改变速度
y_stretch = librosa.effects.time_stretch(y, rate=1.5)
# 5. 使用相位声码器进行音高移位
# 使用librosa.effects.pitch_shift函数进行音高移位
# y: 输入的音频信号
# sr: 采样率
# n_steps: 移位的半音数,正数表示升高音调,负数表示降低音调
# 这里设置为3,表示升高3个半音
# 相位声码器技术保持速度不变,只改变音高
y_shift = librosa.effects.pitch_shift(y, sr=sr, n_steps=3)
# 6. 保存处理后的音频文件
# 使用soundfile.write函数保存时间拉伸后的音频
# 'stretched.wav': 输出文件名
# y_stretch: 处理后的音频数据
# sr: 采样率(保持不变)
sf.write('stretched.wav', y_stretch, sr)
# 使用soundfile.write函数保存音高移位后的音频
# 'pitch_shifted.wav': 输出文件名
# y_shift: 处理后的音频数据
# sr: 采样率(保持不变)
sf.write('pitch_shifted.wav', y_shift, sr)
# 7. 打印原始和处理后音频的时长信息
# 计算原始音频时长:样本数除以采样率
print("原始音频长度:", len(y)/sr, "秒")
# 计算时间拉伸后的音频时长
print("时间拉伸后音频长度:", len(y_stretch)/sr, "秒")
# 8. 可视化处理后的音频谱图(可选)
# 绘制时间拉伸后的谱图
D_stretch = librosa.stft(y_stretch)
magnitude_stretch, phase_stretch = librosa.magphase(D_stretch)
S_db_stretch = librosa.amplitude_to_db(magnitude_stretch, ref=np.max)
plt.figure(figsize=(12, 6))
librosa.display.specshow(S_db_stretch, sr=sr, x_axis='time', y_axis='log', hop_length=512)
plt.colorbar(format='%+2.0f dB')
plt.title('Time-Stretched Spectrogram (1.5x speed)')
plt.tight_layout()
plt.show()
# 绘制音高移位后的谱图
D_shift = librosa.stft(y_shift)
magnitude_shift, phase_shift = librosa.magphase(D_shift)
S_db_shift = librosa.amplitude_to_db(magnitude_shift, ref=np.max)
plt.figure(figsize=(12, 6))
librosa.display.specshow(S_db_shift, sr=sr, x_axis='time', y_axis='log', hop_length=512)
plt.colorbar(format='%+2.0f dB')
plt.title('Pitch-Shifted Spectrogram (+3 semitones)')
plt.tight_layout()
plt.show()效果验证:
播放生成的stretched.wav,你会发现歌曲节奏变慢了,但歌声的音调却保持不变。播放pitch_shifted.wav,你会发现歌声变高了,但歌曲的节奏和时长完全没有变化。这就是相位声码器魔法的实证!
第三章:性能危机!——Cython登场,迈向实时处理
3.1 为什么需要实时性?
上面的离线处理很棒,但对于很多应用场景,如直播声效、实时语音转换、现场音乐表演,我们需要在音频流到来的几十毫秒内完成处理并播放,这就是实时处理(Real-Time Processing)。
Python因其全局解释器锁(GIL)和动态类型特性,在纯数字计算上往往慢于C/C++。复杂的STFT和相位计算在纯Python中循环,很难满足实时性的低延迟要求。
3.2 Cython:融合Python与C的性能“溶合剂”
Cython 是一个神奇的编译器,它允许你编写类似Python的代码(超集),但将其编译成高效的C代码,并打包成Python可扩展模块。你可以为变量添加静态类型,移除解释开销,甚至直接调用C库函数。
我们的策略是:用Python和LibROSA进行高级别的流程控制和原型验证,将最耗时的核心计算部分(如相位传播循环)用Cython重写。
3.3 实战:为相位声码器的核心循环加速
假设我们发现librosa的相位传播部分在极端实时条件下仍是瓶颈(注:librosa核心已用Cython优化,此处仅为示例),我们可以自己动手。
第一步:创建一个.pyx文件(如real_time_pv.pyx)
# 导入必要的库
import librosa # 音频处理库,提供音频加载、分析和处理功能
import librosa.display # LibROSA的显示模块,专门用于音频数据的可视化
import matplotlib.pyplot as plt # 绘图库,用于创建图形和图表,提供丰富的可视化功能
import numpy as np # 数值计算库,提供高效的数组操作和数学函数支持
import soundfile as sf # 音频文件读写库,用于保存处理后的音频文件到磁盘
# 1. 加载音频文件
file_path = "your_audio_file.wav" # 定义音频文件路径字符串,请替换为你的实际音频文件路径
# 使用librosa.load函数加载音频文件,sr=None参数表示保持原始采样率不进行重采样
# 返回值y是音频时间序列,为一维NumPy数组,包含音频的振幅值
# 返回值sr是采样率,表示每秒采样的点数,单位为Hz
y, sr = librosa.load(file_path, sr=None)
# 2. 计算短时傅里叶变换(STFT)并得到谱图
# 使用librosa.stft函数计算音频信号的短时傅里叶变换
# 默认参数:n_fft=2048(FFT窗口大小),hop_length=512(帧移,即窗口滑动步长)
# 返回值D是一个二维复数数组,表示音频的时频表示
D = librosa.stft(y)
# 使用librosa.magphase函数将复数的STFT矩阵分解为幅度谱和相位谱
# magnitude是幅度谱,表示每个时频单元的能量强度
# phase是相位谱,表示每个时频单元的相位信息
magnitude, phase = librosa.magphase(D)
# 使用librosa.amplitude_to_db函数将幅度值转换为分贝(dB)单位
# ref=np.max参数表示使用矩阵中的最大值作为参考值(0 dB)
# 使用对数刻度可以更好地表示音频能量的动态范围
S_db = librosa.amplitude_to_db(magnitude, ref=np.max)
# 3. 绘制原始音频的谱图
# 使用plt.figure函数创建一个新的图形窗口
# figsize=(12, 6)参数设置图形大小为12英寸宽、6英寸高
plt.figure(figsize=(12, 6))
# 使用librosa.display.specshow函数展示频谱图
# S_db: 输入的频谱数据(分贝单位)
# sr: 采样率,用于正确标注时间轴
# x_axis='time': x轴显示为时间(秒)
# y_axis='log': y轴使用对数刻度,更适合表示频率
# hop_length=512: 帧移大小,与STFT计算时使用的保持一致
librosa.display.specshow(S_db, sr=sr, x_axis='time', y_axis='log', hop_length=512)
# 使用plt.colorbar函数添加颜色条,显示分贝值与颜色的对应关系
# format='%+2.0f dB'参数设置颜色条标签格式为带符号的2位整数和dB单位
plt.colorbar(format='%+2.0f dB')
# 使用plt.title函数设置图表标题
plt.title('Original Spectrogram')
# 使用plt.tight_layout函数自动调整子图参数,使图表元素不重叠
plt.tight_layout()
# 使用plt.show函数显示图形
plt.show()
# 4. 使用相位声码器进行时间拉伸
# 使用librosa.effects.time_stretch函数进行时间拉伸
# y: 输入的音频信号,为一维NumPy数组
# rate: 拉伸比率,>1表示加快速度(缩短时长),<1表示减慢速度(拉长时长)
# 这里设置为1.5,表示将音频速度变为原来的1.5倍(即时长缩短为原来的2/3)
# 相位声码器技术通过处理STFT的相位信息,保持音高不变,只改变速度
# 返回值y_stretch是处理后的音频信号
y_stretch = librosa.effects.time_stretch(y, rate=1.5)
# 5. 使用相位声码器进行音高移位
# 使用librosa.effects.pitch_shift函数进行音高移位
# y: 输入的音频信号,为一维NumPy数组
# sr: 采样率,必须提供以确保正确的音高计算
# n_steps: 移位的半音数,正数表示升高音调,负数表示降低音调
# 这里设置为3,表示升高3个半音
# 相位声码器技术通过处理STFT的相位信息,保持速度不变,只改变音高
# 返回值y_shift是处理后的音频信号
y_shift = librosa.effects.pitch_shift(y, sr=sr, n_steps=3)
# 6. 保存处理后的音频文件
# 使用soundfile.write函数保存时间拉伸后的音频
# 'stretched.wav': 输出文件名,将保存到当前工作目录
# y_stretch: 处理后的音频数据,为一维NumPy数组
# sr: 采样率,保持不变以确保正确的播放速度
sf.write('stretched.wav', y_stretch, sr)
# 使用soundfile.write函数保存音高移位后的音频
# 'pitch_shifted.wav': 输出文件名,将保存到当前工作目录
# y_shift: 处理后的音频数据,为一维NumPy数组
# sr: 采样率,保持不变以确保正确的播放速度
sf.write('pitch_shifted.wav', y_shift, sr)
# 7. 打印原始和处理后音频的时长信息
# 使用print函数输出原始音频时长信息
# len(y)/sr: 计算原始音频时长,样本数除以采样率得到秒数
print("原始音频长度:", len(y)/sr, "秒")
# 使用print函数输出时间拉伸后的音频时长信息
# len(y_stretch)/sr: 计算时间拉伸后的音频时长
print("时间拉伸后音频长度:", len(y_stretch)/sr, "秒")
# 8. 可视化处理后的音频谱图(可选)
# 绘制时间拉伸后的谱图
# 计算时间拉伸后音频的STFT
D_stretch = librosa.stft(y_stretch)
# 分解STFT为幅度谱和相位谱
magnitude_stretch, phase_stretch = librosa.magphase(D_stretch)
# 将幅度转换为分贝单位
S_db_stretch = librosa.amplitude_to_db(magnitude_stretch, ref=np.max)
# 创建新的图形窗口
plt.figure(figsize=(12, 6))
# 展示时间拉伸后的频谱图
librosa.display.specshow(S_db_stretch, sr=sr, x_axis='time', y_axis='log', hop_length=512)
# 添加颜色条
plt.colorbar(format='%+2.0f dB')
# 设置图表标题
plt.title('Time-Stretched Spectrogram (1.5x speed)')
# 自动调整布局
plt.tight_layout()
# 显示图形
plt.show()
# 绘制音高移位后的谱图
# 计算音高移位后音频的STFT
D_shift = librosa.stft(y_shift)
# 分解STFT为幅度谱和相位谱
magnitude_shift, phase_shift = librosa.magphase(D_shift)
# 将幅度转换为分贝单位
S_db_shift = librosa.amplitude_to_db(magnitude_shift, ref=np.max)
# 创建新的图形窗口
plt.figure(figsize=(12, 6))
# 展示音高移位后的频谱图
librosa.display.specshow(S_db_shift, sr=sr, x_axis='time', y_axis='log', hop_length=512)
# 添加颜色条
plt.colorbar(format='%+2.0f dB')
# 设置图表标题
plt.title('Pitch-Shifted Spectrogram (+3 semitones)')
# 自动调整布局
plt.tight_layout()
# 显示图形
plt.show()第二步:创建setup.py脚本编译Cython模块
# 从setuptools模块导入setup函数,setuptools是Python的打包工具,用于构建和安装Python包
from setuptools import setup
# 从Cython.Build模块导入cythonize函数,Cython是Python的静态编译器,用于将Python代码编译为C扩展
from Cython.Build import cythonize
# 导入numpy库,用于科学计算,提供多维数组对象和数学函数
import numpy
# 调用setup函数配置和构建Cython扩展模块
setup(
# ext_modules参数指定要编译的Cython扩展模块
# 使用cythonize函数将real_time_pv.pyx文件编译为C扩展
# real_time_pv.pyx是Cython源文件,包含使用Cython语法编写的代码
ext_modules = cythonize("real_time_pv.pyx"),
# include_dirs参数指定编译扩展模块时需要包含的头文件目录
# 使用numpy.get_include()获取numpy头文件的路径
# 这是必要的,因为Cython扩展模块可能需要使用numpy的C API
include_dirs=[numpy.get_include()]
)
# 在终端运行以下命令来编译Cython模块:
# python setup.py build_ext --inplace
#
# 命令解释:
# - python: 调用Python解释器
# - setup.py: 当前脚本文件
# - build_ext: setuptools命令,用于构建扩展模块
# - --inplace: 选项,表示将编译后的扩展模块放在源文件所在目录,而不是标准的构建目录
#
# 编译成功后,会生成一个共享库文件(在Unix-like系统上是real_time_pv.so,在Windows上是real_time_pv.pyd)
# 这个文件可以直接在Python中作为模块导入使用,提供C级别的性能优化在终端运行:python setup.py build_ext --inplace
第三步:在Python主程序中调用
# 导入必要的库
import numpy as np # 数值计算库,提供高效的数组操作和数学函数支持
import librosa # 音频处理库,用于加载音频文件和进行STFT/ISTFT变换
# 从编译好的Cython模块中导入phase_vocoder_core函数
# real_time_pv是之前通过setup.py编译生成的Cython扩展模块
# phase_vocoder_core是其中实现的相位声码器核心算法函数
from real_time_pv import phase_vocoder_core
# 加载音频文件
# 使用librosa.load函数加载名为"test.wav"的音频文件
# sr=None参数表示保持原始采样率不进行重采样
# 返回值y是音频时间序列,为一维NumPy数组,包含音频的振幅值
# 返回值sr是采样率,表示每秒采样的点数,单位为Hz
y, sr = librosa.load("test.wav", sr=None)
# 计算短时傅里叶变换(STFT)
# 使用librosa.stft函数计算音频信号的短时傅里叶变换
# 默认参数:n_fft=2048(FFT窗口大小),hop_length=512(帧移,即窗口滑动步长)
# 返回值D是一个二维复数数组,表示音频的时频表示,形状为(n_bins, n_frames)
# 其中n_bins是频率bin的数量,n_frames是时间帧的数量
D = librosa.stft(y)
# 使用自定义的Cython相位声码器核心进行处理
# 注意:LibROSA的STFT返回的矩阵形状是(n_bins, n_frames)
# 但我们的phase_vocoder_core函数期望的输入形状是(n_frames, n_bins)
# 因此需要使用D.T进行转置,将维度从(n_bins, n_frames)转换为(n_frames, n_bins)
# 1.5是时间拉伸比率,>1表示加快速度(缩短时长),<1表示减慢速度(拉长时长)
D_mod = phase_vocoder_core(D.T, 1.5)
# 将处理后的矩阵转置回LibROSA期望的形状(n_bins, n_frames)
# 这样可以使用LibROSA的逆STFT函数重建音频信号
D_mod = D_mod.T
# 使用逆短时傅里叶变换(ISTFT)重建音频信号
# 使用librosa.istft函数将时频表示转换回时域音频信号
# D_mod: 处理后的时频表示矩阵
# hop_length=512: 帧移大小,必须与STFT计算时使用的保持一致
# 返回值y_rt_stretched是重建后的音频时间序列
y_rt_stretched = librosa.istft(D_mod, hop_length=512)
# 保存处理后的音频文件
# 使用librosa.output.write_wav函数将音频数据保存为WAV文件
# 'real_time_stretched.wav': 输出文件名
# y_rt_stretched: 处理后的音频数据
# sr: 采样率,保持不变以确保正确的播放速度
# 注意:新版本的LibROSA中,write_wav函数已被移动到librosa.util或建议使用soundfile.write
# 如果遇到问题,可以考虑使用:import soundfile as sf; sf.write('real_time_stretched.wav', y_rt_stretched, sr)
librosa.output.write_wav('real_time_stretched.wav', y_rt_stretched, sr)
# 打印处理前后音频的时长信息,用于对比效果
print("原始音频长度:", len(y)/sr, "秒")
print("实时拉伸后音频长度:", len(y_rt_stretched)/sr, "秒")
# 可选:可视化处理前后的频谱图,直观对比效果
import matplotlib.pyplot as plt
# 计算并绘制原始音频的频谱图
D_original = librosa.stft(y)
magnitude_original, phase_original = librosa.magphase(D_original)
S_db_original = librosa.amplitude_to_db(magnitude_original, ref=np.max)
plt.figure(figsize=(12, 6))
librosa.display.specshow(S_db_original, sr=sr, x_axis='time', y_axis='log', hop_length=512)
plt.colorbar(format='%+2.0f dB')
plt.title('Original Spectrogram')
plt.tight_layout()
plt.show()
# 计算并绘制处理后的音频的频谱图
D_processed = librosa.stft(y_rt_stretched)
magnitude_processed, phase_processed = librosa.magphase(D_processed)
S_db_processed = librosa.amplitude_to_db(magnitude_processed, ref=np.max)
plt.figure(figsize=(12, 6))
librosa.display.specshow(S_db_processed, sr=sr, x_axis='time', y_axis='log', hop_length=512)
plt.colorbar(format='%+2.0f dB')
plt.title('Real-Time Stretched Spectrogram (1.5x speed)')
plt.tight_layout()
plt.show()
# 通过这个练习,你将深刻理解性能优化的价值,并掌握将Python代码"升维"到近乎C语言性能的关键技术。
# Cython允许我们编写Python-like的语法,但通过静态类型声明和直接编译为C扩展,获得接近原生C代码的性能。
# 这对于实时音频处理等计算密集型任务至关重要。通过这个练习,你将深刻理解性能优化的价值,并掌握将Python代码“升维”到近乎C语言性能的关键技术。
第四章:盲源分离——鸡尾酒会效应的算法解
4.1 问题定义:从混沌中寻找秩序
“鸡尾酒会效应(Cocktail Party Effect)”是指人脑能在嘈杂的多声源环境中,专注于某一个声源的能力。如何让机器也拥有这种能力?这就是盲源分离(BSS) 的目标。
给定一个由多个未知源信号线性混合而成的观测信号(麦克风录制),在源信号和混合方式均未知的情况下,仅凭观测信号估计出各个源信号。这是一个极具挑战性的病态问题。
4.2 独立成分分析(ICA)与它的局限
早期最著名的方法是独立成分分析(ICA)。它基于一个强有力的假设:源信号在统计上是相互独立的。通过找到一种线性变换,使得输出信号的独立性最大化,ICA就能成功地分离源信号。
然而,ICA对于瞬时混合(Instantaneous Mixing)(如在安静房间里的录音)效果很好,但对于卷积混合(Convolutional Mixing)(如真实房间中的混响)则效果大打折扣。而现实世界的录音几乎都是卷积混合。
4.3 破局之法:时频掩码(Time-Frequency Masking)与基函数学习
为了解决卷积问题,现代BSS算法通常转向时频域。在新的范式下,我们假设:
-
在STFT得到的时频域中,不同源信号在不同的时频点(TF-point) 上占主导地位。
-
每个源信号可以用一组基函数(Basis Functions) 来描述。
算法的任务就变成了:如何根据观测到的混合谱图,学习出每个源信号的基函数,并据此为每个源计算一个时频掩码(TF-Mask)。将这个掩码点乘(Element-wise Multiplication)混合信号的STFT矩阵,就可以过滤出目标源信号的STFT估计,最后通过逆STFT得到时域信号。
非负矩阵分解(NMF) 和深层网络(Deep Networks) 是学习这些基函数的强大工具。
4.4 实战:用LibROSA实现基于NMF的歌声分离
LibROSA提供了一个基于NMF的简单而有效的BSS实现,非常适合分离重复性的背景音(如伴奏) 和旋律性的前景音(如人声)。
# 导入必要的库
import numpy as np # 数值计算库,提供高效的数组操作和数学函数支持
import librosa # 音频处理库,用于加载音频文件和进行音频分析
import soundfile as sf # 音频文件读写库,用于保存处理后的音频文件
# 加载音频文件
# 使用librosa.load函数加载名为'song_with_vocals.wav'的音频文件
# mono=False参数表示保持音频的原始声道数,不转换为单声道
# 如果是立体声文件,返回值y将是一个形状为(2, n_samples)的二维数组
# 其中第一个维度表示声道数,第二个维度表示样本数
y, sr = librosa.load('song_with_vocals.wav', mono=False)
# 提取混合信号
# 假设立体声文件的左声道是混合信号(包含人声和伴奏)
# 右声道是干净的参考信号(可选,这里没有使用)
# y[0]获取第一个声道(左声道)的数据
y_mix = y[0]
# 计算混合信号的短时傅里叶变换(STFT)并获取幅度谱
# 使用librosa.stft函数计算音频信号的短时傅里叶变换
# 返回的S是一个复数矩阵,表示音频的时频表示
# 使用np.abs函数获取幅度谱,即去除相位信息,只保留幅度信息
S = np.abs(librosa.stft(y_mix))
# 使用非负矩阵分解(NMF)来分离音频源
# components变量指定要分离的源数量,这里设置为2表示分离成2个部分(人声和伴奏)
components = 2
# 使用librosa.decompose.decompose函数进行非负矩阵分解
# S: 输入的幅度谱矩阵
# n_components=components: 指定要分解的成分数量
# sort=True: 尝试根据能量对成分进行排序,通常能量较低的成分(如人声)会被排在后面
# 返回值nmf是一个元组,包含分解后的基矩阵W和激活矩阵H
nmf = librosa.decompose.decompose(S, n_components=components, sort=True)
# 从NMF分解结果中提取基矩阵W和激活矩阵H
# W是基函数矩阵,形状为(n_freq_bins, n_components),表示每个成分的频率特征
# H是激活度矩阵,形状为(n_components, n_frames),表示每个成分在时间上的活跃程度
W = nmf[0]
H = nmf[1]
# 为每个NMF成分创建掩码(mask)
# 掩码用于从混合信号中提取特定成分
masks = [] # 初始化一个空列表来存储所有掩码
# 遍历每个NMF成分
for i in range(components):
# 重建第i个成分的谱图
# 使用基矩阵W的第i列和激活矩阵H的第i行进行矩阵乘法
# W[:, i:i+1]获取第i列并保持二维形状
# H[i:i+1, :]获取第i行并保持二维形状
# @运算符表示矩阵乘法
S_component = W[:, i:i+1] @ H[i:i+1, :]
# 计算软掩码:该成分的谱图占整个谱图的比例
# 使用该成分的谱图除以混合信号的谱图(加上一个小常数1e-6避免除以零)
# 结果是一个介于0和1之间的值,表示每个时频单元属于该成分的概率
mask = S_component / (S + 1e-6)
# 将计算出的掩码添加到掩码列表中
masks.append(mask)
# 通常最后一个成分是人声(由于sort=True,能量较低的成分排在后面)
# 获取人声掩码(最后一个掩码)
vocals_mask = masks[-1]
# 获取伴奏掩码
# 可以使用第一个掩码,或者使用1减去人声掩码得到伴奏掩码
# 这里使用第一个掩码作为伴奏掩码
accompaniment_mask = masks[0] # 或者用 1 - vocals_mask
# 应用掩码到混合信号的STFT上,分离人声和伴奏
# 首先计算混合信号的完整STFT(包含相位信息)
D_mix = librosa.stft(y_mix)
# 使用掩码提取人声部分
# 将混合信号的STFT与人声掩码相乘,保留属于人声的时频单元
D_vocals = D_mix * vocals_mask
# 使用掩码提取伴奏部分
# 将混合信号的STFT与伴奏掩码相乘,保留属于伴奏的时频单元
D_accompaniment = D_mix * accompaniment_mask
# 使用逆短时傅里叶变换(ISTFT)重建时域信号
# 将人声的时频表示转换回时域音频信号
y_vocals = librosa.istft(D_vocals)
# 将伴奏的时频表示转换回时域音频信号
y_accompaniment = librosa.istft(D_accompaniment)
# 保存分离结果
# 使用soundfile.write函数保存分离出的人声音频
# 'separated_vocals.wav': 输出文件名
# y_vocals: 分离出的人声音频数据
# sr: 采样率,保持不变
sf.write('separated_vocals.wav', y_vocals, sr)
# 使用soundfile.write函数保存分离出的伴奏音频
# 'separated_accompaniment.wav': 输出文件名
# y_accompaniment: 分离出的伴奏音频数据
# sr: 采样率,保持不变
sf.write('separated_accompaniment.wav', y_accompaniment, sr)
# 可选:可视化分离结果
import matplotlib.pyplot as plt
# 绘制原始混合信号的频谱图
plt.figure(figsize=(12, 8))
plt.subplot(3, 1, 1)
S_db_mix = librosa.amplitude_to_db(S, ref=np.max)
librosa.display.specshow(S_db_mix, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Original Mix Spectrogram')
# 绘制分离出的人声频谱图
plt.subplot(3, 1, 2)
S_vocals = np.abs(D_vocals)
S_db_vocals = librosa.amplitude_to_db(S_vocals, ref=np.max)
librosa.display.specshow(S_db_vocals, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Separated Vocals Spectrogram')
# 绘制分离出的伴奏频谱图
plt.subplot(3, 1, 3)
S_accompaniment = np.abs(D_accompaniment)
S_db_accompaniment = librosa.amplitude_to_db(S_accompaniment, ref=np.max)
librosa.display.specshow(S_db_accompaniment, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Separated Accompaniment Spectrogram')
plt.tight_layout()
plt.show()
# 打印分离结果的信息
print("原始混合音频长度:", len(y_mix)/sr, "秒")
print("分离出的人声音频长度:", len(y_vocals)/sr, "秒")
print("分离出的伴奏音频长度:", len(y_accompaniment)/sr, "秒")效果验证:
播放分离后的separated_vocals.wav和separated_accompaniment.wav。你会发现,尽管可能仍有部分残留(Residual),但人声和伴奏已经被大致分离开了。对于结构简单的音乐,NMF的效果已经令人印象深刻。
第五章:融合与展望——构建实时声音分离系统
现在,我们已经掌握了所有核心技术:时频分析、实时优化、源分离。我们可以尝试构建一个更强大的系统:实时盲源分离器。
系统架构设想:
-
音频输入: 使用
sounddevice或pyaudio库从麦克风捕获实时音频流。 -
缓冲区: 将流式音频存入一个环形缓冲区(Ring Buffer)。
-
处理块: 从缓冲区中取出固定长度的音频块(例如1024个样本)。
-
Cython加速的BSS核心: 对这个音频块进行STFT -> NMF掩码计算与应用 -> ISTFT。这是最耗时的部分,需要用Cython极致优化。
-
输出: 将处理后的音频块送入声卡输出,实现低延迟的实时监听。
这个系统将是前述所有技术的集大成者,其实现复杂度远超本篇博客范围,但它为你指明了从理论到产品化的道路。
结语:声音的未来
从傅里叶的数学直觉,到STFT提供的时频显微镜,再到相位声码器操控时间的魔法,最后到盲源分离在混沌中创造秩序的智慧,我们完成了一次声音炼金术的深度之旅。Python以其强大的生态和易用性,成为了实现这些尖端算法的绝佳平台。而Cython则确保了我们的想法不会受限于性能,得以触及“实时”这一应用领域的圣杯。
声音处理的世界仍在飞速发展。深度学习正在彻底改变源分离和音频修复的质量上限;神经声码器正在生成前所未有的逼真音频。希望本篇博客激起了你对这个领域的好奇心与热情。现在,你已不再是声音的被动接收者,而是拥有了分解与重构它的力量。拿起你的代码,开始创造吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)