论文精读·大模型评审(LLM-as-a-Judge)
摘要:大模型评审(LLM-as-a-Judge)是一种利用大语言模型进行自动化评分和评价的技术。其核心流程包括输入设计、模型选择和后处理,通过优化提示、微调模型和标准化输出来提升性能。评估指标关注模型输出与人类标注的一致性,包括分类准确率、偏差检测和对抗鲁棒性。研究还提出了元评估框架,分析不同优化策略对模型能力的有效性。该技术可应用于文本生成、问答系统等多个领域,但需解决输出格式混乱和潜在偏见等问
大模型评审 LLM-as-a-Judge
大模型评审简单理解就是让大模型模仿人类对一些东西进行打分和评价。
如何评价大模型评审,主要看其回答是否与人类的回答对齐/一致。
形式定义

基本流程
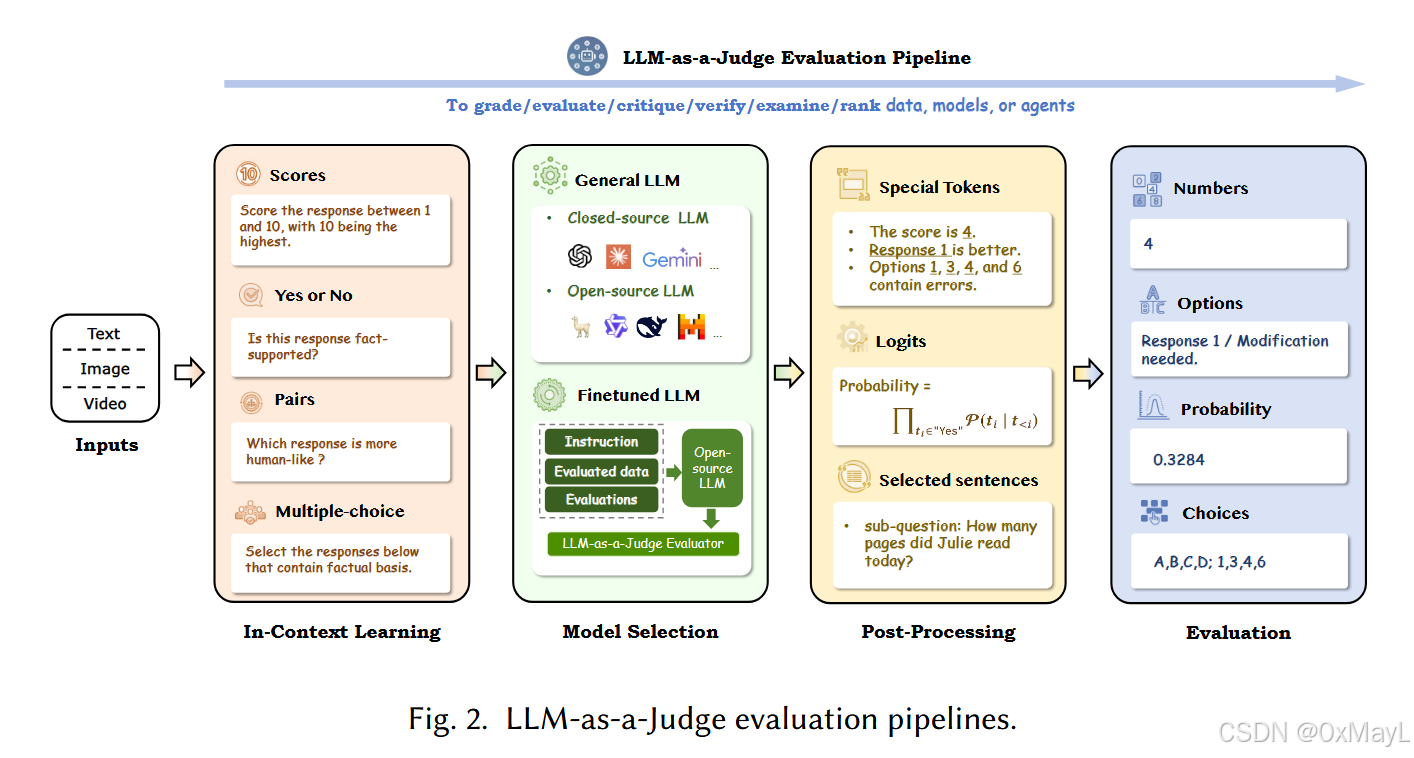
in-context learning
- 核心过程就是输入设计和prompt设计。
- 个人理解:定义问题,通过合适的prompt让LLM理解和学习问题案例。

model selection
- 简单理解为:选择闭源但是强大的模型,或者选择开源的模型进行微调。

post-processing
-
动机:大模型的输出存在随机化,格式也很混乱,需要提取特定token或者得到标准化的输出。
-
Extracting specific tokens.
-
Constrained decoding:这是强制要求LLM输出指定格式,例如JSON格式。
-
Normalizing the output logits:没看懂,未完待续

-
Selecting sentences
evaulation pipeline
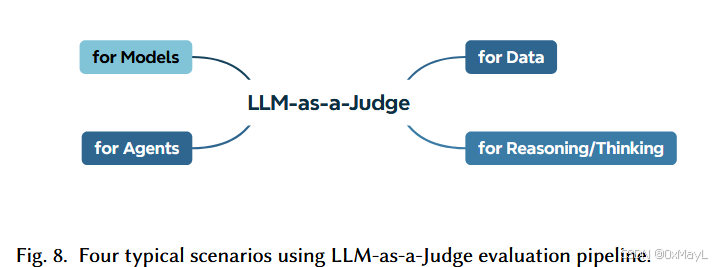
Models
Data
-
这个第一次看还以为是给数据打标签呢,不是这样的!是对于特定数据(可能是LLM生成的内容)进行评估,举三个例子即可完全理解:
-
场景 1(成对偏好) → 对应 RLHF 偏好评估。
-
场景 2(文字评语) → 对应 数据标注/批注生成。
-
场景 3(数值打分) → 对应 单一回答打分/排序。
-
用LLM评估以下东西。
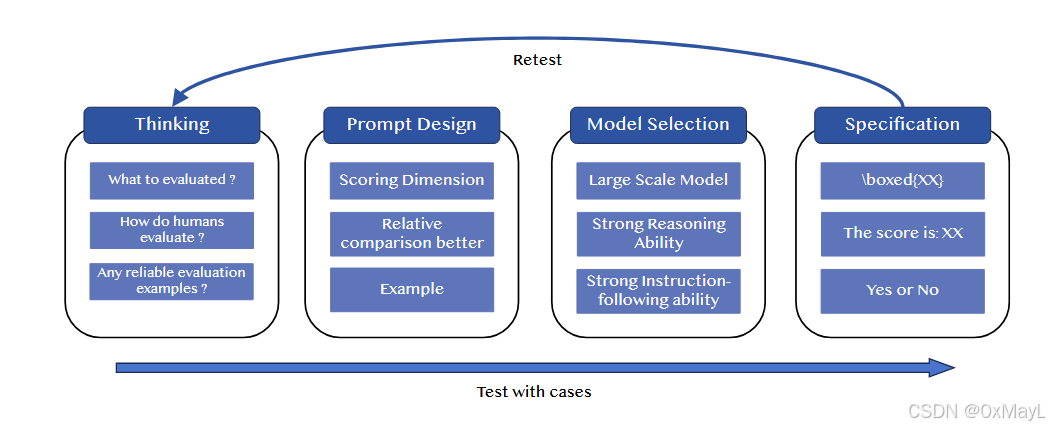
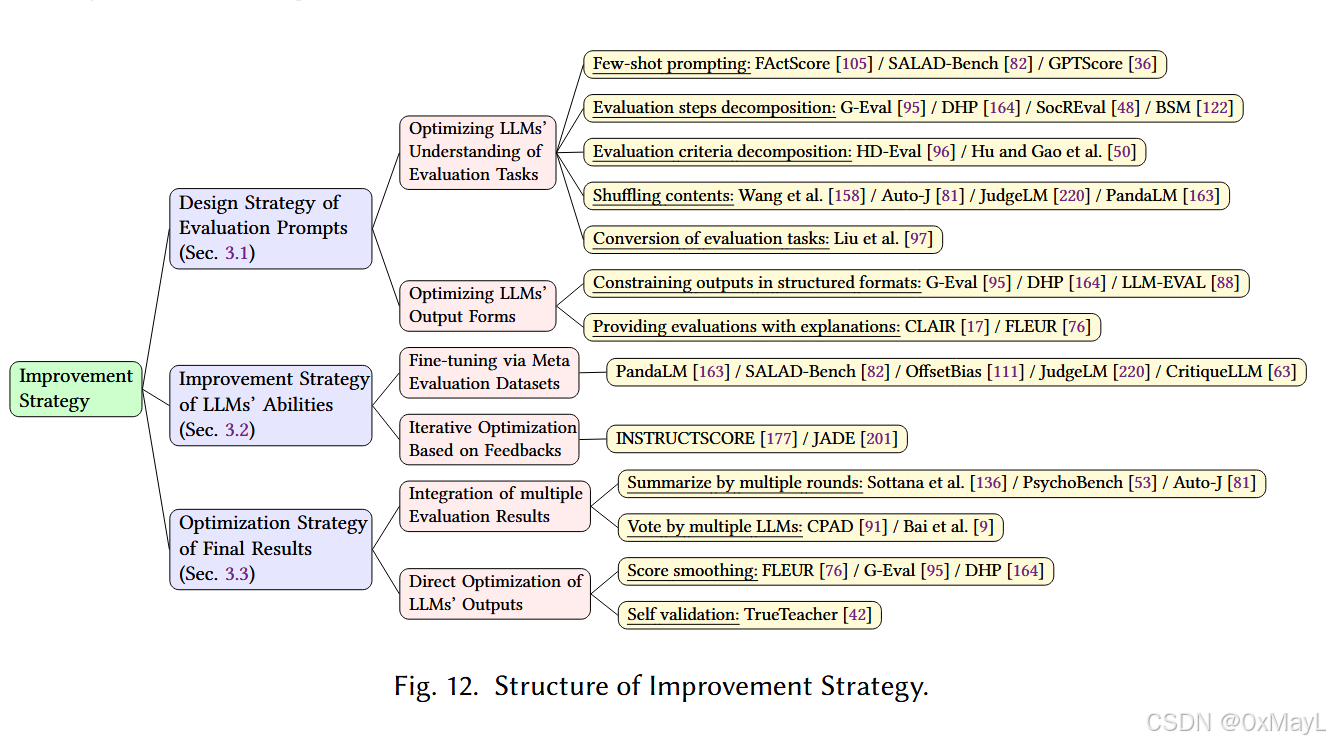
提升策略
- 优化提示,对应in-context learning:旨在帮助LLM理解问题本身。将任务进行分解为多个子任务和子流程,将评价指标解耦为多个子指标。或者直接提供部分案例供LLM学习。
- 微调模型,对应model selection:提高LLM本身的能力,减小歧视(bias)。使用元数据微调,使用表现不好的案例微调。
- 优化结果,对应post-processing:旨在优化LLM的输出,包括使用多个LLM,多轮输出综合和其他策略。
评估LLM-as-a-Judge的指标
-
核心思想:让LLM的输出结果与人类提供的输出结果(人为注释)尽可能一致。
-
**分类指标:**准确率,召回率那些。
-
Agreement(本质也是一种准确率指标)
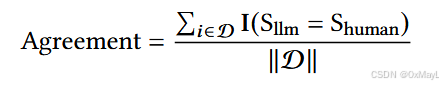
-
Bias(歧视、偏差):各种各样的歧视,所用的指标各不相同。
-
模型的对抗鲁棒性。
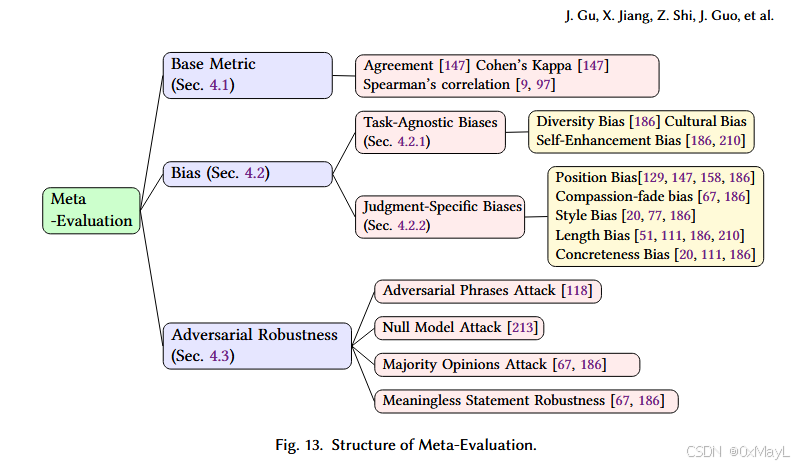
meta-evaluation experiment
- 动机:作者提出了一个元评估框架,旨在评估以上提升策略对LLM哪些能力有效,对于哪些歧视现象无效?

实验部分未完待续。
参考文献
@misc{guSurveyLLMasaJudge2025,
title = {A {{Survey}} on {{LLM-as-a-Judge}}},
author = {Gu, Jiawei and Jiang, Xuhui and Shi, Zhichao and Tan, Hexiang and Zhai, Xuehao and Xu, Chengjin and Li, Wei and Shen, Yinghan and Ma, Shengjie and Liu, Honghao and Wang, Saizhuo and Zhang, Kun and Wang, Yuanzhuo and Gao, Wen and Ni, Lionel and Guo, Jian},
year = {2025},
number = {arXiv:2411.15594},
eprint = {2411.15594},
primaryclass = {cs},
publisher = {arXiv},
doi = {10.48550/arXiv.2411.15594},
archiveprefix = {arXiv}
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)