通过AI工具快速撰写专业报告与提升文档质量的终极指南
AI技术正在重塑专业报告的撰写范式,从线性流程转变为"人机协同、迭代增强"模式。本指南系统介绍了AI报告撰写的全流程解决方案:1. 工具选择:涵盖语言模型、研究辅助、写作优化和可视化四大类工具;2. Prompt工程:提供CRISPE框架及各阶段优质Prompt示例;3. 实战案例:展示Python调用API实现市场分析报告半自动化生成;4. 可视化应用:教学Mermaid流程
前言
在当今快节奏的商业和学术环境中,撰写高质量的专业报告是一项核心技能,但也是一项极其耗时耗力的工作。从数据收集、分析、架构设计到文字润色,每一个环节都对报告最终的质量起着决定性作用。近年来,人工智能(AI)技术的飞速发展,特别是大型语言模型(LLM)的成熟,为报告撰写工作流带来了革命性的变化。AI不再是一个遥远的概念,而是成为了每一位知识工作者触手可及的生产力倍增器。
本报告将深入探讨如何利用各类AI工具,系统化地提升专业报告的撰写效率与成品质量。我们将超越简单的工具介绍,提供一个从理念到实践的全方位指南,内容包括核心工作流设计、Prompt工程精髓、代码级自动化集成、可视化呈现以及伦理风险规避。无论您是分析师、研究员、项目经理还是学生,本指南都将为您提供一套可立即上手的现代化解决方案。
第一章:AI报告撰写的新范式——从线性到迭代增强
传统的报告撰写是一个典型的线性流程:确定主题 -> 搜集资料 -> 撰写初稿 -> 修改校对 -> 定稿发布。这个过程往往存在大量重复劳动,且严重依赖撰写者的个人经验和即时状态。
AI的引入打破了这一线性模式,将其转变为一种“人机协同、迭代增强”的新范式。在这一范式中,人类扮演着“指挥官”和“质检官”的角色,负责提出关键问题、制定战略方向、提供关键输入、进行关键决策并对最终质量负责;而AI则扮演着“副官”、“研究员”、“写手”、“设计师”和“编辑”的角色,负责执行具体任务、拓展思维边界、生成内容草稿和优化细节。
这种协作关系的核心在于将人类的领域知识、批判性思维和全局观与AI的信息处理速度、广博的语言模型和不知疲倦的特性相结合。
为了更直观地展示这一现代化工作流,我们使用Mermaid流程图进行阐述。
flowchart TD
A[人类: 定义报告目标与核心问题] --> B[AI: 生成初步大纲与数据需求]
B --> C[人类: 审核/调整大纲<br>提供核心数据与材料]
C --> D[AI: 数据清洗、分析与可视化]
D --> E[AI: 根据大纲与数据撰写内容草稿]
E --> F{人类: 审阅草稿}
F -- 内容不足/有误 --> G[人类: 提供反馈与指令<br>或补充材料]
G --> E
F -- 结构需优化 --> H[AI: 调整结构与逻辑流畅性]
H --> E
F -- 通过 --> I[AI: 进行语法、风格、润色]
I --> J[AI: 生成摘要、结论与关键点]
J --> K[人类: 最终审核与发布]
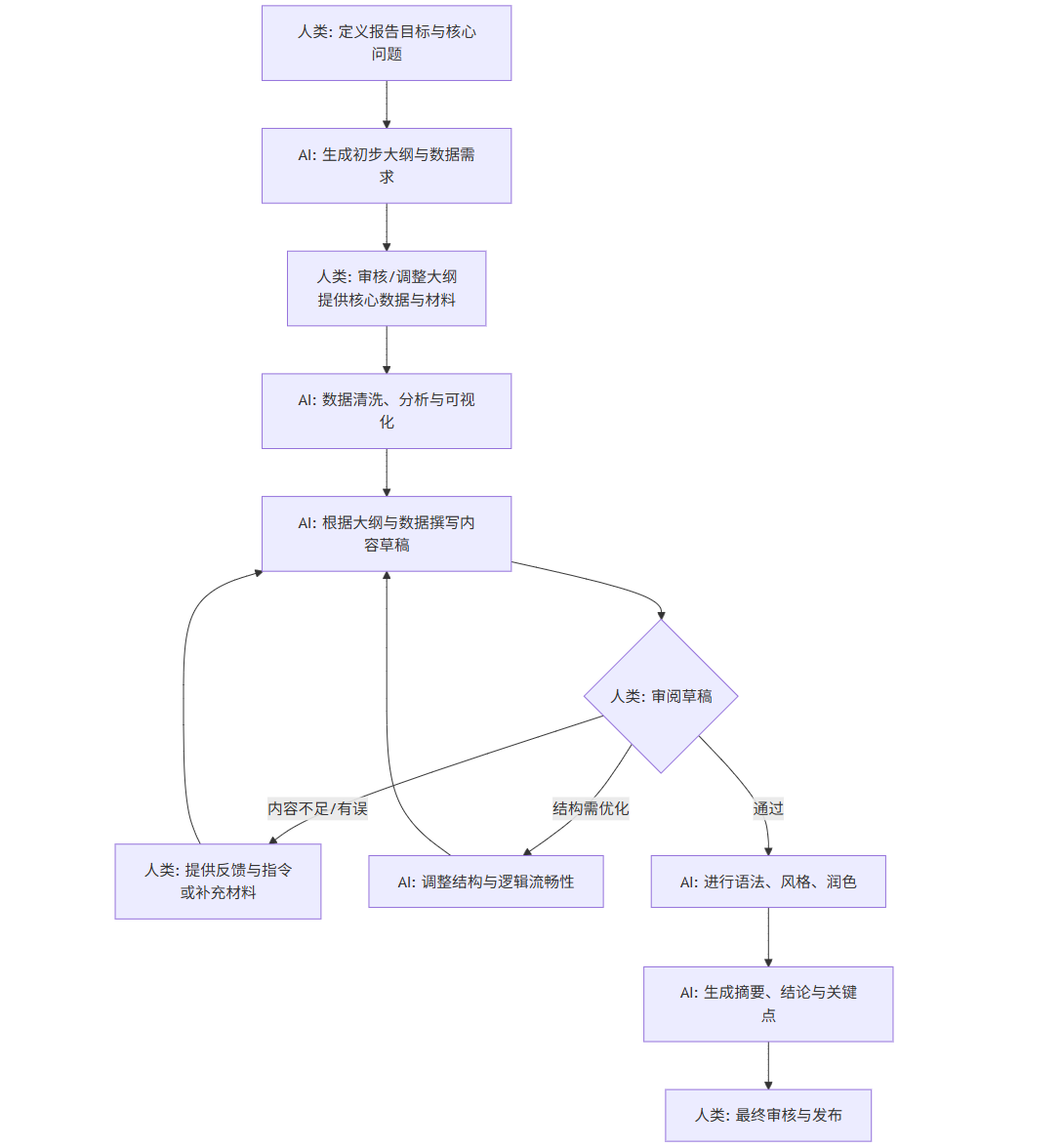
如图所示,流程中的多个环节都构成了“人类审核-AI执行”的闭环,这使得报告质量可以在多次迭代中快速提升,而非在最后阶段才被发现重大问题。
第二章:武器库——核心AI工具分类与选择
工欲善其事,必先利其器。选择合适的AI工具是成功的第一步。以下我们将AI工具分为四类,并推荐代表性产品。
1. 大型语言模型(LLM)平台
这是报告撰写的核心引擎,负责理解指令、生成文本、进行推理和总结。
-
OpenAI ChatGPT (GPT-4): 当前公认能力最强的通用语言模型,在逻辑推理、创意写作和长文本生成方面表现优异。适合作为主要的内容生成和头脑风暴伙伴。
-
Anthropic Claude (Claude 3 Opus/Sonnet): 以其超长上下文窗口(可达20万个token)和“更谨慎、负责任”的输出风格著称。非常适合处理长篇报告、进行深度文献综述和总结冗长文档。
-
Google Gemini (Gemini 1.5): 谷歌旗下的强大模型,在多模态(结合图文)理解方面有独特优势,且与谷歌生态(如Workspace)集成度更高。
-
DeepSeek Chat (DeepSeek-V2/V3): 国内领先的模型,性能强大,对中文语境的理解和处理尤其出色,是处理中文报告的优秀选择。
-
开源模型(Llama 3, Mistral, DeepSeek-Coder): 可本地部署,数据隐私性高,且可通过微调定制专属模型。例如,
DeepSeek-Coder特别擅长代码生成,对于技术报告至关重要。
2. 研究与数据分析辅助工具
这类工具帮助您快速获取信息和洞察数据。
-
Elicit: AI研究助手,可以帮助您根据提出的问题查找相关的学术论文,并自动总结论文要点。
-
Consensus: 基于AI的搜索引擎,直接从科学研究中提取答案,并提供结论共识度。
-
ChatGPT (Code Interpreter/Advanced Data Analysis): 内置的数据分析功能,允许您上传数据文件(CSV, Excel),然后通过自然语言指令让其进行清洗、分析和可视化。这是革命性的功能,极大降低了数据分析门槛。
-
Bing Chat (Copilot): 集成了GPT-4并具备网络搜索能力,适合快速获取最新的网络信息和数据。
3. 写作与编辑增强工具
这类工具专注于文本的打磨和优化。
-
Grammarly: 超越基础语法检查,提供高级风格建议、语气调整和抄袭检测,确保文本的专业性。
-
Hemingway Editor: 重点帮助您写出清晰、简洁、有力的句子,突出显示冗长、复杂的结构。
-
ProWritingAid: 提供极其详细的写作报告,从过度用词、句式多样性到可读性分数,进行全面剖析。
4. 可视化与设计工具
“一图胜千言”,专业的图表和设计极大提升报告的可读性和专业性。
-
AI图表生成(Mermaid, ChartGPT): 正如本报告所示,使用Mermaid的文本语法可以快速生成精准的流程图、时序图等。ChartGPT等工具可以通过描述生成图表代码。
-
AI设计助手(Canva AI, Microsoft Designer): 只需提供报告主题和内容,这些工具可以自动生成专业的报告模板、封面和内页设计建议,节省大量设计时间。
选择策略:建议以一款主力LLM(如ChatGPT-4或Claude)为核心,再根据特定需求(如数据分析、学术研究、设计)搭配 specialized 工具组合使用。
第三章:灵魂所在——Prompt工程的精髓与示例
Prompt(提示词)是与AI交互的“语言”,其质量直接决定了AI输出的质量。一个好的Prompt应具备清晰、具体、上下文丰富的特点。
Prompt基础结构(CRISPE框架)
一个高效的Prompt可以遵循CRISPE框架:
-
Capacity and Role (角色与能力): 为AI设定一个特定的角色。
-
Request (请求): 清晰说明你要它做什么。
-
Instruction (指令): 说明完成请求需要遵循的步骤。
-
Situation (情境): 提供背景信息。
-
Personality (个性): 定义输出的风格。
-
Experiment (实验): 要求它提供多种方案或迭代。
报告撰写各阶段Prompt示例
阶段一:启动与规划
目标: 生成报告大纲和调研方向。
示例Prompt 1 (基础):
“为一份关于‘量子计算对金融服务业网络安全的影响’的专业报告生成一个详细大纲。”
示例Prompt 2 (高级 - 使用CRISPE框架):
text
角色:你是一位顶尖的战略咨询顾问,擅长撰写为C级别高管阅读的行业深度报告。 请求:为我即将撰写的报告生成一个详细大纲。 指令:报告主题是“量子计算对金融服务业网络安全的影响”。请按照以下步骤操作: 1. 首先,分析该主题下最重要的3个关键问题。 2. 然后,设计一个逻辑严谨的报告结构,至少包含摘要、引言、机遇分析、威胁与挑战分析、案例研究、应对策略建议和结论。 3. 在每个主要章节下,提供3-5个核心子论点。 情境:这份报告的目标读者是银行的CTO和首席信息安全官,他们拥有深厚的技术背景,但需要从商业战略角度理解该问题。 个性:报告风格需专业、前瞻、具有洞察力,避免过于学术化的术语。 实验:请提供两个版本的大纲思路,一个侧重于技术实施,另一个侧重于商业战略。
效果对比: 第一个Prompt会得到一个标准但可能流于表面的大纲。第二个Prompt会得到一个深度、结构化、极具针对性和实用性的成果,直接为后续写作打下坚实基础。
阶段二:研究与数据分析
目标: 理解复杂资料或从数据中提取洞察。
示例Prompt (数据分析):
你上传一个名为financial_metrics_2023.csv的文件。
text
你是一位资深数据分析师。请分析我上传的这份数据集。 1. 首先,描述数据集的结构,包括字段名称、类型和示例数据。 2. 计算“利润率”和“年增长率”的关键描述性统计量(均值、中位数、标准差等)。 3. 找出“销售额”最高的三个区域,并分析其利润率是否与其他区域有显著差异。 4. 创建一个关于各区域销售额与利润率关系的散点图,并用趋势线加以说明。 5. 用一段文字总结从数据中看到的最重要的两个商业洞察。
阶段三:内容撰写
目标: 根据大纲和材料撰写报告初稿。
示例Prompt (撰写章节):
text
你正在撰写一份报告的第4部分“威胁与挑战分析”。这是之前的大纲:[粘贴大纲的第四部分]。这是我们之前总结的关于量子计算破解RSA加密的风险摘要:[粘贴关键摘要]。 请根据以上信息,撰写大约800字的完整章节内容。要求: - 开头有一个引导句,承接上一章。 - 论点清晰,使用“首先、其次、最后”等逻辑连接词。 - 包含一个具体的案例,说明一家金融机构可能面临的风险场景。 - 语言严谨,但要有警示性。 - 在结尾部分,自然过渡到下一章“应对策略”。
阶段四:编辑与优化
目标: 提升文本的清晰度、简洁性和专业性。
示例Prompt (优化文本):
text
你是一位专业的文案编辑。请优化下面这段报告内容,要求: 1. 修正任何语法和标点错误。 2. 将长句拆分为更短、更有力的句子,提升可读性。 3. 将被动语态改为主动语态。 4. 消除冗余的词语(例如,“由于事实是”改为“因为”)。 5. 确保术语使用的一致性。 [将需要优化的文本粘贴于此]
第四章:实战演练——自动化生成一份市场分析报告
让我们通过一个具体的例子,演示如何利用Python代码调用OpenAI API,半自动化地生成一份市场分析报告的核心内容。
** scenario:** 我们需要定期生成某行业(如电动汽车)的月度市场动态报告。数据来源是一些固定的新闻网站和分析师报告摘要(已保存为文本文件)。
步骤一:环境设置与API连接
首先,确保你已安装OpenAI Python库并获取了API密钥。
bash
pip install openai python-dotenv
创建一个.env文件存储你的密钥:
text
OPENAI_API_KEY='your-api-key-here'
步骤二:构建代码框架
以下Python代码演示了如何读取多个数据源文件,并调用GPT模型进行总结、分析和报告撰写。
python
import os
import openai
from dotenv import load_dotenv
import glob
# 加载环境变量
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
# 定义模型
MODEL = "gpt-4"
def read_text_files(directory_path):
"""
读取指定目录下的所有.txt文件内容并合并。
"""
all_text = ""
for file_path in glob.glob(os.path.join(directory_path, "*.txt")):
with open(file_path, 'r', encoding='utf-8') as file:
all_text += f"\n--- Content from {os.path.basename(file_path)} ---\n"
all_text += file.read()
return all_text
def call_ai(prompt, model=MODEL, temperature=0.7):
"""
调用OpenAI API的函数。
"""
try:
response = openai.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
return response.choices[0].message.content
except Exception as e:
return f"An error occurred: {e}"
def generate_monthly_report(data_directory, output_file):
"""
主函数:生成月度报告。
"""
# 1. 读取原始数据
raw_data = read_text_files(data_directory)
print("原始数据加载完成。")
# 2. 指令1:总结核心要点
summary_prompt = f"""
你是一位高效的市场分析师。请仔细阅读以下关于2024年5月电动汽车市场的多份原始文本资料(包括新闻、报告摘要),并完成以下任务:
任务:提取并总结本月度的Top 5核心市场动态。每个动态需包含:
- 事件主题
- 关键事实与数据(如销量、份额、价格)
- 潜在影响分析(1-2句话)
请以列表形式呈现,确保内容精准、简洁。
原始资料:
{raw_data}
"""
print("正在生成核心要点总结...")
summary = call_ai(summary_prompt, temperature=0.3) # 低temperature保证准确性
print("总结完成。")
# 3. 指令2:撰写报告摘要
executive_summary_prompt = f"""
基于以下总结的5月电动汽车市场核心动态,为一份给公司高管阅读的月度报告撰写一段“执行摘要”(约150字)。
要求:高度概括,突出最重要的趋势、变化和挑战,语言精炼,直击要点。
核心动态:
{summary}
"""
print("正在撰写执行摘要...")
executive_summary = call_ai(executive_summary_prompt)
print("执行摘要完成。")
# 4. 指令3:深入分析一个特定主题(例如:价格战)
deep_dive_prompt = f"""
基于之前的动态总结,我发现“价格战”是一个重要主题。请你作为行业分析师,深入分析这个问题。
请撰写一个约400字的章节,标题为“价格战升级:动因与未来格局推演”。
内容需包括:
- 本轮价格战的主要参与者及其策略。
- 背后的深层次原因(成本、竞争、战略等)。
- 对未来3个季度市场竞争格局的潜在影响。
- 对中小厂商的建议。
请确保分析有逻辑、有深度,并引用资料中的具体数据支撑观点。
参考资料:{summary}
"""
print("正在进行深度分析...")
deep_dive_analysis = call_ai(deep_dive_prompt, temperature=0.8) # 稍高的temperature鼓励更多洞察
print("深度分析完成。")
# 5. 将输出保存到文件
with open(output_file, 'w', encoding='utf-8') as f:
f.write("=== 月度电动汽车市场分析报告 (2024年5月) ===\n\n")
f.write("一、执行摘要\n")
f.write(executive_summary)
f.write("\n\n二、本月核心动态总结\n")
f.write(summary)
f.write("\n\n三、专题深度分析:价格战\n")
f.write(deep_dive_analysis)
print(f"报告已成功生成并保存至:{output_file}")
# 指定存放原始数据的目录和输出文件路径
data_dir = "./raw_data_ev_may2024/" # 确保此目录存在并包含.txt文件
output_report = "./ev_market_report_may2024.md"
# 运行报告生成器
generate_monthly_report(data_dir, output_report)
步骤三:运行与迭代
-
将收集好的新闻、报告摘要文本文件放入
./raw_data_ev_may2024/目录。 -
运行上述Python脚本。
-
查看生成的Markdown报告文件
ev_market_report_may2024.md。 -
至关重要:将AI生成的内容作为初稿,进行人工审核、事实核查、数据验证和深度修改。AI是副官,你才是司令。
这个脚本实现了从数据聚合、总结、摘要撰写到深度分析的半自动化流程,将您从繁琐的信息整理工作中解放出来,让您能专注于更高层次的策略思考和最终的质量把关。
第五章:超越文本——图表、流程图与可视化
专业报告离不开视觉元素。AI在可视化方面同样能提供巨大助力。
1. 使用Mermaid生成流程图
正如本报告开头所示,Mermaid是一种基于文本的图表绘制工具,它可以完美地集成到AI工作流中。你可以直接要求AI为你生成Mermaid代码。
示例Prompt:
text
请用Mermaid语法绘制一个流程图,描述“企业客户投诉处理流程”。流程包括: 1. 客户通过渠道(电话/在线)提交投诉。 2. 系统生成工单并分类(紧急/一般)。 3. 紧急工单直接升级至高级客服团队,一般工单按轮询分配。 4. 客服处理并记录解决方案。 5. 系统自动发送满意度调查。 6. 如果客户不满意,工单重新开启并升级。 7. 工单关闭后归档。 请确保流程图清晰易懂。
AI生成的Mermaid代码可以直接插入支持Mermaid的Mark编辑器(如Typora、Obsidian、VS Code插件)或GitHub Wiki中渲染成图。
2. 利用AI生成图表代码(如Python Matplotlib)
你可以在Python环境中,让AI帮助你生成数据可视化代码。
示例Prompt (在ChatGPT Code Interpreter或代码环境中):
text
我有一个Pandas DataFrame `df`,包含以下列: - `month` (月份: Jan, Feb, ...) - `product_a_sales` (产品A销售额) - `product_b_sales` (产品B销售额) 请生成Python代码,使用Matplotlib绘制一个折线图,比较产品A和产品B在过去12个月中的销售趋势。 要求: - 图表标题为“Product A vs Product B Sales Trend (2023-2024)” - 为两条线设置不同的颜色和图例 - 添加纵轴标签(“Sales (USD)”)和横轴标签(“Month”) - 设置一个简洁美观的样式(如`seaborn-v0_8-whitegrid`)
AI会提供完整的、可立即运行的代码块,你只需替换变量名或稍作调整即可。
第六章:质量守护神——AI在校对、润色与合规性检查中的应用
初稿完成后,AI是提升文档质量的强大工具。
1. 风格与语气调整
你可以要求AI将一段技术性很强的文字,转换为适合不同受众的版本。
示例Prompt:
text
请将下面这段技术描述,分别改写为适合“高中生”、“行业专家”和“投资人”阅读的版本。 原始文本: “该异构计算架构通过集成CUDA核心与Tensor Core,实现了FP32和FP64精度计算任务的并行处理与负载优化,显著提升了HPC和AI训练工作流的吞吐量。”
2. 合规性与偏见检查
AI可以帮助识别文档中可能存在的隐性偏见或不包容性语言。
示例Prompt:
text
请检查以下段落中是否存在性别、种族、年龄或其他方面的隐性偏见或不包容性语言,并提出修改建议。 段落: “我们的销售团队需要更加 aggressive 地去争取客户。每个销售员都应该像他一样,成为一座孤岛,独自攻克难关。”
第七章:规避陷阱——伦理、风险与最佳实践
尽管AI功能强大,但我们必须清醒地认识到其局限性和风险。
1. 主要风险
-
幻觉与事实错误: AI可能会生成看似合理但完全错误的信息、数据或引用不存在的文献。
-
数据隐私与安全: 将敏感的公司数据或个人信息输入到公共AI平台可能导致严重的泄露风险。
-
版权与知识产权: AI生成内容的版权归属目前仍存在法律灰色地带。直接使用AI生成的大量文本可能被视为 plagiarism(剽窃)。
-
过度依赖与技能退化: 过度依赖AI可能导致自身的研究、分析和写作能力退化。
-
偏见放大: AI模型是在现有数据上训练的,可能继承和放大社会中存在的偏见。
2. 最佳实践与应对策略
-
永远扮演“质检官”: 对AI生成的一切内容保持批判性思维。事实核查(Fact-Check) 是必不可少、不可省略的步骤。
-
控制输入,保护输出: 切勿将机密、敏感或个人身份信息(PII)输入到公共AI工具中。考虑使用本地部署的开源模型处理敏感数据。
-
AI作为助手,而非作者: 使用AI进行 brainstorming、搭建结构、优化语言和生成初稿,但最终的见解、观点和结论必须来自你自己。报告应体现你的智力贡献。
-
明确披露: 如果情况要求(如学术、商业合规),应明确披露AI工具在报告撰写中的辅助作用和使用范围。
-
持续学习: 将使用AI的过程视为学习的机会。分析它提供的结构和论点,思考其背后的逻辑,以此来提升自己的思维和写作能力。
结论
人工智能的出现,标志着报告撰写乃至知识工作领域的一个转折点。它并非要取代人类,而是为我们提供了一套前所未有的强大工具集。通过将AI深度集成到“规划-研究-写作-优化-可视化”的全流程中,我们能够极大地提升效率,将宝贵的时间和智力从繁琐的劳动中解放出来,专注于最核心的战略思考、深度分析和价值创造。
成功的关键在于 adopting一个 “人机协同” 的思维模式:人类负责指引方向、提供关键输入、进行批判性判断和承担最终责任;AI负责高效执行、拓展可能性、处理细节和激发灵感。掌握Prompt工程的艺术,选择合适的工具组合,并始终保持对风险的警惕,你将能驾驭这股强大的力量, consistently 撰写出更高质量、更具影响力的专业报告。
未来,随着多模态模型、智能体和自主研究能力的进一步发展,AI在知识工作中的作用只会越来越深。现在就开始探索和实践这一新范式,将使你在未来的竞争中占据绝对的先发优势。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献136条内容
已为社区贡献136条内容

所有评论(0)