NVIDIA Rubin CPX:为百万级Token上下文工作负载加速推理性能与效率
NVIDIA在COMPUTEX 2024推出Rubin平台,其核心创新是专为LLM预填充阶段设计的CPX处理器。该处理器与Rubin GPU协同工作,通过异构计算解决百万级Token上下文带来的计算瓶颈。CPX针对预填充阶段的计算密集型特性进行优化,与GPU分工协作:CPX处理预填充,GPU专注于生成阶段。这种架构使预填充性能提升4倍,整体推理性能提升3倍,同时能效提高1.5倍。平台采用MGX模块
NVIDIA Rubin CPX:为百万级Token上下文工作负载加速推理性能与效率
摘要
在COMPUTEX 2024上,NVIDIA发布了其下一代AI平台——NVIDIA Rubin。该平台不仅包含了全新的GPU、基于Arm架构的CPU(NVIDIA Vera CPU),还引入了一个关键的新成员:NVIDIA CPX。这是一种专为加速大型语言模型(LLM)中计算密集型的“预填充(prefill)”阶段而设计的处理器。本文将深度解析NVIDIA CPX的技术原理、其在系统中的集成方式,以及它如何与Rubin GPU协同工作,为处理百万级Token上下文的超大规模AI模型带来性能与效率的革命。

图1:NVIDIA Rubin平台将下一代Rubin GPU与基于Arm架构的NVIDIA Vera CPU以及先进的网络技术(如NVLink 6、CX9 SuperNIC和X1600 InfiniBand/Ethernet)相结合,为AI的未来发展提供动力。
一、百万级Token上下文带来的挑战:预填充(Prefill)阶段的计算瓶颈
随着大型语言模型(LLM)向着更长的上下文窗口(如一百万Token)发展,一个严峻的计算挑战浮出水面。LLM的推理过程主要分为两个阶段:
-
预填充(Prefill)阶段:模型并行处理输入提示(prompt)中的所有Token,以生成第一个输出Token。这个阶段的计算特点是计算密集型(Compute-Intensive)和高度并行。它需要巨大的算力来一次性处理整个上下文,其性能瓶颈在于处理器的原始浮点运算能力(FLOPS)。
-
生成(Generation)阶段:模型逐个生成后续的Token,每生成一个Token,就需要将其添加回输入中,形成新的上下文。这个阶段的计算特点是内存带宽密集型(Memory-Bandwidth-Intensive)和顺序执行。由于每次只处理一个Token,其性能瓶颈在于从高带宽内存(HBM)中读取模型权重和KV缓存的速度。
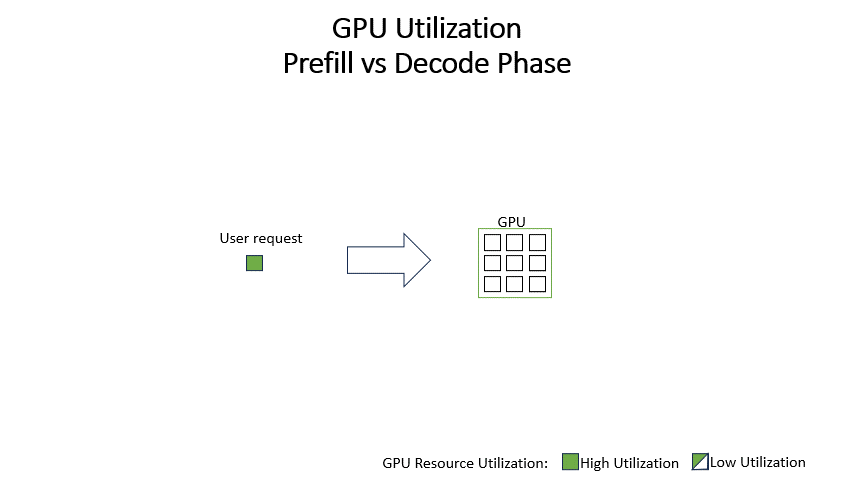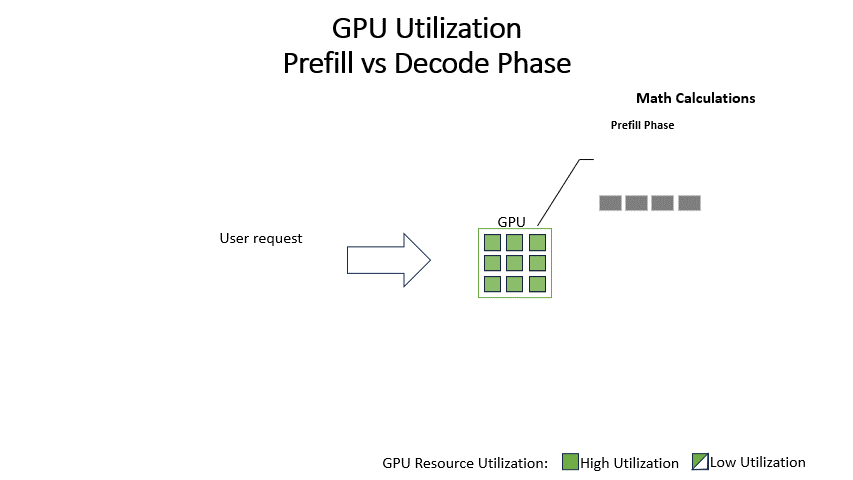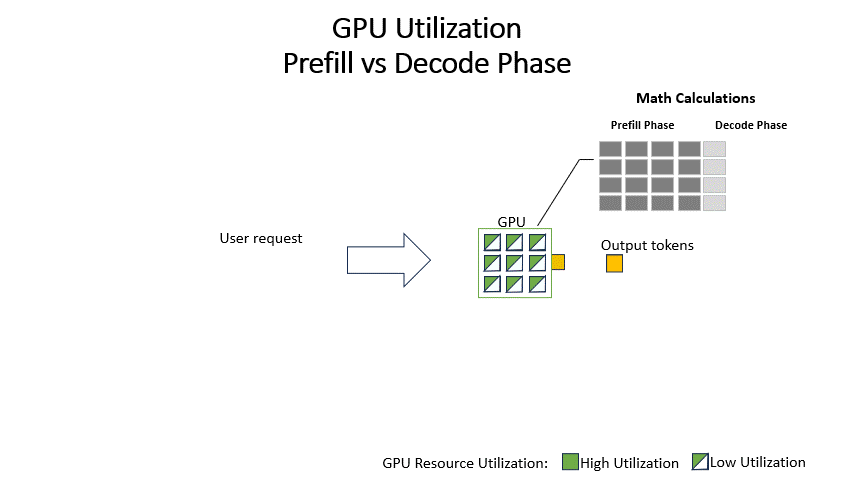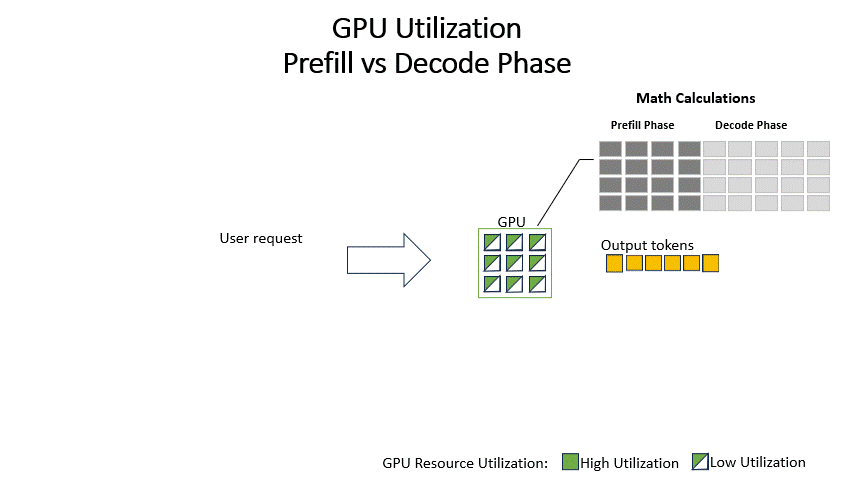
图2:LLM推理的两个阶段。预填充阶段是计算密集型的,而生成阶段则受内存带宽的限制。随着上下文长度的增加,预填充阶段的计算量呈二次方增长,成为主要的性能瓶颈。
对于长达一百万Token的上下文,预填充阶段的计算量变得极为庞大。传统的CPU服务器虽然可以处理该任务,但速度太慢,无法满足实时性要求。而如果完全依赖GPU,虽然其并行计算能力强大,但在处理这种特定类型的计算密集型任务时,可能会导致GPU资源未被最优利用。因此,预填充阶段成为了限制长上下文LLM应用性能和效率的关键瓶颈。
二、NVIDIA CPX:为预填充阶段量身打造的加速引擎
为了解决这一挑战,NVIDIA推出了CPX——一种与Rubin GPU协同工作的新型处理器。CPX本质上是一个高度优化的、拥有强大算力的CPU复合体,专门设计用于处理LLM推理中的预填充阶段。
技术定位与优势
CPX并非要取代通用CPU,而是作为一种专用加速器,与GPU在同一个服务器节点内紧密集成。它的核心优势在于:
- 强大的算力:CPX拥有大量的CPU核心和极高的浮点运算性能,使其能够高效地执行预填充阶段所需的大规模并行计算。
- 与GPU的协同工作:CPX通过高速互连技术(如NVLink)与Rubin GPU紧密相连。在推理过程中,CPX负责处理计算密集的预填充任务,而GPU则专注于其更擅长的、受内存带宽限制的生成任务。
- 资源优化:这种“任务分解”的异构计算模式,使得系统中的每种处理器都能专注于其最擅长的任务,从而实现了整体性能和能效的最大化。GPU可以将其宝贵的HBM带宽和计算核心保留给生成阶段,而CPX则为预填充提供了专用的、强大的计算资源。
这种架构设计思想,体现了NVIDIA对未来AI计算负载的深刻理解:即通过专用的硬件来解决特定的瓶颈,从而实现整个系统的性能飞跃。
三、系统级集成:NVIDIA MGX 与全栈优化
CPX的强大能力需要通过高效的系统设计来释放。NVIDIA MGX模块化服务器架构为此提供了理想的平台。

图3:基于NVIDIA MGX服务器设计,NVIDIA Rubin GPU可以与NVIDIA CPX在单个服务器中灵活组合,以满足不同AI工作负载的需求。
通过MGX,系统构建者可以将多个Rubin GPU模块和CPX模块灵活地组合在同一个服务器机箱内。这种设计的生产级优势显而易见:
- 简化的基础设施:企业不再需要维护独立的、庞大的CPU集群和GPU集群。一个集成了CPX和GPU的服务器节点,就能同时高效处理预填充和生成任务,极大地降低了数据中心的复杂性、网络开销和管理成本。
- 极致的互联带宽:在服务器内部,CPX、GPU和Vera CPU之间通过NVLink 6进行超高速互连,确保数据在不同处理器之间无缝流转,延迟极低。这对于管理庞大的KV缓存至关重要。
- 无缝的横向扩展:当单个节点的计算能力不足以支撑超大模型时,可以通过CX9 SuperNIC和X1600 InfiniBand网络技术,将多个服务器节点连接成一个强大的计算集群。这为训练和推理万亿参数级别的模型提供了必要的扩展能力。
生产级部署视角
从MLOps和DevOps的角度来看,这种集成架构意味着更低的总体拥有成本(TCO)和更高的部署灵活性。模型可以更高效地在单个节点内完成端到端的推理,减少了跨节点通信的延迟和复杂性,从而提升了服务的响应速度和吞吐量。
四、性能飞跃:4倍预填充加速与3倍整体性能提升
集成了CPX的Rubin平台在处理长上下文LLM时,展现了惊人的性能提升。与NVIDIA Hopper架构相比,配备了8个Rubin GPU和8个CPX的服务器节点能够实现:
- 4倍的预填充性能提升:直接解决了长上下文推理中最主要的性能瓶颈。
- 3倍的整体LLM推理性能提升:结合了预填充的加速和生成阶段的优化。
- 高达1.5倍的能效提升:在实现更高性能的同时,显著降低了单位计算的能耗。
图4说明: 原始性能对比图表无法直接链接。根据原文描述,该图表展示了与NVIDIA Hopper架构相比,集成了CPX的Rubin平台在处理百万级Token上下文时,预填充性能提升4倍,整体LLM推理性能提升3倍。
这一性能飞跃,将使得过去因成本和延迟过高而难以实现的百万级Token应用(如处理整本小说、分析完整代码库、对话式AI拥有长期记忆等)变得触手可及。
五、软件生态:TensorRT-LLM与NIM的关键作用
硬件的强大能力离不开软件生态的支持。NVIDIA的全栈计算平台确保了开发者可以轻松利用CPX带来的性能优势。
-
NVIDIA TensorRT-LLM:作为NVIDIA的LLM推理优化库,TensorRT-LLM将是发挥CPX能力的核心。它内置了智能调度器和优化的计算内核,能够自动分析推理任务的特点,并将预填充阶段的计算无缝地卸载到CPX上执行,同时协调GPU处理生成阶段。开发者无需手动管理复杂的硬件资源分配,即可获得最佳性能。
-
NVIDIA NIM(NVIDIA Inference Microservices):NIM是NVIDIA提供的推理微服务。开发者可以将他们使用TensorRT-LLM优化后的模型打包成一个标准的、可移植的NIM容器。这个微服务抽象了所有底层的硬件复杂性,向上提供一个简单的API接口。部署团队只需部署这个NIM,即可在Rubin + CPX平台上获得开箱即用的高性能推理服务,极大地加速了从模型开发到生产部署的流程。
通过这种软硬件协同设计,NVIDIA确保了其最先进的硬件创新能够被广大开发者快速、便捷地应用到实际产品中。
六、结论与展望
NVIDIA Rubin平台及其CPX组件,标志着AI计算架构的一次重要演进。它不再是单纯地堆砌通用算力,而是通过异构计算和专用加速的思路,精准地解决了下一代AI工作负载中最棘手的瓶颈。
通过将专为预填充设计的CPX与专为生成设计的GPU紧密集成在MGX模块化服务器中,并辅以NVLink和InfiniBand等高速网络技术,NVIDIA构建了一个端到端、高度优化的全栈解决方案。这不仅为百万级Token上下文的LLM应用铺平了道路,也为未来更复杂、更多样化的AI模型提供了可扩展、高效率的计算基石。
随着AI的边界不断拓展,这种软硬件深度协同、针对特定负载进行优化的设计哲学,将继续引领人工智能基础设施的未来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)