Datawhale 理工科-大模型入门实训课程 202509 第2次作业
课后作业。
目录
Chapter-2 大模型使用
1 云端大模型调用:最便捷的路径
Step 1:获取 硅基流动 API Key
访问硅基流动平台官网,注册账号,在个人中心找到你的 API Key(密钥) 和 API Base URL(接口地址)。请务必保管好你的 API Key,不要泄露。
创建好账户之后,即可获取到 API Key 和 API Base URL。
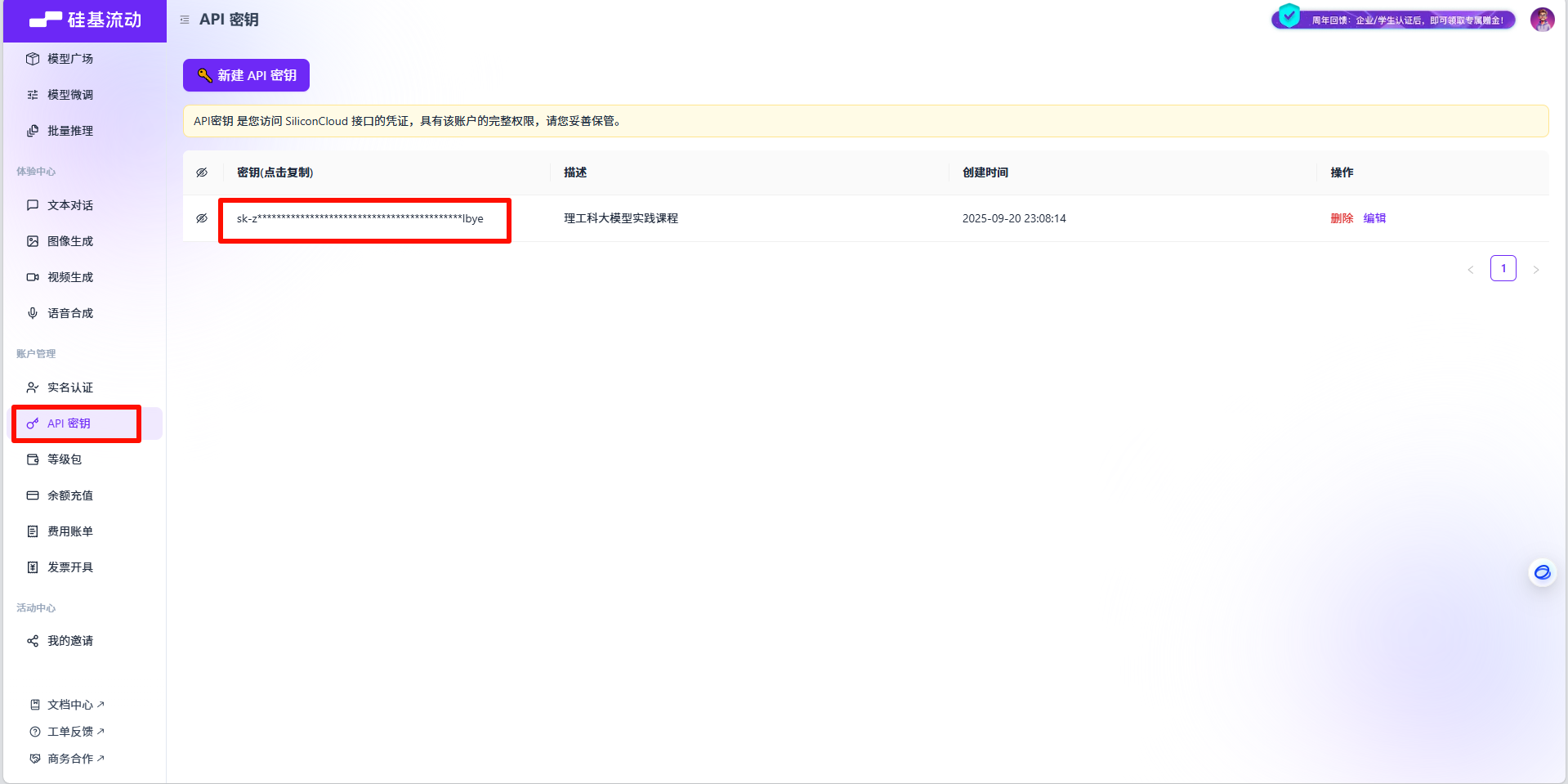 从这个地址直接进
从这个地址直接进Step 2: 调用大模型
接下来,我们安装openai库,用于调用大模型。
!pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
!pip install -q openai使用以下代码调用云端API大模型:
from openai import OpenAI
client = OpenAI(api_key="sk-zyajpnlbijwsyxzzzzcdgiepebvxohoybxoerjaxbaphlbye",
base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{'role': 'user', 'content': "你好!"}
],
max_tokens=1024,
temperature=0.7,
stream=False
)
print(response.choices[0].message.content)def chat_with_model(user_input: str, history: list = None, temperature: float = 0.7, system_prompt: str = None) -> str:
"""
与大模型进行对话的函数
Args:
user_input: 用户输入的文本
history: 历史对话记录列表
temperature: 温度参数,控制输出的随机性
system_prompt: 系统提示词
Returns:
str: 模型返回的文本
"""
# 初始化 OpenAI 客户端
client = OpenAI(api_key="sk-zyajpnlbijwsyxzzzzcdgiepebvxohoybxoerjaxbaphlbye",
base_url="https://api.siliconflow.cn/v1")
# 初始化历史记录
if history is None:
history = []
# 构建消息列表
messages = []
# 添加系统提示词(如果有)
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
# 添加历史对话
for msg in history:
messages.append(msg)
# 添加当前用户输入
messages.append({"role": "user", "content": user_input})
# 调用API获取响应
response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=messages,
temperature=temperature
)
# 返回模型回复的文本
return response.choices[0].message.content
print(chat_with_model("你好哇"))你好!😊 这里是小助手,有什么我可以帮你的吗?
2 本地部署与调用:更强的掌控力
使用 transformers 部署大模型
!pip install -q modelscope transformers accelerate
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-4B-Thinking-2507', cache_dir='/root/autodl-tmp/model', revision='master')from transformers import AutoModelForCausalLM, AutoTokenizer
# 设置模型本地路径
model_name = "/root/autodl-tmp/model/Qwen/Qwen3-4B-Thinking-2507"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 自动选择合适的数据类型
device_map="cuda:0", # 自动选择可用设备(CPU/GPU)
trust_remote_code=True
)
# 准备模型输入
prompt = "你好,请介绍一下自己"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 选择是否打开深度推理模式
)
# 将输入文本转换为模型可处理的张量格式
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成文本
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768 # 设置最大生成token数量
)
# 提取新生成的token ID
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容
try:
# rindex finding 151668 (</think>)
# 查找结束标记"</think>"的位置
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
# 解码思考内容和最终回答
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
# 打印结果
print("thinking content:", thinking_content)
print("content:", content)显示结果:
Loading checkpoint shards: 100%
3/3 [00:01<00:00, 1.40it/s]
thinking content: 嗯,用户让我介绍一下自己。首先,我需要确定他们想要了解什么。可能他们刚接触我,想了解我的功能和能力。作为通义千问,我应该先说明我的中文名和英文名,这样用户能知道我的身份。 接下来,得突出我的主要特点。比如超大规模参数量、多语言支持、对话理解能力。用户可能关心我能不能处理复杂任务,所以得提到代码写作、逻辑推理、多语言翻译这些具体能力。 还要注意用户可能的深层需求。比如他们可能想用我来写代码,或者翻译文档,或者做逻辑题。所以需要举几个例子,比如写Python代码、解释数学问题、翻译英文句子,这样更直观。 另外,用户可能不太清楚模型的训练数据截止时间,这个信息很重要,避免他们用过时的信息。要提到训练数据截止到2024年10月,这样他们知道我的知识是到这个时间点的。 还要考虑用户是否需要进一步帮助。最后应该邀请他们提问,这样能促进互动。比如“如果你有任何问题或需要帮助,随时告诉我!” 需要避免太技术化的术语,保持口语化。比如“超大规模参数量”可能有点专业,但用户可能已经知道,所以还是保留,但用简单的话解释。比如“能处理复杂的任务,比如写代码、解答数学题、翻译语言等”。 检查有没有遗漏的重要点。比如是否提到对话理解能力,是否强调多语言支持。对了,要提到支持多种语言,比如中文、英文、德语等,这样用户知道可以翻译不同语言。 还要注意结构清晰,分点说明可能更好,但用户可能希望自然的段落。所以用连贯的句子,分句说明不同点。 最后,保持友好和专业的语气,避免太生硬。比如开头用“你好!我是通义千问(Qwen)”,然后介绍自己,再举例,最后邀请提问。 可能用户是第一次接触,所以不需要太深入的技术细节,重点在实用功能。比如“能帮你写代码、解答问题、翻译语言”这样的例子。 再想想有没有错误。比如训练数据截止时间,官方是2024年10月,所以要写准确。不能写成2023年,避免误导。 好,大概这样组织语言。先自我介绍,再功能,例子,截止时间,最后邀请提问。 </think> content: 你好!我是通义千问(Qwen),是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我的设计目标是能够帮助用户解决各种问题,无论是日常对话、创作文字,还是处理复杂的逻辑推理、编程任务。 ### 我能帮你做什么? - **回答问题**:比如解释科学概念、解答数学题、提供生活建议等。 - **创作文字**:写故事、写公文、写邮件、写剧本、写诗等。 - **编程**:理解并生成多种编程语言的代码(如Python、Java、C++等)。 - **多语言支持**:我支持中文、英文、德语、法语、西班牙语等百种语言,可以帮你翻译或跨语言交流。 - **逻辑推理**:分析问题、推理结论,甚至参与策略讨论。 - **表达观点**:根据你的需求,提供客观、有理有据的分析和建议。 ### 我的特点 - **超大规模参数量**:能处理复杂的任务,比如长文本生成、多步骤推理。 - **对话理解能力**:能根据上下文理解对话,让交流更自然。 - **训练数据截止时间**:我的训练数据截止到2024年10月,所以对更新的信息可能不了解。 举个例子: - 你可以问我:“怎么用Python写一个简单的计算器?” - 或者:“请用中文翻译这句话:‘Hello, how are you?’” - 甚至:“帮我分析一下这个数学题:3x + 5 = 14” 如果你有任何问题或需要帮助,随时告诉我! 😊
# 准备模型输入
prompt = "你好,请介绍一下自己"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 选择是否打开深度推理模式
)
print(text)<|im_start|>user 你好,请介绍一下自己<|im_end|> <|im_start|>assistant <think>
同样我们也可以将其封装为一个函数,如下代码所示:
from transformers import AutoModelForCausalLM, AutoTokenizer
# 设置模型本地路径
model_name = "/root/autodl-tmp/model/Qwen/Qwen3-4B-Thinking-2507"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 自动选择合适的数据类型
device_map="cuda:0", # 自动选择可用设备(CPU/GPU)
trust_remote_code=True
)
model输出:
Loading checkpoint shards: 100%
3/3 [00:01<00:00, 1.41it/s]
Qwen3ForCausalLM(
(model): Qwen3Model(
(embed_tokens): Embedding(151936, 2560)
(layers): ModuleList(
(0-35): 36 x Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): Linear(in_features=2560, out_features=4096, bias=False)
(k_proj): Linear(in_features=2560, out_features=1024, bias=False)
(v_proj): Linear(in_features=2560, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=2560, bias=False)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
)
(mlp): Qwen3MLP(
(gate_proj): Linear(in_features=2560, out_features=9728, bias=False)
(up_proj): Linear(in_features=2560, out_features=9728, bias=False)
(down_proj): Linear(in_features=9728, out_features=2560, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((2560,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((2560,), eps=1e-06)
)
)
(norm): Qwen3RMSNorm((2560,), eps=1e-06)
(rotary_emb): Qwen3RotaryEmbedding()
)
(lm_head): Linear(in_features=2560, out_features=151936, bias=False)
)
def chat_with_local_model(model, tokenizer, user_input: str, history: list = None, temperature: float = 0.7, max_new_tokens: int = 1024, enable_thinking: bool = True) -> dict:
"""
使用本地大模型进行对话的函数
Args:
model: 加载好的模型
tokenizer: 加载好的分词器
history: 历史对话记录列表,格式为 [{"role": "user", "content": "..."}, {"role": "assistant", "content": "..."}]
temperature: 温度参数,控制输出的随机性 (0.0-1.0)
max_new_tokens: 最大生成token数量
enable_thinking: 是否启用深度推理模式
Returns:
dict: 包含思考内容和最终回答的字典 {"thinking_content": str, "content": str}
"""
# 初始化历史记录
if history is None:
history = []
# 构建消息列表
messages = []
# 添加历史对话
for msg in history:
messages.append(msg)
# 添加当前用户输入
messages.append({"role": "user", "content": user_input})
# 应用聊天模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking # 选择是否打开深度推理模式
)
# 将输入文本转换为模型可处理的张量格式
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成文本
generated_ids = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens, # 设置最大生成token数量
temperature=temperature,
do_sample=True if temperature > 0 else False # 当temperature > 0时启用采样
)
# 提取新生成的token ID
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容
try:
# rindex finding 151668 (</think>)
# 查找结束标记"</think>"的位置
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
# 解码思考内容和最终回答
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
return {
"thinking_content": thinking_content,
"content": content
}
# 使用示例
if __name__ == "__main__":
# 单轮对话示例
result = chat_with_local_model(
model=model,
tokenizer=tokenizer,
user_input="你好,请介绍一下自己",
temperature=0.7
)
print("\n==================== 单轮对话结果 ====================")
print("thinking content:", result["thinking_content"])
print("content:", result["content"])
# 多轮对话示例
history = [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!我是Qwen,一个AI助手。"}
]
result = chat_with_local_model(
model=model,
tokenizer=tokenizer,
user_input="你能帮我写一首诗吗?",
history=history,
temperature=0.8
)
print("\n==================== 多轮对话结果 ====================")
print("thinking content:", result["thinking_content"])
print("content:", result["content"])显示:
==================== 单轮对话结果 ==================== thinking content: 嗯,用户让我介绍一下自己。首先,我需要确定用户想要了解什么。可能他们不太清楚通义千问的具体功能,或者想确认我的能力范围。我应该先说明我的身份,是通义实验室研发的超大规模语言模型,然后重点突出主要功能和特点。 用户可能是个刚接触AI的新手,所以得用简单易懂的语言,避免太技术化的术语。要分点说明,但不要用markdown格式。可能需要提到多语言支持,因为用户可能关心是否能用中文或者其他语言。还要强调应用场景,比如回答问题、创作文字、编程等,这样用户能直观理解能帮到他们什么。 另外,用户可能想知道我的训练数据截止时间,这点很重要,因为涉及到信息的时效性。得提到截止到2024年10月。还要注意不要涉及隐私或敏感内容,保持正面。 可能需要检查有没有遗漏的关键点,比如是否支持对话、逻辑推理、多语言等。对了,用户可能还想知道我的名字“通义千问”有什么含义,可以简单解释一下,比如“通义”代表广泛的知识和普适性,“千问”代表能回答各种问题。 最后要以友好的语气结束,邀请用户提问或指导,这样显得更亲切。避免用太长的句子,保持口语化。现在组织语言,确保流畅自然。 </think> content: 你好!我是**通义千问**(Qwen),是通义实验室研发的超大规模语言模型。我的设计目标是成为一款能够理解人类语言、提供有用信息和创意的AI助手。 ### 我能帮你做什么? 1. **回答问题**:无论是学术问题、生活常识,还是冷知识,我都可以尝试帮你解答。 2. **创作文字**:写故事、写公文、写邮件、写剧本、写诗、写代码……我都能尝试帮你完成。 3. **逻辑推理**:分析问题、推理判断、解决数学题、逻辑题等。 4. **编程**:理解并生成多种编程语言的代码(如Python、Java、C++等)。 5. **多语言支持**:除了中文,我还支持英文、德语、法语、西班牙语等百种语言。 6. **表达观点**:根据你的需求,提供对某些话题的分析和建议。 ### 我的特点 - **超大规模参数量**:拥有强大的语言理解和生成能力。 - **多语言支持**:覆盖全球主流语言,方便跨国交流。 - **对话理解**:能通过多轮对话理解上下文,提供更自然的交互体验。 - **安全合规**:严格遵循法律法规,不涉及敏感或不当内容。 ### 举个例子 如果你问:“如何用Python写一个简单的计算器?” 我可能会先解释基本的Python语法,然后给出一个可运行的代码示例,最后还可能补充一些优化建议。 --- 我的训练数据截止时间是**2024年10月**,所以我会尽量提供最新、最准确的信息。如果你有任何问题或需要帮助,随时告诉我! 😊 有什么具体想了解的吗?或者需要我帮你做点什么? ==================== 多轮对话结果 ==================== thinking content: content: 嗯,用户让我帮忙写一首诗。首先,我需要确定他们想要什么风格的诗,比如古诗、现代诗,或者有特定的主题。不过用户没给具体信息,可能希望我随便创作一首。 先想一下,可能用户是想测试我的创作能力,或者需要一首诗来表达某种情感。比如,可能他们现在心情不错,想分享一首轻松的诗,或者有特定的场景,比如自然、爱情、离别之类的。 我得选一个比较通用的主题,避免太晦涩。比如春天的景象,比较容易引起共鸣。古诗的话,五言或七言比较常见。现代诗可能更自由一些,但用户可能更喜欢传统一点的。 比如,可以写“春日”主题,用一些自然的意象,比如花开、微风、鸟鸣。然后押韵,比如“风”、“红”、“空”之类的。 先试着写七言绝句: 春风轻拂柳丝长, 花影摇曳映池塘。 鸟语声声催梦醒, 一池碧水共月光。 检查一下平仄和押韵。七绝的平仄可能需要调整,不过作为AI生成,可能不太严格。押韵的话,长、塘、光,这里可能不太押韵,塘是ang,光是ang,长是ang,可能可以。但“醒”是ing,可能不太对。需要调整。 比如第二句末尾换成“花影摇曳映池塘”,“塘”是ang,第三句末尾要押ang韵,比如“梦”是eng,可能不行。可能需要换词。 再试一次: 春风轻拂柳丝长, 花影摇曳水波光。 鸟语声声唤新绿, 一池碧水共朝阳。 这里“长”、“光”、“阳”都是ang韵,可能更合适。不过“唤新绿”有点不太自然,可能改成“唤春归”? 或者: 春风轻拂柳丝长, 花影摇曳水波香。 鸟语声声催梦醒, 一池碧水映朝阳。 “香”和“阳”押ang,但“醒”是eng,可能第三句末尾需要换韵。七绝通常是二四句押韵,所以第三句可以不押。 比如: 春风轻拂柳丝长, 花影摇曳水波光。 鸟语声声唤春意, 一池碧水映朝阳。 这样第二句和第四句押ang韵,第三句不押。可能更符合格律。 不过用户可能不需要太严格的格律,所以可以稍微灵活一点。或者用现代诗,更自由。 比如现代诗: 春日的风,轻轻吹过, 柳枝摇曳,花儿微笑。 鸟儿在枝头歌唱, 阳光洒在湖面上,波光粼粼。 这样比较简洁,有画面感。 用户可能希望是中文诗,所以可能需要选择一种风格。可能他们想要比较有诗意的,不要太直白。 再想想,可能用户想要一首短诗,比如四行。或者带点哲理。 比如: 时光如流水, 花开花落几度秋。 莫问前程远, 且看眼前花。 不过可能有点太抽象。 或者更简单一点: 春风吹绿江南岸, 柳絮纷飞似雪轻。 蝶舞花间寻旧梦, 一江春水向东行。 这里押ing/eng韵,可能不太统一。 可能我应该选一个更简单的,避免太复杂。比如: 春风轻,柳丝长, 花儿笑,鸟儿唱。 阳光暖,心也亮, 一天好时光。 不过这样比较口语化,可能不够有诗意。 再考虑用户可能想要一首有情感的,比如思念、喜悦之类的。 比如: 思念如风,吹过山岗, 月光如水,漫过窗。 心中有你,夜夜长, 梦里相逢,笑颜扬。 不过可能有点长。 或者更简短: 月光下,思念在流淌, 心随风,飘向你身旁。 一纸情书,写满星光, 愿你我,永不分离。 不过可能有点太直接。 可能用户需要的是比较传统的,所以还是选七言绝句吧。 再试一次: 春风又绿江南岸, 细雨轻敲柳叶新。 花落无声人已远, 一江春水向东行。 这里“岸”、“新”、“行”可能不押韵。需要调整。 比如: 春风轻拂柳丝长, 细雨润花映日光。 花落无声人已远, 一江春水向东行。 “长”、“光”、“行”不押韵,可能需要第二句和第四句押韵。 比如: 春风轻拂柳丝长, 花影摇曳水波
虽然使用 transformers 在本地部署模型能让我们获得完整的控制权限,但这种方式存在一定的性能瓶颈,尤其在首次推理时表现明显。这种本地部署方式更适合进行简单模型加载测试或算法研究工作,但若要将模型打造成一个支持高并发调用的服务,其计算效率则显得捉襟见肘。这便是 transformers 本地部署方案在性能方面的主要局限。
进阶:使用 vLLM 进行高性能部署
在终端输入:
!pip install -q vllm 使用以下命令在命令行终端启动 vllm 服务:
vllm serve /root/autodl-tmp/model/Qwen/Qwen3-4B-Thinking-2507 \ --served-model-name Qwen3-4B \ --max_model_len 1024 \ --reasoning-parser deepseek_r1以上命令中各参数的含义如下:
/root/autodl-tmp/model/Qwen/Qwen3-4B-Thinking-2507: 模型路径,指向本地存储的 Qwen 3.0 6B 模型文件--served-model-name Qwen3-4B: 服务启动后使用的模型名称--max_model_len 1024: 设置模型最大处理的序列长度为 1024 个 token--reasoning-parser deepseek_r1: 使用 deepseek_r1 作为推理解析器这些参数配置了 vllm 服务的基本运行参数,包括模型位置、服务名称、序列长度限制以及推理相关的功能设置。
注意:如果想要对 vllm 服务进行更多定制化配置,建议参考 vllm 官方文档。
然后就可以像使用云端大模型一样的方式来调用 vllm 启动的模型服务,如下代码所示:
from openai import OpenAI
client = OpenAI(api_key="xxx",
base_url="http://127.0.0.1:8000/v1")
response = client.chat.completions.create(
model="Qwen3-4B",
messages=[
{'role': 'user', 'content': "你好哇"}
],
max_tokens=512,
temperature=0.7,
stream=False
)
print(response.choices[0].message)显示:
ChatCompletionMessage(content='\n\n你好呀!😊 有什么问题或者需要帮忙的吗?', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[], reasoning_content='嗯,用户发来“你好哇”,看起来是打招呼。首先,我需要回应得友好和亲切。可能用户是想开始一段对话,或者测试我的反应。我应该用中文回复,保持口语化。\n\n“你好哇”是中文里常见的问候,带点方言的味道,比如“你好哇”在南方可能更常用,或者网络用语。我需要确认用户可能的意图。可能他们想闲聊,或者有具体的问题。\n\n作为AI助手,我应该先回应问候,然后主动提供帮助。比如问他们需要什么帮助,或者有什么问题。这样既友好又能引导他们说出需求。\n\n要注意避免太机械的回答,比如直接说“你好,有什么可以帮你的吗?”。可能需要加点表情符号,但用户没指定,可能保持简洁。不过之前的例子有“😊”,所以可以加一个。\n\n另外,用户可能想测试我的反应速度或者是否理解中文。所以回复要准确,用中文,不能有错误。\n\n可能的回复:“你好呀!😊 有什么我可以帮你的吗?”\n\n检查有没有错别字,比如“呀”和“哇”都是语气词,但用户用了“哇”,我可以用“呀”来保持自然。或者直接用“你好哇”回应?不过可能重复了,所以用“你好呀”更合适。\n\n或者更亲切一点:“你好哇!😊 有什么问题或者需要帮忙的吗?”\n\n这样既回应了问候,又提供了帮助的选项。用户可能需要进一步说明需求,所以这样提问比较合适。\n\n有没有可能用户有其他意图?比如开玩笑?但“你好哇”比较中性,所以按常规处理。\n\n确定回复内容,保持简短,友好,有帮助导向。\n')
课后作业
请同学们尝试使用 python 中的 requests 来调用模型服务。
import requests
import json
# 设置API端点
url = "http://127.0.0.1:8000/v1/chat/completions"
# 准备请求数据
payload = {
"model": "Qwen3-4B",
"messages": [
{
"role": "user",
"content": "你好哇"
}
],
"max_tokens": 512,
"temperature": 0.7,
"stream": False
}
# 设置请求头
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer your-api-key-here" # 替换为你的实际API密钥
}
try:
# 发送POST请求
response = requests.post(url, json=payload, headers=headers)
# 检查响应状态
if response.status_code == 200:
# 解析JSON响应
result = response.json()
# 提取并打印回复内容
reply = result['choices'][0]['message']['content']
print("模型回复:", reply)
else:
print(f"请求失败,状态码: {response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
except KeyError as e:
print(f"响应格式异常,缺少键: {e}")
print("完整响应:", response.text)显示:
模型回复: 你好呀!✨ 有什么我可以帮你的吗?😊

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)