AI产品测试学习路径全解析:从业务场景到代码实践
AI测试是一个充满挑战但前景广阔的领域。转变思维:从确定性测试转向概率性评估技能升级:掌握统计学、机器学习等新技能业务深入:真正理解AI如何创造业务价值工具掌握:学习使用AI测试相关工具和平台未来的测试工程师不再是简单的"找bug者",而是"质量保障工程师"和"风险控制专家"。
深入AI测试领域,掌握核心技能与学习路线,助力测试工程师转型升级
一、引言:AI测试时代的挑战与机遇
随着人工智能技术的快速发展,AI产品已渗透到各行各业。作为测试工程师,我们面临着新的挑战:
-
AI系统的不确定性如何测试?
-
模型评估指标与传统软件有何不同?
-
如何设计有效的AI测试策略?
本文基于一线实战经验,为你系统梳理AI测试的学习路径,涵盖业务理解、指标计算与性能测试三大核心领域,并提供可运行的代码示例。
二、AI测试 vs 传统测试:根本差异
2.1 业务场景决定测试策略
AI测试与传统测试最大区别在于:业务场景直接决定测试方法。不同AI应用场景需要完全不同的测试策略。
典型案例对比:
| 场景 | 特点 | 测试策略 |
|---|---|---|
| 推荐系统(如抖音) | 高频自学习,模型按小时更新 | 以线上灰度发布和监控为主 |
| 反欺诈系统 | 模型按月更新,变化缓慢 | 可进行充分线下测试 |
如果对推荐系统采用反欺诈的测试方法,等测试完成业务早已发生变化。
2.2 常见AI业务场景
-
分类场景:信用卡反欺诈、垃圾邮件过滤
-
推荐系统:内容推荐、广告推荐
-
计算机视觉:目标检测、人脸识别、OCR
-
自然语言处理:机器翻译、情感分析
-
文档解析:版面识别、元素提取
-
智能体系统:RAG流程、多Agent协作
三、阶段一:深入理解业务场景
3.1 学习建议
-
从相关业务开始:优先学习与自己工作相关的AI场景
-
分类场景入门:没有明确方向可从分类场景开始
-
逐步扩展:过渡到推荐系统、计算机视觉等复杂领域
3.2 业务理解关键问题
-
产品的盈利模式是什么?
-
模型更新频率如何?
-
错误的代价是什么?(如误判欺诈 vs 推荐不准)
-
用户容忍度如何?
🧠 科普小知识:什么是RAG?
RAG(Retrieval-Augmented Generation)结合了检索和生成技术,先从知识库检索相关信息,再基于这些信息生成答案。测试时需要关注检索准确性和生成质量。
四、阶段二:掌握模型评估指标
4.1 分类场景核心指标
分类模型最常用的指标基于混淆矩阵(Confusion Matrix):
| 术语 | 含义 | 说明 |
|---|---|---|
| TP(True Positive) | 真阳性 | 实际为正,预测为正 |
| TN(True Negative) | 真阴性 | 实际为负,预测为负 |
| FP(False Positive) | 假阳性 | 实际为负,预测为正 |
| FN(False Negative) | 假阴性 | 实际为正,预测为负 |
基于这些值,可计算以下指标:
-
准确率(Accuracy):所有预测正确的比例
-
召回率(Recall):实际正例中被预测正确的比例
-
精准率(Precision):预测正例中实际正确的比例
-
F1分数(F1-Score):精准率和召回率的调和平均
-
AUC(Area Under Curve):ROC曲线下的面积
4.2 代码实践:计算分类指标
python
import numpy as np
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score, accuracy_score
# 假设我们有以下真实标签和预测结果
y_true = [1, 0, 1, 1, 0, 1, 0, 0] # 1代表正例,0代表负例
y_pred = [1, 0, 1, 0, 0, 1, 1, 0] # 模型预测结果
# 计算混淆矩阵
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
print(f"TN: {tn}, FP: {fp}, FN: {fn}, TP: {tp}")
# 计算各项指标
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"准确率: {accuracy:.2f}")
print(f"精准率: {precision:.2f}")
print(f"召回率: {recall:.2f}")
print(f"F1分数: {f1:.2f}")
4.3 计算机视觉:IOU指标计算
在目标检测任务中,IOU(Intersection over Union)衡量预测框与真实框的重合程度。
python
def calculate_iou(boxA, boxB):
"""
计算两个边界框的IOU(交并比)
boxA和boxB格式为[x1, y1, x2, y2]
"""
# 确定相交区域的坐标
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
# 计算相交区域面积
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
# 计算两个框的各自面积
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
# 计算交并比
iou = interArea / float(boxAArea + boxBArea - interArea)
return iou
# 示例:计算两个框的IOU
boxA = [10, 10, 50, 50] # [x1, y1, x2, y2]
boxB = [20, 20, 60, 60]
iou = calculate_iou(boxA, boxB)
print(f"IOU: {iou:.2f}")
4.4 文档检索场景:余弦相似度
对于推荐系统、文档检索等需要排序的场景,常使用余弦相似度衡量向量间的相似性。
python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
def semantic_search(query_vector, doc_vectors, top_n=5):
"""
语义检索:计算查询与文档的余弦相似度并返回Top-N结果
"""
# 计算余弦相似度
similarities = cosine_similarity([query_vector], doc_vectors)[0]
# 获取相似度最高的前N个文档
top_indices = np.argsort(similarities)[::-1][:top_n]
top_similarities = similarities[top_indices]
return top_indices, top_similarities
# 示例用法
np.random.seed(42) # 确保结果可重现
query_vec = np.random.rand(300) # 300维查询向量
doc_vectors = np.random.rand(1000, 300) # 1000个文档,每个300维向量
top_docs, top_scores = semantic_search(query_vec, doc_vectors)
print("最相关的前5个文档索引:", top_docs)
print("相似度分数:", top_scores)
🧠 科普小知识:什么是余弦相似度?
余弦相似度通过测量两个向量夹角的余弦值来评估它们的相似性。值越接近1,表示向量方向越一致,相似度越高。
五、阶段三:性能测试深入实战
5.1 计算机视觉性能测试
对于视频流处理系统,需要关注:
-
FPS(Frames Per Second):每秒处理帧数
-
端到端延迟:从输入到输出的总时间
-
单GPU支持路数:单个GPU可同时处理的视频流数量
-
各阶段性能:解码、预处理、推理、后处理的耗时分布
5.2 智能体系统性能测试
对于RAG等智能体系统,需要测试:
-
响应时间:端到端耗时
-
知识库检索性能:百万/千万向量级别的检索速度
-
并发处理能力:系统同时处理多个请求的能力
-
资源利用率:CPU、内存、GPU使用情况
5.3 边缘计算场景测试
在边缘计算场景中,还需关注:
-
模型下发性能:模型更新和分发的效率
-
边缘节点管理:多节点协同工作的能力
-
网络带宽占用:数据传输对网络的影响
-
分布式协同效率:中心与边缘节点的协作效率
六、完整学习路径建议
6.1 三阶段学习法
-
业务场景学习(1-2个月)
-
理解不同AI场景的特点和测试需求
-
学习业务术语和核心概念
-
-
模型指标掌握(2-3个月)
-
学习各类评估指标的计算方法
-
动手编写指标统计代码
-
搭建实验环境进行实践
-
-
性能测试深入(3-6个月)
-
研究系统架构和技术栈
-
学习性能测试工具和方法
-
理解全链路性能瓶颈
-
6.2 实践建议
-
利用公有云服务:AWS、Azure、GCP等平台提供AI服务,低成本实践
-
结合开源项目:使用YOLO、BERT等开源模型进行实验
-
重视业务理解:AI测试不只是技术活,更需要业务洞察力
-
循序渐进:从简单场景开始,逐步过渡到复杂场景
七、总结与展望
AI测试是一个充满挑战但前景广阔的领域。作为测试工程师,我们需要:
-
转变思维:从确定性测试转向概率性评估
-
技能升级:掌握统计学、机器学习等新技能
-
业务深入:真正理解AI如何创造业务价值
-
工具掌握:学习使用AI测试相关工具和平台
未来的测试工程师不再是简单的"找bug者",而是"质量保障工程师"和"风险控制专家"。
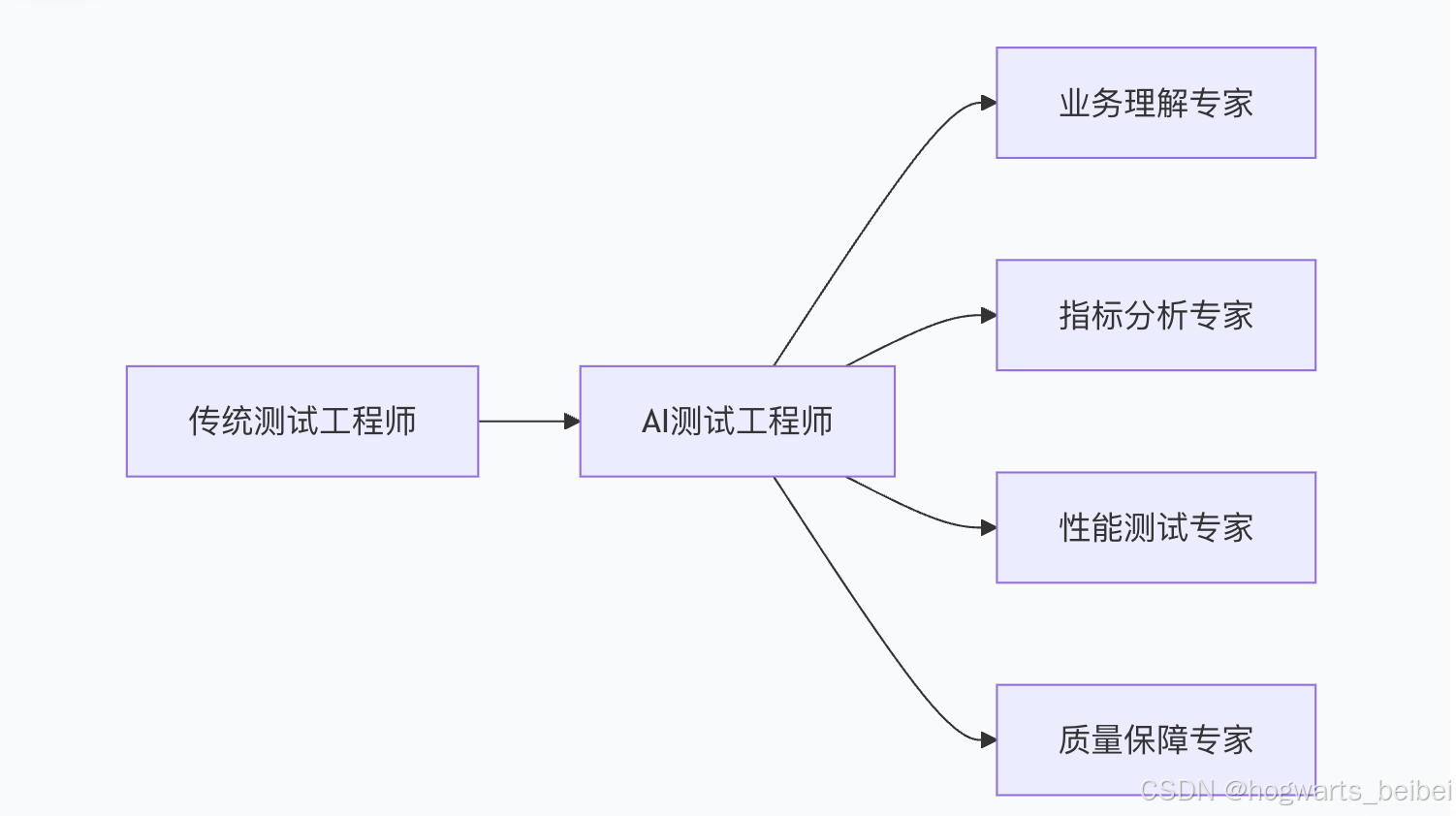
八、进一步学习资源
-
在线课程:
-
Coursera: Machine Learning by Andrew Ng
-
Fast.ai: Practical Deep Learning for Coders
-
-
开源项目:
-
TensorFlow Model Analysis
-
MLflow
-
Evidently AI
-
-
书籍推荐:
-
《机器学习》(周志华)
-
《AI测试实战》
-
《推荐系统实践》
-
-
社区参与:
-
参加Kaggle竞赛
-
加入AI测试技术社区
-
关注AI测试相关开源项目
-
🚀 AI测试时代已经到来,系统性地掌握AI测试技能将为你的职业发展打开新的空间。希望本文提供的学习路径和实践建议能帮助你在AI测试领域快速成长!

---人工智能学习交流群----
推荐阅读
* https://blog.csdn.net/chengzi_beibei/article/details/150393633?spm=1001.2014.3001.5501
* https://blog.csdn.net/chengzi_beibei/article/details/150393354?spm=1001.2014.3001.5501
* https://blog.csdn.net/chengzi_beibei/article/details/150393354?spm=1001.2014.3001.5501
学社精选
- 测试开发之路 大厂面试总结 - 霍格沃兹测试开发学社 - 爱测-测试人社区
- 【面试】分享一个面试题总结,来置个顶 - 霍格沃兹测试学院校内交流 - 爱测-测试人社区
- 测试人生 | 从外包菜鸟到测试开发,薪资一年翻三倍,连自己都不敢信!(附面试真题与答案) - 测试开发 - 爱测-测试人社区
- 人工智能与自动化测试结合实战-探索人工智能在测试领域中的应用
- 爱测智能化测试平台
- 自动化测试平台
- 精准测试平台
- AI测试开发企业技术咨询服务
技术成长路线
系统化进阶路径与学习方案
- 人工智能测试开发路径
- 名企定向就业路径
- 测试开发进阶路线
- 测试开发高阶路线
- 性能测试进阶路径
- 测试管理专项提升路径
- 私教一对一技术指导
- 全日制 / 周末学习计划
- 公众号:霍格沃兹测试学院
- 视频号:霍格沃兹软件测试
- ChatGPT体验地址:霍格沃兹测试开发学社
- 霍格沃兹测试开发学社
企业级解决方案
测试体系建设与项目落地
- 全流程质量保障方案
- 按需定制化测试团队
- 自动化测试框架构建
- AI驱动的测试平台实施
- 车载测试专项方案
- 测吧(北京)科技有限公司
技术平台与工具
自研工具与开放资源
- 爱测智能化测试平台 - 测吧(北京)科技有限公司
- ceshiren.com 技术社区
- 开源工具 AppCrawler
- AI测试助手霍格沃兹测试开发学社
- 开源工具Hogwarts-Browser-Use
人工智能测试开发学习专区

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)