✨ 复现经典!基于AlphaZero的智能五子棋AI项目详解(DRL+MCTS实战)
本项目基于AlphaZero算法实现了五子棋AI,通过纯自我对弈学习,无需人类棋谱。核心架构结合蒙特卡洛树搜索(MCTS)与深度神经网络,其中MCTS负责前瞻性探索,神经网络(含策略网络和价值网络)指导搜索方向。系统包含完整的训练框架和交互界面,支持人机对弈。关键技术包括:残差网络特征提取、温度采样平衡探索利用、时间衰减奖励分配等。实验表明,该AI能自主发现高级战术,验证了AlphaZero在相对
目录
一、项目背景:当AlphaZero遇见五子棋——探索无监督学习的智能博弈新边界
一、项目背景:当AlphaZero遇见五子棋——探索无监督学习的智能博弈新边界
五子棋(Gomoku)作为一种古老而经典的策略性棋类游戏,因其规则简单却蕴含深奥的战术变化,一直是人工智能研究的重要测试平台。传统的五子棋AI解决方案主要依赖于以下技术:
- 启发式规则与搜索算法: 如 Minimax 配合 Alpha-Beta 剪枝,结合人工设计的评估函数(如冲四、活三等棋型权重)。这类方法高度依赖人类专家的先验知识,其性能上限受限于规则设计的完备性和搜索深度的限制。
- 基于人类棋谱的监督学习: 通过训练神经网络学习大量人类高手的对局数据,预测落子位置。虽然效果显著,但模型性能严重受限于训练数据的质量和数量,且难以超越人类的认知边界。
AlphaZero的突破性革命改变了这一局面。2017年,DeepMind提出的AlphaZero算法展示了令人惊叹的能力:仅通过自我对弈(Self-Play),结合蒙特卡洛树搜索和深度强化学习,在围棋、国际象棋和将棋等复杂游戏中迅速超越人类顶级水平,并完全摒弃了人类专家知识或棋谱数据。其核心在于:
- 自我进化: AI通过与自己对战不断学习、改进策略。
- MCTS + DNN 协同: MCTS 负责在给定状态下进行前瞻性探索和评估;深度神经网络则高效地指导搜索方向(策略网络
p)和评估局面优劣(价值网络v)。 - 端到端学习: 从原始棋盘状态输入,直接输出最优策略和局面评估。
然而,将AlphaZero这一强大框架应用于五子棋的研究与实践,相较于其在围棋等领域的广泛应用,仍显不足且具有独特挑战:
- 独特的游戏特性: 五子棋具有更快的终局速度和更强的战术性(如“禁手”规则在某些变体中),对模型的短期计算能力和精确评估能力要求更高。
- 开源实践稀缺: 虽然AlphaZero原理已被广泛讨论,但完整、可复现、且包含友好交互界面的五子棋AlphaZero实现项目在开源社区(如GitHub)或技术博客中仍不多见。
- 工程实现价值: 五子棋规则相对围棋更简单,使其成为理解AlphaZero核心思想(MCTS+DRL协同、自我对弈)和进行工程实践验证的理想切入点,尤其适合学习深度强化学习和探索智能决策的开发者。
💡 本项目应运而生: 我们旨在完整复现并实践AlphaZero算法在五子棋上的应用,打造一个:
✅ 纯自我对弈驱动:不依赖任何人类棋谱或先验知识。
✅ 深度强化学习 + MCTS 深度融合:构建策略-价值网络指导MCTS搜索。
✅ 开箱即用:提供完整的训练框架、直观的游戏界面和人机对弈功能。
通过本项目,我们不仅验证了AlphaZero在相对简单(但战术丰富)的游戏中同样强大的学习与决策能力,更希望为研究者和开发者提供一个清晰、可运行的AlphaZero实践范例,推动深度强化学习在智能博弈领域的发展与应用。
二、核心技术
- **AlphaZero算法**:结合神经网络和MCTS的强化学习算法
- **蒙特卡洛树搜索**:用于策略优化的搜索算法
- **深度神经网络**:策略网络和价值网络的结合
- **自我对弈**:通过AI自我对弈生成训练数据
三、项目结构与准备
1.项目结构搭建
AlaphaZero_Five-master/
├── Game.py # 五子棋游戏逻辑
├── net.py # 神经网络模型和AlphaZero节点
├── train.py # 训练模块
├── main.py # 游戏界面和主程序
├── MCTS/
│ └── Tree.py # MCTS基础节点类
├── data/ # 训练数据存储
└── model.pth # 训练好的模型
2.虚拟环境准备
在Anaconda prompt中使用以下命令一键配置(默认已经安装好PyTorch)
pip install pygame
pip install numpy四、强化学习——AlaphaZero算法
1.算法简介
AlphaZero 有两个关键部分:(1) 在自博弈中使用蒙特卡罗树搜索来收集数据;(2) 使用深度神经网络拟合数据,并在树搜索过程中用于动作概率和状态价值估计。
2.蒙特卡洛树搜索
蒙特卡洛树搜索是一种利用树形数据结构进行搜索的算法,其节点存储是棋盘状态,根节点存储的是棋盘初始状态,其子节点存储是当前状态可能的下一状态。节点上存储的属性包括棋盘当前棋子位置s,访问s的次数n,对节点的估值v。
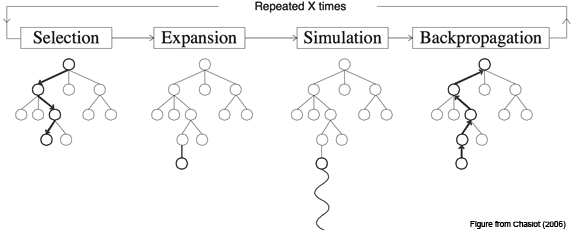
建立一棵蒙特卡洛树的步骤:
- 选择 (Select):根据某个策略,从根节点开始选择动作,直到到达某个叶节点
- 扩展 (Expand):在当前叶节点之后添加子节点
- 模拟 (Simulate):从当前节点开始,通过某种策略(如随机策略)模拟下棋直到游戏结束,得到结果: 胜、负或平局。根据结果获得奖励,通常 +1 代表胜,−1 代表负,0 代表平局
- 回溯 (Backup):回溯更新模拟得到的结果,依次回访本轮树搜索中经过的节点,并更新每个节点上的信息
AlphaZero 算法舍弃了模拟步骤,直接用深度神经网络预测结果。因此,AlphaZero 算法包含三个关键步骤:
- 选择: 根据某个策略,从根节点开始选择动作,直到到达某个叶节点
- 扩展和评估:在当前叶节点之后添加子节点。同时每个动作的选取概率和状态值的估计直接通过策略网络和价值网络预测得到
- 回溯:扩展和评估完成之后,回溯更新结果,依次回访本轮树搜索中经过的节点,并更新每个节点上的信息。如果叶节点不是游戏的终止状态,那么游戏无法返回胜负结果,转而由神经网络预测得到。如果叶节点已经到达游戏的终止状态,那么结果直接由游戏给出
在选择步骤中,动作由公式 ![]() 给出。其中
给出。其中鼓励利用高奖励值对应的动作,
鼓励探索访问次数较少的动作,
表示探索和利用的权重,在 AlphaZero 算法中该值设为 5。
在扩展和评估步骤中,策略网络输出当前状态下每个动作被选择的概率 𝑝(𝑠,𝑎),价值网络输出当前状态 𝑠 的估值 𝑣 。 𝑝(𝑠,𝑎) 用于在选择步骤中计算 𝑈(𝑠,𝑎) ; 𝑣 用于在回溯步骤中计算 𝑊 ,其中 𝑊(𝑠,𝑎)=𝑊(𝑠,𝑎)+𝑣 。神经网络输出的动作概率和状态值估计开始时可能不准确,但在训练过程中会逐渐变准。
在回溯步骤中,每个节点上的信息被依次更新,其中 𝑁(𝑠,𝑎)=𝑁(𝑠,𝑎)+1 , 𝑊(𝑠,𝑎)=𝑊(𝑠,𝑎)+𝑣 , 𝑄(𝑠,𝑎)=𝑊(𝑠,𝑎)𝑁(𝑠,𝑎) 。
3.AlphaZero
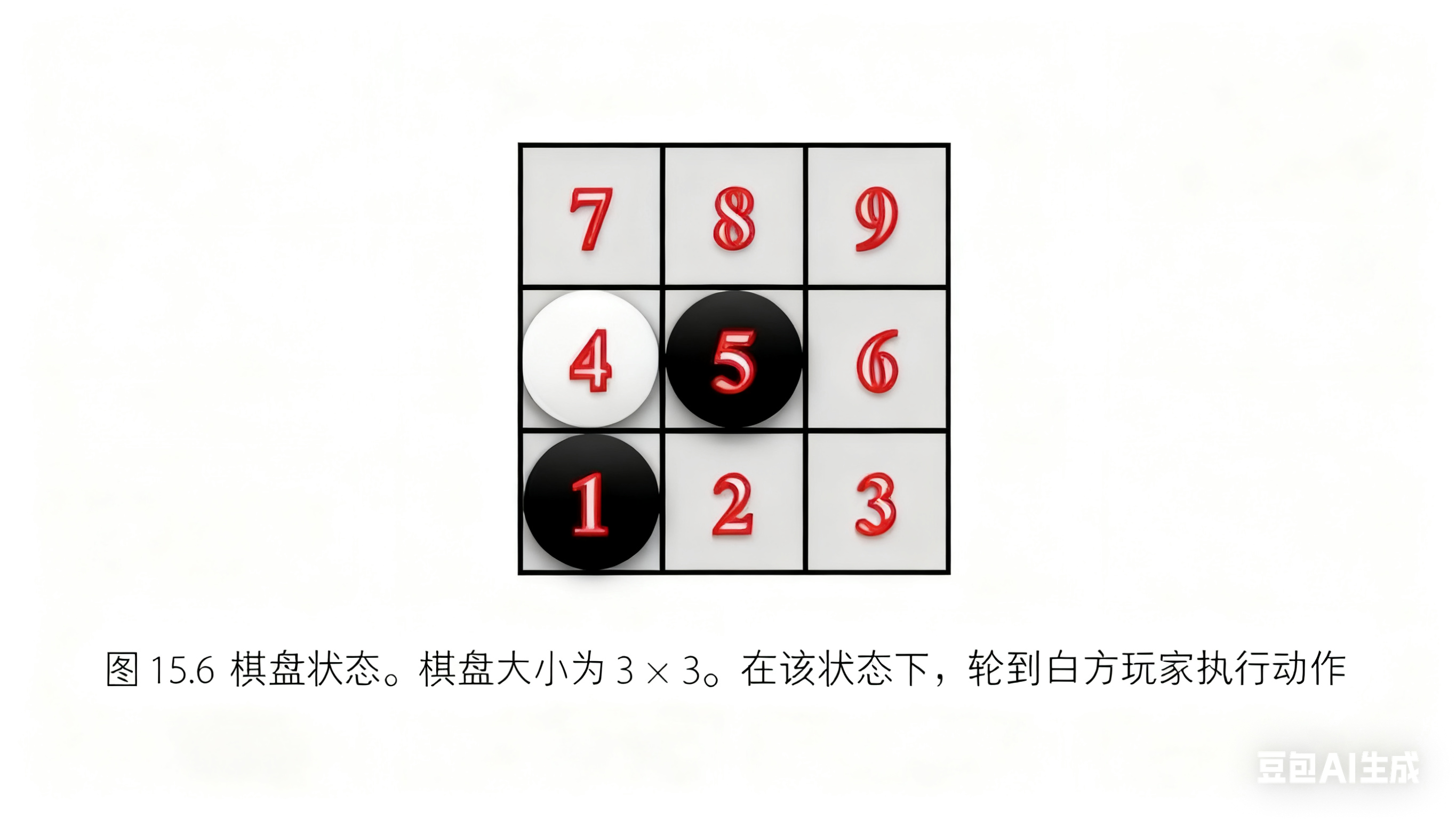
 首先,我们演示蒙特卡罗树搜索收集数据。为了用相对较短的篇幅演示树搜索过程直到游戏的终止状态,我们假定游戏从图 15.6 所示的状态开始(通常游戏是从一个空棋盘开始的)。此时, 轮到白方玩家执行动作。
首先,我们演示蒙特卡罗树搜索收集数据。为了用相对较短的篇幅演示树搜索过程直到游戏的终止状态,我们假定游戏从图 15.6 所示的状态开始(通常游戏是从一个空棋盘开始的)。此时, 轮到白方玩家执行动作。
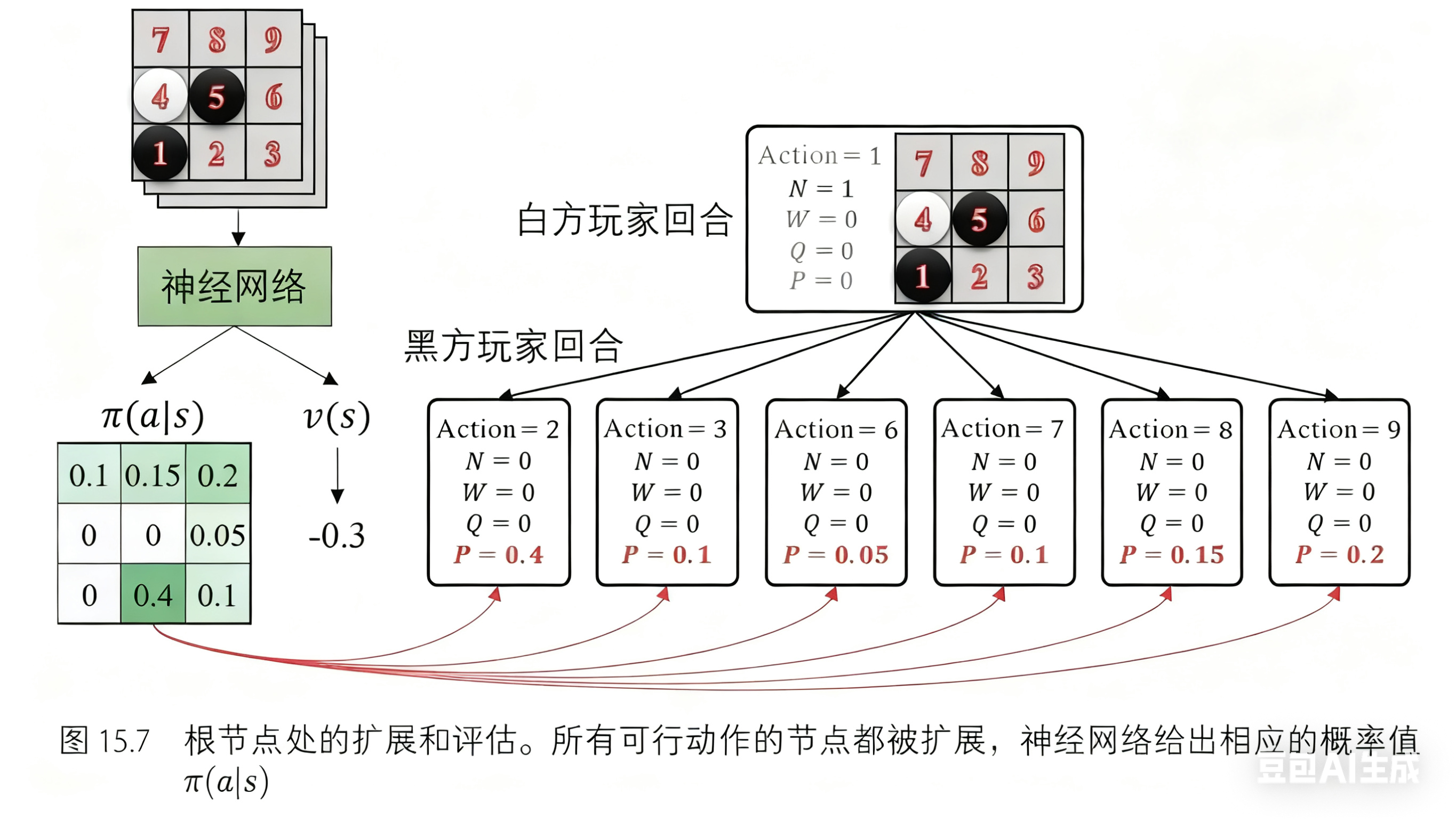
我们从这个状态开始构建树结构,依次执行前述三个树搜索步骤:选择,扩展和评估,回溯。 此时树中只有一个节点,由于它在树的顶部,所以是根节点,又因为它没有子节点,所以它也是叶节点。这意味着我们已经到达了一个叶节点,相当于已经完成了选择步骤。因此,接下来执行第二个步骤:扩展和评估。图 15.7 展示了节点扩展的过程,该节点的所有子节点被展开,同时策略网络以该节点状态作为输入,给出了每个动作被选择的概率。
最后一步是回溯。由于当前节点是根节点,我们不需要回溯 𝑊 和 𝑄 (用于判断树搜索是否应该到达该节点),只需更新访问次数 𝑁 。将 𝑁=0 更新为 𝑁=1 ,本次树搜索过程完成。
每次重新执行树搜索,我们都将从根节点开始。如图 15.8 所示,第二次树搜索过程也将从根节点开始。这一次,根节点下存在子节点,这意味该节点不是叶节点。动作由公式 𝑎=argmax𝑎(𝑄(𝑠,𝑎)+𝑈(𝑠,𝑎)) 给出。这里白方玩家选择动作 𝐴=2(𝑤,2) ,并到达新节点。这个新节点为叶节点,且此时,轮到黑方玩家选择动作。
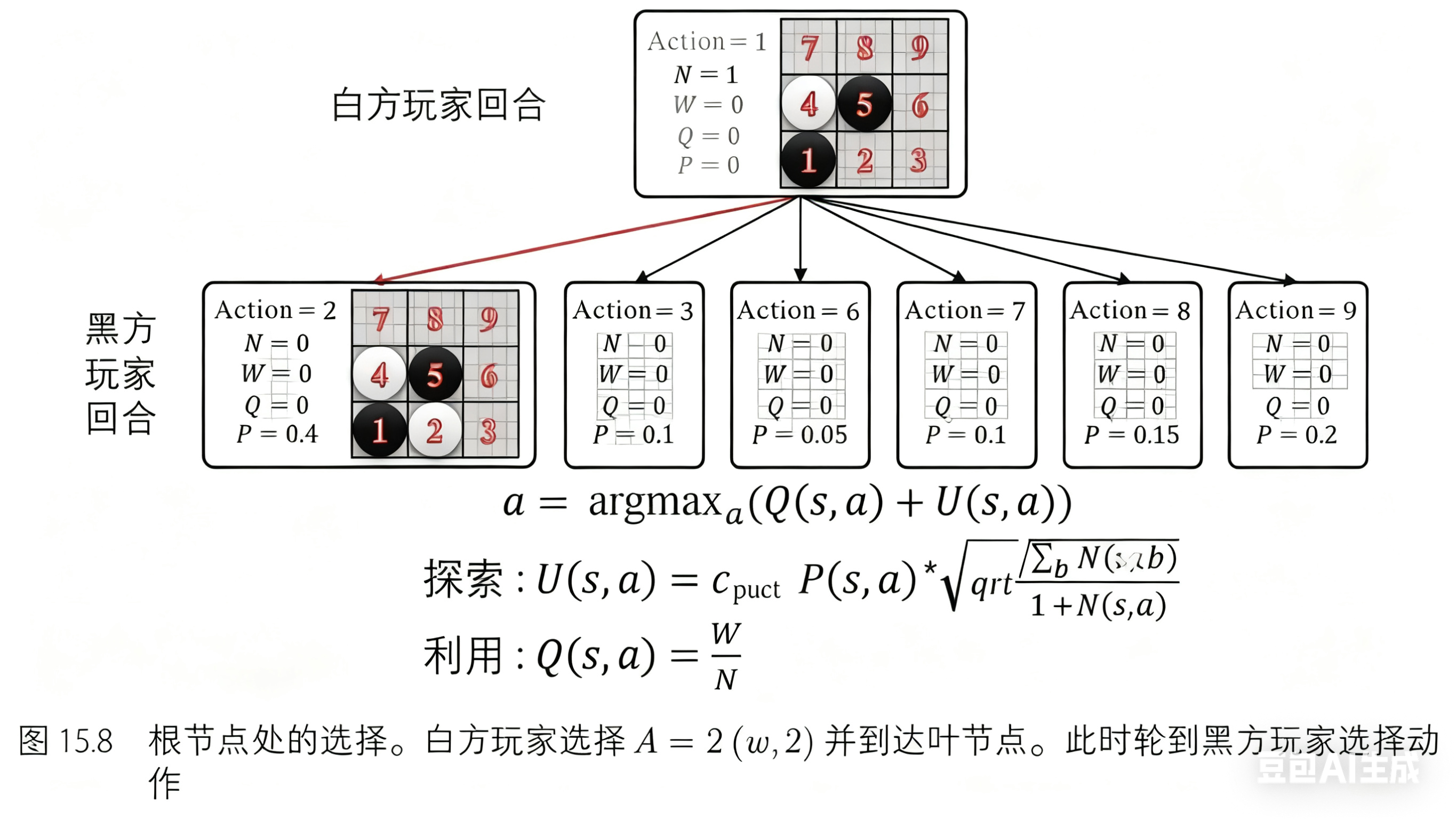
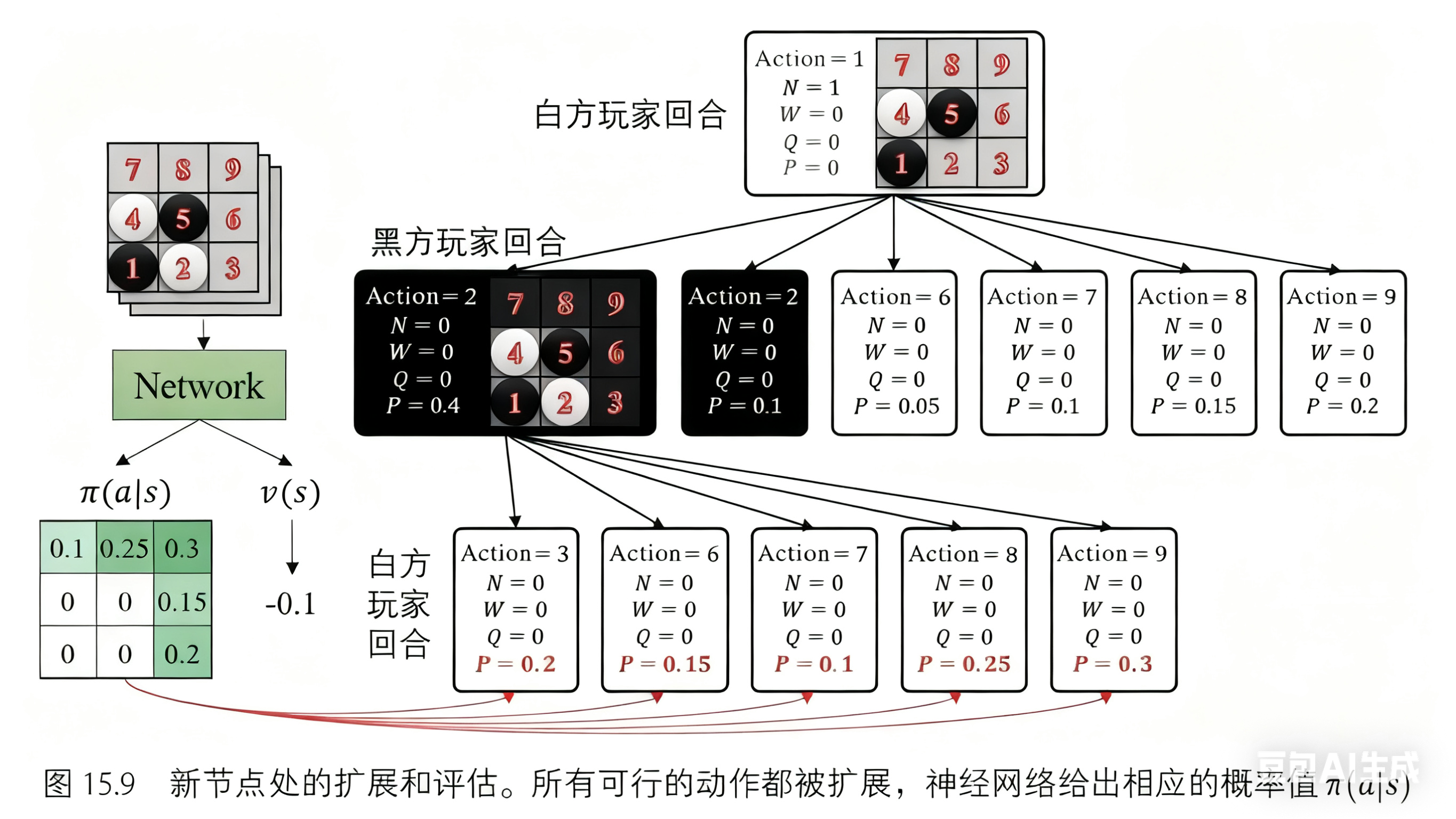
我们对这个叶节点进行扩展和评估。与第一次相同:所有可行的动作都被扩展,每个动作的概率由策略网络给出。
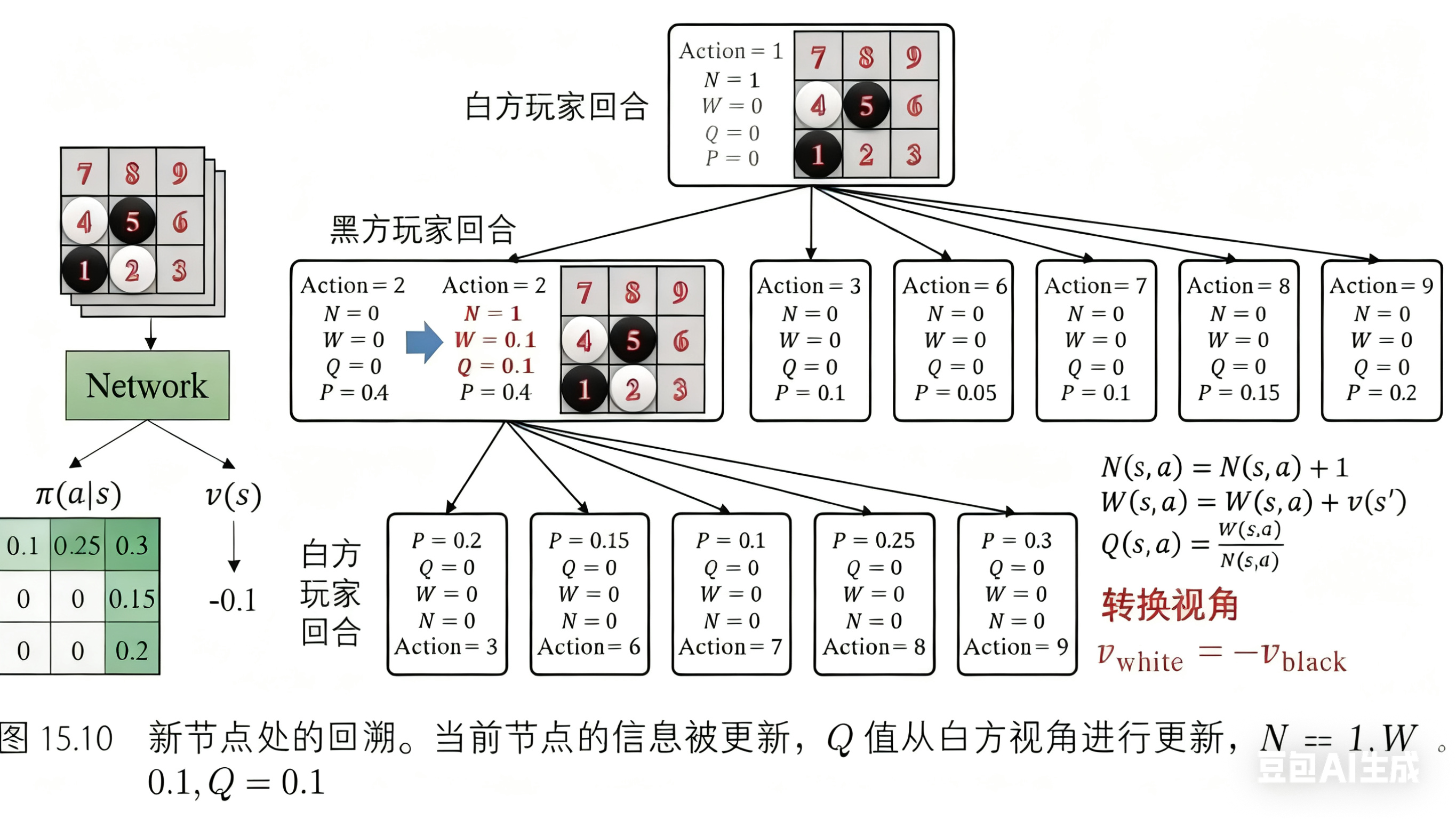
现在轮到回溯操作了。此时树里有两个节点,我们首先更新当前节点,然后更新前一个节点。这两个节点的更新遵值得注意的是,树中有两个视角:黑方视角和白方视角。我们需要注意更新的视角,并且总是以当前玩家的视角更新值。例如,在图 15.10 中,价值网络的估值 v(s) = −0.1,这是从黑方玩家的角度来看的。当更新属于白方玩家的信息时需要取反,即 v(s) = 0.1。所以,我们得 到 N = 1, W = 0.1, Q = 0.1。
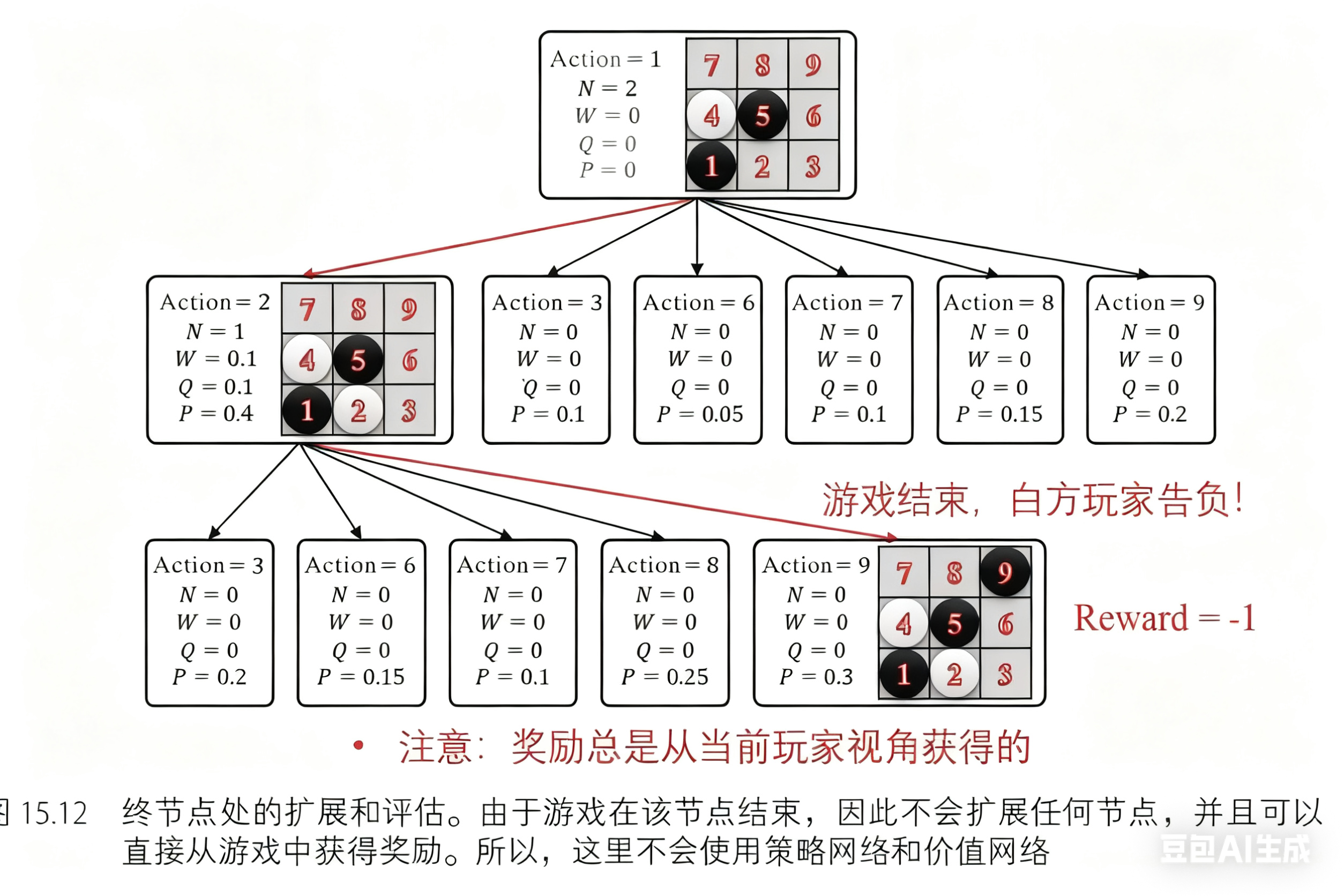
第三次树搜索过程也从根节点开始。根据公式 𝑎=argmax𝑎(𝑄(𝑠,𝑎)+𝑈(𝑠,𝑎)) 和当前树中的信息,白方玩家选择动作 2(𝑤,2) ,黑方玩家选择动作 9(𝑏,9) 。如图 15.12 所示,经过选择步骤后,游戏到达了终止状态。这次对于扩展和评估步骤,节点将不会被扩展,同时可以直接从游戏中获取价值 𝑣 。因此,价值网络不会用来估计状态价值,策略网络也不会输出动作概率。
接下来是回溯,且轨迹上有三个节点。如前所述,节点从叶节点递归更新直到根节点,其中 𝑁(𝑠,𝑎)=𝑁(𝑠,𝑎)+1 , 𝑊(𝑠,𝑎)=𝑊(𝑠,𝑎)+𝑣 , 𝑄(𝑠,𝑎)=𝑊(𝑠,𝑎)𝑁(𝑠,𝑎) 。此外,还应该切换每个节点的 视角,这意味着 𝑣𝑤ℎ𝑖𝑡𝑒=−𝑣𝑏𝑙𝑎𝑐𝑘 。在这个游戏中,黑方玩家选择动作 9(𝑏,9) 并到达一个新节点。 现在本该轮到白方玩家选择动作,但遗憾的是游戏在此结束了,白方玩家输掉了游戏。所以奖励值 𝑟𝑒𝑤𝑎𝑟𝑑=−1 是从白方玩家的视角来看的,也就是说 𝑣𝑤ℎ𝑖𝑡𝑒=−1 。当我们更新这个节点上的信息时,如前所述,这些信息是被黑方玩家用来选择动作 𝐴=9 并到达这个节点,所以这个节点的值应该是 𝑣𝑏𝑙𝑎𝑐𝑘=−𝑣𝑤ℎ𝑖𝑡𝑒=1 ,其他信息同理,有 𝑁=1 , 𝑊=1 , 𝑄=1 。剩余两个节点的信息也以同样的方式更新。
在完成回溯步骤之后,树结构如图 15.13 所示。根节点已被访问三次,并且每个被访问过的节点信息都已更新。
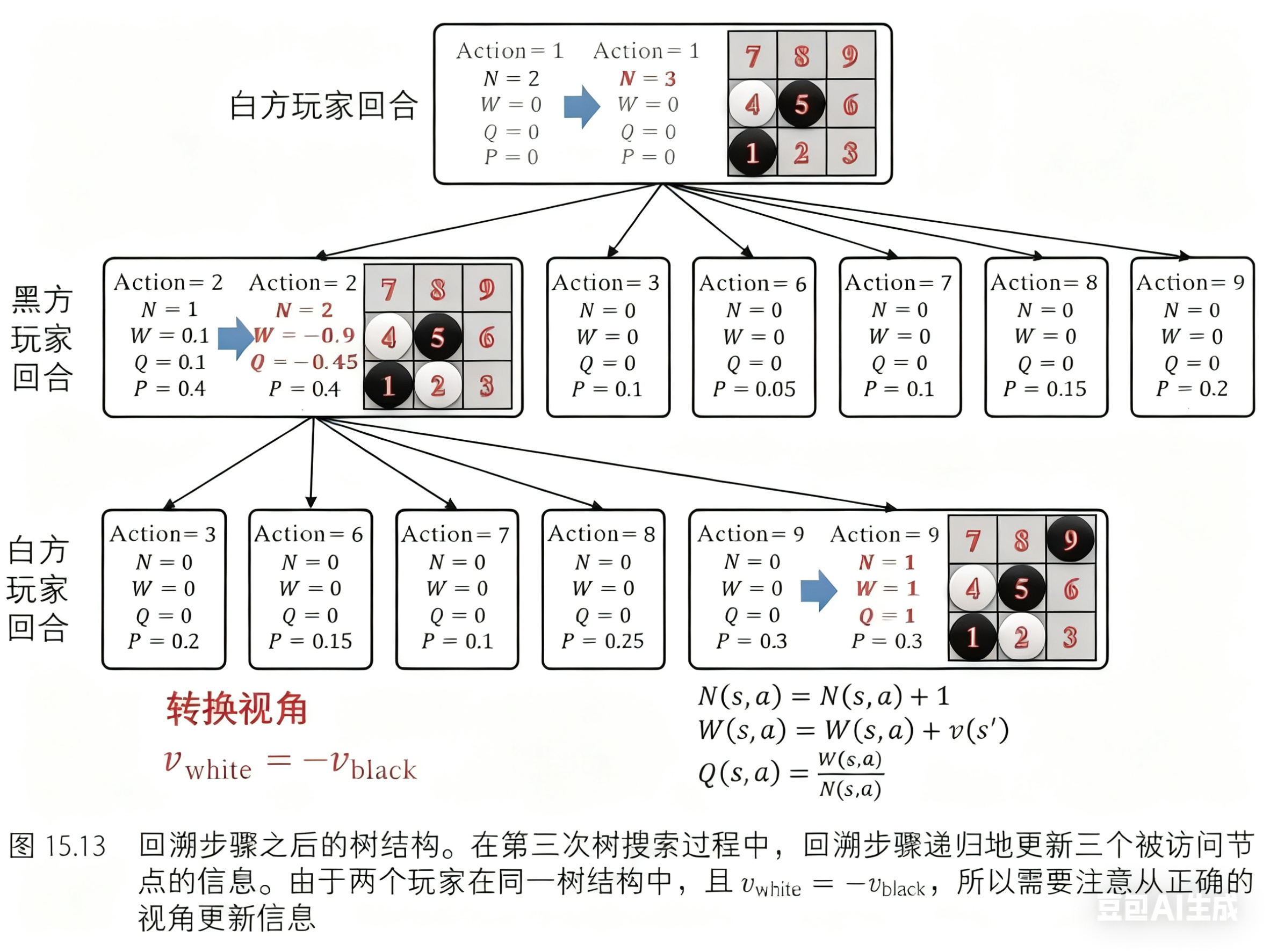
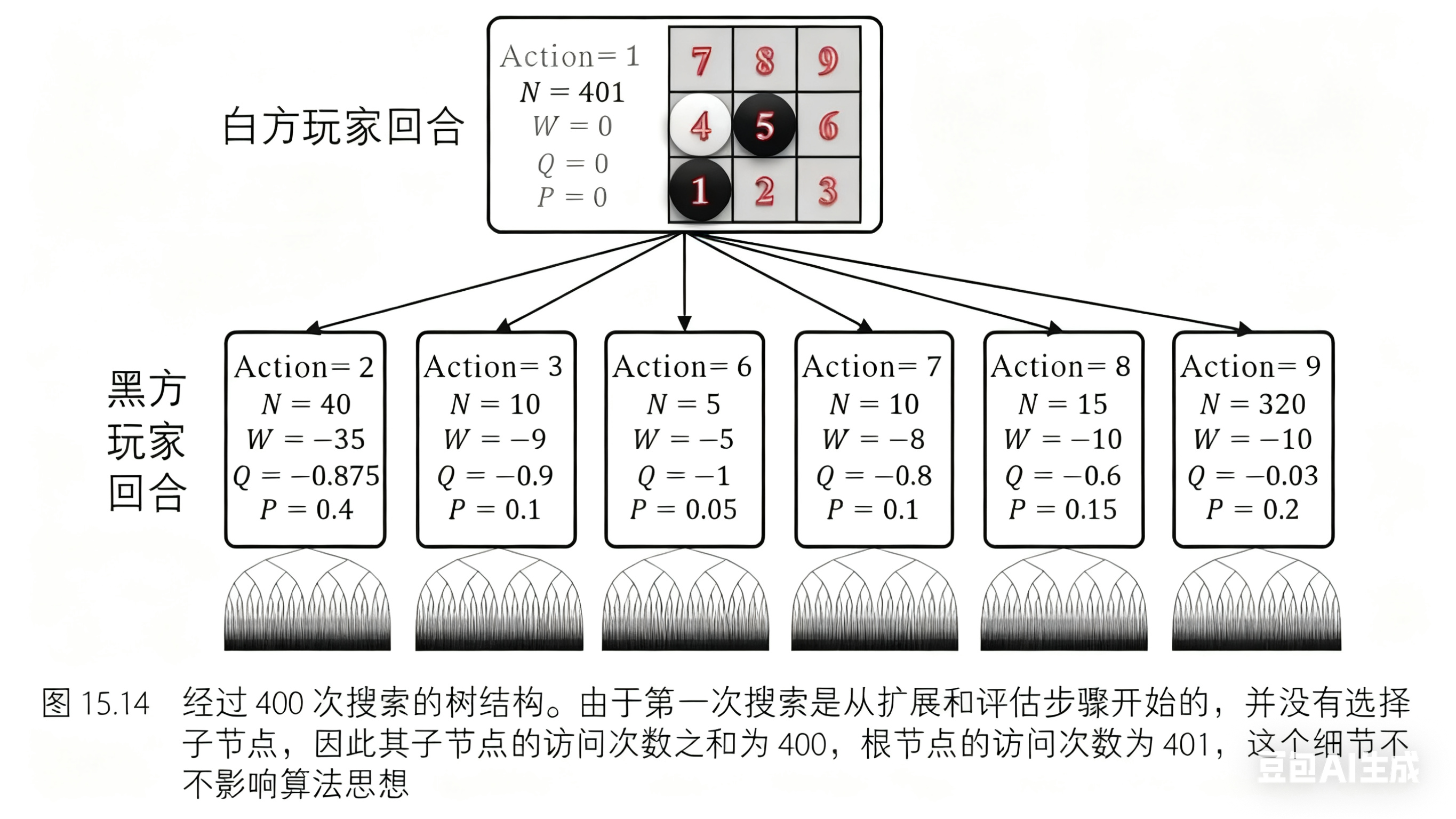
我们已经演示了三次蒙特卡罗树搜索的迭代过程。经过 400 次搜索后(在 AlphaGo Zero 算法中,搜索次数是 1600;在 AlphaZero 算法中,搜索次数是 800,如图 15.14 所示),树结构变得更大,且估值更加精确。
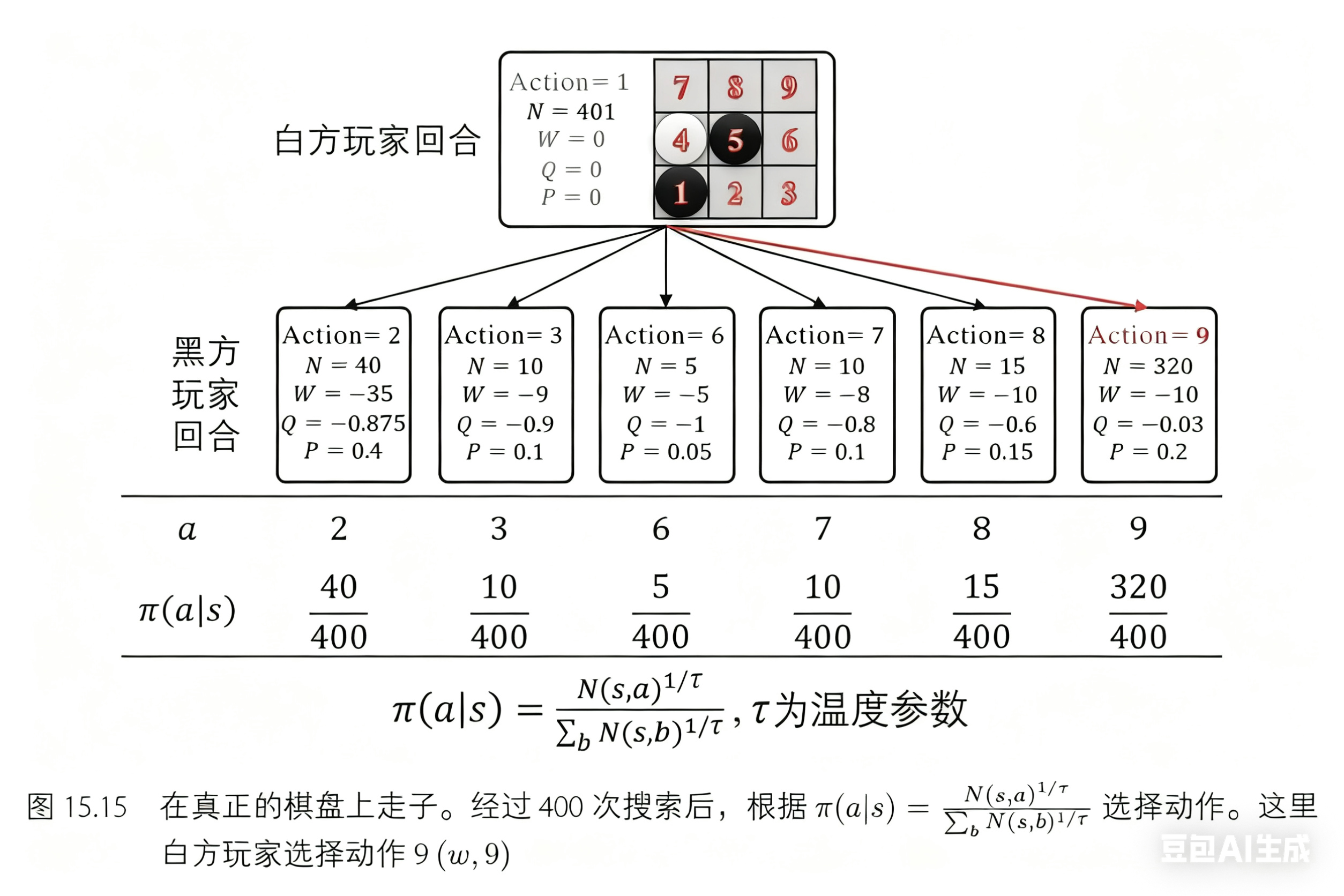
经过树搜索过程之后,可以在真正的棋盘上走子了。动作的选取通过计算每个动作的访问次数并归一化为概率进行选择,而不是直接通过策略网络输出动作概率: 𝜋(𝑎|𝑠)=𝑁(𝑠,𝑎)1/𝜏𝑁(𝑠)1/𝜏−1=𝑁(𝑠,𝑎)1/𝜏∑𝑏𝑁(𝑠,𝑏)1/𝜏 ,其中 𝜏→0 是温度参数, 𝑏∈𝐴 表示状态 𝑠 下的可行动作。这里选择的动作是 9(𝑤,9) ,如图 15.15 所示。温度参数用来控制探索度。若 𝜏=1 ,动作的选择概率和访问次数成正比,则这种方式探索度高,可以确保数据收集的多样性。若 𝜏→0 ,则探索度低,此时倾向于选择访问次数最大的动作。在 AlphaZero 和 AlphaGo Zero 算法中,当执行自博弈过程收集数据时,前 30 步的温度参数设为 𝜏=1 ,其余部分设置为 𝜏→0 。当与真正对手下棋时,温度参数始终设置为 𝜏→0 ,即每次都选择最优动作。
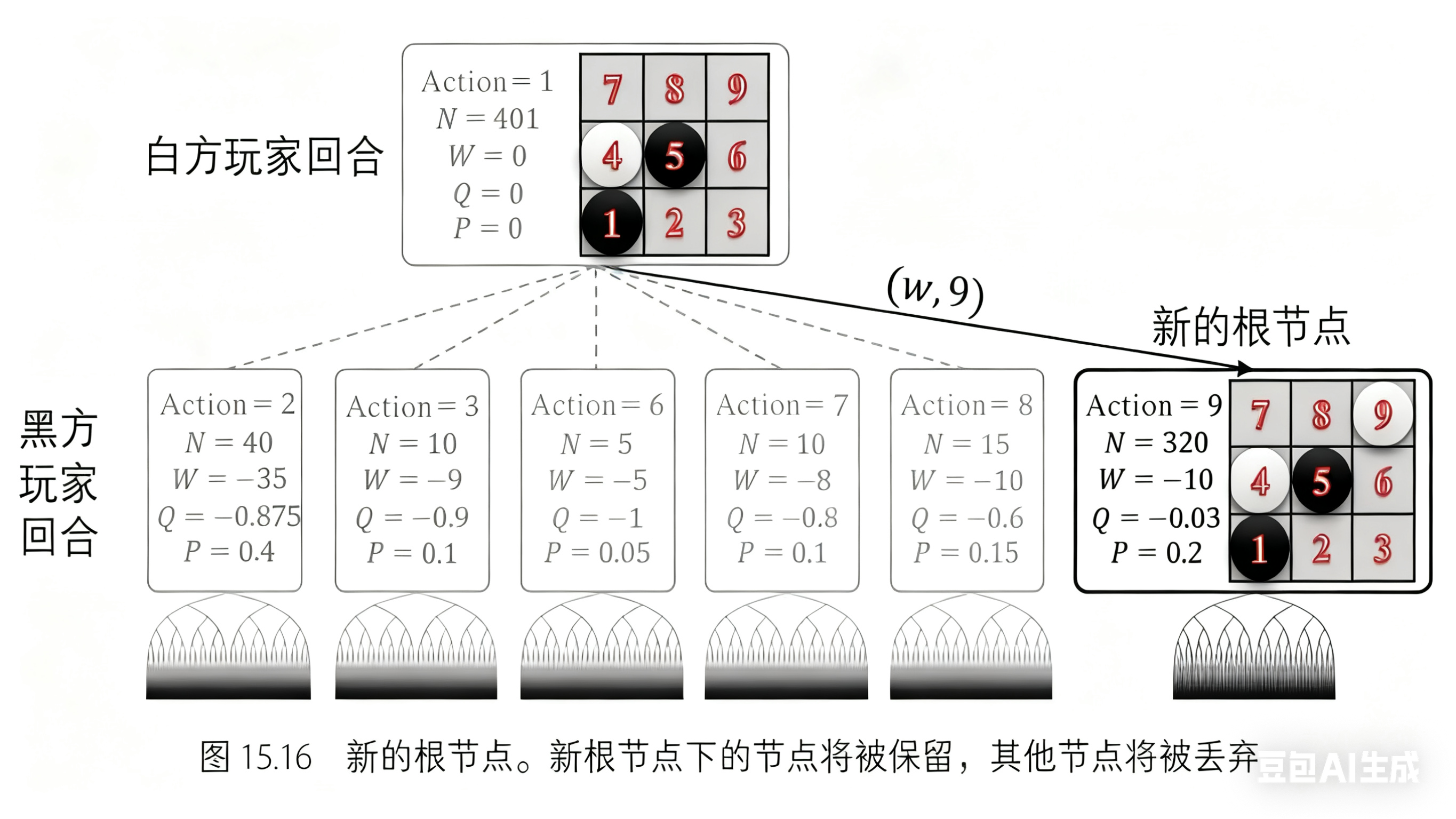
至此,位置 9 处已经放置了白方棋子,因此树中的根节点将被更改。如图 15.16 所示,蒙特卡罗树搜索将从新的根节点继续。其他兄弟节点及其父节点将被剪枝丢弃以节省内存。
整个过程一直重复下去,直到一局游戏结束。我们得到数据和结果如图 15.17 所示。
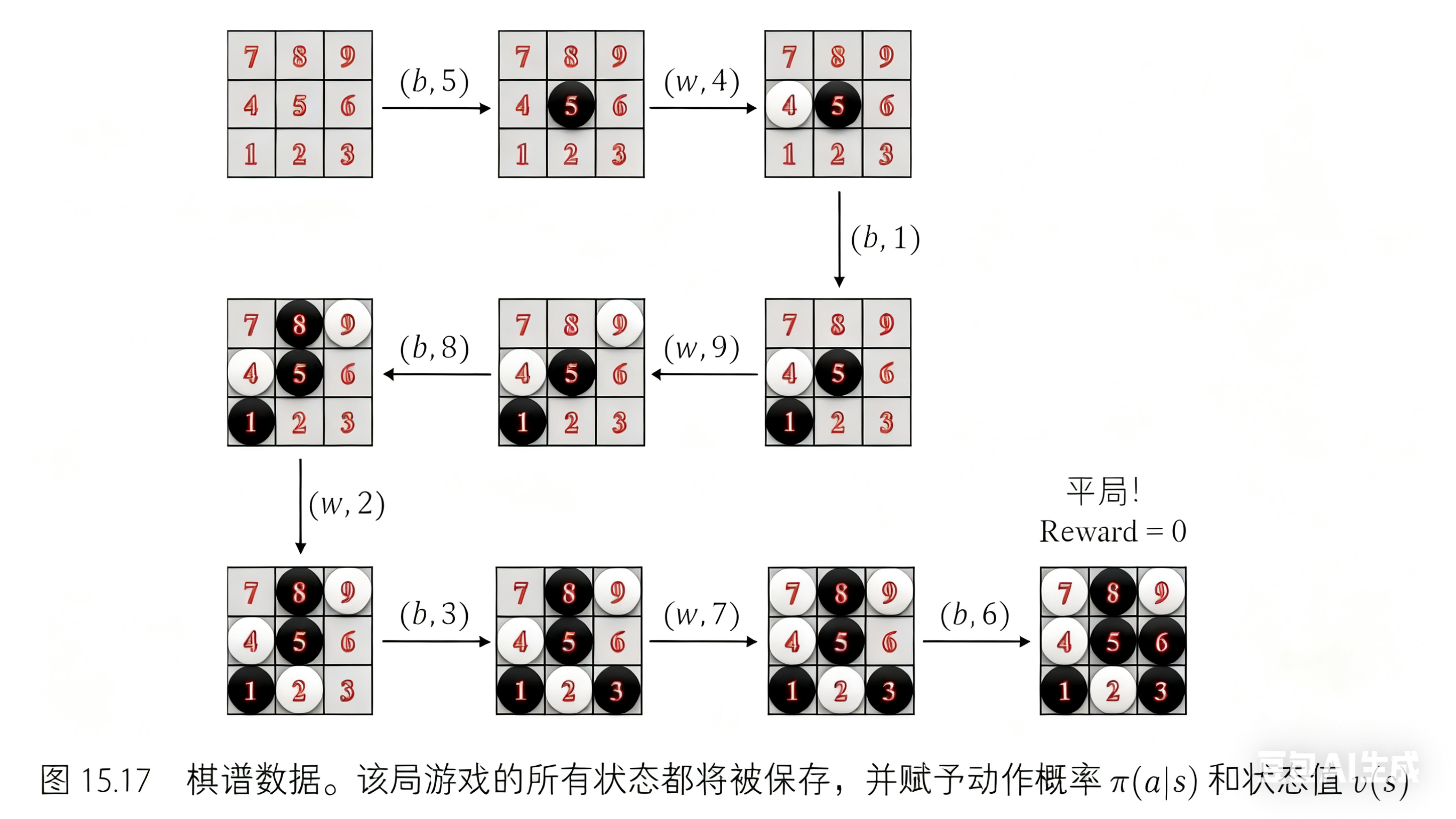
现在我们已经有了蒙特卡罗树搜索生成的数据,下一步就是利用深度神经网络进行训练。在训练过程中,首先将数据转换成堆叠的特征层。每个特征层只包含 0-1 值用以表示玩家的落子,其中一组特征层表示当前玩家的落子,另一组特征层表示对手的落子。这些特征层按照历史动作序列顺序堆叠。
我们使用 ResNet[4]作为网络结构,这和 AlphaGo Zero 算法相同。 网络的输入是前述构造的状态特征 𝑠 ,输出是动作概率 𝑝 和状态值 𝑣 ,网络可以表示为 (𝑝,𝑣)=𝑓𝜃(𝑠)
五、项目完整代码及详细注解
1.Game.py
"""
五子棋游戏类 - AlphaZero项目核心游戏逻辑
实现五子棋的基本游戏规则,包括落子、胜负判断、状态表示等功能
"""
import torch
import numpy as np
# 四个方向的向量:(右,下,右下,左下) - 用于检测五子连珠
vecs = [(1,0),(0,1),(1,1),(1,-1)]
class Game():
"""五子棋游戏类"""
size = 9 # 棋盘大小 9x9
win_num = 5 # 胜利条件:连续5个子
def __init__(self):
"""
初始化游戏棋盘
p_num: 已下棋子数量
board: 9x9的棋盘矩阵,0=空位,1=玩家1,2=玩家2
"""
self.p_num = 0 # 已经下了几个棋子
self.board = np.zeros((self.size,self.size))
def put(self,i:int,j:int,sym:int) -> tuple[bool,int]:
"""
在指定位置落子
Args:
i,j: 棋盘坐标 (行,列)
sym: 棋子类型 (1或2)
Returns:
tuple[bool,int]: (是否放置成功, 游戏状态)
- 游戏状态: 0=未完成, 1=当前玩家胜利, 2=平局
"""
# 检查位置是否合法且为空
if not Game.legal_index(i,j) or not self.board[i][j] == 0:
return False,0
# 落子
self.board[i][j] = sym
self.p_num += 1
# 检查四个方向是否有五子连珠
for vec in vecs:
num = 1 # 当前方向连续棋子数
# 向正方向检查
ii = i+vec[0]
jj = j+vec[1]
while Game.legal_index(ii,jj) and self.board[ii][jj] == sym:
num += 1
ii += vec[0]
jj += vec[1]
# 向负方向检查
ii = i-vec[0]
jj = j-vec[1]
while Game.legal_index(ii,jj) and self.board[ii][jj] == sym:
num += 1
ii -= vec[0]
jj -= vec[1]
# 如果达到胜利条件
if num >= Game.win_num:
return True,1
# 检查是否平局(棋盘已满)
return (True,2) if self.p_num >= Game.size**2 else (True,0)
def clone(self) -> "Game":
"""
深拷贝游戏状态,用于MCTS模拟
Returns:
Game: 新的游戏实例,状态与当前游戏相同
"""
g = Game()
g.p_num = self.p_num
g.board = np.copy(self.board)
return g
def get_state(self,sym:int,flag=True) -> torch.tensor:
"""
将棋盘状态转换为神经网络输入格式
Args:
sym: 当前玩家编号 (1或2)
flag: 是否添加batch维度
Returns:
torch.tensor: 形状为[1,2,9,9]或[2,9,9]的张量
- 通道0: 当前玩家的棋子位置
- 通道1: 对手的棋子位置
"""
out = torch.zeros(2, Game.size, Game.size, dtype=torch.float)
for i in range(Game.size):
for j in range(Game.size):
p = self.board[i][j]
if p == 0:
continue
index = 0 if p == sym else 1 # 0=自己的棋子,1=对手的棋子
out[index][i][j] = 1
if flag:
out = out.unsqueeze(0) # 添加batch维度
return out
@staticmethod
def legal_index(i:int,j:int)->bool:
"""
检查坐标是否在棋盘范围内
Args:
i,j: 坐标
Returns:
bool: 坐标是否合法
"""
return i < Game.size and i >= 0 and j >= 0 and j < Game.size
def __repr__(self):
"""
打印棋盘状态(用于调试)
Returns:
str: 格式化的棋盘字符串
"""
out = "\n"
for i in self.board:
for j in i:
out += f"{int(j)}"
out+="\n"
return out+"\n"
2.net.py
"""
AlphaZero神经网络模型 - 实现策略网络和价值网络的结合
包含残差块、策略头、价值头以及AlphaZero节点的MCTS实现
"""
import torch
from Game import Game
from MCTS.Tree import Node
import math
import random
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import json
use_noise = True # 是否使用噪声进行探索
class ResidualBlock(nn.Module):
"""残差块 - 用于构建深层网络,解决梯度消失问题"""
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(channels)
def forward(self, x):
"""
残差连接前向传播
Args:
x: 输入张量
Returns:
torch.tensor: 残差连接后的输出
"""
identity = x # 保存原始输入
out = self.bn1(self.conv1(x)) # 卷积+批归一化
out += identity # 残差连接
return F.relu(out) # ReLU激活
class Alpha0_Module(torch.nn.Module):
"""
AlphaZero神经网络模型
结合策略网络和价值网络,输入棋盘状态,输出策略分布和局面价值
"""
def __init__(self):
super(Alpha0_Module, self).__init__()
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 主干网络 - 特征提取
self.conv1 = nn.Conv2d(2, 64, kernel_size=3, padding=1) # 输入2通道,输出64通道
self.res1 = ResidualBlock(64) # 残差块1
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1) # 64->128通道
self.res2 = ResidualBlock(128) # 残差块2
# 策略头 - 输出每个位置的落子概率
self.policy_conv = nn.Conv2d(128, 1, kernel_size=1) # 输出[B, 1, H, W]
# 价值头 - 输出局面的价值评估
self.value_fc1 = nn.Linear(128, 128) # 全连接层1
self.value_fc2 = nn.Linear(128, 1) # 全连接层2,输出标量价值
self.relu = nn.ReLU()
self.criterion = torch.nn.MSELoss() # 损失函数
self.optimizer = torch.optim.Adam(self.parameters(), 0.001) # 优化器
# 尝试加载预训练模型
try:
self.load_state_dict(torch.load("model.pth"))
print("成功加载模型")
except Exception as e:
print(f"未加载数据,原因:{e}")
# 经验回放缓冲区 - 存储训练数据
self.buffers = [] # 缓冲区列表
self.buffersize = 50000 # 缓冲区最大容量
self.bufferpointer = 0 # 当前写入位置
self.to(self.device) # 将模型移动到指定设备
# 尝试加载历史训练数据
try:
for i in range(1, 2):
path = f"data/d{i}.json"
with open(path, "r", encoding="utf-8") as f:
data = json.load(f)
self.buffers.extend(data)
self.bufferpointer = len(self.buffers)
# 如果数据超过缓冲区大小,保留最新的数据
if len(self.buffers) >= self.buffersize:
self.buffers = self.buffers[len(self.buffers) - self.buffersize : self.buffersize]
self.bufferpointer = 0
print(f"已加载{len(self.buffers)}条数据")
except Exception as e:
print(f"未加载数据,原因:{e}")
def forward(self, x):
"""
前向传播
Args:
x: 输入张量,形状为[B, 2, 9, 9],表示棋盘状态
Returns:
tuple: (policy_logits, value)
- policy_logits: 策略分布,形状[B, 81],每个位置的概率
- value: 局面价值,形状[B, 1],[-1,1]范围
"""
x = x.to(self.device)
self.to(self.device)
# 主干网络特征提取
x = self.relu(self.conv1(x)) # 2->64通道
x = self.res1(x) # 残差块1
x = self.relu(self.conv2(x)) # 64->128通道
x = self.res2(x) # 残差块2
# 策略头 - 输出每个位置的落子概率
p = self.policy_conv(x) # [B, 1, 9, 9]
policy_logits = p.view(p.size(0), -1) # [B, 81]
# 价值头 - 输出局面价值评估
v = F.adaptive_avg_pool2d(x, (1, 1)) # 全局平均池化 [B, 128, 1, 1]
v = v.view(v.size(0), -1) # [B, 128]
v = self.relu(self.value_fc1(v)) # 全连接层1
value = torch.tanh(self.value_fc2(v)) # 全连接层2,输出[-1,1]范围
return policy_logits, value
def train_model(self, epochs: int):
"""
训练神经网络模型
Args:
epochs: 训练轮数
"""
self.to(self.device) # 确保模型在指定设备
self.train()
for epoch in range(epochs):
# 从经验回放缓冲区随机采样一个批次
batch = random.sample(self.buffers, min(128, len(self.buffers)))
states, target_policies, target_values = [], [], []
# 随机数据增强参数
n = int(random.random()*3) # 旋转角度
n1 = random.random() # 翻转概率
for data in batch:
# 转换数据格式
state = torch.tensor(data["state"], dtype=torch.float32).view(2, Game.size, Game.size) # [2,9,9]
policy = torch.tensor(data["search_rate"], dtype=torch.float32) # [9,9]
# 数据增强 - 旋转和翻转增加数据多样性
state = torch.rot90(state, k=n, dims=(1, 2)) # 旋转
policy = torch.rot90(policy, k=n, dims=(0, 1))
if n1 < 0.5: # 50%概率翻转
state = torch.flip(state, dims=[2])
policy = torch.flip(policy, dims=[1])
states.append(state)
target_policies.append(policy.reshape(-1)) # 展平为81维
target_values.append(torch.tensor(data["win_rate"], dtype=torch.float32))
# 转换为张量并移动到设备
states = torch.stack(states).to(self.device)
target_policies = torch.stack(target_policies).to(self.device)
target_values = torch.stack(target_values).unsqueeze(-1).to(self.device)
# 前向传播
policy_logits, values = self(states)
# 计算损失函数
policy_loss = -(target_policies * F.log_softmax(policy_logits, dim=1)).sum(dim=1).mean() # 交叉熵损失
value_loss = F.mse_loss(values, target_values) # 均方误差损失
loss = policy_loss + 0.4 * value_loss # 总损失
# 反向传播和参数更新
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 定期打印训练进度
if epoch % 200 == 0:
print(f"Epoch: {epoch}, Loss: {loss.item():.4f}, "
f"Policy: {policy_loss.item():.4f}, Value: {value_loss.item():.4f}")
# 保存模型并清理
self.to("cpu")
torch.save(self.state_dict(), "model.pth")
print("模型已保存")
torch.cuda.empty_cache() # 清理GPU缓存
self.eval()
def add_buffer(self, data):
"""
向经验回放缓冲区添加数据
Args:
data: 训练数据,包含state、search_rate、win_rate
"""
if len(self.buffers) < self.buffersize:
self.buffers.append(data)
else:
# 缓冲区已满,使用循环覆盖
self.buffers[self.bufferpointer] = data
self.bufferpointer = (self.bufferpointer + 1) % self.buffersize
# 全局模型实例
model = Alpha0_Module()
class Alpha0_Node(Node):
"""
AlphaZero MCTS节点
继承自基础Node类,添加神经网络评估和策略选择功能
"""
def __init__(self, i: int, j: int, sym: int, game: Game):
"""
初始化AlphaZero节点
Args:
i, j: 棋盘坐标
sym: 当前玩家编号
game: 游戏状态
"""
super().__init__()
self.i, self.j, self.sym = i, j, sym
self.game: Game = game.clone()
self.end = 0 # 游戏结束状态:0=继续,1=输,2=平,3=赢
self.model = model
# 如果不是根节点,执行落子
if self.i is not None:
_, self.end = self.game.put(self.i, self.j, 3-self.sym)
# 根节点需要神经网络评估
if self.fnode == None:
with torch.no_grad():
state = self.game.get_state(self.sym).to(self.model.device)
self.policy_out, self.value_out = self.model(state)
self.policy_out = self.policy_out[0]
self.value_out = self.value_out.item()
# 屏蔽已占用位置
for i in range(Game.size):
for j in range(Game.size):
if not self.game.board[i][j] == 0:
self.policy_out[i*Game.size+j] = -1e9
self.policy_out = F.softmax(self.policy_out, dim=-1).cpu().numpy()
def init_Nodes(self) -> int:
"""
初始化子节点,使用神经网络批量评估所有可能的落子位置
Returns:
int: 子节点数量
"""
# 如果游戏已结束,无需初始化子节点
if not self.end == 0:
return 0
# 如果已经初始化过,直接返回
if not len(self.nodes) == 0:
return len(self.nodes)
states = []
# 为每个空位置创建子节点
for i in range(Game.size):
for j in range(Game.size):
if self.game.board[i][j] == 0:
node = Alpha0_Node(i, j, 3-self.sym, self.game)
node.fnode = self
self.nodes.append(node)
self.unsearch_nodes.append(node)
# 如果子节点直接获胜,当前节点获胜
if node.end == 1:
node.value_out = -1
self.end = 3
self.value_out = 1
return 0
states.append(node.game.get_state(node.sym, False))
# 批量神经网络评估
with torch.no_grad():
states = torch.stack(states).float().to(self.model.device)
policy, value = self.model.forward(states)
# 创建掩码,屏蔽已占用位置
masks = []
for node in self.nodes:
mask = torch.from_numpy(node.game.board.flatten() != 0)
masks.append(mask)
masks = torch.stack(masks).to(dtype=torch.bool, device=model.device)
# 应用掩码并计算softmax
policy[masks] = -1e9
policy = F.softmax(policy, dim=-1)
policy = policy.cpu().numpy()
value = value.cpu().squeeze(-1).numpy()
# 将评估结果分配给子节点
for i in range(len(self.nodes)):
self.nodes[i].policy_out = policy[i]
self.nodes[i].value_out = float(value[i])
self.nodes[i].cal_model_out()
return len(self.nodes)
def cal_model_out(self):
"""
计算模型输出,处理游戏结束状态
"""
if self.end == 1: # 如果对手获胜,当前节点价值为-1
self.value_out = -1
elif self.end == 2: # 平局,价值为0
self.value_out = 0
def random_play(self) -> float:
"""
随机游戏模拟,返回神经网络评估的价值
Returns:
float: 当前局面的价值评估
"""
return self.value_out
def get_node(self):
"""
使用UCT算法选择最优子节点进行扩展
Returns:
Alpha0_Node: 选择的子节点
"""
win_rates = np.array([-n.get_win_rate() for n in self.nodes], dtype=np.float32)
nums = np.array([n.num for n in self.nodes], dtype=np.float32)
idxs = np.array([n.i * Game.size + n.j for n in self.nodes], dtype=np.int32)
priors = self.policy_out[idxs]
# UCT公式:Q(s,a) + c * P(s,a) * sqrt(N(s)) / (1 + N(s,a))
uct = win_rates + self.c * priors * math.sqrt(self.num) / (1.0 + nums)
best_idx = np.argmax(uct)
return self.nodes[best_idx]
def get_action(self, tau: float = 1):
"""
根据访问次数选择行动
Args:
tau: 温度参数,控制探索程度
- tau=0: 贪心选择(访问次数最多)
- tau>0: 温度采样
Returns:
Alpha0_Node: 选择的行动节点
"""
counts = np.array([node.num for node in self.nodes], dtype=np.float32)
if tau == 0:
# 贪心:选择访问次数最多的
idx = np.argmax(counts)
else:
# 温度采样:根据访问次数分布采样
probs = counts ** (1.0 / tau)
probs /= probs.sum()
idx = np.random.choice(len(self.nodes), p=probs)
return self.nodes[idx]
def __repr__(self):
"""
打印节点信息,用于调试和分析
Returns:
str: 格式化的节点信息,包括模型胜率、探索胜率、探索次数
"""
out = "\n"
# 打印神经网络评估的胜率
out += "子节点模型胜率:\n"
win_rate = [[0.00 for _ in range(Game.size)] for _ in range(Game.size)]
for node in self.nodes:
win_rate[node.i][node.j] = -node.value_out
for vec in win_rate:
for i in vec:
out += f"{i:.2f} "
out += "\n"
# 打印MCTS探索得出的胜率
out += "子节点探索胜率:\n"
win_rate = [[0.00 for _ in range(Game.size)] for _ in range(Game.size)]
for node in self.nodes:
win_rate[node.i][node.j] = -node.get_win_rate()
for vec in win_rate:
for i in vec:
out += f"{i:.2f} "
out += "\n"
# 打印每个位置的探索次数
out += "子节点探索次数:\n"
nums = [[0 for _ in range(Game.size)] for _ in range(Game.size)]
for node in self.nodes:
nums[node.i][node.j] = node.num
for vec in nums:
for i in vec:
out += f"{i} "
out += "\n"
out += "\n"
return out
if __name__ == "__main__":
# 直接训练模型
model.train_model(5000)
3.train.py
"""
AlphaZero训练模块
实现自我对弈生成训练数据,并进行神经网络训练
"""
from Game import Game
from net import Alpha0_Node
import net as net
import json
import numpy as np
def one_game(show: bool):
"""
进行一局完整的自我对弈,生成训练数据
Args:
show: 是否显示游戏过程
"""
# 初始化游戏,黑子先手,在中心落子
game = Game()
game.put(4, 4, 2) # 在中心(4,4)放置黑子
# 存储两个玩家的训练数据
buffer = [[], []]
sym = 1 # 当前玩家:1=白子,2=黑子
end = False
step = 0
while not end:
step += 1
# 创建MCTS搜索树
tree = Alpha0_Node(None, None, sym, game)
tree.init_Nodes()
# 进行300次MCTS模拟
for i in range(300):
tree.update()
# 计算搜索策略分布(访问次数归一化)
search_rate = np.zeros((Game.size, Game.size))
for node in tree.nodes:
search_rate[node.i][node.j] = node.num / tree.num
# 保存训练数据:当前状态、搜索策略、胜率
buffer[sym - 1].append({
"state": game.get_state(tree.sym).tolist(),
"search_rate": search_rate.tolist(),
"win_rate": tree.get_win_rate()
})
# 前5步使用温度采样,之后使用贪心策略
t = 0 if step > 5 else 1
# 根据策略选择行动
node = tree.get_action(t)
i, j = node.i, node.j
# 执行落子
_, end = game.put(i, j, tree.sym)
# 切换玩家
sym = 3 - sym
# 添加终局数据
buffer[sym - 1].append({
"state": game.get_state(sym).tolist(),
"search_rate": np.zeros((Game.size, Game.size)).tolist(),
"win_rate": -1 if end == 1 else 0 # 对手赢了为-1,平局为0
})
# 如果有玩家获胜,更新奖励
if end == 1:
win = 3 - sym # 获胜玩家(sym在游戏结束后会切换,需要反转)
print(f"玩家{win}获胜")
# 为获胜者的历史状态分配正向奖励(时间衰减)
reward = 1
for i in range(len(buffer[win-1])-1, -1, -1):
buffer[win-1][i]["win_rate"] += reward
reward *= 0.6 # 时间衰减因子
reward = max(0.2, reward) # 最小奖励
buffer[win-1][i]["win_rate"] = min(1, buffer[win-1][i]["win_rate"])
# 为失败者的历史状态分配负向奖励
reward = 1
for i in range(len(buffer[sym-1])-1, -1, -1):
buffer[sym-1][i]["win_rate"] -= reward
reward *= 0.6
reward = max(0.2, reward)
buffer[sym-1][i]["win_rate"] = max(-1, buffer[sym-1][i]["win_rate"])
# 将所有训练数据添加到模型的缓冲区
for i in buffer:
for j in i:
net.model.add_buffer(j)
if __name__ == "__main__":
"""
主训练循环
进行100,000局自我对弈,定期训练模型并保存数据
"""
for i in range(100000):
print(f"第{i}局")
show = True if i % 10 == 0 else False # 每10局显示一次
one_game(show) # 进行一局自我对弈
# 每10局训练一次模型(前10局不训练,因为数据不足)
if i >= 10 and i % 10 == 0:
net.model.train_model(2000) # 训练2000个epoch
# 每300局保存一次训练数据
if i % 300 == 0 and i > 0:
with open("data/d1.json", "w", encoding="utf-8") as f:
json.dump(net.model.buffers, f, ensure_ascii=False, indent=4)4.main.py
"""
AlphaZero五子棋游戏主界面
实现人机对弈界面,显示游戏状态、神经网络评估、MCTS搜索统计等信息
"""
from net import Alpha0_Node
from Game import Game
import pygame
# 界面配置参数
cell_size = 35 # 棋盘格子大小
eage = 20 # 边界大小
black = (0, 0, 0) # 黑色
white = (255, 255, 255) # 白色
brown = (222, 184, 135) # 棕色(棋盘背景)
# 初始化pygame
pygame.init()
font = pygame.font.Font(None, 20)
screen = pygame.display.set_mode((cell_size*Game.size*2 + 3 * eage, cell_size*Game.size*2 + 3 * eage))
pygame.display.set_caption("AlphaZero五子棋")
# 四个显示区域的偏移量:(左上,右上,左下,右下)
bias = [(eage, eage), (eage*2+cell_size*Game.size, eage),
(eage, eage*2+cell_size*Game.size), (eage*2+cell_size*Game.size, eage*2+cell_size*Game.size)]
# 四个区域的标题
text = ["board", "value_out", "search_num", "policy_out"]
def draw_area(sym: int, game: Game, node: Alpha0_Node):
"""
绘制游戏界面的一个区域
Args:
sym: 区域编号 (0=棋盘, 1=价值评估, 2=搜索次数, 3=策略分布)
game: 游戏状态
node: MCTS节点
"""
# 绘制棋盘背景
pygame.draw.rect(screen, brown, (bias[sym][0], bias[sym][1], cell_size*Game.size, cell_size*Game.size))
# 绘制横线
for i in range(0, Game.size+1):
pygame.draw.line(screen, black,
(0+bias[sym][0], i*cell_size+bias[sym][1]),
(cell_size*Game.size+bias[sym][0], i*cell_size+bias[sym][1]), 3)
# 绘制竖线
for i in range(0, Game.size+1):
pygame.draw.line(screen, black,
(i*cell_size+bias[sym][0], 0+bias[sym][1]),
(i*cell_size+bias[sym][0], cell_size*Game.size+bias[sym][1]), 3)
# 绘制区域标题
text_surface = font.render(text[sym], True, black)
screen.blit(text_surface, (bias[sym][0]+0.2*Game.size*cell_size, bias[sym][1]-eage+4))
# 绘制棋子
for i in range(Game.size):
for j in range(Game.size):
if game.board[i][j] == 0:
continue
else:
color = white if game.board[i][j] == 1 else black
pygame.draw.circle(screen, color,
(bias[sym][0] + 0.5*cell_size + i*cell_size,
bias[sym][1] + 0.5*cell_size + j*cell_size), 13)
# 绘制数值信息(非棋盘区域)
if sym == 0:
return
for n in node.nodes:
value = 0
i, j = n.i, n.j
if sym == 1:
# 显示神经网络评估的价值
value = float(f"{-n.value_out:.2f}")
elif sym == 2:
# 显示MCTS搜索次数
value = n.num
else:
# 显示策略分布概率
value = float(f"{node.policy_out[i*Game.size + j]:.2f}")
text_surface = font.render(str(value), True, black)
screen.blit(text_surface, (bias[sym][0] + 0.1*cell_size + i*cell_size,
bias[sym][1] + 0.2*cell_size + j*cell_size))
def draw(game: Game, node: Alpha0_Node):
"""
绘制完整的游戏界面
Args:
game: 游戏状态
node: MCTS节点
"""
screen.fill((255, 255, 255)) # 白色背景
for i in range(4):
draw_area(i, game, node) # 绘制四个区域
def wait_click():
"""
等待用户鼠标点击
Returns:
tuple: 鼠标点击的坐标
"""
while True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
elif event.type == pygame.MOUSEBUTTONDOWN:
return event.pos
if __name__ == "__main__":
"""
主游戏循环 - 人机对弈
"""
# 初始化游戏状态
game = Game()
sym = 1 # 当前玩家:1=人类玩家,2=AI
end = 0 # 游戏结束标志
i, j = 0, 0 # 落子坐标
node = Alpha0_Node(None, None, sym, game) # 创建MCTS根节点
while True:
# 初始化子节点
node.init_Nodes()
# 进行500次MCTS模拟搜索
for i in range(500):
if i % 10 == 0: # 每10次更新一次界面
draw(game, node)
pygame.display.flip()
node.update()
# 显示最终搜索结果
draw(game, node)
pygame.display.flip()
if sym == 1: # 人类玩家回合
while True:
pos = wait_click() # 等待用户点击
# 将屏幕坐标转换为棋盘坐标
pos = (pos[0] - eage, pos[1] - eage)
i, j = int(pos[0]/cell_size), int(pos[1]/cell_size)
flag, end = game.put(i, j, sym)
if flag: # 落子成功
break
else: # AI回合
n = node.get_action(0) # 贪心选择最优行动
i, j = n.i, n.j
_, end = game.put(i, j, sym)
wait_click() # 等待用户点击继续
# 更新界面
draw(game, node)
pygame.display.flip()
# 切换玩家
sym = 3 - sym
# 在MCTS树中找到对应的子节点,如果没有则创建新的根节点
flag = True
for n in node.nodes:
if n.i == i and n.j == j:
node = n
flag = False
if flag:
node = Alpha0_Node(None, None, sym, game)
# 检查游戏是否结束
if not end == 0:
draw(game, node)
pygame.display.flip()
wait_click() # 等待用户点击退出
break
5.MCTS-Tree.py
"""
蒙特卡洛树搜索(MCTS)基础节点类
实现MCTS算法的核心功能:选择、扩展、模拟、回传
"""
from __future__ import annotations
import math
class Node():
"""
MCTS基础节点类
实现蒙特卡洛树搜索算法的核心逻辑
"""
def __init__(self):
self.num: int = 0 # 访问次数
self.nodes: list[Node] = [] # 子节点列表
self.unsearch_nodes: list[Node] = [] # 未探索的子节点
self.reward = 0 # 累计奖励
self.c = 0.3 # UCT探索常数
self.fnode: Node = None # 父节点引用
def init_Nodes(self) -> int:
"""
初始化子节点(基础实现,返回0)
子类需要重写此方法来实现具体的节点初始化逻辑
Returns:
int: 子节点数量
"""
return 0
def update(self) -> None:
"""
MCTS算法的核心更新方法
实现选择->扩展->模拟->回传的完整流程
"""
if not len(self.unsearch_nodes) == 0:
# 扩展:如果有未探索的节点,选择一个进行扩展
node = self.unsearch_nodes.pop()
reward = node.random_play() # 模拟
node.backward(reward) # 回传
else:
# 选择:选择最优子节点继续搜索
node: Node = self.get_node()
if(node.init_Nodes() == 0):
# 如果是叶节点,进行模拟
reward = node.random_play()
node.backward(reward)
else:
# 递归搜索子节点
node.update()
def get_win_rate(self) -> int:
"""
计算当前节点的胜率
Returns:
float: 胜率 = 累计奖励 / 访问次数
"""
if self.num == 0:
return 0
return self.reward/self.num
def random_play(self) -> float:
"""
随机游戏模拟(基础实现)
子类需要重写此方法来实现具体的游戏模拟逻辑
Returns:
float: 模拟结果奖励
"""
return 1
def get_node(self) -> Node:
"""
使用UCT算法选择最优子节点
Returns:
Node: 选择的子节点
"""
max, out = -999999, None
for node in self.nodes:
# UCT公式:Q(s,a) + c * sqrt(ln(N(s)) / N(s,a))
win_rate = -node.get_win_rate() # 注意:这里用负号,因为是对手的视角
value = win_rate + self.c * math.sqrt(math.log(self.num + 1) / (node.num + 1))
if value > max:
max = value
out = node
return out
def backward(self, reward: float) -> None:
"""
回传奖励,更新路径上所有节点的统计信息
Args:
reward: 模拟得到的奖励
"""
node = self
while node is not None:
node.num += 1 # 增加访问次数
node.reward += reward # 累加奖励
reward *= -1 # 奖励取反(因为是对手视角)
node = node.fnode # 移动到父节点
def get_action(self) -> Node:
"""
根据访问次数选择最优行动
Returns:
Node: 访问次数最多的子节点
"""
max, out = -1, None
for node in self.nodes:
if node.num >= max:
max = node.num
out = node
return out
6.预训练模型
我已将训练好的模型上传到百度网盘,各位小伙伴课自行下载,搭建起整个项目
通过网盘分享的文件:model.pth
链接: https://pan.baidu.com/s/1aM_l4sGcsEejI_fPP97DNA?pwd=c699 提取码: c699
六、效果展示
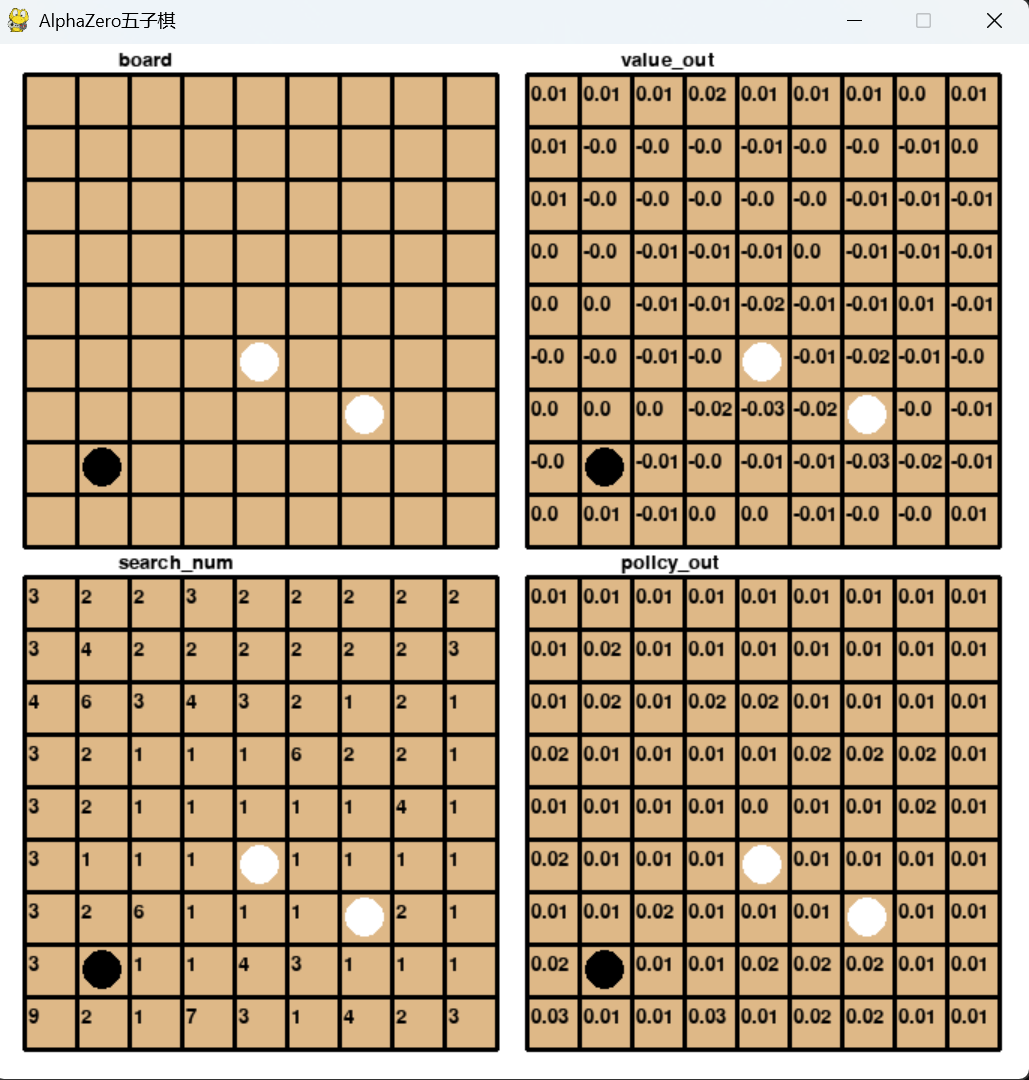
七、致谢
由于本人能力和时间关系,在《四、强化学习——AlaphaZero算法》中的《AlaphaZero》部分,直接引用了《强化学习之 Monte Carlo Tree Search 算法》文章的部分内容,特对该文章的作者表示非常感谢🙇!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)