[论文阅读] 人工智能 + 软件工程 | 4907个用户故事验证!SEEAgent:解决敏捷估计“黑箱+不协作”的终极方案
这篇论文提出了一款名为SEEAgent的LLM多智能体框架,专门解决敏捷开发中“工作量估计难”的痛点——比如团队用“规划扑克”主观猜点不准、传统ML模型给结果不给解释、还没法和人协作的问题。SEEAgent靠“长期记忆”(微调Llama-3.1或用GPT-4o-mini学项目知识,减少幻觉)、“短期记忆”(存会话和历史故事)、“行动+通信模块”(支持聊天解释和提交估计)实现“估计准、能唠、可解释”
4907个用户故事验证!SEEAgent:解决敏捷估计“黑箱+不协作”的终极方案
论文信息
- 论文原标题:SEEAgent: A LLM-based Multi-Agent Framework for Explainable and Collaborative Agile Software Effort Estimation
- 核心链接:论文PDF下载:https://arxiv.org/pdf/2509.14483
一段话总结
这篇论文提出了一款名为SEEAgent的LLM多智能体框架,专门解决敏捷开发中“工作量估计难”的痛点——比如团队用“规划扑克”主观猜点不准、传统ML模型给结果不给解释、还没法和人协作的问题。SEEAgent靠“长期记忆”(微调Llama-3.1或用GPT-4o-mini学项目知识,减少幻觉)、“短期记忆”(存会话和历史故事)、“行动+通信模块”(支持聊天解释和提交估计)实现“估计准、能唠、可解释”,还能装“前端/后端”角色。实验用4907个用户故事验证,微调版比Deep-SE等SOTA模型更准;12个从业者实测后,83%觉得协作自然,58%愿意信任推荐,最终给敏捷团队提供了“人机一起定方案”的新工具。
思维导图
研究背景:敏捷估计的“三大老大难”,你团队中过招吗?
咱们先聊个真实场景:你是敏捷团队的前端开发,每周迭代会用“规划扑克”估用户故事——比如“做一个商品收藏功能”,新人说1个点,老后端说5个点,产品经理急得拍桌子,最后取个中间值3,结果做的时候发现要对接3个接口,延期了2天。这就是敏捷估计的日常:不准、吵、没依据。
再说说“高科技方案”:有些团队用Deep-SE这种ML模型,把历史故事喂进去,模型直接输出“3个点”。但你问“为啥是3?”,模型答不上来——这就是“黑箱”;而且模型没法跟你讨论“要不要考虑兼容老版本”,最后团队还是不敢信,宁愿自己拍脑袋。
总结下行业的“三大痛点”:
- 主观估计太“盲”:靠经验、凭感觉,同个故事不同人估差好几倍,项目经常“计划赶不上变化”;
- AI模型太“冷”:只给结果不给解释,像医生只说“你病了”不说“为啥病”,团队不敢用;
- 人机协作太“难”:AI是AI,人是人,两者各干各的,没法一起讨论出共识——毕竟敏捷开发的核心是“团队协作”,不是“AI独断”。
这篇论文的作者就是看到了这些问题,才想做一个“既懂技术、又会聊天、还能跟人商量”的工具——也就是SEEAgent。
创新点:SEEAgent的“三板斧”,解决老问题的关键
SEEAgent能脱颖而出,靠的是三个“别人没有的本事”,正好对应上面的三大痛点:
1. 第一斧:“双记忆”设计,既准又不瞎猜
传统LLM容易“一本正经地胡说八道”(幻觉),SEEAgent用“长期记忆(LTM)+短期记忆(STM)”搞定:
- 长期记忆:像“大脑知识库”,要么用QLoRA微调Llama-3.1(4位量化,内存省4倍),要么用GPT-4o-mini,把历史项目的“故事+点数”喂进去,学懂“什么样的故事该估多少点”;
- 短期记忆:像“笔记本”,存当前会话的聊天记录、同伴的估计、甚至可选的历史相似故事——比如估“商品收藏”时,自动调出上次“用户收藏夹同步”的故事,说“上次那个用了2个点,这次多了接口对接,建议3个点”,有理有据。
2. 第二斧:“会聊天的行动模块”,告别黑箱
别的模型只输出数字,SEEAgent会“唠嗑”:你问“为啥估3个点?”,它会说“因为这个故事需要对接用户中心、商品库、收藏数据库3个接口,比上次只对接1个接口的故事多2个点,所以建议3”;你说“要不要考虑兼容iOS 12?”,它会回“哦对,之前兼容老系统多花了1个点,那可以调整到4”——相当于给AI加了“嘴”,能解释、能讨论。
3. 第三斧:“角色化多智能体+共识机制”,融入团队
SEEAgent不是“一个AI打天下”,而是可以配置多个“角色智能体”:比如“前端Agent”懂UX和兼容性,“后端Agent”懂数据库和接口——估“商品收藏”时,前端说“页面适配要1个点”,后端说“接口对接要2个点”,SEEAgent会协调两者意见,再跟人讨论,最后达成共识。而且整个流程遵循“规划扑克”的规则,团队不用改习惯,直接上手。
研究方法和思路:SEEAgent是怎么“工作”的?(拆解步骤)
咱们把SEEAgent的工作流程拆成“搭框架→做推理→做实验”三步,像看说明书一样简单:
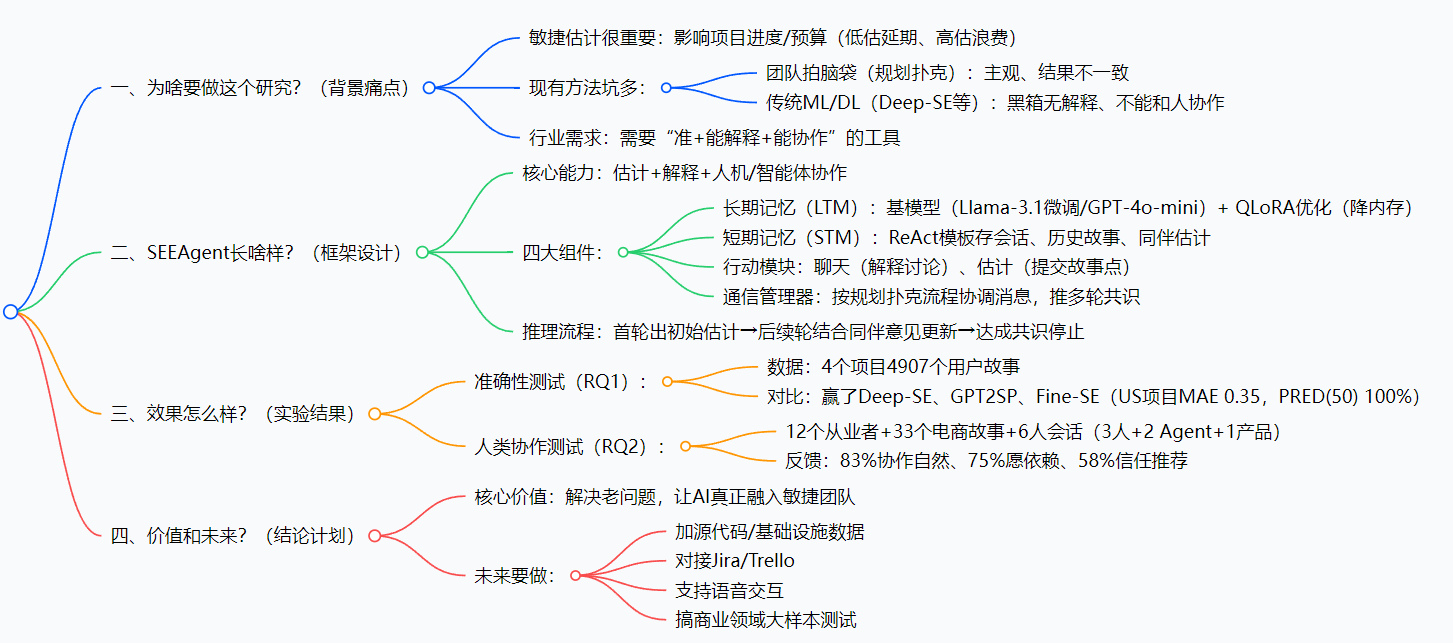
第一步:搭框架——四大组件各司其职
SEEAgent的架构就像一个“小团队”,每个组件有明确分工:
| 组件 | 作用 | 具体操作步骤 |
|---|---|---|
| 长期记忆(LTM) | 提供“专业知识” | 1. 选基模型(微调用Llama-3.1-8B-Instruct,默认用GPT-4o-mini); 2. 微调:用历史“故事+点数”数据,按“系统指令+故事+回答”的Prompt格式训练(比如Listing 1); 3. 优化:用QLoRA(秩=8)+ PEFT,训练10轮,学习率2e-4,减少幻觉。 |
| 短期记忆(STM) | 记录“当前任务信息” | 1. 按ReAct模板整理内容:包含角色(人/Agent)、消息、推理状态、历史故事; 2. 实时更新:每轮讨论后,把新的聊天记录、同伴估计加进去。 |
| 行动模块 | 执行“交互动作” | 1. 聊天动作:根据LTM和STM,生成解释、回应问题; 2. 估计动作:提交具体的故事点(比如1、2、3、5这种斐波那契数)。 |
| 通信管理器 | 协调“人机/Agent沟通” | 1. 首轮:收集所有人和Agent的初始信息,生成结构化Prompt给LTM; 2. 多轮:整合上一轮的估计和讨论,推送给所有人/Agent,直到达成共识或到最大轮次。 |
第二步:做推理——从“初始估计”到“共识”的4步走
比如要估“商品收藏功能”这个新故事,SEEAgent的推理流程是:
- 准备:STM加载新故事、历史相似故事(比如“用户收藏夹同步”);
- 首轮估计:LTM根据历史数据,输出初始估计“3个点”,并解释“因为需要对接3个接口”;
- 讨论更新:前端人说“要兼容iOS 12,得加1个点”,前端Agent附和,LTM结合这个意见,把估计调整为“4个点”,解释“兼容老系统需额外开发,参考上次类似需求”;
- 达成共识:后端人、产品经理都同意“4个点”,通信管理器宣布结束,输出最终结果。
第三步:做实验——用数据和人验证效果
作者做了两个关键实验,分别验证“准不准”和“好不好用”:
实验1:准确性测试(RQ1)——跟SOTA模型比谁更准
- 数据:4个开源项目,共4907个用户故事(比如DM项目4320个,US项目100个);
- 对比对象:Deep-SE(LSTM模型)、GPT2SP(Transformer模型)、Fine-SE(BERT+专家特征);
- 指标:MAE(越小越准)、MMRE(越小越准)、PRED(50)(越大越准,代表误差≤50%的比例);
- 操作:只测LTM组件,训练测试分割跟Fine-SE一样,用Unsloth库微调。
实验2:人类协作测试(RQ2)——跟真人团队比谁更顺
- 参与者:12个软件从业者(有前端、后端、产品,懂敏捷);
- 任务:估eShope电商项目的33个用户故事(比如“商品搜索过滤”“订单详情页优化”);
- 配置:6人一组(3个真人+2个SEEAgent(前端/后端角色)+1个产品经理),按规划扑克流程讨论30分钟;
- 数据收集:填问卷(12个量表题+2个开放题),问“协作自然吗?”“敢信吗?”“愿推荐吗?”。
主要成果和贡献:SEEAgent到底有多厉害?(大白话+表格)
1. 准确性成果:比SOTA模型更准,部分项目满分
先看实验1的核心结果(拿表现最好的US项目举例):
| 模型 | MAE(平均绝对误差) | MMRE(平均相对误差) | PRED(50)(误差≤50%比例) |
|---|---|---|---|
| Deep-SE(SOTA) | 0.489 | 0.163 | 0.900 |
| GPT2SP(SOTA) | 0.447 | 0.121 | 0.950 |
| Fine-SE(SOTA) | 0.462 | 0.135 | 0.920 |
| SEEAgent(微调) | 0.350 | 0.085 | 1.000 |
大白话解读:US项目的100个故事,SEEAgent估的平均误差只有0.35个点,比最好的GPT2SP还低21.7%;而且100%的估计误差都在50%以内(比如该估4个点的,最多估6个点,不会差到8个点)——相当于“百发百中”。
2. 人类协作成果:83%觉得自然,58%愿意推荐
实验2的问卷反馈(12人数据):
| 反馈维度 | 关键结论(百分比) |
|---|---|
| 协作体验 | 83.3%认为“和SEEAgent协作很自然”,83.3%觉得“它的回应清晰易懂” |
| 信任度 | 75%愿意“在实际工作中依赖它的估计”,58.3%“信任它的结果”,58.3%“会推荐给其他团队” |
| 实用价值 | 66.7%认为“它能帮助团队高效达成共识”,58.3%觉得“它能弥合新老成员的知识差距” |
3. 核心贡献:给行业带来的3个实际价值
- 解决“不敢用AI”的问题:有解释、能讨论,团队不用再“盲信黑箱”;
- 提升项目效率:估计更准,减少延期和资源浪费,比如之前估不准导致的加班,现在能少很多;
- 贴合敏捷本质:不替代人类,而是辅助团队协作——毕竟敏捷的核心是“人”,SEEAgent是“团队的一员”,不是“指挥者”。
4. 开源/数据集信息
目前论文未公开代码和数据集,但作者提到:
- 数据集基于Fine-SE的4个开源项目(DM、ME、TD、US),共4907个用户故事,可参考Fine-SE的公开数据;
- 未来计划公开SEEAgent的核心代码,以及对接Jira/Trello的插件。
关键问题:用问答看懂核心
问题1:SEEAgent怎么解决传统AI模型“黑箱”的问题?
答:靠“解释型输出+历史依据”。比如估一个故事,它不会只说“3个点”,而是会告诉你“因为这个故事需要对接用户中心、商品库2个接口,参考上次类似的‘地址管理’故事(对接2个接口,估3个点),所以这次也建议3个点”——相当于把“思考过程”列出来,你能跟着它的逻辑走,自然敢信。
问题2:SEEAgent需要大量历史数据吗?如果是新团队没数据怎么办?
答:不用非要大量数据,它有两种模式:
- 数据多的团队:用QLoRA微调Llama-3.1,学自己项目的规律,更准;
- 新团队没数据:用GPT-4o-mini的“上下文学习”,把少量相似历史故事(比如5-10个)放进短期记忆(STM),它就能参考着估——比如你给它“做登录页(2个点)”“做注册页(3个点)”,它就能估“做找回密码页(2.5个点)”。
问题3:SEEAgent的“角色化智能体”有啥用?比如前端Agent和后端Agent的区别?
答:能覆盖不同专业视角,避免“片面估计”。比如估“商品详情页优化”:
- 前端Agent会考虑“页面适配(PC/手机)、动画效果、兼容老浏览器”,可能加1个点;
- 后端Agent会考虑“接口响应速度、缓存策略、对接库存系统”,可能加2个点;
- 最后SEEAgent会把两者的意见整合,跟人讨论后定最终点数——比“一个AI啥都管”考虑得更全,也更符合团队分工。
问题4:如果团队和SEEAgent的意见不一致,比如团队说4个点,SEEAgent说2个点,怎么办?
答:SEEAgent会“据理力争”但不“固执”。它会先解释“为啥我觉得2个点”(比如“这个故事不用对接新接口,上次类似的只花了2个点”);如果团队说“要加个新功能”,它会根据这个新信息,重新计算,调整到3或4个点——核心是“基于事实讨论”,不是“非要赢”,最终目的是团队达成共识。
问题5:SEEAgent未来能对接我们常用的Jira吗?
答:作者在“未来工作”里明确说了要做!现在的SEEAgent还是一个框架,未来会开发Jira、Trello的插件——到时候你在Jira里打开一个用户故事,SEEAgent会自动弹出来,帮你拉取历史数据、发起讨论、记录共识,不用再切换工具,更方便。
总结
SEEAgent本质上是一款“懂敏捷、会聊天、能协作”的LLM多智能体工具,它没想着“取代人类”,而是“帮人类把估计做得更准、更顺”。它解决了行业长期存在的“主观不准、AI冷、协作难”三大痛点,用4907个故事验证了准确性,用12个从业者验证了实用性——尤其适合那些“想用好AI,但又不敢信黑箱”的敏捷团队。
当然,它也有要改进的地方:比如现在还不能整合源代码数据(比如看代码复杂度来估点),还不能语音交互(未来会加),但已经是一个“能用、好用”的方案了。如果你的团队还在为“估点吵架、延期加班”,那SEEAgent可能就是你要找的工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)