Multi-Agent多智能体系统(三)
概述;Agno:实战;OWL;AgentScope:架构、对比LangGraph、其他;Agent Squad:架构、实战。
概述
智能体(Agent)实在是太火爆,国内外各大公司都在主推,有闭源,也有开源。之前搜集汇总过不少MAS系统,本文继续系列篇第三篇。
参考
Agno
官网,之前叫Phidata,后更名为Agno。开源(GitHub,33.5K Star,4.3K Fork),官方文档,旨在构建高性能、多模态、多智能代理系统,能够处理文本、图像、音频和视频等,并能为智能体添加所需的记忆、知识和工具。
作为一个用于构建多模态智能体的框架,拥有丰富的工具集、灵活的智能体配置和强大的工作流支持。为开发者提供一个便捷高效的框架,使开发者可以更加专注于智能体的逻辑和功能实现,而无需过多关注底层的技术细节。
特性:
- 极致性能:智能体创建速度比LangGraph快约10000倍,启动速度非常快,内存占用低,适合大规模Agent系统;
- 模型无关:可使用任何模型、任何提供商的服务,不存在任何绑定;
- 多模态:原生支持文本、图像、音频和视频等多模态内容输入和输出;
- 多智能体:构建具备记忆能力、知识检索、工具调用等能力智能体组成的智能团队,实现智能体编排、工作流构建;
- 记忆管理:能够将智能体的会话和状态存储在数据库中,构建有记忆的智能体;
- 知识存储:可使用向量数据库实现Agentic RAG或动态小样本学习
- 结构化输出:智能体能够以结构化的数据形式进行输出,方便数据交互
- 监控功能:可实时调试、跟踪智能体的会话和性能
实战
安装
pip install -U agno
export OPENAI_API_KEY=sk-xxxx
示例
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.tools.duckduckgo import DuckDuckGoTools
agent = Agent(
model=OpenAIChat(id="gpt-4o"),
description="You are an enthusiastic news reporter with a flair for storytelling!",
tools=[DuckDuckGoTools()],
show_tool_calls=True,
markdown=True
)
agent.print_response("Tell me about a breaking news story from New York.", stream=True)
# 知识库配置
agent = Agent(
model=OpenAIChat(id="gpt-4o"),
description="You are a Thai cuisine expert!",
instructions=[
"Searchyour knowledge base for Thai recipes.",
"Ifthe question is better suited for the web, search the web to fill in gaps.",
"Preferthe information in your knowledge base over the web results."
],
knowledge=PDFUrlKnowledgeBase(
urls=["https://agno-public.s3.amazonaws.com/recipes/ThaiRecipes.pdf"],
vector_db=LanceDb(
uri="tmp/lancedb",
table_name="recipes",
search_type=SearchType.hybrid,
embedder=OpenAIEmbedder(id="text-embedding-3-small"),
),
),
tools=[DuckDuckGoTools()],
show_tool_calls=True,
markdown=True
)
OWL
开源(GitHub,18.1K Star,2.1K Fork),文档,
采用双角色协作框架,基于部分可观察马尔可夫决策过程(POMDP)优化实时决策,增强任务执行的灵活性。设计目标是通用多智能体辅助,适用于多种现实任务。
功能
- 在线搜索:支持多个搜索引擎,用于实时信息检索和知识获取。
- 多模态处理:支持处理互联网或本地的视频、图像和音频数据。
- 浏览器自动化:利用Playwright框架模拟浏览器交互,包括滚动、点击、输入处理、下载、导航等。
- 文档解析:从Word、Excel、PDF和PowerPoint文件中提取内容,并将其转换为文本或Markdown格式。
- 代码执行:使用解释器编写和执行Python代码。
- 内置工具集:访问一整套内置工具,包括:
- MCP:一个通用的协议层,标准化AI模型与各种工具和数据源的交互。
- 核心工具集:包括ArxivToolkit(搜索和分析学术论文)、AudioAnalysisToolkit(音频分析,包括语言转文本)、CodeExecutionToolkit(编写和执行Python代码)、DalleToolkit(生成图像)、DataCommonsToolkit(数据通用处理)、ExcelToolkit(处理Excel文件)、GitHubToolkit(与GitHub交互)、GoogleMapsToolkit(位置查询和视图服务)、GoogleScholarToolkit(学术搜索)、ImageAnalysisToolkit(图像分类和分析)、MathToolkit(教学运算)、NetworkXToolkit(网络图分析)、NotionToolkit(与Notion交互)、OpenAPIToolkit(调用开放API)、RedditToolkit(Reddit搜索)、SearchToolkit(通用网页搜索)、SemanticScholarToolkit(学术搜索)、SymPyToolkit(符号教学运算)、VideoAnalysisToolkit(视频分析、关键帧提取)、WeatherToolkit(天气信息获取)、BrowserToolkit(网页浏览)等,以及更多用于特定任务的专业工具。
适用场景:
- 学术研究与信息检索:通过ArxivToolkit和GoogleScholarToolkit,可用于搜索和分析学术论文。
- 音频和媒体处理:AudioAnalysis工具包支持语音转文本,VideoAnalysisToolkit可处理视频关键帧提取。
- 代码开发与执行:CodeExecutionToolkit允许编写和执行Python代码,GitHubToolkit支持与GitHub的交互。
- 数据分析与操作:ExcelToolkit处理Excel文件,MathToolkit和SymPyToolkit支持数学运算。
- 网络交互:BrowserToolkit、GoogleMapsToolkit和SearchToolkit提供网页浏览、位置查询和通用搜索功能。
- 多模态集成:支持图像分类(ImageAnalysisToolkit)、天气信息获取(WeatherToolkit)等。
安装
AgentScope
论文,阿里开源(GitHub,12.1K Star,939 Fork),官方文档。
对标LangGraph的企业级智能体开发框架,将消息驱动与分层架构深度融合,为企业级应用提供一套开箱即用、可扩展且易维护的方案。
架构
三层分离,职责清晰:工具→管理器→智能体。
- 工具层(Utility Layer):负责与外部模型、数据库或第三方服务的交互。封装调用方式、重试逻辑和错误处理,并将结果包装成统一的消息结构,便于后续层级消费。
- 管理器层(Manager and Wrapper Layer):整个系统的大脑。它实现资源调度、容错策略以及跨智能体协作的中枢。比如,当某个工具调用失败时,它会根据预设的重试策略自动触发补救流程;当有新任务到来时,管理器会依据智能体能力和负载情况分配最合适的实例。
- 智能体层(Agent Layer):业务逻辑所在。每个智能体都是一个可独立部署、可复用的微服务,拥有自己的状态机和工具集。通过消息中枢进行通信,支持
@定向调用,使得多方协作像团队会议一样自然。
最大优势在于解耦与横向扩展。开发者专注业务,而不必担心底层网络、容错等细节;当流量激增时,只需往管理器里添加更多智能体实例即可,系统自动完成负载均衡。
分布式计算的突破:Actor模型+并行优化
在分布式方面借鉴Actor模型的异步消息传递特性。每个智能体都是一个独立的Actor,通过MsgHub(消息中枢)发布/订阅事件,完成协同。系统会自动构建通信图并识别哪些节点可以并行执行,从而在高并发场景下将响应时间压缩到毫秒级。
引入占位符机制,解决分布式环境下的变量传递问题。智能体内部可使用占位符来引用全局上下文或其他智能体产生的数据,而无需担心网络延迟导致的数据不一致。整个过程对外透明,开发者只需要在定义工具时声明所需参数即可。
状态与记忆的双层管理
传统LLM工作流往往只能保持短期上下文,长链任务很容易出现信息丢失。两项关键改造:
- 长/短时记忆分离
- 短时记忆:由每个智能体内部维护,用于当前对话或迭代中的即时推理。
- 长期记忆:通过持久化存储(如Redis或自定义数据库)保存关键知识点,跨会话共享。两者在需要时相互补充,实现信息的持续流动。
- 状态快照与回溯:系统会在每个节点执行后自动生成Checkpoint,支持时间旅行式调试和错误恢复。若某一步出现异常,可以直接回滚到上一个稳定点,而不必重新走完整条流程。
工具与模型的无缝接入
在工具层面提供Toolkit模块,该模块可一次性注册多种工具(REST API、数据库查询、文件读写等),并为每个工具生成统一的调用接口。开发者只需在智能体配置中声明需要使用的工具,即可获得自动重试与参数校验功能。
对于模型调用,支持MCP多协议接入。无论远端还是本地部署LLM,只需一行配置即可切换。工具层内部已经对模型幻觉做了过滤策略,显著提升输出可靠性。
开发体验:零代码拖拽+可视化监控
为降低技术门槛,提供Studio平台;支持LangGraph Studio。开发者可在浏览器中通过GUI完成:
- 智能体链路搭建:从左侧库拖入所需的工具或自定义函数节点,连接形成完整工作流。
- 参数配置:每个节点可直接编辑输入输出字段、重试次数等属性。
- 实时监控:提供调度状态图、消息日志与成本统计,一眼看清系统整体健康;整合类似LangSmith功能。
这套工具链让非技术背景的产品经理也能快速搭建原型,验证业务可行性。
对比LangGraph
并发能力
- AgentScope在单节点上已支持数千级智能体并发,分布式部署后吞吐量提升超过24倍。
- LangGraph虽在本地可达几百节点,但需额外部署MQ或数据库做持久化,且负载不易自动平衡。
延迟
- AgentScope在同等硬件下平均响应时间约为3–5ms(含模型调用),并发时仍保持稳定。
- LangGraph受限于单进程状态管理,峰值时可能出现几十毫秒的抖动。
资源占用
- 工具沙箱与消息中枢采用轻量级容器技术,内存占用比等价LangGraph实现低约30%。
稳定性
- AgentScope内置错误分类(网络、格式、业务)并自动触发重试或降级;
- LangGraph的状态回滚需手动编写,容错机制不够成熟。
其他
典型应用案例
| 场景 | 问题 | AgentScope解决方案 |
|---|---|---|
| 电商客服 | 多个业务线(售后、物流、推荐)需并行处理 | 智能体分工:咨询、退换货、个性化;MsgHub自动路由@指令,保证对话上下文一致 |
| 智能运维 | 监控告警频繁、修复脚本执行慢 | 监控智能体实时采集metrics→根因分析器自动生成修复计划→执行者立即重启服务,平均故障排除时间从2h降到5min |
| 多模态内容创作 | 文本、图像、音频需同步生成与审核 | 通过Toolkit注册OpenAI图文模型和内部审计工具;工作流节点按条件分支,支持人工在环验证后再继续 |
积极集成已有生态:
- LangChain:可直接调用LangChain工具链,以实现更细粒度Prompt管理;
- MCP Server:支持部署为多租户服务,兼容Flutter、Web等前端框架;
- Alibaba Cloud集成:天然支持OSS、RDS与安全中心等服务,一键接入企业云环境。
发展规划
- 多模态统一框架:计划引入通义千问VLM,进一步支持文本、图像、音频的无缝切换;
- 自学习与优化:基于RL机制,让智能体在真实业务中不断调优决策路径;
- 标准化接口:推动AgentScope与A2A、AutoGen等框架共通协议,以实现跨平台协作。
Agent Squad
官网,原Multi-Agent Orchestrator,专注于编排(Orchestration),AWS开源(GitHub,6.9K Star,619 Fork)。
专为管理多个AI智能体并处理复杂对话而设计的开源框架。核心任务是智能地将用户的请求路由给最合适的智能体,并在整个交互过程中无缝管理和维护对话上下文,确保沟通的连贯性和准确性。提供丰富的预构建组件,让开发者可快速部署应用,还具备高度可扩展性,能够轻松集成自定义的智能体和数据存储方案。
特性
- 智能意图分类:根据对话上下文和内容,动态地将用户请求路由到最合适的智能体
- 双语言支持:提供Python和TypeScript两种主流语言的完整实现
- 灵活的响应模式:支持不同智能体返回的流式(Streaming)和非流式响应
- 强大的上下文管理:在多个智能体之间有效维护和传递对话历史,保证交互的连贯性
- 可扩展的架构:允许开发者轻松集成新的智能体或定制现有组件,以满足特定需求
- 通用部署能力:支持在任何环境下运行,从云平台(如AWS Lambda)到本地服务器
- 丰富的预构建组件:提供多种即插即用的智能体和分类器实现,加速开发进程
对比
- LangChain:LangChain提供从数据加载、模型交互到Agent执行的庞大工具链。而Agent Squad更为轻量,专注于解决当有多个独立的智能体时,如何选择正确的那个并管理它们的对话这一特定问题。在集成现有系统时侵入性更小、更灵活。
- CrewAI/AutoGen:CrewAI和AutoGen等框架更侧重于定义智能体之间的协作工作流(Workflow),让它们像一个团队一样自主完成复杂任务。Agent Squad的SupervisorAgent提供类似能力,但其更大的优势在于与企业级服务的无缝集成(如Amazon Lex,Bedrock Agents),使其不仅能用于实验性的自主代理,更能轻松落地到生产级的对话式AI应用中。
架构
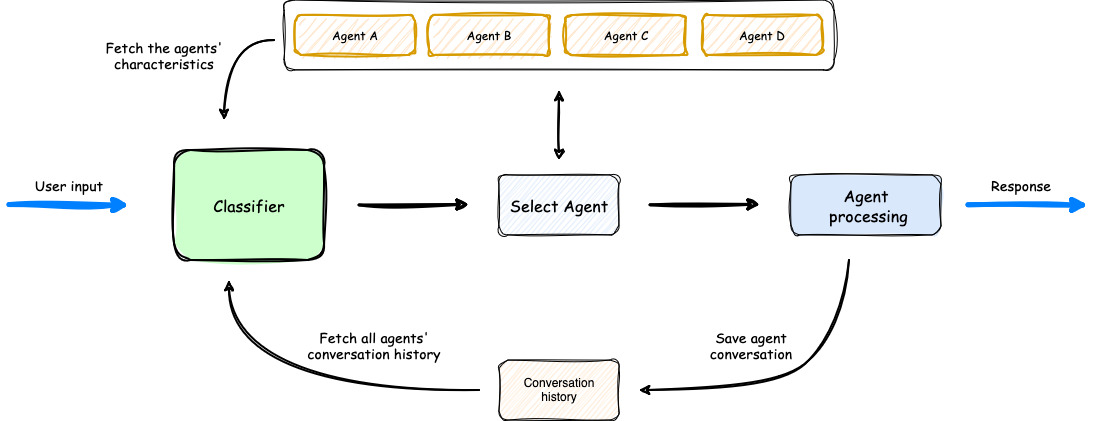
步骤:
- 用户输入:用户发起请求。
- 分类器分析:框架的分类器(Classifier)接收请求,并结合各智能体的特征描述和历史对话记录进行综合分析。
- 智能体选择:分类器选择最适合处理当前请求的智能体。
- 任务处理与响应:选定的智能体处理用户输入,并生成响应。
- 上下文保存与返回:在将响应返回给用户之前,编排器会保存本次对话记录,用于未来的上下文理解。
SupervisorAgent实现高级协同
SupervisorAgent采用智能体即工具(agent-as-tools)架构,允许主管智能体并行协调多个专家智能体共同完成任务。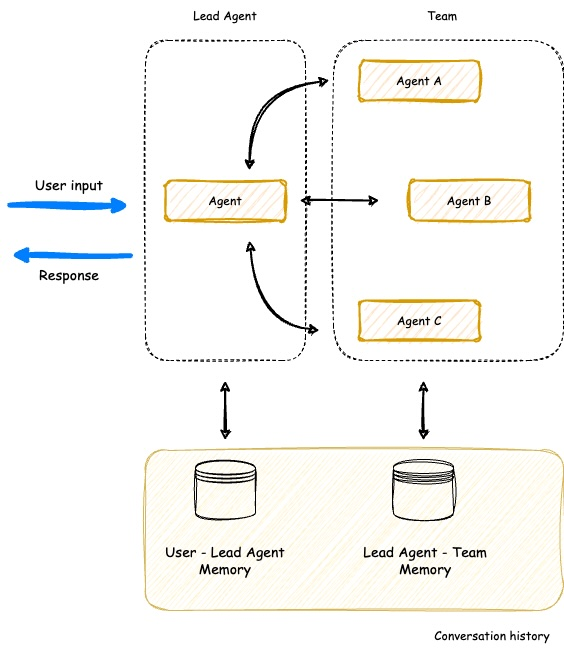
SupervisorAgent关键能力包括:
- 团队协调:组织多个专业智能体共同处理复杂任务
- 并行处理:能够同时执行多个智能体查询,大幅提升效率
- 智能上下文管理:在所有团队成员之间保持统一的对话历史
- 动态任务委派:智能地将子任务分配给最合适的团队成员
实战
安装
# 仅安装核心框架和AWS集成
pip install "agent-squad[aws]"
# 安装OpenAI集成
pip install "agent-squad[openai]"
# 安装所有可选依赖
pip install "agent-squad[all]"
示例
import asyncio
from agent_squad.orchestrator import AgentSquad
from agent_squad.agents import BedrockLLMAgent, BedrockLLMAgentOptions
# 1. 初始化编排器
orchestrator = AgentSquad()
# 2. 添加智能体
tech_agent = BedrockLLMAgent(BedrockLLMAgentOptions(
name="Tech Agent",
description="专注于解答技术相关问题",
streaming=True
))
orchestrator.add_agent(tech_agent)
# 3. 路由用户请求
async def main():
response = await orchestrator.route_request(
"什么是AWS Lambda?",
'user123',
'session456'
)
# 4. 处理响应(流式或非流式)
if response.streaming:
async for chunk in response.output:
print(chunk.text, end='', flush=True)
else:
print(response.output.content)
if __name__ == "__main__":
asyncio.run(main())
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)