FantasyHSI:Video-Generation-Centric 4D Human Synthesis In Any Scene through A Graph-based
设计了一种新颖的HSI框架,以视频生成和无配对数据的多智能体系统为中心,将复杂的交互过程建模为一个动态有向图,在此基础上构建了一个协作的多智能体系统。多智能体系统包括一个用于环境感知和高级路径规划的场景导航智能体,一个将远景目标分解为原子动作的规划智能体,和一个批评智能体,通过评估生成的动作与计划路径之间的偏差来建立闭环反馈机制,能够动态修正由生成模型的随机性引起的轨迹漂移,从而确保长期的逻辑一致
目录
贡献概述
-
设计了一种新颖的HSI框架,以视频生成和无配对数据的多智能体系统为中心,将复杂的交互过程建模为一个动态有向图,在此基础上构建了一个协作的多智能体系统。
-
多智能体系统包括一个用于环境感知和高级路径规划的场景导航智能体,一个将远景目标分解为原子动作的规划智能体,和一个批评智能体,通过评估生成的动作与计划路径之间的偏差来建立闭环反馈机制,能够动态修正由生成模型的随机性引起的轨迹漂移,从而确保长期的逻辑一致性。
-
利用强化学习来训练动作生成器,显著减少了肢体扭曲和脚滑动等伪影,保持生成的一致性和物理性。
背景
-
适应性挑战和成对数据集依赖:作为通用智能体,人类能够执行各种复杂的交互任务,灵活地响应观察到的环境信息,并快速适应新环境。然而,当前的方法与人类智能的这一水平仍然存在显著差距。许多方法依赖于成对的人机环境数据,这通常需要在特定环境中收集大量匹配的动作捕捉和场景数据。因此,当面对未知的物体布局或动态变化时,它们缺乏适应性,难以涵盖现实世界中丰富多样的交互。
-
高级动作完成性挑战:而一些方法尝试利用视觉语言模型 (VLM) 的先验知识来绕过对配对数据集的依赖或视频扩散模型(VDM)以零样本方式生成人与环境交互序列,这些序列通常仅限于诸如坐下或触摸等低级简单动作。它们不适用于高级任务,例如探索城堡。
-
生成动作的物理性挑战:生成的动作还必须在物理上合理。任何视觉伪影,例如肢体变形或脚部滑动,都违反物理定律,严重损害结果的真实感和实际应用。
方法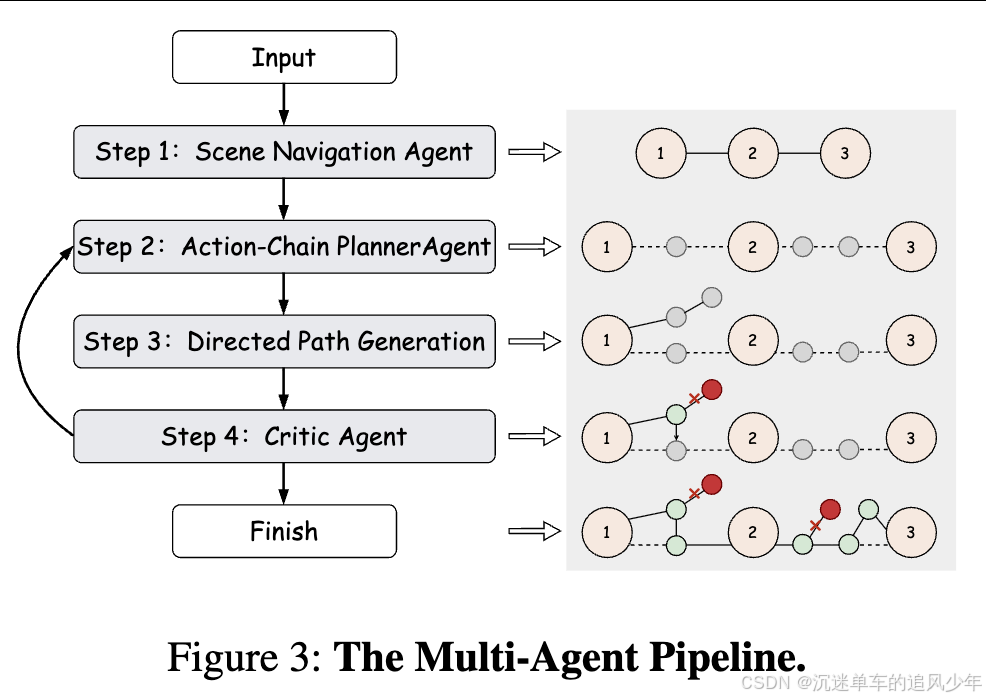
-
动态有向图建模:将复杂的环境场景建模为动态有向图。通过将基于 VLM 的多智能体与 VDM 相结合,FantasyHSI 实现了有效的环境感知和规划,根据环境反馈调整人体运动,生成物理上合理的人体动作序列,并消除了对人-环境配对数据集的依赖。
-
多智能体系统:该系统包含一个用于环境感知和理解的场景导航智能体,以及一个执行高级任务分解的规划智能体,将长期目标分解为原始动作。至关重要的是,为了解决生成模型固有的随机性,我们引入了一个评判智能体来形成闭环反馈回路,量化生成动作与规划轨迹之间的差异,从而能够动态校正偏离的节点状态。这种协同多智能体架构将感知、规划和校正统一起来,从而解决了由生成随机性引起的轨迹漂移问题,并确保了在长期交互中持续的逻辑一致性和物理可行性。
-
强化学习优化生成的物理性:使用强化学习优化VDM设计了一个可控的、物理增强的动作生成器,这显著提高了生成动作的物理真实感。
效果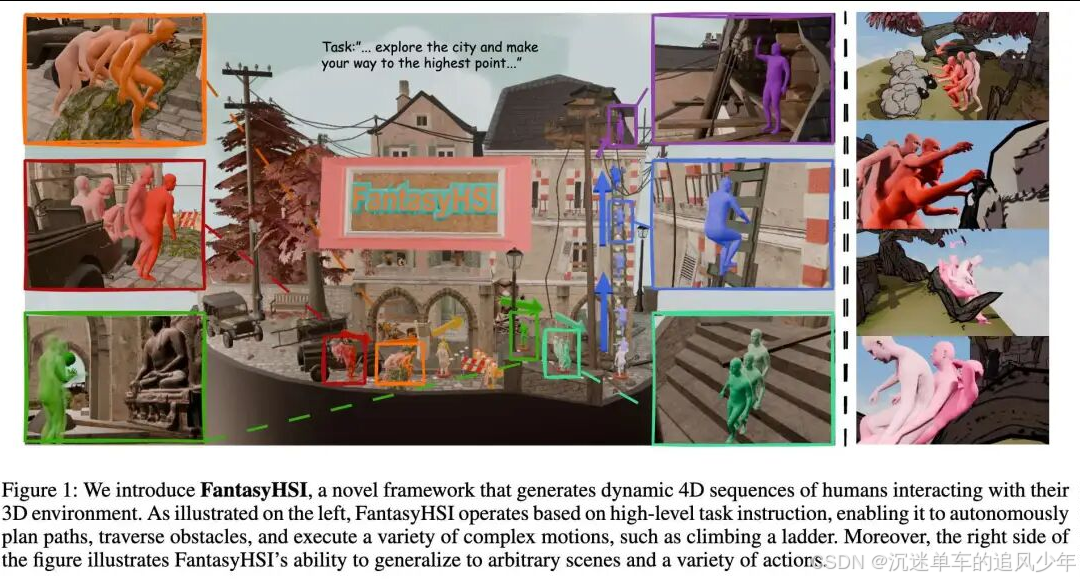
-
可解释性:提出了一种使用动态有向图进行长远人与环境交互的新方法,为感知、规划和行为细化建立了可解释的基础。
-
多智能体协作:开发了一个协作多智能体系统,该系统集成了环境感知、路径规划和闭环校正,以纠正由生成模型固有的随机性引起的动作偏差。
-
物理性强化:通过使用强化学习优化 VDM 设计了一个可控的、物理增强的动作生成器,这显著提高了生成动作的物理真实感。
-
实验验证:在泛化能力、长期任务完成能力和物理真实感方面显著优于现有方法。
实验分析
场景交互能力评估:如下图4(a)所示,展示了 FantasyHSI 与基线方法在 SceneBench 上的场景交互能力的定性对比。结果表明,所提方法在多种环境中生成了生动且富有表现力的动作,能够完成超越简单行走或触碰的多样化高层人-场景交互任务。例如,该方法能够生成高度抽象且类人的行为,如在垃圾堆旁扇鼻子、坐在窗台等非典型位置,甚至如下图1所示,能够攀爬20米长的梯子到达屋顶,而所有其他方法在这些任务上均失败。 定性分析显示,TRUMANS 存在严重的训练数据分布过拟合问题,在遇到新物体时默认仅生成坐姿动作。如图4(a)第一列所示,该方法未能感知窗台的实际高度,而是生成了与训练数据中标准椅子高度一致的坐姿。此外,LINGO 在未见环境中难以准确感知表面边界(如图4(a)第三、四列所示),场景理解能力有限,导致严重穿透现象,无法为高度抽象的交互任务(第二列)生成合理动作。尽管 PedGen 能生成时间上连贯的行走序列,但其动作多样性极低,缺乏执行有意义场景交互的能力。 如表1所示,该方法在CLIP Score和动作多样性方面达到最高值,同时在穿透率(Penetration)和帧间相似度(FS)指标上最低,大多数指标均优于现有方法。这表明所提方法生成的动作在语义对齐性、物理合理性及多样性方面表现更优。
场景感知与响应能力评估:在场景感知与响应能力评估中,图4(b)展示了定性对比结果。在所有方法中,仅有该方法成功感知到障碍物(南瓜)并生成合理的应对行为,例如跨过障碍物。 尽管 TRUMANS 和 LINGO 能通过占据栅格检测障碍物的存在,但其感知范围局限于虚拟人周围1米的立方体区域(以点云表示)。该有限的感知范围截断了周围物体的完整点云,导致模型无法感知物体的完整结构,造成语义信息严重丢失。因此,LINGO 仅生成回头一瞥的动作,而 TRUMANS 未能生成任何合理反应,既未成功避开也未与障碍物发生有效交互。相比之下,PedGen 的障碍物感知能力极差,直接穿过南瓜而无任何反应行为。 与视觉观察一致,如表1所示,该方法在“障碍物穿透得分”(Penetration Obstacle Score)和“反应多样性得分”(Reaction Divergence Score)上均优于所有对比方法,表明其具备更优的场景理解与响应能力。
多智能体框架消融实验:为评估所提出的多智能体协同框架的有效性,进行了一项消融实验:在该设置中,不引入任何智能体进行动作规划或将复杂动作分解为动作单元链。此时,复杂动作直接通过视频生成模型生成。如图5第二行所示,在“跳上围栏”的任务中,由于缺乏由多智能体提供的详细动作规划作为指令,模型未能生成期望的动作序列。 相比之下,所提方法将复杂运动分解为一系列动作单元。基于这一详细计划,虚拟人首先被指示用手扶住岩石以获得支撑,随后跃起并双脚稳稳落在岩石顶部,从而成功完成整体动作。此外,如表1所示,CLIP-S 分数显著下降表明,在缺少多智能体组件将主目标分解为清晰子任务的情况下,模型难以达成任务目标。该结果验证了多智能体框架在任务分解与结构化规划中的关键作用。
评判智能体消融实验: 为评估评判智能体在方法中的有效性,进行了包含与不包含该组件的对比实验。如下图5所示,在未引入评判智能体所提供的评估与回溯机制时,模型无法纠正偏离预期路径的行为,最终未能到达规划的目标位置。而当引入评判智能体后,系统能够成功引导虚拟人重新回到目标位置。 进一步地,如下表1所示,移除评判智能体导致 CLIP 分数显著降低,表明模型在完成指定目标方面存在困难。同时,Diversity(多样性)指标的上升主要源于生成了更多偏离主路径的动作片段——这些片段在完整系统中本应被评判智能体识别、回溯并剪枝。这说明评判智能体不仅提升了任务完成度,还有效控制了无效行为的扩散。
强化学习消融实验:为验证采用DPO优化的视频生成模型的有效性,使用监督微调(SFT)模型和原始预训练模型在测试集上进行了对比实验。如图5和表1所示,尽管基础模型和SFT方法展现出一定程度的指令跟随能力,但其生成结果常出现违背物理规律的动态行为,包括角色穿透场景、肢体形变以及不自然的滑动运动等伪影。 相比之下,经过DPO优化的方法显著增强了生成符合真实世界物理规律动态的能力,有效减少了上述问题,从而在视觉合理性和任务准确性方面取得了更优的整体表现。该结果证明了基于人类偏好反馈(DPO)对生成模型进行精细化调整在提升物理真实性方面的有效性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)