多模态大模型相关概述
支持最高1.8M像素的高分辨率图像输入(例如1344*1344),支持任意长宽比图像。图像压缩层,引入一个单层交叉注意力层和一层可训练的query emb。压缩token长度到query emb。
·
文章目录
多模态大模型相关概述
Prequisite
视觉大模型
ViT
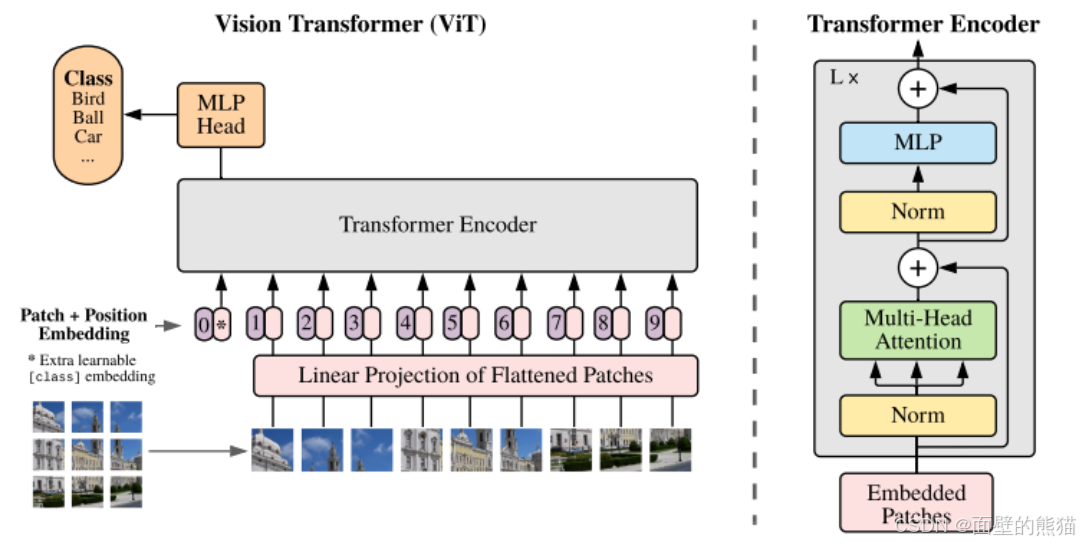
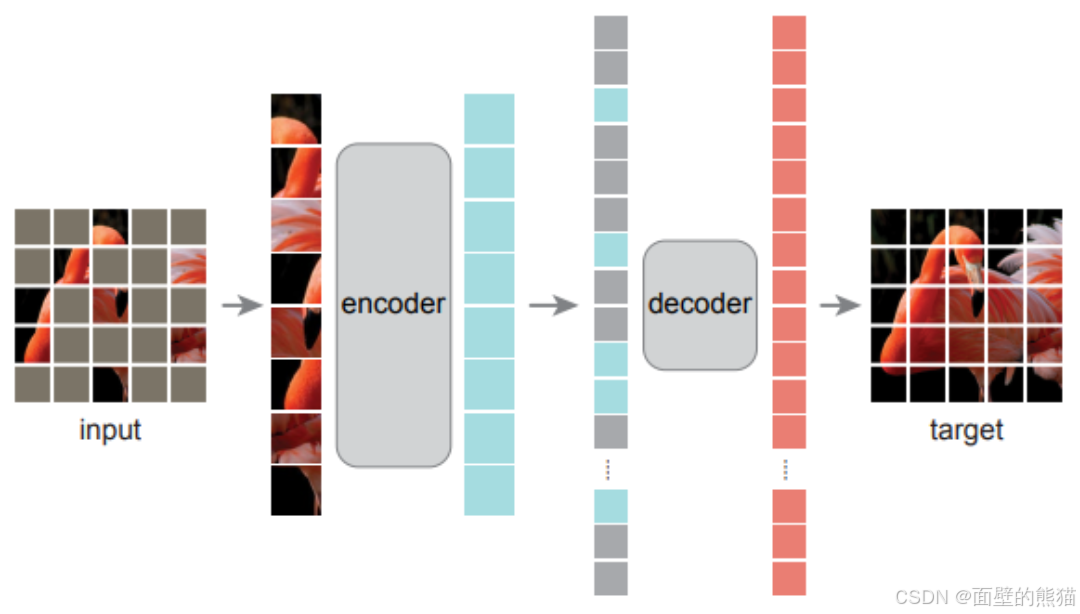
MAE
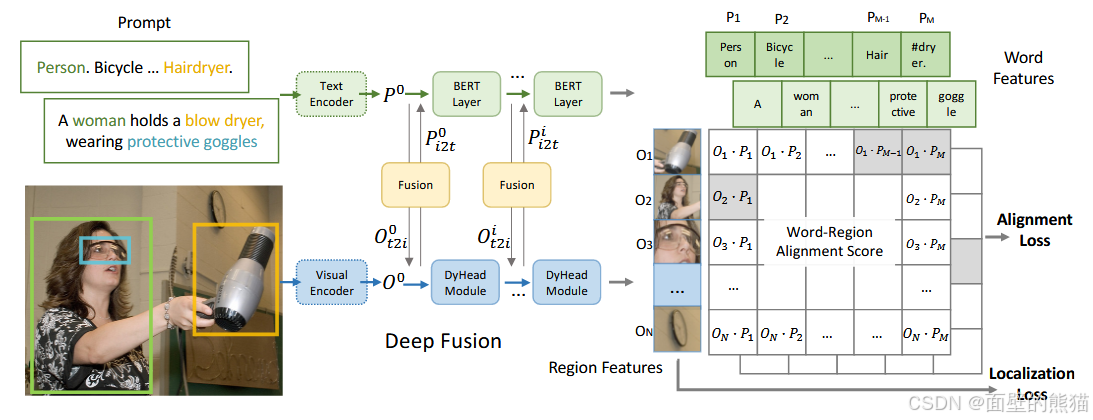
GLIP
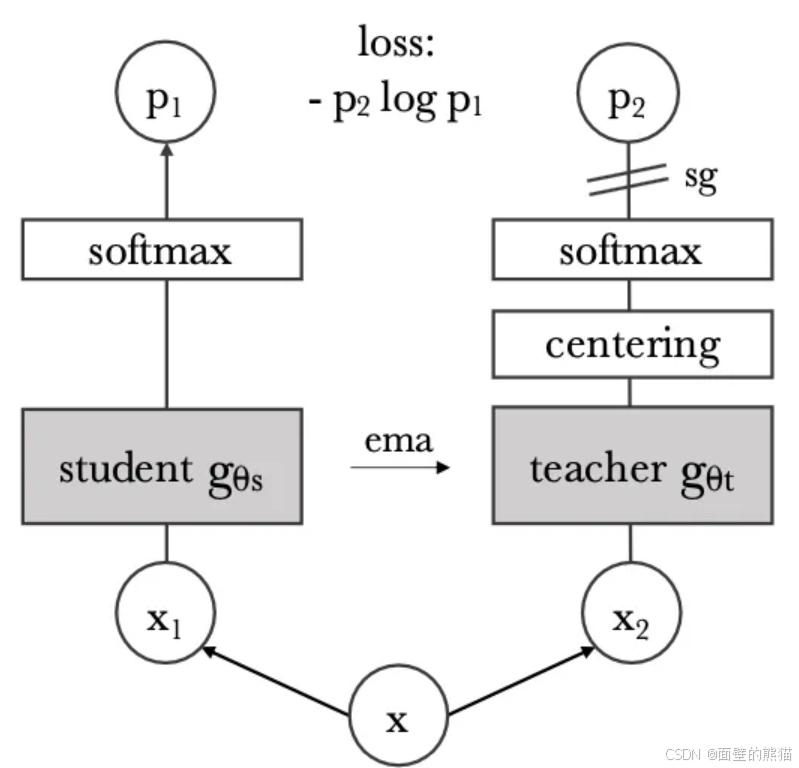
DINO
DETR
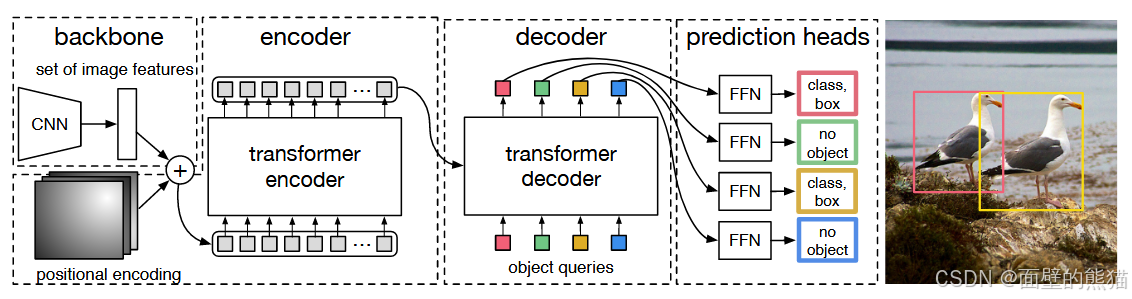
SAM(Segment Anything)
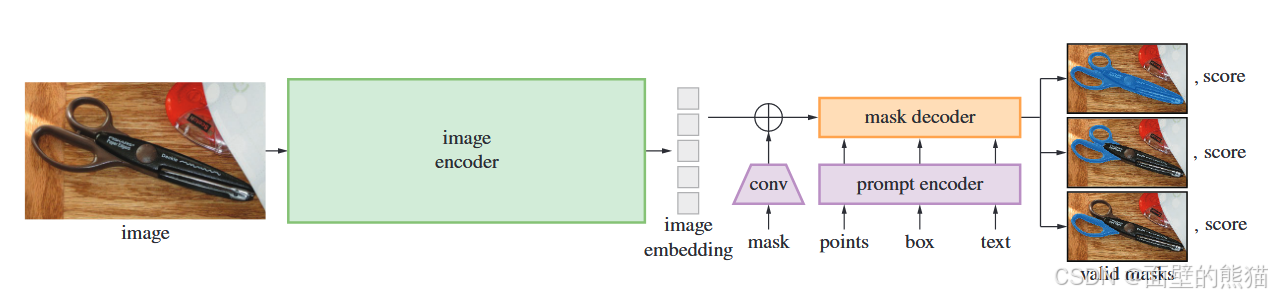
Grounded SAM
大模型相关
链接–>todo
相关工作
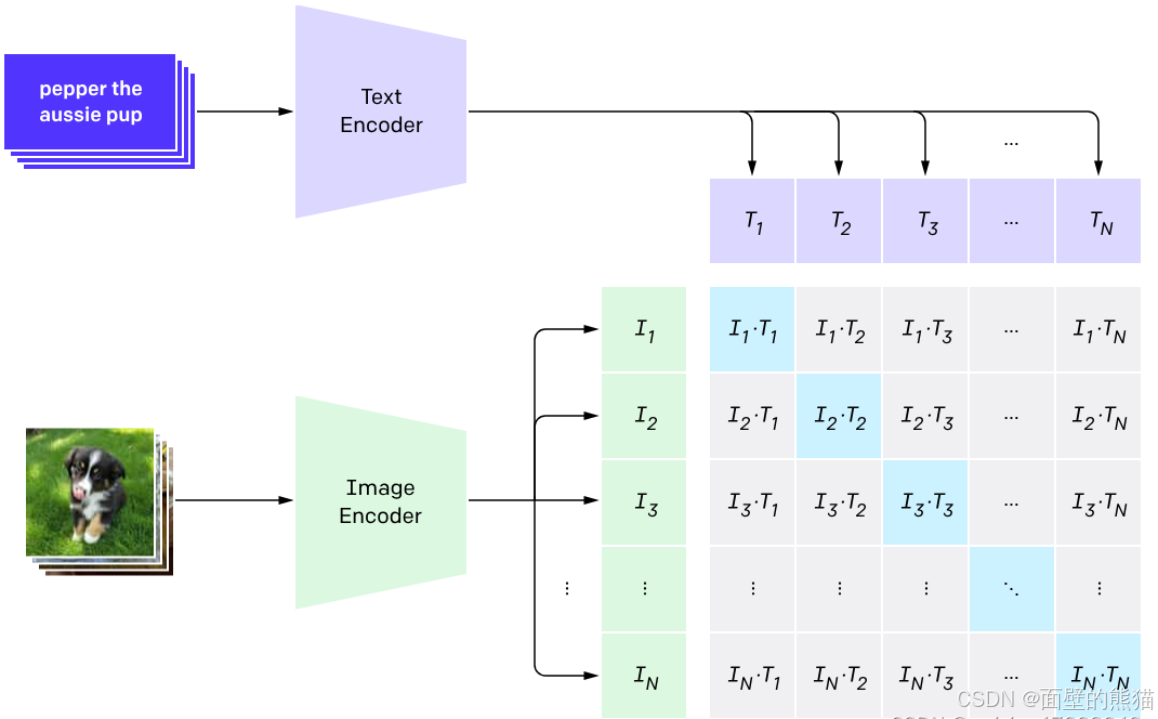
CLIP
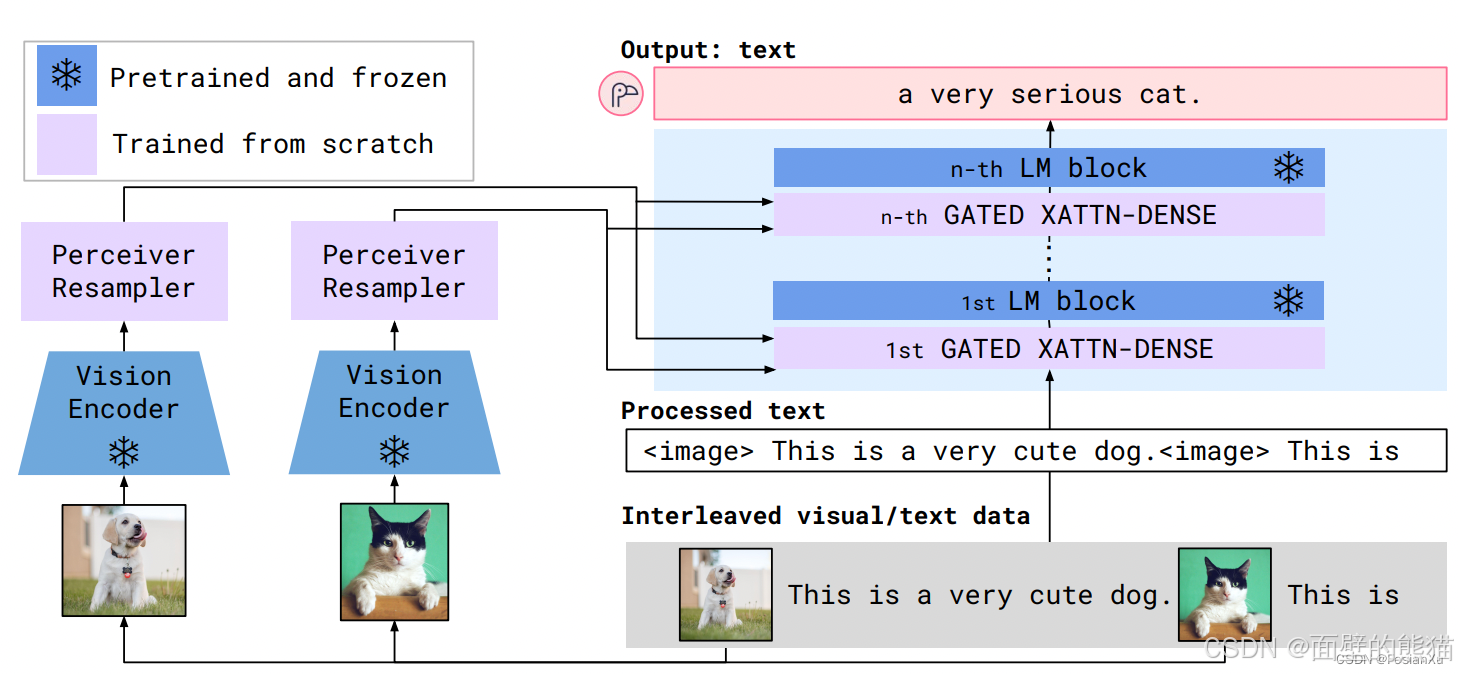
Flamingo
LLaVA 1.5
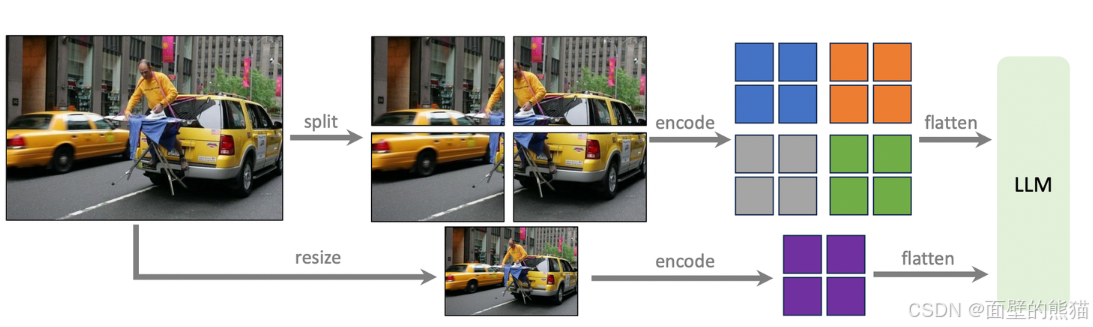
LLaVA-UHD
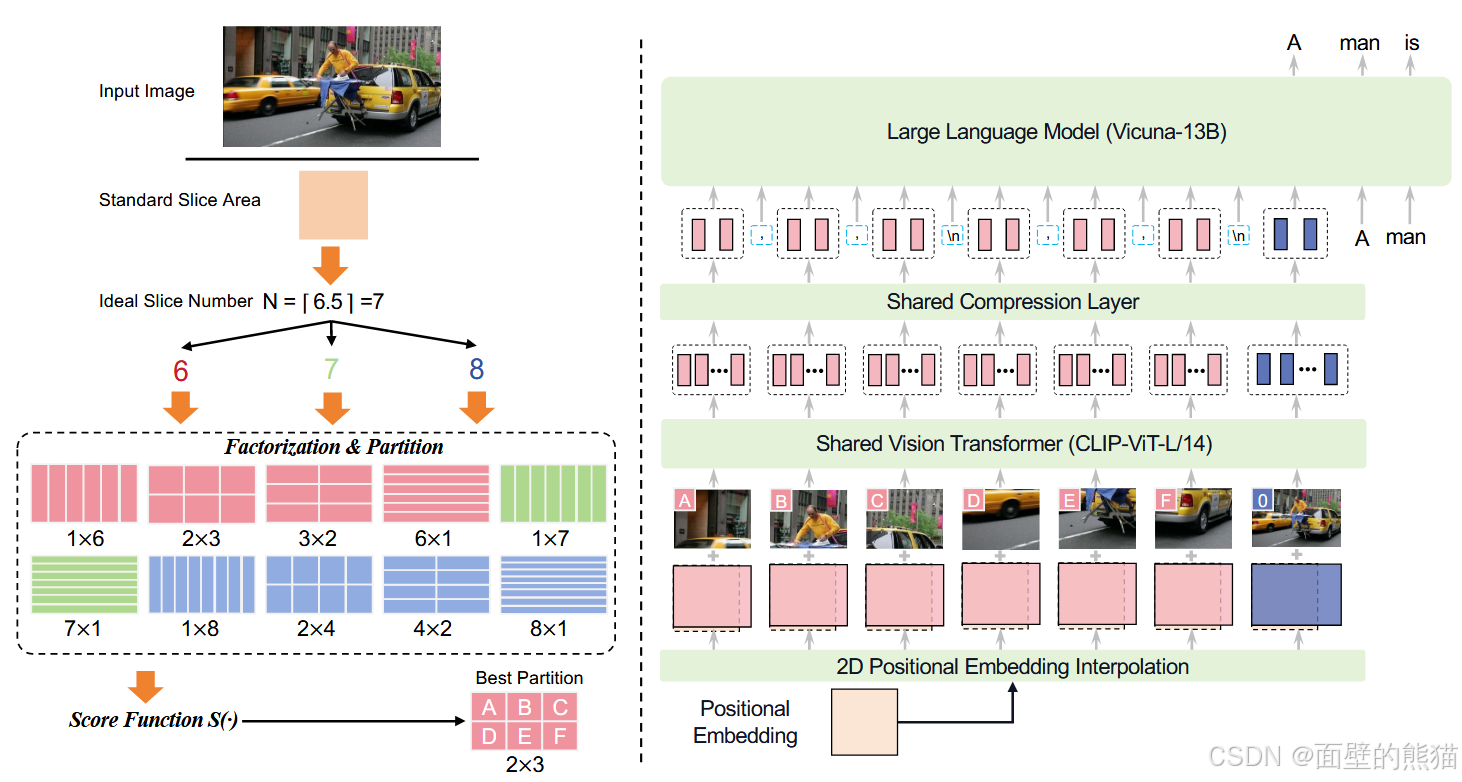
BLIP
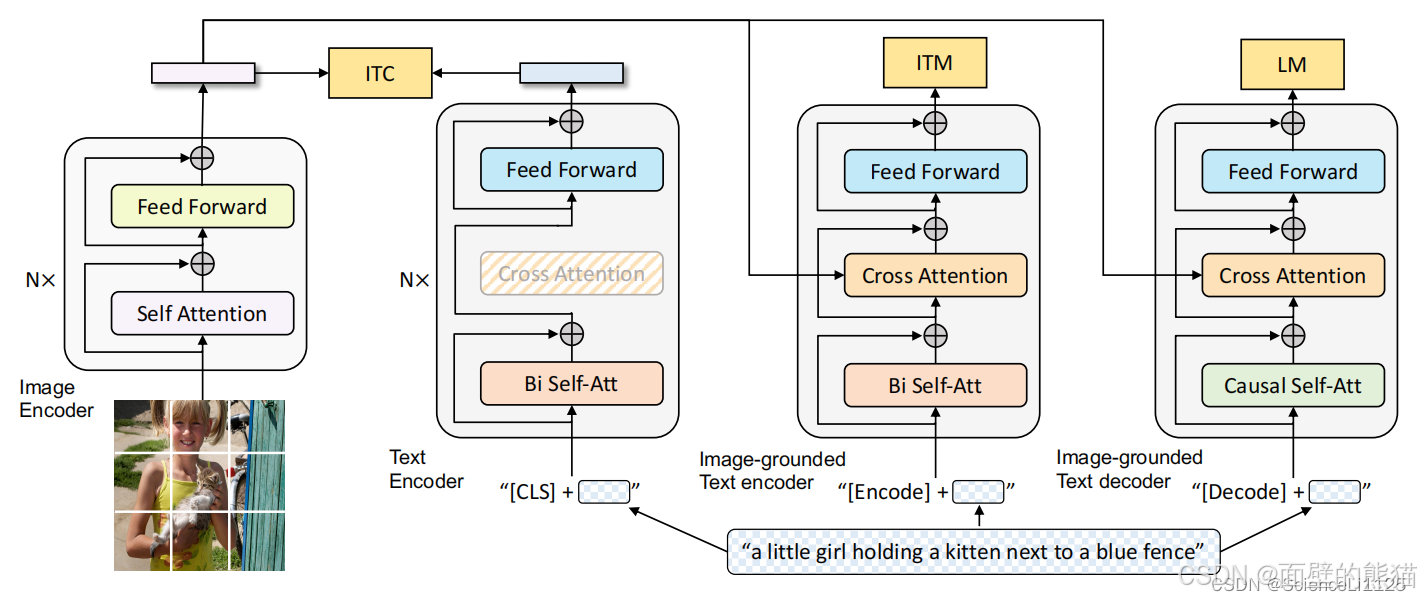
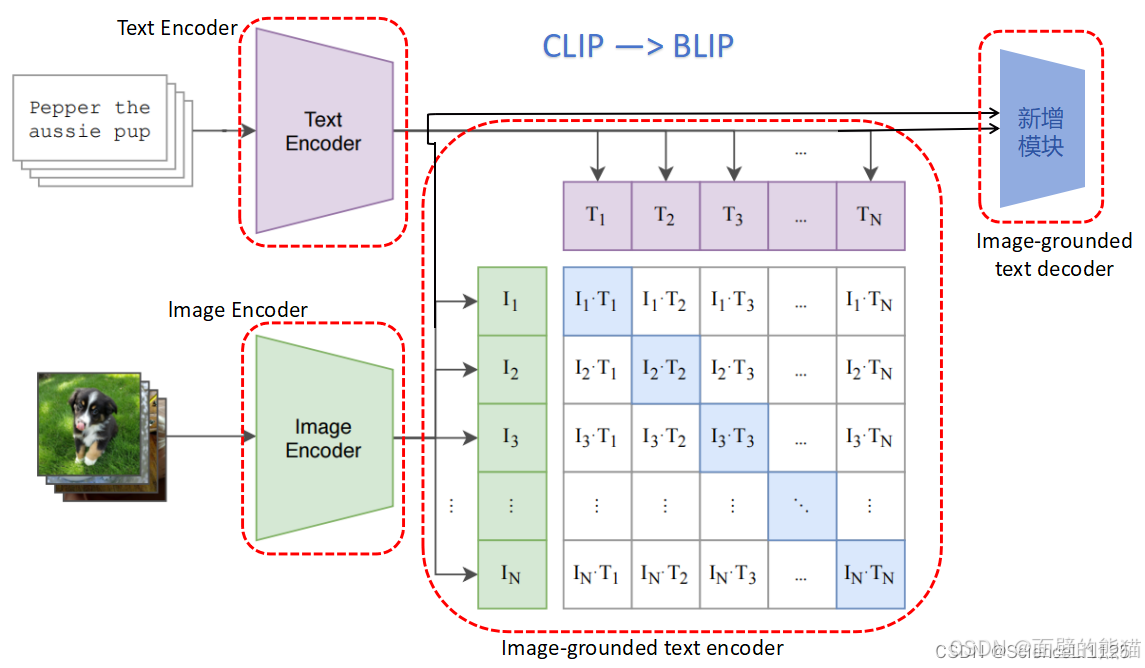
BLIP采用编码器-解码器的多模态混合结构,包括两个单模态编码器、一个以图像为基础的文本编码器和一个以图像为基础的文本解码器。
- 单模态编码器 lmage Encoder:基于 transformer 的 ViT 的架构,将输入图像分割为多个的 patch 并将它们编码为一系列 Image Embedding,并使用 [CLS] token 来表示全局的图像特征。lmage Encoder 用来提取图像特征做对比学习,相当于 CLIP 中的 Image Encoder;
- 单模态编码器 Text Encoder:基于 BERT 的架构,将 [CLS] token 加到输入文本的开头以总结句子。Text Encoder 用来提取文本特征做对比学习,相当于 CLIP 中的 Text Encoder;
- 以图像为基础的编码器 Image-grounded text encoder:在 Text Encoder 的 self-attention 层和前馈网络之间添加一个 交叉注意 (cross-attention, CA) 层用来注入视觉信息,还将 [Encode] token 加到输入文本的开头以标识特定任务。Image-grounded text encoder 用来提取文本特征并将其和图像特征对齐,相当于 CLIP 中更精细化的 Text - Image 对齐;
- 以图像为基础的解码器 Image-grounded text decoder:将 Image-grounded text encoder 的 self-attention 层换成 causal self-attention 层,还将 [Decode] token 和 [EOS] token 加到输入文本的开头和结尾以标识序列的开始和结束。Image-grounded text decoder 用来生成符合图像和文本特征的文本描述,这是 CLIP 中所没有的;
CapFilt 机制:
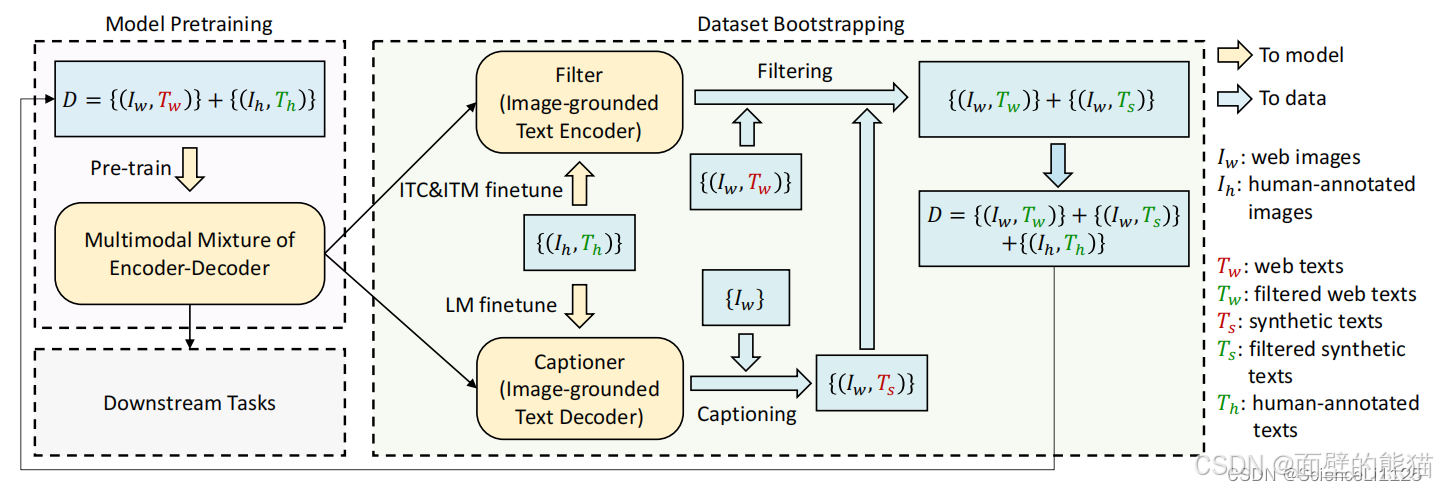


BLIP训练思路:
先使用含有噪声的网络数据训练一遍 BLIP,再在 COCO 数据集上进行微调以训练 Captioner 和 Filter,然后使用 Filter 从原始网络文本和合成文本中删除嘈杂的字幕,得到干净的数据。最后再使用干净的数据训练一遍得到高性能的 BLIP。
BLIP 2
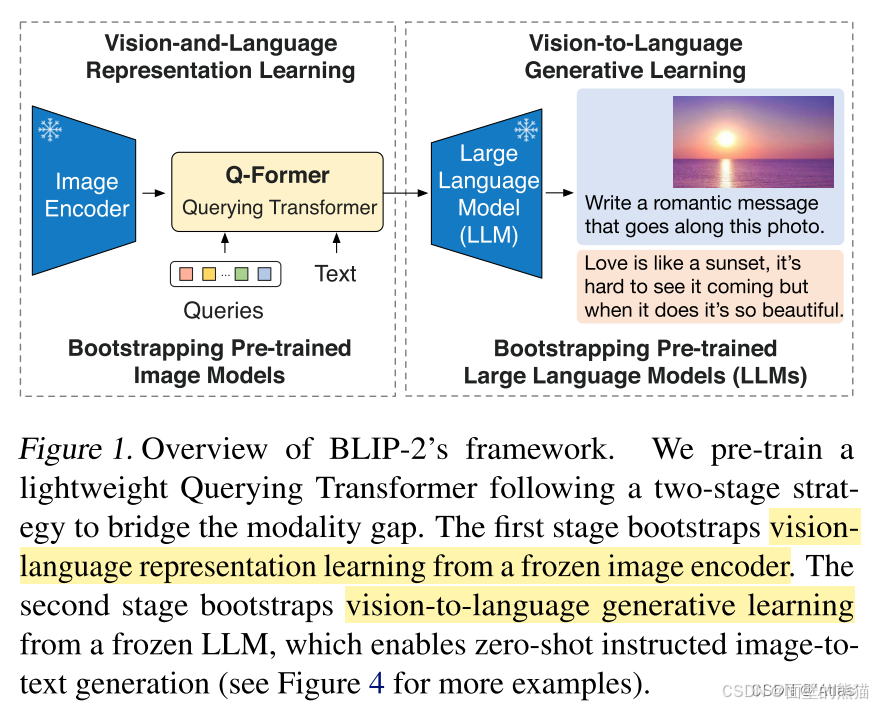
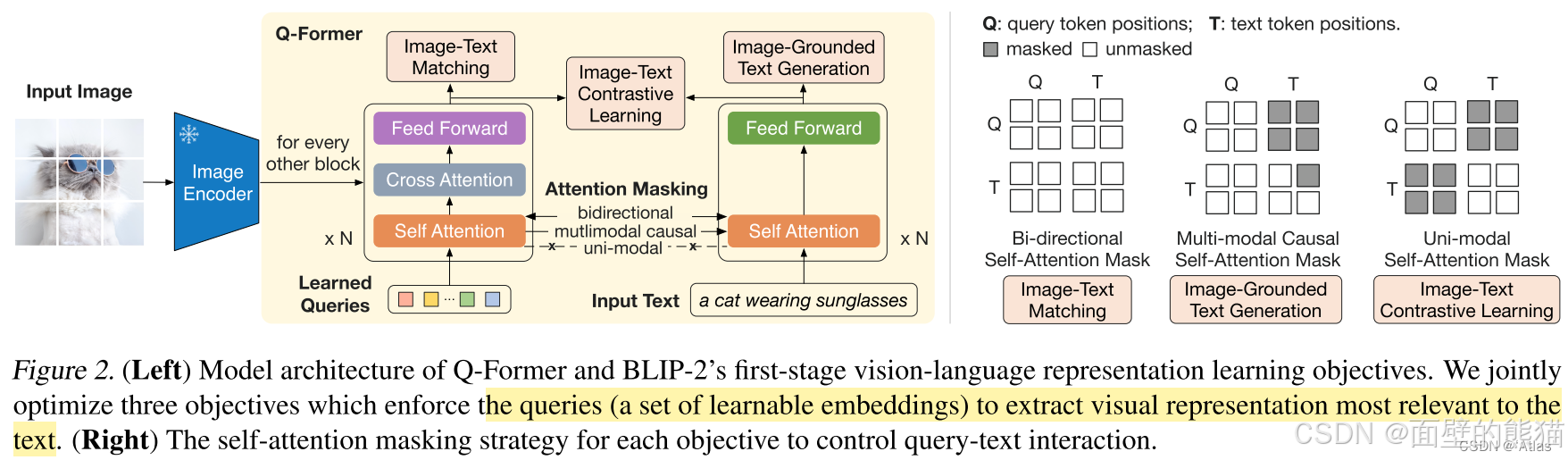
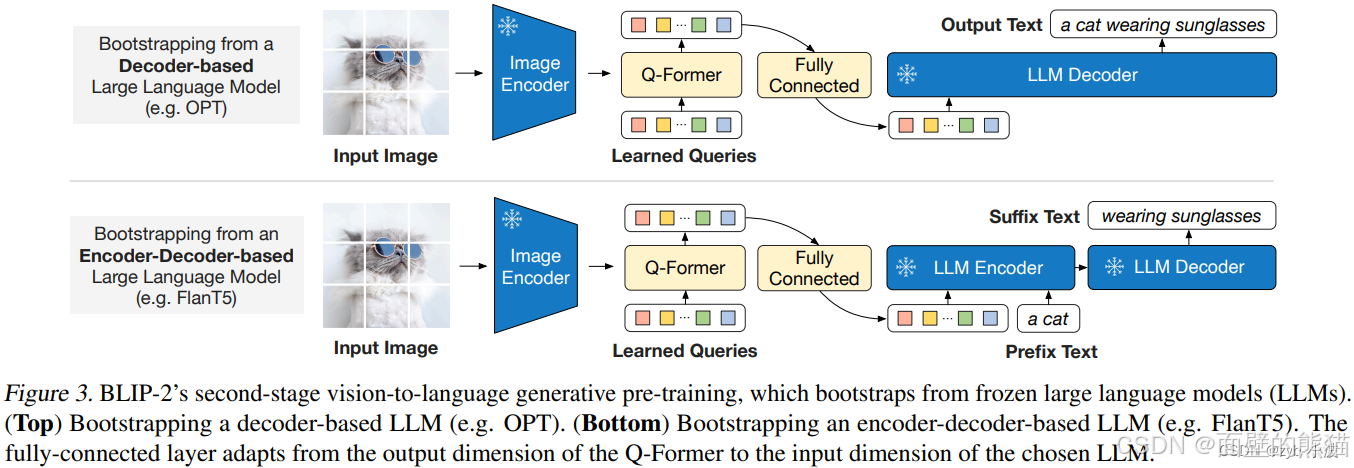
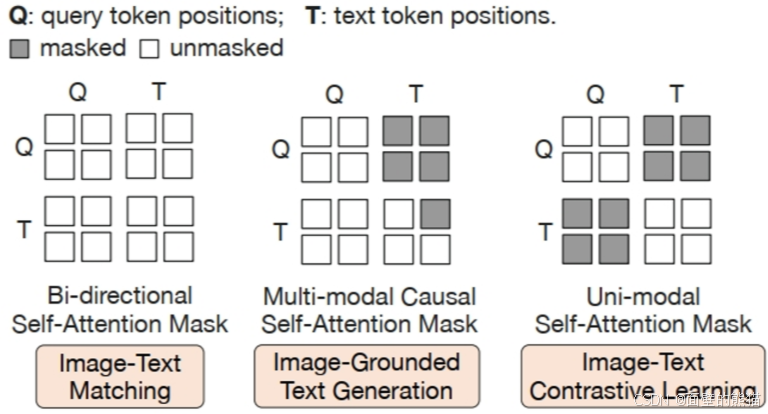
不同的交互任务:
- ITC,使用单模态视觉和大语言模型各自的注意力掩码,Q向量和T之间没有交互。
- ITM,使用双向注意力机制掩码(MLM),实现Q向量和T之间的任意交互。Q向量可以attention T,T也可以attention Q向量。
- ITG,使用单向注意力机制掩码(CLM),实现Q向量和T之间的部分交互。Q向量不能attention T,T中的text token可以attention Q向量和前面的text tokens。
MiniCPM-V 2.6
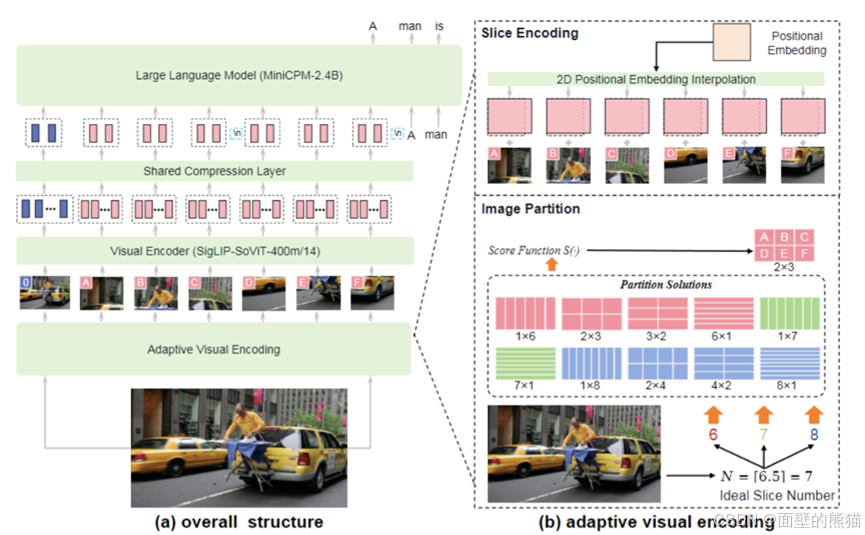
- 支持最高1.8M像素的高分辨率图像输入(例如1344*1344),支持任意长宽比图像。
- 图像压缩层,引入一个单层交叉注意力层和一层可训练的query emb。压缩token长度到query emb。
Qwen2.5 VL
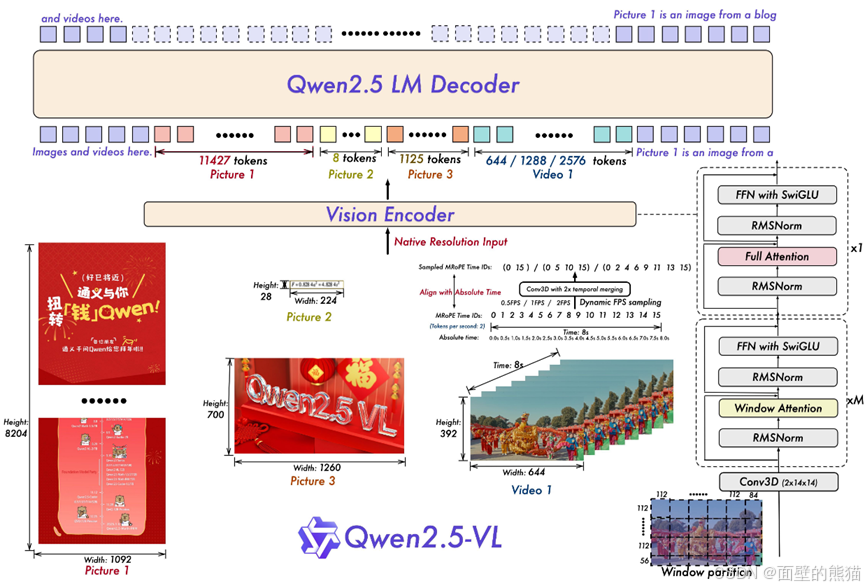
- 数据量翻倍,Qwen2-VL预训练使用的1.2万亿token,Qwen2.5-VL增加到4.1万亿。
- 重新设计的Vision Encoder,2D-RoPE和window attention;
- Vision Encoder的patch size是14x14,绝大部分的layer是计算window attention,只有4 layers是计算full attention。
- 采用2D-RoPE有效捕捉空间信息,RMSNorm以及SwiGLU提高计算效率。
- 对于视频输入,采用动态帧率(更好的补充视内容的时间动态)以及绝对时间编码。
- 提出MRoPE(多模态RoPE),位置编码由时序、高度、宽度三部分组成。
- 模型grounding能力的又一提升,扩大数据集类目、合成数据。
- 预训练分阶段训练,第一阶段只训ViT(对齐),第二阶段全部训练,第三阶段长数据、agent数据(提高推理能力)。
- Post-training:SFT+DPO
- 数据清洗:rule-based、model-based filtering
- 拒绝采样技术,增强模型的推理能力。使用一个中间版本的 Qwen2.5-VL 模型,对带有标注的数据集生成响应,将模型生成的响应与标注的正确答案进行比较,只保留模型输出与正确答案匹配的样本,丢弃不匹配的样本。
InternVL 3.0
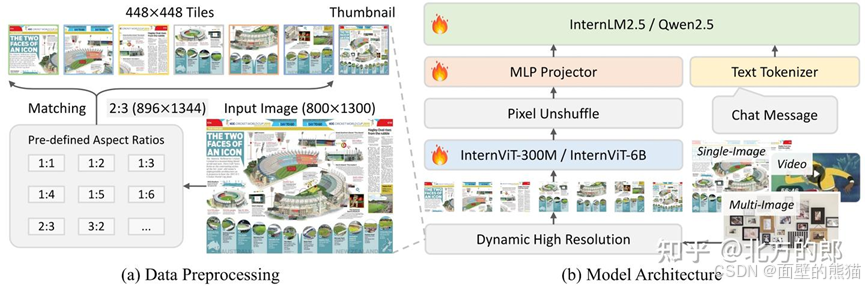
- 原生多模态大模型预训练范式,说白了就是“所有参数一块训”。
- 和InternVL2.5一样,采用pixel unshuffle提高可扩展性和效率(token数减小到原来1/4)。
- V2PE(可变的视觉位置编码器),
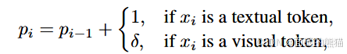
,减少索引增长速率。 - Square averaging weight,大量使用平均权重会导致梯度偏向过长过短文本回复。因此这里用square averaging权重系数。
- Post-training:SFT+MPO(mixed preference optimization)。
- MPO在DPO的基础上引入额外的损失,质量和生成损失。DPO使模型学会选择响应和拒绝响应的偏好。
- 动态高分辨率(Dynamic high resolution),对于输入图像首先resize到448x448的倍数,然后按照预定义尺寸比例从图像上crop对应的区域。(size变小,通道数增加)
InternVL 3.5
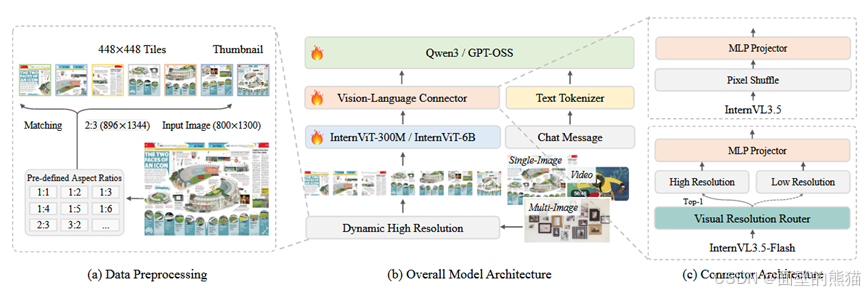
- Cascade RL(级联强化)。Offline+online RL,先收敛 再对齐。
- ViR(Visual Resolution Router)动态调整视觉token分辨率。
- DvD(Decoupled Vision-Language Deployment)Vit和LLM的解离训练策略。
- 支持GUI、embodied agency等新能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)