NeurIPS 2025 spotlight 自动驾驶最新VLA+世界模型 FSDrive
阿里高德与西安交大联合研发的FutureSightDrive系统,创新性地提出"时空思维链"(Spatio-Temporal CoT)技术,突破传统自动驾驶模型依赖文本推理的局限。该系统让AI直接在视觉层面模拟未来路况,通过"骨架-主体-细节"的渐进式方式生成预测图像,实现更精准的路径规划。实验数据显示,该方法使碰撞风险降低31%,在nuScenes等测试基
🚗论文地址: https://arxiv.org/abs/2505.17685
🚀代码地址: https://github.com/MIV-XJTU/FSDrive
自动驾驶还在玩“文字游戏”?当下的VLM模型习惯于将视觉信息压缩成文本再进行推理,丢失了大量关键细节。阿里高德与西安交大联合提出FutureSightDrive,首创“时空思维链”(Spatio-Temporal CoT),让自动驾驶模型学会像人类驾驶员一样,直接在“脑海”中用图像思考和预演未来。这一“视觉思考”范式不仅大幅提升了规划的准确性,更在关键的碰撞率指标上降低了31%,为自动驾驶的视觉推理能力开启了新篇章!
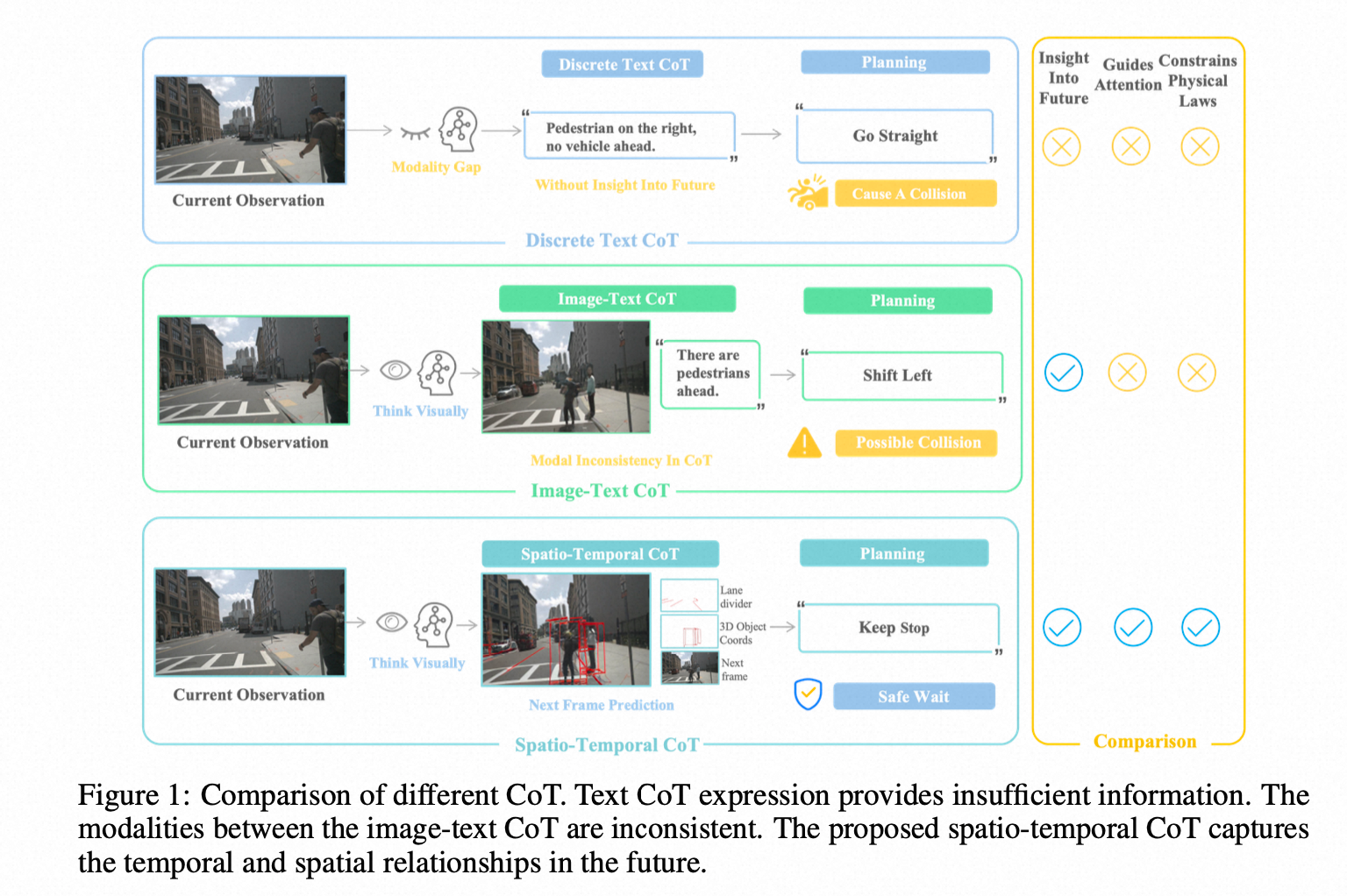
一、老司机 VS 新手AI:你的自动驾驶真的“会看路”吗?
各位开发者、技术爱好者们,大家好!
回想一下我们人类开车时的决策过程:看到前方路况,我们的大脑会瞬间“脑补”出接下来几秒的画面——那辆车可能会变道,那个行人可能会横穿马路... 我们是在用一种**“视觉想象力”**来预判风险、规划路径。
然而,当前的许多自动驾驶大模型(VLM)在“思考”时,走的却是一条截然不同的路。它们更像是一个“新手翻译官”,先把摄像头捕捉到的复杂世界翻译成干巴巴的文本描述(例如,“前方有一辆白色SUV,速度30km/h”),也就是所谓的文本思维链(Text CoT),然后再基于这些文字进行逻辑推理。
这种“先翻译,再思考”的模式存在三大致命缺陷:
- 信息丢失:丰富的视觉细节(如车辆的微小姿态变化、路面的水渍反光)在转为文字时被大量过滤。
- 时空模糊:文字难以精确描述物体间复杂的时空相对关系。
- 模态鸿沟:从图像到文本,再到行动指令,反复的模态转换本身就是一种损耗。
那么,我们能否教会AI跳过“文字狱”,像老司机一样直接用图像思考?
二、核心突破:时空思维链 (Spatio-Temporal CoT),让AI“眼见为实”
FutureSightDrive的核心创新,在于提出了一种全新的推理范式——时空思维链 (Spatio-Temporal CoT)。
简单来说,当模型需要规划路径时,它不再生成一行行描述文字作为中间步骤,而是直接**生成一幅“未来的图像”**作为它的“思考过程”。这幅未来的图像不仅仅是一张快照,它包含了两个维度的关键信息:
- 空间维度 (Spatial Thinking):模型会在这幅未来图像上,直接“画”出它预测的未来车道线和关键物体的3D检测框。这就像人类驾驶员在脑中勾勒出的“安全驾驶走廊”和“重点关注对象”,为后续的精细化思考提供了物理世界的骨架和约束。
- 时间维度 (Temporal Thinking):整幅未来图像的内容(背景、动态物体的位置变化)直观地展示了世界随时间的演变规律。这种视觉上的动态演化,比任何文字描述都更加直观和丰富。
通过这种方式,FutureSightDrive将“对未来的感知”和“对未来的思考”统一在了图像这一种模态下,彻底消除了跨模态转换带来的信息损失和语义鸿沟,建立了一条端到端的视觉推理管线。
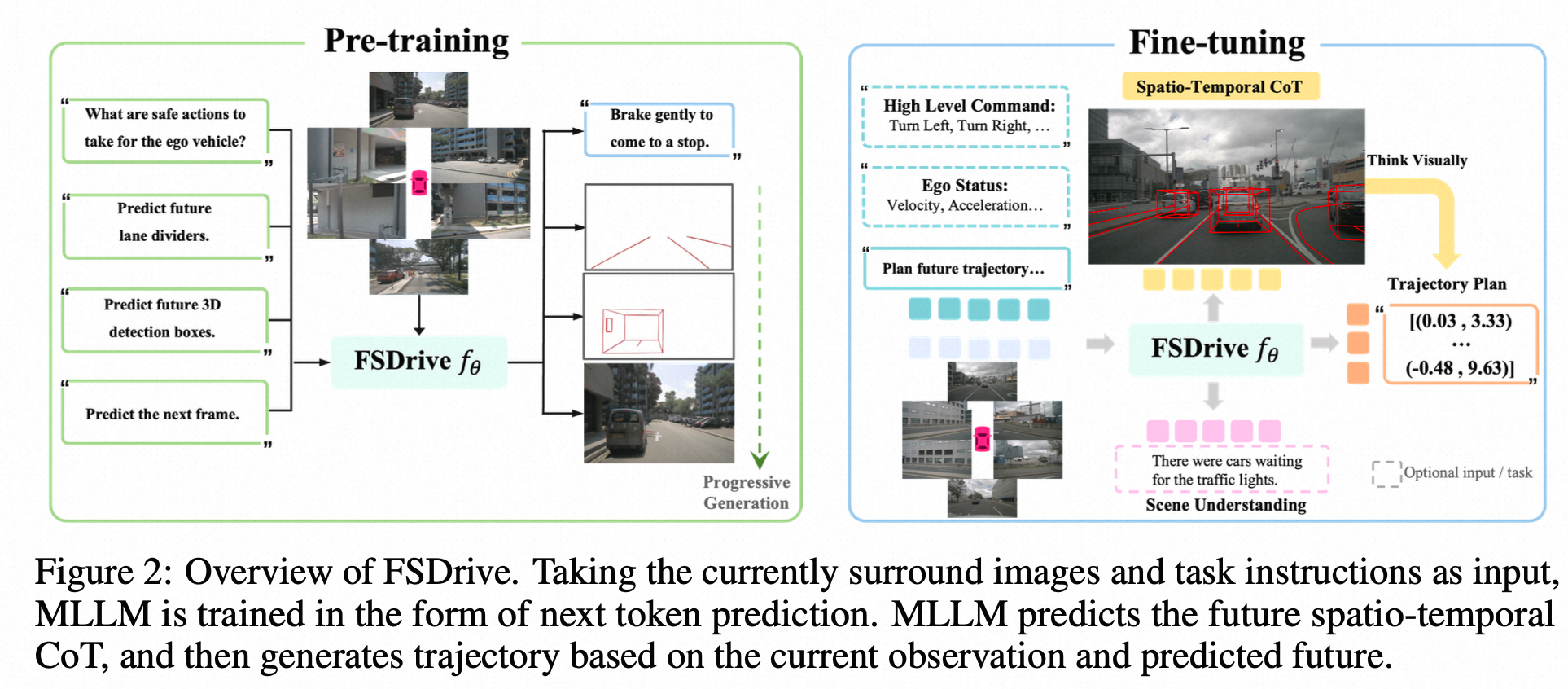
三、FSDrive是如何炼成的?
让一个VLM学会“无中生有”地画出未来,听起来很酷,但技术上如何实现呢?FSDrive提出了一个巧妙的两阶段训练策略。
阶段一:统一预训练——唤醒VLM的“绘画”天赋
我们没有从零开始训练一个庞大的模型,而是基于现有的VLM(如Qwen2-VL, LLaVA),通过一个统一的预训练范式来“激活”其视觉生成能力,同时保留其强大的理解能力。
- 激活生成能力:我们扩充了VLM的词汇表,加入了能代表图像像素的“视觉词元”(visual tokens),并通过预测未来帧的任务,教会模型如何像生成文本一样自回归地“画”出图像。
- 保留理解能力:同时,我们继续进行视觉问答(VQA)任务的训练,确保模型不会“忘了”如何理解世界。
更关键的是,为了让生成的未来符合物理规律,我们引入了**“从易到难”的渐进式生成(Progressive Generation)**:
- 第一步:画骨架。先生成未来的车道线,约束静态物理世界。
- 第二步:定主体。再生成关键物体的3D框,约束动态物理世界。
- 第三步:填细节。在骨架和主体的约束下,生成完整的、细节丰富的未来图像。
这种方法,让模型学会了有条理、有逻辑地“构思”未来,而不是天马行空的“幻想”。
阶段二:监督微调——从“思考者”到“决策者”
在模型具备了“脑补”未来的能力后,我们再通过监督微调,教会它如何利用这份“预见”来做决策。此时,VLM扮演着双重角色:
- 世界模型 (World Model):根据当前输入,生成包含时空思维链的未来图像。
- 逆动力学模型 (Inverse Dynamics Model):结合当前观测和自己预测的未来,反推出最优的行驶轨迹。
这种“基于预见来规划”的模式,让FSDrive在面对突发情况时更具前瞻性,能够做出更安全、更合理的决策。
四、实验效果:实力碾压,SOTA达成!
空谈不如实证。FSDrive在多个自动驾驶权威基准上都取得了卓越的成绩。
- 轨迹规划任务 (nuScenes):
- 在不使用车辆自身状态(ego-status)这一“简单模式”下,FSDrive在L2误差和碰撞率等核心指标上均优于现有的自回归和非自回归方法。
- 最令人振奋的是,与不使用任何CoT的基线模型相比,FSDrive的时空思维链将碰撞风险(Collision Rate)平均降低了高达31%!这直接证明了“视觉思考”在提升安全性上的巨大价值。

-
未来帧生成质量:
- 尽管生成图像只是中间步骤,FSDrive的生成质量依然惊人。其FID分数达到了10.1,甚至优于一些专门的扩散模型(Diffusion Model),证明了其强大的视觉生成能力。
-
场景理解任务 (DriveLM):
- FSDrive在场景理解问答上也取得了SOTA成绩,这表明我们的统一预训练范式成功地在“激活生成”和“保留理解”之间取得了完美平衡。
五、总结与展望
FutureSightDrive的核心贡献,是为自动驾驶领域引入了一种全新的、更符合物理世界交互本质的视觉推理范式。
它告诉我们:与其让模型在抽象的符号世界里“绕圈子”,不如直接赋予它“看见”和“想象”未来的能力。
核心贡献总结:
- 提出时空思维链(Spatio-Temporal CoT):让模型通过生成未来图像进行推理,实现了端到端的视觉因果推断。
- 提出统一的预训练范式:高效地激活了现有VLM的视觉生成能力,无需从零开始训练。
- 提出渐进式生成方法:通过“骨架-主体-细节”的顺序,确保了生成未来的物理真实性。
当然,目前FSDrive主要生成前视视角的未来,下一步我们将探索生成环视(Surround-view)的未来世界,以实现更全面的安全保障。
这项工作标志着自动驾驶正从依赖人类设计的抽象符号,迈向一个模型能自主与环境进行像素级交互和视觉推理的新纪元。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)