刘二大人-Pytorch深度学习实践-线性模型-笔记与作业02
个人博客原文:https://blog.gutaicheng.top
名词解释
-
数据集(Data Set)
-
训练集(Traing Set)
-
已知输入x和输出y,用于训练模型
-
训练集可在分一部分出来作为开发集,用于评估模型的泛化能力,防止过拟合
-
-
测试集(Test Set)
- 只知道输入x
-
-
过拟合(Overfitting)
- 是模型在训练集上表现很好,但在新数据上表现很差
- 但它并没有真正学到数据背后的普遍规律,而是把训练数据中的所有特征,包括噪声,都当作了学习目标。当它遇到新数据时,它的表现会急剧下降,预测结果非常不准确
-
泛化(Generalization)
- 泛化是机器学习模型的真正目标,它是指模型在未见过的新数据上的表现能力
线性模型(Linear Model)
拿到数据集,先试着用线性模型试一下,即找到一个权重w和截距b,使得训练集满足:

-
ŷ读作y_hat,表示预测的值,并不是准确值
-
为了方便学习,这里选择简化模型,将截距b去掉

所以线性模型的关键是找到一个合适的权重w,而什么叫做”合适呢“?即误差小。
-
初始数据集可能并不是严格的在直线上的点集,会是离散的,而我们预设的线性模型是一条严格的直线
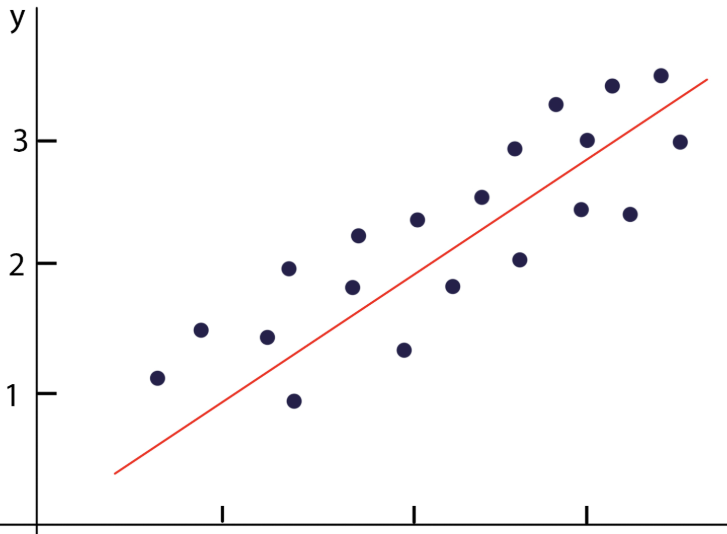
-
而预测的**ŷ(a)会和对应的同一个横坐标a的真实值y(a)**有差值
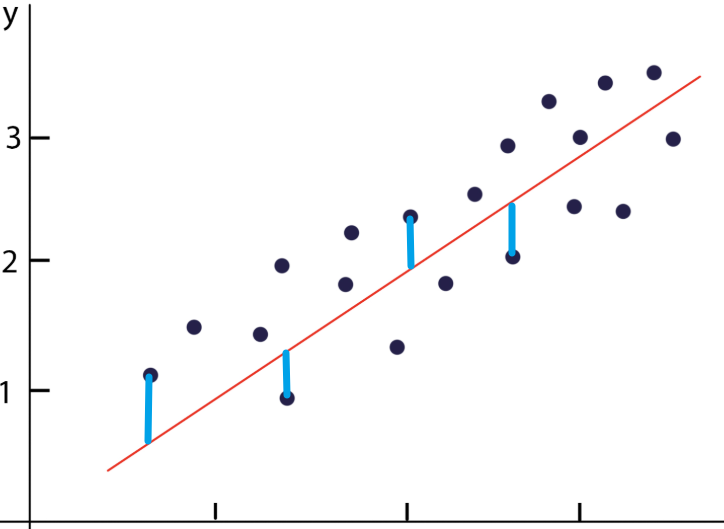
-
但是由于差值有正有负,所以对差值进行求平方(当然也有其他方法,取绝对值等,但是平方对于误差大的惩罚越大)即可消去负值影响,而这些平方值即为损失(loss)
- loss只是针对单独一个样本的
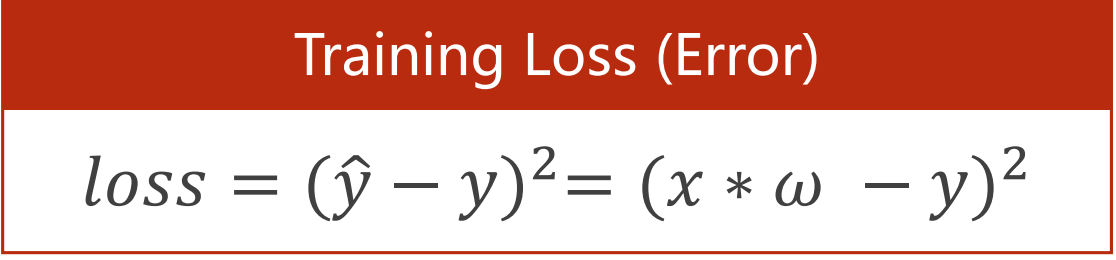
-
得到单独样本损失后,对所有样本的损失进行求和,再取平均值,即得到训练集的误差(Error)
- 采用平方来计算这种方法得到的误差叫做平均平方误差或者均方误差(Mean Squared Error, MSE)
- 误差(Error)是针对训练集training set的
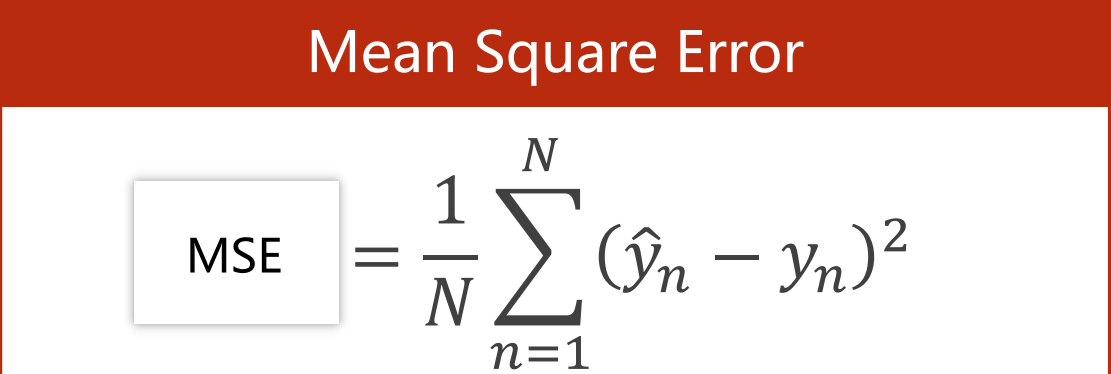
[!IMPORTANT]
注意:
损失函数loss function的定义:并不是上面的 loss = 差值的平方
而是最终求和后的平均计算,比如MSE的公式
-
最终找到一个误差最小的权重w,就是线性模型的关键。
比如下图的数据集与权重选择
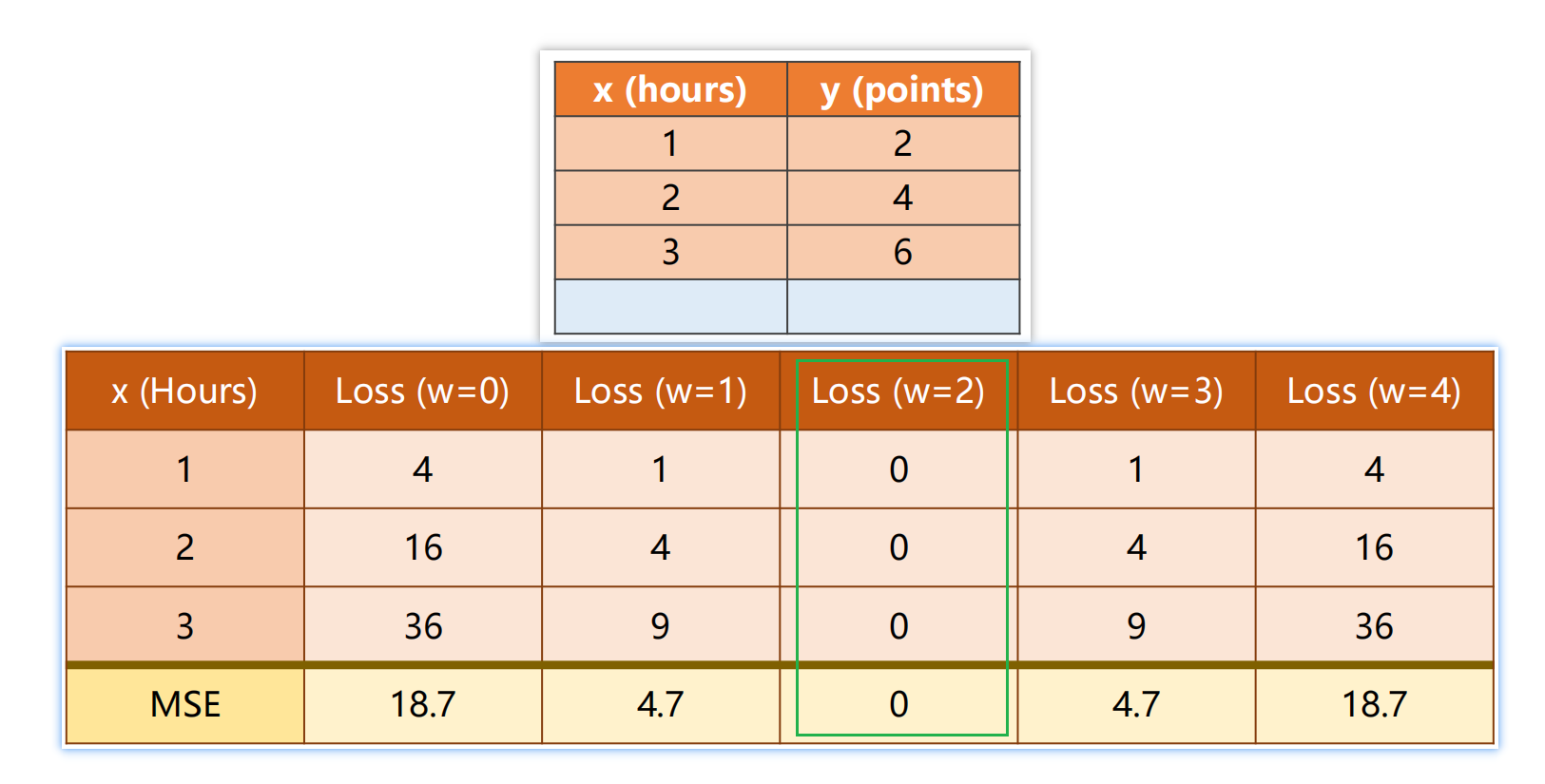
穷举法找权重w
-
先随机找一个大的步长范围,尝试找到一个**可能(可能有增或减的趋势)**存在最小权重的范围
-
再在这个范围内,缩短步长,以此找到产生最小误差的权重
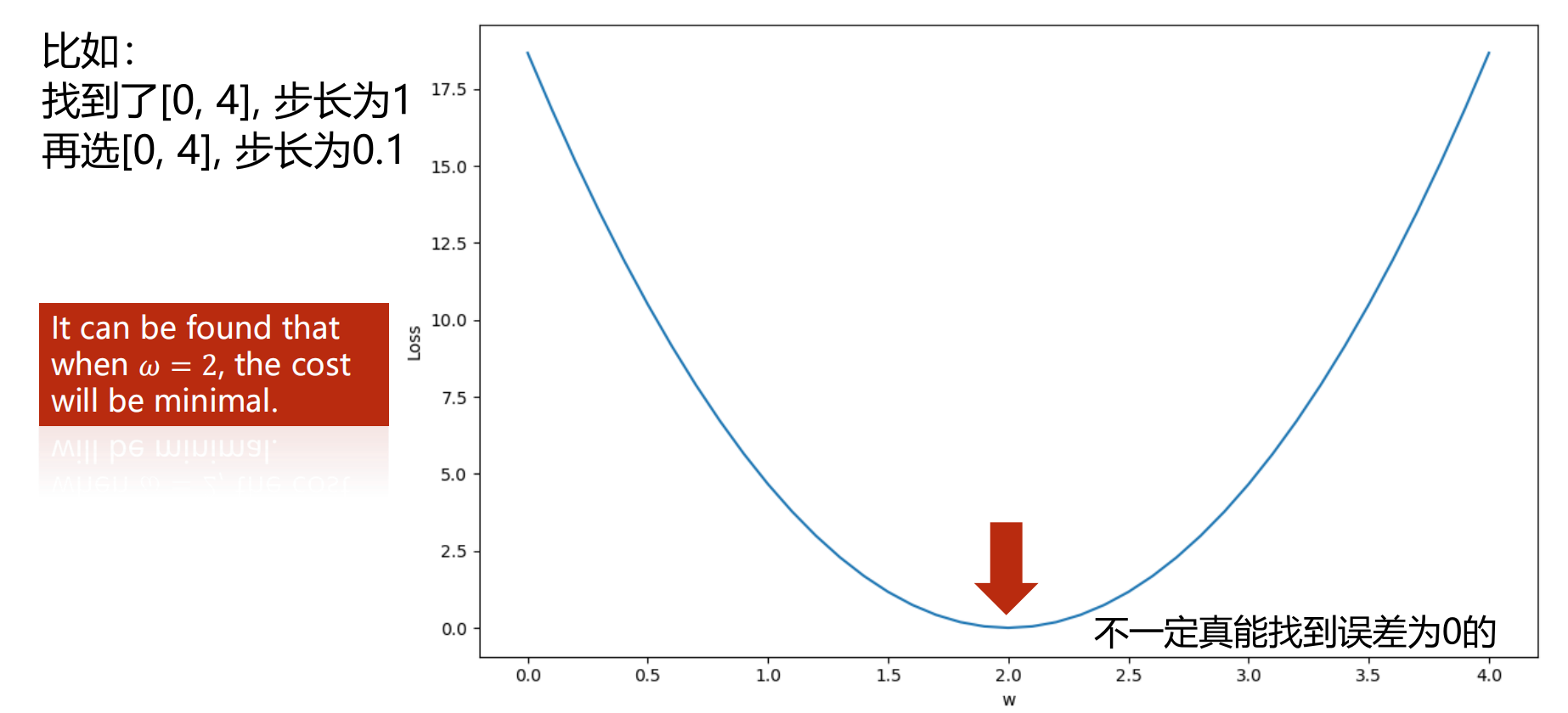
-
代码演示,绘制图如上
# 导入计算和绘图用的包 import numpy as np import matplotlib.pyplot as plt # 定义数据集 x_data = [1.0, 2.0, 3.0] # 输入 y_data = [2.0, 4.0, 6.0] # 输出 # 用于计算 y 的预测值 def forward(x, w): return x * w # 单个样本的损失loss def loss(x, y, w): y_pred = forward(x, w) return (y_pred - y) * (y_pred - y) # MES损失函数 def MSE(xd, yd, w): loss_sum = 0 for x_val, y_val in zip(xd, yd): loss_sum += loss(x_val, y_val, w) return loss_sum / len(xd) # 权重值列表 w_list = [] # MSE误差列表 mse_list = [] # w权重取值范围在 [0.0, 4.0], 步长间隔为 0.1 for w in np.arange(0.0, 4.1, 0.1): print('w=', w) mes = MSE(x_data, y_data, w) print('MSE=', mes) w_list.append(w) mse_list.append(mes) plt.plot(w_list, mse_list) plt.ylabel('Loss') plt.xlabel('w') plt.show() -
非简化版本,基本模型:ŷ = x*w + b; w,b,mse,三维绘制
# 导入计算和绘图用的包 import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot3d import Axes3D # 导入3D绘图模块 # --- 添加这三行,设置中文显示 --- plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为黑体 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像时负号 '-' 显示为方块的问题 # -------------------------------- # 定义数据集 x_data = [1.0, 2.0, 3.0] # 输入 y_data = [2.0, 4.0, 6.0] # 输出 # 用于计算 y 的预测值 def forward(x, w, b): return x * w + b # 单个样本的损失loss def loss(x, y, w, b): y_pred = forward(x, w, b) return (y_pred - y) * (y_pred - y) # MES损失函数 def MSE(xd, yd, w, b): loss_sum = 0 for x_val, y_val in zip(xd, yd): loss_val = loss(x_val, y_val, w, b) loss_sum += loss_val return loss_sum / len(xd) # 定义 w 和 b 的取值范围 # arange是 Numpy 库中的一个函数,它类似于 Python 内置的 range() 函数,但主要用于创建包含浮点数的数组。 # 第一行代码会创建一个从 0.0 开始,到 4.1 结束(不包含 4.1),步长为 0.1 的一维数组。 # 第二行代码会创建一个从 -2.0 到 2.1 结束(不包含 2.1),步长为 0.1 的数组。 w_range = np.arange(0.0, 4.1, 0.1) b_range = np.arange(-2.0, 2.1, 0.1) # 创建一个用于存储 MSE 值的二维网格 # 分别创建两个矩阵 w_values 和 b_values, 用于绘制 3D 图时的 x, y 坐标 # w_values:这个矩阵的每一 行 都是 w_range 数组的重复 # b_values:这个矩阵的每一 列 都是 b_range 数组的重复。 # 故此将两个矩阵重叠,相同位置的两个元素(w,b)就代表了所有可能的点 w_values, b_values = np.meshgrid(w_range, b_range) # 创建全零矩阵保存所有的损失值 # np.zeros_like():这个函数会创建一个与 w_values 形状完全相同(即行列数一样)的全零矩阵。 mse_values = np.zeros_like(w_values) # 遍历 w 和 b 的所有组合,计算并存储 MSE 值 for i, w in enumerate(w_range): for j, b in enumerate(b_range): mse_values[j, i] = MSE(x_data, y_data, w, b) # 绘制 3D 图像 # figure函数 创建一个新的图形窗口 # figsize 参数设置了窗口的尺寸(长和宽),当然figsize不填也行 fig = plt.figure(figsize=(10, 8)) # add_subplot()函数 在图形窗口中添加一个子图(subplot) # 111 表示将图形窗口划分为 1x1 的网格,并在第 1 个子图上绘图 # 下列方式是简便的工厂模式。告诉 add_subplot 函数你想要一个 3D 坐标系,它就会在后台为你创建一个 Axes3D 对象。 # projection='3d' 告诉 Matplotlib 要创建一个 3D 坐标系,而不是默认的 2D 坐标系 # 这种方式代码更简洁,但可能会让 IDE 产生误判,导致最开始的import显示未引用 ax = fig.add_subplot(111, projection='3d') # 绘制曲面图 # plot_surface() 绘制曲面图函数 # w_values, b_values, mse_values:这三个参数是 3D 表面图的三个坐标轴:x 轴、y 轴和 z 轴 # cmap=cm.viridis:cmap 是 "colormap"(颜色映射)的缩写,它定义了曲面图的颜色方案。viridis 是一种常用的、颜色渐变平滑的方案 # alpha=0.9:alpha 设置了曲面的透明度,0.0 是完全透明,1.0 是完全不透明。 surf = ax.plot_surface(w_values, b_values, mse_values, cmap=cm.viridis, alpha=0.9) # 设置图像标题和标签 ax.set_title("3D 损失函数(MSE)表面图", fontsize=16) ax.set_xlabel('w (权重)', fontsize=12) ax.set_ylabel('b (截距)', fontsize=12) ax.set_zlabel('MSE (损失)', fontsize=12) # 添加颜色条 fig.colorbar(surf, shrink=0.5, aspect=5) # 找到损失函数的最小值点(理论上,w=2.0, b=0.0 时损失为0) # np.argmin():这个函数返回一个数组中最小值元素的索引 # axis=None:忽略数组的维度,而是在整个二维矩阵中寻找唯一的一个最小值。它会返回这个最小值在一维展平(flattened)后的数组中的索引 # axis=0:表示沿着列(columns)进行操作,有几列就会返回几个元素的数组 # axis=1:表示沿着行(rows)进行操作,有几行就返回几个元素的数组 # 例如取None时 mse_values 矩阵是 [[10, 20], [3, 40]],那么它的最小值是 3 # 在一维展平后,数组变为 [10, 20, 3, 40],3 的索引是 2。所以 np.argmin() 会返回 2 # np.unravel_index():反向将一维数组的索引转换为二维,但是要填入参数 shape:即我们传入的是原始矩阵的形状 # 最后返回的是二维坐标 (w, b) min_mse_index = np.unravel_index(np.argmin(mse_values, axis=None), mse_values.shape) # 在两个矩阵中获取最小MES对应的具体值 min_b = b_values[min_mse_index] min_w = w_values[min_mse_index] # 在图上标记最小值点 # 参数依次对应:颜色、形状、大小、标签说明 ax.scatter(min_w, min_b, mse_values.min(), color='red', marker='o', s=100, label=f'最小损失点\n(w={min_w:.2f}, b={min_b:.2f})') # 显示散点图的图例 ax.legend() # 调整视角以获得更好的可视化效果 # elev 是仰角,azim 是方位角 ax.view_init(elev=20, azim=-120) # 显示最终绘制好的图形窗口 plt.show()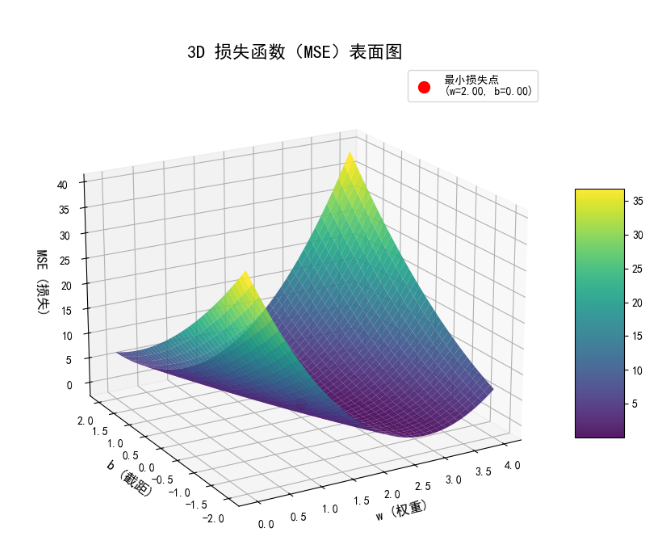

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)