【多模态大模型部署】【提示词反推】采样Flask框架部署Qwen/Qwen2-VL-2B-Instruct,并采用OpenAI形式调用生成图片描述,可用于图片理解等解决方案
·
示例1:
反推提示词,并生成图片。
实际图和生成图片
操作方式:
1.采用部署的Qwen/Qwen2-VL-2B-Instruct进行生成图片描述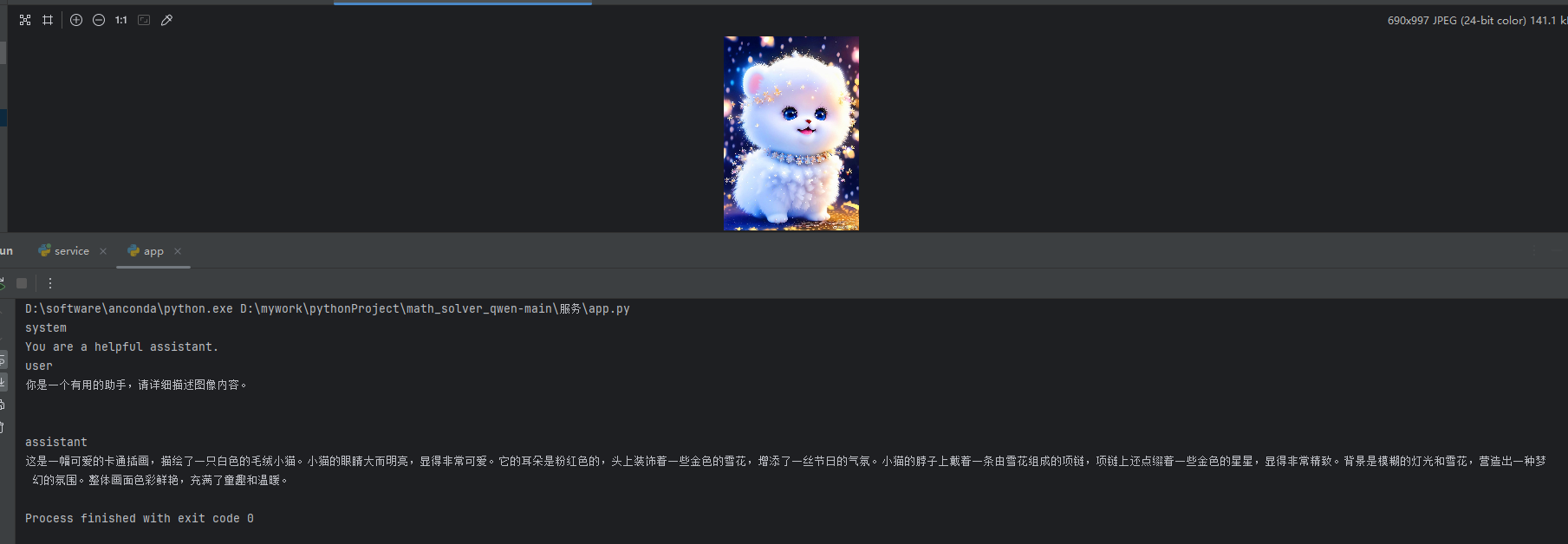
2.在chat.qwen.ai进行绘图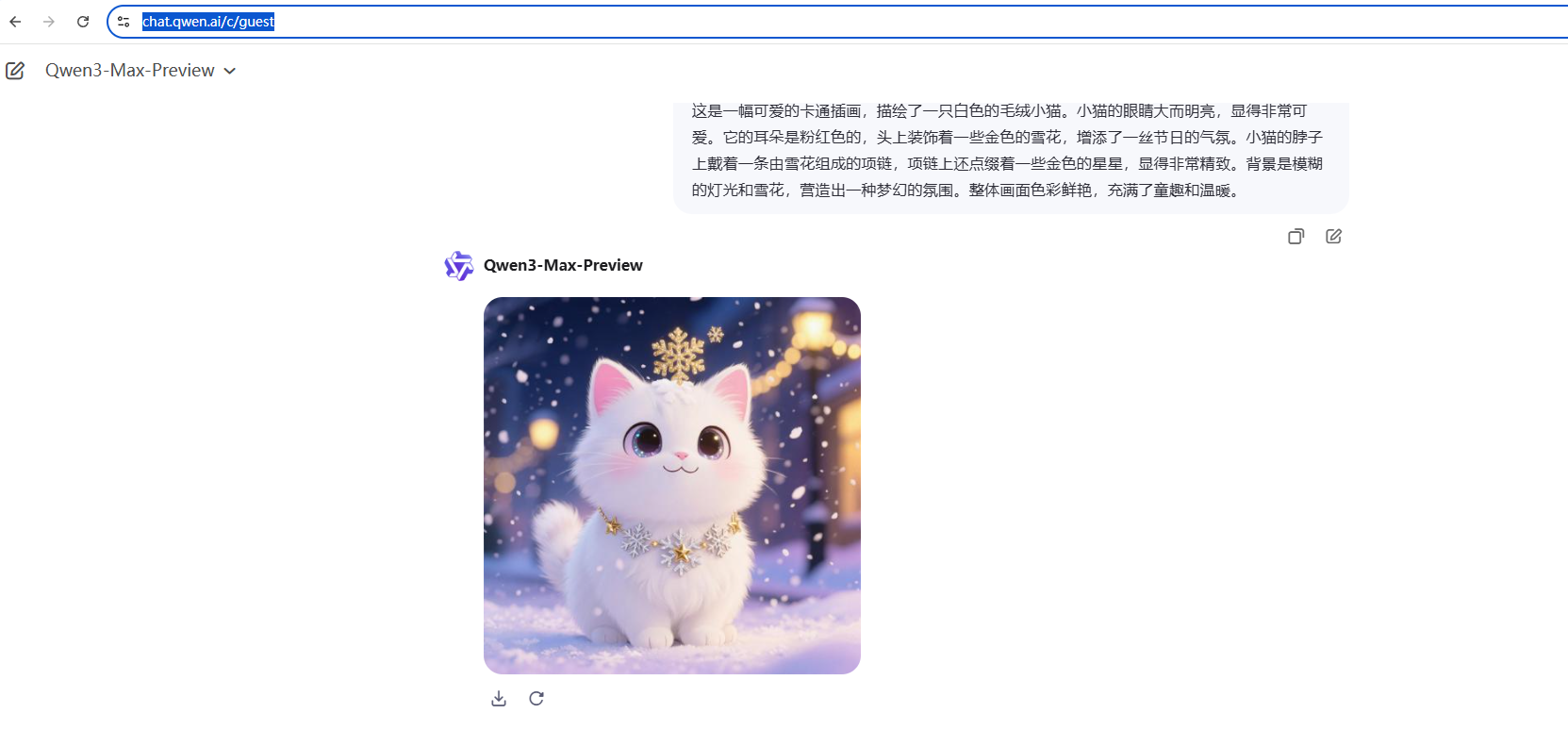
示例2
拍照解题,输入题目图片进行进行解题
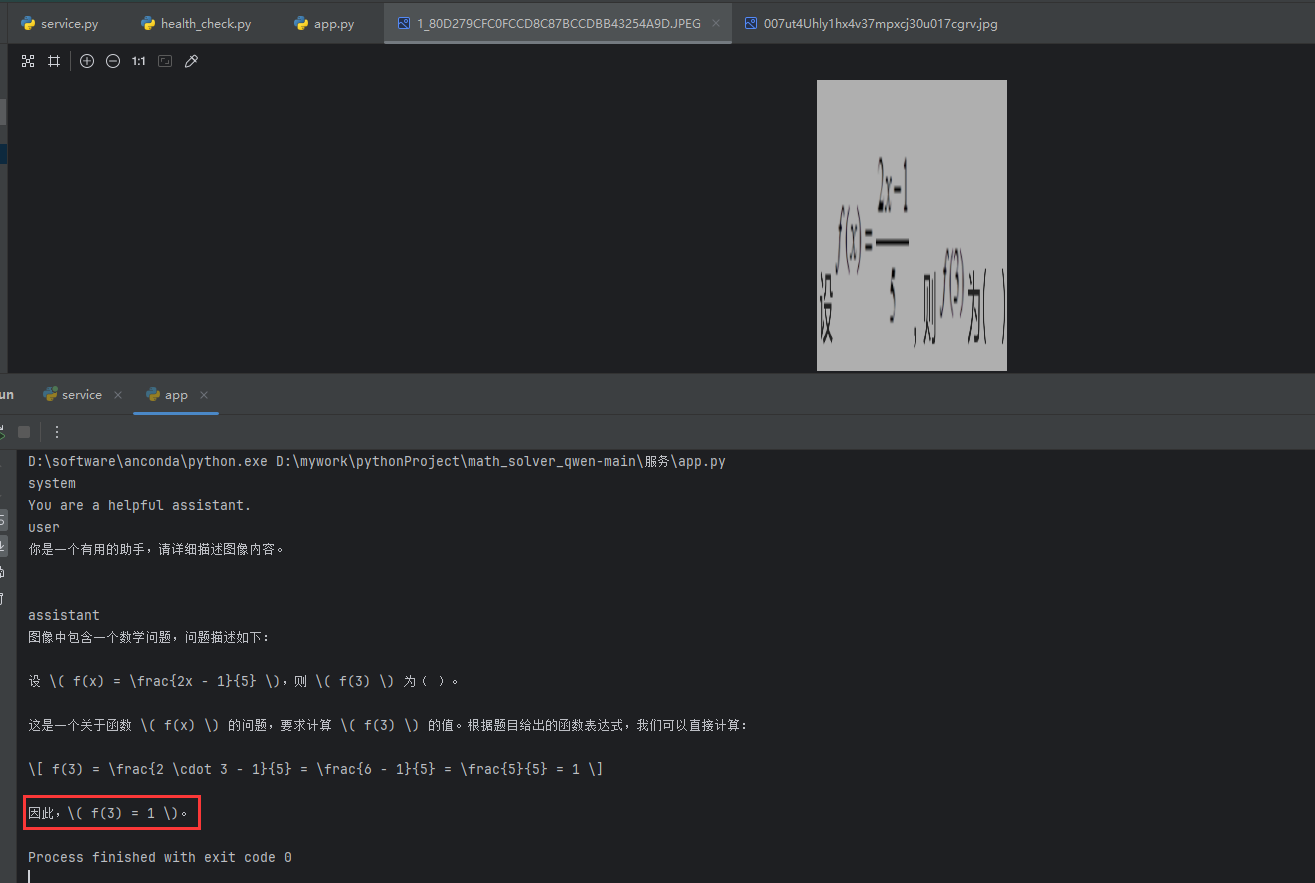
服务端:service.py
import time
import sys
import os
import re
import json
import torch
from PIL import Image
import base64
from io import BytesIO
from flask import Flask, request, jsonify
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
AutoProcessor,
AutoModelForVision2Seq
)
import threading
# 创建Flask应用
app = Flask(__name__)
# 全局变量存储模型实例
vision_model = None
vision_processor = None
device = None
# 初始化锁,防止多线程同时使用模型
model_lock = threading.Lock()
def log(msg, *args, **kwargs):
timestamp = time.strftime("[%Y-%m-%d %H:%M:%S]", time.localtime())
print(f"{timestamp} {msg}", flush=True, *args, **kwargs)
def resize_if_needed(image, max_size=1024):
"""如果图像大于指定尺寸,则按比例缩小"""
width, height = image.size
if width > max_size or height > max_size:
# 计算新的尺寸,保持宽高比
ratio = min(max_size / width, max_size / height)
new_width = int(width * ratio)
new_height = int(height * ratio)
resized_img = image.resize((new_width, new_height), Image.LANCZOS)
return resized_img
return image
def initialize_models():
"""初始化模型"""
global vision_model, vision_processor, device
log("Initializing models...")
# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
log(f"Using device: {device}")
# 初始化视觉模型
try:
vision_model_name = "Qwen/Qwen2-VL-2B-Instruct" # 使用更大的模型以获得更好的通用理解能力
vision_processor = AutoProcessor.from_pretrained(vision_model_name)
vision_model = model = AutoModelForVision2Seq.from_pretrained(vision_model_name, torch_dtype=torch.float16)
# 将模型移动到GPU(如果可用)
model.to(device)
log("Vision model loaded successfully")
except Exception as e:
log(f"Error loading vision model: {e}")
vision_model = None
log("Model initialization completed")
def process_image_and_text(image, text_prompt, max_new_tokens=1024, temperature=0.7):
"""处理图像和文本提示,返回模型响应"""
global vision_model, vision_processor, device
if vision_model is None:
return {"error": "Vision model not initialized"}
try:
# 调整图像大小(如果需要)
image = resize_if_needed(image)
# 构建消息
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": text_prompt},
],
}
]
# 使用处理器准备文本输入
text = vision_processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 使用处理器处理输入
inputs = vision_processor(
text=[text],
images=[image],
padding=True,
return_tensors="pt",
).to(device)
# 生成响应
generated_ids = vision_model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=temperature > 0,
temperature=temperature,
)
# 解码生成的文本
generated_text = vision_processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 提取模型生成的回答部分(去掉输入提示)
# 注意:apply_chat_template 可能会添加特殊标记,所以需要更精确地提取
# prompt_length = len(text)
# if len(generated_text) > prompt_length:
# response = generated_text[prompt_length:].strip()
# else:
response = generated_text.strip()
return {"success": True, "response": response}
except Exception as e:
log(f"Error processing image and text: {e}")
return {"error": f"Error processing image and text: {str(e)}"}
def base64_to_image(base64_str):
"""将base64字符串转换为PIL图像"""
if base64_str.startswith('data:image'):
base64_str = base64_str.split(',', 1)[1]
image_data = base64.b64decode(base64_str)
return Image.open(BytesIO(image_data)).convert('RGB')
@app.route('/health', methods=['GET'])
def health_check():
"""健康检查端点"""
model_loaded = vision_model is not None
return jsonify({"status": "ok", "model_loaded": model_loaded})
@app.route('/v1/chat/completions', methods=['POST'])
def chat_completions():
"""OpenAI API兼容的聊天补全端点"""
# 验证API密钥
auth_header = request.headers.get('Authorization')
if not auth_header or not auth_header.startswith('Bearer '):
return jsonify({"error": "Invalid API key"}), 401
# 解析请求数据
data = request.get_json()
if not data:
return jsonify({"error": "Invalid JSON data"}), 400
# 获取参数
model_name = data.get('model', 'vision-understanding')
messages = data.get('messages', [])
temperature = data.get('temperature', 0.7)
max_tokens = data.get('max_tokens', 1024)
# 解析消息内容
image_data = None
text_prompt = ""
# 提取系统提示和用户消息
system_prompt = ""
user_messages = []
for message in messages:
if message.get('role') == 'system':
system_prompt = message.get('content', '')
elif message.get('role') == 'user':
user_messages.append(message)
# 处理最后一个用户消息(假设包含图像)
if user_messages:
last_message = user_messages[-1]
content = last_message.get('content', '')
if isinstance(content, list):
for item in content:
if item.get('type') == 'text':
text_prompt = item.get('text', '')
elif item.get('type') == 'image_url':
image_url = item.get('image_url', {})
if isinstance(image_url, dict):
image_data = image_url.get('url', '')
else:
image_data = image_url
elif isinstance(content, str):
text_prompt = content
# 添加系统提示到文本提示
if system_prompt:
text_prompt = f"{system_prompt}\n\n{text_prompt}"
# 检查是否有图像数据
if not image_data:
return jsonify({"error": "No image data provided"}), 400
try:
# 转换base64图像数据为PIL图像
image = base64_to_image(image_data)
# 使用锁确保模型不会被多个线程同时使用
with model_lock:
# 处理图像和文本
result = process_image_and_text(
image,
text_prompt,
max_new_tokens=max_tokens,
temperature=temperature
)
if "error" in result:
return jsonify({"error": result["error"]}), 500
# 构建OpenAI API兼容的响应
response_data = {
"id": f"chatcmpl-{int(time.time())}",
"object": "chat.completion",
"created": int(time.time()),
"model": model_name,
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": result["response"]
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}
return jsonify(response_data)
except Exception as e:
log(f"Error in chat completion: {e}")
return jsonify({"error": f"Internal server error: {str(e)}"}), 500
@app.route('/vision/understand', methods=['POST'])
def vision_understand():
"""简化的视觉理解端点"""
# 检查请求内容
if 'image' not in request.files or 'prompt' not in request.form:
return jsonify({"error": "Missing image or prompt parameter"}), 400
# 获取图像和提示
image_file = request.files['image']
prompt = request.form['prompt']
# 获取可选参数
max_tokens = int(request.form.get('max_tokens', 1024))
temperature = float(request.form.get('temperature', 0.7))
try:
# 打开图像
image = Image.open(image_file).convert("RGB")
# 使用锁确保模型不会被多个线程同时使用
with model_lock:
# 处理图像和文本
result = process_image_and_text(
image,
prompt,
max_new_tokens=max_tokens,
temperature=temperature
)
if "error" in result:
return jsonify(result), 500
# 返回结果
return jsonify({
"success": True,
"response": result["response"]
})
except Exception as e:
log(f"Error in vision understand: {e}")
return jsonify({"error": f"Internal server error: {str(e)}"}), 500
if __name__ == '__main__':
# 初始化模型
initialize_models()
# 启动Flask应用
log("Starting Flask server...")
app.run(host='0.0.0.0', port=5000, debug=False, threaded=True)
客户端:app.py
import base64
from openai import OpenAI
# 设置API基本信息
client = OpenAI(
api_key="EMPTY", # 任意字符串
base_url="http://192.168.2.15:5000/v1", # 服务地址
)
# 读取图像并转换为base64
def image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# 构建消息
image_data = image_to_base64("1_80D279CFC0FCCD8C87BCCDBB43254A9D.JPEG")
image_url = f"data:image/jpeg;base64,{image_data}"
messages = [
{
"role": "system",
"content": "你是一个有用的助手,请详细描述图像内容。"
},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url}}
]
}
]
# 发送请求
response = client.chat.completions.create(
model="vision-understanding",
messages=messages,
max_tokens=1024,
temperature=0.7
)
# 输出结果
print(response.choices[0].message.content)
模型下载地址:Qwen/Qwen2-VL-2B-Instruct

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)