Beyond Surface Alignment: Rebuilding LLMs Safety Mechanism via Probabilistically Ablating Refusal
解决大模型表面安全对齐的防御微调方法
@misc{xie2025surfacealignmentrebuildingllms,
title={Beyond Surface Alignment: Rebuilding LLMs Safety Mechanism via Probabilistically Ablating Refusal Direction},
author={Yuanbo Xie and Yingjie Zhang and Tianyun Liu and Duohe Ma and Tingwen Liu},
year={2025},
eprint={2509.15202},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2509.15202},
}
- EMNLP 2025 Findings
Beyond Surface Alignment: Rebuilding LLMs Safety Mechanism via Probabilistically Ablating Refusal Direction

- 开源:github
- 这篇工作是在 [NeurIPS 2024] Improving Alignment and Robustness with Circuit Breakers 基础上的进一步工作。
Abstract
越狱攻击对大型语言模型(LLM)构成了持续的威胁。当前的安全对齐方法试图解决这些问题,但存在两个显著的局限性:安全对齐深度不足和内部防御机制不够稳健。这些局限性使它们容易受到预填充和拒绝方向操纵等对抗性攻击。我们提出了DeepRefusal,这是一个强大的安全对齐框架,能够克服这些问题。DeepRefusal通过在微调过程中跨层和标记深度概率性地消融拒绝方向,迫使模型从越狱状态动态重建其拒绝机制。我们的方法不仅能够防御预填充和拒绝方向攻击,还对其他未见的越狱策略表现出强大的韧性。在四个开源LLM家族和六种代表性攻击上的广泛评估表明,DeepRefusal将攻击成功率降低了大约95%,同时在保持模型能力方面几乎没有性能退化。
1 Introduction
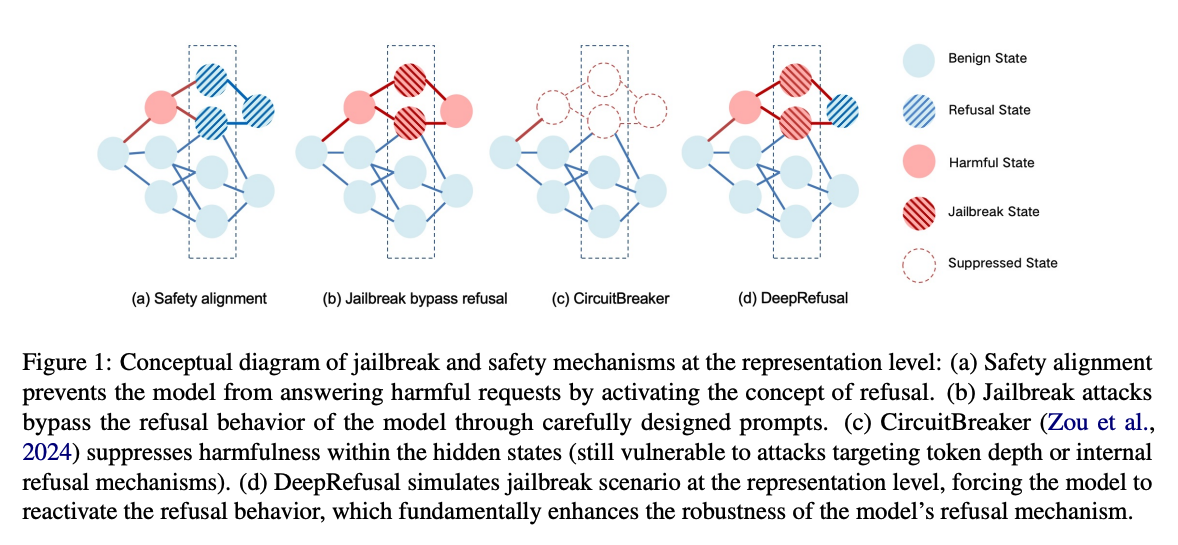
大型语言模型(LLM)在各种自然语言任务中展现出了令人印象深刻的性能,但确保其行为安全可靠仍然是一个重大挑战。安全对齐工作,例如拒绝训练,赋予了 LLM 在面对不适当和有毒提示时提供拒绝回应的能力,如图 1a 所示。然而,这些保护措施在面对对抗性越狱攻击时经常失效,这些攻击通过精心设计的提示来诱导 LLM 绕过拒绝行为,陷入越狱状态,如图 1b 所示。
目前,已经提出了许多防御策略来抵御越狱攻击。对抗性训练试图通过在越狱样本上训练来增强 LLM 对此类攻击的拒绝鲁棒性。CircuitBreaker 通过抑制模型隐藏状态中的有害激活来增强韧性(如图 1c)。然而,我们的实验表明,即使是现有的最先进的防御策略,也容易被预填充攻击和拒绝方向攻击绕过,并且容易受到转移攻击的影响。具体来说,我们发现现有防御主要停留在表面级别,并表现出两个显著的局限性。(1)安全对齐深度不足:当前的安全对齐方法侧重于抑制初始几个回应标记中的毒性,而忽略了后续标记的有害性。因此,LLM 的固有保护可以通过操纵初始回应标记(即预填充攻击)来绕过。(2)内部防御机制不够稳健:浅层的内部防御机制对先进的越狱方法表现出有限的韧性。攻击者可以通过迭代细化输入提示来越狱 LLM。此外,简单的技术,如拒绝方向消融,可以轻易地绕过现有的防御。
为了缓解当前安全对齐方法中存在的这些局限性,我们提出了 DeepRefusal,这是一个用于深度和稳健安全对齐的创新框架。与传统方法仅侧重于表面级别的微调不同,DeepRefusal 将对抗压力直接引入模型的表示空间,如图 1d 所示。通过跨多个层和标记深度概率性地消融拒绝方向,DeepRefusal 有效地在内部模拟潜在的越狱场景。拒绝方向是模型内部表示空间中的一个方向,与产生拒绝回应密切相关。这种独特的方法迫使模型开发出更稳健的拒绝机制,确保其能够在每个标记深度和层深度抵抗有害输出,从而增强其安全对齐能力。
我们的贡献总结如下:
- 我们确定了稳健安全对齐中的两个关键技术挑战,并表明沿着拒绝方向的攻击是对最先进的安全对齐的可转移且未得到充分解决的威胁。
- 我们设计了 DeepRefusal,一个框架,通过在各种标记和层深度模拟对抗条件,训练 LLM 从越狱状态重建安全机制,弥合表面级别对齐和稳健内部防御之间的差距。
- 通过广泛的实验,我们证明了 DeepRefusal 显著提高了对齐鲁棒性,将攻击成功率降低了大约 95%,同时有效防御预填充攻击、拒绝方向攻击,并对其他未见的越狱表现出强大的鲁棒性。
2 相关工作
2.1 LLM 的越狱攻击
尽管 LLM 展示出令人印象深刻的性能,但它们仍然容易受到绕过安全限制的对抗性输入的影响。早期的研究探索了手动构造的提示,以引出有害输出,而最近的方法则采用了自动化方法。GCG 攻击通过基于梯度的优化生成对抗性后缀,而 CodeAttack 利用了代码领域中对齐不足的问题。AutoDAN 利用遗传操作来进化越狱提示,而 PAIR 使用攻击者-受害者循环来迭代细化越狱提示。预填充攻击通过操纵早期标记激活来影响模型输出。最近的研究揭示了拒绝方向可以用于越狱。我们的实验确认这些拒绝方向攻击的成功率高,并且在微调模型中表现出强大的可转移性。此外,我们发现当前最先进的防御技术无法防御此类攻击,突显了在表示级别进行防御的必要性。
2.2 LLM 安全对齐
对 LLM 安全对齐的研究已经产生了一些针对对抗性攻击的防御策略。例如,R2D2 和 CAT 利用对抗性训练,通过引入优化后的提示或输入级别的扰动来增强模型的韧性。与此同时,LAT 专注于通过针对模型的内部残差流来增强模型对有害输出的抵抗能力。然而,这些方法通常需要大量的计算资源。此外,一种在(Qi et al., 2025)中提出的方法旨在通过数据增强实现深度安全对齐,但事实证明它对以前未见过的攻击效果不佳。CircuitBreaker 通过抑制有害的隐藏状态来防御越狱攻击,但往往会生成无意义的输出。这一缺点严重限制了其在需要清晰及时拒绝回应的应用中的实际应用价值。除了上述工作外,一些解决方案侧重于设计输入/输出过滤器以筛选潜在的有害内容,或在推理时干预模型解码。然而,这些方法并没有从根本上增强模型对齐。相反,它们需要额外的组件,从而在测试期间引入额外的开销。需要注意的是,这些方法与安全微调是正交的,可以在测试时一起使用。因此,我们在此不比较我们的方法与这些方法。
2.3 表示工程和拒绝方向
最近,对 LLM 内部表示(即激活)的分析和操作技术引起了广泛关注。(Zou et al., 2023a)正式引入了表示工程(RepE),它借鉴了认知神经科学的见解来提高 AI 系统的透明度。此外,(Arditi et al., 2024)表明 LLM 中的拒绝是由一个单一方向介导的,称为拒绝方向,并阐明了在表示级别上的越狱机制。此外,(Rimsky et al., 2024; Stickland et al., 2024)展示了如何通过在表示级别进行干预来有效控制模型输出行为。我们的方法利用了这些关于越狱和 LLM 安全机制可解释性的见解,以增强模型对齐。
3 观察与动机
3.1 当前安全微调仅针对前几个标记
大多数现有的安全对齐方法存在一个共同的局限性:它们过度依赖于对齐模型生成的初始几个标记。这导致了一个固有的漏洞,称为“对齐深度问题”。这个问题源于一个广泛存在但不切实际的假设:当遇到有害提示时,一个对齐良好的模型应该立即拒绝,即在输出的最开始就产生像“我很抱歉……”这样的拒绝标记。然而,最近的研究表明,一旦这个初始保护被绕过,模型往往可以自由地生成有害内容。
这种行为被几乎所有最近提出的越狱攻击所利用。例如,DeRTa 发现拒绝回应通常将第一个拒绝标记放在前 20 个输出标记内。如果提示成功地在这一早期区域抑制了拒绝行为,那么越狱成功的可能性就会显著增加。同样,Qi 等人通过 KL 散度分析表明,安全微调不成比例地对齐了早期标记,而后续标记则对齐不足。
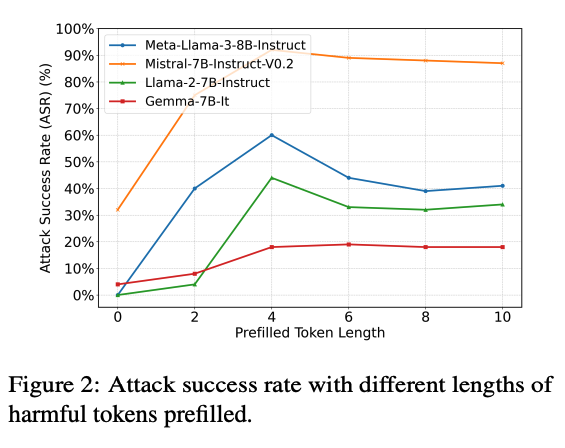
从攻击者的角度来看,Wei 等人认为越狱本质上是关于抑制早期拒绝的。这进一步体现在预填充攻击中,该攻击通过在实际提示之前添加有害上下文来误导模型的早期生成。为了验证这一点,我们进行了如图 2 所示的预填充攻击实验。我们从 AdvBench 中随机选择了 100 个有害指令,并在前面添加了长度不断增加的预填充有害标记。结果表明了一个明显的趋势:随着预填充内容长度的增加,攻击成功率也随之上升。
现有证据共同表明,仅仅依赖于在回应开始处的浅层对齐,远远不足以确保稳健的安全性。这突显了由于对齐深度问题而产生的关键漏洞,并强调了需要更深层次的安全对齐机制的必要性,这种机制应该深入嵌入模型的内部表示中,并贯穿整个回应生成过程的所有阶段。
3.2 越狱抑制拒绝方向的激活
最近的研究表明,LLM 内部编码了一个拒绝方向,这是一个与拒绝生成相对应的独特激活模式。为了提取这一方向,我们采用了 Arditi 等人的方法。具体来说,对于每一层 l ∈ [ L ] l \in [L] l∈[L] 和指令后标记位置 i ∈ [ I ] i \in [I] i∈[I],我们分别计算有害提示的平均激活 μ i ( l ) \mu^{(l)}_i μi(l) 和无害提示的平均激活 ν i ( l ) \nu^{(l)}_i νi(l):

这两个平均向量之间的差异定义了候选的拒绝方向: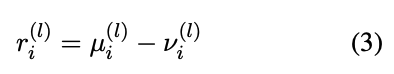
这一过程产生了一个 ∣ I ∣ × L |I| \times L ∣I∣×L 的候选向量数组。按照 Arditi 等人的方法,我们通过启发式过滤来识别最有效的单一方向 r i ∗ ( l ∗ ) r^{(l^*)}_{i^*} ri∗(l∗),依据是其在操纵时诱导或抑制拒绝行为的能力。重要的是,这一分析揭示了越狱提示积极抑制模型内部的拒绝方向。如图 3 所示,在处理对抗性提示时,模型激活与拒绝方向之间的余弦相似度显著下降。这表明越狱不仅仅是提示技巧,它们直接改变了模型内部与安全相关的激活,有效地绕过了其内置的拒绝机制。
这一观察结果得出了一个关键的见解:我们可以通过直接从 LLM 的激活中消融拒绝方向来模拟越狱攻击的最坏影响。与依赖于特定越狱提示的传统训练方法不同,这种激活级别的近似直接聚焦于被越狱攻击利用的核心机制。它消除了对特定攻击方法详细知识的需求,使该方法更具普遍性和可控性。更重要的是,它使模型能够在极端内部条件下重建拒绝行为。这一创新还消除了对大规模越狱语料库的需求,使训练过程更加高效和实用。
4 我们的 DeepRefusal 方法
基于这些观察,我们提出了 DeepRefusal,这是一种用于为 LLM 实现深度和稳健安全对齐的创新方法。DeepRefusal 通过在模型的内部结构中模拟越狱场景,促使模型在不损害其语言建模能力或实用性的情况下,重建和强化其拒绝机制。我们的目标是在训练期间让模型接触到这些模拟的越狱场景,确保模型即使在对抗条件下也能保持稳健的拒绝行为。
在实践中,DeepRefusal 采用两种主要策略来实现这一目标:逐层和逐标记的概率激活消融(PAA)。前者涉及在模型的不同层中概率性地移除激活模式,而后者则专注于在模型输出序列的特定标记位置选择性地消融激活。通过整合这些策略,我们确保模型能够遇到各种模拟的对抗性攻击。这种全面的方法迫使模型发展出针对各种越狱技术的稳健防御,从而即使在具有挑战性的场景中也能保持安全和可靠的性能。
4.1 获取拒绝方向
DeepRefusal 的一个关键方面是获取一个真正代表拒绝概念的方向。这个方向必须能够在无害和有害样本上一致地诱导拒绝行为:当添加时,它鼓励模型拒绝;当消融时,它阻止模型拒绝。鉴于 LLM 中不同的标记位置和层可能提供大量的潜在方向,我们使用启发式过滤方法来识别最具代表性的拒绝方向。
具体来说,我们根据候选方向在多样化提示集上一致触发或抑制拒绝回应的能力来评估它们。具体而言,我们定义拒绝方向为满足以下两个关键标准的向量 r:
(1)添加约束:添加此方向应始终触发拒绝回应,即使对于无害提示也是如此。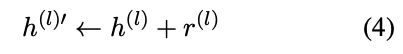
(2)消融约束:移除此方向应绕过拒绝机制,使模型能够回应有害提示。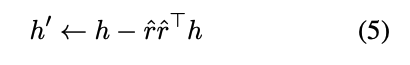
从一组候选方向 r i ( l ) {r_i^{(l)}} ri(l) 中,我们选择最能满足这两个约束条件的单一方向 r i ∗ ( l ∗ ) {r_{i^*}^{(l^*)}} ri∗(l∗)(记作 r ^ \hat{r} r^ )。此外,我们尝试在微调过程中动态改变拒绝方向,但我们发现通过这种方式获得的方向非常不稳定,难以实时满足上述两个约束条件。最终,我们选择离线预先计算最优单一拒绝方向。这一选择确保了消融的方向一定是拒绝方向,减少了对其他概念表示和语言建模的副作用。我们的实验表明,使用离线拒绝方向足以提高对齐效果。
4.2 通过逐层 PAA 模拟越狱
为了在模型的内部隐藏状态中模拟越狱场景,并促使模型重建其拒绝机制,我们在每个 L 层独立地以概率 p 实施激活干预。具体来说,我们将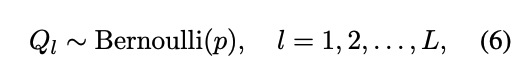
作为指示层 l 是否被干预的指标。Qi=1表示我们在层 l 应用方向性激活消融。因此,公式(5)可以重新表述为: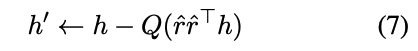
逐层 PAA 允许我们概率性地移除模型不同层中的激活模式。这模拟了模型在不同层的内部安全机制被破坏的对抗条件。通过这种方式,模型被迫在其整个层深度上强化其拒绝行为。这一过程显著提高了模型对潜在越狱攻击的鲁棒性。
4.3 通过逐标记 PAA 模拟越狱

逐标记 PAA 有选择地针对模型输出序列中的特定标记位置。这种策略直接解决了当某些标记被操纵或抑制时模型生成有害内容的脆弱性。通过专注于这些关键位置,模型被训练来识别并对抗这种对抗性操纵。因此,它学会了在整个标记生成过程中始终保持稳健的拒绝行为,从而显著提高了模型的安全性和可靠性。
4.4 DeepRefusal 的训练过程


我们使用公式(11)来模拟预填充攻击,其中有害前缀被添加到回应中。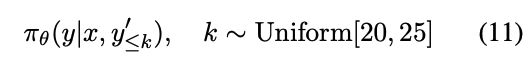
为了微调模型以抵御此类攻击,我们使用以下目标函数: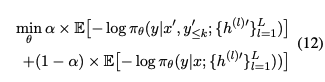

算法 1 概述了 DeepRefusal 的整个过程。它首先按照 Arditi 等人的方法获得全局拒绝方向 r ^ \hat{r} r^。然后,它使用概率激活消融和有害前缀增强来微调模型。PAA 应用于注意力(attn)、多层感知器(mlp)和残差流模块,提供更全面的防御。我们进一步通过有害前缀增强训练数据,以确保模型即使在遇到被操纵的输入时也能保持其拒绝行为。通过整合这些技术,DeepRefusal 有效地增强了模型的对齐和鲁棒性,抵御了一系列越狱攻击,这与传统的表面级别微调有着根本的不同。

5 实验
5.1 实验设置
背景模型
我们在四个具有代表性的开源 LLM 上进行了评估,分别是 Llama3-8B-instruct、Llama2-7B-instruct、Mistral-7B-Instruct-v0.2 和 Gemma-7B-it。这些模型在架构和训练数据上存在差异,能够全面评估 DeepRefusal 在不同 LLM 背景下的有效性。
训练配置
所有模型均使用一块 NVIDIA A100 80GB GPU 进行微调。训练过程持续 1 个 epoch,大约耗时 45 分钟。我们采用了 LoRA 技术,其超参数与 CircuitBreaker 保持一致:LoRA alpha=16,LoRA rank=16。训练时的批量大小为 16。值得注意的是,PAA 概率 p=0.5 在实验中表现出了最佳性能。
数据集
训练集由 2000 个来自 CircuitBreaker(Zou et al., 2024)的有害样本组成,这些样本利用公式(11)进行了预填充增强,以及 4000 个来自 UltraChat(Ding et al., 2023)的良性样本。为了应对过度拒绝的问题,我们还额外加入了 500 个来自 XSTest(Röttger et al., 2024)和 Or-bench(Cui et al., 2025)的样本。
测试时,我们从 AdvBench(Zou et al., 2023b)、HarmBench(Mazeika et al., 2024)和 JailbreakBench(Chao et al., 2024)中各抽取了 500 个样本,以评估模型的防御能力。在手动攻击评估中,我们将抽取的样本与来自 HarmBench 的 HumanJailbreak 模板相结合。对于 GCG 攻击的评估,我们仅限于 100 个有害样本。此外,在过度拒绝评估中,我们随机从 XSTest 和 Or-bench 中抽取了 200 个提示。需要注意的是,用于在训练期间缓解过度拒绝的数据与过度拒绝测试数据不同。
攻击方法
我们对 DeepRefusal 在以下七种具有代表性的攻击向量下进行了评估:无攻击、手动(来自 HarmBench 的 HumanJailbreaks)、CodeAttack(来自 Ren et al., 2024 的分布外攻击)、GCG(基于梯度的优化)、拒绝、拒绝转移以及预填充攻击(Vega et al., 2024)。
防御基线
我们将 DeepRefusal 与五种具有代表性的防御方法进行了比较。(1)RT:拒绝训练;(2)RT-Augmented:带有有害前缀增强的拒绝训练(Qi et al., 2025);(3)LAT:潜在对抗训练(Sheshadri et al., 2024);(4)CAT:连续对抗训练(Xhonneux et al., 2024);(5)CircuitBreaker:(Zou et al., 2024)。RT 和 RT-Augmented 使用与 DeepRefusal 相同的训练集。
评估指标
我们使用了三类指标。(1)ASR(攻击成功率):成功攻击的百分比(越低越好);(2)能力:在 MMLU(Hendrycks et al., 2021)、GSM8k(Cobbe et al., 2021)和 MT-bench(Zheng et al., 2023)基准测试中的表现(越高越好);(3)过度拒绝:错误拒绝无害查询的比率(越低越好)。
5.2 结果与分析
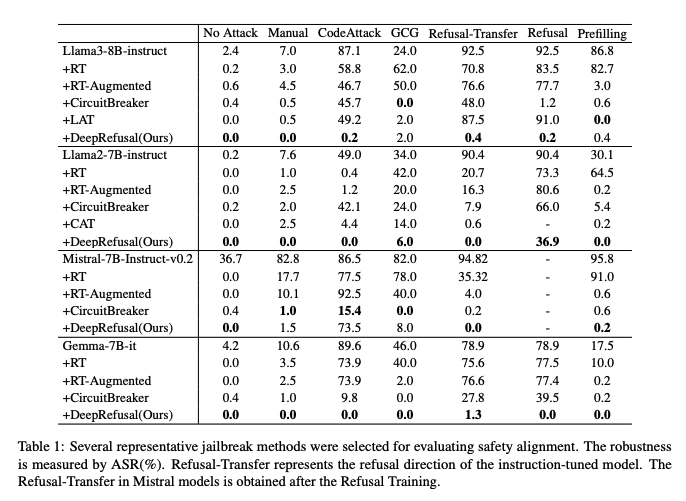
攻击成功率
如表 1 所示,DeepRefusal 显著降低了所有模型和攻击类型的攻击成功率(ASR)。例如,在 Llama3-8B 上,DeepRefusal 将 CodeAttack 的 ASR 从 87.1%(指令模型)降低到了微不足道的 0.2%。值得注意的是,DeepRefusal 在对抗拒绝攻击方面表现出色,包括在拒绝转移设置中,而其他方法未能提供类似的韧性。然而,CircuitBreaker 在 Llama3-8B-Instruct 模型上容易受到拒绝转移攻击的影响。我们进一步在附录 B 中评估了针对替代拒绝方向构建的鲁棒性,并在附录 C 中检验了我们方法的跨语言泛化能力。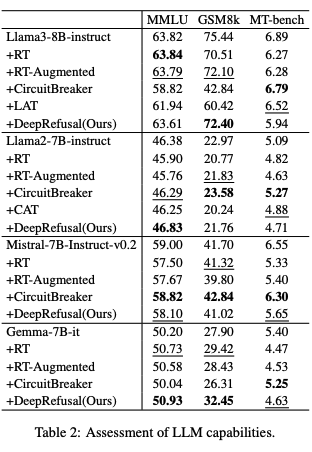
能力保持
表 2 显示,DeepRefusal 在保持模型能力方面仅出现了最小程度的退化。对于 Llama3-8B,DeepRefusal 保持了 MMLU 为 63.61(与基础 63.82 相比)和 GSM8k 为 72.40(与基础 75.44 相比)。这意味着它仅略微降低了数学推理能力,同时保持了对一般知识的掌握。相比之下,CircuitBreaker 对能力的影响显著,特别是在 GSM8k 上(42.84 与基础 75.44 相比)。这种性能下降可能源于 CircuitBreaker 生成无意义输出,表明抑制有害激活可能会无意中破坏语言建模。值得注意的是,过度拒绝率在附录 A 中并未导致显著改进。
5.3 消融研究
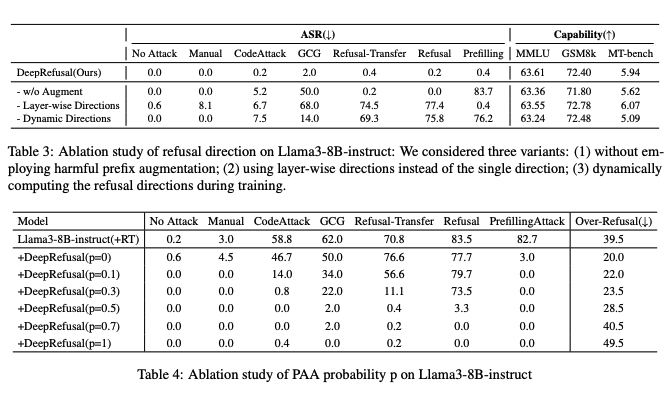
我们系统地评估了 DeepRefusal 方法的三个关键设计组成部分对 Llama3-8b-instruct 模型的影响。具体来说,我们研究了以下三种配置。(1)不使用有害前缀增强:我们移除了有害前缀增强机制 ( x ′ , y < k ′ , y ) (x′,y'_{<k},y) (x′,y<k′,y)。(2)逐层方向:代替使用单一拒绝方向,我们采用逐层方向。这种变体探索了是否允许每一层学习独立的拒绝方向可以增强模型的鲁棒性。(3)动态方向:按照 Yu et al.(2025)的方法,我们在训练过程中动态计算拒绝方向。
表 3 的结果显示,移除有害前缀增强会降低对 GCG 攻击的韧性。逐层方向和动态方向变体的表现均不如 DeepRefusal。我们提出的设计,使用单一静态拒绝方向并结合有害前缀增强,实现了鲁棒性和通用能力之间的最佳平衡。
我们进一步检验了 PAA 概率 p 的影响,如表 4 所示。结果表明,较小的 p 值会使模型在对抗条件下训练不足,而较大的 p 值会导致过度拒绝过多。设置 p=0.5 提供了最佳平衡。
6 结论
我们的研究揭示了当前安全对齐方法存在显著的缺陷,表明现有的防御措施容易受到通过拒绝方向的越狱攻击的影响,这些攻击甚至可以被用于转移攻击。为了解决这一问题,我们提出了 DeepRefusal,这是一种新颖的防御方法,通过在不同的标记和层深度消融拒绝方向来模拟对抗条件,从而迫使模型发展出更深层次、更稳健的拒绝机制。DeepRefusal 为训练 LLM 从越狱状态重建安全机制提供了一种合理的方法,弥合了表面级别对齐和稳健内部防御之间的差距。
实验结果表明,DeepRefusal 在多个模型上针对各种攻击实现了最佳的防御性能。我们的 DeepRefusal 方法得益于 LLM 可解释性的进步,并超越了表面对齐,是可解释性研究如何增强安全对齐的一个有力例证。在未来的工作中,我们计划将 DeepRefusal 扩展到多模态场景中,在这些场景中,安全对齐的挑战更为复杂。
限制
尽管 DeepRefusal 显著增强了 LLM 的防御能力,但它也存在一定的限制。首先,我们的方法从根本上依赖于模型中的拒绝方向。这意味着将其扩展到多模态模型需要先将这些拒绝方向扩展到多模态上下文中。其次,模型大小、架构和训练数据的变化会影响防御性能。具体来说,包含旨在减轻过度拒绝的高质量数据对于降低过度拒绝率至关重要。
伦理声明
我们的工作识别出了一种针对安全对齐的转移攻击。然而,由于这种攻击需要操纵模型的隐藏状态,这是一种不切实际的强大攻击设置,因此它不适用于黑盒设置。尽管这一发现可能会为未来的越狱尝试提供信息,但它并不会显著增加 LLM 的实际风险。尽管我们的发现强调了当前安全机制的漏洞,但我们认为我们的工作积极地促进了对这些风险的理解。这种理解对于推进更稳健和安全的 AI 至关重要。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)