【AI论文】ReSum:通过上下文摘要解锁长视野搜索智能
摘要:本研究提出ReSum范式解决大语言模型(LLM)网页智能体在复杂查询中的上下文窗口限制问题。通过定期摘要交互历史为紧凑推理状态,ReSum实现无限探索能力。配套开发的ReSumTool-30B摘要模型和ReSum-GRPO训练算法(结合GRPO强化学习与分段轨迹优化),使智能体适应摘要条件下的推理。实验显示,ReSum较ReAct范式平均提升4.5%,经ReSum-GRPO训练后提升达8.2
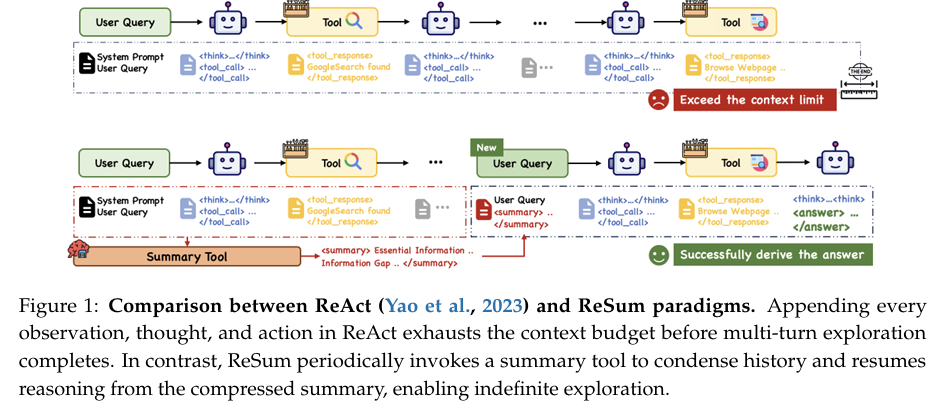
摘要:基于大语言模型(LLM)的网页智能体在知识密集型任务中表现出色,但在ReAct等范式中受限于上下文窗口容量。涉及多实体、复杂关联关系及高度不确定性的复杂查询,需要大量搜索周期,而智能体往往在找到完整解决方案前就已耗尽上下文预算。为应对这一挑战,我们提出ReSum这一新型范式,通过周期性上下文摘要实现无限探索。ReSum将不断增长的交互历史转换为紧凑的推理状态,在保持对先前发现信息认知的同时绕过上下文限制。针对范式适配问题,我们提出ReSum-GRPO,将GRPO(一种强化学习算法)与分段轨迹训练及优势广播相结合,使智能体熟悉基于摘要条件的推理。在三个基准测试中对不同规模的网页智能体开展的大量实验表明,ReSum相较于ReAct平均绝对提升达4.5%,经ReSum-GRPO训练后性能可进一步提升高达8.2%。值得注意的是,仅使用1000个训练样本,我们的WebResummer-30B(基于WebSailor-30B经ReSum-GRPO训练的版本)在BrowseComp-zh上达到33.3%的Pass@1指标,在BrowseComp-en上达到18.3%,超越了现有开源网页智能体。Huggingface链接:Paper page,论文链接:2509.13313
研究背景和目的
研究背景:
近年来,基于大型语言模型(LLM)的智能体在处理复杂、知识密集型任务时表现出色,尤其是在网络搜索和网页浏览领域。这些智能体能够主动搜索和浏览开放网络,从多种来源中提取并验证事实,合成既符合用户需求又最新的答案。然而,对于涉及多个实体、错综复杂关系以及高度不确定性的复杂查询,智能体需要经过多轮有针对性的查询、浏览、提取和交叉验证,才能逐步减少不确定性并构建完整、有根据的证据链。这一过程中,LLM的上下文窗口限制成为了一个主要障碍,因为大多数LLM的上下文窗口有限(如32k个token),而传统的ReAct范式通过不断追加每一次的观察、思考和行动到对话历史中,在完成多轮探索之前就会迅速耗尽上下文预算,导致在找到完整答案之前就被迫终止。
研究目的:
为了解决上述挑战,本研究引入了ReSum范式,旨在通过定期的上下文摘要实现无限探索。ReSum将不断增长的交互历史转化为紧凑的推理状态,保持对先前发现的意识同时绕过上下文限制。此外,为了使智能体能够适应ReSum范式,研究提出了ReSum-GRPO算法,通过分段轨迹训练和优势广播,使智能体熟悉基于摘要的推理。最终,通过广泛的实验,研究验证了ReSum在多个不同规模的网页智能体上的有效性,相较于ReAct范式,ReSum平均实现了4.5%的绝对提升,在ReSum-GRPO训练后,进一步提升最高达8.2%。
研究方法
1. ReSum范式:
ReSum范式通过定期调用摘要工具来压缩对话历史,形成紧凑的推理状态,使智能体能够从压缩后的摘要重新开始推理,从而实现无限探索。具体实现中,当对话历史超过上下文限制时,会触发一个摘要工具,将累积的对话压缩成结构化摘要,并形成新的查询状态,重置工作历史,继续探索。
2. ReSumTool-30B的开发:
为了实现上下文摘要功能,研究通过微调Qwen3-30B-A3B-Thinking模型,使用从强大的开源模型中收集的⟨对话,摘要⟩对,这些数据对用于训练ReSumTool-30B,使其专门提取关键证据和线索、识别信息差距并突出下一步的方向。这一专门训练使ReSumTool-30B在网页搜索的上下文摘要任务中表现出色,结合了轻量部署和任务特定增强,其摘要质量超过了更大的模型如Qwen3-235B和DeepSeek-R1-671B。
3. ReSum-GRPO算法:
为了使智能体适应ReSum范式,研究采用了强化学习(RL)方法,设计了ReSum-GRPO算法。该算法结合了GRPO(Generalized Policy Optimization)方法,并进行了适应性修改,包括分段轨迹训练和优势广播机制。在分段轨迹训练中,每个段作为一个独立的训练片段,并通过广播轨迹级别的优势来鼓励智能体从压缩状态中有效推理并收集高质量摘要。
研究结果
ReSum范式性能提升:
实验结果表明,ReSum范式在各种规模的网页智能体上相较于ReAct范式有显著提升。具体而言,在BrowseComp-zh、BrowseComp-en和GAIA三个基准测试中,ReSum实现了平均4.5%的提升,在ReSum-GRPO训练后,进一步提升最高达8.2%。例如,仅使用1K个训练样本,WebResummer-30B(一个基于ReSum-GRPO训练的WebSailor-30B版本)在BrowseComp-zh上实现了33.3%的Pass@1,在BrowseComp-en上实现了18.3%的Pass@1,超过了现有的开源网页智能体。
ReSum-GRPO训练效果:
ReSum-GRPO算法成功使智能体熟悉了ReSum范式,实现了更显著的性能提升。例如,在WebSailor-3B上,ReSum-GRPO训练后Pass@1从8.2%提升至20.5%,在BrowseComp-zh上从13.7%提升至24.1%。
研究局限
1. 训练数据量有限:
尽管ReSum-GRPO算法在有限训练数据下表现良好,但受限于训练样本量(仅1K个样本),这在一定程度上限制了模型的进一步优化和泛化能力。未来研究可考虑增加训练数据量以提高模型性能。
2. 上下文摘要准确性:
尽管ReSumTool-30B在摘要生成方面表现出色,但其准确性仍有提升空间。未来的研究可进一步优化摘要工具,提高信息提取的准确性和完整性。
3. 模型泛化能力:
目前的研究主要集中在特定任务和基准测试上,未来研究可探索将ReSum和ReSum-GRPO算法应用于更多样化的任务和实际场景中,提高模型的泛化能力和适应性。
未来研究方向
1. 更大规模的实验验证:
未来研究可在更多数据集和更复杂的任务上验证ReSum和ReSum-GRPO算法的有效性,包括跨不同任务类型和不同规模的智能体。
2. 模型优化与轻量化部署:
针对ReSumTool-30B等模型,未来可进一步优化模型结构,提高摘要质量和推理效率。同时,探索模型的轻量化部署方案,降低模型部署成本,提高实际应用中的可行性和经济性。
3. 多模态与跨领域应用:
未来可探索将ReSum范式应用于多模态任务中,如结合图像、视频等信息进行综合摘要和推理。同时,考虑跨领域应用,如医疗、教育等,验证ReSum范式的通用性和有效性。
4. 智能体的自我总结能力提升:
未来可研究如何使智能体在没有人工干预的情况下,更智能地自我发起总结调用,减少对基于规则的总结触发机制的依赖。
总之,本研究通过引入ReSum范式和ReSum-GRPO算法,有效解决了LLM智能体在复杂网络搜索中的上下文限制问题,为未来智能体技术的发展提供了新的方向和思路。未来的研究将在此基础上进一步探索模型优化、多模态应用和智能体自我总结能力的提升,推动智能体技术在更多领域中的广泛应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献147条内容
已为社区贡献147条内容

所有评论(0)