InternVLA-N1:基于学习潜规划的开放式双-系统视觉-语言导航基础模型
25年9月来自上海 AI 实验室的论文“InternVLA-N1: An Open Dual-System Vision-Language Navigation Foundation Model with Learned Latent Plans”。InternVLA-N1 是首个开放的双-系统视觉-语言导航基础模型。与以往只能在有限的离散空间中采取短期行动的导航基础模型不同,InternVLA-
25年9月来自上海 AI 实验室的论文“InternVLA-N1: An Open Dual-System Vision-Language Navigation Foundation Model with Learned Latent Plans”。
InternVLA-N1 是首个开放的双-系统视觉-语言导航基础模型。与以往只能在有限的离散空间中采取短期行动的导航基础模型不同,InternVLA-N1 将任务解耦为使用系统 2 进行像素目标规划和使用系统 1 进行敏捷执行。该框架设计一个课程两-阶段训练范式:首先,使用明确的像素目标作为监督或条件对两个系统进行预训练。随后,冻结系统 2,并以异步端到端的方式使用系统 1 对新增的潜规划进行微调。这种依赖潜规划作为中间表示的范式消除像素目标规划的模糊性,并为通过视频预测进行预训练扩展提供潜力。为了实现可扩展的训练,在模拟中开发一个高效的导航数据生成流程,并引入迄今为止最大的导航数据集 InternData-N1。 InternData-N1 包含从 3,000 多个场景收集的超过 5,000 万张以自我为中心的图像,总计 4,839 公里的机器人导航经验。在 6 个极具挑战性的导航基准测试中对 InternVLA-N1 进行评估,其始终保持着最佳性能,性能提升幅度在 3% 到 28% 之间。值得一提的是,尽管仅使用模拟数据进行训练,但它可以在各种机器人形态(轮式、四足动物、人形机器人)和野外环境中进行零样本泛化,并在现实世界中展现长距离规划(>150 米)和实时决策(>30Hz)能力的协同集成。所有代码、模型和数据集均已公开发布。
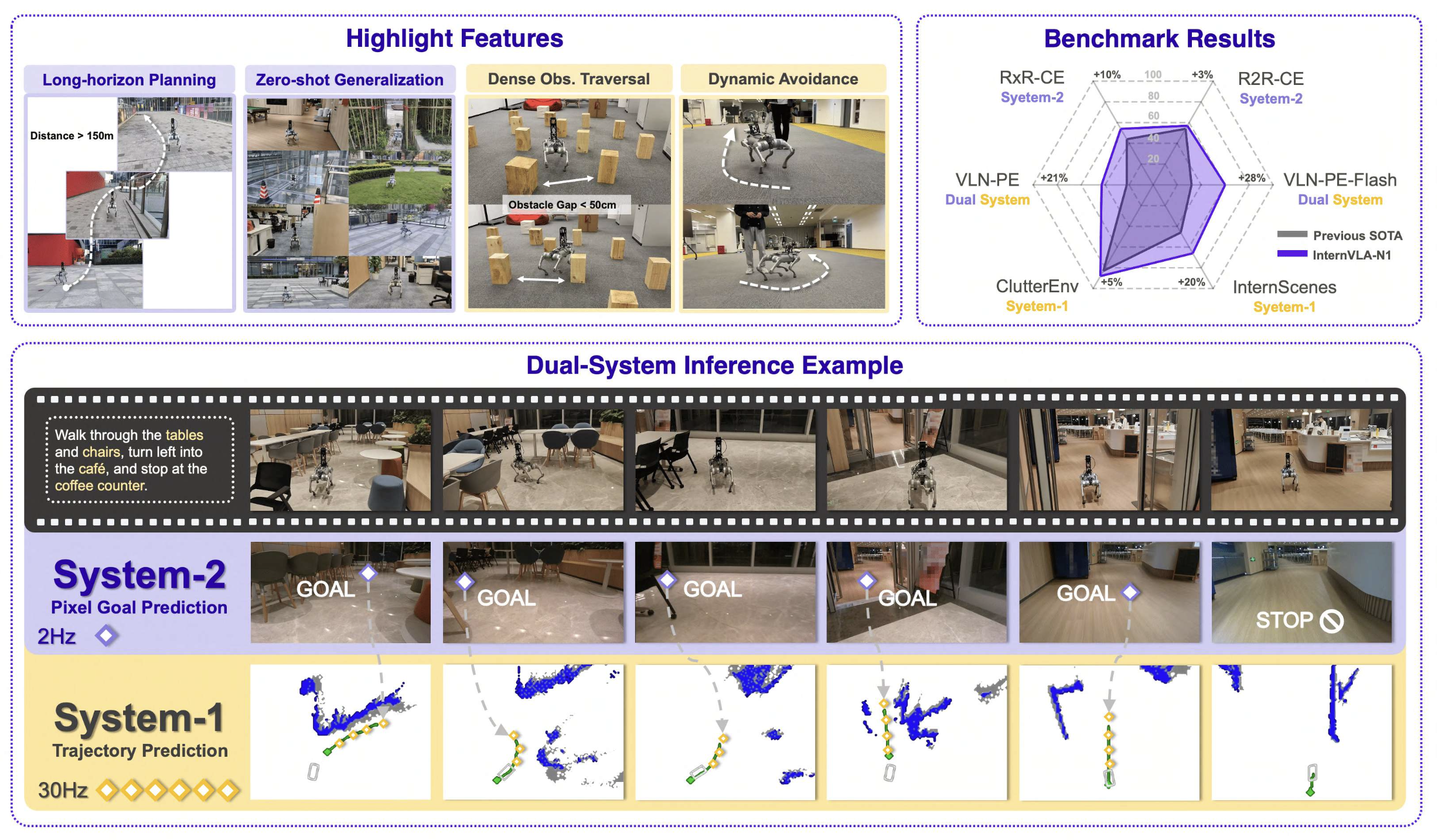
如图所示:InternVLA-N1 的特征和例子
导航是机器人技术的一项基本任务。在实践中,导航系统通常将语言指令和视觉观察结果作为输入,并相应地执行规划的轨迹。近年来,该领域取得了长足的进步,从基于离散目标规划的基准构建探索(Anderson (2018a);Ku (2020)),到连续动作空间(Krantz (2020b)),以及基于运动控制器的物理真实感模拟(Cheng (2025);Wang (2025b))。另一方面,多模态 LLM 提供潜力,使其能够在模拟中训练此类模型,同时凭借其强大的先验知识推广到开放的现实世界。研究界对此表现出越来越浓厚的兴趣(Cheng (2025);Wei (2025);Zhang (2025a);Zheng (2025)。 (2024),并已在此方向上进行成功的初步尝试,并在包括四足机器人和人形机器人在内的各种实例进行演示。
然而,尽管这些模型是在 VLN-CE(Krantz 2020b) 等连续环境基准上开发的,但它们的动作空间被简化为离散的选择,并以端到端的方式进行预测。因此,它们只能在有限的空间内采取短期行动步骤,并且在推理速度和碎片化导航行为方面存在困难。直观地说,与从视觉观察和语言指令到直接动作输出的这种硬映射相比,更原生的目标类型应该是中期目标,尤其是在图像像素上,它指示机器人应该去哪里,并且可以与多模态 LLM 的视觉落地能力保持一致。同时,设计另一个高频局部规划器来执行朝着中期目标的路径规划,并灵活地避开动态障碍物。最终,整个框架的执行机制类似于人类认知理论 Kahneman(2011)的“系统 1 执行与系统 2 思考”。在构建VLA模型方面,已有多项尝试,例如Helix (FigureAI 2025)、GR00T (Bjorck 2025)、Hi Robot (Shi 2025)和 OneTwoVLA (Lin 2025b)。
视觉-语言导航。视觉-语言导航 (VLN) 是一项长视界指令跟踪任务,需要机器人进行精确规划和跟踪。早期方法通过采用离散设置来简化问题 Anderson (2018a); Ku (2020); Qi (2020),其中智体在导航图中的预定义节点之间传送。这种抽象绕过了现实世界中的关键挑战,例如避障和路径规划。为了更好地模拟现实世界的情况,引入了连续环境中的视觉-语言导航 (VLN-CE) Krantz (2020b); Savva (2019),其中智体使用低级离散控制动作进行操作。此后,人们提出了许多方法 An (2022, 2023); Hong (2022); Irshad (2022); Krantz & Lee (2022); Krantz (2021); Raychaudhuri (2021); Wang (2023b) 的研究,稳步提高模拟环境中的导航精度。然而,对特定于任务的网络架构和有限的训练数据的依赖仍然阻碍着零样本泛化和模拟-到-现实的迁移。为了解决这些限制,最近的智体方法 Chen (2024, 2025); Lin (2025a); Long (2024c,d); Qiao (2024); Zhang (2025b); Zhou (2023, 2024) 利用通用基础模型,在现实世界的 VLN 任务中展示了改进的性能和鲁棒性。然而,由于无法访问用于下游任务微调的多样化数据,此类通用基础模型与导航领域的一致性仍然很差。
视觉导航策略学习。视觉导航技能负责实现明确的目标并执行实时避障。传统的模块化方法,如 Fox (1997);Karaman & Frazzoli (2011);Kramer & Stachniss (2012);Williams (2015);Zhou (2020),依赖于显式定位和地图构建来完成导航任务。然而,这些系统通常会受到级联模块引入的复合误差和延迟的影响,并且通常需要进行大量的超参数调整才能适应不同的机器人平台。为了应对这些挑战,最近的研究探索基于端到端学习的方法。例如,GNM Shah (2023a)、X-Nav Wang (2025a)、RING Eftekhar (2024) 和 X-Mobility Liu (2024) 专注于改进不同实施例中的零样本策略泛化能力。其他方法,如 iPlanner Yang (2023)、ViPlanner Roth (2024)、FDM Roth (2025) 和 S2E He (2025) 研究了高效的训练范式,并增强了点-目标导航中的模拟-到-现实的迁移。同时,SLING Wasserman (2023)、ViNT Shah (2023b)、NoMad Sridhar (2024) 和 NaviDiffuser Zeng (2025) 等方法专注于图像-目标导航。
用于导航的视觉-语言-动作模型。近期研究越来越多地利用多模态大模型作为导航任务的预训练主干网络,旨在利用主干网络中固有的常识性知识来提升导航性能。一种常见的方法是将导航动作表述为文本,从而将任务统一为大语言模型 (LLM) 中的下一个 token 预测问题。例如,Gao (2025);Wang (2025c);Wei (2025);Zhang (2024, 2025a) 和 Zheng (2024) 的一系列工作,采用与 VLN-CE 相同的离散动作空间,并定义相应的词汇表,将其用作 LLM 的响应标签。相比之下,RoboPoint Yuan (2025) 和 NaviMaster Luo (2025) 通过将导航构建为像素落地任务,规避离散动作空间的局限性。然而,动作执行仍然需要额外的模块,例如相机标定和点-目标导航策略。近期的方法,如 UniVLA Bu (2025) 和 TrackVLA Wang (2025d) 采用端到端范式,将从大语言模型 (LLM) 中提取的潜特征直接映射到机器人可执行的连续轨迹。然而,这些方法通常依赖于同步框架,这限制了它们在动态开放世界中做出高频决策的能力。尽管近期已有研究探索慢-快的双-系统架构(Bu et al. (2024); FigureAI (2025); Shi et al. (2025)),但这些方法主要针对桌面操作任务,而未能解决长上下文记忆建模和未知场景探索的挑战。
本文提出 InternVLA-N1,一个开放的双-系统视觉-语言导航基础模型,它将学习到的潜规划作为中间表示。与桌面操作等完全可观察环境中的规划不同,InternVLA-N1中的系统 2 需要在部分可观察和移动外感受视角的条件下,基于语言指令进行多轮精确规划。同时,系统 1 负责在现实环境中执行这些规划,并稳健地处理行人等动态干扰。
为了应对这些挑战,将系统 2 设计为像素目标规划器,利用多模态 LLM 作为主干网络,充分利用其固有的常识知识和多模态感知能力。将像素目标定义为投影在二维图像平面上的首选导航点。作为补充,系统 1 被设计为一种轻量级的、基于扩散的视觉导航策略,能够根据系统 2 生成的目标进行实时路径规划。这两个系统都首先经过预训练,形成基本的导航能力。系统 2 被训练为将像素落地能力与 VLN 域对齐,而系统 1 被训练为以明确的目标(包括像素目标坐标)为条件,并生成朝向目标的无碰撞导航路径。
为了解决这些问题,引入一个额外的微调阶段,该阶段支持异步推理,并增强两个系统之间中间目标接口的空间表征。具体而言,在微调过程中,系统 1 持续接收最新观测值,而系统 2 则处理延迟输入。这种设置促使系统 1 动态估计目标完成情况并适应异步执行速度。此外,用可学习的潜 token 替换显式像素目标,通过联合调整实现更具信息量的隐规划参考。为了增强和验证潜表征,训练一个基于潜规划的世界模型,以扩展预测后续的以自我为中心的观测序列。实验表明,该世界模型能够构想一致且高质量的以自我为中心的观测序列,以实现规划目标。视频预测目标有助于从潜 token 中提取空间信息,并加速联合调整过程的效率,从而形成一个基于真实世界视频数据的可扩展训练范式。
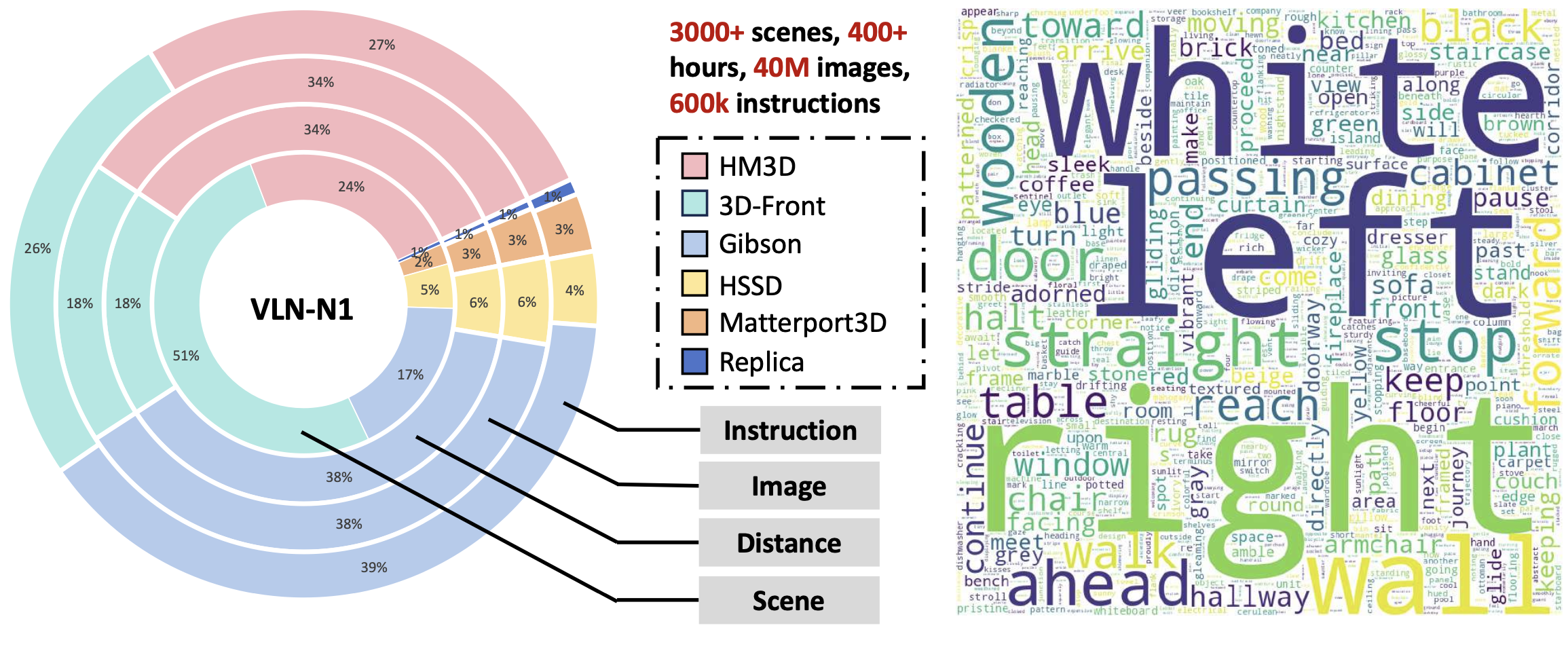
为了支持上述预训练和联合微调,开发一套高效的仿真数据生成流程,单机每日可生成 5 万条导航轨迹。该流程结合自动指令 token 和数据滤波流程,构建大规模导航数据集 InternData-N1,其中包含超过 5300 万条以自我为中心的图像观测数据和 80 万条语言指令,涵盖 3000 多个室内场景,相当于约 4839 公里的机器人导航经验。
实验结果表明,InternVLA-N1 在六个极具挑战性的基准测试中始终优于先前的先进方法,性能提升幅度在 3% 到 28% 之间。此外,实际测试表明,InternVLA-N1 在不同场景的多个机器人平台上均展现出强大的长距离规划能力(>150 米)和实时决策能力(>30Hz),彰显了其在动态开放世界中的适应性。
对于导航任务,大多数现实世界数据集(Hirose (2018, 2023); Karnan (2022); Shah (2021))受到场景多样性和规模的限制。同时,网络视频数据集(Lin (2023); Liu (2025))的定位和地图信息不够精确,限制它们作为轨迹预测可靠导航数据集的可行性。相比之下,本文提出三种高效的仿真导航数据集生成流程,旨在促进可扩展的训练。具体而言,InternData-N1 数据集包含 VLN-N1、VLN-CE 和 VLN-PE 三个子集,它们具有以下互补特性:
• VLN-N1 数据集来自大规模开源 3D 资源,并进行广泛域随机化,增强其在各种现实世界场景中的泛化能力。
• VLN-CE 提供高质量、细粒度的指令注释,从而提升长距离下游导航任务的性能。
• VLN-PE 在基于物理的仿真中集成低级运动控制器,通过对导航过程中真实的机器人动力学进行建模,支持有效的模拟-到-现实的迁移。
VLN-N1
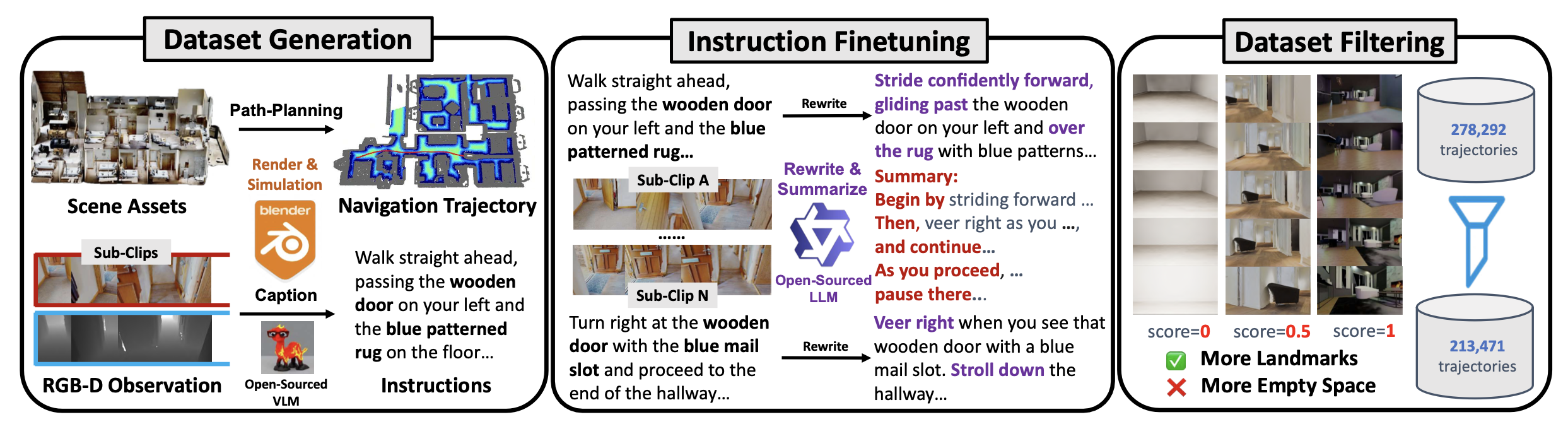
丰富的开源场景资源为生成室内导航轨迹提供了理想的平台。用 Replica Straub (2019)、Matterport3D Chang (2017)、Gibson Xia (2018)、3D-Front Fu (2021)、HSSD Khanna (2024) 和 HM3D Ramakrishnan (2021) 的资源作为场景存储库。为了生成基于自我中心观测的真实导航过程,用多阶段路径规划流程生成一批无碰撞且平滑的轨迹。首先,基于网格结构为每层构建欧氏有向距离场 (ESDF),然后进行全局路径规划,该规划包含三个步骤,类似于 Cai (2025) 的研究:(1) 使用 A-star 算法初始化随机采样的起点和目标点的全局路径。(2) 使用 ESDF 地图优化轨迹路点。(3) 轨迹平滑。收集的轨迹用于在 BlenderProc 中渲染 RGB 和深度观测数据(Denninger (2020))。
为了生成细粒度或长视界任务语言指令,首先根据轨迹几何信息提取关键帧,例如急转弯时对应的帧。基于提取的关键帧,将整个轨迹拆分为多个子片段。然后,部署一个开源的多模态大模型 LLaVa-OneVision(Li et al. (2024)),为每个子片段生成细粒度的语言指令。生成的指令语言风格有限,因此,采用另一个语言模型——Qwen3-72b(Yang et al. (2025)),重写每个片段的语言指令,并将所有子片段汇总为一条用于长视界任务的指令。按照下图所示的流程,构建一个新的大规模导航数据集 VLN-N1。
数据集比例详情和统计指标如图所示。
VLN-CE
VLN-CE 数据集源自成熟的视觉和语言导航基准数据集,包括Krantz et al. (2020b) 的 VLN-CE、EnvDrop Tan et al. (2019) 和 Wang et al.(2023a)ScaleVLN,这些模型旨在训练通用室内导航模型。用 Habitat 模拟器 Szot(2021),渲染 Matterport3D Chang(2017)和 HM3D Ramakrishnan(2021)中的场景,然后重放这些场景以收集数据集。具体来说,利用 Habitat 内置的 ShortestPathFollower 智体,通过遵循预定义的参考路径来生成轨迹,每条路径对应一条对齐的细粒度自然语言指令。动作空间遵循 Habitat 默认的 VLN 任务配置,包含四个离散动作:向前移动(0.25 米)、向左转(15°)、向右转(15°)和停止。对于每个场景,记录 RGB 观测值及其对应的动作序列。总共收集 332,179 个事件,涵盖 Matterport3D 和 HM3D 数据集中的 856 个独特场景。为了使该数据集适用于训练 System 2,将原始轨迹分割成多个片段,并将智体的位置投影到二维图像平面上,作为像素目标标签。
VLN-PE
VLN-PE 数据集旨在通过收集反映物理仿真平台 InternUtopia Wang (2024a) 中真实机器人运动的数据,弥合视觉和语言导航 (VLN) 任务中模拟与现实之间的差距。与之前的 VLN-N1 和 VLN-CE 不同,VLN-PE 明确地将机器人具身和运动策略融入其数据收集过程中。采用多种机器人平台,包括四足机器人(Unitree AlienGo)、人形机器人(Unitree H1 和 G1)和轮式机器人(Jetbot),并使用现有的基于学习的运动控制器 Long(2024a,b);Pan(2025)来控制它们的运动。每个机器人的任务是遵循与自然语言指令一致的预定义导航路径,从而产生相应的以自我为中心的观察结果。语言指令和路径主要来源于 R2R 数据集 Anderson(2018a),并进行修改。具体来说,排除涉及楼梯穿越(即上楼梯或下楼梯)的场景,当前的运动策略无法稳健地处理这些场景。最终的 VLN-PE 数据集包含来自 Matterport3D 数据集 Chang(2017)的 61 个场景的 8,679 个场景。
概述
如图所示,InternVLA-N1 采用双-系统设计的组合架构,将高级指令解释与低级动作执行协同结合。具体而言,系统集成:
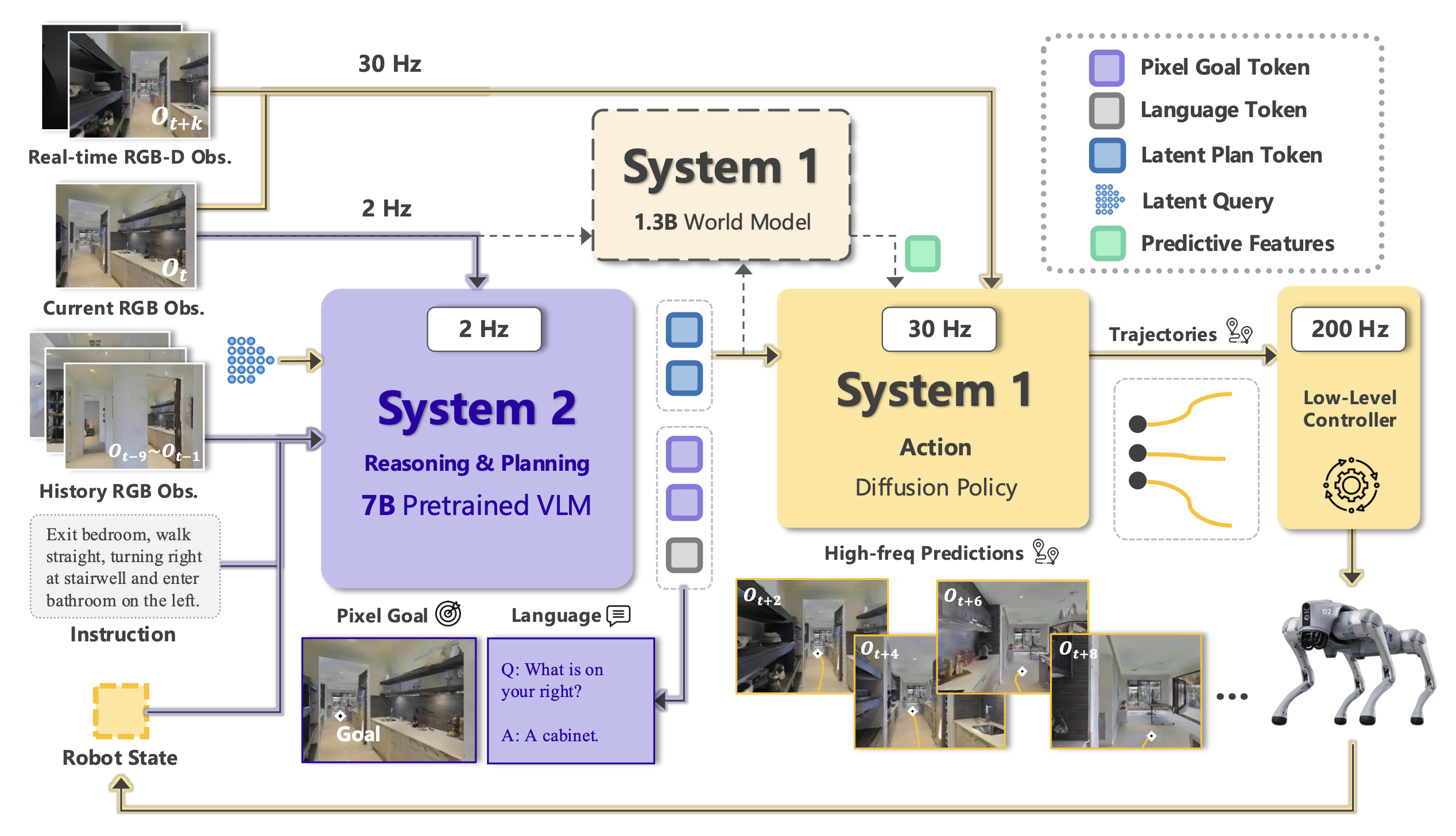
• 系统 2:基于视觉-语言模型 (VLM) 的规划模块,该模块通过基于图像的推理,解释导航指令并预测中期航点目标。通过预测图像空间中的像素坐标,它有效地将指令理解与空间推理相结合,从而实现长距离导航指令跟踪。
• 系统 1:一种多模态目标条件扩散策略,由潜规划或支持的显式目标引导,该策略根据当前观测结果和来自系统 2 的异步潜特征生成可执行的短距离轨迹。它能够在复杂环境中实现鲁棒的实时控制和局部决策。
为了充分释放双-系统架构中的开放世界泛化和异步推理能力,设计一套课程训练方案。最初,每个系统分别进行训练,在同步环境下使用明确的目标来获得基本的导航技能。然后,引入联合微调阶段。在此阶段,将可学习的 token 作为隐式中期目标纳入系统 2,以减少基于像素目标的模糊性。此外,系统 2 接收延迟观测值,迫使系统 1 适应异步执行。
系统 2:基于像素落地的视觉-语言模型规划
目标规划模块基于 Bai (2025) 提出的 Qwen-VL-2.5 模型,这是一个强大的开源视觉-语言模型,能够进行空间落地。Qwen-VL-2.5 由三个主要组件组成:视觉编码器、语言模型和用于模态融合的轻量级多模态连接器。它通过直接预测响应空间查询的像素坐标来支持基础任务,使其特别适合需要细粒度定位的任务,例如参考表达理解和视觉问答。
为了使 Qwen-VL-2.5 适用于视觉和语言导航 (VLN),将高级规划表述为最远像素目标预测问题。该模型以一系列以自我为中心的图像和语言指令作为输入,并预测图像中与下一个首选导航航点相对应的二维坐标。用 InternData-N1 VLN-CE 子集对 Qwen-VL-2.5 进行微调。通过测量智体位置和摄像机视图之间的可见性,将每个原始 VLN-CE 轨迹划分为多个最远像素预测训练样本,最终生成超过 500 万个样本,用于与导航规划任务对齐。此外,系统 2 负责决定任务完成后何时停止,以及在图像中未检测到合适的导航路径点时执行原地旋转。与直接动作预测相比,本文方法提供一种更有效的机制,将多模态理解与空间决策相结合。
系统 1:多目标条件扩散策略
系统 1 模型是一种基于扩散的局部导航策略,旨在实现实时防撞和路径规划。它采用之前的研究 NavDP Cai (2025) 类似的架构,该研究预测导航轨迹及其相应的安全分数,以便进行轨迹选择。为了提高不同类型目标的导航性能,引入显式目标嵌入对齐作为额外的训练目标。
具体而言,将点目标视为目标规范的通用且明确的形式。引入两个辅助预测头,分别以图像目标和像素目标嵌入作为输入,并以点目标作为标签进行监督。目标对齐损失与动作损失和评判损失相结合,构成整体训练目标。通过引入目标对齐目标,所有类型的导航任务都被隐式地转换为点目标导航任务,从而显著降低学习复杂度。系统 1 使用 VLN-N1 子集进行训练。
分层联合训练
阶段 1:单系统预训练。系统 2 的训练过程始于一个已在大规模图文语料库上预训练的视觉-语言模型(Qwen-VL-2.5 7B 模型)。通过任务自适应监督微调,使该模型适应特定于导航的规划。具体而言,用由导航指令、以自我为中心的观测值和中期航点组成的成对轨迹。在此设置中,每个中期航点都表示为当前观测图像像素空间中的二维坐标。在训练过程中,所有组件(包括视觉编码器、跨模态连接器和语言模型)都会与精选的 SFT 数据集联合优化一个 epoch。该模型学习在上下文中解读指令,并预测与预期导航航点对齐的图像上的像素级目标位置。
除 DepthAnything Yang (2024) 的 RGB 编码器外,系统 1 模型的所有组件均从头开始训练。系统 1 模型的训练主要基于三个目标:不同目标之间的嵌入对齐、扩散策略的噪声预测和判别器预测。对于嵌入对齐,添加两个辅助点-目标预测任务,分别以图像目标编码或像素目标编码作为输入。这有助于从头开始训练的目标编码器捕捉导航任务的重要表征。具体来说,将图像目标表示为 𝐼_𝑔,将像素目标表示为 𝑐_𝑔 = (𝑢, 𝑣),将当前 RGB 观测值表示为 𝐼_𝑡,将点目标表示为 𝑝_𝑔 = (𝑥, 𝑦, 𝜃)。为了对像素目标𝑐_𝑔进行编码,首先将 𝑐_𝑔 转换为图像掩码 𝑀_𝑔,其中仅 (𝑢, 𝑣) 周围的局部区域设置为 1,其他像素保留为 0。然后,使用两个从头开始训练的 ViT 编码器来融合 (𝐼_𝑔, 𝐼_𝑡) 和 (𝑀_𝑔, 𝐼_𝑡)。编码嵌入 𝑧_𝑖 = 𝑓_𝑖𝑚𝑔 (𝐼_𝑔, 𝐼_𝑡) 和 𝑧_𝑝 = 𝑓_𝑝𝑖𝑥 (𝑀_𝑔, 𝐼_𝑡) 附加一个 MLP 层来预测估计的点目标。
此外,扩散过程和评价预测的训练损失遵循 NavDP 中介绍的方法。联合优化动作损失、评价损失和目标对齐损失,并使用加权系数平衡它们。将系数设置为 𝛼 = 0.8、𝛽 = 0.2 和 𝛾 = 0.5。
阶段 2:多系统联合调优。用二维像素来表示精确的三维导航目标存在歧义,并且在嵌入式设备上对 7B VLM 进行高速推理也极具挑战性。因此,设计能够连接不同系统的中间特征连接至关重要。此类中间特征连接应保留原有系统的优势(不降低其效率或表示能力),同时支持信息在这些功能互补的系统之间有效流动。没有直接使用包含大量异构信息的 VLM 隐藏状态,而是引入一组可学习的潜查询。输出潜特征作为紧凑的中间特征,通过快速调优连接视觉-语言模型 (VLM) 和扩散策略模型。此外,还调整两个系统输入的时间对齐,以适应异步执行。具体来说,系统 1 在时间步 𝑇 接收最新的观测值,而系统 2 的 RGB 内存输入则从 (0, 𝑇 − 𝐾) 范围内更早的时间步采样,其中 𝐾 是从 (0, 12) 范围内随机选取的区间。这种时间解耦使双-系统框架能够更好地适应异步执行。
扩展:使用世界模型学习更优的潜规划
为了更好地表征潜规划,对模型进行扩展,使用预测世界模型解码器生成以自我为中心的观测序列,以实现中期目标。该范式有望实现基于互联网视频的可扩展训练,并显著提升动态环境下的预测能力。具体而言,采用预训练的 1.3B Wan2.1 模型(Wan,2025)作为主干模型,并用系统 2 生成的潜规划 token 替换其基于 T5 的编码器(Raffel,2020)。在 InternData-N1 导航数据集上进行微调后,世界模型能够以较高的预测精度模拟以系统 2 输出的潜规划为条件的未来结果。
系统 2 评估
数据集和评估指标。基于 Anderson (2018a) 的 R2R-CE 和 Ku (2020) 的 RxR-CE 基准测试集对 系统 2 进行评估,这两个基准测试集均基于 Krantz (2020b) 的 VLN-CE 设置,并使用 Habitat 模拟器建立。这些基准测试集模拟 Matterport3D 环境中真实的室内导航,要求智体在持续控制下遵循自然语言指令。R2R-CE 提供的纯英语指令路径相对较短,而 RxR-CE 是一个大规模多语言基准测试集,轨迹更长且更加多样化。
为了评估系统 2 的泛化能力,在两个基准测试集的验证集未见过样本分割上进行所有实验。借鉴前人的研究,采用 VLN 的标准指标:导航误差 (NE),衡量最终到达目标的距离;成功率 (SR),即智体在距离目标 3 米以内的场景百分比;预测成功率 (OSR),其中考虑路径上的最佳点;以及路径长度加权成功率 (SPL),用于惩罚不必要的长轨迹。这些指标可以全面评估指令遵循的有效性和效率。
系统 1 评估
数据集和评估指标。为了评估系统 1 的泛化能力和鲁棒性,用 IsaacSim 构建一个模拟基准,该基准反映真实机器人部署中模拟与现实之间的潜差距。收集各种各样的场景进行全面评估。这些场景主要包括两类:随机生成的、障碍物杂乱的布局,以及专业设计的、涵盖住宅和商业环境的布局(Wang,2024a)。评估场景的概览如图所示。

将所有评估环境分为四个子集,分别是 ClutterEnv-Easy (10)、ClutterEnv-Hard (10)、InternScenes-Home (20)、InternScenes-Commercial (20)。数字代表评估场景资产的数量。在轮式机器人的环境中评估三种类型的局部导航任务。对于无目标探索任务,测量指标 Episode Time 和 Explore Area 来评估避碰和探索技能。对于点-目标导航和图像-目标导航任务,评估成功率 (SR) 和路径长度加权的成功率 (SPL)。如果智体在 1.0 米范围内到达目标点,则该场景定义为成功。对于每个任务,机器人都会随机初始化,并在每个场景中评估 100 个场景。
双-系统评估
数据集和评估指标。首先在与系统 2 评估相同的 VLN-CE 基准上评估双-系统,方法是用系统 1 替换 Habitat-Sim 中的默认点-目标导航策略。进一步在 VLN-PE Wang (2025b) 上评估双-系统,这是一个物理上真实的 VLN 平台和基准,用于模拟实际部署中遇到的机器人动力学和控制误差。考虑 Anderson (2018a) 的 R2R 数据集以及 VLN-PE 中的类人 Unitree H1 机器人。
遵循 Anderson (2018a);Krantz (2020b) 的标准 VLN 评估协议,采用五个主要指标:轨迹长度 (TL) 量化智体导航轨迹的平均长度,以米为单位。导航误差 (NE) 记录智体最终停止位置与指定目的地之间的平均距离。成功率 (SR) 表示智体成功到达目的地的概率。需要注意的是,如果智体在目标位置 3 米半径范围内停下,则视为智体已到达目的地。预言成功率 (OS) 是指智体导航轨迹中任意一点到达目的地的概率。SR 加权路径长度 (SPL) 可平衡 SR 和 TL。对于物理模拟,还应用两个附加指标:跌倒率 (Fall Rate) 衡量机器人跌倒的频率,卡住率 (Stuck Rate) 衡量代理无法移动的发生次数。
扩展:世界模型定性结果
世界模型经过微调,以系统 2 生成的潜规划 token 为条件,并生成相应的以自我为中心的视频序列,描述朝着预期目标的导航。在模拟和真实环境中评估生成视频的质量。
真实世界实验
实验设置。在轮式机器人(Turtlebot4)、四足机器人(Unitree Go2)和人形机器人(Unitree G1)上进行真实世界实验。所有机器人均配备英特尔 Realsense D455 摄像头,这些摄像头安装在不同的高度,但向下倾斜 15°。将整个系统部署在一台配备 RTX 4090 GPU 的远程机器上。InternVLA-N1 模型占用 GPU 约 20GB 的内存。在多个室内和室外场景中评估零样本指令跟踪和避障性能。
流程和速度。初始给定 VLN 指令,机器人持续捕获实时对齐的图像(RGB 和深度),并将其传输到远程服务器进行推理。服务器在后台对双-系统模型进行异步推理,并将最新的轨迹或离散动作返回给机器人。根据推理图像时的里程表,将轨迹转换到世界坐标系下,并用 MPC 控制器进行跟踪。在系统 2 的多轮对话中重用 KV 缓存,将轨迹 token 的推理速度从约 1.1 秒加速到 0.7 秒。通过使用 TensorRT 进行优化,系统 1 模型可以在约 0.03 秒内并行生成 32 条轨迹。得益于异步流水线和推理优化,机器人可以在最后一条轨迹完全跟踪到终点后获得更新的轨迹,从而使运动更平滑。当达到语言指令的目标时,系统 2 会输出 STOP 标志。如果 (1) 机器人与所有静态和动态障碍物保持无碰撞,(2) 机器人经过所有期望的地标并停在期望的目标处,则现实世界的实验被认为是成功的。
基线与指标。为了定量评估 InternVLA-N1 在实际场景中的稳健性和泛化能力,将模型与其他基线方法在走廊(简单的 VLN 教学)、卧室(单个房间的中等 VLN 教学)和办公室(房间间 VLN 教学)场景下的性能进行比较。基线包括基于传统学习的方法 CMA Krantz (2020a)、基于 VLM 的方法 NaVid Zhang (2024)、NaVILA Cheng (2025) 以及之前的输出离散动作的 StreamVLN Wei (2025) 的工作。在每种场景中针对每个模型进行 20 次实验,旨在观察执行 VLN 任务的成功率 (SR) 和导航错误率 (NE)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)