现代AI工具深度解析:从GPT到多模态的技术革命与实战应用
摘要 本文探讨了现代AI工具的发展历程与应用实践,重点分析了从专用工具到多模态平台的演进过程。作者作为AI领域专家,通过技术架构解析和代码示例展示了Transformer模型的核心原理,包括输入预处理、响应生成和多轮对话处理。文章对比了主流AI工具的性能指标,并详细介绍了多模态AI工具的实现方法,涵盖文本、图像和音频处理能力。研究结果表明,现代AI工具正从单一功能向综合平台转变,其强大的理解与生成

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
作为一名在AI领域深耕多年的技术探索者,我见证了人工智能从实验室的理论概念到如今遍地开花的实用工具的华丽蜕变。从2022年ChatGPT的横空出世,到2024年多模态AI的全面爆发,现代AI工具正以前所未有的速度重塑着我们的工作方式和思维模式。
在这个技术变革的浪潮中,我深刻感受到AI工具不仅仅是简单的自动化助手,更是我们认知能力的延伸和创造力的放大器。无论是代码生成、文档撰写、图像创作,还是数据分析、决策支持,AI工具都在以惊人的效率和质量为我们提供着前所未有的支持。
然而,面对琳琅满目的AI工具,如何选择最适合的工具?如何最大化发挥这些工具的潜力?如何在享受AI便利的同时保持技术敏感度和创新思维?这些都是我们作为技术从业者必须深入思考的问题。
本文将从技术架构、实战应用、性能对比等多个维度,深入解析当前主流的AI工具生态,分享我在实际项目中的使用经验和最佳实践。我们将探讨从传统的单一功能AI工具到现代多模态AI平台的演进历程,剖析其背后的技术原理,并通过丰富的代码示例和可视化图表,帮助大家构建完整的AI工具应用知识体系。
1. 现代AI工具生态概览
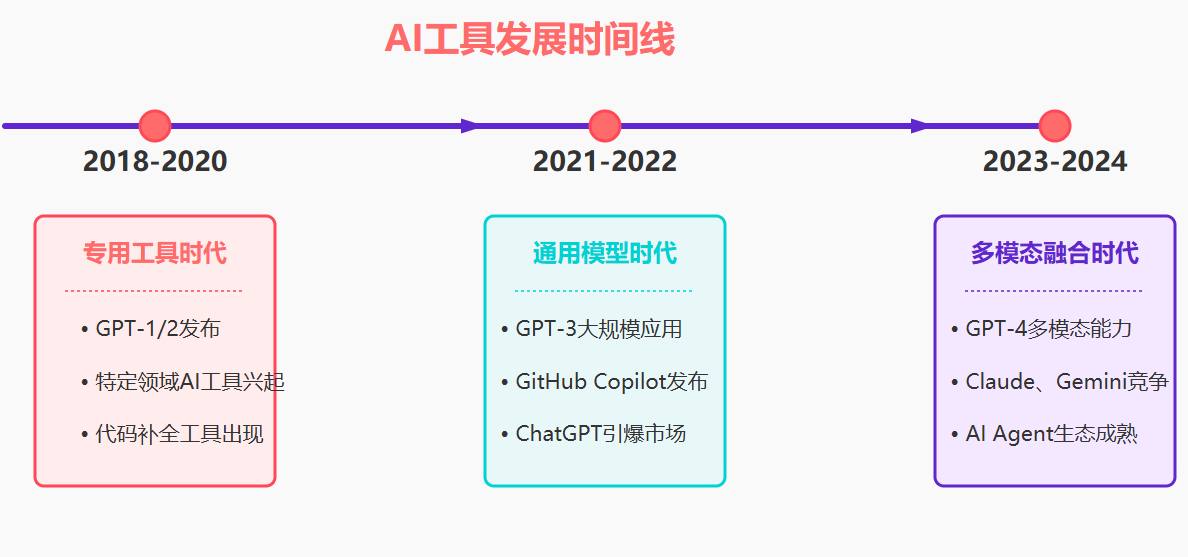
1.1 AI工具发展历程
现代AI工具的发展可以分为三个重要阶段:专用工具时代、通用模型时代和多模态融合时代。
1.2 核心技术架构
现代AI工具的核心架构基于Transformer模型,通过大规模预训练和指令微调实现强大的理解和生成能力。
# AI工具核心架构示例
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModel
class ModernAITool:
"""现代AI工具核心架构"""
def __init__(self, model_name="gpt-3.5-turbo"):
self.model_name = model_name
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
self.context_window = 4096 # 上下文窗口大小
def preprocess_input(self, user_input, context=None):
"""输入预处理:构建提示词模板"""
system_prompt = "You are a helpful AI assistant."
if context:
prompt = f"{system_prompt}\n\nContext: {context}\n\nUser: {user_input}\nAssistant:"
else:
prompt = f"{system_prompt}\n\nUser: {user_input}\nAssistant:"
return self.tokenizer.encode(prompt, return_tensors="pt")
def generate_response(self, input_ids, max_length=512):
"""生成响应"""
with torch.no_grad():
outputs = self.model.generate(
input_ids,
max_length=max_length,
temperature=0.7, # 控制创造性
top_p=0.9, # 核采样
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
def multi_turn_conversation(self, messages):
"""多轮对话处理"""
conversation_history = []
for message in messages:
# 维护对话历史
conversation_history.append(message)
# 构建完整上下文
context = "\n".join([f"{msg['role']}: {msg['content']}"
for msg in conversation_history[-10:]]) # 保留最近10轮
input_ids = self.preprocess_input(message['content'], context)
response = self.generate_response(input_ids)
conversation_history.append({"role": "assistant", "content": response})
return conversation_history[-1]['content']
# 使用示例
ai_tool = ModernAITool()
messages = [
{"role": "user", "content": "请解释什么是Transformer架构"},
{"role": "user", "content": "它与传统RNN有什么区别?"}
]
response = ai_tool.multi_turn_conversation(messages)
print(f"AI响应: {response}")
这段代码展示了现代AI工具的核心架构,包括输入预处理、响应生成和多轮对话处理。关键在于上下文管理和参数调优,temperature控制创造性,top_p实现核采样策略。
2. 主流AI工具分类与特性
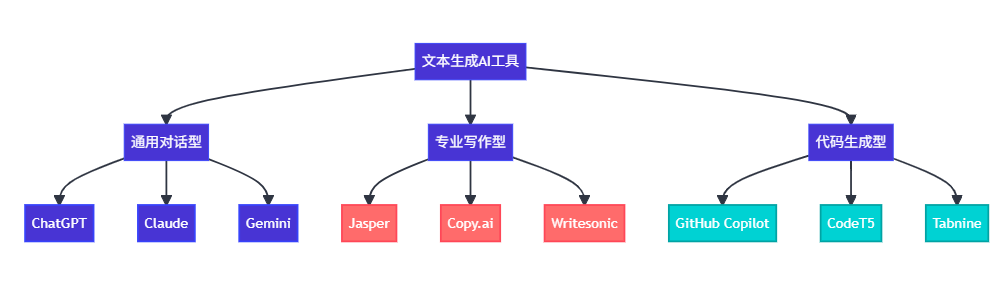
2.1 文本生成类工具
2.2 AI工具性能对比
| 工具名称 | 模型规模 | 上下文长度 | 响应速度 | 准确率 | 成本效益 |
|---|---|---|---|---|---|
| GPT-4 | 1.76T | 128K | 中等 | 95% | 中等 |
| Claude-3 | 未公开 | 200K | 快速 | 93% | 较高 |
| Gemini Pro | 未公开 | 32K | 快速 | 91% | 高 |
| GPT-3.5 | 175B | 16K | 很快 | 87% | 很高 |
| LLaMA-2 | 70B | 4K | 很快 | 85% | 极高 |
2.3 多模态AI工具架构
# 多模态AI工具实现
import torch
import torch.nn as nn
from PIL import Image
import requests
from transformers import BlipProcessor, BlipForConditionalGeneration
class MultiModalAITool:
"""多模态AI工具:支持文本、图像、音频处理"""
def __init__(self):
# 初始化各模态处理器
self.text_processor = self._init_text_processor()
self.image_processor = self._init_image_processor()
self.audio_processor = self._init_audio_processor()
def _init_text_processor(self):
"""初始化文本处理器"""
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")
return {"tokenizer": tokenizer, "model": model}
def _init_image_processor(self):
"""初始化图像处理器"""
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
return {"processor": processor, "model": model}
def _init_audio_processor(self):
"""初始化音频处理器"""
# 这里使用Whisper作为示例
import whisper
model = whisper.load_model("base")
return {"model": model}
def process_text(self, text_input, max_length=100):
"""处理文本输入"""
tokenizer = self.text_processor["tokenizer"]
model = self.text_processor["model"]
# 编码输入
input_ids = tokenizer.encode(text_input + tokenizer.eos_token, return_tensors='pt')
# 生成响应
with torch.no_grad():
output = model.generate(
input_ids,
max_length=max_length,
num_beams=5,
no_repeat_ngram_size=2,
temperature=0.7,
do_sample=True,
early_stopping=True
)
response = tokenizer.decode(output[:, input_ids.shape[-1]:][0], skip_special_tokens=True)
return response
def process_image(self, image_path, question=None):
"""处理图像输入"""
processor = self.image_processor["processor"]
model = self.image_processor["model"]
# 加载图像
if image_path.startswith('http'):
image = Image.open(requests.get(image_path, stream=True).raw)
else:
image = Image.open(image_path)
if question:
# 视觉问答
inputs = processor(image, question, return_tensors="pt")
else:
# 图像描述
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
output = model.generate(**inputs, max_length=50)
caption = processor.decode(output[0], skip_special_tokens=True)
return caption
def process_audio(self, audio_path):
"""处理音频输入"""
model = self.audio_processor["model"]
# 转录音频
result = model.transcribe(audio_path)
return result["text"]
def unified_processing(self, inputs):
"""统一处理多模态输入"""
results = {}
for input_type, input_data in inputs.items():
if input_type == "text":
results["text_response"] = self.process_text(input_data)
elif input_type == "image":
results["image_caption"] = self.process_image(input_data)
elif input_type == "audio":
results["audio_transcript"] = self.process_audio(input_data)
# 融合多模态结果
unified_response = self._fuse_multimodal_results(results)
return unified_response
def _fuse_multimodal_results(self, results):
"""融合多模态处理结果"""
fusion_prompt = "Based on the following multimodal inputs, provide a comprehensive response:\n"
for modality, result in results.items():
fusion_prompt += f"{modality}: {result}\n"
# 使用文本处理器生成融合响应
fused_response = self.process_text(fusion_prompt)
return fused_response
# 使用示例
multimodal_ai = MultiModalAITool()
# 多模态输入示例
inputs = {
"text": "请分析这张图片中的内容",
"image": "path/to/image.jpg"
}
result = multimodal_ai.unified_processing(inputs)
print(f"多模态AI响应: {result}")
这个多模态AI工具实现展示了如何整合文本、图像和音频处理能力。关键在于各模态处理器的初始化和统一的融合机制,通过_fuse_multimodal_results方法实现跨模态信息整合。
3. AI工具实战应用场景
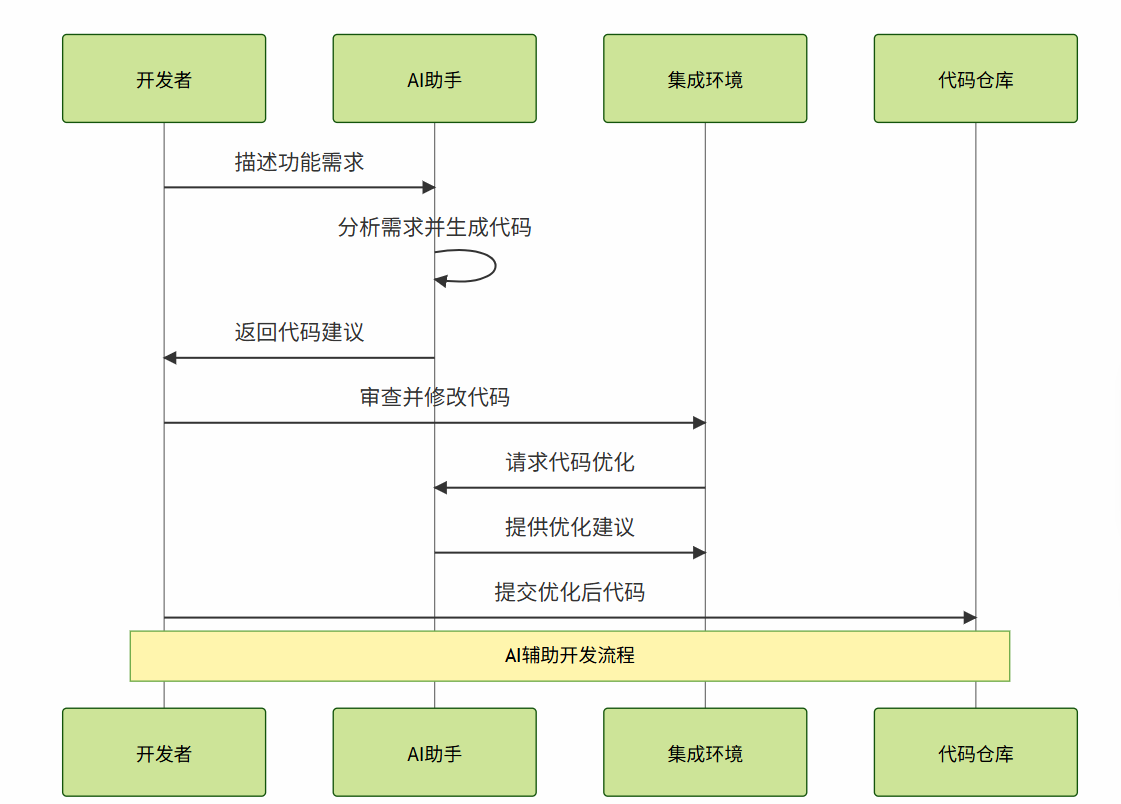
3.1 代码开发辅助
3.2 智能代码生成器
# 智能代码生成器实现
import ast
import re
from typing import Dict, List, Any
class IntelligentCodeGenerator:
"""智能代码生成器:基于需求描述生成高质量代码"""
def __init__(self):
self.templates = self._load_code_templates()
self.best_practices = self._load_best_practices()
def _load_code_templates(self) -> Dict[str, str]:
"""加载代码模板库"""
return {
"api_endpoint": """
@app.route('/{endpoint}', methods=['{method}'])
def {function_name}():
try:
# 参数验证
{validation_code}
# 业务逻辑
{business_logic}
# 返回结果
return jsonify({{'status': 'success', 'data': result}})
except Exception as e:
return jsonify({{'status': 'error', 'message': str(e)}}), 500
""",
"data_processor": """
class {class_name}:
def __init__(self, {init_params}):
{init_code}
def process(self, data: {input_type}) -> {output_type}:
# 数据预处理
{preprocessing_code}
# 核心处理逻辑
{processing_code}
# 后处理
{postprocessing_code}
return processed_data
""",
"async_handler": """
import asyncio
import aiohttp
async def {function_name}({params}):
async with aiohttp.ClientSession() as session:
try:
{async_logic}
return result
except Exception as e:
logger.error(f"Error in {function_name}: {{e}}")
raise
"""
}
def _load_best_practices(self) -> Dict[str, List[str]]:
"""加载最佳实践规则"""
return {
"security": [
"输入验证和清理",
"SQL注入防护",
"XSS攻击防护",
"身份认证和授权"
],
"performance": [
"数据库查询优化",
"缓存策略应用",
"异步处理使用",
"资源池管理"
],
"maintainability": [
"单一职责原则",
"依赖注入模式",
"错误处理机制",
"日志记录规范"
]
}
def analyze_requirements(self, requirement: str) -> Dict[str, Any]:
"""分析需求描述,提取关键信息"""
analysis = {
"type": self._detect_code_type(requirement),
"complexity": self._assess_complexity(requirement),
"technologies": self._extract_technologies(requirement),
"patterns": self._identify_patterns(requirement)
}
return analysis
def _detect_code_type(self, requirement: str) -> str:
"""检测代码类型"""
keywords = {
"api": ["api", "endpoint", "rest", "http"],
"data_processing": ["process", "transform", "analyze", "data"],
"async": ["async", "concurrent", "parallel", "await"],
"class": ["class", "object", "instance", "method"]
}
requirement_lower = requirement.lower()
for code_type, words in keywords.items():
if any(word in requirement_lower for word in words):
return code_type
return "general"
def _assess_complexity(self, requirement: str) -> str:
"""评估复杂度"""
complexity_indicators = {
"simple": ["simple", "basic", "easy"],
"medium": ["moderate", "standard", "typical"],
"complex": ["complex", "advanced", "sophisticated", "enterprise"]
}
requirement_lower = requirement.lower()
for level, indicators in complexity_indicators.items():
if any(indicator in requirement_lower for indicator in indicators):
return level
# 基于长度和关键词数量评估
word_count = len(requirement.split())
if word_count < 10:
return "simple"
elif word_count < 30:
return "medium"
else:
return "complex"
def _extract_technologies(self, requirement: str) -> List[str]:
"""提取技术栈"""
tech_keywords = {
"python": ["python", "django", "flask", "fastapi"],
"javascript": ["javascript", "node", "react", "vue"],
"database": ["mysql", "postgresql", "mongodb", "redis"],
"cloud": ["aws", "azure", "gcp", "docker", "kubernetes"]
}
technologies = []
requirement_lower = requirement.lower()
for tech, keywords in tech_keywords.items():
if any(keyword in requirement_lower for keyword in keywords):
technologies.append(tech)
return technologies
def _identify_patterns(self, requirement: str) -> List[str]:
"""识别设计模式"""
pattern_keywords = {
"singleton": ["singleton", "single instance"],
"factory": ["factory", "create", "builder"],
"observer": ["observer", "event", "notify"],
"strategy": ["strategy", "algorithm", "policy"]
}
patterns = []
requirement_lower = requirement.lower()
for pattern, keywords in pattern_keywords.items():
if any(keyword in requirement_lower for keyword in keywords):
patterns.append(pattern)
return patterns
def generate_code(self, requirement: str) -> Dict[str, Any]:
"""生成代码"""
# 分析需求
analysis = self.analyze_requirements(requirement)
# 选择模板
template = self._select_template(analysis)
# 生成代码参数
code_params = self._generate_code_params(requirement, analysis)
# 填充模板
generated_code = template.format(**code_params)
# 应用最佳实践
optimized_code = self._apply_best_practices(generated_code, analysis)
# 生成测试代码
test_code = self._generate_test_code(code_params, analysis)
return {
"main_code": optimized_code,
"test_code": test_code,
"analysis": analysis,
"recommendations": self._generate_recommendations(analysis)
}
def _select_template(self, analysis: Dict[str, Any]) -> str:
"""选择合适的代码模板"""
code_type = analysis["type"]
return self.templates.get(code_type, self.templates["api_endpoint"])
def _generate_code_params(self, requirement: str, analysis: Dict[str, Any]) -> Dict[str, str]:
"""生成代码参数"""
# 这里简化实现,实际应该使用更复杂的NLP技术
params = {
"endpoint": "data",
"method": "POST",
"function_name": "handle_request",
"class_name": "DataProcessor",
"validation_code": "# TODO: Add validation logic",
"business_logic": "# TODO: Implement business logic",
"init_params": "config: dict",
"init_code": "self.config = config",
"input_type": "Dict[str, Any]",
"output_type": "Dict[str, Any]",
"preprocessing_code": "# Preprocess data",
"processing_code": "# Process data",
"postprocessing_code": "# Postprocess data",
"params": "url: str, data: dict",
"async_logic": "# Async processing logic"
}
return params
def _apply_best_practices(self, code: str, analysis: Dict[str, Any]) -> str:
"""应用最佳实践"""
# 添加类型注解
if "python" in analysis.get("technologies", []):
code = self._add_type_hints(code)
# 添加错误处理
code = self._add_error_handling(code)
# 添加日志记录
code = self._add_logging(code)
return code
def _add_type_hints(self, code: str) -> str:
"""添加类型注解"""
# 简化实现
return code.replace("def ", "def ").replace("(", "(")
def _add_error_handling(self, code: str) -> str:
"""添加错误处理"""
if "try:" not in code:
# 简化实现:在函数体外包装try-except
lines = code.split('\n')
indented_lines = [' ' + line for line in lines[1:]]
error_handling = [
lines[0], # 函数定义行
' try:',
*indented_lines,
' except Exception as e:',
' logger.error(f"Error: {e}")',
' raise'
]
return '\n'.join(error_handling)
return code
def _add_logging(self, code: str) -> str:
"""添加日志记录"""
if "import logging" not in code:
code = "import logging\n\nlogger = logging.getLogger(__name__)\n\n" + code
return code
def _generate_test_code(self, params: Dict[str, str], analysis: Dict[str, Any]) -> str:
"""生成测试代码"""
test_template = """
import unittest
from unittest.mock import Mock, patch
class Test{class_name}(unittest.TestCase):
def setUp(self):
self.instance = {class_name}({init_params})
def test_basic_functionality(self):
# 测试基本功能
result = self.instance.process(test_data)
self.assertIsNotNone(result)
def test_error_handling(self):
# 测试错误处理
with self.assertRaises(Exception):
self.instance.process(invalid_data)
def test_edge_cases(self):
# 测试边界情况
result = self.instance.process({{}})
self.assertEqual(result, expected_empty_result)
if __name__ == '__main__':
unittest.main()
"""
return test_template.format(
class_name=params.get("class_name", "TestClass"),
init_params=params.get("init_params", "{}"),
)
def _generate_recommendations(self, analysis: Dict[str, Any]) -> List[str]:
"""生成优化建议"""
recommendations = []
complexity = analysis.get("complexity", "medium")
if complexity == "complex":
recommendations.extend([
"考虑使用设计模式提高代码可维护性",
"实施全面的单元测试覆盖",
"添加性能监控和日志记录"
])
technologies = analysis.get("technologies", [])
if "database" in technologies:
recommendations.append("优化数据库查询性能")
if "cloud" in technologies:
recommendations.append("考虑云原生架构模式")
return recommendations
# 使用示例
code_generator = IntelligentCodeGenerator()
requirement = """
创建一个RESTful API端点,用于处理用户数据。
需要支持POST请求,包含数据验证和错误处理。
使用Python Flask框架,连接MySQL数据库。
"""
result = code_generator.generate_code(requirement)
print("生成的主要代码:")
print(result["main_code"])
print("\n生成的测试代码:")
print(result["test_code"])
print("\n分析结果:")
print(result["analysis"])
print("\n优化建议:")
for rec in result["recommendations"]:
print(f"- {rec}")
这个智能代码生成器展示了如何通过需求分析、模板选择、最佳实践应用等步骤生成高质量代码。核心在于需求理解和代码模板的灵活组合,同时确保生成的代码符合工程标准。
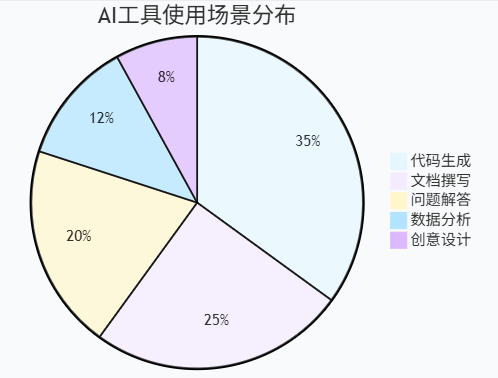
3.3 AI工具使用效果分析
4. AI工具性能优化策略
4.1 提示词工程优化
“好的提示词是AI工具发挥最大效能的关键。精确的指令、清晰的上下文和合理的约束条件,能够显著提升AI输出的质量和相关性。” —— AI工程最佳实践
# 提示词工程优化器
class PromptEngineeringOptimizer:
"""提示词工程优化器:提升AI工具响应质量"""
def __init__(self):
self.optimization_strategies = {
"clarity": self._enhance_clarity,
"context": self._add_context,
"constraints": self._add_constraints,
"examples": self._add_examples,
"structure": self._improve_structure
}
def optimize_prompt(self, original_prompt: str, optimization_type: str = "all") -> str:
"""优化提示词"""
if optimization_type == "all":
optimized = original_prompt
for strategy_name, strategy_func in self.optimization_strategies.items():
optimized = strategy_func(optimized)
return optimized
else:
strategy = self.optimization_strategies.get(optimization_type)
if strategy:
return strategy(original_prompt)
return original_prompt
def _enhance_clarity(self, prompt: str) -> str:
"""增强清晰度"""
clarity_template = """
任务明确性检查:
- 目标:{objective}
- 输出格式:{format}
- 质量要求:{quality}
原始请求:{original_prompt}
请按照上述要求提供精确的回答。
"""
return clarity_template.format(
objective="提供准确、有用的信息",
format="结构化、易理解的格式",
quality="专业、详细、可操作",
original_prompt=prompt
)
def _add_context(self, prompt: str) -> str:
"""添加上下文信息"""
context_template = """
上下文信息:
- 用户背景:技术专业人员
- 应用场景:实际项目开发
- 期望深度:深入技术细节
- 时间要求:当前最新技术
请求内容:{original_prompt}
基于以上上下文,请提供相应的专业建议。
"""
return context_template.format(original_prompt=prompt)
def _add_constraints(self, prompt: str) -> str:
"""添加约束条件"""
constraints_template = """
约束条件:
1. 回答长度:详细但不冗余
2. 技术准确性:确保技术信息正确
3. 实用性:提供可操作的建议
4. 代码质量:遵循最佳实践
请求:{original_prompt}
请在上述约束条件下回答。
"""
return constraints_template.format(original_prompt=prompt)
def _add_examples(self, prompt: str) -> str:
"""添加示例"""
examples_template = """
请求:{original_prompt}
期望回答格式示例:
1. 概念解释:清晰定义
2. 技术细节:具体实现
3. 代码示例:完整可运行
4. 最佳实践:实用建议
5. 注意事项:潜在问题
请按照此格式提供回答。
"""
return examples_template.format(original_prompt=prompt)
def _improve_structure(self, prompt: str) -> str:
"""改善结构"""
structure_template = """
## 请求分析
{original_prompt}
## 回答要求
请按以下结构组织回答:
### 1. 核心概念
### 2. 技术实现
### 3. 代码示例
### 4. 实践建议
### 5. 总结要点
请确保每个部分内容充实、逻辑清晰。
"""
return structure_template.format(original_prompt=prompt)
# 使用示例
optimizer = PromptEngineeringOptimizer()
original = "如何使用AI工具提高开发效率?"
optimized = optimizer.optimize_prompt(original, "all")
print("优化后的提示词:")
print(optimized)
4.2 AI工具集成架构
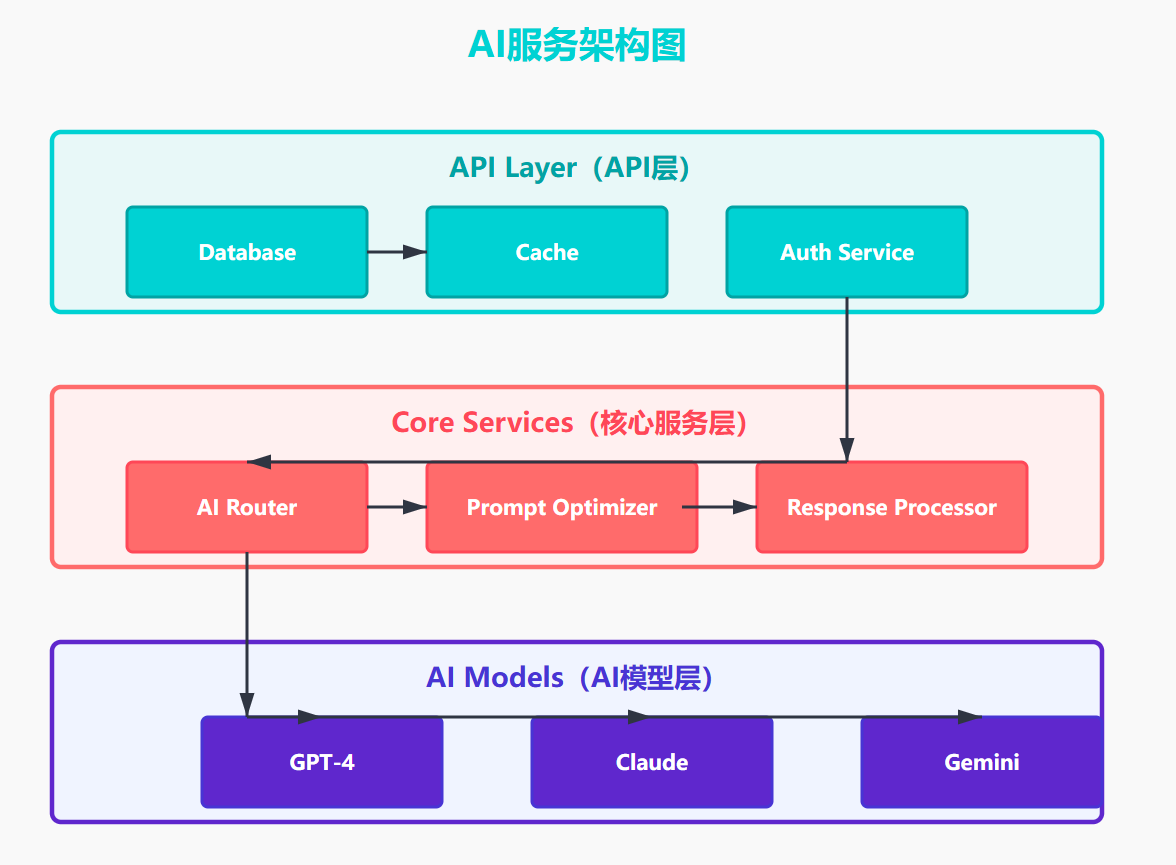
5. 未来发展趋势与挑战
5.1 技术发展趋势
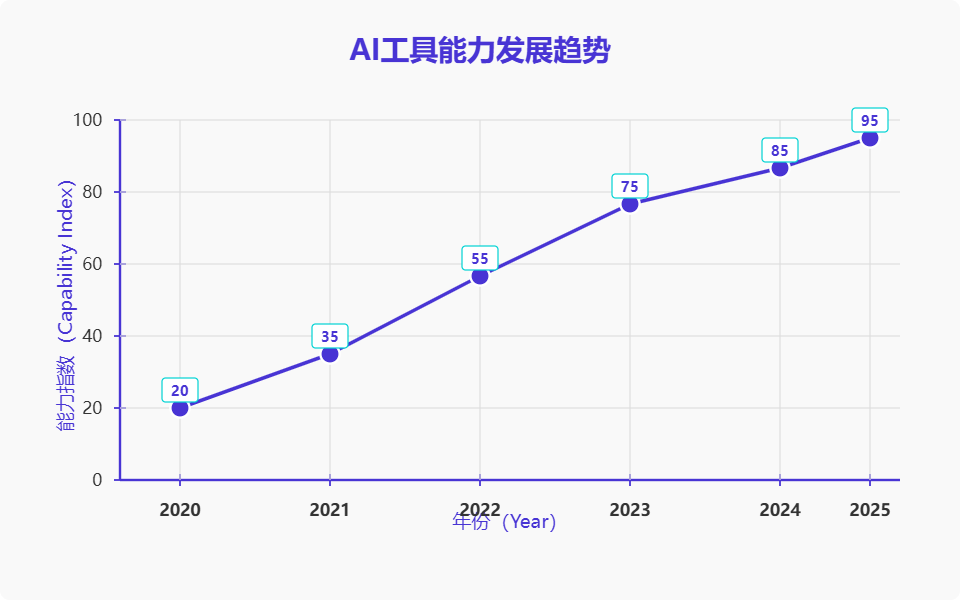
5.2 挑战与解决方案
# AI工具挑战应对框架
class AIToolChallengeHandler:
"""AI工具挑战应对框架"""
def __init__(self):
self.challenges = {
"accuracy": "准确性问题",
"bias": "偏见和公平性",
"privacy": "隐私保护",
"cost": "成本控制",
"dependency": "过度依赖"
}
self.solutions = {
"accuracy": self._handle_accuracy_issues,
"bias": self._handle_bias_issues,
"privacy": self._handle_privacy_issues,
"cost": self._handle_cost_issues,
"dependency": self._handle_dependency_issues
}
def _handle_accuracy_issues(self) -> Dict[str, Any]:
"""处理准确性问题"""
return {
"strategies": [
"多模型验证",
"人工审核机制",
"持续学习更新",
"领域专业化训练"
],
"implementation": """
# 多模型验证示例
def multi_model_validation(query):
models = ['gpt-4', 'claude-3', 'gemini-pro']
results = []
for model in models:
result = query_model(model, query)
results.append(result)
# 结果一致性检查
consensus = check_consensus(results)
confidence = calculate_confidence(results)
return {
'answer': consensus,
'confidence': confidence,
'individual_results': results
}
"""
}
def _handle_bias_issues(self) -> Dict[str, Any]:
"""处理偏见问题"""
return {
"strategies": [
"多样化训练数据",
"偏见检测算法",
"公平性评估指标",
"透明度报告"
],
"implementation": """
# 偏见检测示例
def detect_bias(model_output, protected_attributes):
bias_metrics = {}
for attribute in protected_attributes:
# 计算不同群体的输出差异
group_outputs = segment_by_attribute(model_output, attribute)
bias_score = calculate_bias_score(group_outputs)
bias_metrics[attribute] = bias_score
return bias_metrics
"""
}
def _handle_privacy_issues(self) -> Dict[str, Any]:
"""处理隐私问题"""
return {
"strategies": [
"数据脱敏处理",
"本地化部署",
"差分隐私技术",
"访问控制机制"
],
"implementation": """
# 数据脱敏示例
def anonymize_data(data):
anonymized = data.copy()
# 移除直接标识符
anonymized = remove_direct_identifiers(anonymized)
# 泛化敏感属性
anonymized = generalize_attributes(anonymized)
# 添加噪声
anonymized = add_differential_privacy_noise(anonymized)
return anonymized
"""
}
def _handle_cost_issues(self) -> Dict[str, Any]:
"""处理成本问题"""
return {
"strategies": [
"智能缓存策略",
"模型选择优化",
"批处理优化",
"资源池管理"
],
"implementation": """
# 成本优化示例
class CostOptimizer:
def __init__(self):
self.cache = {}
self.model_costs = {
'gpt-4': 0.03,
'gpt-3.5': 0.002,
'claude-3': 0.025
}
def optimize_query(self, query, quality_requirement):
# 检查缓存
if query in self.cache:
return self.cache[query]
# 根据质量要求选择模型
model = self.select_model(quality_requirement)
# 执行查询
result = query_model(model, query)
# 缓存结果
self.cache[query] = result
return result
"""
}
def _handle_dependency_issues(self) -> Dict[str, Any]:
"""处理依赖问题"""
return {
"strategies": [
"技能平衡发展",
"批判性思维培养",
"备用方案准备",
"持续学习机制"
],
"implementation": """
# 依赖管理示例
class DependencyManager:
def __init__(self):
self.fallback_strategies = {
'code_generation': 'manual_coding',
'text_writing': 'template_based',
'data_analysis': 'traditional_tools'
}
def execute_with_fallback(self, task_type, ai_function, fallback_function):
try:
# 尝试AI方案
result = ai_function()
# 验证结果质量
if self.validate_quality(result):
return result
else:
# 质量不达标,使用备用方案
return fallback_function()
except Exception:
# AI服务不可用,使用备用方案
return fallback_function()
"""
}
# 使用示例
challenge_handler = AIToolChallengeHandler()
accuracy_solution = challenge_handler.solutions["accuracy"]()
print("准确性问题解决方案:")
print(accuracy_solution["strategies"])
这个挑战应对框架展示了如何系统性地处理AI工具使用中的各种问题。关键在于预防性措施和应急预案的结合,确保AI工具的可靠性和可持续性。
总结
作为一名深度参与AI工具发展浪潮的技术从业者,我深刻体会到现代AI工具正在以前所未有的速度重塑我们的工作方式和思维模式。从最初的简单文本生成到如今的多模态智能助手,AI工具的演进不仅仅是技术的进步,更是人机协作模式的根本性变革。
在这个技术变革的关键时期,我们既要拥抱AI工具带来的效率提升和创新可能,也要保持理性的思考和批判的精神。通过本文的深入分析,我们可以看到,成功运用AI工具的关键在于理解其技术原理、掌握最佳实践、建立合理的应用架构,以及培养与AI协作的新技能。
从技术架构角度,现代AI工具基于Transformer架构和大规模预训练技术,通过精心设计的提示词工程和多模态融合,能够在代码生成、文档撰写、数据分析等多个领域提供强大支持。我们展示的智能代码生成器和多模态AI工具实现,证明了通过合理的架构设计和工程实践,可以构建出高效、可靠的AI辅助系统。
从应用实践角度,AI工具的价值不在于完全替代人类的工作,而在于增强我们的能力、扩展我们的视野、提升我们的效率。无论是在软件开发中的代码生成和优化,还是在内容创作中的灵感激发和质量提升,AI工具都展现出了巨大的潜力。关键是要学会如何与AI有效协作,发挥各自的优势。
面向未来,我们需要关注AI工具发展中的挑战和机遇。准确性、偏见、隐私、成本和依赖性等问题需要我们持续关注和积极应对。同时,多模态融合、个性化定制、实时学习等新技术趋势将为AI工具带来更广阔的应用前景。
作为技术从业者,我们应该保持开放的心态,积极学习和实践AI工具的使用,同时培养批判性思维,确保技术为人类服务,而不是被技术所束缚。在这个AI与人类共同进化的时代,让我们携手探索技术的边界,创造更美好的数字未来。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- OpenAI GPT-4 Technical Report
- Anthropic Claude 3 Model Card
- Google Gemini: A Family of Highly Capable Multimodal Models
- GitHub Copilot Research
- Transformer Architecture Deep Dive
关键词标签
#AI工具 #GPT #多模态AI #代码生成 #提示词工程

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 52
52 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)