大模型技术演变-4Transformer架构奠基Attention is all you need读后笔记
Attention is All You Need》这篇论文无疑是深度学习领域的重要里程碑,它提出的Transformer架构不仅彻底改变了自然语言处理领域,也对整个人工智能学科产生了深远影响。通过阅读这篇论文,我获得了以下核心启示:简洁即力量:Transformer架构的核心思想异常简洁——仅使用注意力机制,但这种简洁性却带来了前所未有的性能和效率提升。这提醒我们在解决复杂问题时,有时最简单
1 论文基本信息与核心思想
《Attention is All You Need》由Google Research的Ashish Vaswani等人在2017年的NeurIPS会议上发表,这篇论文彻底改变了自然语言处理(NLP)领域的建模范式。论文提出了Transformer架构,完全摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),仅依靠自注意力机制(Self-Attention)完成序列建模任务。该论文被视为"后RNN时代"的里程碑,成为后来GPT、BERT、ChatGPT等大模型的根基,开启了深度学习的"Attention时代"。
论文的核心思想是用Self-Attention机制取代循环网络,通过全局信息建模提升模型效率与性能。在Transformer出现之前,NLP领域的主力架构是RNN及其变体LSTM,这些传统模型存在三个关键问题:计算串行(无法并行处理,训练速度慢)、梯度消失(长距离依赖难以建模)和记忆有限(信息在长句中逐渐衰减)。虽然当时已经有了基于Attention的Seq2Seq模型,但仍然依赖RNN架构。Transformer提出了一个大胆设想:"Attention就够了!",完全摒弃了循环和卷积结构。
2 Transformer架构组件解析
2.1 整体架构设计
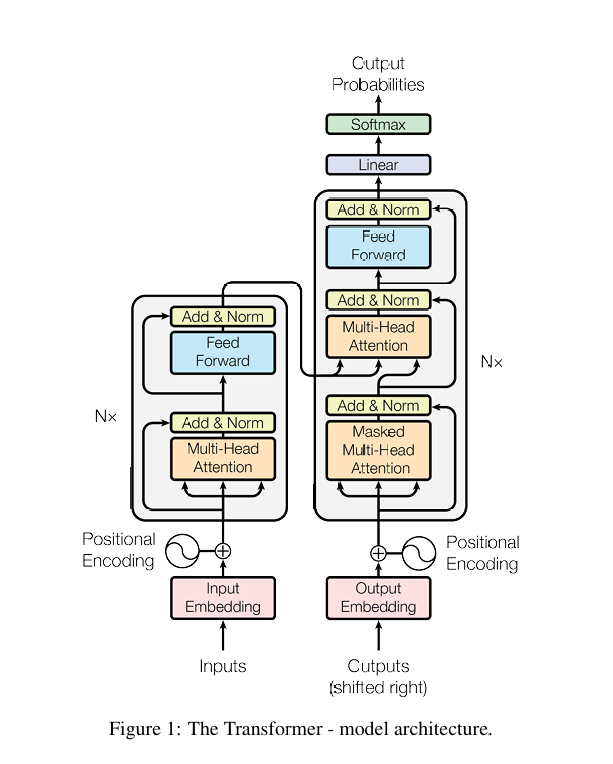
Transformer模型由两个主要部分组成:编码器(Encoder) 和 解码器(Decoder)。编码器将输入序列映射为中间表示(语义向量),解码器则根据这些中间表示生成目标序列。这种架构设计非常适合序列到序列的任务,如机器翻译、文本摘要等。
-
编码器结构:由N个相同层堆叠而成(原论文中N=6),每层包含两个子层:
-
多头自注意力机制(Multi-Head Self-Attention)
-
前馈全连接网络(Feed-Forward Network)
-
每个子层都配有残差连接(Residual Connection)和层归一化(Layer Normalization)
-
-
解码器结构:同样由N个相同层堆叠而成,但每层包含三个子层:
-
掩码多头自注意力机制(Masked Multi-Head Self-Attention,防止看到未来信息)
-
与编码器输出的Attention(Encoder-Decoder Attention)
-
前馈全连接网络
-
每个子层也同样配有残差连接和层归一化
-
2.2 自注意力机制
自注意力机制(Self-Attention)是Transformer架构的核心创新,它允许模型直接计算序列中任意两个元素之间的依赖关系,无论它们之间的距离有多远。这与传统的RNN和LSTM形成鲜明对比,后者需要逐步传递信息,难以处理长距离依赖。
自注意力机制通过查询(Query)、键(Key)和值(Value) 三个矩阵进行计算,其核心公式为:
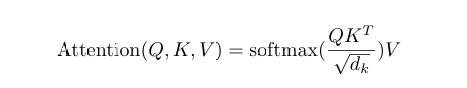
其中Q表示查询矩阵,K表示键矩阵,V表示值矩阵,d_k是键向量的维度(用于缩放)。缩放因子√d_k的作用是防止点积过大导致Softmax函数梯度消失。
自注意力机制的计算过程可以分为以下几步:
-
线性变换:将输入序列通过线性变换生成Q、K、V三个矩阵
-
注意力评分:计算Q和K的点积,得到每对词元之间的相关性分数
-
缩放处理:将得分除以√d_k,防止梯度消失
-
Softmax归一化:应用Softmax函数获得注意力权重(0-1之间)
-
加权求和:使用注意力权重对V值进行加权求和,得到输出向量
2.3 多头注意力机制
论文中进一步提出了多头注意力机制(Multi-Head Attention),这是自注意力机制的扩展形式。多头注意力通过并行运行多个独立的注意力头,使模型能够同时关注输入序列的不同子空间和信息方面。
具体而言,多头注意力机制:
-
将Q、K、V矩阵投影到多个低维子空间(原论文中使用8个注意力头)
-
在每个头上独立计算缩放点积注意力
-
将所有头的输出拼接起来
-
通过线性变换得到最终输出

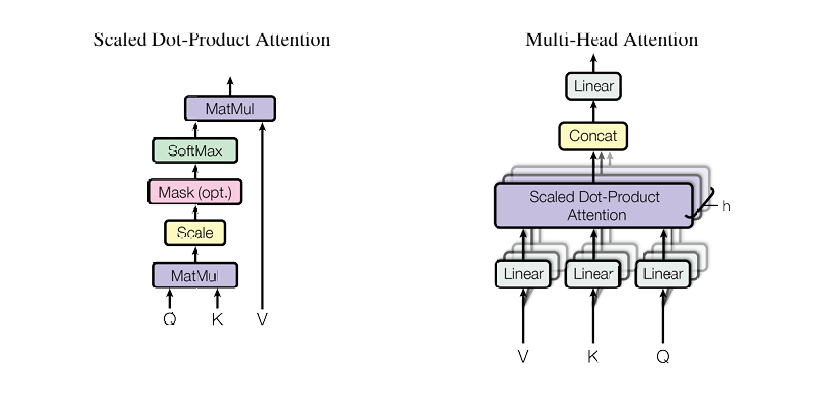
这种设计允许不同的注意力头专注于不同类型的语义关系,例如有些头可能关注语法关系,有些头可能关注语义关系,从而增强模型的表达能力和泛化能力。
2.4 位置编码
由于自注意力机制本身不对序列顺序敏感(即排列不变性),Transformer需要一种方法来注入序列的位置信息。论文提出了正弦和余弦位置编码(Positional Encoding),使用不同频率的正弦和余弦函数为每个位置生成独特的编码向量:
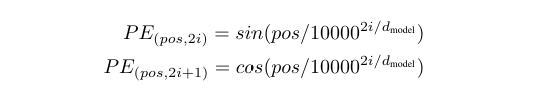
其中pos表示位置,i表示维度,d_model是模型维度。这种位置编码的设计使得模型能够轻松学习到相对位置信息,因为对于固定偏移量k,PE(pos+k)可以表示为PE(pos)的线性函数。
2.5 前馈网络与残差连接
Transformer中的前馈网络(Feed-Forward Network,FFN)是一个简单的两层全连接神经网络,对每个位置独立应用以下变换:
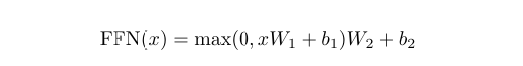
其中第一层使用ReLU激活函数,第二层是线性变换。FFN的作用是对自注意力机制提取的特征进行进一步变换和整合。
每个子层(自注意力和FFN)周围都添加了残差连接,然后进行层归一化(Layer Normalization)。残差连接有助于缓解深层网络中的梯度消失问题,而层归一化则提高了训练稳定性。层归一化的公式为:
其中μ和σ²是当前层的均值和方差,γ和β是可学习参数,ε是为了数值稳定性而添加的小常数。
2.6 传统RNN/LSTM与Transformer的对比
下表总结了传统序列模型与Transformer架构的主要区别:
|
特性 |
RNN/LSTM |
Transformer |
|---|---|---|
|
处理机制 |
顺序串行处理 |
并行处理所有词元 |
|
长距离依赖 |
难以处理,梯度消失 |
直接建模任意距离依赖 |
|
计算效率 |
低,难以并行化 |
高,充分利用GPU并行能力 |
|
上下文建模 |
有限上下文窗口 |
全局上下文建模 |
|
位置信息 |
天然顺序感知 |
需要显式位置编码 |
|
可解释性 |
较低 |
注意力权重提供可视化洞察 |
3 实验结果与性能分析
论文在两个机器翻译任务上对Transformer进行了测试:WMT 2014英德翻译(EN→DE)和WMT 2014英法翻译(EN→FR)。
3.1 翻译结果
Transformer取得了当时最先进的性能表现:
-
在英德翻译任务上,BLEU分数达到28.4,优于当时所有模型
-
在英法翻译任务上,BLEU分数达到41.8,同样显著优于传统模型
3.2 性能优势
相比传统的RNN和LSTM模型,Transformer展现出显著优势:
-
训练速度:训练速度是RNN模型的数倍,大幅缩短了模型开发周期
-
参数效率:参数利用更加高效,在相同参数量下表现更好
-
长序列处理:能够有效处理长序列,解决了长期依赖问题
-
并行化能力:完全并行化的计算使得大规模训练成为可能
4 Transformer的深远影响
4.1 推动大模型发展
Transformer架构为大规模预训练模型奠定了基础,催生了多个有影响力的模型家族:
-
GPT系列(生成式预训练Transformer):使用仅解码器架构,通过自回归方式生成文本,开创了生成式语言模型的新范式
-
BERT(双向编码器表示):使用仅编码器架构,通过双向注意力机制深度理解语言上下文,在多项NLP任务中取得突破性性能
-
T5/MT5:采用编码器-解码器完整架构,将所有NLP任务统一为"文本到文本"的转换框架
-
多模态模型:Transformer架构进一步扩展到多模态领域,如ViT(Vision Transformer)将图像处理转化为序列问题,开创了计算机视觉新范式
4.2 跨领域应用
Transformer的影响力远远超出了自然语言处理领域,广泛应用于:
-
计算机视觉:图像分类、目标检测、图像生成
-
语音处理:语音识别、文本到语音合成
-
多模态系统:图文理解、视频生成、跨模态检索
-
生物信息学:蛋白质结构预测、基因序列分析
5 理论意义与局限性
5.1 理论贡献
Transformer架构的核心理论贡献包括:
-
全局依赖建模:通过自注意力机制直接建立序列中任意两个位置之间的连接,解决了长距离依赖问题
-
并行计算范式:摆脱了序列顺序处理的约束,极大提高了计算效率
-
可解释性机制:注意力权重提供了模型决策过程的可视化洞察,增强了模型的可解释性
-
统一架构框架:为多种模态和任务提供了统一的建模框架,促进了AI领域的融合
5.2 局限性与发展
尽管革命性,Transformer仍存在一些局限性,这也为后续研究指明了方向:
-
计算复杂度:自注意力机制的计算复杂度是序列长度的平方级(O(n²)),处理长序列时内存消耗大
-
位置编码缺陷:正弦位置编码在处理远长于训练时的序列时可能表现不佳
-
能耗问题:大规模Transformer训练和推理需要大量计算资源,带来显著能源消耗
针对这些局限性,研究者们提出了多种改进方案:
-
高效注意力机制:如Longformer的稀疏注意力、Linformer的低秩近似、Performer的线性注意力等
-
改进位置编码:如可学习的位置嵌入、相对位置编码、旋转位置编码(RoPE)等
-
模型压缩技术:如知识蒸馏、量化、剪枝等减少模型规模和推理成本
-
混合架构:如RNN+Transformer混合模型、状态空间模型(如Mamba)等
6 总结与反思
《Attention is All You Need》这篇论文无疑是深度学习领域的重要里程碑,它提出的Transformer架构不仅彻底改变了自然语言处理领域,也对整个人工智能学科产生了深远影响。通过阅读这篇论文,我获得了以下核心启示:
-
简洁即力量:Transformer架构的核心思想异常简洁——仅使用注意力机制,但这种简洁性却带来了前所未有的性能和效率提升。这提醒我们在解决复杂问题时,有时最简单的方案是最有效的。
-
并行化思维:论文突破了序列建模必须顺序处理的思维定式,展示了如何通过巧妙的架构设计实现完全并行化,这对处理大规模数据具有重要意义。
-
通用性设计:Transformer架构展现出了惊人的通用性,不仅适用于NLP任务,后来还被广泛应用于计算机视觉、语音处理甚至生物信息学等多个领域。这种跨学科的通用性体现了其基础性价值。
-
基础创新价值:Transformer架构属于基础性创新,它并非对现有模型的渐进式改进,而是从根本上重新思考了序列建模的方式。这种基础创新虽然风险较高,但一旦成功,带来的影响也是革命性的。
-
开源与共享:论文作者公开了他们的研究成果,促进了整个领域的快速发展。这种开放精神加速了人工智能技术的进步,使更多人能够在此基础上进行建设和创新。
Transformer架构的成功启示我们,在人工智能研究中,架构创新与算法优化同样重要。随着技术的不断发展,Transformer可能会被更新的架构所超越,但其核心思想——利用注意力机制捕捉全局依赖,以及设计高度并行化的计算模式——将继续影响未来神经网络架构的发展方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)