【论文阅读】WebWalker: Benchmarking LLMs in Web Traversal
【导读】传统搜索只能“扫射”网页表层,而复杂答案往往藏在多级按钮之后。阿里通义实验室最新论文提出WebWalkerQA,用680个双语问答,首次系统评测大模型“翻网页找答案”的能力。作者还设计多智能体框架WebWalker,让探索者负责逐层点击,评论者实时记忆与判断,像人类一样深度遍历。实验显示,即使GPT-4o,准确率也不到40%,证明深度信息仍是RAG盲区。把WebWalker插入传统RAG后
https://arxiv.org/pdf/2501.07572
【导读】
传统搜索只能“扫射”网页表层,而复杂答案往往藏在多级按钮之后。阿里通义实验室最新论文提出WebWalkerQA,用680个双语问答,首次系统评测大模型“翻网页找答案”的能力。作者还设计多智能体框架WebWalker,让探索者负责逐层点击,评论者实时记忆与判断,像人类一样深度遍历。实验显示,即使GPT-4o,准确率也不到40%,证明深度信息仍是RAG盲区。把WebWalker插入传统RAG后,性能立涨,尤其擅长多源问答。想让你的AI不止会搜,还会点?这篇干货值得细读。
WebWalker:在网页遍历中LLMs的基准测试
吴家龙,尹文标,蒋勇,王正林,席泽坤,方润南,张林海,何玉兰,周德宇,谢鹏军,黄飞
Tongyi Lab ,AlibabaGrou
https://github.com/Alibaba- NLP/WebAgent
摘要
检索增强生成(RAG)在开放域问答任务中表现出色。然而,传统搜索引擎可能检索浅层内容,限制了大语言模型(LLM)处理复杂、多层信息的能力。为此,我们引入WebWalkerQA,这是一个用于评估LLM网页遍历能力的基准。它评估了LLM遍历网站子页面以系统性地提取高质量数据的能力。我们提出了WebWalker,这是一个多智能体框架,通过探索- 评价范式模拟类似人类的网页导航。大量的实验结果表明,WebWalkerQA具有挑战性,并通过在真实场景中的水平和垂直整合,展示了RAG与WebWalker结合的有效性。
1引言
大语言模型(LLM)在广泛的自然语言处理任务中展现了令人印象深刻的性能(Ouyang等人,2022年;OpenAI,2022a)。尽管它们的知识库在训练后保持静态,但通过检索增强生成(RAG)集成外部搜索引擎,允许LLM从网络检索最新信息,增强了它们在动态、知识密集型场景中的实用性(Lewis等人,2020年)。然而,传统的在线搜索引擎,例如Google或Bing,执行查询的水平搜索,可能无法有效地追踪嵌入在网站中的深层内容。
与网页交互并深入挖掘可以有效地解决这个问题。以往关于网页的研究主要关注基于动作的请求,例如Mind2Web (Deng 等人,2023)和WebArena (Zhou 等人,2024a);这些基于HTML的指令- 动作基准面临着信息过噪和输入过长等挑战,由于长上下文理解的限制,这会显著影响性能。此外,它们无法捕捉现实世界场景的复杂性,其中相关信息深埋于网页之中,需要多层交互才能获取。
为填补这一空白,我们提出了一个新的任务WebTraversal,给定一个与查询对应的初始网站,系统地遍历网页以发现信息。我们提出了WebWalkerQA,专门用于评估LLM在给定根网站上处理嵌入在复杂、多步网络交互中的查询的能力。WebWalkerQA侧重于基于文本的推理能力,使用问答格式来评估网络场景中的遍历和问题解决能力。我们将操作约束为“点击”以评估代理的导航和信息获取能力。这种范式更具针对性,并且与实际应用更契合。WebWalkerQA反映了现实世界的挑战,强调了教育、会议、组织和游戏领域源信息的深度,其中官方信息被发布,信息路径结构更清晰,带有可点击的按钮和推理逻辑。我们开发了多种类型,包括多源和单源问答,以评估LLM模仿不同人类网络导航范式的能力。
此外,我们介绍一个强大的基准——WebWalker,一个多智能体框架,旨在通过垂直探索模拟类似人类的网页导航。该框架由一个探索者智能体和一个评价者智能体组成。鉴于推理能力对于有效导航和交互网页的需求,探索者智能体基于ReAct框架(Yao等人,2023年)构建,利用思维动作观察范式,而评论家代理负责维护记忆,并根据探索者代理进行的探索生成响应。
我们使用WebWalkerQA作为基准,评估了WebWalker在各种主流LLM上的性能,包括闭源和开源的LLM。然而,即使使用最强大的LLM作为支撑,其在WebWalkerQA上的性能仍然不理想,从而验证了WebWalkerQA所提出的挑战。
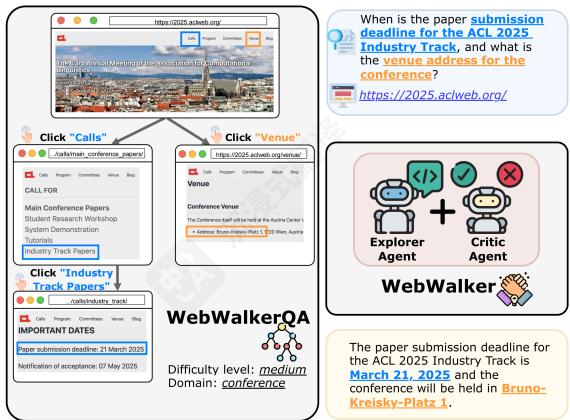
图1:Web-WalkerQA的一个多源QA示例,需要遍历网页以收集信息来回答给定的问题。
然后我们进行了进一步实验,以验证与RAG在信息检索问答任务中的集成。我们的研究结果如下:(i)在需要规划和推理的任务中,网络导航仍然需要改进;(ii)通过将RAG与WebWalker结合,这种横向并且垂直协调有效;(iii)对页面进行垂直探索为扩展RAG系统的推理时间提供了有前景的方向。
我们工作的贡献如下:
我们构建了一个具有挑战性的基准测试WebWalkerQA,它由来自四个真实世界场景、跨越超过1373个网页的680个查询组成。- 为了应对需要长上下文的网页导航任务,我们提出了WebWalker,它利用多智能体框架进行有效的内存管理。- 大量实验表明,WebWalkerQA具有挑战性,对于信息检索任务,页面内的垂直探索被证明是有益的。
2相关工作
2.1面向网页的基准测试
在大型语言模型(LLMs)的时代之前,已经提出了几个面向网络的基准测试(Liu等人,2018;Xu等人,2021;Humphreys等人,2022;Yao等人,2022;Mialon等人,2024;Xu等人,2024)。LLMs能够与复杂环境交互,例如HTML或DOM格式的开放网络(Tan等人,2024),这导致了越来越多旨在评估LLMs与网络内容交互能力的基准测试的开发。目前广泛使用的基准测试Mind2Web(Deng等人,2023)是一个用于评估遵循指令完成复杂任务的网络代理的数据集,通常通过多项选择题进行。后续工作将交互扩展到了
| 语言 | 格式 | 深度 | 宽度 | Hop | #页数 | |
| Mind2Web(邓等人,2023) | En | 多选 | × | × | × | 100 |
| WebArena(Zhou等人,2024a) | En | 动作 | × | × | × | 6 |
| AssistantBench(Yoran等人,2024) | En | QA | × | ✓ | ✓ | 525 |
| MMInA(张等人,2024c) | En | 动作 | × | ✓ | ✓ | 100 |
| GAIAMialon等人,2024) | En | QA | × | ✓ | ✓ | - |
| WebWalkerQA | En&Zh | QA | ✓ | ✓ | ✓ | 1373 |
表1:WebWalkerQA与其他基准的比较。深度指在给定网站上所需的探索程度。宽度表示回答查询是否需要多个来源。跳跃次数表示完成任务是否需要多个步骤。#页面指涉及到的网页数量。
视觉领域,结合了来自屏幕截图的信息(Zheng等人,2024a;b;He等人,2024a;Koh等人,2024a;Cheng等人,2024)。面向网络的基准测试正变得越来越像人类。以视觉为中心,并且越来越广泛、复杂和真实(Liu等人,2024;Hong等人,2024;Kim等人,2024;Zhang等人,2024c)。与我们最接近的是MMInA(Zhang等人,2024c)和AssistantBench(Yoran等人,2024),两者都专注于需要跨多页导航的耗时任务。在我们的工作中,WebWalkerQA采取问答对的形式。与所有先前的工作不同,我们从网站的宽度角度构建单源和多源查询,旨在模拟人类通常表现出两种类型的页面探索模式。WebWalkerQA与其他基准测试的比较显示在表2中。
2.2 Web导航代理
基于面向网络的基准测试,已经提出了许多网络代理(Nakano等人,2021;Liu等人,2023;Zhou等人,2023;Lai等人,2024;Zhou等人,2024b)。网络代理主要遵循两条发展路线:一条利用专门训练的小型语言模型来过滤动作或识别相关的HTML元素(Zheng等人,2024a;Deng等人,2024;Furuta等人,2024)。另一条路线专注于提示LLMs(Reddy等人,2024;Song等人,2024;Koh等人,2024b),其中使用不同的代理模块来指导模型更有效地完成复杂的网络导航任务。此外,随着面向视觉网络的基准测试的兴起,许多代理现在使用截图作为感官输入(He等人,2024b;Abuelsaad等人,2024;Iong等人,2024)。与之前的工作不同,WebWalker专门通过推理HTML按钮数据来进行信息搜索。它通过模拟人类般的页面交互来访问网络页面,利用多代理框架获取可靠、权威的信息。
3 WebWalkerQA
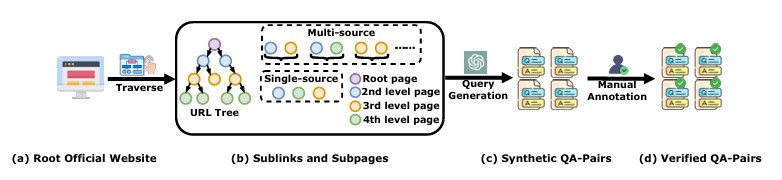
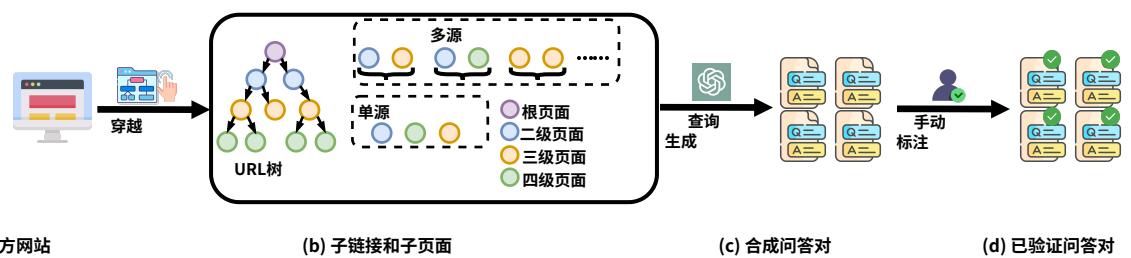
图2:WebWalkerQA数据生成流程。我们首先收集会议、组织、教育和游戏领域的根官方网站。然后通过在根页面上系统地点击和收集通过子链接可访问的子页面来模拟人类行为。使用预定义规则,我们利用GPT4o根据收集到的信息生成合成QA对,随后进行人工验证以确保准确性和相关性。
在本节中,我们介绍了WebWalkerQA,首先概述了数据收集过程以确保质量(§3.1),然后讨论了WebWalkerQA的统计数据(§3.2)。最后,我们介绍了新任务Web导航,并描述了WebWalkerQA的评估指标(§3.3)。
3.1数据收集
为了使标注过程既经济又准确,我们采用了一种两阶段漏斗式标注策略,结合基于大型语言模型(LLM)的标注和人工标注。在第一阶段,GPT- 4o(OpenAI,2022b)执行初始标注,然后在第二阶段,众包的人工标注员进行质量控制和筛选,以优化最终结果。整体数据收集流程如图2所示。
基于大型语言模型的标注
- 步骤1:递归遍历官方网站,收集可访问的子链接及其对应页面的信息。- 步骤2:根据提供的页面信息和指定的角色构建查询,例如专注于单页或同时考虑两页。- 步骤3:验证并筛选出偏离自然、类人表述的合法查询,仅保留包含实体的简短答案的问答对。
附加细节,包括特定步骤的提示和案例示例,在附录E中提供。如图2(b)所示,我们的数据集构建包括多源和单源两种类型,对应于网页内两种类型的人类信息寻求行为。单源类型模拟用户深入探索网页中隐藏的单个信息,而多源类型模拟用户依赖多个页面来解决查询的多源场景。值得注意的是,多源问答任务不容易被搜索引擎捷径(Mavi等人,2024)利用。
人工标注在LLM生成的合成查询后,人工标注员可以重写和校准问题和答案,以确保问答对是正确和一致的。
3.2数据统计
通过这种包含LLM和人工参与的数据构建方法,我们获得了680个WebWalkerQA问答对。标注案例如图8所示。我们将提供WebWalkerQA的全面统计数据,按类型、领域和语言分类。
TypeWebWalkerQA包含两种类型的数据:多源问答和单源问答。单源问答被标记为单_源,其中i∈[2,4],表示相应子页面的深度。类似地,多源问答被标记为多_源,其中i∈[2,8],表示两个相关子页面2的深度之和。换句话说,回答此查询需要同时读取这两个页面。
| 单源问答 | 多源问答 | ||||
| 8 Easy | 8 O 中等 | 8 O Hand | 8 O Easy | 8 O 中等 | 8 O Hand |
| 80 | 140 | 120 | 80 | 140 | 120 |
表2:数据难度级别上的数据集统计。
难度等级我们根据i的值将问题分为三个难度等级:简单、中等和困难。具体来说,single_source2single_source3,和single_source4分别对应
简单、中等和困难等级。类似地,对于多源问题,multi_source 2−4_{2 - 4}2−4 、multi_source 4−6_{4 - 6}4−6 和multi_source 6−8_{6 - 8}6−8 分别对应简单、中等和困难等级。不同数据类型的数据统计结果展示在表2中。
Domain WebWalkerQA包含四个现实世界领域:会议、组织、教育和游戏。这些领域被选中是因为它们提供了与其各自领域相关的权威信息,并且它们的页面包含丰富的可点击内容,为探索提供了相当大的深度。
语言WebWalkerQA是一个双语数据集,包括中文和英文 3^{3}3 ,反映了现实世界网络环境中最广泛使用和通用的语言。
WebWalkerQA在领域和语言上的统计数据在图3中说明。会议、组织、教育和游戏领域的有效比例分别为 24.0%24.0\%24.0% 、 7.9%7.9\%7.9% 、 46.3%46.3\%46.3% 和 24.0%24.0\%24.0% 。从语言分布来看,中文和英文分别占 60.5%60.5\%60.5% 和 39.5%39.5\%39.5% 。WebWalkerQA具有多样化的语言和领域分布,以确保全面的评估。
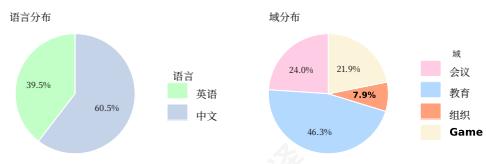
图3:语言和领域分布。
3.3网页遍历任务与评估
形式上,给定一个初始网站URLUroot和一个需要通过探索网站来回答的查询 QQQ 。该任务的目标是通过页面遍历收集足够的信息,最终回答查询 QQQ 。该任务是通过导航网站来找到相应信息。
WebWalkerQA可以从性能和效率的角度进行评估。使用问答准确率(acc.)作为性能指标,以及成功代理执行的正确回答的动作计数(A.C.)作为效率指标。由于生成文本长度的不同,即使我们控制了简短答案,进行精确匹配评估仍然具有挑战性。我们使用GPT- 4作为评估器,它通过使用CoT提示策略(Wei等人,2022)4将预测答案与真实答案进行比较来确定答案的正确性。
4 WebWalker
我们介绍了WebWalker,这是一个多智能体框架,旨在与网络环境交互以回答查询。WebWalker框架由两个智能体组成:一个探索智能体和一个评估智能体。如图4所示,探索智能体在Thought- Action- Observation(T,A,O)范式下遍历网页。评估智能体更新内存,直到积累足够的信息以有效回答查询。关于两个智能体的提示的详细信息在附录E.3中呈现。
4.1先思考再探索
探索代理通过交互页面上的HTML按钮来探索子页面。在时间步t,探索代理从web环境接收观察 Ot\mathcal{O}_tOt 并采取行动 AtA_tAt ,遵循策略 π(At∣Ht)\pi (\mathcal{A}_t|\mathcal{H}_t)π(At∣Ht) 。观察 Ot=(pt,lt)\mathcal{O}_t = (p_t,l_t)Ot=(pt,lt) 包含当前页面 pt\mathbf{p}_tpt 的信息以及一组可点击的子链接 lt={buttoni}i=1Kl_t = \{button_i\}_{i = 1}^Klt={buttoni}i=1K ,其中每个按钮 iii 描述HTML按钮信息
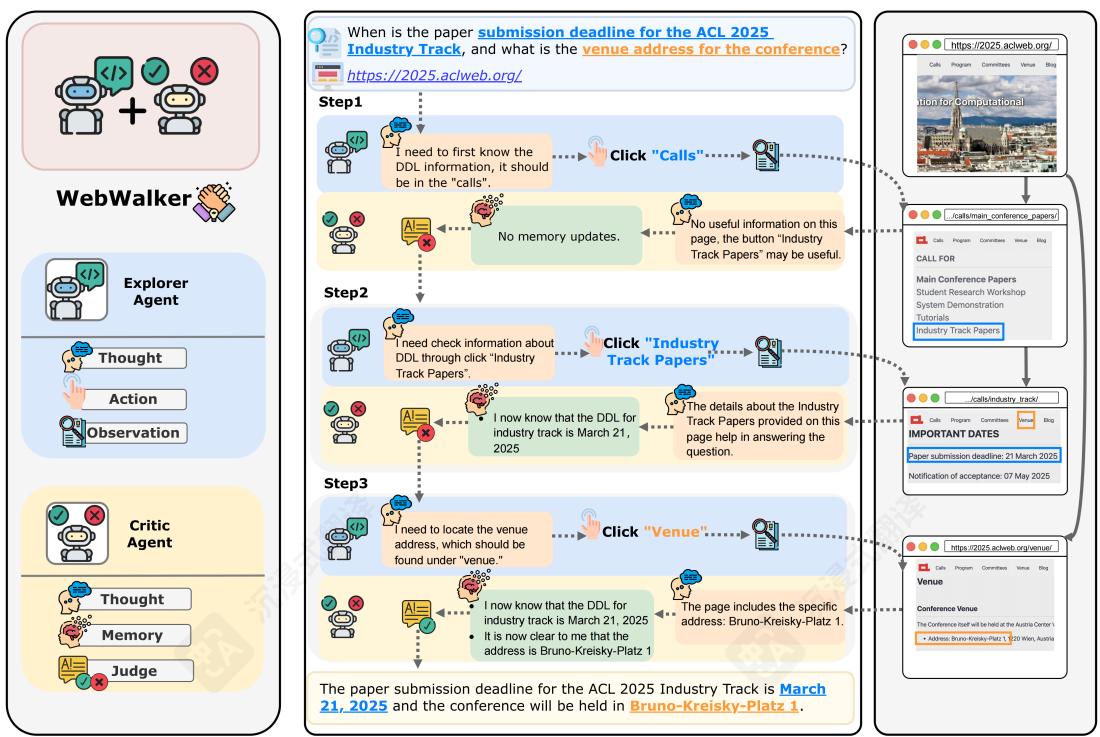
图4:WebWalker的整体框架。
用于K个子链接中的一个,并具有关联的URL。行动 At\mathcal{A}_tAt 涉及选择要探索的子页面的URL,并不包括回答问题。具体来说,我们使用网页的markdown内容以及使用BeautifulSoup提取的可点击HTML按钮(以及相应的URL)作为当前页面的观察。上下文 Ht=(Tt,At,O1t,…,Ot−1,Tt,At,Ot)\mathcal{H}_t = (\mathcal{T}_t, \mathcal{A}_t, \mathcal{O}_{1t}, \dots , \mathcal{O}_{t - 1}, \mathcal{T}_t, \mathcal{A}_t, \mathcal{O}_t)Ht=(Tt,At,O1t,…,Ot−1,Tt,At,Ot) 表示到达当前步t的过去观察和行动的序列。上下文将被更新,并且这个探索过程将持续进行,直到评论代理决定回答查询或达到最大步数。
4.2 思考然后批判
由于政策 π(At∣Ht)\pi (\mathcal{A}_t | \mathcal{H}_t)π(At∣Ht) 是隐式的,并且 Ht\mathcal{H}_tHt 可能会很大,受结对编程(Williams等人,2000年;Noori & Kazemifard,2015年)的启发,我们将一个批判代理集成到WebWalker框架中,以应对这些挑战。批判代理在探索代理每次执行后运行。它的输入包括查询和探索代理的当前观察。批判代理初始化一个内存来增量累积相关信息。形式上,在探索代理执行后的每一步t,批判代理将查询 Q\mathcal{Q}Q 和探索代理的当前观察和动作 (Ot,At)(\mathcal{O}_t, \mathcal{A}_t)(Ot,At) 作为输入。然后它更新内存 M\mathcal{M}M ,评估收集到的信息是否足够完整以回答查询,并在所需信息被认为足够时提供答案。
5 实验
5.1 实验设置
基线我们选择广泛认可的当前最佳代理框架ReAct和Reflexion作为我们的基线。ReAct(Yao等人,2023)是一种通用范式,通过多个思维- 行动- 观察步骤将推理和行动与LLM结合。Reflexion(Shinn等人,2024)是一个单代理框架,旨在通过反馈强化语言代理。
| 骨干网络 | 方法 | 单源问答 | 多源问答 | 总体 | |||||||||||
| Easy | 爆炸 | Hard | Easy | Medium | Hard | ||||||||||
| acc. | A.C. | acc. | A.C. | acc. | A.C. | acc. | A.C. | acc. | A.C. | acc. | A.C. | ||||
| Closed-So urced LLMs | |||||||||||||||
| GPT-4o | ReAct | 53.75 | 2.53 | 45.00 | 3.34 | 30.00 | 5.61 | 32.50 | 2.34 | 31.43 | 3.97 | 15.00 | 6.77 | 33.82 | 3.83 |
| Reflexion | 56.25 | 2.91 | 51.43 | 3.88 | 30.83 | 5.75 | 35.00 | 3.67 | 27.14 | 4.38 | 16.67 | 7.05 | 35.29 | 4.27 | |
| WebWalker | 55.00 | 2.91 | 50.00 | 3.43 | 30.00 | 6.02 | 47.50 | 4.00 | 34.29 | 4.38 | 15.83 | 6.57 | 37.50 | 4.67 | |
| Qwen-Plus | ReAct | 48.75 | 1.67 | 48.57 | 2.69 | 28.33 | 4.00 | 35.00 | 2.60 | 27.86 | 3.11 | 14.17 | 6.55 | 33.08 | 3.03 |
| Reflexion | 53.75 | 3.66 | 40.00 | 3.79 | 24.17 | 5.88 | 47.50 | 3.28 | 30.00 | 4.07 | 15.00 | 7.11 | 33.23 | 4.32 | |
| WebWalker | 55.00 | 3.72 | 47.14 | 3.19 | 30.00 | 6.13 | 35.00 | 3.89 | 27.14 | 4.39 | 15.00 | 7.38 | 33.82 | 4.36 | |
| Open-Sourced LLMs | |||||||||||||||
| Qwen-2.5-7B | ReAct | 37.50 | 3.36 | 18.57 | 4.88 | 9.17 | 5.45 | 17.50 | 3.42 | 11.43 | 3.62 | 5.83 | 4.57 | 16.02 | 2.99 |
| Reflexion | 37.50 | 4.03 | 25.00 | 3.48 | 11.67 | 4.57 | 30.00 | 2.66 | 15.71 | 5.45 | 4.17 | 7.8 | 19.11 | 4.07 | |
| WebWalker | 41.25 | 4.39 | 24.71 | 3.86 | 12.50 | 5.93 | 18.75 | 3.00 | 20.71 | 3.34 | 5.83 | 7.28 | 19.85 | 3.94 | |
| Qwen-2.5-14B | ReAct | 36.25 | 1.86 | 32.14 | 2.75 | 15.00 | 3.61 | 27.50 | 2.31 | 22.86 | 3.00 | 5.00 | 5.00 | 22.35 | 2.76 |
| Reflexion | 46.25 | 2.21 | 34.29 | 2.83 | 15.00 | 4.44 | 36.25 | 2.51 | 22.86 | 3.34 | 5.83 | 5.42 | 25.14 | 3.01 | |
| WebWalker | 41.25 | 2.42 | 41.43 | 3.24 | 23.33 | 4.42 | 30.00 | 3.95 | 22.86 | 3.56 | 10.00 | 6.16 | 27.50 | 3.60 | |
| Qwen-2.5-32B | ReAct | 47.50 | 2.21 | 35.71 | 3.20 | 16.67 | 3.55 | 36.25 | 2.68 | 18.57 | 3.00 | 8.33 | 3.70 | 25.44 | 2.93 |
| Reflexion | 42.50 | 2.52 | 32.86 | 2.65 | 16.67 | 3.90 | 31.25 | 2.84 | 23.57 | 3.12 | 5.83 | 5.00 | 23.26 | 3.00 | |
| WebWalker | 41.25 | 2.69 | 34.29 | 4.14 | 22.50 | 5.14 | 27.50 | 3.13 | 25.00 | 3.51 | 10.00 | 6.08 | 26.02 | 3.90 | |
| Qwen-2.5-72B | ReAct | 47.50 | 1.68 | 38.57 | 2.79 | 20.00 | 4.04 | 45.00 | 2.25 | 32.14 | 3.13 | 10.00 | 5.41 | 30.73 | 2.86 |
| Reflexion | 57.50 | 3.04 | 44.29 | 3.88 | 28.33 | 5.82 | 36.25 | 3.62 | 25.00 | 3.60 | 12.50 | 6.26 | 32.50 | 4.09 | |
| WebWalker | 58.75 | 2.70 | 48.57 | 3.07 | 25.83 | 5.77 | 35.00 | 3.57 | 29.29 | 4.87 | 15.00 | 7.38 | 33.26 | 4.32 | |
表3:三种方法在闭源和开源LLM作为主干时的主要结果。Acc.和A.C.分别指准确率和动作计数。
主干为了全面评估现有基于LLM的代理的网页遍历能力,我们选择上下文窗口至少为128K的模型,以适应页面信息的长度。鉴于任务的固有复杂性,我们选择参数至少为7B的模型。我们验证了总共九个模型,包括闭源和开源的模型:
闭源LLM GPT- 4o5(OpenAI,2022b);Qwen- Plus6(团队,2024);开源LLM Qwen2.5系列模型(Yang等人,2024年)具体来说,Qwen2.5- {7,14,32,72}B- Instruct.7
实现细节考虑到模型的上下文限制,我们提出的WebWalker,以及两个基线,都在零样本设置下运行。我们将探索者代理的动作数量K限制为15,这意味着探索者代理最多可以执行15步。更多实现细节在附录B中介绍。
5.2主要结果
六种LLM的主要结果如表3所示,闭源模型在性能和效率方面都优于开源模型。对于开源模型,随着模型规模的增加,性能和效率会提高。我们提出的WebWalker框架优于Reflexion,Reflexion又优于React。我们只统计了正确执行的动作次数(A.C.),随着模型规模的增加,A.C.会增长,表明更大的LLM具有更强的长程信息搜索能力。即使使用GPT- 4o作为核心的WebWalker表现最好的情况也不超过 40%40\%40% ,突出了WebWalkerQA带来的挑战。可以观察到,随着深度的增加或所需信息来源数量的增加,获取解决查询所需信息的难度会更大,导致准确性能下降。
不同方法在各种模型上的准确率和动作计数性能分布是显示在图5. 越靠近右上角,网络遍历就越有效和持久。我们观察到,增加模型大小或在每个动作过程中引入反射可以解决某些需要多步解决方案的问题,从而在网络遍历任务中实现长距离任务解决能力。
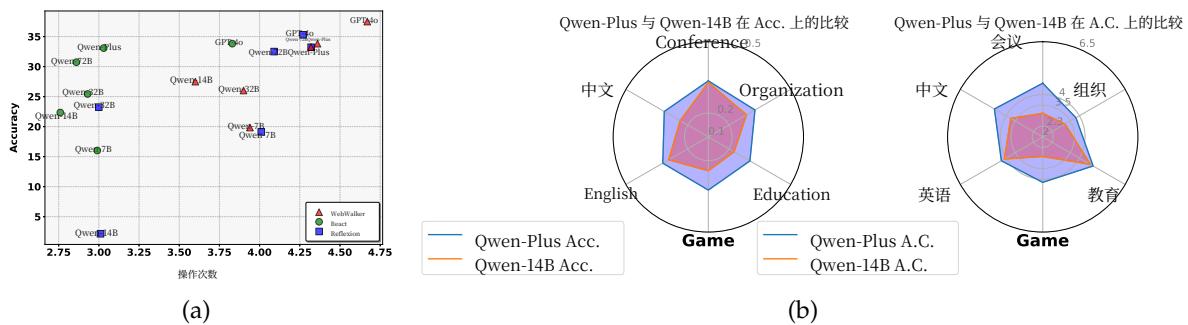
图5:(a) ▲ 表示使用各种模型作为骨干的WebWalker,■ 表示使用不同骨干模型的Reflextion,● 表示使用各种骨干模型的ReAct。(b) 基于Qwen-14B和Qwen-Plus的WebWalker在不同领域和语言上的性能。
5.3 跨领域和跨语言的结果
WebWalkerQA 是一个包含中文和英文的双语数据集,涵盖了多个领域,包括游戏、会议、教育和组织。不同领域和语言下的性能如图?? 所示。在会议领域,该框架表现出相对优越的性能,这可能是由于按钮信息更具明确性和指令性,从而促进了更直接的推理。该框架在中文和英文中的表现相似,因为我们使用的模型都是在双语环境下进行预训练和监督微调的。
5.4 错误评估
对于执行错误,错误也可以分为三种类型:拒绝回答或定位错误、推理错误以及超过最大步数K。预测分布如图6所示。使用ReAct框架的参数数量相对较少的模型缺乏探索信息深度的能力,在仅进行几次行动迭代内就做出判断,无论是否找到相关信息。它倾向于“放弃”,并表现出不耐烦的特征。引入内存管理长上下文,并增加模型参数,提供了证据表明这种现象源于长上下文干扰存在噪声
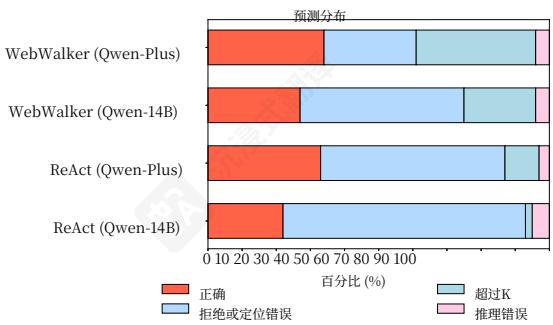
图6:基于Qwen-14B和Qwen-Plus的WebWalker和React方法预测分布。
信息以及模型本身的固有功能,与 §5.2 中得出的分析一致。一些错误被归类为推理错误,其中黄金页面已在访问页面中找到,但仍然被错误标记。这突显了在某些情况下对页面信息进行推理的挑战。8
| 系统 | 单源问答 | 多源问答 | 总体 | ||||
| Easy | 中 | Hard | Easy | 中 | Hard | ||
| 关闭书籍(无法检索) | |||||||
| Gemini-1.5-Pro | 12.50 | 7.86 | 8.33 | 11.25 | 6.43 | 5.00 | 8.08 |
| ol-preview | 16.25 | 10.00 | 9.17 | 7.50 | 10.71 | 6.67 | 9.85 |
| Commercial Systems | |||||||
| Doubao | 40.00 | 15.00 | 18.33 | 13.75 | 8.57 | 10.00 | 16.76 |
| Gemini-Search | 40.00 | 32.14 | 29.17 | 30.00 | 23.57 | 17.50 | 27.94 |
| ERNIE-4.0-8K | 52.50 | 30.00 | 28.33 | 21.25 | 18.57 | 30.00 | 28.97 |
| Kimi | 77.50 | 41.43 | 40.83 | 26.25 | 26.43 | 22.50 | 37.35 |
| 通义 | 41.25 | 45.00 | 41.67 | 40.00 | 41.43 | 34.17 | 40.73 |
| 开源系统 | |||||||
| 朴素 RAG | 37.50 | 25.71 | 24.17 | 20.00 | 14.29 | 12.50 | 20.73 |
| MindSearch | 15.00 | 11.43 | 10.83 | 8.75 | 12.14 | 10.00 | 11.32 |
| Avg. | 37.50 | 24.29 | 23.42 | 19.86 | 18.02 | 16.48 | - |
表4:商业和开源搜索增强RAG系统的准确率结果
6讨论
6.1RAG Performance on WebWalkerQA
我们评估了RAG系统在应对WebWalkerQA挑战方面的性能,具体来说,它们是否能够检索深度信息,如表4所示。
我们首先使用最先进的模型OpenAIol(OpenAI,2024)和没有检索的Gemini- 1.5- Pro在闭卷设置下评估性能。然后我们访问几个商业和开源RAG系统的性能。不进行搜索,即使是强大的模型也表现出非常差的性能。WebWalkerQA是基于官方网站且信息动态更新的,而预训练模型依赖于静态知识,受截止日期限制且缺乏动态更新。商业和开源RAG系统在WebWalkerQA上的表现相对较差,最好的结果来自通义,仅达到 40%40\%40% 。商业RAG系统通常是模块化的,由重写、路由器、重排序和其他组件组成。一些系统,如ERNIE,可能具有更强的中文搜索能力,从而导致更高的值。对于开源RAG系统,多源查询的准确率低于单源查询,这验证了WebWalkerQA提出的挑战,因为搜索引擎无法在一次或几次单次水平搜索尝试中检索所有相关信息。此外,随着难度的增加,例如信息深度变深,性能往往会下降。总的来说,搜索引擎在检索更深层次的内容时仍然面临挑战。
发现(i):RAG系统在需要有效网络遍历的关键挑战上存在困难。
6.2 WebWalker与RAG系统
标准的RAG系统可以被视为针对查询在相关文档中进行水平搜索,而WebWalker可以被认为是一种垂直探索方法。WebWalker可以无缝集成到标准的RAG系统中,以获取深度信息并增强问题解决能力。我们将基于Qwen- 2.5- Plus构建的WebWalker集成到朴素RAG系统中,详细结果如图7(a)所示。WebWalker的核心贡献是为问答提供有用信息;具体来说,评论代理的内存 M\mathcal{M}M 被追加到相关文档中以辅助生成。观察到,在集成后,所有难度级别的性能都有所提高,尤其是在多源类别中。
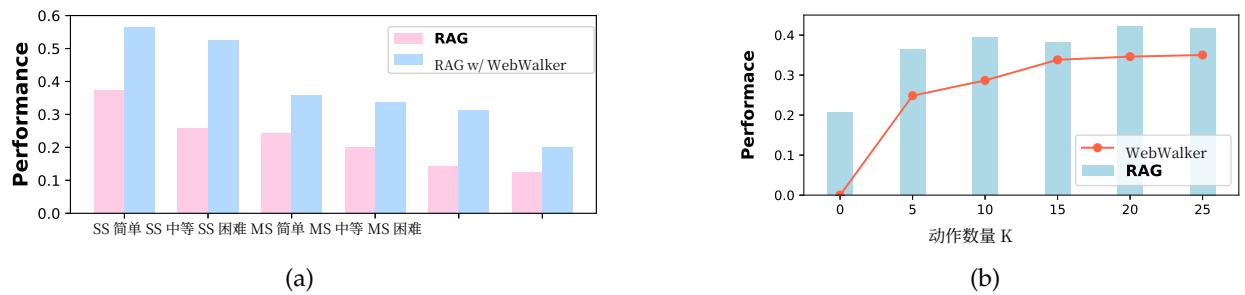
图7:(a)标准RAG和与WebWalker组合配置下的性能。SS和MS表示单源和多源QA。(b)在不同K值下WebWalker和RAG组合WebWalker的整体性能,使用Qwen-Plus作为主干。
发现(ii):WebWalker可以是智能体RAG系统中的一个模块,实现垂直探索。
6.3 在动作计数K上扩展
先前工作(Yue等人,2024)通过研究增加检索文档的影响,探索了RAG系统的推理扩展规律。我们将 K∈{5,10,15,20,25}\mathrm{K} \in \{5,10,15,20,25\}K∈{5,10,15,20,25} 的数量扩展以研究在追踪源信息时推理阶段扩展的影响。图7(b)显示了扩展的结果,其中K的值越大性能越好,验证了在一定范围内垂直扩展的可行性。
发现(iii):扩展挖掘链接的过程可能代表RAG系统垂直探索的一个潜在方向。
7结论
我们介绍了WebWalkerQA,一个用于评估LLM在复杂、多步骤信息搜索任务中网络遍历能力的基准。我们还提出了WebWalker,一个模仿人类式网络导航的多智能体框架,结合探索和批判。实验表明WebWalkerQA有效地挑战了RAG系统,并且将RAG与WebWalker结合提高了网络导航性能。我们的工作强调了深度、垂直探索在网络任务中的重要性,为集成RAG的、更具可扩展性和可靠性的基于LLM的信息检索铺平了道路。
A 限制与讨论
我们讨论以下限制:
数据集大小:由于网络代理领域的查询复杂性,类似于AssistantBench(Yoran 等人,2024)(214)和MMIna(Zhang等人,2024c)(1,050)等基准测试,以及GAIA(Mialon 等人,2024)(466),我们提出的WebWalkerQA目前包含680个高质量的问答对。此外,我们还拥有大约14k个银质问答对集合,尽管尚未经过仔细人工验证,但可以作为补充训练数据来提升代理性能,仍有进一步探索的空间。
多模态环境:在这项工作中,我们仅利用HTML- DOM来解析可点击按钮。实际上,视觉模态,如图像截图,也可以提供辅助并提供更直观的方法(Nguyen等人,2024;Zhang等人,2024a;He等人,2024b)。我们将其留待未来工作。
代理调优:WebWalker由提示驱动,无需额外训练。我们可以使用agenttuning帮助LLM学习网页遍历。这涉及使用黄金轨迹微调模型,使它们能够为完成信息检索任务采取有效行动(Zeng等人,2024;Chen等人,2024b;Zhang等人,2024b;Qiao等人,2024;Zhu等人,2024)。
与RAG系统更好的集成:在 §6.2\S 6.2§6.2 中,为WebWalker提供了根url以执行。为了更好地与RAG系统集成,一种方法可以是首先在RAG系统中重写查询以细化搜索,将其指向可能包含相关信息的查询的官方网站。然后可以使用WebWalker提取有用信息。从RAG系统检索到的知识和WebWalker挖掘的信息可以结合作为增强检索知识用于生成,从而获得更好的结果。
WebWalker可以独立作为网页信息检索助手,或与RAG系统无缝集成以扩展其范围。在代理式RAG范式下,点击操作被证明非常有效。
B 实现细节
B实现细节在本研究中,我们使用Qwen- Agent作为构建和开发所提出的WebWalker基准的基础代码库。生成LLM超参数的详细信息如下: topp=0.8\mathrm{top}_p = 0.8topp=0.8 。我们衷心感谢ai4crawl的贡献者和维护者,他们的开源工具帮助我们以类似Markdown的格式获取网页。我们将发布WebWalker的代码到GitHub。
C RAG系统的细节
我们选择了五个主流商业系统和两个开源系统进行评估
C.1商业系统
百度13,ERNIE- 4.0- 8K14,通义、金句和Gemini- Search都是通过其面向业务的API接口进行访问以确保可复现性。每个API的详细配置可以在我们的代码库中找到。
C.2开源系统
(a)Mindsearch(陈等人,2024a)是在网页信息搜索和整合中模仿人类思维,这可以通过一个由WebPlanner和
注释数据格式

图8:WebWalkerQA中的一个JSON格式案例。
WebSearcher组成的多智能体框架来实现。(b)从头开始构建的Naive RAG我们使用Google查询相关术语,并将Top- 10返回链接中的信息与查询连接起来,为Qwen- Plus生成响应提供指令。
D 注释案例
图8显示了注释案例。WebWalkerQAdataset将在HuggingFace Datasets中提供。
E 注释详情
E.1根页面来源
通过使用“会议官方网站”或“游戏官方网站”等关键词进行谷歌搜索,最初识别根页面,然后进行人工筛选。对于教育领域,我们选择各个大学计算机科学系的官方网站,紧密反映现实场景。域名分布如图3所示。
E.2注释提示的详细信息
GPT- 4o- based初始标注的提示如下所示
多源数据注释提示
问题生成
你是一位专业的网页内容分析师。根据提供的材料,构建一个查询语句:子链接1URL;子链接1INFO子链接2URL;子链接2信息子链接nURL;子链接n信息###要求:1. **查询的核心目标**:创建一个多- 步的独立查询,用户需要整合至少两个子链接中的信息以找到最终答案。答案应该是单一、清晰、简洁且精确的实体。2. **子链接的相关性**:所选的子链接必须具有内在联系应该通过结合这两个子链接的信息来推导得出。3. 逻辑和复杂:构建的查询应尽可能复杂和具体,具有挑战性,并可以利用时间、序列或常见主题来构建自然连贯的推理过程。避免关于浏览历史、浏览路径等没有实际价值的问题。4.答案的准确性:确保答案准确、简洁,并与查询中构建的逻辑链紧密相连。
请以JSON格式返回,结构如下:
“sublink_reason”:“描述选择这些特定子链接的原因以及它们如何相互关联。”,“sublinks”:[“选定的子链接URL”,“选定的子链接URL”],“reason”:“解释设计此查询的原因以及它如何鼓励用户参与多- 步推理。”,“query”:“您的查询语句”,“answer”:“对查询的答案”(@\textcolor\blue}子链接1URL;子链接1信息\子链接2URL;子链接2信息…\子链接nURL;子链接n信息}@*)
问答验证
你将扮演一个严格的裁判。你需要评估是否仅通过结合两个文档(doc1和doc2)以及提供的答案,可以准确回答给定的查询。此外,还需要检查答案是否简洁(作为一个实体或一个判断)并且正确。
如果答案不正确,只能使用一个文档回答,或者不够简洁,你应该返回false。如果任何文档(doc1或doc2)不包含答案所需的键信息,并且仅提供查询的背景信息,你应该返回false。如果任何文档仅提供与答案无关的查询背景信息,并且不提供必要的答案信息,你应该返回false。需要结合两个文档的信息,你应该返回false。如果答案是长答案且不是实体类型,你应该返回false。如果查询不自然,看起来不完整,或者语气严厉,你应该返回false。每个问题都应该需要结合两个文档的信息,这意味着答案结果来自多- 跳推理或多- 步推理,并且对于你来说返回true是简洁的。你非常严格,任何不符合上述标准的案例都应该导致false。请返回json{ “translation”,} “reason”:"请按上述条件的顺序逐一考虑,以评估查询和答案"满足标准。如果它们确实满足标准,请列出每个文档中有助于回答问题的部分。问题。“决策”:“true/false”(@蓝色文字{Doc1INFO};{Doc2INFO} @∗@\ast@∗
单源数据标注提示
问题生成
问答验证
您将扮演一名严格的裁判。您需要根据提供的两份文档(doc1和doc2)以及给定的答案,评估当前知识(来自doc2)是否需要准确回答给定的查询。Doc1代表已知知识,而doc2代表当前知识。您的任务是确定答案是否依赖于doc2才能准确提供。此外,评估答案是否简短(实体或判断)且正确。
如果答案不正确或不简洁,返回false。如果在已知知识文档doc1中找到必要的键信息,也返回false。如果答案是长答案且不是实体类型,返回false。如果查询不自然、不完整或措辞尴尬,返回false。答案应通过多- 跳推理或多- 步推理得出,其中多- 步推理表示生成的查询具有挑战性,需要推理或计算来回答,并且只有当答案简洁时才返回true。
你极其严格,任何未满足的要求都应返回false。
json{ “translation”: "}
json{ “translation”: "} json{ "reason": "根据上述条件逐步进行评估,考虑查询和" 答案符合条件。使用英语进行说明,如果符合,请列出 doc2 中的部分。 协助回答查询。 "决策": "true/false" }
E.3详细说明代理提示
Explorer Agent和 Critic Agent的下所示。
Prompts for WebWalker
The Expoloer Agent
Digging through the buttons to find quality sources and the right information. You have access to the following tools:
∗∗Q^{\ast \ast \mathcal{Q}}∗∗Q \textcolor{blue}{{tool},{descs}}@*)
Use the following format:
Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [tool_names] Action Input: the input to the action Observation: the result of the action … (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Begin!
∗∗Q^{\ast \ast \mathcal{Q}}∗∗Q \textcolor{blue}{{query}}@*)
The Critic Agent
∗∗Q^{\ast \ast \mathcal{Q}}∗∗Q \textbf{critic} @*)
You are a critic agent. Your task is to analyze the given observation and extract information relevant to the current query. You need to decide if the observation contains useful information for the query. If it does, return a JSON object with a “usefulness” value of true and an “information” field with the relevant details. If not, return a JSON object with a “usefulness” value of false.
**Input:** - Query: “”
- Observation: “”
**Output (JSON)😗*
1
“usefulness”: true,
“information”: “”
Or, if the observation does not contain useful information:
* usefulness’: false
-
Query: (∗Q)(\ast \mathcal{Q})(∗Q) \textcolor{blue}{{Query}}@*)
-
Observation: (∗Q)(\ast \mathcal{Q})(∗Q) \textcolor{blue}{{Observation}}@*)
∗∗Q^{\ast \ast \mathcal{Q}}∗∗Q \textbf{Answer} @*)
You are a critic agent. Your task is to evaluate whether the accumulated useful information is sufficient to answer the current query. If it is sufficient, return a JSON object with a “judge” value of true and an “answer” field with the answer.
If the information is insufficient, return a JSON object with a “judge” value of false.
**Input:**
-
Query: “”
-
Accumulated Information: “”
**Output (JSON)😗*
1
你是一位正在批改测验的教师。
你将得到一个问题、该问题所属的上下文以及学生的答案。你需要根据上下文,将学生的答案评为正确或错误,根据上下文以逐步的方式写出你的推理,以确保你的结论是正确的。避免简单地在开头陈述正确答案。
示例格式:
问题:这里提问背景:这里提供问题背景学生答案:这里填写学生的答案解释:这里逐步说明推理过程等级:此处填写正确或错误
仅根据学生的factualaccuracy评分。忽略标点符号和学生答案与正确答案之间的措辞差异。如果学生答案包含比正确答案更多的信息,只要它不包含任何相互矛盾的陈述即可。开始!
问题:(*@\textcolor{blue}{{{query}}}@)背景:(*@\textcolor{blue}{{{answer}}}@)学生答案:(*@\textcolor{blue}{{{result}}}@*)解释成绩:
“judge”: true, “answer”: “” Or, if the information is insufficient to answer the query: { “judge”: false } - Query: (*@\textcolor{blue}{{{Query}}@) - Accumulated Information: (*@\textcolor{blue}{{{Information}}@)
F 评估详情
F.1评估器
评估器提示语显示在图9中。
G案例研究
G.1推理错误
如表5所示,此问题需要首先定位与包容性连接休息室相关的网页,然后全面理解页面上的信息以计算所需时间。在这种情况下,还需要考虑系统执行时间计算或推理的能力。因此,即使源页面成功定位,如果系统未能正确处理时间,仍可能发生错误。
G.2时间截止
如表6所示,01的时间数据的截止日期是2023年10月,因此无法提供关于此日期之后发布的网络信息的答案。
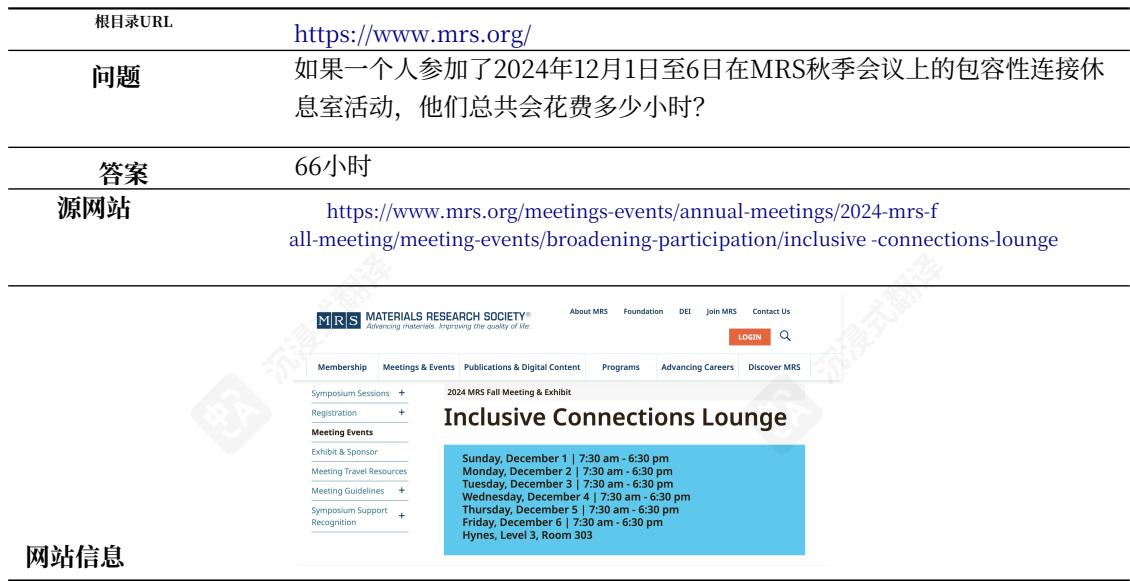
表5:网络遍历任务中需要推理能力的案例。
| 问题 | 2025年MRS秋季会议将在哪里、什么时候举行? |
| 答案 | 波士顿,马萨诸塞州;2025年11月30日至12月5日。 |
| 预测 | 截至我2023年10月的知识截止日期,MRS尚未宣布2025年MRS秋季会议的确切日期或地点。 |
表6:ol生成的预测中时间截止的情况

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)