AI面试题
它直接显式地定义了实体间的关联(如“A是B的母公司”、“C是D的组成部分”),这种关联不受文本描述方式的影响。:在真正的答案生成步骤之前,可以加一个步骤,让LLM先判断检索到的每段文档是否与问题相关,只保留相关的部分。例如:在医疗领域,微调后的模型会知道“心肌梗死”和“心梗”的相似度远高于“心肌梗死”和“心脏病”(泛称)。:为您的文档添加丰富的元数据(如:文档类型、发布日期、作者、类别、标签、来源
1、向量数据库检索召回率高可能会带来很多不相关的数据,干扰大模型的输出,如何解决?
即如何过滤噪声,保证结果相关性。
(1)重排序(Re-ranking)
- 是什么:使用一个专门的、更强大的交叉编码器(Cross-Encoder)模型对初检的Top K个结果进行精细化的相关性评分和重新排序。
- 为什么有效:
- Bi-Encoder(向量检索模型):速度快,适合海量初筛。但它是将查询和文档分别编码后计算相似度,是“间接”比较。
- Cross-Encoder(重排序模型):速度慢,但精度极高。它同时接收查询和文档作为输入,进行深度的注意力交互,直接判断两者的相关性,准确度远超向量相似度。
- 如何做:
- 用向量数据库快速召回 Top 50(高Recall)。
- 将这50个
(查询, 文档)对,送入一个Re-ranking模型(如bge-reranker-large,ms-marco-MiniLM-L-12-v2)进行评分。 - 根据Reranker的分数,选出Top 3或Top 5最相关的文档,再交给LLM。
-
效果:完美解决了“扩大召回范围”和“保证结果相关”之间的矛盾。
(2)元数据过滤(Metadata Filter)
-
是什么:为您的文档添加丰富的元数据(如:文档类型、发布日期、作者、类别、标签、来源等)。
-
如何做:在检索时,先过滤(filter)再搜索(search)。
-
示例:用户问“最新版用户手册关于电池的章节”,可以先过滤
doc_type == "用户手册" AND version == "latest",然后再在这个缩小了的集合里进行向量相似度搜索。
-
-
效果:能直接排除大量不相关文档,极大提升精度。
(3)后处理(Post-processing)与LLM的提示工程
-
动态上下文压缩:即使在检索后,也可以让LLM自己判断哪些上下文是相关的。在Prompt中指示LLM:“请根据以下上下文回答问题,如果上下文与问题无关,请忽略它。”
-
让LLM评估上下文相关性:在真正的答案生成步骤之前,可以加一个步骤,让LLM先判断检索到的每段文档是否与问题相关,只保留相关的部分。
2、怎么利用AI实现测试全流程,开发在其中可以做什么?
-
开发人员编写代码和文档 -> AI 分析代码和文档,自动生成单元测试、API测试初稿 -> 开发人员 审查和补充AI生成的测试。
-
代码提交后 -> AI 根据变更预测高风险测试用例,CI优先执行这些用例。
-
自动化UI测试运行 -> AI 利用视觉技术和自愈功能执行并维护脚本 -> 若失败,AI 分析日志和截图,将根因和建议提交给开发人员。
-
开发人员 根据AI的精准报告快速修复问题。
-
AI 自动生成本轮测试的总结报告,告知所有成员质量状态。
3、如果知识库里有数据是关联度高的,但是检索时识别不出来,如何解决?
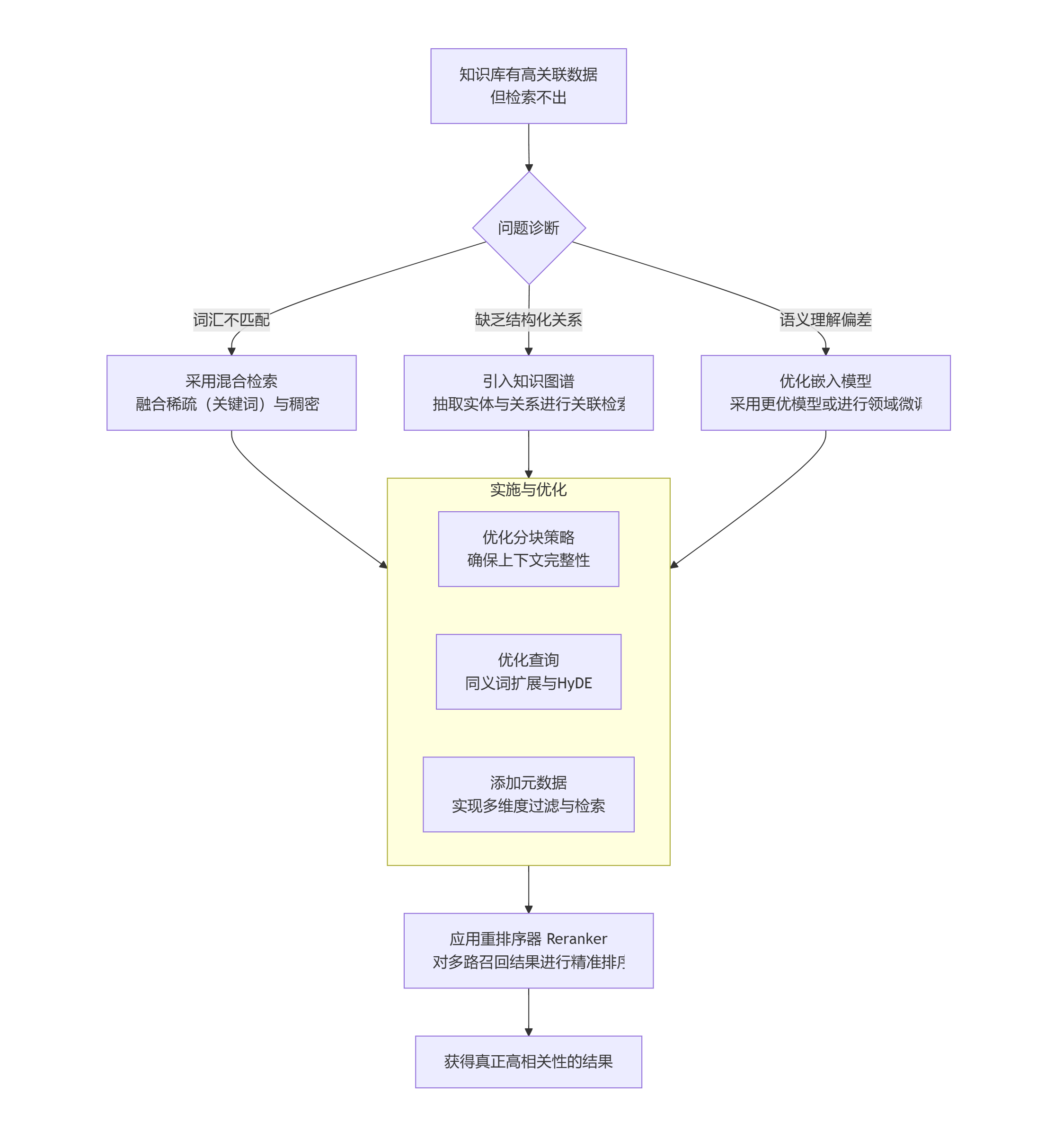
(1)混合检索(Hybrid Search) - 首选方案
这是目前解决该问题最直接、最有效的方法。它结合了两种不同的检索方式:
-
稠密向量检索(Dense Vector Search):基于语义相似度。擅长找到“意思相近但用词不同”的内容。
-
*例如:搜索“苹果的最新手机” -> 召回“iPhone 15 Pro Max 的评测”*
-
-
稀疏向量检索(Sparse Vector Search)/关键词检索(如 BM25):基于词汇匹配。擅长找到“用词高度重叠”的内容。
-
例如:搜索“苹果的最新手机” -> 召回“苹果手机发布新品”
-
为什么有效?
很多高关联内容恰恰是通过共享关键术语、产品代号、人名、特定型号等连接起来的。这些内容语义上可能看似不近,但关键词权重很高。
如何实现?
-
同时进行向量检索和关键词检索。
-
将两者的结果列表按照一定规则(如 RRF(Reciprocal Rank Fusion))进行融合重排。
-
最终得到一个既包含语义相关又包含关键词相关的综合列表。
工具:很多现代向量数据库(如 Weaviate, Qdrant, Elasticsearch)都原生支持混合检索。
(2) 引入知识图谱(Knowledge Graph)或元数据关系
如果数据中存在大量的实体(人、地点、产品、概念)和它们之间的明确关系,那么知识图谱是终极解决方案。
为什么有效?
它直接显式地定义了实体间的关联(如“A是B的母公司”、“C是D的组成部分”),这种关联不受文本描述方式的影响。
如何实现?
-
实体抽取:从您的文档中提取出实体(可以用LLM或NLP工具)。
-
关系构建:建立实体之间的关系(“苹果” --子公司--> “Beats”)。
-
关联检索:
-
当用户查询“苹果的耳机”时,系统可以先识别实体“苹果”。
-
然后通过知识图谱找到其子公司“Beats”。
-
最后再去向量库或全文检索库中查找所有关于“Beats”的文档,即使用户查询里根本没提“Beats”这个词。
-
(3)优化嵌入模型(Embedding Model)
有时,不是关联不存在,而是您使用的模型“能力不足”,无法理解某些领域的细微语义。
-
升级模型:从通用的
text-embedding-ada-002升级到更强大的模型,如text-embedding-3-large,BGE(BAAI),Voyager等。新模型通常在语义理解上更精确。 -
领域微调(Fine-tuning):如果您有领域特定的数据,可以用它们来微调一个通用的嵌入模型。这让模型学会在您的专业领域里,哪些概念在语义上更接近。
-
例如:在医疗领域,微调后的模型会知道“心肌梗死”和“心梗”的相似度远高于“心肌梗死”和“心脏病”(泛称)。
-
(4) 优化查询(Query Transformation & Expansion)
让查询本身变得更“好检索”。
-
查询扩展(Query Expansion):使用LLM或同义词库,为查询中的关键词生成同义词和相关词,然后用这组扩展后的词去检索。
-
查询:“如何解决App崩溃” -> 扩展为:“如何解决 应用程序 应用 Crash 闪退 崩溃 无响应”
-
-
HyDE(Hypothetical Document Embeddings):让LLM根据查询生成一个假设的理想答案(即使这个答案可能不准确),然后用这个生成的答案文档去向量数据库里检索真实的相似文档。这个方法能极大地提升对深层语义需求的召回能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)