第2节:大模型基础与选择策略
《大语言模型应用选型指南》摘要(136字) 本课程系统讲解大语言模型选型方法论,涵盖核心知识点:1)解析Transformer架构与规模效应;2)对比分析主流闭源/开源模型特性;3)提供本地部署与云端API的决策框架,重点考量数据安全、技术门槛与成本结构;4)建立多维评估体系(性能/技术/商业指标);5)给出量化/蒸馏等优化策略。强调模型选择需平衡性能、成本与业务需求,为构建RAG系统提供科学的选
·
📚 课程目标
通过本课程的学习,学员将能够:
- 了解主流大语言模型的特点和架构
- 掌握本地部署与云端API的成本分析方法
- 学会根据应用场景选择合适的大模型
- 理解大模型在RAG系统中的角色和作用
🎯 课程大纲
- 大语言模型概述
- 主流大模型对比分析
- 模型架构与工作原理
- 本地部署 vs 云端API
- 模型选择标准与评估方法
- 成本分析与优化策略
📖 课程内容
1. 大语言模型概述
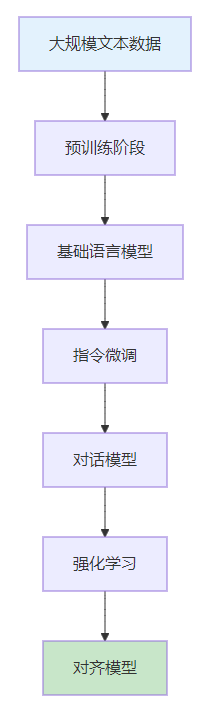
大语言模型(Large Language Models, LLMs)是基于Transformer架构的深度学习模型,通过在大规模文本数据上进行预训练,具备了强大的语言理解和生成能力。
1.1 大模型的核心特征
- 参数量巨大:通常包含数十亿到数千亿参数
- 预训练数据丰富:在互联网规模的文本数据上训练
- 涌现能力:随着规模增大出现的新能力
- 泛化能力强:能够处理未见过的任务
1.2 大模型的关键技术
- Transformer架构:自注意力机制
- 预训练策略:掩码语言模型、因果语言模型
- 微调技术:指令微调、RLHF
- 推理优化:量化、剪枝、蒸馏
2. 主流大模型对比分析
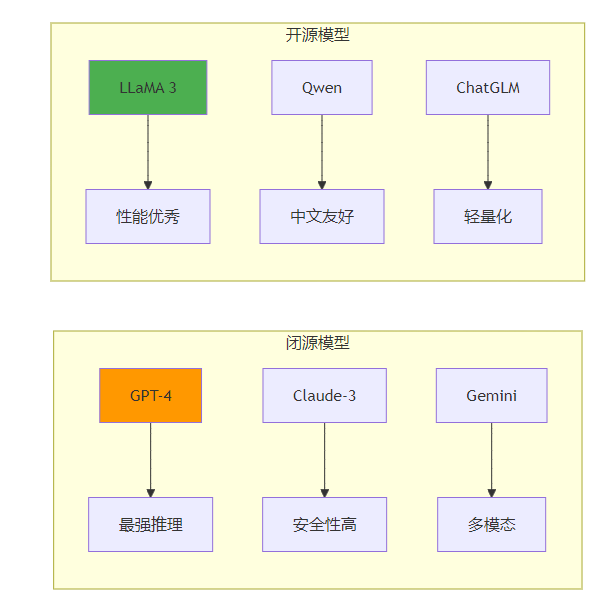
2.1 闭源模型
GPT系列(OpenAI)
- GPT-3.5 Turbo:平衡性能与成本
- GPT-4:最强推理能力
- GPT-4 Turbo:更长上下文,更低成本
Claude系列(Anthropic)
- Claude-3 Haiku:快速响应
- Claude-3 Sonnet:平衡性能
- Claude-3 Opus:最强能力
Gemini系列(Google)
- Gemini Pro:多模态能力
- Gemini Ultra:顶级性能
2.2 开源模型
Meta系列
- LLaMA 2:7B/13B/70B参数版本
- Code Llama:代码专用模型
- Llama 3:最新版本,性能提升
其他开源模型
- Qwen系列:阿里巴巴开源
- ChatGLM:清华大学开源
- Baichuan:百川智能开源
- InternLM:上海AI实验室开源
3. 模型架构与工作原理
3.1 Transformer架构核心组件
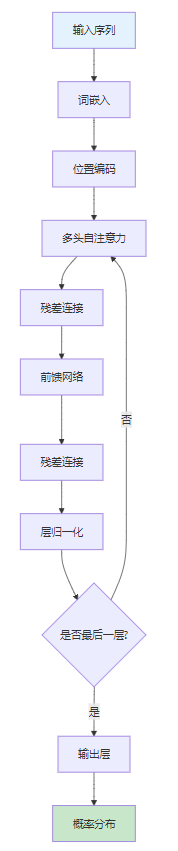
3.2 注意力机制详解
注意力机制是大模型的核心,它允许模型在处理每个位置时关注序列中的所有其他位置:
自注意力公式:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
其中:
- Q:查询矩阵
- K:键矩阵
- V:值矩阵
- d_k:键的维度
3.3 模型规模与性能关系

规模效应:
- 7B模型:基础对话能力
- 13B模型:复杂推理能力
- 70B模型:接近人类水平
- 100B+模型:涌现新能力
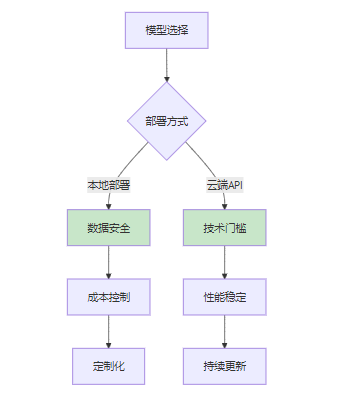
4. 本地部署 vs 云端API
4.1 本地部署优势
数据安全
- 数据不出本地环境
- 符合数据合规要求
- 避免数据泄露风险
成本控制
- 一次投入,长期使用
- 无API调用费用
- 可控制使用量
定制化
- 可进行模型微调
- 支持私有化部署
- 完全自主控制
4.2 云端API优势
技术门槛低
- 无需模型部署
- 无需硬件配置
- 开箱即用
性能稳定
- 专业团队维护
- 高可用保障
- 自动扩缩容
持续更新
- 模型自动升级
- 新功能及时获得
- 无需维护成本
4.3 成本对比分析
本地部署成本:
- 硬件成本:GPU服务器(10-50万)
- 电费成本:每月1000-5000元
- 维护成本:技术人员成本
- 总成本:初期投入大,长期成本低
云端API成本:
- 调用费用:按token计费
- 月费用:1000-10000元
- 无硬件成本:零初始投入
- 总成本:初期投入低,长期成本高
5. 模型选择标准与评估方法
5.1 选择标准
性能指标
- 理解能力:对问题的理解准确性
- 生成质量:回答的准确性和流畅性
- 推理能力:逻辑推理和问题解决能力
- 多语言能力:对中文等语言的支持
技术指标
- 响应速度:生成答案的时间
- 并发能力:同时处理请求的能力
- 上下文长度:支持的最大对话长度
- 内存占用:运行时资源消耗
商业指标
- 成本效益:性能与成本的比值
- 可用性:服务的稳定性和可靠性
- 扩展性:支持业务增长的能力
- 合规性:满足法律法规要求

5.2 评估方法
基准测试
- MMLU:大规模多任务语言理解
- HellaSwag:常识推理测试
- HumanEval:代码生成测试
- C-Eval:中文理解测试
实际应用测试
- 问答准确性:专业领域问题回答
- 对话流畅性:多轮对话体验
- 任务完成率:特定任务的成功率
- 用户满意度:真实用户反馈
6. 成本分析与优化策略
6.1 成本构成分析
硬件成本
- GPU服务器:A100、V100、RTX4090
- 内存需求:根据模型大小确定
- 存储需求:模型文件和数据存储
运营成本
- 电费:GPU功耗 × 运行时间 × 电价
- 网络费用:数据传输费用
- 维护费用:技术人员成本
API成本
- 调用费用:按token计费
- 并发费用:高并发时的额外费用
- 存储费用:模型和数据存储费用
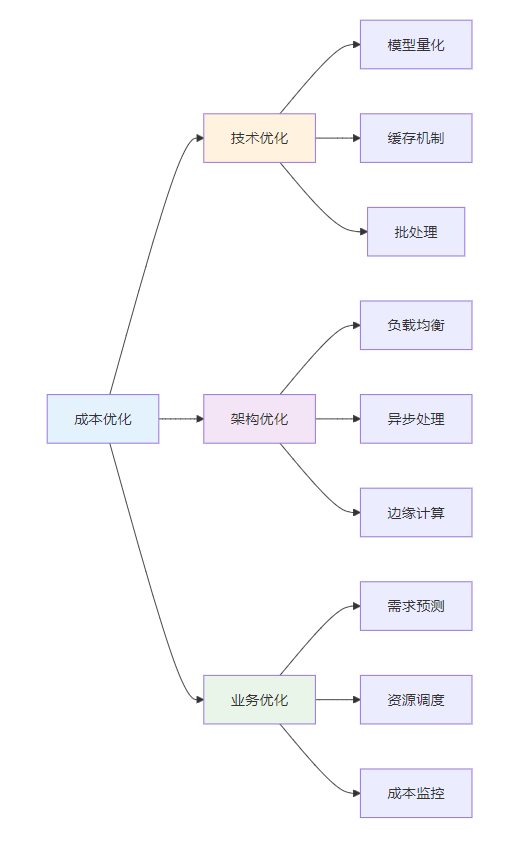
6.2 优化策略
技术优化
- 模型量化:降低模型精度,减少内存占用
- 模型蒸馏:用小模型学习大模型能力
- 缓存机制:缓存常见问题的答案
- 批处理:批量处理请求,提高效率
架构优化
- 负载均衡:分散请求压力
- 异步处理:提高并发处理能力
- 冷热分离:区分热门和冷门内容
- 边缘计算:在用户附近部署模型
📝 课程总结
大模型的选择是构建RAG系统的关键决策,需要综合考虑性能、成本、安全等多个因素。理解不同模型的特点和适用场景,能够帮助我们做出最优的技术选择。
关键要点回顾:
- 闭源模型性能优秀但成本较高,开源模型性价比高但需要技术投入
- 本地部署保证数据安全,云端API降低技术门槛
- 模型选择需要根据具体应用场景和业务需求
- 成本优化需要从技术、架构、业务多个维度考虑

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)