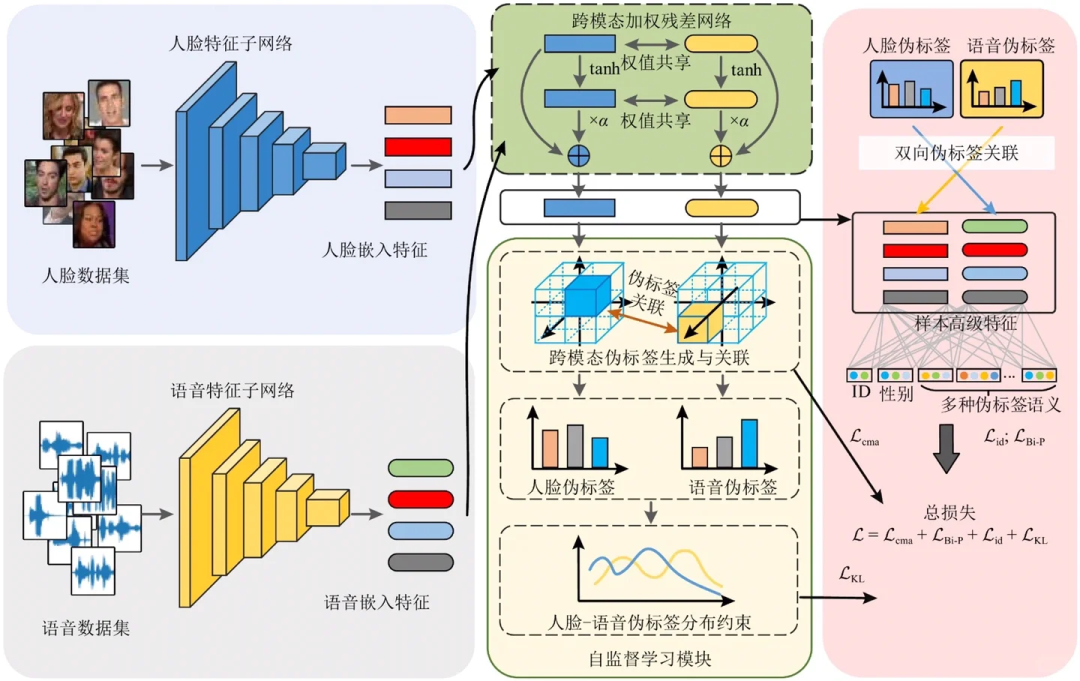
多模态大语言模型(MLLM)是什么?MLLM的基本架构是什么?
摘要:多模态大语言模型(MLLM)能处理文本、图像、音频等多模态信息,通过模态编码器、跨模态对齐模块、语言模型主干和专用生成器实现跨模态理解和生成。典型架构包括ViT等视觉编码器,以及特征投影、查询式融合等对齐方式。训练分预训练、对齐和后训练三阶段,推理时需模态解析、特征融合和文本生成。应用场景涵盖智能驾驶、内容审核等,但仍面临模态鸿沟、计算成本高等挑战。随着AI大模型快速发展,相关人才需求激增,
1、什么是多模态大语言模型(MLLM)
多模态大语言模型(Multi-modal Large LanguageModel.MLLM)是一类能够同时理解和生成文本、图像、音频、视频等多种模态信息的人工智能模型。
相比只能处理文本的传统大语言模型(LLM),MLLM通过引入模态编码器和跨模态对齐机制,打通了不同信息模态之间的语义壁垒,使模型能够:
“看懂”图像、音频或视频
“用语言”描述非文本内容
“结合”多模态信息进行复杂推理与生成
某些 MLLM 还支持反向生成,即根据文字描述生成图像、语音或视频,实现从理解到创造的闭环能力。
2、MLLM的基本架构
典型的 MLLM 包含四个关键模块:
1)模态编码器
用于处理图像、音频或视频等非文本输入,将其转化为高维语义特征。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
以图像为例,常见视觉编码器包括:
ViT(Vision Transformer)
ConvNeXt
CLIP/SigLIP
EVA-CLIP
这些编码器从图片中提取包含空间结构和高级语义的视觉token,为后续的跨模态融合提供基础表示。
2)跨模态对齐模块
该模块负责将视觉编码器提取的视觉特征映射到语言模型可处理的语义空间,是连接感知与理解的核心桥梁。
常见对齐方式包括:
特征投影
通过线性层或多层感知机(MLP),将视觉特征直接映射到语言模型的嵌入空间,并与文本 token 拼接输入语言模型。
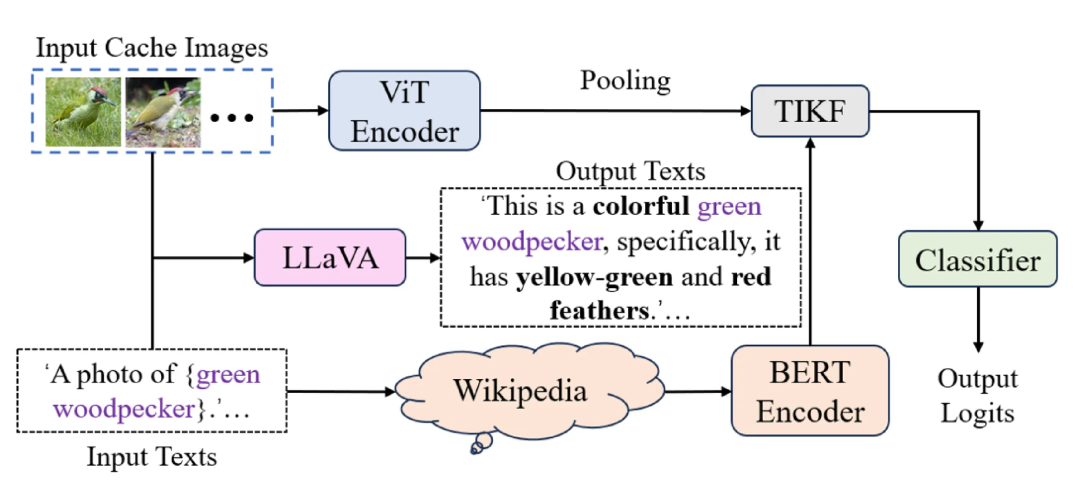
结构简洁,训练高效
代表模型:LLaVA
查询式融合
引入可学习查询向量(Learnable Queries),通过交叉注意力机制,从视觉特征中提取语义相关的关键信息,生成固定数量的视觉上下文 token,并与文本 token 拼接后输入语言模型。
能捕捉更精细语义信息
代表模型: BLIP-2(Q-Former)
感知重采样注入
利用感知重采样模块(如 Flamingo 中的 Perceiver Resampler),将高维视觉 token 压缩为少量语义密集的latent token,通过交叉注意力机制动态注入语言模型的各层。
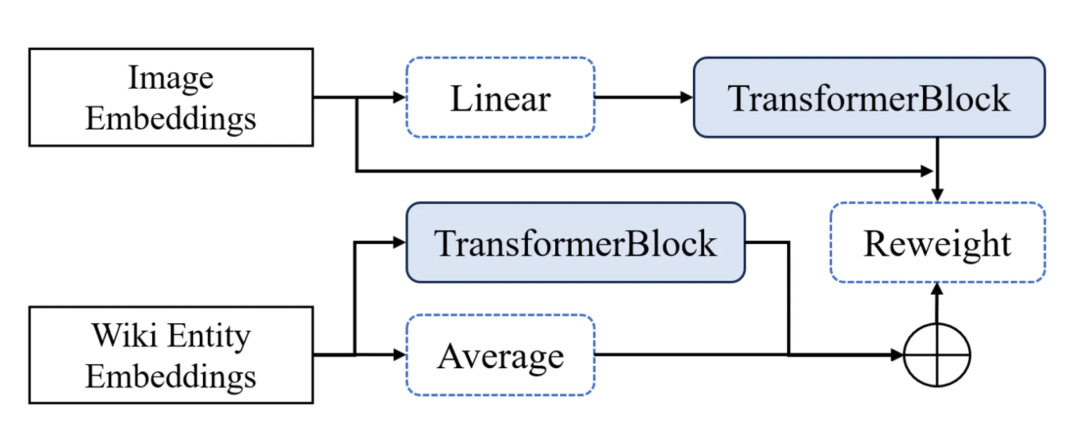
更灵活的层级融合方式
代表模型: Flamingo
3)语言模型主干
语言模型是 MLLM 的核心推理与生成引擎,主要功能包括:
语义整合与理解: 融合来自对齐模块的多模态上下文,建模图文一致性、指代关系等复杂语义结构。
推理与知识调用: 利用预训练中习得的语言逻辑与世界知识,对融合后的信息进行因果推理、场景理解、属性判断等。
自然语言生成: 基于融合后的多模态表示,以自回归方式逐 token 输出自然语言,实现看图说话、视觉问答、多模态对话等任务。
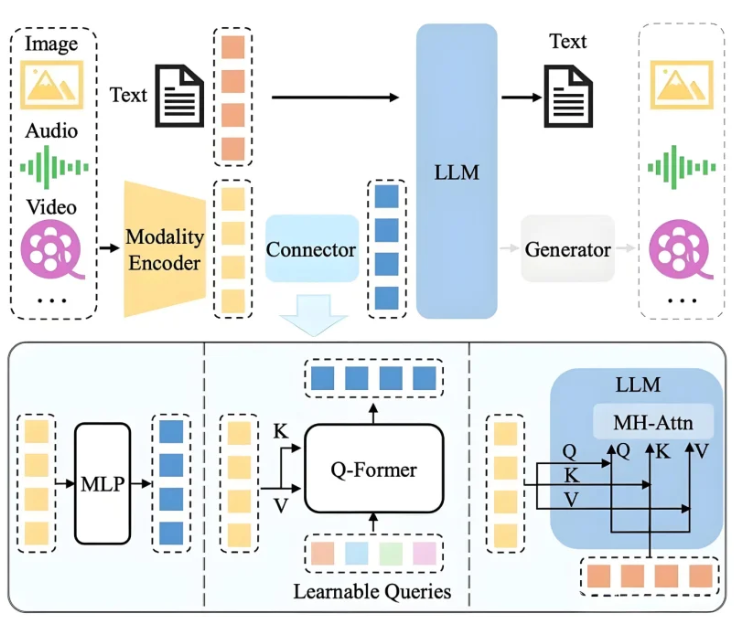
4)专用生成器
若模型需要生成图像、音频或视频等非文本内容,通常会引入专用的生成器。它们接收来自语言模型生成的提示或控制信号,合成对应模态的内容。
常见生成器如:
扩散模型(Diffusion Models)
生成对抗网络(GAN)
声码器(Vocoder)
此外,部分研究也在探索端到端的生成路径,通过将目标模态离散化为 token,由语言模型直接自回归生成,无需依赖外部生成器(如 Emu2)。
3、训练和推理
1)训练流程
MLLM 通常采用分阶段训练策略:
预训练阶段
语言模型: 在大规模文本数据上自回归预训练,掌握语言能力。
视觉编码器: 在大规模图文对(如 LAION)上预训练,学习视觉语义表征。

跨模态对齐阶段
冻结语言模型和视觉编码器,仅训练对齐模块(如线性投影、MLP 或 Q-Former等)。
目标是把视觉特征映射到语言模型可理解的嵌入空间。
后训练阶段
使用人工构造或合成的多模态指令数据,进行监督微调(SFT)。
部分模型还进一步采用 RLHF 或 DPO 优化响应质量与安全性。
2)推理流程
模态解析
图像、视频等输入先经过视觉编码器提取高维视觉特征。
特征对齐
将视觉特征映射到语言模型的嵌入空间,使其与文本特征兼容。
上下文融合
将视觉特征与文本特征共同输入语言模型,实现跨模态语义整合。
主流方式包括:
序列拼接: 将处理后的视觉与文本 token 序列拼接后送入语言模型。
交叉注意力注入: 通过交叉注意力机制,让语言模型在生成过程中动态获取视觉信息,逐层整合多模态语义。
文本生成:基于融合后的多模态表示,语言模型以自回归方式逐token 生成自然语言输出。
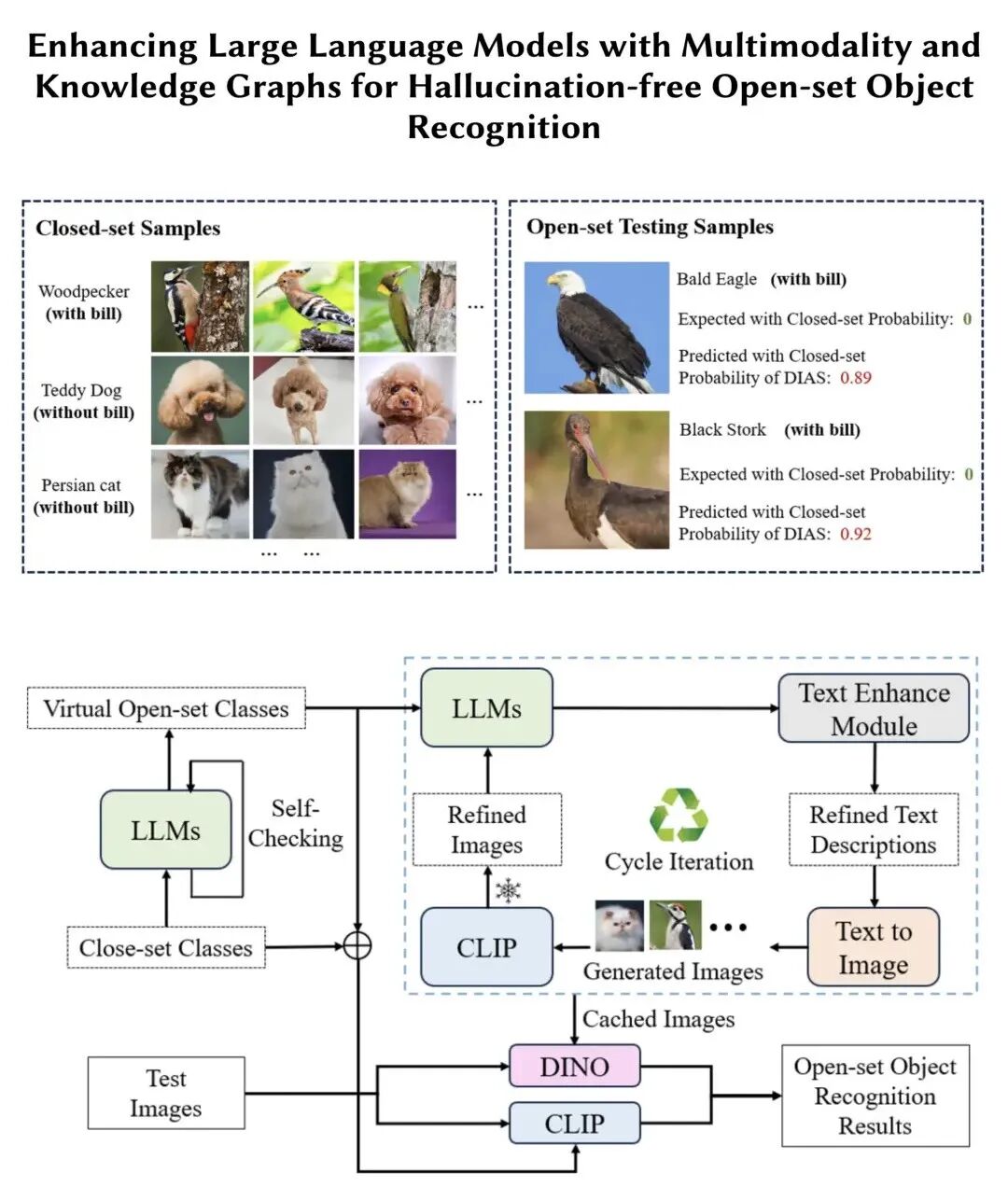
4、代表性模型案例
GPT-4o: OpenAl推出的全模态模型,统一处理文本图像和语音的输入与输出,支持多语言与高效的跨模态理解与生成(闭源)。
LLaVA: 基于 CLIP 和 LLaMA 的开源模型,视觉特征经线性投影接入语言模型,结构轻量,易复现与拓展。
Flamingo: DeepMind 开发的模型,能将图像信息灵活融合进语言模型,适合以少量样本完成跨模态任务。
BLIP-2: 通过 Q-Former 提取并对齐图像信息,结合表示学习与生成预训练,强化图文生成与问答能力。
Qwen-VL: 通义千问开源多模态模型,采用 ViT 实现视觉编码,实现图文细粒度对齐与文档级跨模态理解。
5、应用场景
多模态大语言模型(MLLM)是 LLM 的自然延伸,也是当前 AI 领域的研究热点。
相比只能处理文本的语言模型,MLLM 融合图像、语音、视频等多种模态,让模型具备“看、听、说、想”的综合能力,显著拓展了 AI在现实场景中的应用边界。
典型应用案例
智能驾驶: 融合摄像头图像、激光雷达和车载文本信息实现环境感知与路径规划。
内容审核与治理: 联合分析图片与视频画面、语音内容与字幕文本,识别违规行为与伪造信息。
远程运维: 结合监控视频、传感器音频与故障记录,支持自动诊断与远程协作。
多模态人机交互: 支持图文对话、看图问答、语音指令等,广泛应用于教育、办公等场景。
随着模型能力持续演进,MLLM 的应用潜力远不止于当前已知的这些领域。
6、存在的问题
模态鸿沟: 视觉等具象模态与语言的抽象语义在表征方式上存在差异,难以完全对齐,容易导致理解偏差。
推理成本高: 需同时处理高维视觉特征与语言信息,计算开销大,导致推理延迟增加、部署难度提升。
长视频处理能力有限: 当前模型对长视频理解力有限,难以捕捉完整的时序逻辑与因果关系。
生成能力受限: 多模态内容生成仍依赖外部生成器,细节控制能力不足。端到端生成路径尚未成熟,仍处于探索阶段。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)