【AI】模型微调涉猎
大部分时间成本在数据集的准备上;
·
微调
成败在于数据集,大部分时间成本在数据集的准备上;
- 数据集的准备是一件大工程,涉及数据源、数据清洗等。
- 有的数据集来自大模型生成,再通过工程或者人工review
开源数据集
可以在https://huggingface.co/datasets 上寻找你感兴趣的开源数据集
我们就【非暴力沟通-区分观察与评论】这份数据集展开
thomasgauthier/observation_or_evaluation · Datasets at HF Mirror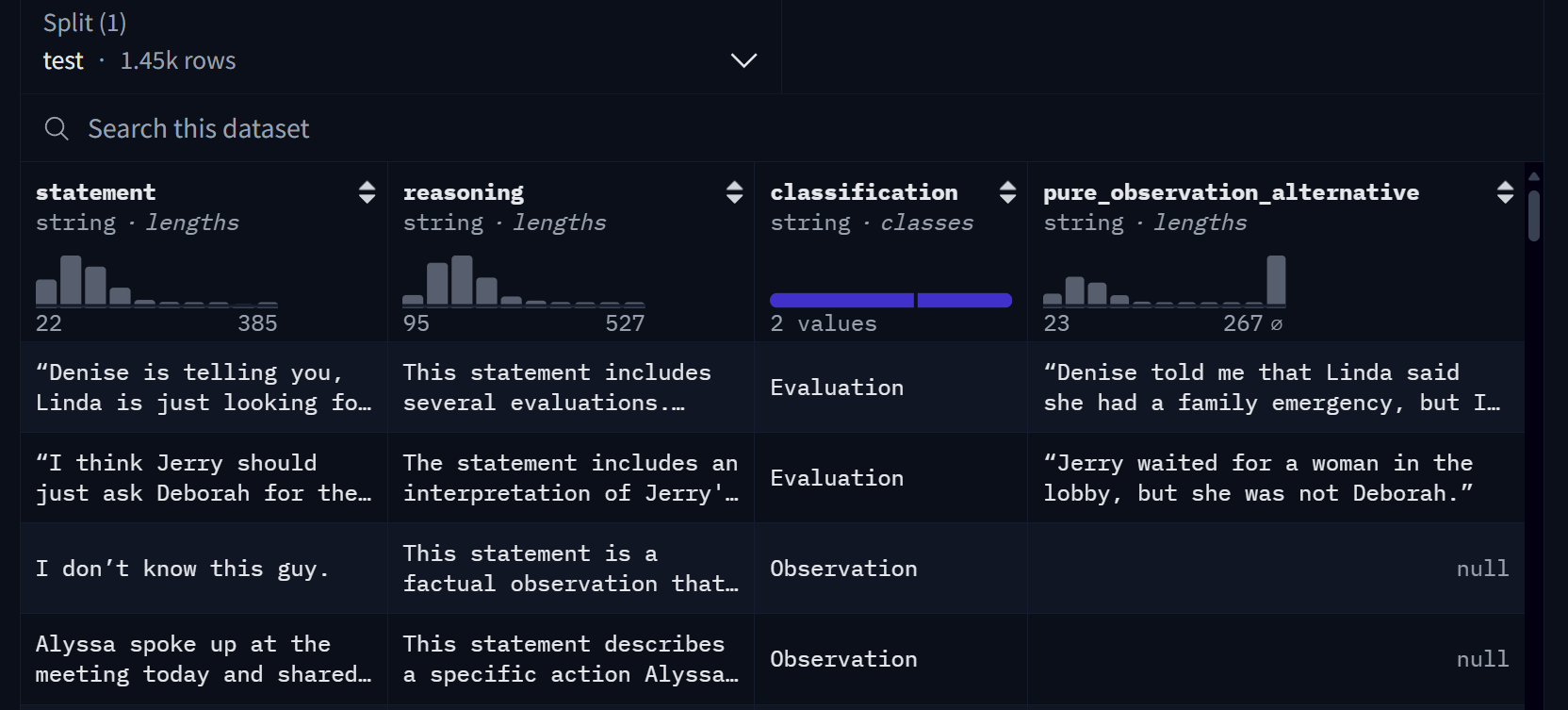
- 这是一份纯英文数据集,我希望把它翻译一下,找到了一个开源项目,不过只支持alpaca格式的数据集翻译:【wangerzi/datasets-translator: 本项目是一个用于翻译数据集的工具,支持通过命令行脚本调用进行数据集多语言翻译。】
- 就该项目简单二次开发来支持翻译这份数据集,现支持alpaca、shareGPT以及自定义格式的数据集翻译:【hbchen7/datasets-translator: A tool for translating datasets, supporting multilingual translation of datasets through command-line script calls. Supports alpaca, sharegpt and custom format datasets. 翻译数据集的工具,支持通过命令行脚本调用对数据集进行多语言翻译。支持alpaca,sharept和自定义格式的数据集】
- 接入了硅基流动的免费小模型,翻译效果还可以:

格式化数据集
这里用到了花园老师的工具↓
花园老师从零打造的微调数据集开源项目 Easy DataSet:https://github.com/ConardLi/easy-dataset
-
导入数据集
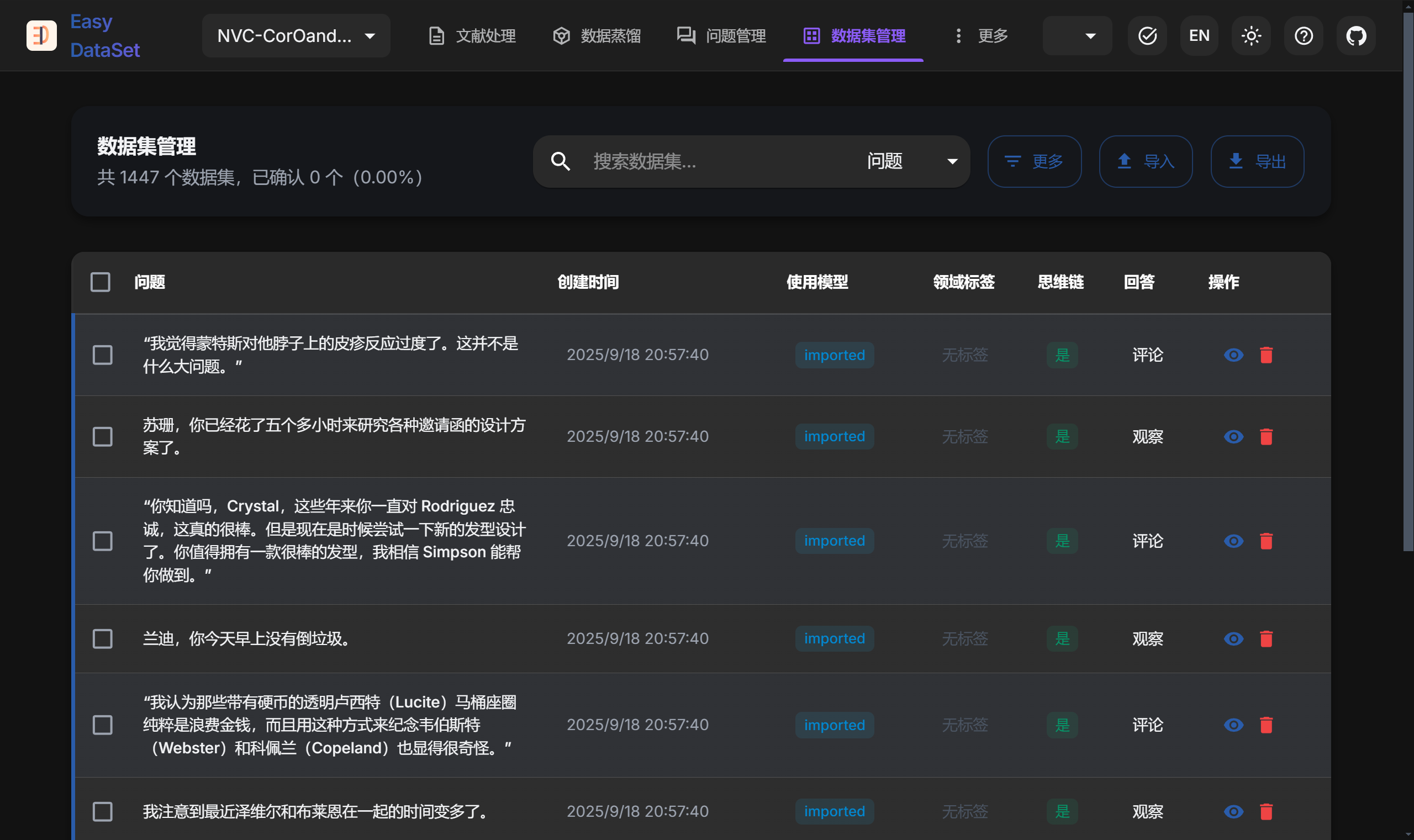
-
支持导出多种格式数据集
这里我们导出 ShareGPT - JSONL 格式,这是硅基流动微调平台的标准格式.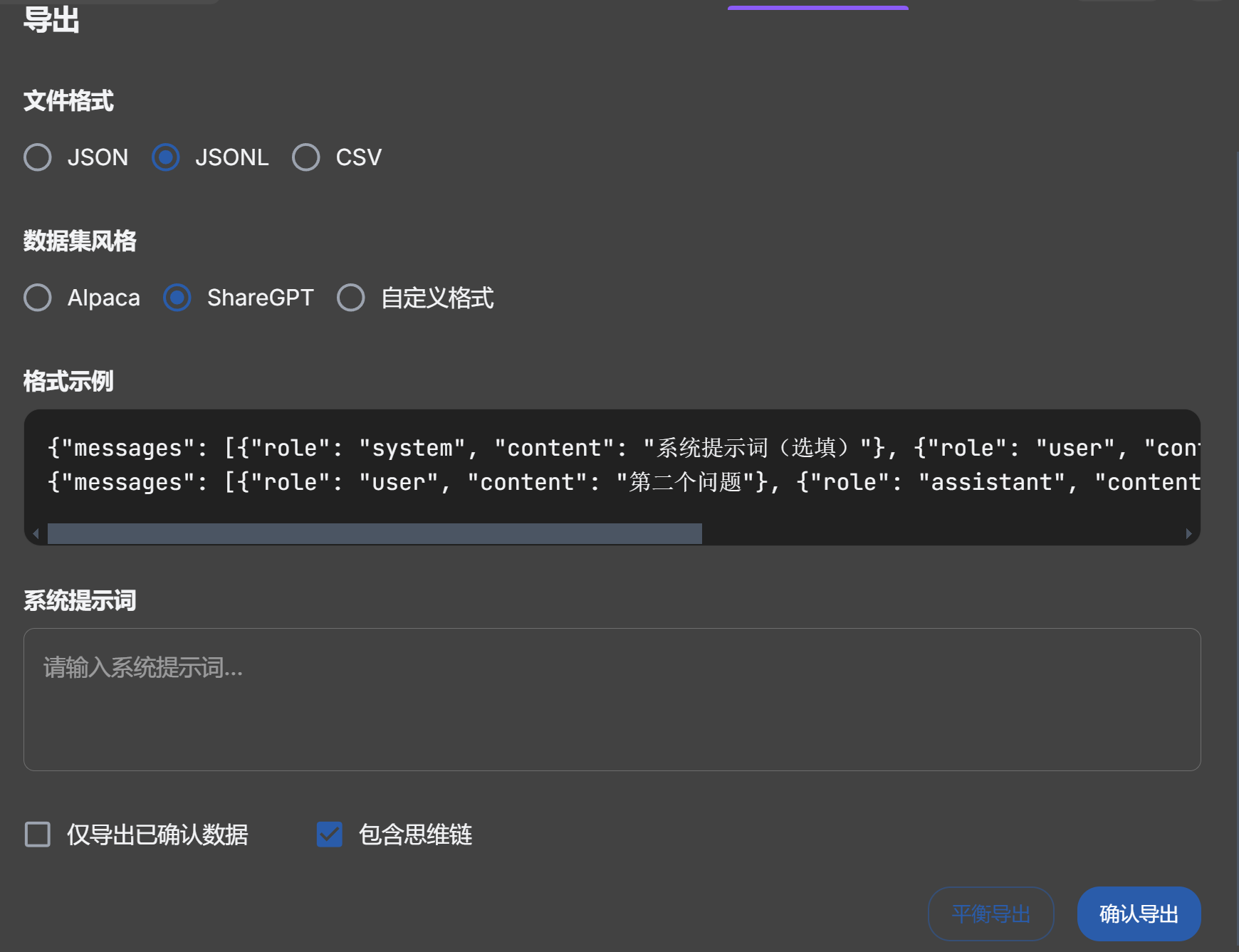
开调
在线平台微调
- 选择模型
- 导入我们翻译、转换好格式的数据集↓
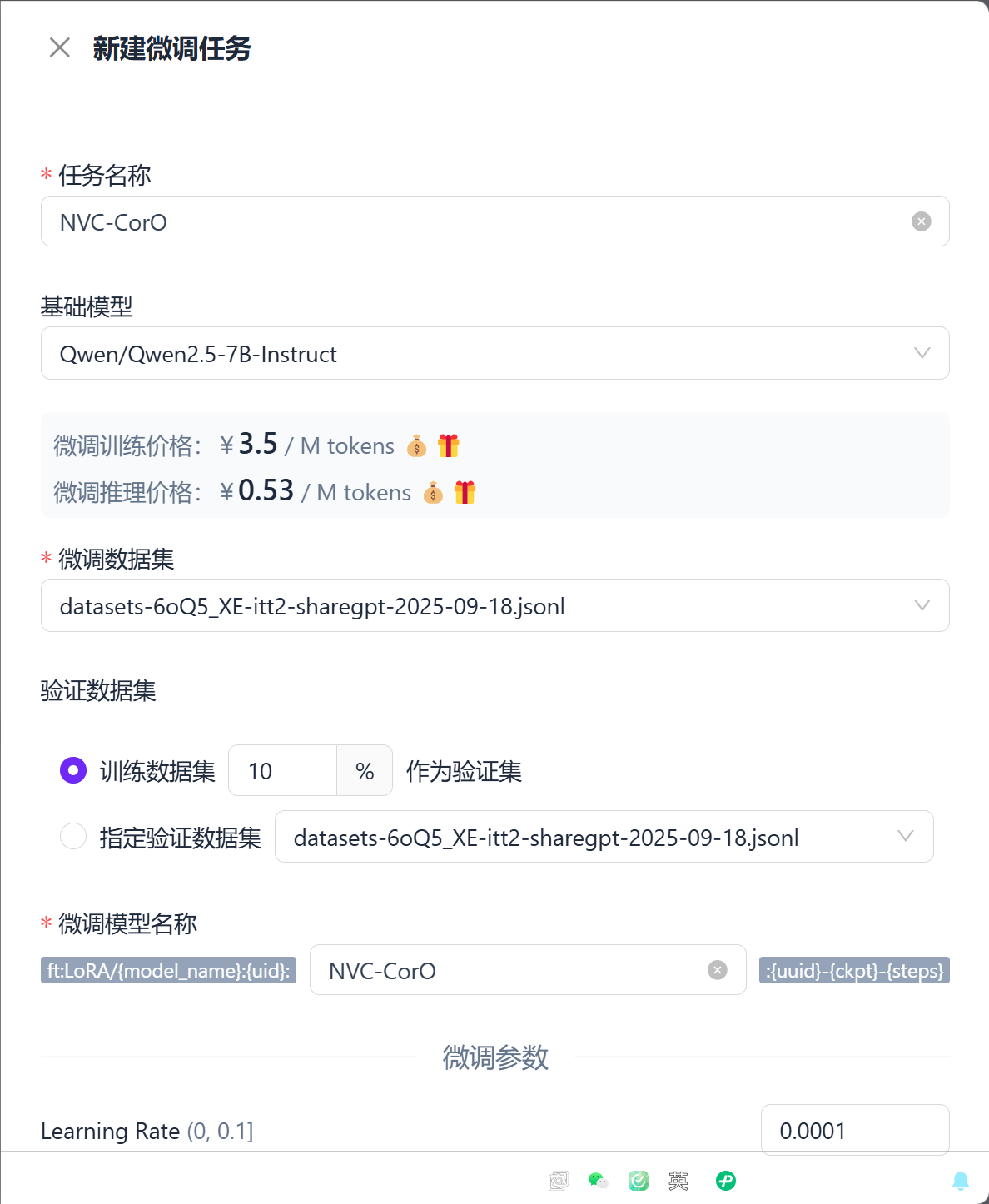
默认的参数已经能满足大部分情况下的微调需求,我们点击【开始微调】
等待它完成~
3分钟后完成了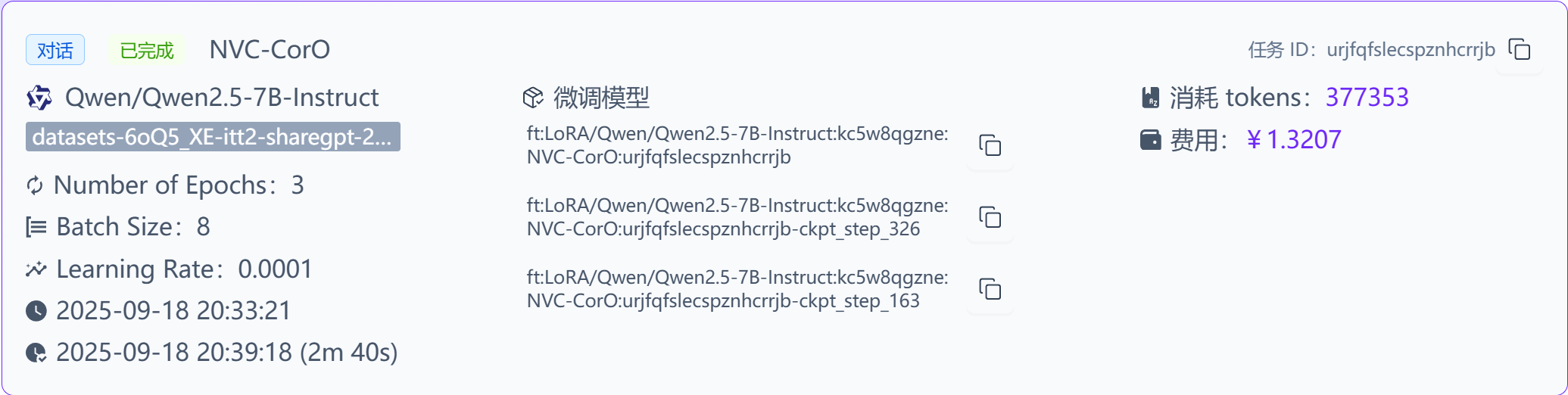
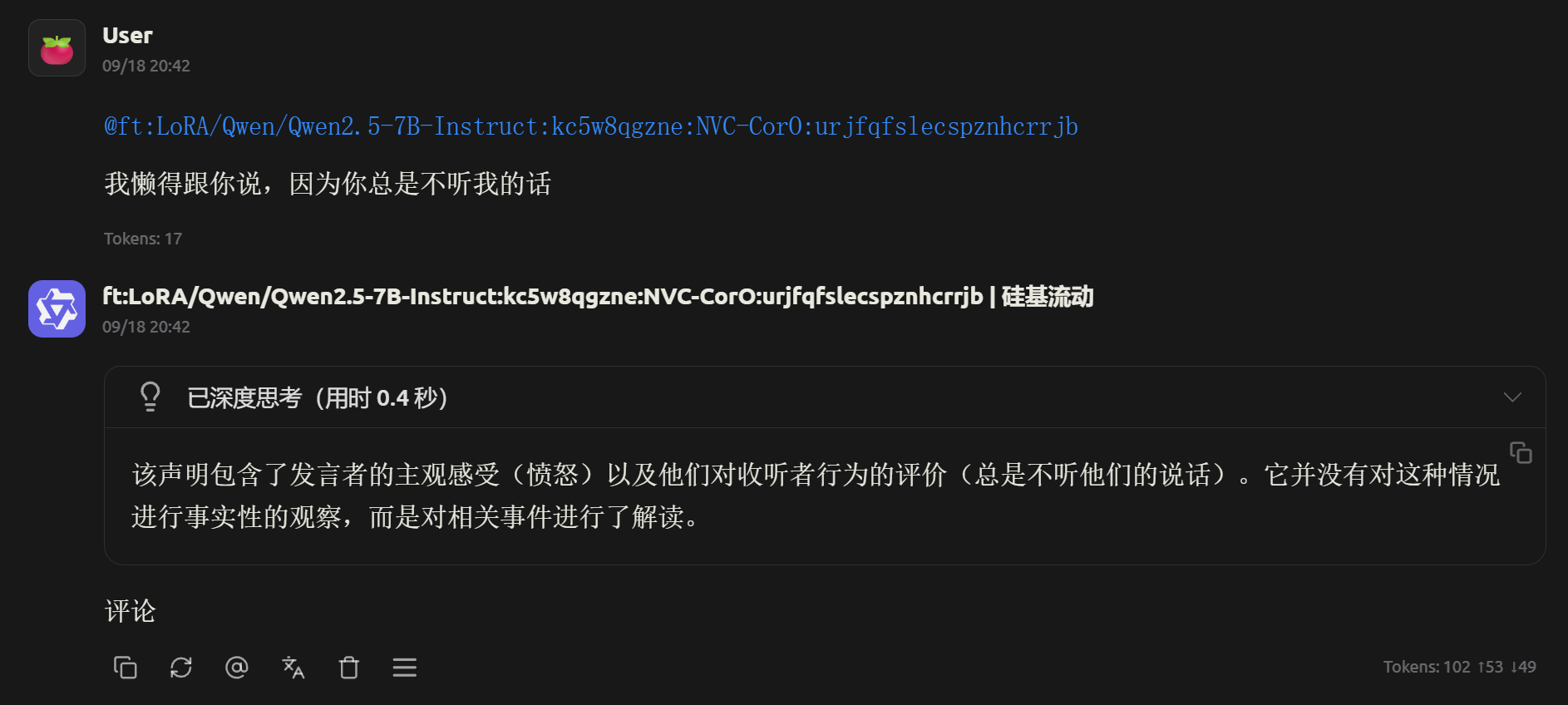
效果展示
- 复制模型名,填入url和apikey;这里我用Cherry Studio↓
- 可见有思维链的过程,回复也是标准的【评论\观察】

本地微调
平台微调简单方便,不过模型的选择有限、数据集的大小也有限制.
就可以在本地上使用 LLaMA Factory 来进行更专业的微调训练
推荐教学:【全36集】B站最细微调教程:教你从零打造专属领域大模型!_哔哩哔哩_bilibili
待续…

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)