大模型思维链揭秘:原来 LLM 靠这两招学会推理,长思考真能变聪明!
表层结构知识:通过上下文学习快速习得的推理步骤格式,表现为对特定连接词和句式的模仿深层逻辑知识:从预训练数据中习得的领域规则和推理模式,决定了推理的正确性散点图直观展示了推理动词数量与准确率的强相关性:在三个不同规模的模型(LLaMA3-8B、Gemma2-9B、Gemma2-27B)上,推理动词数量与准确率均呈现正相关,证实深层逻辑知识对推理性能的关键作用。
摘要:思维链推理已成为增强模型推理能力的关键方法。尽管人们对思维链推理的兴趣日益浓厚,但其潜在机制仍不明确。本文从上下文学习与预训练先验的双重关系角度,探究思维链推理的工作机制。首先,我们对推理过程进行细粒度的词汇级分析,以考察模型的推理行为。然后,通过逐步引入含噪示例,研究模型如何平衡预训练先验与错误的上下文信息。最后,我们探究提示工程是否能诱导大型语言模型进行慢速思考。大量实验揭示了三个关键发现:(1)模型不仅能快速学习词汇层面的推理结构,还能掌握更深层次的逻辑推理模式,但严重依赖预训练先验;(2)提供充足的示例会使模型的决策重心从预训练先验转向上下文信号,而误导性提示会引入不稳定性;(3)长思维链提示能诱导模型生成更长的推理链,进而提升其在下游任务中的性能。
论文标题: "Rethinking the Chain-of-Thought: The Roles of In-Context Learning and Pretrained Priors"
作者: "Hao Yang, Zhiyu Yang, Yunjie Zhang"
会议/期刊: "arXiv preprint arXiv:2509.01236"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.01236"
关键词: ["思维链推理", "上下文学习", "预训练先验", "提示工程", "大语言模型"]
核心要点:该文章研究揭示,思维链(CoT)推理的核心优势源于预训练先验与上下文学习的协同作用,而非单一机制,这一发现为优化大语言模型推理性能提供了全新视角。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
思维链推理的黑匣子:为什么我们需要重新思考CoT的工作机制?
自思维链(Chain-of-Thought, CoT)推理方法问世以来,它已成为提升大语言模型(LLM)复杂任务能力的关键技术。通过引导模型生成中间推理步骤,CoT显著提高了数学问题解决、逻辑推理和代码生成等任务的性能。然而,这一机制背后的真正原理长期以来笼罩在迷雾中:模型究竟是依赖于预训练时习得的知识(预训练先验),还是通过上下文学习(In-Context Learning)从示例中获取推理模式?
现有方法的痛点主要集中在三个方面:
- 机制模糊:CoT性能提升的根本原因不明确,难以针对性优化
- 鲁棒性不足:面对噪声示例时,模型容易被误导,推理稳定性差
- 效率低下:长推理链导致计算成本增加,且不一定带来性能提升
这项研究通过精细的词汇级分析、噪声示例干扰实验和提示工程诱导,首次系统揭示了CoT推理中预训练先验与上下文学习的动态平衡机制,为构建更高效、更鲁棒的推理系统奠定了理论基础。
双引擎驱动:CoT推理的协同框架与工作原理
预训练先验与上下文学习的协同框架
研究提出的协同框架颠覆了以往对CoT的单因素认知,将其重新定义为预训练先验与上下文学习的有机结合:
框架图清晰展示了两种机制的协同作用:
- 预训练先验(Pretrained Priors):模型在大规模语料上习得的推理模式和世界知识,表现为对特定词汇和逻辑结构的偏好
- 上下文学习(In-Context Learning):模型从任务示例中快速捕捉推理结构的能力,使模型能够适应新任务格式
这两种机制并非相互排斥,而是形成了"双引擎"驱动模式——预训练先验提供推理的"语法规则",上下文学习则负责填充具体的"语义内容"。
推理行为的词汇级分析:模型究竟学到了什么?
通过对模型生成的推理链进行精细的词汇级分析,研究团队有了惊人发现:
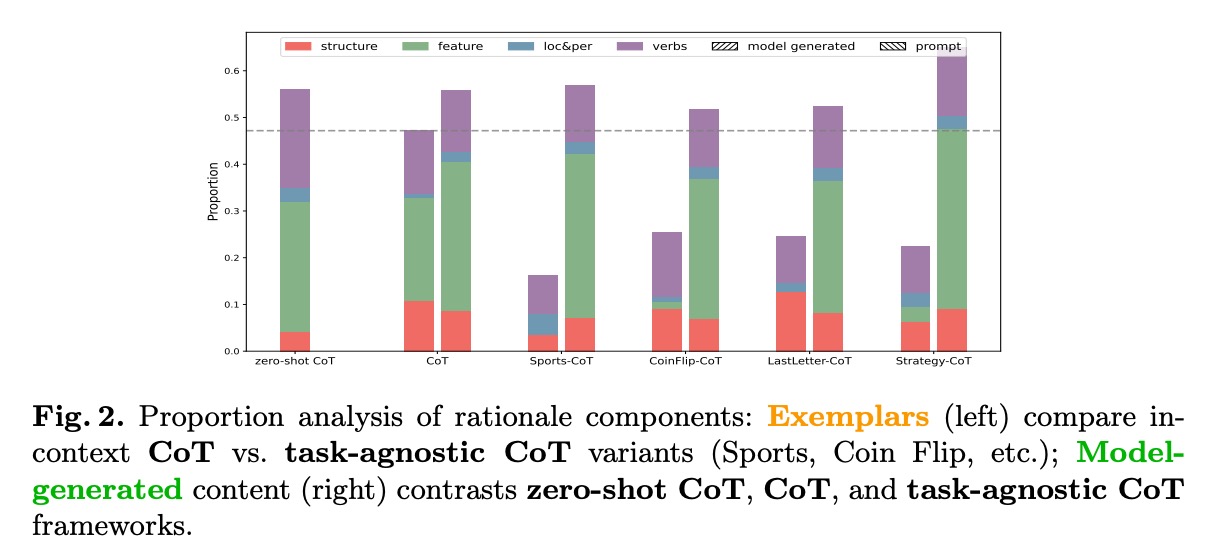
柱状图显示了不同CoT变体下推理成分的比例分布,揭示三个关键发现:
- 结构学习:模型能快速掌握推理的表层结构(如"首先"、"因此"等连接词的使用)
- 深层逻辑:更重要的是,模型能捕捉到深层逻辑推理模式,体现在推理动词(reasoning verbs)的使用频率与准确率的强相关性
- 知识依赖:即使在任务无关的CoT变体(如Sports-CoT、CoinFlip-CoT)中,模型仍能保持一定性能,证明预训练先验的主导作用
这一发现解释了为什么简单的CoT提示就能显著提升性能——模型并非真正"理解"推理过程,而是结合了预训练的推理模板和上下文示例的结构线索。
三大核心发现:重新定义CoT推理的认知边界
发现一:推理能力的双重来源
模型在CoT推理中同时利用两种知识来源:
- 表层结构知识:通过上下文学习快速习得的推理步骤格式,表现为对特定连接词和句式的模仿
- 深层逻辑知识:从预训练数据中习得的领域规则和推理模式,决定了推理的正确性
散点图直观展示了推理动词数量与准确率的强相关性:
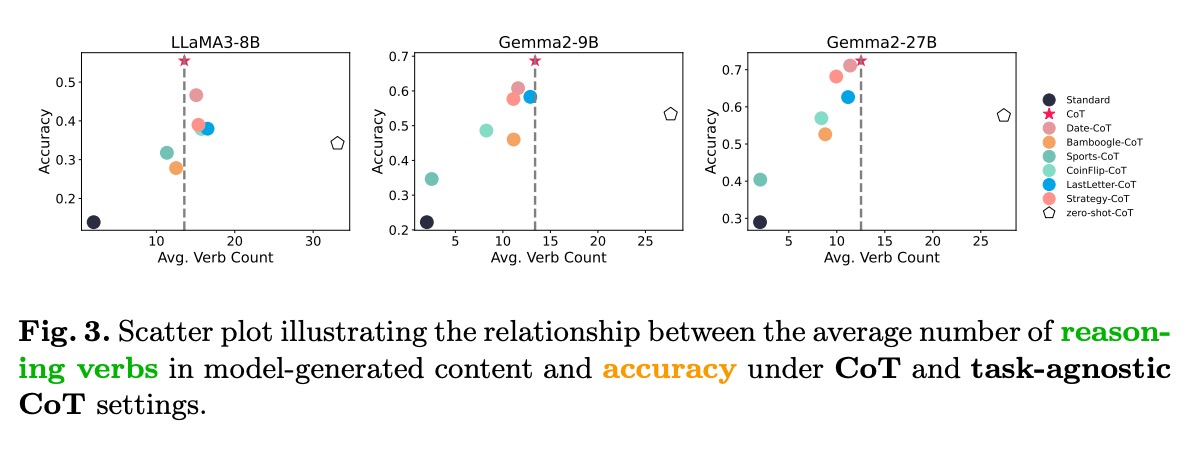
在三个不同规模的模型(LLaMA3-8B、Gemma2-9B、Gemma2-27B)上,推理动词数量与准确率均呈现正相关,证实深层逻辑知识对推理性能的关键作用。
发现二:噪声示例下的机制平衡
当引入错误示例时,模型表现出有趣的适应策略:
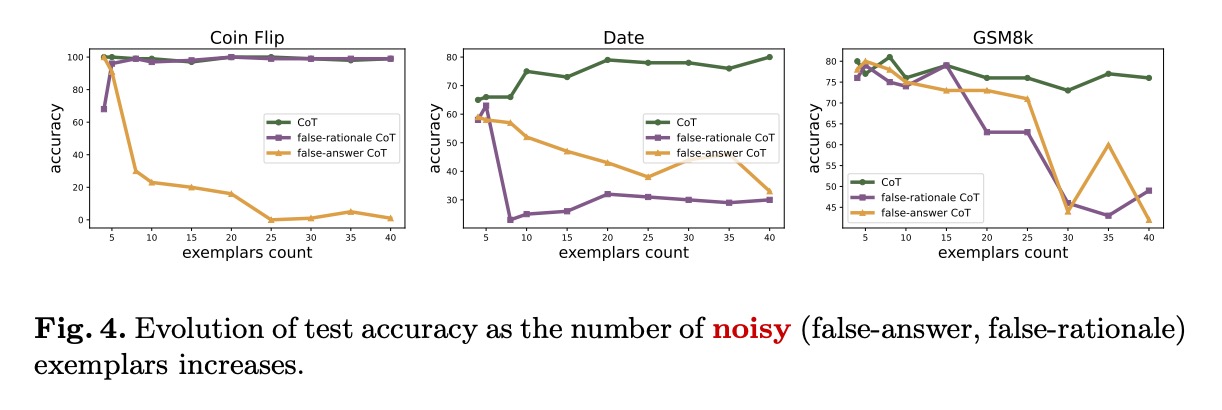
实验结果显示:
- 少量噪声:模型主要依赖预训练先验,忽略错误示例
- 大量噪声:模型逐渐转向上下文学习,导致性能下降
- 错误类型敏感性:错误推理(false-rationalle)比错误答案(false-answer)更易误导模型
这一发现为构建鲁棒推理系统提供了重要启示——通过控制示例质量和数量,可以引导模型在两种机制间取得平衡。
发现三:慢思考的可控诱导
通过精心设计的提示工程,研究团队成功诱导模型进入"慢思考"模式,其框架如下:
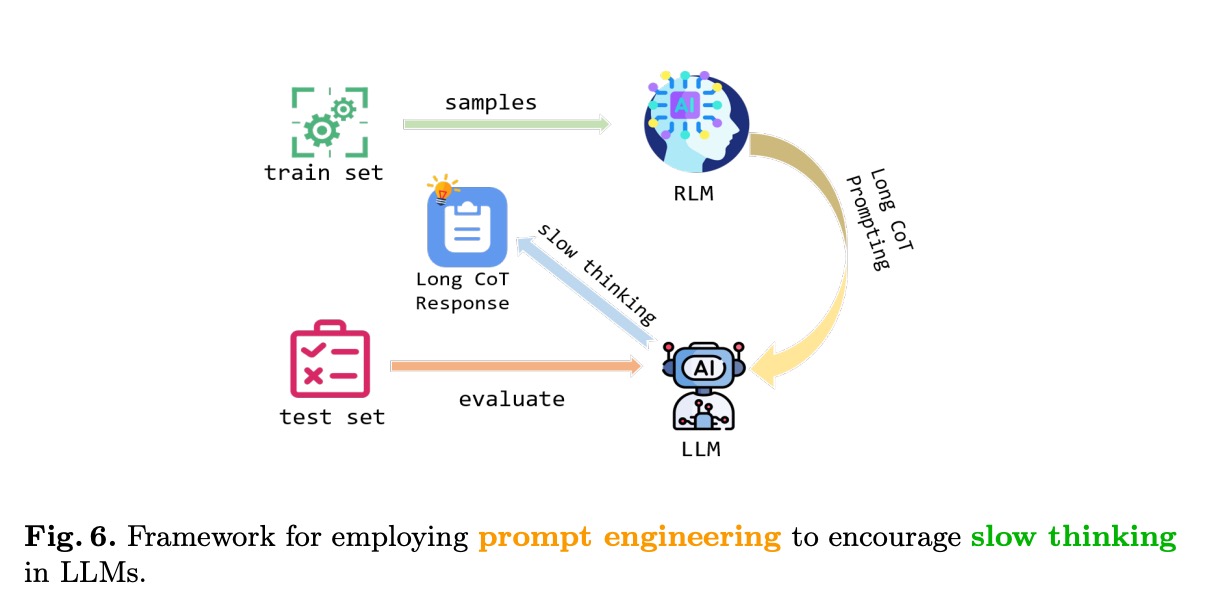
该框架通过检索增强生成(RLM)和长思维链提示,引导模型进行深度推理。实验结果显示,慢思考模式下的概率演化曲线更稳定:
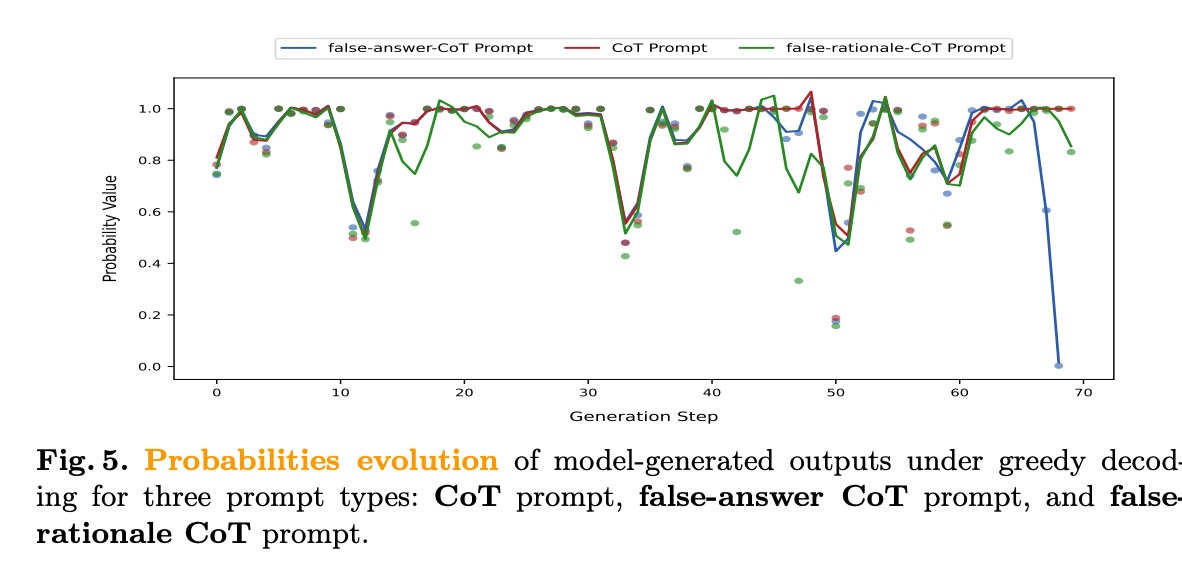
这表明:
- 模型能够通过提示控制推理速度和深度
- 慢思考能显著提高复杂问题的推理准确率
- 推理时间与性能之间存在最优平衡点
实验验证:四大基准测试下的性能表现
跨模型性能对比
在LLaMA3.1和Qwen2.5系列模型上的实验结果表明,协同框架能一致提升推理性能:
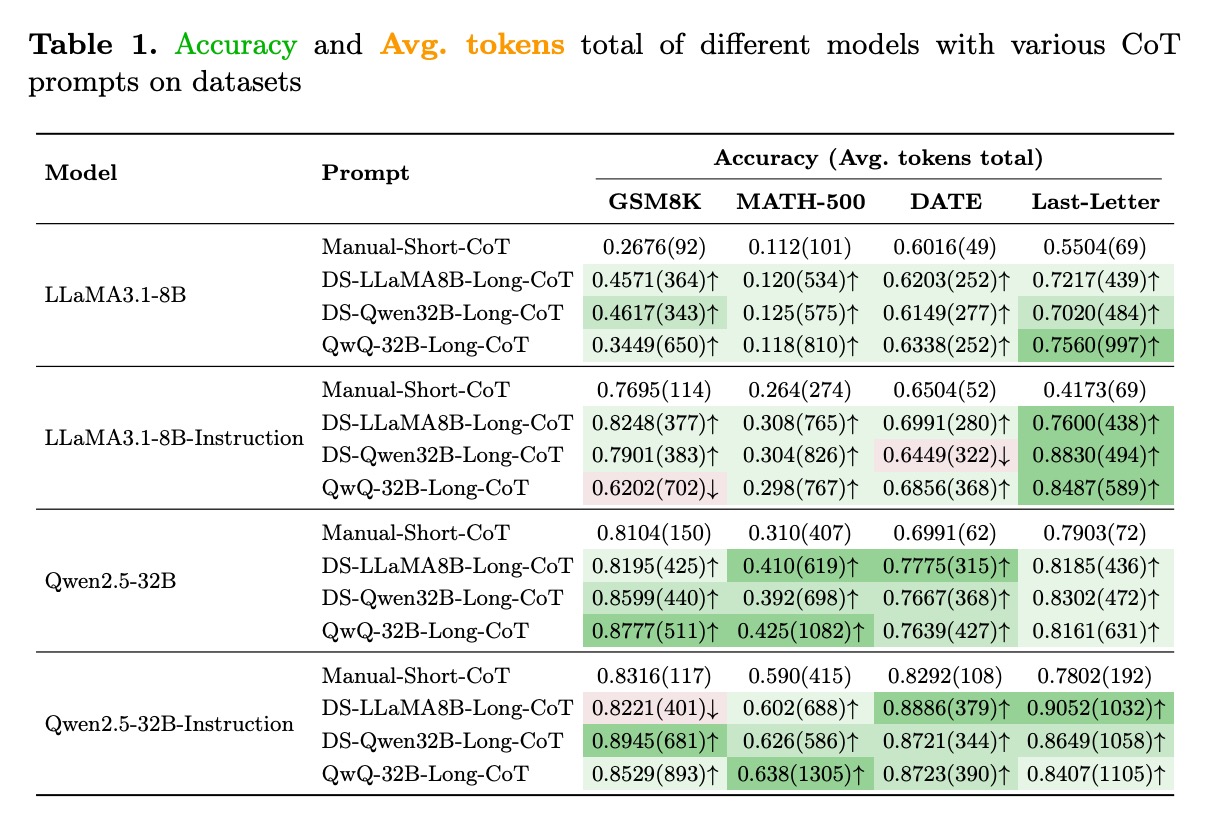
关键数据亮点:
- LLaMA3.1-8B:使用DS-LLaMA8B-Long-CoT提示后,GSM8K准确率从0.2676提升至0.4571(+70.8%)
- Qwen2.5-32B-Instruction:在MATH-500数据集上达到0.638准确率,显著优于其他提示方法
- 指令微调模型优势: Instruction版本模型普遍表现更好,证明预训练先验与微调的互补性
实用启示:如何构建更高效的CoT推理系统
提示工程最佳实践
基于研究发现,提出CoT提示设计的三大原则:
- 结构-内容分离:明确区分推理结构(依赖上下文学习)和领域知识(依赖预训练先验)
- 动词强化:有意识地增加"推理动词"密度,如"分析"、“推断”、"验证"等
- 渐进式噪声:在训练过程中逐步引入噪声示例,增强模型鲁棒性
模型选择与优化建议
不同应用场景下的模型选择策略:
- 资源受限场景:优先选择指令微调模型,如Qwen2.5-32B-Instruction
- 复杂推理任务:采用"慢思考"提示工程,配合较大规模模型(如Gemma2-27B)
- 实时性要求高的应用:平衡推理链长度与响应速度,通常15-20个推理动词为最优
未来研究方向
这项研究打开了多个值得深入探索的方向:
- 动态平衡机制:设计能自动调整预训练先验与上下文学习权重的自适应系统
- 多模态CoT:将协同框架扩展到图像-文本推理任务
- 鲁棒性增强:开发能抵抗恶意噪声示例的防御机制
- 推理质量评估:构建基于推理动词和逻辑结构的自动评估指标

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)