RAG系统优化大揭秘:让你的AI从学渣变学霸的进化之路
你的RAG系统回答问题总是差那么一点?从用户反馈收集到强化学习,这篇文章带你了解如何打造进化不息的RAG系统。通过一家书店智能助手的进化故事,展示数据驱动优化和模型微调策略如何让RAG系统越变越聪明,并帮助AI拥有真正的'学习能力'。
大家好啊,今天我要跟各位聊一个有趣的话题:为什么有的RAG系统像学霸,知道的越来越多,而有的却像学渣,天天"编、抄、混"?
想象一下,你刚刚给一家书店部署了一个智能助手系统。刚上线那天,老板信心满满,结果第一个顾客问:"你们有《百年孤独》的简体中文新版吗?",AI助手自信地回答:"有的,就在科幻小说区。"
老板:......
AI也需要"家长会":数据驱动的持续优化
首先,让我们看看RAG系统优化的整体流程是什么样的:
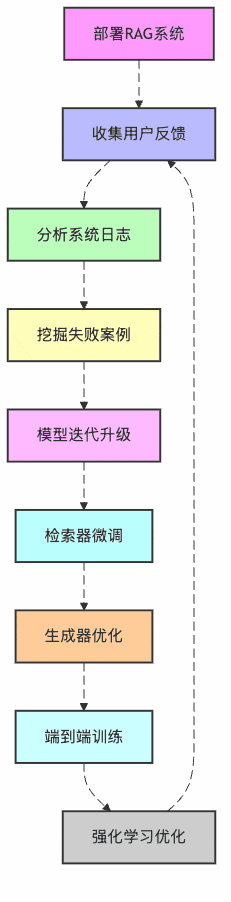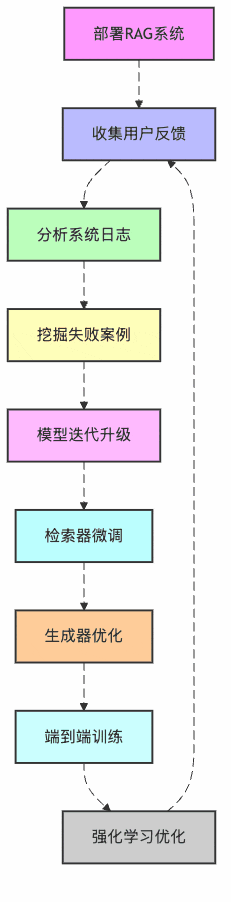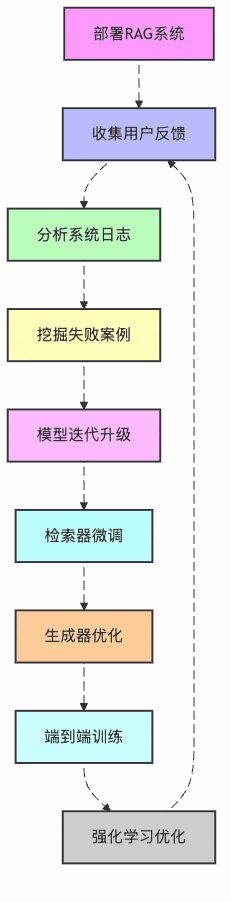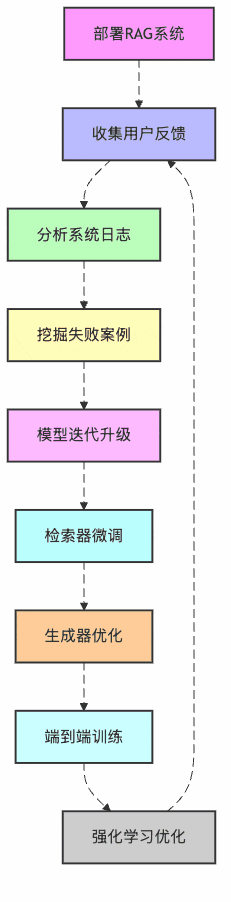
图1:RAG系统持续优化闭环
看到没?这就像孩子从幼儿园到博士的完整教育路径!我们的书店AI助手也需要这样的"成长路径"。
"顾客意见簿":用户反馈收集
还记得以前商店里的意见簿吗?RAG系统也需要这样的机制。
书店老板决定在每次AI回答后,添加一个简单的"这个回答有帮助吗?"按钮。没想到收集到这样的反馈:
"AI说《哈利·波特》是关于一个叫波特的厨师发明了一种神奇哈利酱汁的故事..."
老板看完后陷入了沉思:这AI是认真的吗?是谁教它这些的?
实际上,收集用户反馈就像给AI装了一个"纠错系统"。你知道为什么中国学生数学好吗?因为做错一题,老师和家长能让你抄100遍正确答案!AI也需要这样的"严格教育"。
实用小贴士:不要只收集"是/否"这样简单的反馈,尝试让用户指出具体哪里出错了。就像老师不会只告诉你"答案错了",而是会告诉你"这里符号用错了"。
"AI体检报告":检索日志分析
每次用户提问,RAG系统都会留下"足迹",这些数据就像AI的体检报告,告诉我们系统哪里出了问题。
书店AI助手的日志分析发现:
-
当顾客问"这本书讲什么的"时,系统总是检索出书名和作者,而不是内容简介
-
70%的"你们有XX书吗"的问题,检索结果都不包含库存信息
这就像医生看完体检报告说:"嗯,你的消化系统没问题,但视力可能需要矫正。"
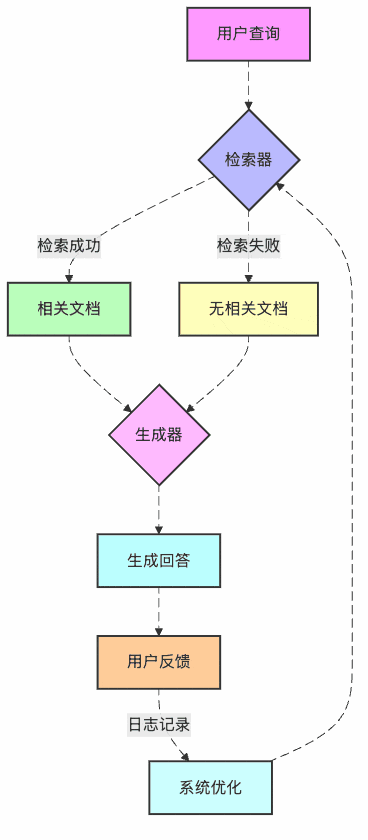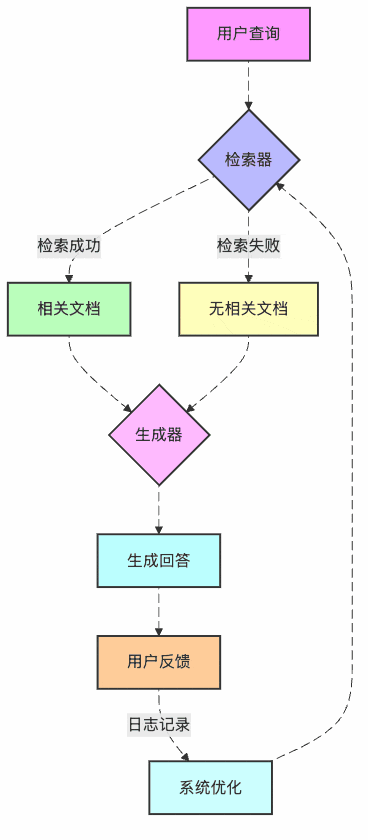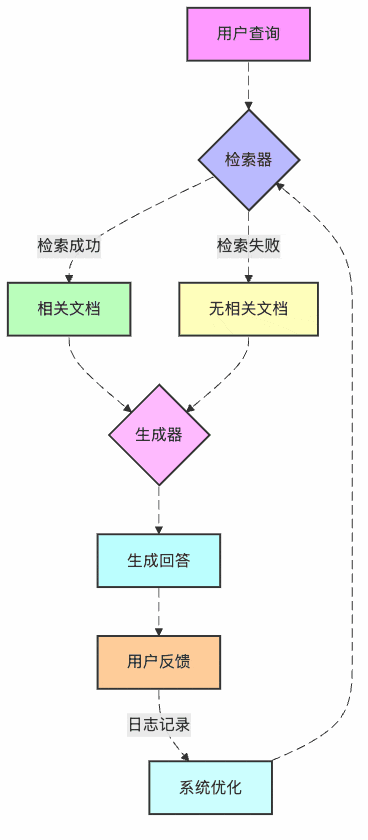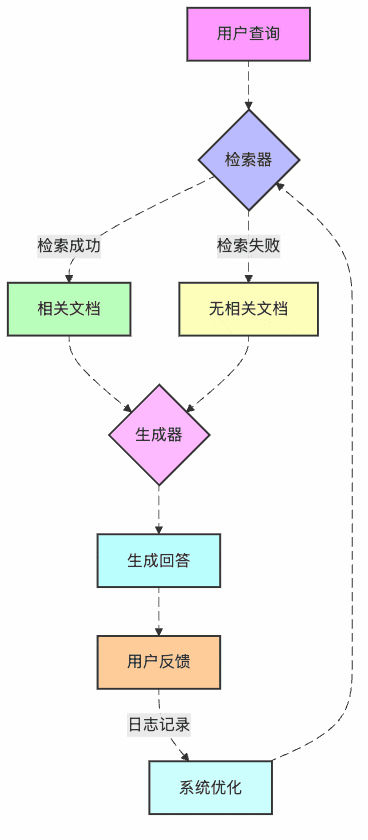
图2:RAG系统日志分析与优化流程
"事故档案室":失败案例挖掘
每个RAG系统都应该有自己的"事故档案室",收集那些惨不忍睹的回答。
书店老板创建了一个"AI翻车现场"文件夹,收集那些离谱的回答:
顾客:"这本书适合10岁的孩子看吗?"
AI:"这本《五十度灰》是一本关于室内装饰的书,当然适合孩子阅读,能培养他们的审美。"
分析这些失败案例,发现AI对书籍分类和适读年龄的理解存在严重问题。这就像分析交通事故录像,找出哪个路口最容易出事故。
实用小贴士:特别关注那些AI非常"自信"却完全错误的回答,这往往说明你的知识库有漏洞或错误信息。
"知识更新课":模型迭代升级
就像学校会定期更新教材一样,RAG系统也需要"充电"。
书店每周会更新新书信息、调整书籍分类,并且记录哪些书已售罄。这些信息需要及时更新到知识库中。
更有趣的是,书店发现把书籍简介按"开头、中间、结尾"分成三块,比整本书放在一起检索效果更好,因为顾客通常只对某一部分内容感兴趣。
这就像你不会把整本《红楼梦》塞进脑子,而是记住关键情节和人物关系。AI也需要学会这样"提炼信息"。
AI的"专项培训":模型微调策略
如果数据驱动优化是AI的"义务教育",那模型微调就是"专项培训"了。
"特长培养":检索器微调策略
检索器就像图书馆的检索系统,需要不断优化才能找到最相关的书籍。
书店的AI助手原本对"推理小说"和"侦探小说"分不清楚,老板决定给它做个"特训":
-
收集100个关于不同类型小说的查询和理想结果
-
让AI尝试检索,看结果对不对
-
标记哪些检索结果是好的,哪些是不相关的
-
用这些标记数据"教育"AI,让它学会更好的检索能力
这就像家长发现孩子数学不好,专门请家教针对性辅导一样。
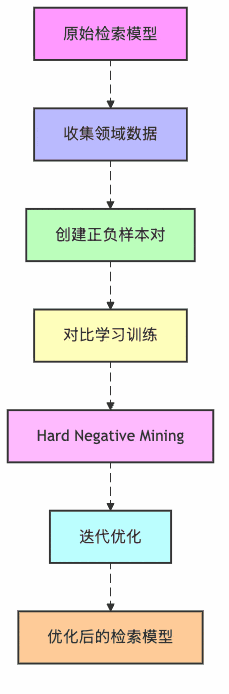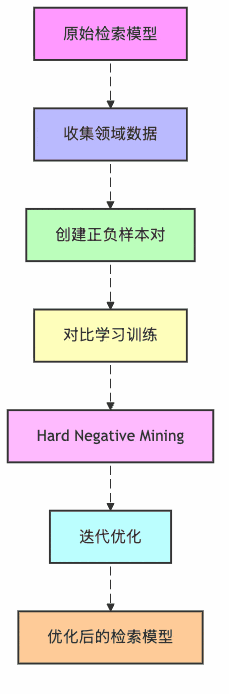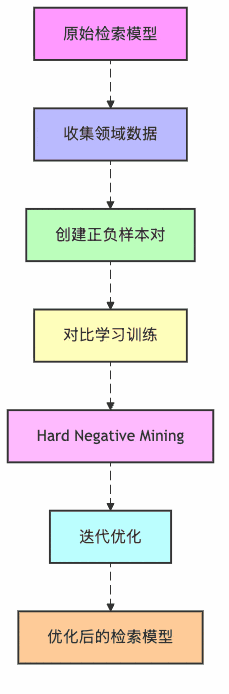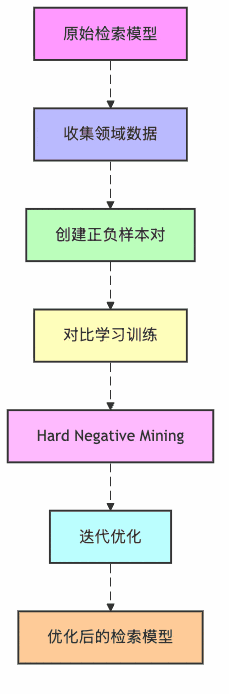
图3:检索器微调流程
"表达能力训练":生成器适应性训练
如果检索器负责"知道",那生成器就负责"表达"。有些AI知道的不少,就是说不清楚,这就需要表达能力训练。
书店老板发现AI的回答太过机械,于是收集了书店最受欢迎的销售员的回答样本,让AI学习这种温暖、专业又不失幽默的表达风格。
想象一下这两种回答的区别:
机械版:"《百年孤独》是魔幻现实主义文学作品。作者是加西亚·马尔克斯。出版于1967年。"
优化版:"《百年孤独》是马尔克斯的传世之作,讲述了布恩迪亚家族七代人的命运,如果你喜欢魔幻现实主义风格,这本书绝对会让你着迷。顺便说一句,我们刚好有新到的简体中文精装版。"
这就像教孩子不仅要"知道答案",还要"会表达"一样。
"协同训练":端到端联合优化
检索和生成本该是一对好搭档,但很多系统里,它们就像两个互不理解的同事。
书店的AI系统经常出现这种情况:检索出了正确的库存信息,但生成模块却忽略了这个信息,导致回答不准确。这就需要"团队协作训练"。
端到端联合优化就像足球队的整体训练,不仅要提高每个队员的技术,还要提高整体配合。通过同时调整检索和生成模块,让它们更好地配合工作。
"奖惩机制":强化学习优化
最高级的优化是建立"奖惩机制",让AI通过不断尝试和反馈来自我提升。
书店老板设计了一套评分系统:
-
如果AI的回答导致顾客购买了书,+10分
-
如果回答准确但顾客没购买,+5分
-
如果回答不准确,-5分
-
如果回答导致顾客投诉,-20分
通过这种"奖惩机制",AI学会了推荐什么样的书更符合顾客需求,而不只是机械地回答问题。
这就像父母不只告诉孩子"这题做错了",而是建立一套零花钱与成绩挂钩的激励机制,让孩子自己想办法提高成绩。
从"死记硬背"到"融会贯通":RAG系统的进化之路
回到我们的书店例子,经过持续优化,AI助手已经从当初只会"死记硬背"的学渣,变成了能够"融会贯通"的学霸:
顾客:"我女儿7岁,喜欢有冒险元素但不太吓人的书,有推荐吗?"
优化前的AI:"我们有《哈利·波特》系列。"
优化后的AI:"对7岁的小朋友,我推荐《小魔女宅急便》或《爱丽丝梦游仙境》,它们有奇幻冒险元素但不会太吓人。如果她喜欢有插图的,'罗尔德·达尔'的作品如《了不起的狐狸爸爸》也很适合。这些书都在儿童区的C3架,要我带您去看看吗?"
这就是RAG系统优化的魅力所在。事实上,任何RAG系统都不可能一次构建就完美,真正的价值在于建立一个持续优化的机制,让系统能够不断学习、不断进化。
为什么你的RAG系统需要"持续进化"
如果你正在学习或构建RAG系统,请记住:一个没有优化机制的RAG系统,就像一个毕业后再也不学习的人,知识很快就会过时。
持续优化是RAG技术的核心竞争力,也是它区别于简单问答系统的关键所在。通过本文介绍的数据驱动优化和模型微调策略,你的RAG系统可以:
-
从用户交互中持续学习
-
适应不断变化的知识和需求
-
提高回答的准确性和相关性
-
优化用户体验和系统性能
最重要的是,通过这些优化,我们让AI拥有了真正的"学习能力",而不只是固定的"知识库"。
下次当有人问你:"RAG系统和普通知识库有什么区别?",你可以自豪地回答:"普通知识库就像一本静态的百科全书,而优化后的RAG系统则像一个不断学习进步的学生,今天的它,比昨天的更聪明。"
这,才是人工智能的未来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)