DeepSeek 登上《自然》封面,全球首个通过同行评审的大模型!
DeepSeek 登上《自然》封面,全球首个通过同行评审的大模型!
昨天被 DeepSeek 刷屏了。
有点炸裂,DeepSeek-R1 论文登上《自然》封面了!
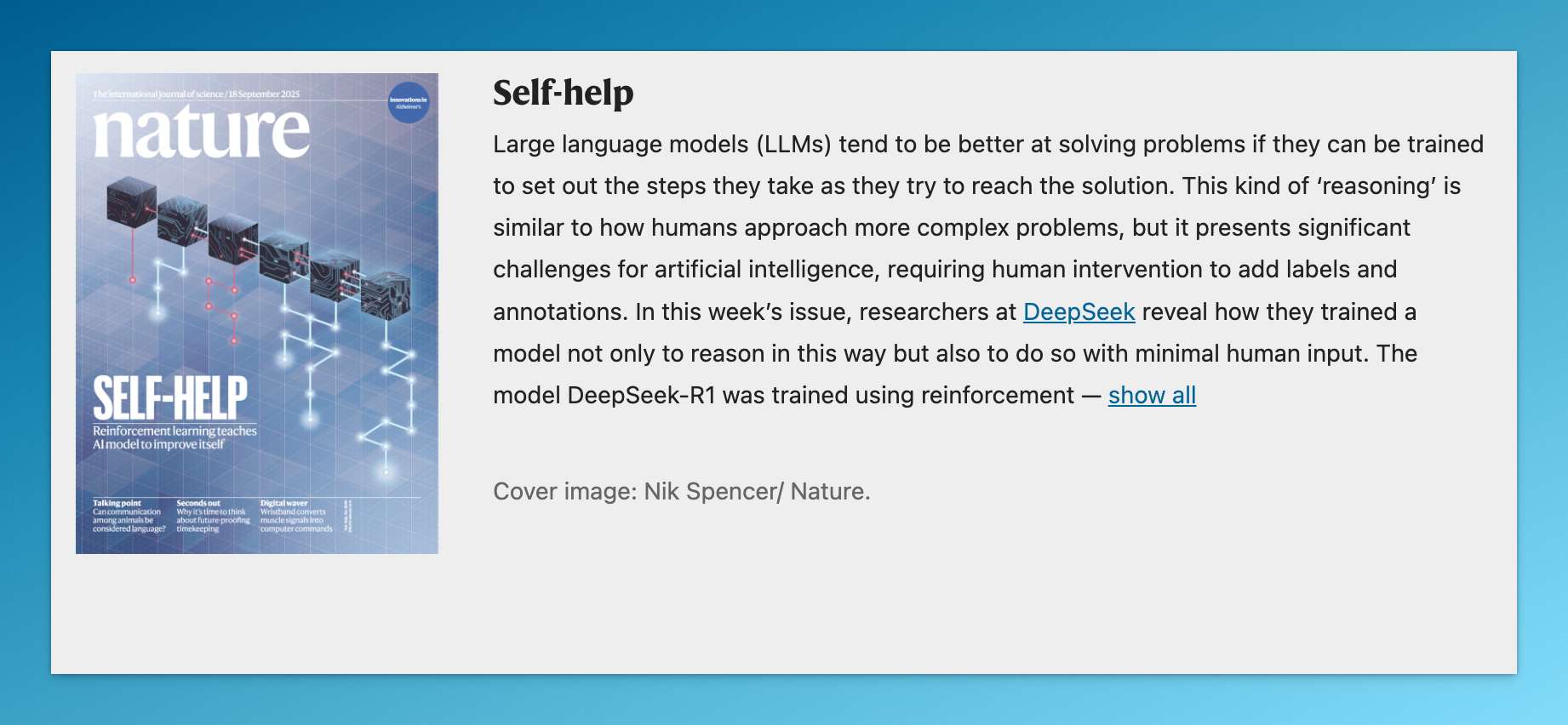
01|全球首个通过同行评审的大模型
这是什么概念?
它成为了全球第一个,真正意义上在顶级学术期刊通过 peer review(同行评审)的大模型。
GPT、Claude、Gemini?没有。它们都是在自己官网或 arXiv 上发表技术报告。
从 2 月 14 日投稿到 7 月 17 日被正式接收,DeepSeek 打磨了整整 5 个月。
《自然》是这么评价的:
“几乎所有主流的大模型都没有经过独立同行评审,这一空白终于被 DeepSeek 打破。”
最终,DeepSeek-R1 成了首个被学术界认证的 AI 模型。
你可能要问,OpenAI、谷歌这些巨头干嘛去了?
很简单,他们根本没这个打算。
闭源模型、商业机密,没人愿意把技术细节暴露在聚光灯下给同行研究。
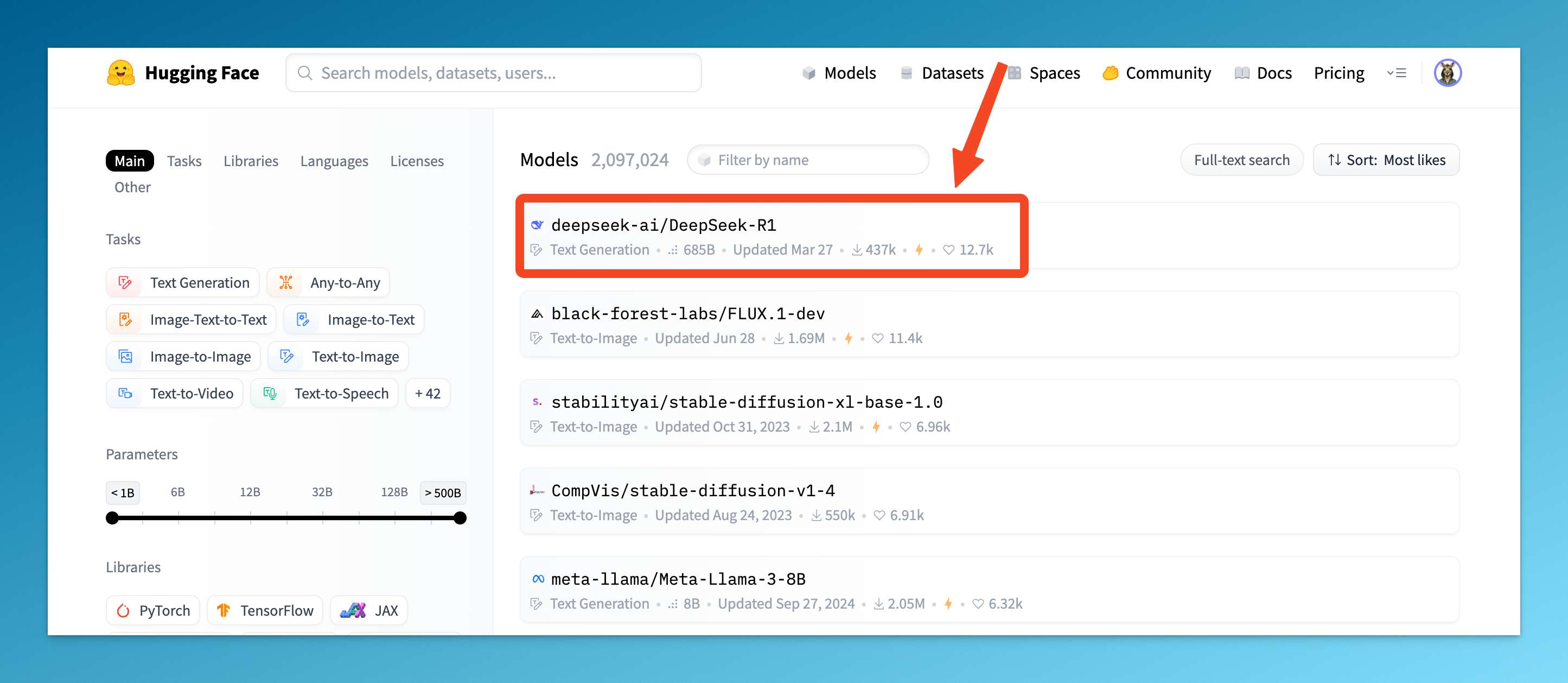
02|Hugging Face 最受欢迎模型
让数据说话。
DeepSeek-R1 是第一个在开源平台登顶的国产模型。
作为 Hugging Face 最受欢迎的模型,它的下载量已突破 1090 万次。
这个平台有 150 万个模型,能冲到第一,实力不必多说。
03|29 万美元,训练出顶级模型
训练成本,这才是重磅炸弹。
《自然》首次披露了 DeepSeek-R1 的训练成本:29.4 万美元。
是的,你没有看错,29.4 万。
具体来说,这里指的是 R1 的增量训练成本。
但即使加上基础模型的 600 万美元成本,总共也就 629.4 万美元。
OpenAI 训练 GPT-4 花了多少?保守估计上亿美元。
04|纯粹的强化学习,让模型自学推理
能发表在《自然》,“活儿”少不了。
总结一波,R1 的核心创新在于:让 AI 学会自己推理。

通过纯粹的强化学习(RL)来提升模型的推理能力,从而减少增强性能所需的人类输入工作量。
讲人话:不给解题过程,只给答案对错,让模型自己摸索。
这就像教小孩做题,传统方法是手把手教解题步骤,DeepSeek 的方法是:“你自己试,对了奖励,错了重来。”
听上去有点不靠谱,但效果惊人。以 AIME 2024 为例,它的解题准确率(pass@1)从最初的 15.6%,一路飙升至 77.9%。
如果配合"自洽解码"技术,准确率能到 86.7%,这超过了所有人类参赛选手的平均水平。
05|512 块 H800 GPU
更狠的是 R1 的训练配置。
第二阶段的成果是 DeepSeek-R1-Zero,DeepSeek 团队用了 512 块 H800 GPU,耗时约 198 小时。
最后的 DeepSeek-R1,仍然采用 512 块 H800 GPU 的配置,但仅用时 80 小时便宣告训练完成。
这里的重点是 H800。
H800 说白了就是英伟达专门为中国市场“阉割”的版本,性能比 H100 差了不少。
而 DeepSeek 用阉割版硬件,做出了世界级成果。
有点东西。
06|数据集不在大,在精
本次论文还首次披露了 R1 的训练数据构成。
-
数学数据集由 2.6 万道定量推理题构成
-
编程数据集由 1.7 万道算法竞赛题与 8 千道 Bug 修复题构成
-
STEM 数据集由 2.2 万道选择题构成
-
逻辑数据集由真实问题和合成问题共 1.5 万题构成
数据量不算大,但质量很高。
某种意义上,这证明了:大力不一定出奇迹,方法才是关键。
结语
DeepSeek 登上《自然》封面,不只是一个团队的胜利。
它证明了几件事:
-
钞能力不一定能解决所有问题:29 万美元 vs 上亿美元,效果却差不多
-
开放比封闭更有生命力:1090 万次下载,开发者用脚投票
-
学术规范依然重要:同行评审虽然麻烦,但能让技术更可信
当然,最重要的启示是:在 AI 这条赛道上,创新的方法比堆算力更重要。
OpenAI、谷歌确实很强,但他们的路不是唯一的路。
DeepSeek 用自己的方式,走出了一条不一样的路。
期待 R2。
我是木易,一个专注 AI 领域的技术产品经理,国内 Top2 本科 + 美国 Top10 CS 硕士。
相信 AI 是普通人的“外挂”,致力于分享 AI 全维度知识。这里有最新的 AI 科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用 AI 为你的未来加速。
精选推荐

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)