AI编码:使用AI工具提高代码编写效率的革命性技巧与实战案例
AI编程助手正在变革软件开发流程,通过代码自动生成、解释、重构和测试等核心功能显著提升效率。主流工具包括GitHub Copilot、ChatGPT等,支持多种编程场景。本文详细介绍了AI辅助编程的应用技巧,包括Prompt优化、工作流设计及高级应用案例,同时强调需保持代码审查和安全意识。AI虽能提升35-70%的开发效率,但仍需与开发者专业知识结合使用。未来趋势包括多模态编码和全流程自动化,但人
引言:我们正站在编程范式变革的拐点
在软件开发领域,一场静默的革命正在发生。人工智能不再是科幻小说中的概念,而是成为了程序员工作台上一个强大的“副驾驶”。AI编程助手正在从根本上改变我们编写、理解、优化和调试代码的方式,将开发者从重复性劳动中解放出来,让我们能够更专注于架构设计、创造性解决问题等更高价值的活动。
传统的编程流程往往需要开发者耗费大量时间在语法查找、API学习、边界情况处理和调试上。而现在,通过智能化的AI工具,我们可以实现代码自动补全、智能生成、错误预测、语义搜索和自然语言编程,显著提升开发效率与代码质量。
本文将深入探讨如何利用AI工具提升编码效率,包含大量实用技巧、具体案例、可视化图表和Prompt示例,帮助您将AI深度集成到您的开发工作流中。
一、主流AI编码工具全景图
目前市场上有多种类型的AI编码助手,它们以不同形式集成到开发环境中:
1. IDE集成类工具
-
GitHub Copilot: 由GitHub、OpenAI和Microsoft联合开发,支持多种IDE和语言
-
Amazon CodeWhisperer: AWS推出的AI编程助手,专注于安全性和AWS服务集成
-
Tabnine: 支持全代码库上下文理解的AI辅助工具
2. 聊天交互类工具
-
ChatGPT (特别是GPT-4): OpenAI的对话式AI,支持代码生成和解释
-
Claude: Anthropic开发的AI助手,擅长代码分析和长上下文理解
-
DeepSeek Coder: 专注于代码生成的AI模型
3. 专用代码模型
-
CodeLlama: Meta发布的专注于代码的Llama变体
-
StarCoder: BigCode社区开发的大规模代码模型
-
Codex: OpenAI的代码专用模型(CoPilot的后端技术)
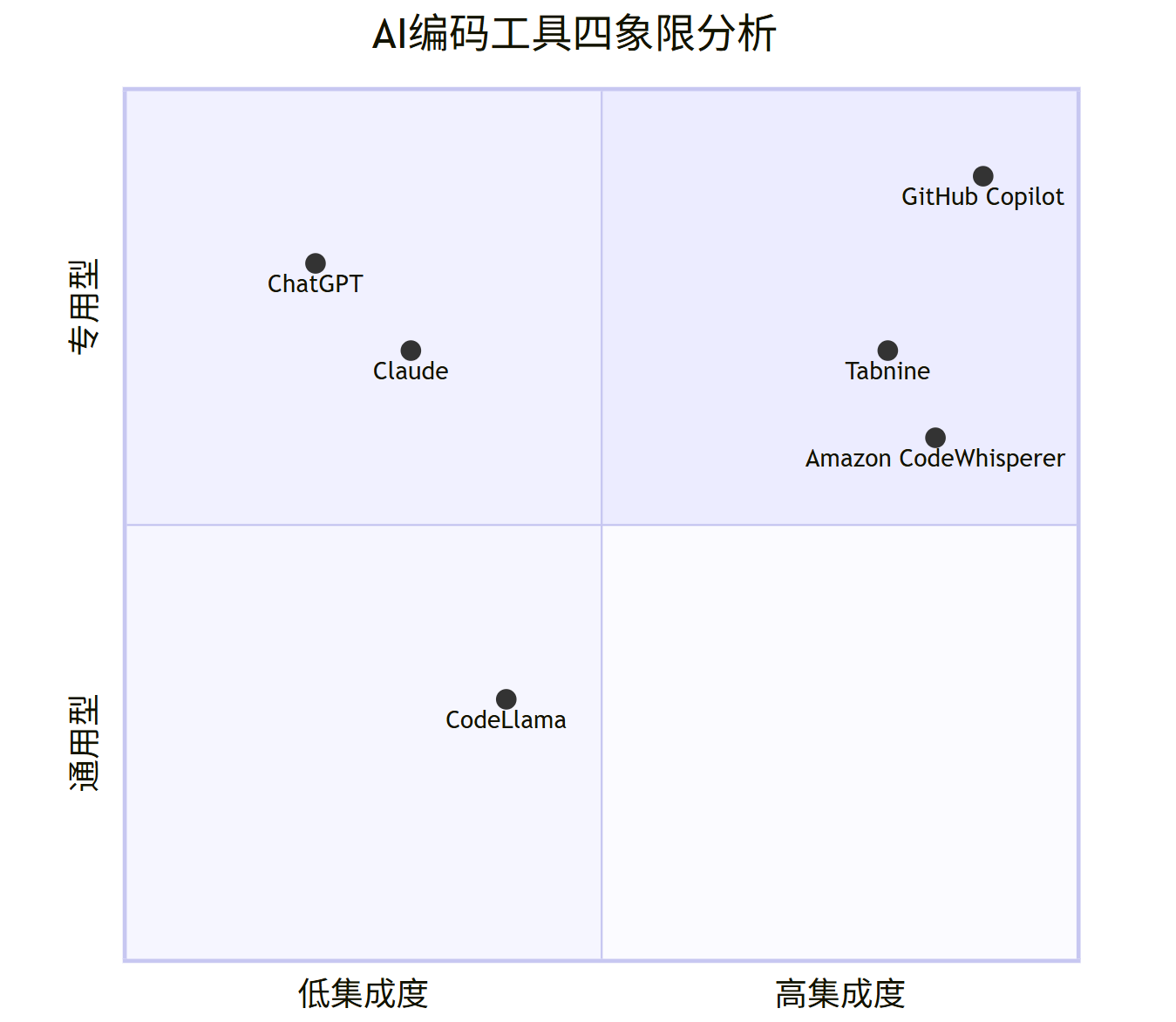
下面是主流AI编码工具的对比分析图:
quadrantChart
title AI编码工具四象限分析
x-axis "低集成度" --> "高集成度"
y-axis "通用型" --> "专用型"
"ChatGPT": [0.2, 0.8]
"Claude": [0.3, 0.7]
"GitHub Copilot": [0.9, 0.9]
"Amazon CodeWhisperer": [0.85, 0.6]
"Tabnine": [0.8, 0.7]
"CodeLlama": [0.4, 0.3]
二、AI编码的核心应用场景与技巧
1. 代码自动补全与生成
AI工具最直接的应用是代码自动补全,它能够根据上下文预测你接下来要写的代码。
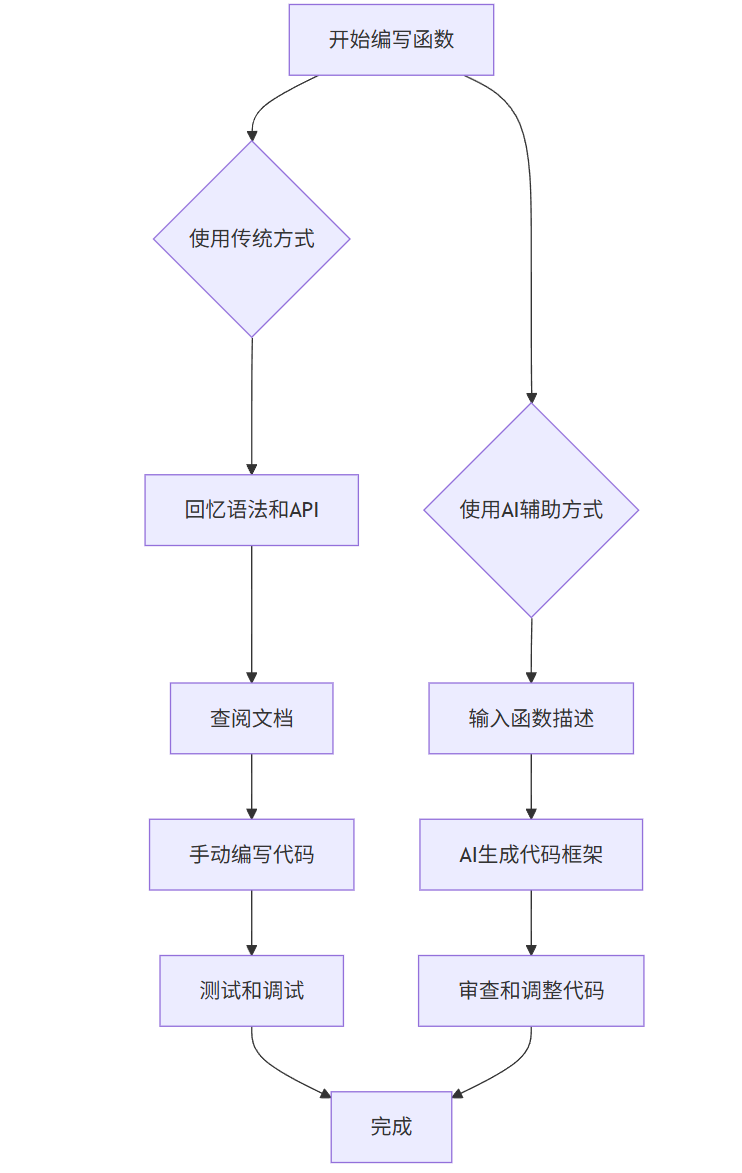
传统方式 vs AI增强方式对比:
flowchart TD
A[开始编写函数] --> B{使用传统方式}
A --> C{使用AI辅助方式}
B --> B1[回忆语法和API]
B1 --> B2[查阅文档]
B2 --> B3[手动编写代码]
B3 --> B4[测试和调试]
B4 --> F[完成]
C --> C1[输入函数描述]
C1 --> C2[AI生成代码框架]
C2 --> C3[审查和调整代码]
C3 --> F
案例:生成一个Python数据处理函数
Prompt示例:
text
请用Python编写一个函数,实现以下功能: 1. 接受一个字典列表作为输入 2. 根据指定的键和排序方向(升序/降序)进行排序 3. 支持多级排序(多个键) 4. 返回排序后的新列表 请添加适当的类型注解和文档字符串。
AI生成的代码:
python
from typing import List, Dict, Union, Literal
def sort_dict_list(
data: List[Dict],
sort_keys: Union[str, List[str]],
sort_order: Literal['asc', 'desc'] = 'asc'
) -> List[Dict]:
"""
对字典列表按照指定键进行排序
Args:
data: 要排序的字典列表
sort_keys: 排序依据的键,可以是单个键或键的列表
sort_order: 排序方向,'asc'表示升序,'desc'表示降序
Returns:
排序后的新字典列表
Examples:
>>> data = [{'name': 'Alice', 'age': 30}, {'name': 'Bob', 'age': 25}]
>>> sort_dict_list(data, 'age')
[{'name': 'Bob', 'age': 25}, {'name': 'Alice', 'age': 30}]
"""
if not data:
return []
# 确保sort_keys是列表形式
if isinstance(sort_keys, str):
sort_keys = [sort_keys]
# 创建排序键函数
def get_sort_keys(item):
return [item.get(key) for key in sort_keys]
# 进行排序
reverse = (sort_order == 'desc')
sorted_data = sorted(data, key=get_sort_keys, reverse=reverse)
return sorted_data
2. 代码解释与理解
遇到难以理解的老代码或第三方库代码时,AI可以快速提供解释。
案例:解释复杂正则表达式
难以理解的代码:
python
import re
pattern = r'^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&]{8,}$'
Prompt示例:
text
请解释以下正则表达式的含义和用途:
r'^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&]{8,}$'
请逐部分解释,并给出3个符合和3个不符合的示例。
AI解释:
text
这是一个用于验证强密码的正则表达式,要求密码包含:
1. 至少一个小写字母 [(?=.*[a-z])]
2. 至少一个大写字母 [(?=.*[A-Z])]
3. 至少一个数字 [(?=.*\d)]
4. 至少一个特殊字符 [@$!%*?&]
5. 总长度至少8位 [[A-Za-z\d@$!%*?&]{8,}]
符合的示例:
1. "Password123!" - 包含大小写字母、数字和特殊字符
2. "Secure@123" - 符合所有要求
3. "Test#2023" - 满足所有条件
不符合的示例:
1. "password" - 缺少大写字母、数字和特殊字符
2. "PASSWORD123" - 缺少小写字母和特殊字符
3. "Pass#1" - 长度不足8个字符
3. 代码重构与优化
AI可以帮助识别代码中的坏味道,并提供重构建议。
案例:重构复杂的条件判断
原始代码:
javascript
function getPrice(userType, productType, price) {
if (userType === 1) {
if (productType === 1) {
return price * 0.9;
} else if (productType === 2) {
return price * 0.85;
} else if (productType === 3) {
return price * 0.8;
}
} else if (userType === 2) {
if (productType === 1) {
return price * 0.8;
} else if (productType === 2) {
return price * 0.75;
} else if (productType === 3) {
return price * 0.7;
}
} else if (userType === 3) {
if (productType === 1) {
return price * 0.7;
} else if (productType === 2) {
return price * 0.65;
} else if (productType === 3) {
return price * 0.6;
}
}
return price;
}
Prompt示例:
text
请重构以下JavaScript代码,消除深层嵌套的条件判断,提高可读性和可维护性。使用更优雅的方式实现相同的折扣逻辑。
AI重构后的代码:
javascript
const discountRules = {
1: { // userType 1
1: 0.9, // productType 1: 10% discount
2: 0.85, // productType 2: 15% discount
3: 0.8 // productType 3: 20% discount
},
2: { // userType 2
1: 0.8, // 20% discount
2: 0.75, // 25% discount
3: 0.7 // 30% discount
},
3: { // userType 3
1: 0.7, // 30% discount
2: 0.65, // 35% discount
3: 0.6 // 40% discount
}
};
function getPrice(userType, productType, price) {
const discount = discountRules[userType]?.[productType];
return discount ? price * discount : price;
}
4. 测试代码生成
AI可以快速生成单元测试,提高测试覆盖率。
案例:为React组件生成测试
React组件代码:
jsx
import React, { useState } from 'react';
const Counter = ({ initialValue = 0, step = 1 }) => {
const [count, setCount] = useState(initialValue);
const increment = () => setCount(count + step);
const decrement = () => setCount(count - step);
const reset = () => setCount(initialValue);
return (
<div>
<h2>Count: {count}</h2>
<button onClick={increment}>+{step}</button>
<button onClick={decrement}>-{step}</button>
<button onClick={reset}>Reset</button>
</div>
);
};
export default Counter;
Prompt示例:
text
请使用Jest和React Testing Library为以下React Counter组件编写完整的测试套件。覆盖所有功能包括初始化、递增、递减和重置操作。请包含边缘情况的测试。
AI生成的测试代码:
jsx
import React from 'react';
import { render, screen, fireEvent } from '@testing-library/react';
import '@testing-library/jest-dom';
import Counter from './Counter';
describe('Counter Component', () => {
test('renders with initial value', () => {
render(<Counter initialValue={5} />);
expect(screen.getByText('Count: 5')).toBeInTheDocument();
});
test('renders with default initial value of 0', () => {
render(<Counter />);
expect(screen.getByText('Count: 0')).toBeInTheDocument();
});
test('increments count by step value', () => {
render(<Counter initialValue={0} step={2} />);
fireEvent.click(screen.getByText('+2'));
expect(screen.getByText('Count: 2')).toBeInTheDocument();
});
test('decrements count by step value', () => {
render(<Counter initialValue={5} step={3} />);
fireEvent.click(screen.getByText('-3'));
expect(screen.getByText('Count: 2')).toBeInTheDocument();
});
test('resets to initial value', () => {
render(<Counter initialValue={10} />);
fireEvent.click(screen.getByText('+1')); // Count becomes 11
fireEvent.click(screen.getByText('Reset'));
expect(screen.getByText('Count: 10')).toBeInTheDocument();
});
test('handles multiple operations correctly', () => {
render(<Counter initialValue={0} step={2} />);
fireEvent.click(screen.getByText('+2')); // +2
fireEvent.click(screen.getByText('+2')); // +2
fireEvent.click(screen.getByText('-2')); // -2
fireEvent.click(screen.getByText('Reset')); // reset
expect(screen.getByText('Count: 0')).toBeInTheDocument();
});
});
5. 调试与错误解决
AI可以帮助快速定位和解决代码中的错误。
案例:调试异步JavaScript代码
有问题的代码:
javascript
async function fetchUserData(userId) {
const response = fetch(`https://api.example.com/users/${userId}`);
const data = response.json();
return data;
}
async function displayUserInfo() {
try {
const userData = fetchUserData(123);
console.log(`User: ${userData.name}, Email: ${userData.email}`);
} catch (error) {
console.log('Error fetching user data');
}
}
displayUserInfo();
Prompt示例:
text
以下JavaScript代码没有按预期工作,它应该获取用户数据并显示,但总是显示"undefined"。请识别问题并提供修复后的代码。
AI分析和修复:
text
问题分析: 1. 在fetchUserData函数中,缺少await关键字,导致response是一个Promise而不是实际响应 2. 在displayUserInfo函数中,调用fetchUserData时也缺少await关键字 3. 错误处理不够详细 修复后的代码:
javascript
async function fetchUserData(userId) {
const response = await fetch(`https://api.example.com/users/${userId}`);
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data = await response.json();
return data;
}
async function displayUserInfo() {
try {
const userData = await fetchUserData(123);
console.log(`User: ${userData.name}, Email: ${userData.email}`);
} catch (error) {
console.log(`Error fetching user data: ${error.message}`);
}
}
displayUserInfo();
三、AI辅助编程工作流设计
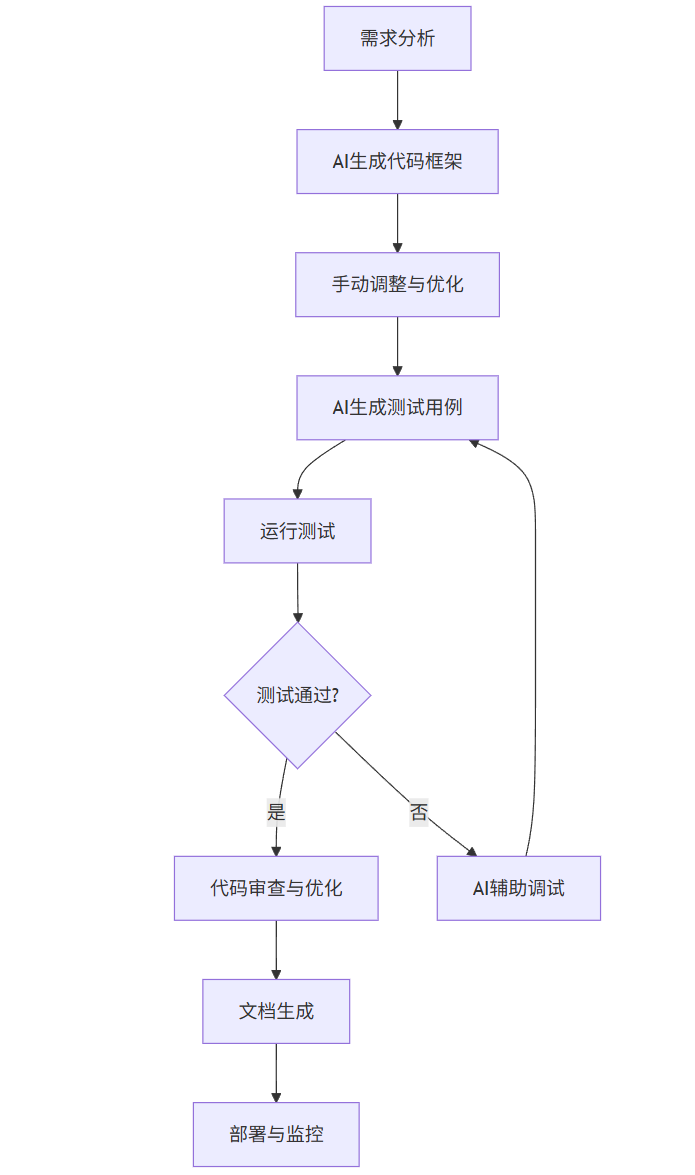
将AI工具有效集成到开发工作流中,可以最大化提升效率。以下是推荐的AI辅助编程流程:
flowchart TD
A[需求分析] --> B[AI生成代码框架]
B --> C[手动调整与优化]
C --> D[AI生成测试用例]
D --> E[运行测试]
E --> F{测试通过?}
F -->|是| G[代码审查与优化]
F -->|否| H[AI辅助调试]
H --> D
G --> I[文档生成]
I --> J[部署与监控]
高效Prompt编写技巧
为了从AI获得最佳结果,需要掌握Prompt工程技巧:
-
明确角色和上下文
text
作为资深Python开发者,请帮我...
-
提供清晰的结构要求
text
请按照以下要求编写函数: - 功能: ... - 输入: ... - 输出: ... - 约束: ...
-
提供示例
text
类似以下示例,但需要增加错误处理功能: [示例代码]
-
迭代优化
text
基于之前的代码,请添加缓存机制以提高性能。
-
指定格式和风格
text
请使用Google风格注释,包含参数类型和返回值说明。
四、高级应用场景
1. 数据库查询优化
案例:优化复杂SQL查询
Prompt示例:
text
请优化以下SQL查询,提高性能并保持结果相同。同时请解释优化原理。
SELECT
u.name,
u.email,
COUNT(o.id) as order_count,
SUM(o.amount) as total_amount
FROM
users u
LEFT JOIN
orders o ON u.id = o.user_id
WHERE
u.created_at > '2023-01-01'
AND o.status = 'completed'
GROUP BY
u.id, u.name, u.email
HAVING
COUNT(o.id) > 5
ORDER BY
total_amount DESC
LIMIT 100;
AI优化建议:
sql
-- 优化后的查询
SELECT
u.name,
u.email,
o.order_count,
o.total_amount
FROM
users u
INNER JOIN (
SELECT
user_id,
COUNT(id) as order_count,
SUM(amount) as total_amount
FROM
orders
WHERE
status = 'completed'
GROUP BY
user_id
HAVING
COUNT(id) > 5
) o ON u.id = o.user_id
WHERE
u.created_at > '2023-01-01'
ORDER BY
o.total_amount DESC
LIMIT 100;
/*
优化原理:
1. 将LEFT JOIN改为INNER JOIN:因为HAVING条件已经过滤掉没有订单的用户
2. 使用子查询预先聚合订单数据:减少主查询需要处理的数据量
3. 在子查询中先过滤status='completed':尽早减少数据集大小
4. 移除GROUP BY中不必要的字段:只需要按user_id分组即可
*/
2. 算法设计与优化
案例:实现高效搜索算法
Prompt示例:
text
我需要处理大量数据(超过100万条记录)的模糊搜索,请提供一个高效的三元搜索树(Ternary Search Tree)实现,用于存储和搜索字符串集合。请用Python实现,包含插入和搜索方法,并考虑内存效率。
AI实现的代码:
python
class TernarySearchNode:
__slots__ = ['char', 'left', 'mid', 'right', 'value', 'is_end']
def __init__(self, char):
self.char = char
self.left = None
self.mid = None
self.right = None
self.value = None
self.is_end = False
class TernarySearchTree:
def __init__(self):
self.root = None
self._size = 0
def insert(self, key, value=None):
"""插入键值对到三元搜索树中"""
self.root = self._insert(self.root, key, 0, value)
if self.root:
self._size += 1
def _insert(self, node, key, index, value):
char = key[index]
if node is None:
node = TernarySearchNode(char)
if char < node.char:
node.left = self._insert(node.left, key, index, value)
elif char > node.char:
node.right = self._insert(node.right, key, index, value)
else:
if index < len(key) - 1:
node.mid = self._insert(node.mid, key, index + 1, value)
else:
node.is_end = True
node.value = value
return node
def search(self, key):
"""搜索指定的键,返回对应的值"""
node = self._search(self.root, key, 0)
return node.value if node and node.is_end else None
def _search(self, node, key, index):
if node is None or index >= len(key):
return None
char = key[index]
if char < node.char:
return self._search(node.left, key, index)
elif char > node.char:
return self._search(node.right, key, index)
else:
if index == len(key) - 1:
return node if node.is_end else None
return self._search(node.mid, key, index + 1)
def starts_with(self, prefix):
"""查找所有以指定前缀开头的键"""
results = []
node = self._find_prefix_node(self.root, prefix, 0)
if node:
if node.is_end:
results.append(prefix)
self._collect_keys(node.mid, prefix, results)
return results
def _find_prefix_node(self, node, prefix, index):
if node is None or index >= len(prefix):
return None
char = prefix[index]
if char < node.char:
return self._find_prefix_node(node.left, prefix, index)
elif char > node.char:
return self._find_prefix_node(node.right, prefix, index)
else:
if index == len(prefix) - 1:
return node
return self._find_prefix_node(node.mid, prefix, index + 1)
def _collect_keys(self, node, current_prefix, results):
if node is None:
return
# 遍历左子树
self._collect_keys(node.left, current_prefix, results)
# 处理当前节点
new_prefix = current_prefix + node.char
if node.is_end:
results.append(new_prefix)
# 遍历中间子树
self._collect_keys(node.mid, new_prefix, results)
# 遍历右子树
self._collect_keys(node.right, current_prefix, results)
def size(self):
return self._size
# 使用示例
if __name__ == "__main__":
tst = TernarySearchTree()
# 插入数据
words = ["apple", "app", "application", "banana", "band", "bandwidth"]
for word in words:
tst.insert(word, f"value_{word}")
# 搜索测试
print(tst.search("app")) # 输出: value_app
print(tst.search("apple")) # 输出: value_apple
print(tst.search("appl")) # 输出: None (不是完整单词)
# 前缀搜索
print(tst.starts_with("ban")) # 输出: ['banana', 'band', 'bandwidth']
3. 架构设计辅助
AI可以帮助设计系统架构,提供多种方案比较。
Prompt示例:
text
我需要设计一个高并发的实时聊天系统,预计同时在线用户数超过10万。请提供微服务架构设计方案,包含以下组件: 1. 认证服务 2. 消息处理服务 3. 在线状态管理 4. 群组聊天支持 5. 消息持久化 请给出架构图(用mermaid格式)和每个服务的职责说明。
AI提供的架构设计:
text
以下是实时聊天系统的微服务架构设计:
graph TB
Client([客户端]) --> GW[API网关]
subgraph 微服务集群
GW --> Auth[认证服务]
GW --> Msg[消息服务]
GW --> Presence[状态服务]
GW --> Group[群组服务]
Msg --> Cache[消息缓存]
Msg --> MQ[消息队列]
MQ --> Persist[持久化服务]
Presence --> Redis[Redis状态存储]
Group --> DB[群组数据库]
Persist --> MsgDB[消息数据库]
end
subgraph 基础设施
Cache[Redis缓存]
MQ[Kafka/RabbitMQ]
Redis[Redis集群]
DB[MySQL群组数据]
MsgDB[MongoDB消息存储]
end
Client --> WS[WebSocket连接]
WS --> GW
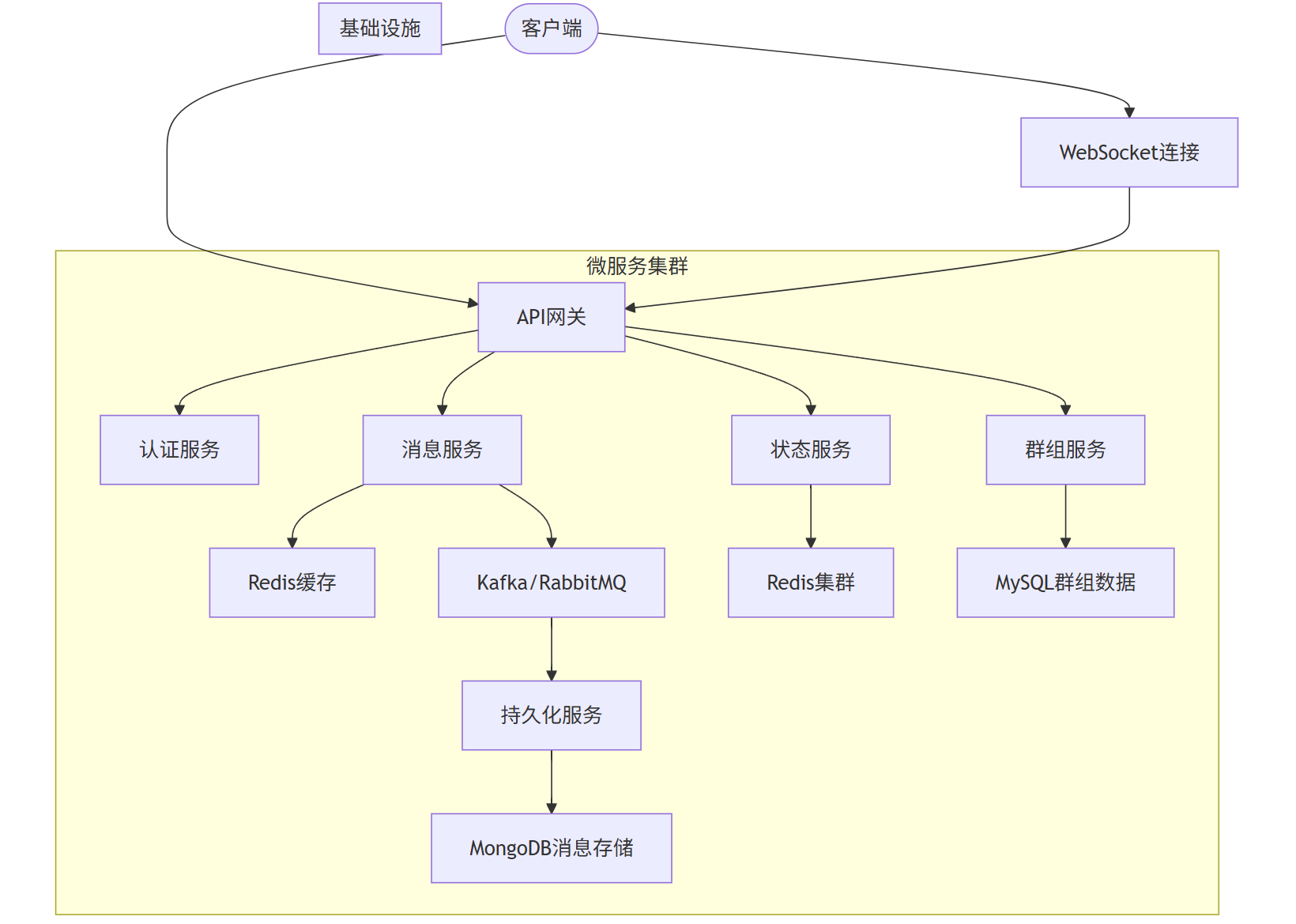
服务职责说明:
-
API网关:统一入口、负载均衡、请求路由、SSL终止
-
认证服务:用户登录、Token签发验证、权限管理
-
消息服务:实时消息接收、转发、基础验证
-
状态服务:管理用户在线状态、心跳检测
-
群组服务:群组管理、成员管理、权限控制
-
持久化服务:消息落库、历史消息查询
-
消息队列:流量削峰、异步处理
-
缓存系统:热点数据缓存、会话管理
五、AI编码的最佳实践与注意事项
1. 最佳实践
-
迭代式开发:不要期望AI一次生成完美代码,采用"生成-审查-迭代"的方式
-
代码审查:始终审查AI生成的代码,确保符合项目标准和最佳实践
-
安全性检查:特别注意AI可能引入的安全漏洞,如SQL注入、XSS等
-
性能测试:对AI生成的算法和代码进行性能基准测试
-
知识验证:验证AI提供的技术建议和信息的准确性
2. 潜在风险与防范
| 风险类型 | 示例 | 防范措施 |
|---|---|---|
| 代码质量风险 | AI生成低效或有错误的代码 | 代码审查、单元测试、静态分析 |
| 安全风险 | 引入安全漏洞或硬编码凭证 | 安全扫描、代码审计、遵循安全最佳实践 |
| 法律风险 | 生成受版权保护的代码 | 使用许可证检查工具、了解AI训练数据来源 |
| 依赖风险 | 过度依赖特定AI工具 | 保持自身编程能力、多工具对比验证 |
| 隐私风险 | 敏感代码被发送到云端AI | 使用本地化AI工具、数据脱敏处理 |
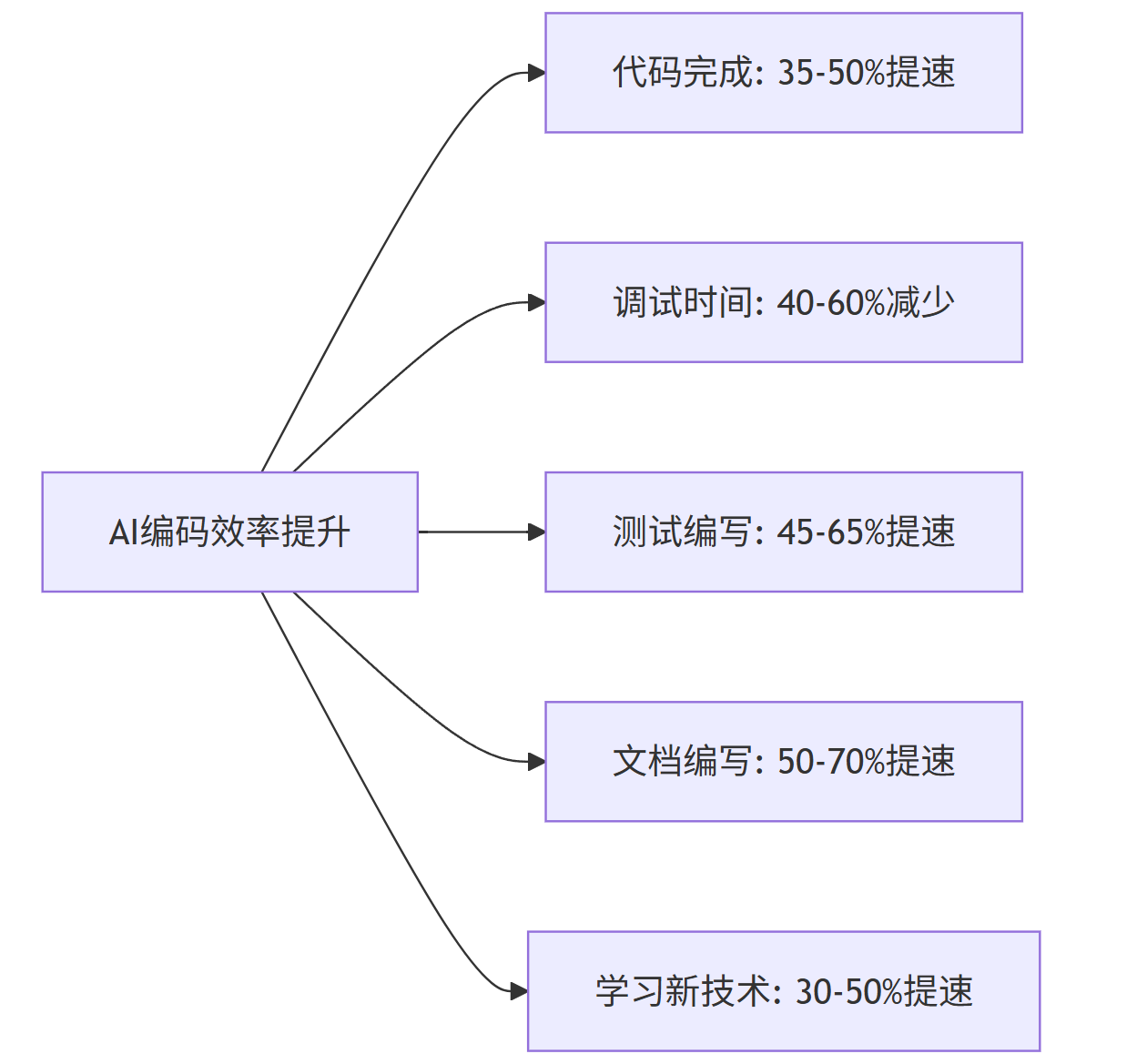
3. 效率提升数据统计
根据业界研究和实际使用情况,AI编码助手可以在以下方面提升效率:
graph LR
A[AI编码效率提升] --> B[代码完成: 35-50%提速]
A --> C[调试时间: 40-60%减少]
A --> D[测试编写: 45-65%提速]
A --> E[文档编写: 50-70%提速]
A --> F[学习新技术: 30-50%提速]
六、未来展望
AI编码技术仍在快速发展,未来可能出现以下趋势:
-
多模态编码助手:结合代码、文档、图表的多模态理解与生成
-
个性化编码风格:学习开发者个人偏好和项目规范生成代码
-
全流程自动化:从需求分析到部署监控的全流程AI辅助
-
实时协作增强:AI辅助的实时团队协作和代码审查
-
自我优化系统:AI系统能够根据反馈自我改进和优化
结论
AI编码工具已经成为现代软件开发不可或缺的组成部分,它们显著提高了开发效率、代码质量和开发者体验。然而,成功的AI辅助编程需要开发者保持批判性思维,结合自身经验对AI输出进行审查和优化。
通过掌握有效的Prompt技巧、将AI工具合理集成到开发工作流中,并遵循最佳实践,开发团队可以最大化AI编码的价值,同时规避潜在风险。未来,随着AI技术的进一步发展,人机协作的编程模式将继续演进,带来更加智能和高效的软件开发体验。
最重要的是记住,AI是增强人类开发者的工具,而不是替代品。深厚的编程知识、问题解决能力和架构设计能力仍然是优秀开发者的核心价值,AI只是让这些能力得到了更好的发挥和扩展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献134条内容
已为社区贡献134条内容

所有评论(0)