如何从零开发一款商业化的OneAgent
本文深度解析一款商用级OneAgent从零自研的全过程。揭秘我们如何实现50MB内存占用、非Root安装、SQL实时查询及采集即治理等核心特性,并分享在轻量化、易用性与可扩展性方面的架构设计思考,为构建企业级可观测平台提供数据基石
目录
在运维和可观测行业中,已经有不少优秀的终端数据采集器,其中包括不少的开源项目,如Datadog Agent,Elastic Beats,Telegraf等等,它们在一些特定的需求场景中可以很出色的工作。但是,对于一家商业化的可观测工具公司来说,这些数据采集器并没有完全满足当前数据智能对采集端的要求,尤其是现在GenAI、AgenticAI的时代,对数据工具/技能的要求会越来越高。
因此,笔者所在公司耗费了很长时间、很多功夫,从零开始自研一款属于自己的商业化OneAgent,作为可观测智能的数据基石。并且从规划设计之初,我们就着重关注其轻量、易用、可扩展的关键属性。经过近几年的商用打磨,OneAgent已经成熟稳定地运行在众多客户的生产环境。
01 OneAgent 的核心设计理念
● 轻量化:降低资源占用,实现高效采集
基础数据采集时(CPU、内存、磁盘、进程、容器、网络)的资源占用情况: 内存≈50 MB, CPU < 1 % 。
● 易用性:简化操作,自动化服务识别与配置
一键安装、服务自动识别、自动打包、自动关联,最终达到 “无脑安装” 的程序。
● 可拓展性:插件机制助力自定义采集扩展
采用插件机制支持自定义的采集,插件可以使用任何开发语言实现,包括shell脚本、python等。此外,插件可以随时启用和停止,不需要重新启动OneAgent (这同时也体现了易用性)
02 OneAgent 的亮点功能
除了以上几点,OneAgent还有以下几个亮点功能:
● 除了主动采集,还可以接收其它组件推送的数据,如SNMP trap, statsd指标
● 支持普通用户安装和采集,非Root权限也可以安装
● 支持使用SQL语法获取实时采集的数据(类似osquery),可以很容易当作目前火热的AI-Agent的Tools使用
● 采集的同时完成数据治理,实现采集即治理,无感知情境富化
● 可视化统一管理,后端Web界面统一管理配置
下图是OneAgent 的数据采集概览图,涵盖了目前常见的几种采集方式。
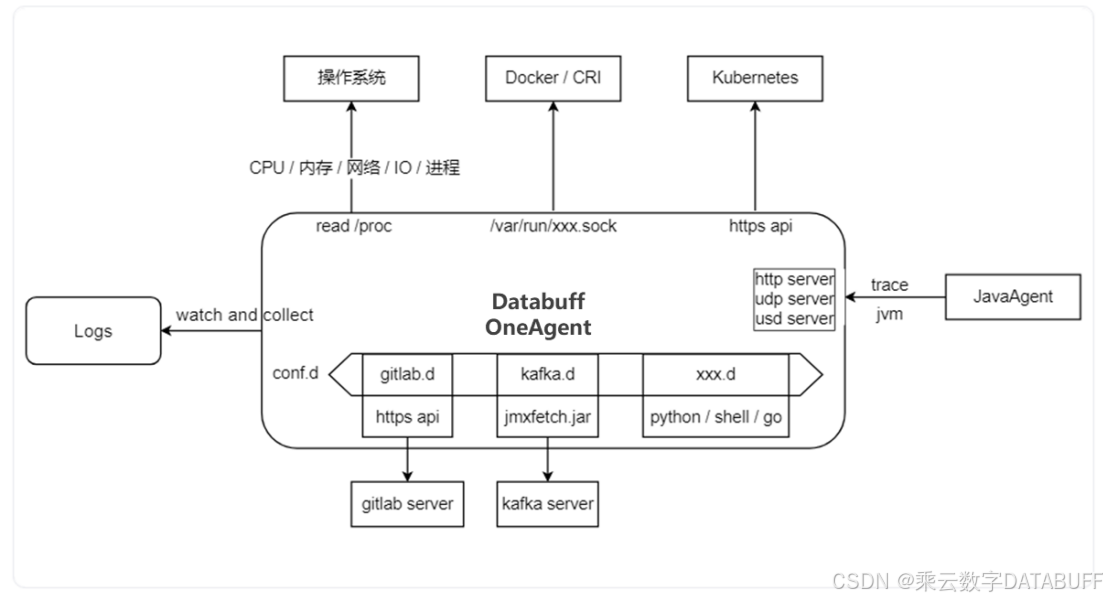
图:OneAgent架构图
接下来,详细说明一下,我们是如何实现以上的一些主要特性。
03 如何实现OneAgent的主要特性
1. 实现 OneAgent 轻量化:减少资源占用的技术策略
轻量的重要指标就是在采集期间尽量少的占用资源,尤其是CPU资源,而采集器经常是通过遍历的方式来获取系统的相关信息。比如,在采集进程相关信息时,采集器会递归访问/proc目录,读取每个进程目录下的信息文件。这样一次采集往往会涉及成百上千个内存文件的打开、读取和关闭操作,消耗的CPU资源不容忽视,尤其当系统中的进程比较多时,甚至会影响业务的正常运行。
OneAgent在采集进程信息时,首先会对进程进行分类,对于与业务无关的进程,只需要采集基本的信息即可;而对于业务进程,需要采集更多的详细信息,比如网络连接统计信息。此外,OneAgent不会每次采集都遍历系统目录,只需要定期遍历一次系统目录(比如一小时一次),期间通过Netlink的NETLINK_CONNECTOR子系统可以实时侦听进程的创建和结束事件,从而每次采集只需要关注这些增量信息即可,极大的减少了对系统目录的访问量。
2. 提高易用性:从安装到采集、治理的全自动化
采集器的易用性指不需要过多的人为配置和操作,就能采集到用户和系统需要的数据。OneAgent通过服务自动发现、自动配置、自动关联和打标来减少人工干预并提高准确性。
OneAgent采集进程信息时,根据采集到的信息可以判断是否为需要关注的服务,如采集到进程名为mysqld,说明系统有mysql服务正在运行,同时可以获取mysql侦听的地址和端口,这样就可以自动生成mysql采集插件的配置信息,如果系统启用了该插件,就可以自动采集mysql服务的指标信息。同理,当OneAgent部署在K8S环境中时,OneAgent会根据采集到的Pod信息,自动推断etcd, ApiServer, ControlManager, KubeProxy等组件的连接信息并自动生成配置数据。
此外,OneAgent还会跟踪环境的网络流量并支持常见协议的解析,比如当前主机访问远程的一个Mysql服务器,OneAgent通过网络流量可以识别出Mysql协议,发现远端的Mysql服务器相关信息,自动生成配置数据。同样,如果这时的Mysql采集插件已经启用,就可以自动采集指标信息。
除了自动发现环境中的服务和组件,OneAgent还会自动关联属性,比如采集进程信息时,如果还启用了容器采集或是运行在K8S环境中,那么进程信息中还会关联上容器和Pod的信息。这样,当我们在定位问题时,可以很容易从进程上探至容器和Pod。又比如,当OneAgent从网络流量中提取出一条TCP连接时,它还会根据TCP连接的五元组信息,关联至与该连接相关的进程,因此可以很轻易地将一条传输延迟很高的网络连接定位至某个进程。
3. 扩展性:利用插件机制赋能自定义采集
任何一个采集器都不可能预见到所有需要采集的组件,因此允许用户用自己擅长的方式去自定义采集方式对一个采集器来说是也一项至关重要的特性。OneAgent 通过插件机制实现采集扩展性,而插件的实现方式并不局限于某种开发语言,只要插件的输出格式满足OneAgent要求的规范即可。
我们以shell脚本插件举例说明,如何写一个符合规范的自定义插件:
#!/bin/bash
echo "# system.user.LOGIN_TIME:GAUGE
echo “# system.user.LAST_LOGIN:GAUGE"
echo "# system.mem.usage:COUNTER|desc text"
echo "123{user=abc, age=18}, 45.33, 2342{email=abc.com}"可见,这个规范并不复杂,主要包括以下几点:
-
插件启动时,首先要输出采集指标的描述信息,包括指标名,指标类型
√ 输出行以 # 开头
√ 指标描述信息的格式如下:指标名:指标类型|指标描述信息
√指标类型可取值:GAUGE, COUNTER, RATE, MONITONIC, HISTORGRAM
2. 按行输出采集的指标,指标内容与Promepheus格式一致,多个指标数据以","分隔,每个指标数据包含两部分:数值和标签,标签部分包含在{}。
通过以上内容,我们大致了解了Databuff-OneAgent的主要工作机制及设计原则。做过数据分析工作的朋友可能深有体会,高质量的数据不仅能大大减少数据预处理的时间,而且也决定着各种机器学习/AI分析的效果。因此,一款优秀的数据采集器值得各行各业的关注。
如果您正在评估可观测性方案,或受困于现有采集器的性能瓶颈,欢迎交流探讨。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)