IsaacLab入门:SO-ARM100抓取任务训练代码解读
本文深入解析了IsaacLab中SO-ARM100机械臂的代码实现与任务配置。首先回顾了train.py主脚本流程的变化,重点分析了机械臂通过USD文件定义物理属性与Python代码配置仿真行为的双重机制。详细解读了抓取任务(Lift-Cube)的配置实现,包括场景搭建、任务目标生成以及训练/测试环境的差异设置。文章还对比了USD与URDF格式的异同,并提供了相关工具查看USD文件的方法。通过结合
上一篇简单的总结了一下IsaacLab中cartpole相关的代码,今天再来看一个复杂一些的例子——SO-ARM100机械臂。如果对于Isaac体系还不熟悉可以先看这一篇。
本文的内容包括:
- 回顾train.py主脚本流程,SO-ARM100有哪些变化
- 代码解读:如何加载SO-ARM100的USD文件,针对抓取任务的配置
- 用usdview等工具查看USD文件的详细配置,USD和URDF格式对比
参考代码https://github.com/MuammerBay/isaac_so_arm101/tree/main,文字版实战教程参考https://cloud.tencent.com/developer/article/2557331。建议先按照实战操作一遍,再来看这里的基础原理。
重点回顾
先简单回顾一下前面的内容,SO-100的代码也会按照这个套路。
- train.py和play.py两个脚本负责训练和测试。
- 选择执行的任务用–task参数,需要用gym.register方法注册
- gym.register注册的每一个task,都需要定义env和算法两个cfg类。
- 环境的配置有managerbased和direct两套接口。
- {算法包名称}VecEnvWrapper用来统一不同的强化学习算法包。
- Runner类负责算法训练的流程。
主脚本流程
主要的流程不变,上述在SO-100中稍有变化
- 有四个task:SO-ARM100-Lift-Cube-v0,SO-ARM100-Lift-Cube-Play-v0,SO-ARM100-Reach-v0,SO-ARM100-Reach-Play-v0。Lift/Reach分别是抓取和到达指定位置两种任务,不带Play和带Play区分训练和测试。
- train.py脚本的整体流程和之前的cartpole一致。因为算法包从rl-games换成了RSL-RL,所以环境的包装类换成了RslRlVecEnvWrapper,Runner类换成了OnPolicyRunner。
机械臂配置
source\SO_100\SO_100\robots\so_arm100.py文件中有SO_ARM100_CFG和SO_ARM100_ROS2_CFG两个类,这两个类分别是仿真和ROS2实际操控的接口。两个类要定义的物理含义是相同的,只是接口变量名不一样。这两个类中都先读取了usd文件usd_path=f"{TEMPLATE_ASSETS_DATA_DIR}/Robots/so_arm100/so_100.usd",在此基础上又用代码进行了一些其他的配置。需要用USD文件+代码两部分进行配置的原因:
- USD文件定义了机器人的“物理本质”:它是什么样子的,它的物理属性(质量、惯性),它的结构(连杆和关节),以及它的物理限制(关节活动范围)。它是一个通用的、可移植的数字资产。
- 代码配置(如
ArticulationCfg)定义了机器人在“特定仿真场景中的行为和初始状态”:它在仿真开始时处于什么姿态,它的电机如何工作(力、速度、控制器参数),以及仿真器应该如何与它交互。
下面我们来详细看看这两者的区别。
1. USD 文件:描述“静态资产”
USD (Universal Scene Description) 是一个用于描述3D场景和资产的框架。对于一个机器人来说,USD文件通常包含以下信息:
-
**视觉信息 (Visuals)**:机器人的外观,包括网格(Meshes)、材质(Materials)、纹理(Textures)。这决定了你在仿真中看到的机器人长什么样。
-
**物理形态 (Physics Shapes)**:用于物理计算的碰撞体。这通常是比视觉网格更简化的形状(如胶囊体、方块),以提高仿真效率。
-
**物理属性 (Rigid Body Properties)**:每个连杆(link)的质量(mass)和惯性张量(inertia tensor)。这些是机器人动力学计算的基础,决定了它在受力后如何运动。
-
**运动学结构 (Kinematic Chain)**:
-
**连杆 (Links/Bodies)**:机器人的各个刚性部件。
-
**关节 (Joints)**:连接连杆的方式(如旋转关节、移动关节)以及它们的父子关系,构成了机器人的骨架。
-
**关节限位 (Joint Limits)**:每个关节能够活动的物理范围(例如,肘关节只能在0到150度之间弯曲)。
可以把USD文件想象成一个机器人的“CAD图纸”或“产品说明书”。 它描述了这个机器人本身固有的、不轻易改变的属性。一个so_arm100.usd文件可以在多个不同的项目和仿真中被重复使用,因为它只定义了机器人本身。
2. Python代码配置:描述“仿真情景”
你的Python代码(SO_ARM100_CFG)是在告诉仿真器(Isaac Sim)如何使用这个USD资产。它定义了特定于本次仿真任务的参数和行为。让我们逐一分析你代码中的配置项:
-
spawn: -
usd_path: 告诉仿真器去哪里加载这个机器人的“图纸”。 -
activate_contact_sensors: 仿真特定功能。USD本身不关心接触传感器是否开启,这是仿真运行时才需要决定的事情,因为它会消耗计算资源。 -
rigid_props,articulation_props: 仿真器参数调整。这些是针对PhysX物理引擎的设置,比如solver_position_iteration_count(求解器迭代次数)或max_depenetration_velocity(最大穿透速度)。这些参数会影响仿真的稳定性、精度和性能,但它们不是机器人固有的属性。一个3D建模师在创建USD时不会也不应该关心这些。 -
init_state: -
rot,joint_pos,joint_vel: 初始状态。这定义了仿真开始时,机器人被放置在世界中的姿态、每个关节的角度和角速度。在另一个仿真任务中,你可能希望它从一个完全不同的起始姿态开始。这个信息是短暂的、情景性的,不应该被硬编码到USD文件中。 -
actuators: -
ImplicitActuatorCfg: 这是最关键的区别之一。USD定义了“关节”(Joint),一个运动学上的约束。而代码定义了驱动这个关节的“执行器”(Actuator),也就是模拟的电机。 -
同一个物理关节可以由不同型号的电机驱动。这里的配置就是在模拟一个特定的电机模型。
-
effort_limit_sim,velocity_limit_sim: 电机能输出的最大力矩和最大速度。 -
stiffness(刚度) 和damping(阻尼): 这两个参数定义了一个模拟的PD控制器。这是控制层面的东西,而不是物理层面的。stiffness相当于P增益,damping相当于D增益。通过调整这些值,你可以模拟出电机响应的“软硬”程度——是快速而精确,还是缓慢而平滑。这纯粹是控制行为的定义,与USD中的物理属性完全分离。例如,你为抓取任务设置的stiffness可能会比为写字任务设置的更高。
在机械臂的基础上定义Lift任务
source\SO_100\SO_100\tasks\lift\lift_env_cfg.py文件是在上面硬件接口的基础上,又定义了关于**抓取任务(从桌子上抓起来一个方块)**的信息。 有两个环境相关的类,一个是SoArm100CubeCubeLiftEnvCfg用于训练,还有一个SoArm100CubeCubeLiftEnvCfg_PLAY用于测试。下面介绍一下具体的配置内容。
整体任务目标
- 执行者 (Agent): SO_ARM100 机械臂。
- 操作对象 (Object): 一个可实例化的方块 (
dex_cube_instanceable.usd)。 - 环境 (Environment): 一张桌子,机械臂和方块都在桌子上。
- 目标 (Goal): 将方块从桌上拿起,并移动到每轮(episode)开始时在空中随机生成的一个目标点。
- 学习方式 (Method): 通过强化学习,根据奖励(Reward)信号来学习最优策略。
各部分详细配置解读
我们将按照代码的逻辑结构来逐一分析:
1. 场景 (ObjectTableSceneCfg)
这部分定义了仿真世界中的所有“静态”和“动态”资产。
-
robot: ArticulationCfg = MISSING: 这是一个占位符,表示具体的机器人模型将在后续的配置中指定。 -
object: RigidObjectCfg | DeformableObjectCfg = MISSING: 这也是一个占位符,用于后续指定要操作的物体。 -
table: -
路径:
{ENV_REGEX_NS}/Table,在仿真场景图中创建名为"Table"的物体。 -
初始位置:
pos=[0.5, 0, 0],桌子被放置在场景中一个固定的位置。 -
模型文件: 从NVIDIA的Nucleus服务器加载
SeattleLabTable/table_instanceable.usd。 -
plane: 一个无限大的地面,防止物体掉出世界。 -
light: 一个穹顶灯,为整个场景提供均匀的光照。
2. 任务目标 (CommandsCfg)
这部分定义了任务的目标是如何生成的。
-
object_pose = mdp.UniformPoseCommandCfg(...): -
pos_x,pos_y,pos_z: 目标位置在机器人基座坐标系下的一个长方体空间内随机生成。 -
roll,pitch,yaw: 目标姿态是固定的((0,0,0)),意味着任务不要求机械臂以特定角度旋转方块,只需要举到目标位置即可。 -
功能: 为机器人生成一个均匀分布的随机目标位姿(位置+姿态)。
-
resampling_time_range=(5.0, 5.0): 目标每5秒钟会重新生成一次。由于整个episode的时长也是5秒,这意味着每轮任务只有一个固定的目标。 -
debug_vis=True: 在仿真界面中会可视化显示这个目标点。 -
ranges: 定义了目标点生成的空间范围。
3. 机器人控制/动作 (ActionsCfg)
这部分定义了强化学习Agent(AI)的输出如何转化为机器人的实际动作。在 SoArm100CubeCubeLiftEnvCfg 中被具体化:
-
arm_action = mdp.JointPositionActionCfg(...): -
控制方式: 关节位置控制。AI的输出是5个主要关节(从肩膀到手腕)的目标角度。
-
scale=0.5: 将AI的输出值(通常在-1到1之间)进行缩放,这可以使动作更平滑,防止动作过大。 -
gripper_action = mdp.BinaryJointPositionActionCfg(...): -
控制方式: 二元位置控制。这是一个简化的夹爪控制。AI只需要输出一个信号。
-
open_command_expr: 如果AI输出“打开”信号,夹爪关节(Gripper)的目标角度设为0.5。 -
close_command_expr: 如果AI输出“关闭”信号,夹爪关节的目标角度设为0.0。
4. 机器人感知/观察 (ObservationsCfg)
这部分定义了AI在做决策前能“看到”哪些信息。
-
PolicyCfg组包含了所有输入给AI决策网络的信息: -
joint_pos_rel: 机器人各关节的相对位置。 -
joint_vel_rel: 机器人各关节的相对速度。 -
object_position_in_robot_root_frame: 方块相对于机器人基座的位置。这是最关键的信息之一,告诉AI物体在哪里。 -
target_object_position: 目标点相对于机器人基座的位置。AI需要知道目标在哪里。 -
actions: 上一时刻执行的动作。这能帮助AI学习动作的连续性。 -
enable_corruption = True: 在训练时,会对观察值加入一定的噪声,这能让训练出的模型(策略)更具鲁棒性,不易受到微小传感器误差的影响。
5. 奖励函数 (RewardsCfg)
这是强化学习的核心,它通过“胡萝卜加大棒”的方式引导AI学习。AI的目标就是最大化所有奖励项的总和。
reaching_object(权重: 1.0): 接近奖励。机械臂末端(end-effector)离方块越近,奖励越高。这是一个“塑形奖励”(shaping reward),用于在初期引导机械臂先学会去接触方块。lifting_object(权重: 15.0): 举起奖励。一旦方块被举起超过0.04米(4厘米),就会获得一个很大的奖励。这是完成任务第一阶段(拿起)的关键信号。object_goal_tracking(权重: 16.0): 目标跟踪奖励。当方块被举起后,它离最终目标点越近,奖励越高。这是最重要的奖励项,引导机械臂完成任务的第二阶段。std: 0.3表示这是一个比较“宽容”的奖励,只要大致方向对就行。object_goal_tracking_fine_grained(权重: 5.0): 精确目标跟踪奖励。与上一个类似,但std: 0.05表示这是一个更“精确”的奖励,用于在接近目标时进行微调。action_rate(权重: -1e-4): 动作惩罚。惩罚AI输出剧烈变化的动作,鼓励平滑控制。joint_vel(权重: -1e-4): 关节速度惩罚。惩罚过快的关节运动,鼓励稳定、节能的动作。
6. 任务结束条件 (TerminationsCfg)
定义了一轮(episode)在什么情况下会提前结束。
time_out: 任务时长达到5.0秒后正常结束。object_dropping: 失败条件。如果方块的高度低于某个阈值(例如从桌子上掉下去了),任务立即失败并结束。
7. 整体环境配置 (LiftEnvCfg 和 SoArm100CubeCubeLiftEnvCfg)
这部分将所有组件整合在一起,并设置仿真参数。
-
num_envs=4096: 大规模并行仿真。同时运行4096个环境,每个环境都在独立尝试任务。这是现代强化学习能够快速训练的关键。 -
episode_length_s = 5.0: 每轮任务的尝试时间上限为5秒。 -
decimation = 2: 仿真器每运行2个物理步(dt=0.01s),AI才进行一次决策。这意味着物理仿真频率是100Hz,而AI的决策频率是50Hz。 -
SoArm100CubeCubeLiftEnvCfg_PLAY: 这是一个用于测试和可视化的配置。 -
num_envs = 50: 环境数量减少,以便于实时渲染和观察。 -
enable_corruption = False: 禁用了观察噪声,使得测试时的行为是确定和可复现的。
算法配置
RSL-RL算法是用类的形式来配置
@configclass
class LiftCubePPORunnerCfg(RslRlOnPolicyRunnerCfg):
num_steps_per_env = 24
max_iterations = 1500
save_interval = 50
experiment_name = "so_arm100_lift"
empirical_normalization = False
policy = RslRlPpoActorCriticCfg(
init_noise_std=1.0,
actor_hidden_dims=[256, 128, 64],
critic_hidden_dims=[256, 128, 64],
activation="elu",
)
algorithm = RslRlPpoAlgorithmCfg(
value_loss_coef=1.0,
use_clipped_value_loss=True,
clip_param=0.2,
entropy_coef=0.006,
num_learning_epochs=5,
num_mini_batches=4,
learning_rate=1.0e-4,
schedule="adaptive",
gamma=0.98,
lam=0.95,
desired_kl=0.01,
max_grad_norm=1.0,
)
下面我们逐一解读这个配置的每一部分。
整体框架
这个配置分为三个主要部分:
RslRlOnPolicyRunnerCfg(训练流程配置): 定义了整个训练循环的宏观参数,比如训练多长时间、收集多少数据等。policy(策略网络配置): 定义了智能体(Agent)的“大脑”——神经网络的结构。algorithm(PPO算法核心参数): 定义了PPO算法本身的学习规则和超参数。
1. RslRlOnPolicyRunnerCfg (训练流程配置)
这部分控制着训练的“节拍”和元数据。
-
num_steps_per_env = 24: -
含义: 在每次进行策略更新(学习)之前,每个并行的仿真环境需要运行24个时间步。这24步的数据(状态、动作、奖励等)构成了一小段“经验轨迹”(trajectory)。
-
作用: 这是On-Policy算法(如PPO)中一个关键的参数,决定了数据收集和模型更新的频率。值越小,更新越频繁,但可能导致学习不稳定;值越大,更新频率低,评估更准,但反馈慢。对于一个快速的“举起”任务,24步可能已经是一个有意义的动作序列。
-
max_iterations = 1500: -
含义: 整个训练过程总共要进行1500次“迭代”。一次迭代包括“收集数据(
num_steps_per_env步)”和“更新模型”两个阶段。 -
作用: 定义了总的训练量。总训练步数 =
max_iterations×num_steps_per_env×并行环境数量。 -
save_interval = 50: -
含义: 每进行50次迭代,就保存一次模型的权重(“存档”)。
-
作用: 用于后续的模型评估、恢复训练或防止训练中断导致进度丢失。
-
experiment_name = "so_arm100_lift": -
含义: 本次实验的名称。
-
作用: 用于区分不同的训练任务,方便在日志和结果文件中进行管理。
-
empirical_normalization = False: -
含义: 是否对观测(Observation)和奖励(Reward)进行经验归一化。归一化通常是指减去均值、除以标准差。
-
作用: 归一化是稳定神经网络训练的常用技巧。这里设置为
False,意味着开发者可能在环境内部已经对数据进行了处理(例如,将关节角度映射到-1到1之间),或者他们认为这个特定任务的原始数据范围已经很适合训练了,不需要自动归一化。
2. policy: RslRlPpoActorCriticCfg (策略网络配置)
这部分定义了智能体的“大脑”,它由两个部分组成:Actor(演员)和Critic(评论家)。
-
init_noise_std = 1.0: -
含义: 策略网络在输出动作时,会附加一个高斯噪声以鼓励探索。这个参数定义了训练开始时这个噪声的标准差。
-
作用:
1.0是一个相对较高的初始值,意味着在训练初期,智能体的动作会非常随机,像是在“胡乱”尝试。这有助于它探索环境,发现可能获得奖励的行为。随着训练的进行,网络会自己学会降低这个噪声(标准差会变小),动作会变得更加确定和精准。 -
actor_hidden_dims=[256, 128, 64]: -
含义: 定义了Actor网络的结构。它是一个有3个隐藏层的多层感知机(MLP),每层的神经元数量分别是256、128、64。
-
作用: Actor负责根据当前的状态决定要执行什么动作。这个网络结构的大小适中,对于一个机械臂控制任务来说是比较常见的配置。
-
critic_hidden_dims=[256, 128, 64]: -
含义: 定义了Critic网络的结构,与Actor相同。
-
作用: Critic负责评估当前状态的“好坏”(即预测未来可能获得的总奖励,称为价值Value)。它帮助Actor判断之前的动作是好是坏,从而指导Actor进行改进。
-
activation="elu": -
含义: 神经网络中使用的激活函数是ELU (Exponential Linear Unit)。
-
作用: ELU是ReLU的一个变体,通常表现良好,可以避免“神经元死亡”问题,是一种稳健的选择。
3. algorithm: RslRlPpoAlgorithmCfg (PPO算法核心参数)
这是PPO算法的“心脏”,定义了学习和优化的具体细节。
-
value_loss_coef = 1.0: -
含义: 在总损失函数中,Critic网络的损失(价值损失)所占的权重。
-
作用:
1.0表示Critic的准确性与Actor的策略优化同等重要。确保Critic能准确评估状态,对于稳定训练至关重要。 -
use_clipped_value_loss = True: -
含义: 使用PPO论文中提出的“截断的价值损失”。
-
作用: 这是一种稳定技巧,防止Critic网络的权重在单次更新中变化过大,有助于保持学习过程的平稳。
-
clip_param = 0.2: -
含义: PPO核心的“截断”参数(Clipped Surrogate Objective中的ε)。
-
作用: 这是PPO的精髓所在。它限制了每次策略更新的幅度,确保新的策略不会与旧的策略偏离太远。
0.2是一个非常标准和常用的值,它在保证学习效率和稳定性之间取得了很好的平衡,防止灾难性的“学坏”情况发生。 -
entropy_coef = 0.006: -
含义: 熵(entropy)奖励的系数。熵衡量了策略输出动作的随机性。
-
作用: 在损失函数中加入一项熵的奖励,可以鼓励智能体保持一定的探索性,避免过早地收敛到一个次优的确定性策略(即只知道一种笨办法,不愿尝试其他可能更好的方法)。
0.006是一个较小的值,表示温和地鼓励探索。 -
num_learning_epochs = 5: -
含义: 每收集到一批数据(由
num_steps_per_env定义),用这批数据对网络进行5轮(epoch)训练。 -
作用: 提高了数据利用率。不是看完一遍数据就扔掉,而是反复“咀嚼”5遍,从而更充分地从经验中学习。
-
num_mini_batches = 4: -
含义: 在每一轮(epoch)训练中,将收集到的整批数据分成4个更小的批次(mini-batch)进行更新。
-
作用: 使用小批量随机梯度下降(SGD)进行训练,可以使训练过程更稳定,并减少内存占用。
-
learning_rate = 1.0e-4: -
含义: 学习率,即每次更新网络权重时步子迈多大。
-
作用:
1e-4(0.0001) 是一个相对较小且稳健的学习率,适合用于复杂的控制任务,避免因步子太大而错过最优点。 -
schedule = "adaptive": -
含义: 学习率不是固定的,而是自适应调整的。
-
作用: 通常会与下面的
desired_kl配合。如果策略更新得太快(KL散度过大),就自动减小学习率;反之,则可能增大学习率。这是一种高级的稳定训练的技巧。 -
gamma = 0.98: -
含义: 折扣因子(Discount Factor)。
-
作用: 衡量对未来奖励的重视程度。
0.98表示智能体非常看重未来的奖励,但略微偏好眼前的奖励。奖励_t+1的价值是奖励_t的98%。对于一个短暂的抓取任务,这个值是合理的。 -
lam = 0.95: -
含义: GAE (Generalized Advantage Estimation) 的lambda参数。
-
作用: GAE是一种更精确地估计“优势”(Advantage,即某个动作比平均水平好多少)的方法。
lambda在偏差和方差之间做一个权衡。0.95是一个非常标准的、效果很好的默认值。 -
desired_kl = 0.01: -
含义: 期望的KL散度。KL散度衡量了新旧策略之间的差异。
-
作用: 与
schedule = "adaptive"配合,算法会尝试调整学习率,使得每次更新后新旧策略的KL散度保持在0.01左右,从而控制更新的步长。 -
max_grad_norm = 1.0: -
含义: 梯度裁剪(Gradient Clipping)的阈值。
-
作用: 另一个关键的稳定技巧。如果计算出的梯度(更新方向)的模长超过1.0,就把它缩放到1.0。这可以防止在某些极端情况下出现梯度爆炸,导致网络权重被彻底破坏。
这个配置描述了一个稳健、标准且经过精心调优的PPO训练流程,专门用于机器人控制任务。
- 核心思想: 采用PPO算法,通过Actor-Critic架构,在策略更新时使用截断(clipping)来保证稳定性。
- 训练策略: 倾向于稳定压倒一切。使用了多种技巧来防止训练崩溃,如低学习率、自适应调整、梯度裁剪、值函数裁剪等。
- 探索机制: 在训练初期通过较大的动作噪声进行探索,并在整个过程中通过熵奖励来维持一定的探索能力。
- 数据效率: 通过多轮次(epochs)的训练来提高对采集到的每批数据的利用效率。
训练日志解读
执行train.py之后可以看到训练日志
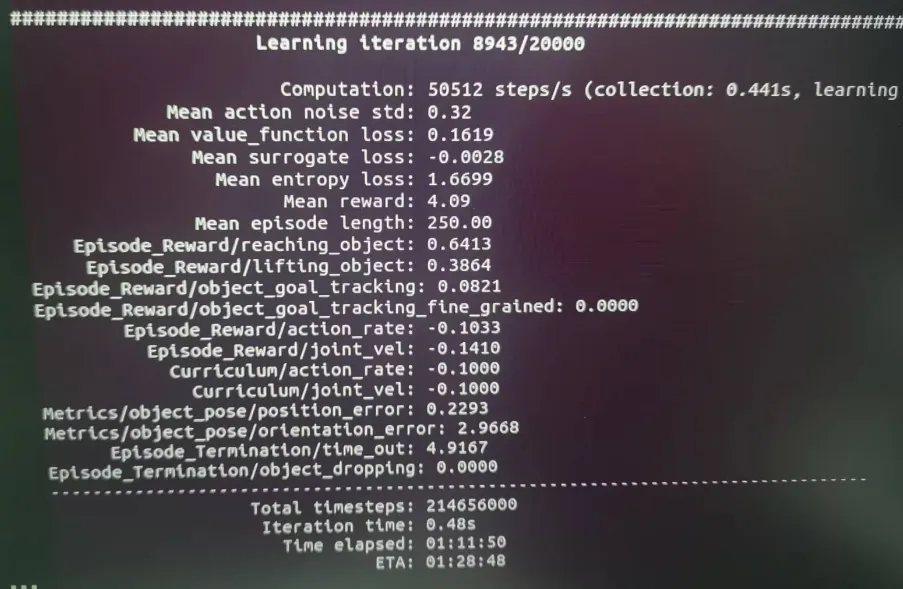
下面逐一解释这些损失(loss)和指标的含义。
A. 强化学习算法本身的损失
这几项是核心的RL算法用来更新其内部神经网络的指标。
Mean value_function loss: 0.1619
- 含义: 这是“评论家”(Critic)网络的损失。在Actor-Critic方法中,评论家的工作是评估当前状态有多好,即预测从当前状态开始能获得多少未来的总奖励。这个损失值衡量了评论家预测的准确性。
- 解读:
0.1619是一个比较小的值。这个值在训练过程中不断下降,意味着评论家对局势的判断越来越准了。
Mean surrogate loss: -0.0028
- 含义: 这是“演员”(Actor)网络的损失,也是最核心的策略提升指标。“演员”是最终做出决策(选择动作)的网络。这个损失函数被设计用来衡量新策略比旧策略好多少。
- 解读: 这个值是负的,这是非常好的信号! 负值意味着算法找到的新策略能够获得比预期更高的奖励,表明策略正在向好的方向更新。如果这个值是正的,可能说明学习率太大或者学习不稳定。
Mean entropy loss: 1.6699
- 含义: “熵”(Entropy)衡量的是策略输出动作的随机性或不确定性。高熵意味着AI倾向于“探索”各种不同的动作,低熵意味着AI对自己的选择非常确定,倾向于“利用”已知的最优动作。
- 解读:
1.6699是一个健康的正值。在训练中,我们通常会把熵作为一项奖励(或者说一个负的损失),来鼓励AI在初期进行充分的探索,防止它过早地锁定在一个不是最优的策略上。这个值会随着训练的进行而逐渐降低。
B. 任务表现与奖励
这部分直接反映了AI在执行我们定义的lift任务时的表现。
Mean reward: 4.09
- 含义: 每一轮(episode)中,AI获得的平均总奖励。这是衡量AI性能的最重要、最直接的指标。训练的目标就是最大化这个值。
- 解读: AI平均每轮能拿到4.09分。这个分数是下面所有
Episode_Reward项的加权总和。
Mean episode length: 250.00
- 含义: 每一轮任务平均持续的步数。
- 解读: 我们的配置中,每轮任务最长
5.0秒,决策频率50Hz,所以最大步数是5.0 * 50 = 250。这里的平均长度是250.00,说明几乎所有任务都是因为时间耗尽(time_out)而正常结束的,而不是因为失败(比如把方块弄掉了)。这是一个非常好的信号。
奖励细分 (Episode_Reward/...)
这些项 دقیقا对应了我们在 RewardsCfg 中定义的各个奖励函数。
reaching_object: 0.6413: AI因为接近方块平均获得了0.64分。说明它已经稳定地学会了如何将机械臂末端移动到方块附近。lifting_object: 0.3864: AI因为成功将方块举起平均获得了0.38分。这是一个正数,说明AI已经学会了抓取和抬升的动作。object_goal_tracking: 0.0821: AI因为将举起的方块移向目标点平均只获得了0.08分。这个分数相对较低。object_goal_tracking_fine_grained: 0.0000: AI因为精确地到达目标点获得了0分。action_rate和joint_vel:-0.1033和-0.1410。这些是负数,因为它们是惩罚项。AI因为动作变化过快或关节速度过高而被扣分,这鼓励它学习更平滑、稳定的动作。
C. 客观任务指标 (Metrics/...)
这些不是奖励,而是对任务完成情况的直接物理测量。
Metrics/object_pose/position_error: 0.2293
- 含义: 在任务结束时,方块的实际位置与目标位置之间的平均距离误差(单位:米)。
- 解读: 平均误差约为23厘米。这是一个比较大的误差,说明AI还没有精确地学会将方块移动到目标点。这与上面
object_goal_tracking奖励很低的情况完全吻合。
D. 任务结束原因分析
Episode_Termination/time_out: 4.9167
- 含义: 因超时而结束的任务,其平均结束时间。
- 解读: 这个值非常接近5.0秒的上限,再次确认了绝大多数任务都是正常结束的。
Episode_Termination/object_dropping: 0.0000
- 含义: 这个值记录了因为“方块掉落”而导致任务失败的频率或相关指标。
- 解读: 值为0,这是另一个极好的信号! 这意味着AI的抓取非常稳定,一旦抓住方块,就几乎不会再掉落。
根据这份日志,我们可以得出以下结论:
- 学习阶段: AI处于中期学习阶段。
- 已掌握的技能:
- 稳定接近: 能够可靠地将夹爪移动到方块处。
- 稳定抓取: 抓取动作非常成功,几乎不会失手掉落。
- 基础举起: 已经学会将方块从桌面上拿起。
-
当前的瓶颈/待学习的技能:
-
目标导向移动: AI虽然能拿起方块,但还不擅长将它精确地移动到随机生成的目标位置。这是它当前需要集中学习的核心任务,表现为
position_error很高,而object_goal_tracking奖励很低。
下一步的训练预期是: object_goal_tracking的奖励会逐渐上升,同时position_error会逐渐下降。当这两个指标改善后,就说明AI真正掌握了整个“拿起并移动”的任务。
最终训练的效果

SO-ARM100
SO-ARM100是个开源的机械臂,https://github.com/TheRobotStudio/SO-ARM100这里提供了3D打印自己组装的方案,以及需要的电机的购买链接。实物有leader和follower两个臂。我们的usd文件实际用的是图中左边的follower臂,右边的leader臂是人类辅助的时候才用的。

可视化工具加载usd
上面我们只看了代码,usd文件的内容对我们来说还是个黑盒子,如果想看看机械臂的具体配置可以参考这个链接安装usdviewhttps://docs.omniverse.nvidia.com/usd/latest/usdview/quickstart.html。安装之后在scripts路径下可以找到usdview_gui,这是程序的启动入口。启动usdview之后open即可在左边的列表里看到SO-ARM100的每个组件,不过右边的显示还有点问题,需要在Display->Shading Mode里面改成points才可以看到机械臂的轮廓。
如果用https://mechaverse.dev/这个网站来打开的话,可以看到一个灰色,完全静态的机械臂。
而网站上给的其他案例的每个关节都是可以动的。
USD文件转结构化数据
在usdview安装好之后,在script路径下还有很多工具,其中的usdtree工具可以将isaac_so_arm101项目中source\SO_100\data\Robots\so_arm100\so_100.usd这个USD文件生成一个树结构,还有一个usdcat工具可以USD文件转成纯文本的USDA格式。USDA格式的文本太长了,里面有很多具体的数值。
usdtree的输出可以清晰的看到usd文件的结构。
|--World [def Xform]
|--Environment [def Xform]
| `--defaultLight [def DistantLight]
|--physicsScene [def PhysicsScene]
|--SO_5DOF_ARM100_05d_SLDASM [def Xform]
| |--Looks [def Scope]
| | |--DefaultMaterial [def Material]
| | | `--DefaultMaterial [def Shader]
| | `--material_CAD1EE [def Material]
| | `--Shader [def Shader]
| |--joints [def Scope]
| | |--Shoulder_Rotation [def PhysicsRevoluteJoint]
| | |--Shoulder_Pitch [def PhysicsRevoluteJoint]
| | |--Elbow [def PhysicsRevoluteJoint]
| | |--Wrist_Pitch [def PhysicsRevoluteJoint]
| | |--Wrist_Roll [def PhysicsRevoluteJoint]
| | `--Gripper [def PhysicsRevoluteJoint]
| |--root_joint [def PhysicsFixedJoint]
| |--Base [def Xform]
| | |--visuals [def Xform]
| | `--collisions [def Xform]
| |--Shoulder_Rotation_Pitch [def Xform]
| | |--visuals [def Xform]
| | `--collisions [def Xform]
| |--Upper_Arm [def Xform]
| | |--visuals [def Xform]
| | `--collisions [def Xform]
| |--Lower_Arm [def Xform]
| | |--visuals [def Xform]
| | `--collisions [def Xform]
| |--Wrist_Pitch_Roll [def Xform]
| | |--visuals [def Xform]
| | `--collisions [def Xform]
| |--Fixed_Gripper [def Xform]
| | |--visuals [def Xform]
| | `--collisions [def Xform]
| `--Moving_Jaw [def Xform]
| |--visuals [def Xform]
| `--collisions [def Xform]
|--visuals [def Scope]
| |--Base [def Xform]
| | `--Base [def Xform]
| |--Shoulder_Rotation_Pitch [def Xform]
| | `--Shoulder_Rotation_Pitch [def Xform]
| |--Upper_Arm [def Xform]
| | `--Upper_Arm [def Xform]
| |--Lower_Arm [def Xform]
| | `--Lower_Arm [def Xform]
| |--Wrist_Pitch_Roll [def Xform]
| | `--Wrist_Pitch_Roll [def Xform]
| |--Fixed_Gripper [def Xform]
| | `--Fixed_Gripper [def Xform]
| `--Moving_Jaw [def Xform]
| `--Moving_Jaw [def Xform]
|--colliders [def Scope]
| |--Base [def Xform]
| | `--Base [def Xform]
| |--Shoulder_Rotation_Pitch [def Xform]
| | `--Shoulder_Rotation_Pitch [def Xform]
| |--Upper_Arm [def Xform]
| | `--Upper_Arm [def Xform]
| |--Lower_Arm [def Xform]
| | `--Lower_Arm [def Xform]
| |--Wrist_Pitch_Roll [def Xform]
| | `--Wrist_Pitch_Roll [def Xform]
| |--Fixed_Gripper [def Xform]
| | `--Fixed_Gripper [def Xform]
| |--Moving_Jaw [def Xform]
| | `--Moving_Jaw [def Xform]
| |--robotCollisionGroup [def PhysicsCollisionGroup]
| `--collidersCollisionGroup [def PhysicsCollisionGroup]
`--meshes [def Scope]
|--Base [def Xform]
| `--mesh [def Mesh]
|--Shoulder_Rotation_Pitch [def Xform]
| `--mesh [def Mesh]
|--Upper_Arm [def Xform]
| `--mesh [def Mesh]
|--Lower_Arm [def Xform]
| `--mesh [def Mesh]
|--Wrist_Pitch_Roll [def Xform]
| `--mesh [def Mesh]
|--Fixed_Gripper [def Xform]
| `--mesh [def Mesh]
`--Moving_Jaw [def Xform]
`--mesh [def Mesh]
下面解读一下这个结果。
|--表示一个子节点。[def Xform]中的def表示这是一个定义的(defined)图元,而不是从别处引用的。Xform是图元的类型,代表一个可变换的节点(具有位置、旋转、缩放属性)。
整体结构分析
整个场景被组织在根路径 / 下(这里没有显示,但它是隐含的),主要分为以下几个大的部分:
/World: 场景的根节点,所有其他内容都组织在它下面。这是一个常见的约定,用于清晰地组织场景。/Environment: 包含与场景环境相关的元素。
defaultLight [def DistantLight]: 定义了一盏平行光(类似太阳光),用于照亮整个场景。
/physicsScene: 定义了物理模拟的全局参数,如重力方向、物理引擎设置等。/SO_5DOF_ARM100_05d_SLDASM: 这是场景的核心,代表整个机械臂资产。SLDASM后缀暗示它可能最初来源于一个 SolidWorks 装配体文件。这个机械臂内部结构非常清晰:
-
visuals [def Xform]: 包含该部件的可见模型,即渲染时我们能看到的模型。 -
collisions [def Xform]: 包含该部件的碰撞体模型。碰撞体通常是简化的几何体,用于物理引擎进行高效的碰撞检测,它在渲染时是不可见的。 -
Shoulder_Rotation,Elbow等[def PhysicsRevoluteJoint]: 定义了六个旋转关节,它们是让机械臂能够运动的关键。这些关节将不同的连杆(link)连接起来,并限制它们的相对运动为旋转。 -
DefaultMaterial和material_CAD1EE: 包含了两个材质定义,每个Material图元下都有一个Shader(着色器)来描述具体的表面属性(如颜色、粗糙度等)。 -
/Looks: 定义了机械臂的外观和材质。 -
/joints: 专门用于定义物理关节。 -
/root_joint: 一个PhysicsFixedJoint(固定关节),用于将机械臂的基座(Base)固定在世界空间中,防止它移动。 -
机械臂连杆 (Links): 从
Base到Moving_Jaw的一系列Xform图元,代表了机械臂的每一个物理部件。每个部件都遵循一种标准的组织模式:
/visuals,/colliders,/meshes: 这三个部分是一种非聚合(un-aggregated)的、按功能分类的组织方式。它们将机械臂的所有几何体和碰撞体按类型分开存放。
/meshes: 存放了所有部件的原始网格数据(Mesh)。这是最底层的几何定义。/visuals: 引用了/meshes中的网格,并将它们组织成用于渲染的层级结构。/colliders: 也引用了/meshes中的网格(或者使用更简单的几何体),并将它们组织成用于物理碰撞的层级结构。同时,这里还定义了PhysicsCollisionGroup,用于管理哪些物体之间应该或不应该发生碰撞。
urdf文件
在SO-ARM100项目中还提供了一个URDF文件,是xml格式的。内容很长就放个链接了 https://github.com/TheRobotStudio/SO-ARM100/blob/main/Simulation/SO100/so100.urdf 内容也是将机械臂模块化的定义出来。那么USD文件和URDF有什么区别呢?
- URDF: 一份机器人的工程蓝图。它极其精确地描述了机器人的骨骼、关节和肌肉,但对“皮肤”和“所处的世界”描述得非常粗略。
- USD: 一部完整的电影场景。它不仅能描述电影主角(机器人)的外观细节,还能描述他所处的环境、灯光、其他角色、以及摄像机如何拍摄他。
核心区别对比
| 特性 | URDF (Unified Robot Description Format) | USD (Universal Scene Description) |
|---|---|---|
| 主要目标 | 描述机器人的运动学和动力学结构 | 描述、组合和渲染任意复杂的3D场景 |
| 诞生背景 | 由机器人操作系统 ROS 社区推动,为机器人控制和物理仿真而生。 | 由皮克斯动画工作室 (Pixar) 创造,为高效协作制作大规模CG电影而生。 |
| 核心结构 | 严格的树状结构。一个连杆(link)只能有一个父关节。 | 灵活的**有向无环图 (DAG)**。一个物体可以被多个场景引用和组合。 |
| 视觉表现 | 极其基础。只能定义简单的颜色和可选的单个纹理。 | 极其丰富。原生支持PBR物理材质、MaterialX、复杂的着色器网络和高清纹理。 |
使用场景的区别
场景一:什么时候你绝对会选择 URDF?
当你工作的核心是机器人本身的控制和运动规划时。
- 运动规划 (MoveIt): MoveIt2 等主流运动规划框架需要 URDF 来获取机器人的运动学链、关节限制,从而进行碰撞检测和生成无碰撞轨迹。
- 传统物理仿真 (Gazebo): 如果你的仿真目标是快速验证算法,对视觉效果要求不高,Gazebo + URDF 是一个非常成熟、轻量化的选择。
在这些场景下,URDF 是“功能”的源头,是描述“机器人能做什么”的权威文件。
场景二:什么时候你会转向使用 USD?
当你需要构建一个高保真的、复杂的、可交互的虚拟世界时。
- 创建数字孪生 (Digital Twin): 如果你不仅要仿真机器人,还要仿真它所在的整个工厂、仓库或实验室环境,USD 是唯一的选择。你可以将机器人的 USD 文件、产线的 USD 文件、建筑的 USD 文件轻松组合在一起。
- 逼真的视觉效果: 当你需要为机器人生成用于 AI 训练的合成数据,或者需要向客户进行高质量的可视化演示时,USD 提供的照片级渲染能力是 URDF 无法比拟的。
- 高级物理仿真: 如果你需要仿真柔性电缆的摆动、机器人抓取软体物体、或与流体交互,你需要 USD 背后强大的物理引擎(如 PhysX)。
- 大规模团队协作: 当一个团队的艺术家负责环境建模,另一个团队的工程师负责机器人仿真时,USD 的层叠和引用机制允许多人并行工作,而不会互相覆盖对方的文件。
在这些场景下,USD 是“世界”的容器,是描述“机器人和它周围的一切看起来、感觉起来像什么”的权威文件。
现代工作流:不是“或”,而是“和”
现在,最先进的机器人开发流程已经不再是“二选一”,而是将两者结合起来,形成一个清晰的流程:
CAD 设计 → URDF (功能蓝图) → USD (仿真数字孪生)
- URDF 作为运动学核心: 机器人首先被定义成 URDF 文件,因为它最擅长描述核心的运动学和动力学特性。它是机器人“如何动”的“唯一真实来源”。
- 导入并增强为 USD: 然后,这个 URDF 文件被导入到像 NVIDIA Isaac Sim 这样的平台中,自动转换为 USD 格式。
- 在 USD 中“打扮”和“放置”: 转换后的 USD 文件会被赋予逼真的 PBR 材质、高细节的纹理。然后,这个机器人 USD 资产会被引用到一个更大的工厂场景 USD 文件中,并添加专业的灯光和相机。
总结
- 从isaac_so_arm101项目的代码中,我们看到了如何加载一个机械臂的USD文件,结合python代码定义一个抓取的任务,进行强化学习的训练。
- 然后回头再看一看USD文件究竟都有什么内容。
- 最后对比一下URDF和USD两种文件格式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献137条内容
已为社区贡献137条内容

所有评论(0)