FastGPT智能体开发:代码运行与批量运行节点介绍
FastGPT代码运行与批量运行节点介绍。
代码运行
FastGPT 代码运行节点介绍
功能
可用于执行一段简单的 js 代码,用于进行一些复杂的数据处理。代码运行在沙盒中,无法进行网络请求、dom和异步操作。如需复杂操作,需外挂 HTTP 实现。
注意事项
- 私有化用户需要部署
fastgpt-sandbox镜像,并配置SANDBOX_URL环境变量。 - 沙盒最大运行 10s, 32M 内存限制。
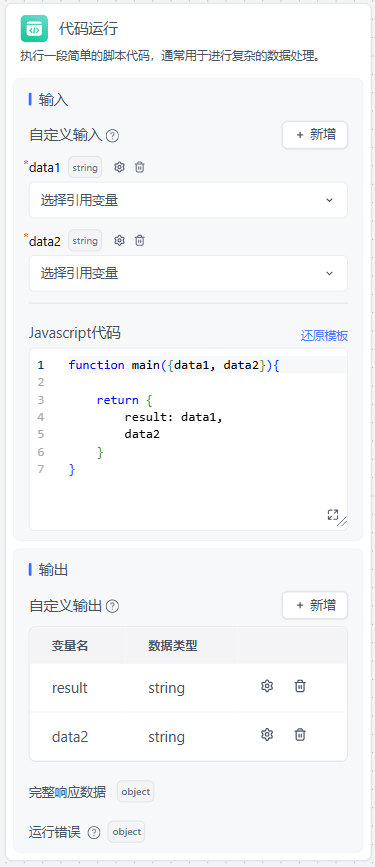
变量输入
可在自定义输入中添加代码运行需要的变量,在代码的 main 函数中,可解构出相同名字的变量。
如上图,自定义输入中有 data1 和 data2 两个变量,main 函数中可以解构出相同名字的变量。
结果输出
务必返回一个 object 对象
自定义输出中,可以添加变量名来获取 object 对应 key 下的值。例如上图中,返回了一个对象:
{ result: data1, data2}他有 2 个 key:result和 data2(js 缩写,key=data2,value=data2)。这时候自定义输出中就可以添加 2 个变量来获取对应 key 下的 value。
内置 JS 全局变量
delay 延迟
延迟 1 秒后返回
async function main({data1, data2}){ await delay(1000) return { result: "111" }}countToken 统计 token
function main({input}){ return { result: countToken(input) }}
strToBase64 字符串转 base64(4.8.11 版本新增)
可用于将 SVG 图片转换为 base64 格式展示。
function main({input}){ return { /* param1: input 需要转换的字符串 param2: base64 prefix 前缀 */ result: strToBase64(input,'data:image/svg+xml;base64,') }}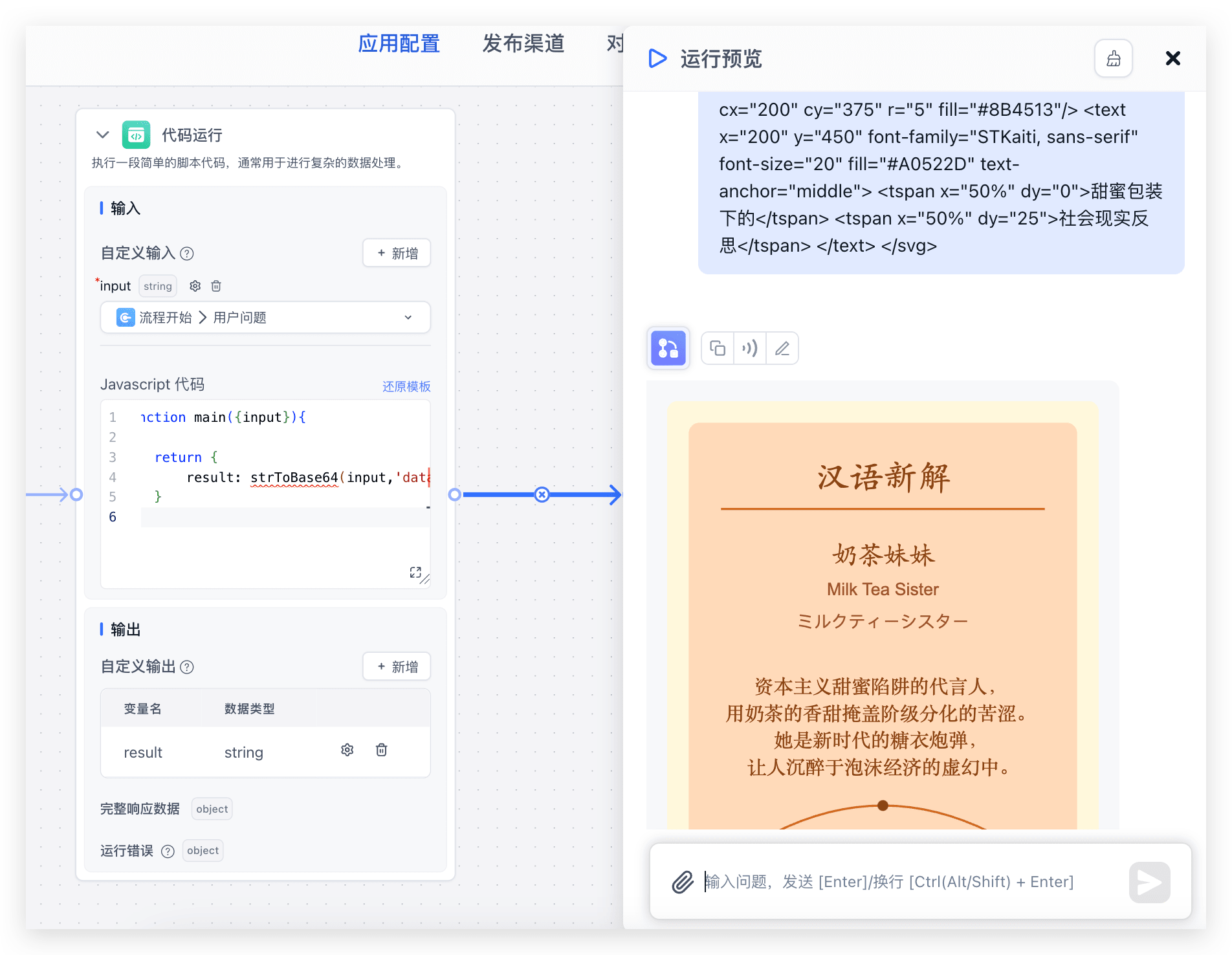
createHmac 加密
与 node 中 crypto 的 createHmac 方法一致。
function main({secret}){ const {sign,timestamp} = createHmac('sha256',secret) return { sign,timestamp }}批量运行
FastGPT 批量运行节点介绍和使用
节点概述
【批量运行】节点是 FastGPT V4.8.11 版本新增的一个重要功能模块。它允许工作流对数组类型的输入数据进行迭代处理,每次处理数组中的一个元素,并自动执行后续节点,直到完成整个数组的处理。
这个节点的设计灵感来自编程语言中的循环结构,但以可视化的方式呈现。
在程序中,节点可以理解为一个个 Function 或者接口。可以理解为它就是一个步骤。将多个节点一个个拼接起来,即可一步步的去实现最终的 AI 输出。
【批量运行】节点本质上也是一个 Function,它的主要职责是自动化地重复执行特定的工作流程。
核心特性
-
数组批量处理
- 支持输入数组类型数据
- 自动遍历数组元素
- 保持处理顺序
- 支持并行处理 (性能优化)
-
自动迭代执行
- 自动触发后续节点
- 支持条件终止
- 支持循环计数
- 维护执行上下文
-
与其他节点协同
- 支持与 AI 对话节点配合
- 支持与 HTTP 节点配合
- 支持与内容提取节点配合
- 支持与判断器节点配合
应用场景
【批量运行】节点的主要作用是通过自动化的方式扩展工作流的处理能力,使 FastGPT 能够更好地处理批量任务和复杂的数据处理流程。特别是在处理大规模数据或需要多轮迭代的场景下,批量运行节点能显著提升工作流的效率和自动化程度。
【批量运行】节点特别适合以下场景:
-
批量数据处理
- 批量翻译文本
- 批量总结文档
- 批量生成内容
-
数据流水线处理
- 对搜索结果逐条分析
- 对知识库检索结果逐条处理
- 对 HTTP 请求返回的数组数据逐项处理
-
递归或迭代任务
- 长文本分段处理
- 多轮优化内容
- 链式数据处理
使用方法
输入参数设置
【批量运行】节点需要配置两个核心输入参数:
-
数组 (必填):接收一个数组类型的输入,可以是:
- 字符串数组 (
Array<string>) - 数字数组 (
Array<number>) - 布尔数组 (
Array<boolean>) - 对象数组 (
Array<object>)
- 字符串数组 (
-
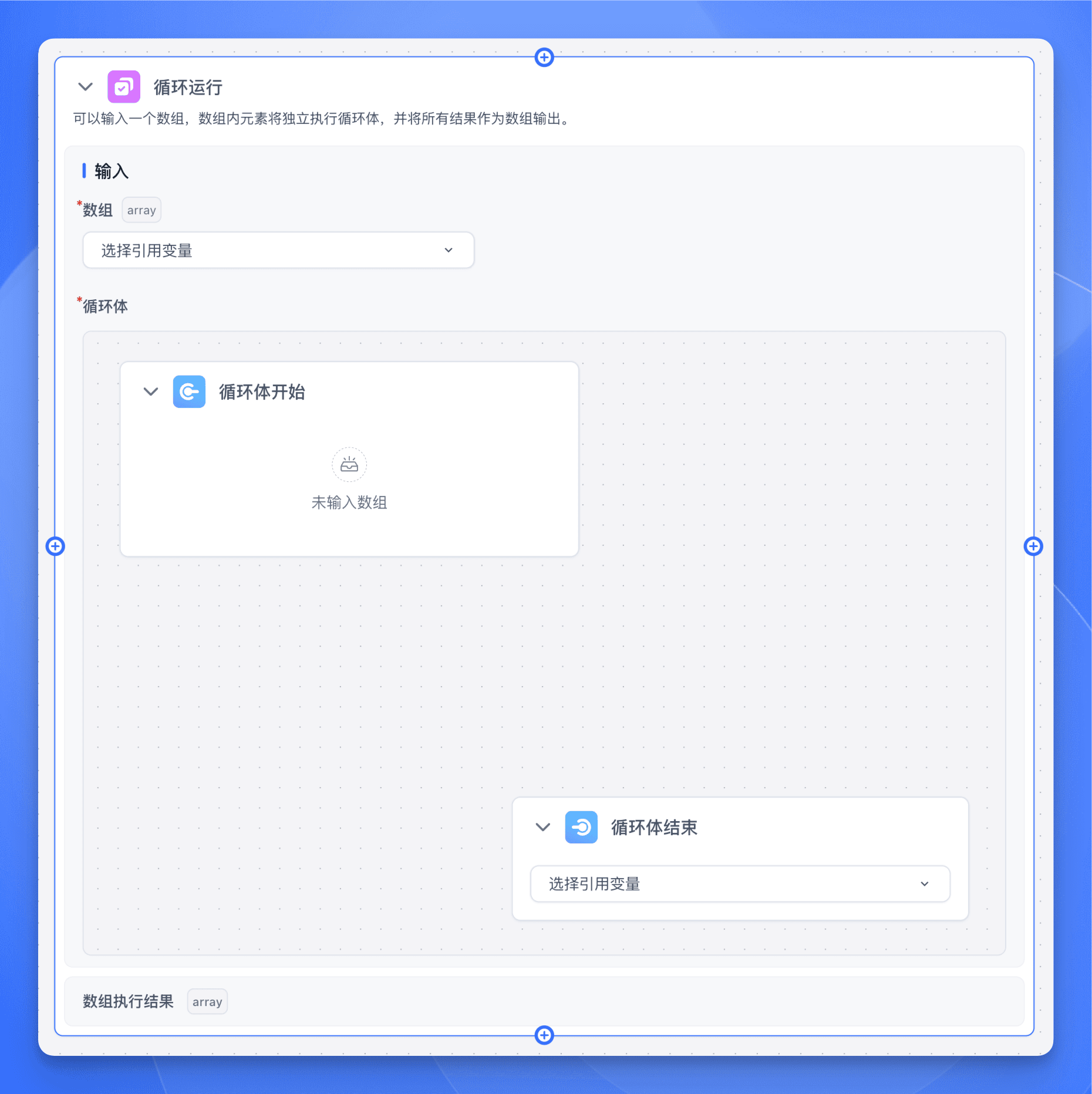
循环体 (必填):定义每次循环需要执行的节点流程,包含:
- 循环体开始:标记循环开始的位置。
- 循环体结束:标记循环结束的位置,并可选择输出结果变量。
循环体配置
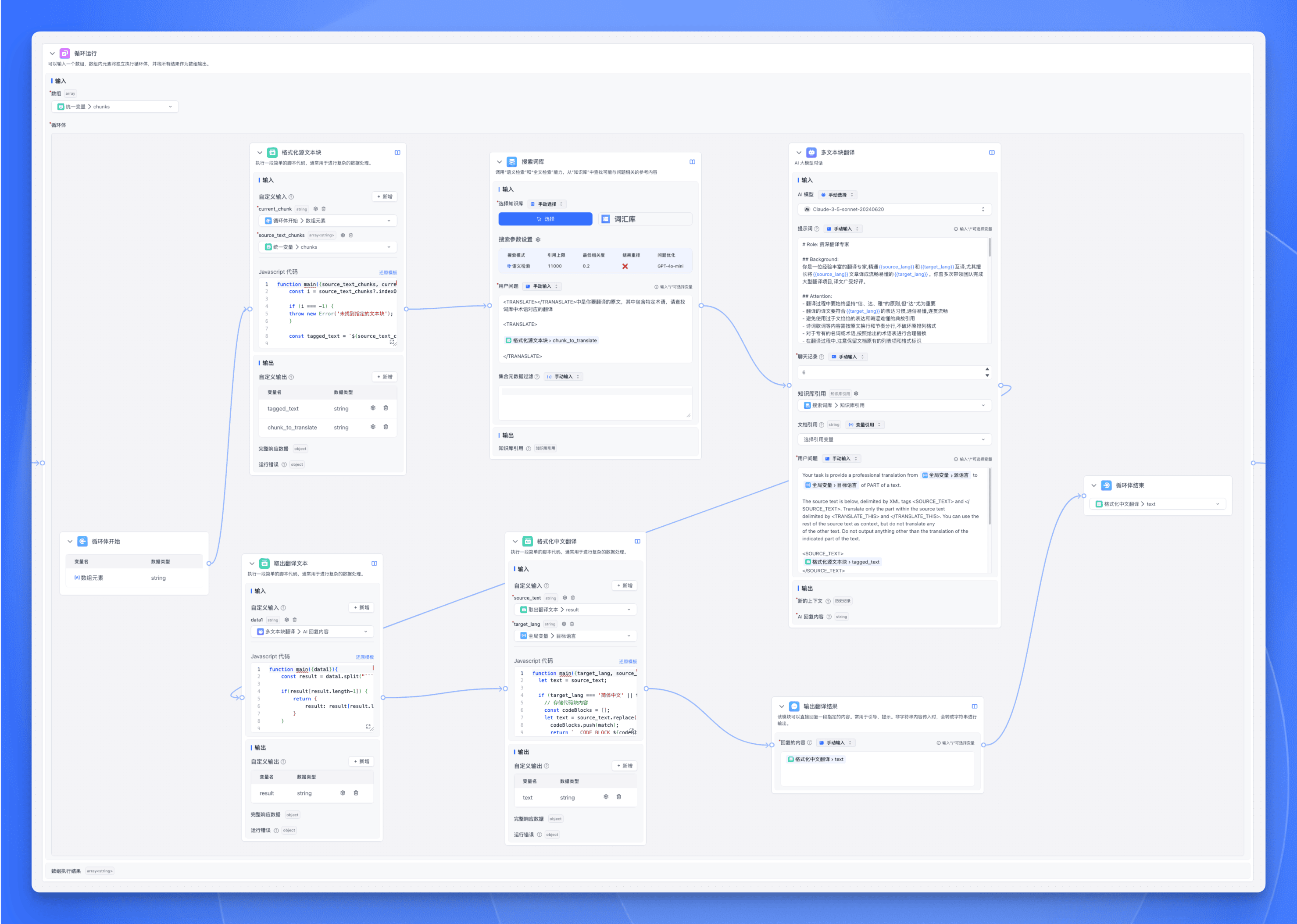
-
在循环体内部,可以添加任意类型的节点,如:
- AI 对话节点
- HTTP 请求节点
- 内容提取节点
- 文本加工节点等
-
循环体结束节点配置:
- 通过下拉菜单选择要输出的变量
- 该变量将作为当前循环的结果被收集
- 所有循环的结果将组成一个新的数组作为最终输出
场景示例
批量处理数组
假设我们有一个包含多个文本的数组,需要对每个文本进行 AI 处理。这是批量运行节点最基础也最常见的应用场景。
实现步骤
-
准备输入数组
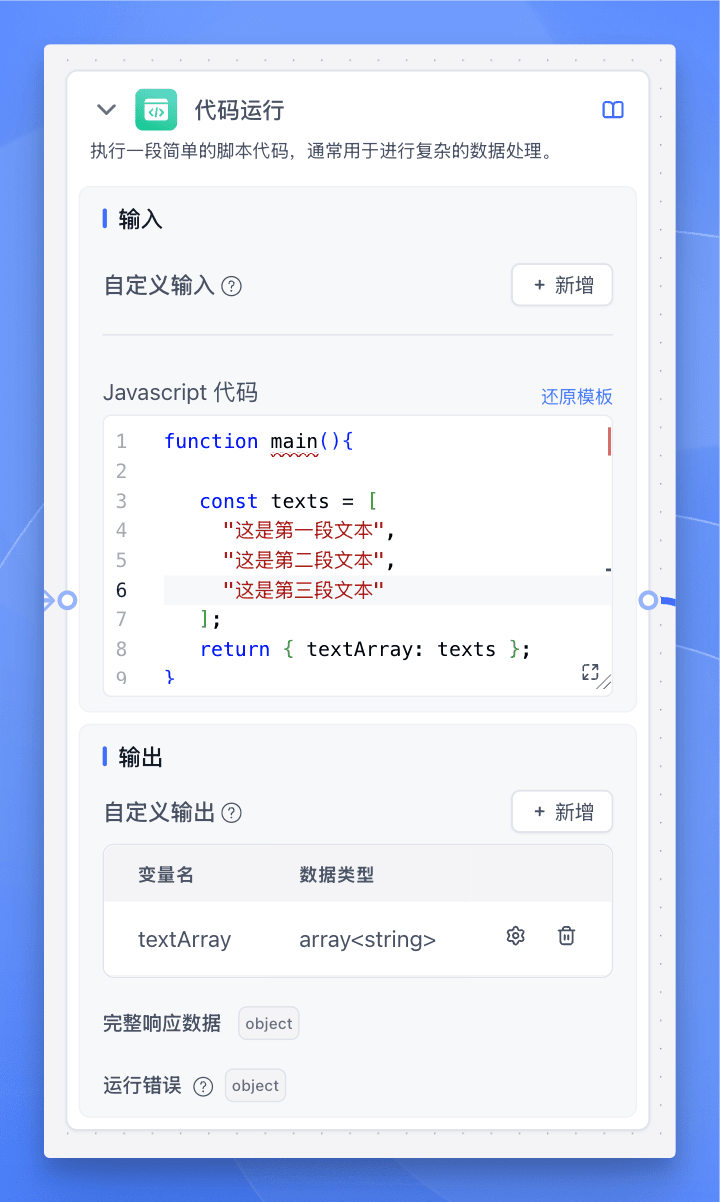
使用【代码运行】节点创建测试数组:
const texts = [ "这是第一段文本", "这是第二段文本", "这是第三段文本"];return { textArray: texts }; -
配置批量运行节点
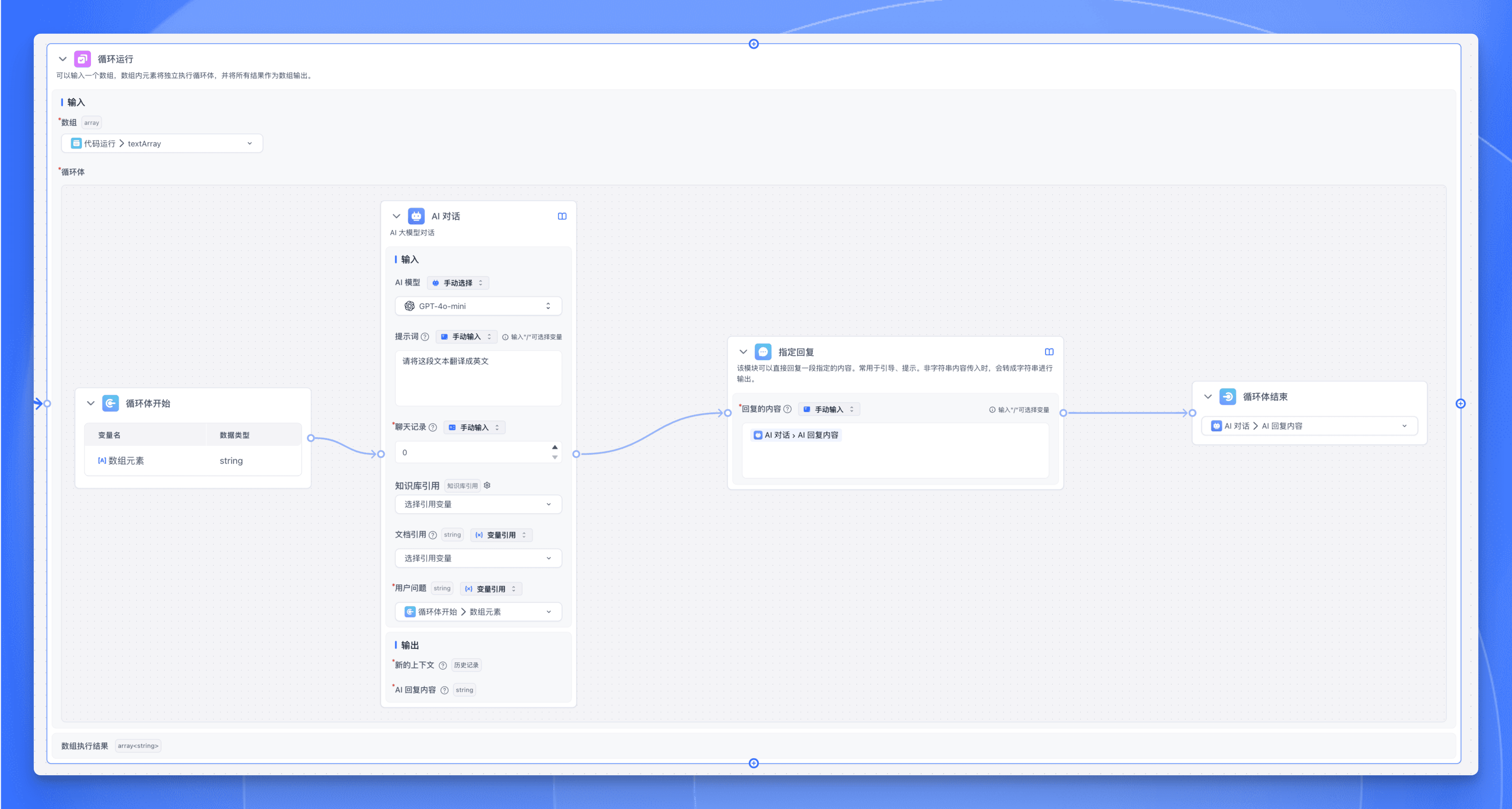
- 数组输入:选择上一步代码运行节点的输出变量
textArray。 - 循环体内添加一个【AI 对话】节点,用于处理每个文本。这里我们输入的 prompt 为:
请将这段文本翻译成英文。 - 再添加一个【指定回复】节点,用于输出翻译后的文本。
- 循环体结束节点选择输出变量为 AI 回复内容。
- 数组输入:选择上一步代码运行节点的输出变量
运行流程
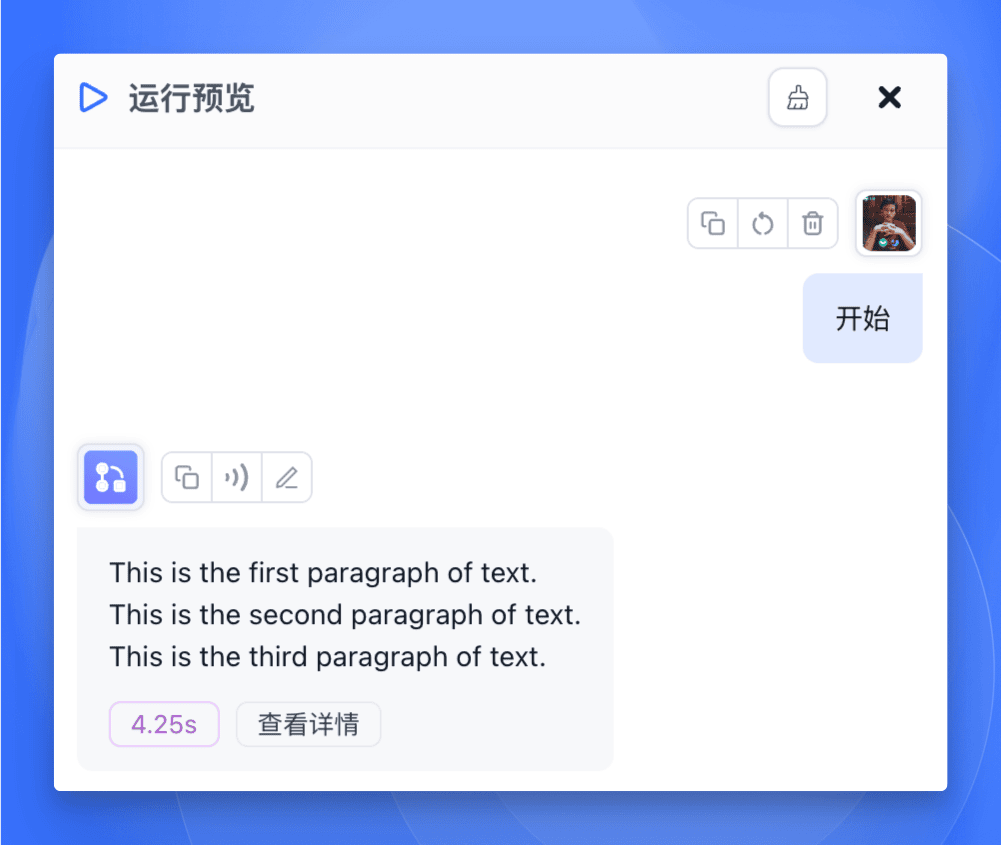
- 【代码运行】节点执行,生成测试数组
- 【批量运行】节点接收数组,开始遍历
- 对每个数组元素:
- 【AI 对话】节点处理当前元素
- 【指定回复】节点输出翻译后的文本
- 【循环体结束】节点收集处理结果
- 完成所有元素处理后,输出结果数组
长文本翻译
在处理长文本翻译时,我们经常会遇到以下挑战:
- 文本长度超出 LLM 的 token 限制
- 需要保持翻译风格的一致性
- 需要维护上下文的连贯性
- 翻译质量需要多轮优化
【批量运行】节点可以很好地解决这些问题。
实现步骤
-
文本预处理与分段
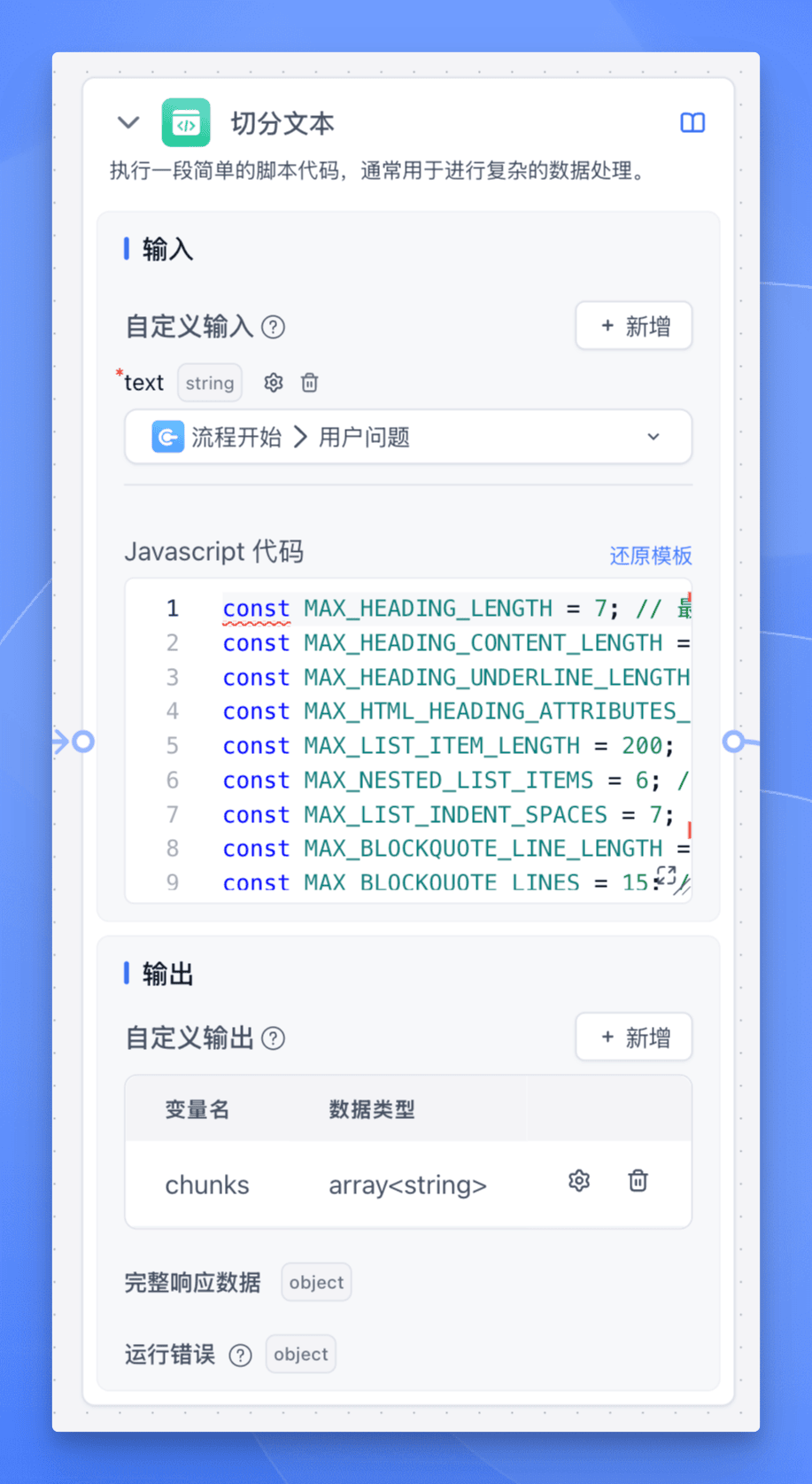
使用【代码运行】节点进行文本分段,代码如下:
const MAX_HEADING_LENGTH = 7; // 最大标题长度const MAX_HEADING_CONTENT_LENGTH = 200; // 最大标题内容长度const MAX_HEADING_UNDERLINE_LENGTH = 200; // 最大标题下划线长度const MAX_HTML_HEADING_ATTRIBUTES_LENGTH = 100; // 最大HTML标题属性长度const MAX_LIST_ITEM_LENGTH = 200; // 最大列表项长度const MAX_NESTED_LIST_ITEMS = 6; // 最大嵌套列表项数const MAX_LIST_INDENT_SPACES = 7; // 最大列表缩进空格数const MAX_BLOCKQUOTE_LINE_LENGTH = 200; // 最大块引用行长度const MAX_BLOCKQUOTE_LINES = 15; // 最大块引用行数const MAX_CODE_BLOCK_LENGTH = 1500; // 最大代码块长度const MAX_CODE_LANGUAGE_LENGTH = 20; // 最大代码语言长度const MAX_INDENTED_CODE_LINES = 20; // 最大缩进代码行数const MAX_TABLE_CELL_LENGTH = 200; // 最大表格单元格长度const MAX_TABLE_ROWS = 20; // 最大表格行数const MAX_HTML_TABLE_LENGTH = 2000; // 最大HTML表格长度const MIN_HORIZONTAL_RULE_LENGTH = 3; // 最小水平分隔线长度const MAX_SENTENCE_LENGTH = 400; // 最大句子长度const MAX_QUOTED_TEXT_LENGTH = 300; // 最大引用文本长度const MAX_PARENTHETICAL_CONTENT_LENGTH = 200; // 最大括号内容长度const MAX_NESTED_PARENTHESES = 5; // 最大嵌套括号数const MAX_MATH_INLINE_LENGTH = 100; // 最大行内数学公式长度const MAX_MATH_BLOCK_LENGTH = 500; // 最大数学公式块长度const MAX_PARAGRAPH_LENGTH = 1000; // 最大段落长度const MAX_STANDALONE_LINE_LENGTH = 800; // 最大独立行长度const MAX_HTML_TAG_ATTRIBUTES_LENGTH = 100; // 最大HTML标签属性长度const MAX_HTML_TAG_CONTENT_LENGTH = 1000; // 最大HTML标签内容长度const LOOKAHEAD_RANGE = 100; // 向前查找句子边界的字符数const AVOID_AT_START = `[\\s\\]})>,']`; // 避免在开头匹配的字符const PUNCTUATION = `[.!?…]|\\.{3}|[\\u2026\\u2047-\\u2049]|[\\p{Emoji_Presentation}\\p{Extended_Pictographic}]`; // 标点符号const QUOTE_END = `(?:'(?=\`)|''(?=\`\`))`; // 引号结束const SENTENCE_END = `(?:${PUNCTUATION}(?<!${AVOID_AT_START}(?=${PUNCTUATION}))|${QUOTE_END})(?=\\S|$)`; // 句子结束const SENTENCE_BOUNDARY = `(?:${SENTENCE_END}|(?=[\\r\\n]|$))`; // 句子边界const LOOKAHEAD_PATTERN = `(?:(?!${SENTENCE_END}).){1,${LOOKAHEAD_RANGE}}${SENTENCE_END}`; // 向前查找句子结束的模式const NOT_PUNCTUATION_SPACE = `(?!${PUNCTUATION}\\s)`; // 非标点符号空格const SENTENCE_PATTERN = `${NOT_PUNCTUATION_SPACE}(?:[^\\r\\n]{1,{MAX_LENGTH}}${SENTENCE_BOUNDARY}|[^\\r\\n]{1,{MAX_LENGTH}}(?=${PUNCTUATION}|$ {QUOTE_END})(?:${LOOKAHEAD_PATTERN})?)${AVOID_AT_START}*`; // 句子模式const regex = new RegExp( "(" + // 1. Headings (Setext-style, Markdown, and HTML-style, with length constraints) `(?:^(?:[#*=-]{1,${MAX_HEADING_LENGTH}}|\\w[^\\r\\n]{0,${MAX_HEADING_CONTENT_LENGTH}}\\r?\\n[-=]{2,${MAX_HEADING_UNDERLINE_LENGTH}}|<h[1-6][^>] {0,${MAX_HTML_HEADING_ATTRIBUTES_LENGTH}}>)[^\\r\\n]{1,${MAX_HEADING_CONTENT_LENGTH}}(?:</h[1-6]>)?(?:\\r?\\n|$))` + "|" + // New pattern for citations `(?:\\[[0-9]+\\][^\\r\\n]{1,${MAX_STANDALONE_LINE_LENGTH}})` + "|" + // 2. List items (bulleted, numbered, lettered, or task lists, including nested, up to three levels, with length constraints) `(?:(?:^|\\r?\\n)[ \\t]{0,3}(?:[-*+•]|\\d{1,3}\\.\\w\\.|\\[[ xX]\\])[ \\t]+${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String (MAX_LIST_ITEM_LENGTH))}` + `(?:(?:\\r?\\n[ \\t]{2,5}(?:[-*+•]|\\d{1,3}\\.\\w\\.|\\[[ xX]\\])[ \\t]+${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String (MAX_LIST_ITEM_LENGTH))}){0,${MAX_NESTED_LIST_ITEMS}}` + `(?:\\r?\\n[ \\t]{4,${MAX_LIST_INDENT_SPACES}}(?:[-*+•]|\\d{1,3}\\.\\w\\.|\\[[ xX]\\])[ \\t]+${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String (MAX_LIST_ITEM_LENGTH))}){0,${MAX_NESTED_LIST_ITEMS}})?)` + "|" + // 3. Block quotes (including nested quotes and citations, up to three levels, with length constraints) `(?:(?:^>(?:>|\\s{2,}){0,2}${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String(MAX_BLOCKQUOTE_LINE_LENGTH))}\\r?\\n?){1,$ {MAX_BLOCKQUOTE_LINES}})` + "|" + // 4. Code blocks (fenced, indented, or HTML pre/code tags, with length constraints) `(?:(?:^|\\r?\\n)(?:\`\`\`|~~~)(?:\\w{0,${MAX_CODE_LANGUAGE_LENGTH}})?\\r?\\n[\\s\\S]{0,${MAX_CODE_BLOCK_LENGTH}}?(?:\`\`\`|~~~)\\r?\\n?` + `|(?:(?:^|\\r?\\n)(?: {4}|\\t)[^\\r\\n]{0,${MAX_LIST_ITEM_LENGTH}}(?:\\r?\\n(?: {4}|\\t)[^\\r\\n]{0,${MAX_LIST_ITEM_LENGTH}}){0,$ {MAX_INDENTED_CODE_LINES}}\\r?\\n?)` + `|(?:<pre>(?:<code>)?[\\s\\S]{0,${MAX_CODE_BLOCK_LENGTH}}?(?:</code>)?</pre>))` + "|" + // 5. Tables (Markdown, grid tables, and HTML tables, with length constraints) `(?:(?:^|\\r?\\n)(?:\\|[^\\r\\n]{0,${MAX_TABLE_CELL_LENGTH}}\\|(?:\\r?\\n\\|[-:]{1,${MAX_TABLE_CELL_LENGTH}}\\|){0,1}(?:\\r?\\n\\|[^\\r\\n]{0,$ {MAX_TABLE_CELL_LENGTH}}\\|){0,${MAX_TABLE_ROWS}}` + `|<table>[\\s\\S]{0,${MAX_HTML_TABLE_LENGTH}}?</table>))` + "|" + // 6. Horizontal rules (Markdown and HTML hr tag) `(?:^(?:[-*_]){${MIN_HORIZONTAL_RULE_LENGTH},}\\s*$|<hr\\s*/?>)` + "|" + // 10. Standalone lines or phrases (including single-line blocks and HTML elements, with length constraints) `(?!${AVOID_AT_START})(?:^(?:<[a-zA-Z][^>]{0,${MAX_HTML_TAG_ATTRIBUTES_LENGTH}}>)?${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String (MAX_STANDALONE_LINE_LENGTH))}(?:</[a-zA-Z]+>)?(?:\\r?\\n|$))` + "|" + // 7. Sentences or phrases ending with punctuation (including ellipsis and Unicode punctuation) `(?!${AVOID_AT_START})${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String(MAX_SENTENCE_LENGTH))}` + "|" + // 8. Quoted text, parenthetical phrases, or bracketed content (with length constraints) "(?:" + `(?<!\\w)\"\"\"[^\"]{0,${MAX_QUOTED_TEXT_LENGTH}}\"\"\"(?!\\w)` + `|(?<!\\w)(?:['\"\`'"])[^\\r\\n]{0,${MAX_QUOTED_TEXT_LENGTH}}\\1(?!\\w)` + `|(?<!\\w)\`[^\\r\\n]{0,${MAX_QUOTED_TEXT_LENGTH}}'(?!\\w)` + `|(?<!\\w)\`\`[^\\r\\n]{0,${MAX_QUOTED_TEXT_LENGTH}}''(?!\\w)` + `|\\([^\\r\\n()]{0,${MAX_PARENTHETICAL_CONTENT_LENGTH}}(?:\\([^\\r\\n()]{0,${MAX_PARENTHETICAL_CONTENT_LENGTH}}\\)[^\\r\\n()]{0,$ {MAX_PARENTHETICAL_CONTENT_LENGTH}}){0,${MAX_NESTED_PARENTHESES}}\\)` + `|\\[[^\\r\\n\\[\\]]{0,${MAX_PARENTHETICAL_CONTENT_LENGTH}}(?:\\[[^\\r\\n\\[\\]]{0,${MAX_PARENTHETICAL_CONTENT_LENGTH}}\\][^\\r\\n\\[\\]]{0,$ {MAX_PARENTHETICAL_CONTENT_LENGTH}}){0,${MAX_NESTED_PARENTHESES}}\\]` + `|\\$[^\\r\\n$]{0,${MAX_MATH_INLINE_LENGTH}}\\$` + `|\`[^\`\\r\\n]{0,${MAX_MATH_INLINE_LENGTH}}\`` + ")" + "|" + // 9. Paragraphs (with length constraints) `(?!${AVOID_AT_START})(?:(?:^|\\r?\\n\\r?\\n)(?:<p>)?${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String(MAX_PARAGRAPH_LENGTH))}(?:</p>)?(?=\\r? \\n\\r?\\n|$))` + "|" + // 11. HTML-like tags and their content (including self-closing tags and attributes, with length constraints) `(?:<[a-zA-Z][^>]{0,${MAX_HTML_TAG_ATTRIBUTES_LENGTH}}(?:>[\\s\\S]{0,${MAX_HTML_TAG_CONTENT_LENGTH}}?</[a-zA-Z]+>|\\s*/>))` + "|" + // 12. LaTeX-style math expressions (inline and block, with length constraints) `(?:(?:\\$\\$[\\s\\S]{0,${MAX_MATH_BLOCK_LENGTH}}?\\$\\$)|(?:\\$[^\\$\\r\\n]{0,${MAX_MATH_INLINE_LENGTH}}\\$))` + "|" + // 14. Fallback for any remaining content (with length constraints) `(?!${AVOID_AT_START})${SENTENCE_PATTERN.replace(/{MAX_LENGTH}/g, String(MAX_STANDALONE_LINE_LENGTH))}` + ")", "gmu");function main({text}){ const chunks = []; let currentChunk = ''; const tokens = countToken(text) const matches = text.match(regex); if (matches) { matches.forEach((match) => { if (currentChunk.length + match.length <= 1000) { currentChunk += match; } else { if (currentChunk) { chunks.push(currentChunk); } currentChunk = match; } }); if (currentChunk) { chunks.push(currentChunk); } } return {chunks, tokens};}这里我们用到了 Jina AI 开源的一个强大的正则表达式,它能利用所有可能的边界线索和启发式方法来精确切分文本。
-
配置批量运行节点
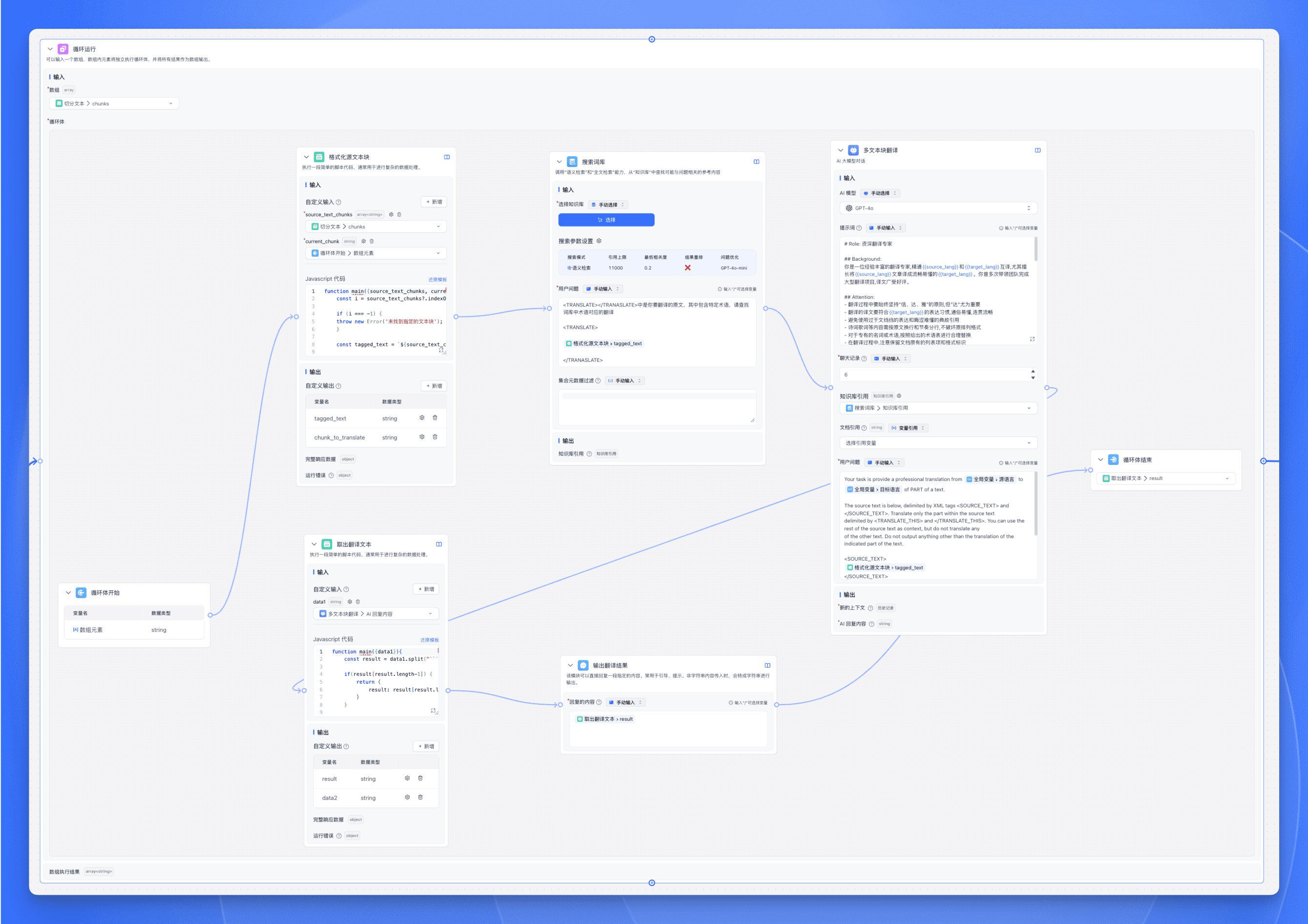
- 数组输入:选择上一步代码运行节点的输出变量
chunks。 - 循环体内添加一个【代码运行】节点,对源文本进行格式化。
- 添加一个【搜索词库】节点,将专有名词的词库作为知识库,在翻译前进行搜索。
- 添加一个【AI 对话】节点,使用 CoT 思维链,让 LLM 显式地、系统地生成推理链条,展示翻译的完整思考过程。
- 添加一个【代码运行】节点,将【AI 对话】节点最后一轮的翻译结果提取出来。
- 添加一个【指定回复】节点,输出翻译后的文本。
- 循环体结束节点选择输出变量为【取出翻译文本】的输出变量
result。
- 数组输入:选择上一步代码运行节点的输出变量
《CDA数据分析师技能树系列图书》系统整合数据分析核心知识,从基础工具(如Python、SQL、Excel、Tableau、SPSS等)到机器学习、深度学习算法,再到行业实战(金融、零售等场景)形成完整体系。书中结合案例讲解数据清洗、建模、可视化等技能,兼顾理论深度与实操性,帮助读者构建系统化知识框架。同时,内容紧跟行业趋势,涵盖大数据分析、商业智能、ChatGPT与DeepSeek等前沿领域,还配套练习与项目实战,助力读者将知识转化为职场竞争力,是数据分析师从入门到进阶的实用参考资料。



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献108条内容
已为社区贡献108条内容

所有评论(0)