FastGPT智能体开发:API 文件库功能介绍和使用方式
FastGPT API 文件库功能介绍和使用方式。
FastGPT API 文件库功能介绍和使用方式
|
|
|
背景
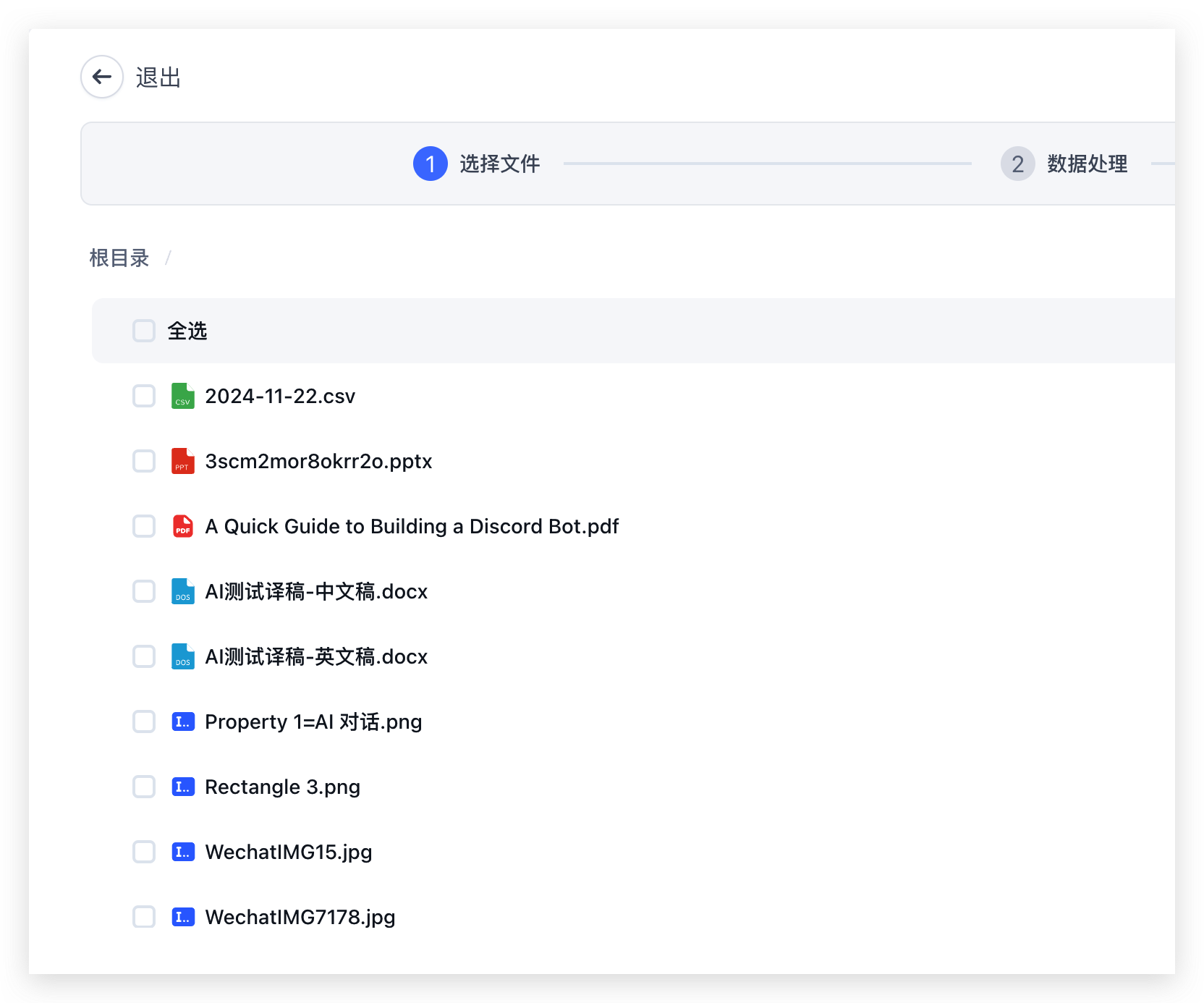
目前 FastGPT 支持本地文件导入,但是很多时候,用户自身已经有了一套文档库,如果把文件重复导入一遍,会造成二次存储,并且不方便管理。因为 FastGPT 提供了一个 API 文件库的概念,可以通过简单的 API 接口,去拉取已有的文档库,并且可以灵活配置是否导入。
API 文件库能够让用户轻松对接已有的文档库,只需要按照 FastGPT 的 API 文件库规范,提供相应文件接口,然后将服务接口的 baseURL 和 token 填入知识库创建参数中,就能直接在页面上拿到文件库的内容,并选择性导入
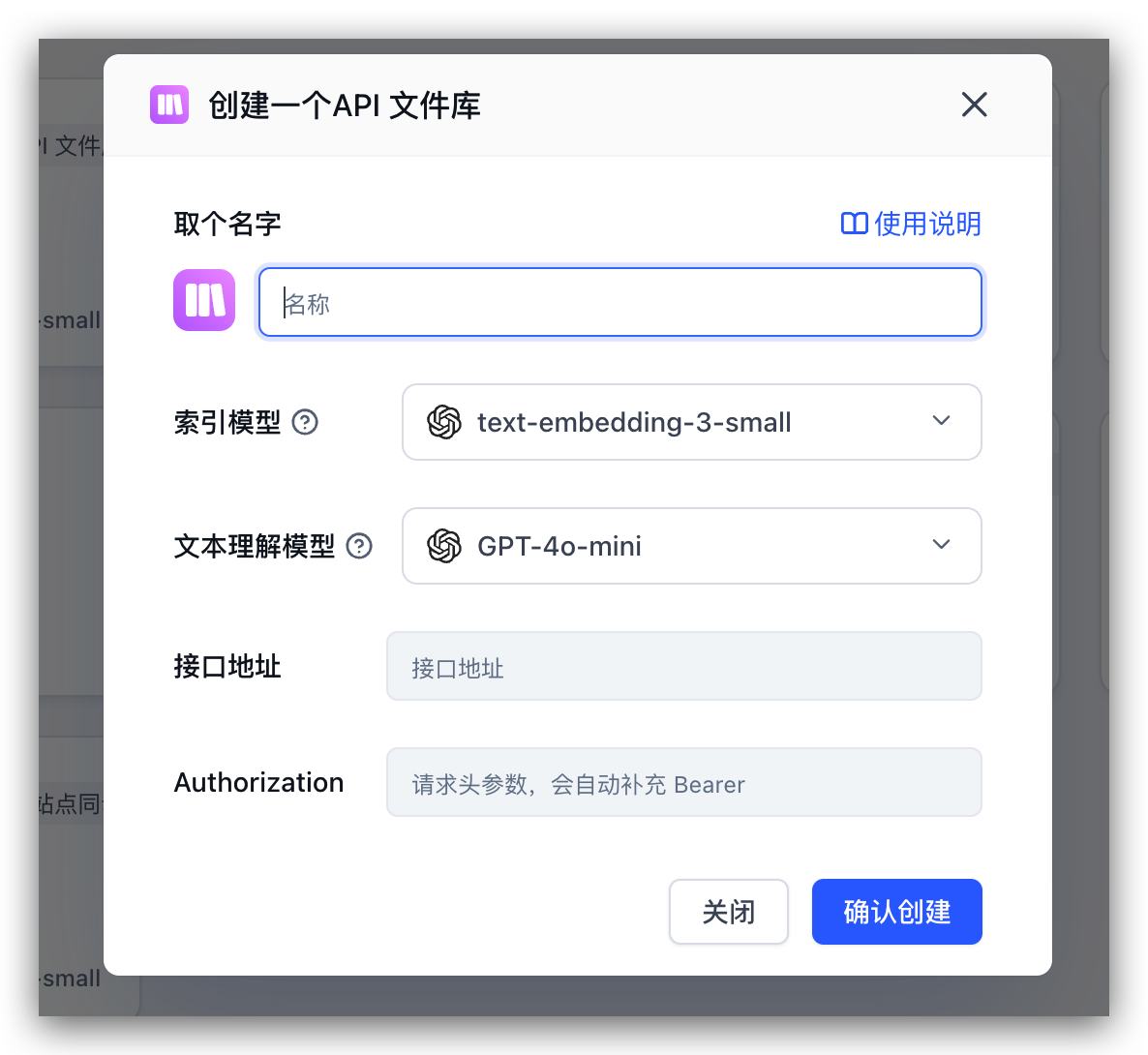
如何使用 API 文件库
创建知识库时,选择 API 文件库类型,然后需要配置两个关键参数:文件服务接口的 baseURL 和用于身份验证的请求头信息。只要提供的接口规范符合 FastGPT 的要求,系统就能自动获取并展示完整的文件列表,可以根据需要选择性地将文件导入到知识库中。
你需要提供两个参数:
- baseURL: 文件服务接口的 baseURL
- authorization: 用于身份验证的请求头信息,实际请求格式为
Authorization: Bearer <token>
接口规范
接口响应格式:
type ResponseType = { success: boolean; message: string; data: any;}数据类型:
// 文件列表中,单项的文件类型type FileListItem = { id: string; parentId: string | null; name: string; type: 'file' | 'folder'; updateTime: Date; createTime: Date;}1. 获取文件树
请求示例响应示例
- parentId - 父级 id,可选,或者 null。
- searchKey - 检索词,可选
curl --location --request POST '{{baseURL}}/v1/file/list' \--header 'Authorization: Bearer {{authorization}}' \--header 'Content-Type: application/json' \--data-raw '{ "parentId": null, "searchKey": ""}'2. 获取单个文件内容(文本内容或访问链接)
请求示例响应示例
curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \--header 'Authorization: Bearer {{authorization}}'3. 获取文件阅读链接(用于查看原文)
请求示例响应示例
id 为文件的 id。
curl --location --request GET '{{baseURL}}/v1/file/read?id=xx' \--header 'Authorization: Bearer {{authorization}}'《动手学PyTorch建模与应用:从深度学习到大模型》是一本从零基础上手深度学习和大模型的PyTorch实战指南。全书共11章,前6章涵盖深度学习基础,包括张量运算、神经网络原理、数据预处理及卷积神经网络等;后5章进阶探讨图像、文本、音频建模技术,并结合Transformer架构解析大语言模型的开发实践。书中通过房价预测、图像分类等案例讲解模型构建方法,每章附有动手练习题,帮助读者巩固实战能力。内容兼顾数学原理与工程实现,适配PyTorch框架最新技术发展趋势。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献108条内容
已为社区贡献108条内容

所有评论(0)