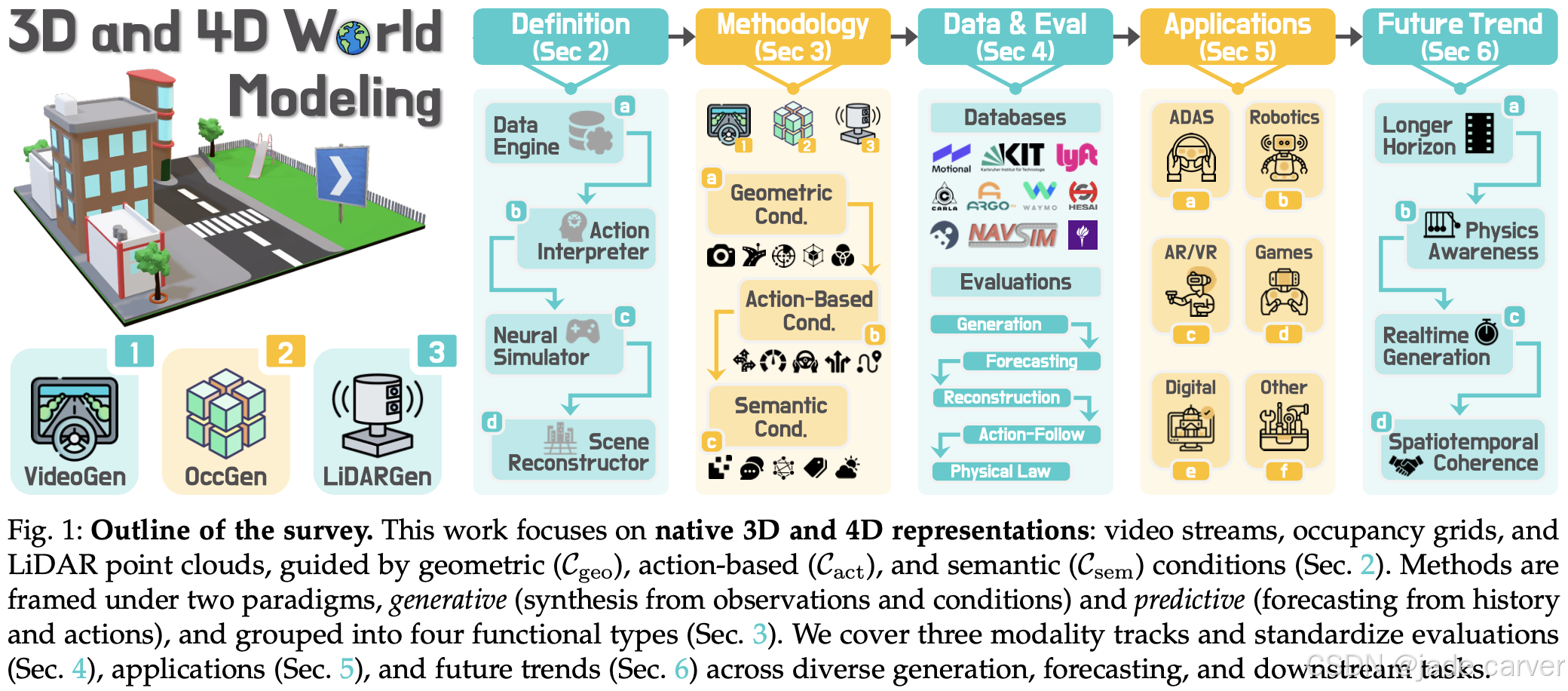
综述:3D and 4D World Modeling(method)
世界建模已成为人工智慧研究的基石,使智能体能够理解、表示并预测其所处的动态环境。以往的研究大多强调针对2D 图像和视频数据的生成式方法,却忽视了快速增长的、基于原生 3D 与 4D 表示(如 RGB-D 影像、占据网格、LiDAR 点云)的 大规模场景建模研究。与此同时,由于缺乏对“世界模型”的标准化定义与分类体系,现有文献中出现了零散甚至不一致的论述。本综述旨在填补这一空白,首次对3D 与 4D
本文翻译自:https://arxiv.org/abs/2509.07996 标题:3D and 4D World Modeling: A Survey 作者:Lingdong Kong∗,Wesley Yang∗,Jianbiao Mei∗,Youquan Liu∗,Ao Liang∗,Dekai Zhu∗,Dongyue Lu∗,Wei Yin∗,Xiaotao Hu, Mingkai Jia, Junyuan Deng, Kaiwen Zhang, Yang Wu, Tianyi Yan, Shenyuan Gao, Song Wang,Linfeng Li, Liang Pan, Yong Liu, Jianke Zhu, Wei Tsang Ooi, Steven C. H. Hoi, Ziwei Liu 许可:Deed - Attribution 4.0 International - Creative Commons

自动驾驶和具身智能领域的一篇3D和4D世界模型的综述,从三种世界模型出发:VideoGen、OccGen、LiDARGen,分别总结了相关的多种应用-数据工程、行为解释、神经模拟,感兴趣可以看看目前该领域的思维浪潮。
abstract
世界建模已成为人工智慧研究的基石,使智能体能够理解、表示并预测其所处的动态环境。以往的研究大多强调针对 2D 图像和视频数据 的生成式方法,却忽视了快速增长的、基于 原生 3D 与 4D 表示(如 RGB-D 影像、占据网格、LiDAR 点云)的 大规模场景建模研究。与此同时,由于缺乏对“世界模型”的 标准化定义与分类体系,现有文献中出现了零散甚至不一致的论述。
本综述旨在填补这一空白,首次对 3D 与 4D 世界建模与生成 进行全面梳理。我们给出精确的定义,并提出一个结构化的分类法,涵盖 基于视频的 (VideoGen)、基于占据的 (OccGen) 以及 基于 LiDAR 的 (LiDARGen) 方法。同时,我们系统总结了适用于 3D/4D 场景的数据集与评估指标。除此之外,还探讨了实际应用、指出了亟待解决的挑战,并展望了潜在的研究方向,力求为该领域的发展提供清晰且基础性的参考。
1 INTRODUCTION
世界建模是 AI 与机器人领域的核心任务,旨在让智能体能够理解、表征并预测动态环境。近年来,VAE、GAN、扩散模型、自回归模型等生成式技术推动了图像与视频等 2D 数据建模 的进步,但现实场景本质上存在于 3D 空间并具有时间动态,因此依赖 原生 3D 与 4D 表示(如 RGB-D、占据网格、LiDAR 点云及其时序形式)。这些模态提供了显式几何与物理约束,在自动驾驶与机器人等安全关键系统中不可或缺。
相较于传统的 2D 投影,3D/4D 数据天然编码了 度量几何、可见性与运动规律,有助于实现多视角一致性、刚体与非刚体运动学、遮挡推理以及拓扑约束,从而保证模型在 保真度、因果性与可控性 方面的可靠性。与此同时,相关研究还延伸至视频/全景/网格建模与对象中心的 3D 资产生成,它们在外观、拓扑与资产层面提供互补,而原生 3D/4D 模型则负责几何驱动的动态与交互。
然而,当前“世界模型”的定义仍然模糊,既有研究将其狭义理解为感知数据生成,也有研究扩展至预测、模拟与决策框架;现有综述大多偏向 2D 或视觉模态,导致缺乏统一框架与对 3D/4D 挑战的系统总结。为解决这一问题,本文贡献包括:
- 提出 精确定义,澄清“世界模型”与“3D/4D 世界建模”的概念;
- 构建 层次化分类体系,按表示模态划分为 VideoGen、OccGen、LiDARGen,并结合功能角色(数据引擎、动作解释器、神经模拟器、场景重建器);
- 系统整理了 数据集与评估协议,为未来基准测试提供支持。
从条件到功能。 当前的常见痛点是混淆“模型输入条件”与“模型功能”。本文将几何/动作/语义条件 (见表 1) 与功能类型明确区分,并依此建立分类:
- 数据引擎 (Data Engines):在 (
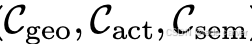 ) 下进行多样化场景合成;
) 下进行多样化场景合成; - 动作解释器 (Action Interpreters):基于历史与 Cact 进行预测;
- 神经模拟器 (Neural Simulators):支持策略闭环推演;
- 场景重建器 (Scene Reconstructors):从部分 3D/4D 观测中完成/迁移。
- 这种解耦使得不同方法能够在 保真度、一致性、可控性、可扩展性 维度上进行公平比较。
本文专注于 原生 3D 与 4D 表示 的世界建模,填补了以往综述的空白,并为开发健壮、可泛化的 3D/4D 生成模型提供了基础性参考。
结构安排
第 2 节介绍预备知识,包括核心概念、定义与生成范式;第 3 节提出新的层次化分类,细分 VideoGen、OccGen、LiDARGen,并对比其优劣;第 4 节总结常用数据集与评估指标,并回顾近期方法的基准表现;第 5 节探讨在自动驾驶、机器人与仿真等应用场景中的实践;第 6 节讨论主要挑战与未来研究方向;第 7 节总结全文。
2 PRELIMINARIES
在本节中,我们定义关键概念,并建立理解3D和4D世界建模所必需的统一数学符号。包括对关键表示的详细描述、生成和预测世界模型的定义以及模型分类。
2.1 3D and 4D Representations
为了系统分析 3D/4D 世界模型,首先需要明确其依赖的 场景表示,这些表示可作为输入、输出或生成预测过程中的中间状态,主要区别在于对 空间几何、时间动态与语义上下文 的刻画方式:

这些表示共同构成了 3D/4D 世界建模的核心支撑,分别在几何显式性、时间动态、物理一致性与渲染保真度之间提供不同权衡。
2.2 Definition of World Modeling in 3D and 4D
上述场景表示构成了 3D/4D 世界模型的结构基础,但在实际生成或预测时,往往需要 条件信号 (conditions) 来约束几何结构、描述智能体行为或定义语义目标。如表1所示,常见的条件可分为三类:
- 几何条件 (
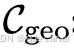 ):提供空间布局信息,如相机位姿、深度图、占据体素等;
):提供空间布局信息,如相机位姿、深度图、占据体素等; - 动作条件 (
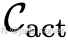 ):描述自车或智能体的运动,如轨迹、控制指令、导航目标;
):描述自车或智能体的运动,如轨迹、控制指令、导航目标; - 语义条件 (
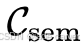 ):传递高层场景意图,如文本提示、场景图、环境属性。
):传递高层场景意图,如文本提示、场景图、环境属性。
这些条件既可以独立使用,也能组合使用,从而决定生成或预测场景的 真实感、可控性与多样性。
2.2.1 Model Definitions
根据建模目标,3D/4D 世界模型主要分为两种互补的范式:
(1)生成式世界模型 (Generative World Models)
从零或部分观测出发,在几何 (![]() )、动作 (
)、动作 (![]() )、语义 (
)、语义 (![]() ) 等多模态条件的引导下,合成合理的场景。形式化为:
) 等多模态条件的引导下,合成合理的场景。形式化为:
![]()
其中输入 ![]() 可为空、噪声、或部分表示(如视频片段、占据网格、LiDAR 数据),输出
可为空、噪声、或部分表示(如视频片段、占据网格、LiDAR 数据),输出 ![]() 为生成的 3D/4D 场景(视频序列、占据体素、LiDAR 扫描序列等)。
为生成的 3D/4D 场景(视频序列、占据体素、LiDAR 扫描序列等)。
(2)预测式世界模型 (Predictive World Models)
基于历史观测并结合动作条件 (![]() ),预测未来场景演化。形式化为:
),预测未来场景演化。形式化为:
![]()
-
其中
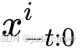 表示过去 t 步到当前的观测,输出
表示过去 t 步到当前的观测,输出 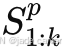 为未来 k 步的场景预测。
为未来 k 步的场景预测。
两者结合体现了世界模型的双重能力:既能 生成多样且可控的场景(想象力),也能 预测合理的未来演化(前瞻性)。
2.2.2 Model Categorizations
在生成与预测范式的基础上,现有方法可进一步划分为四种功能类型。这些方法的区别体现在:历史观测数据的利用方式、条件信号的性质(几何条件![]() 、动作条件
、动作条件![]() 、语义条件
、语义条件![]() ),以及其运行模式属于开环还是闭环设置。
),以及其运行模式属于开环还是闭环设置。
(1)数据工程(生成数据)

(2)行为解释器(状态自回归)

(3)神经模拟(状态交互模拟)
(4)3D/4D重建

这四大类别共同勾勒出三维/四维世界建模的功能版图。尽管其目标均在于生成物理与语义连贯的场景,但这些方法在历史观测数据运用方式、条件信号处理机制以及交互回路设计上存在显著差异——其应用范围涵盖大规模数据合成、策略评估、交互式仿真及场景复原等多个领域。
2.3 Generative Models
生成模型是 3D/4D 世界建模的算法核心,使智能体能够在多样条件下学习、想象与预测感知数据。它们支持合成真实且物理合理的场景,不同范式在 质量、可控性与效率 上各有权衡,主要包括:
1) 变分自编码器(VAE)

2) 生成对抗网络(GAN)

3) 扩散模型 / score-based 模型(Diffusion / Score-based)

4) 自回归模型(Autoregressive, AR)

这些生成范式构成了世界模型的基础,不同结构、训练稳定性与推理效率的差异直接决定了 3D 环境的合成、预测与控制方式。在迈向原生 3D/4D 场景时,这些权衡将进一步放大,因为 可扩展性、可控性与多模态整合 是构建可靠世界模型的关键。
3 METHODS: A HIERARCHICAL TAXONOMY
在本节中,我们根据现有的3D和4D世界建模方法的表示模式对其进行标准化和分类。这包括对基于视频生成的世界建模的描述和讨论(Sec.3.1),占用生成(Sec.3.2),以及激光雷达生成(Sec.3.3)模型。
3.1 World Modeling from Video Generation
基于视频的生成已经成为一种新的范式,提供视觉线索和时间动态来模拟复杂的现实世界场景。通过生成多视图或以自我为中心的视频序列,这些模型可以合成训练数据,预测未来结果,并创建交互式模拟环境。根据其主要功能,现有方法可以分为三类:数据引擎、动作解释器和神经模拟器。表2总结了这些领域下的现有模型。
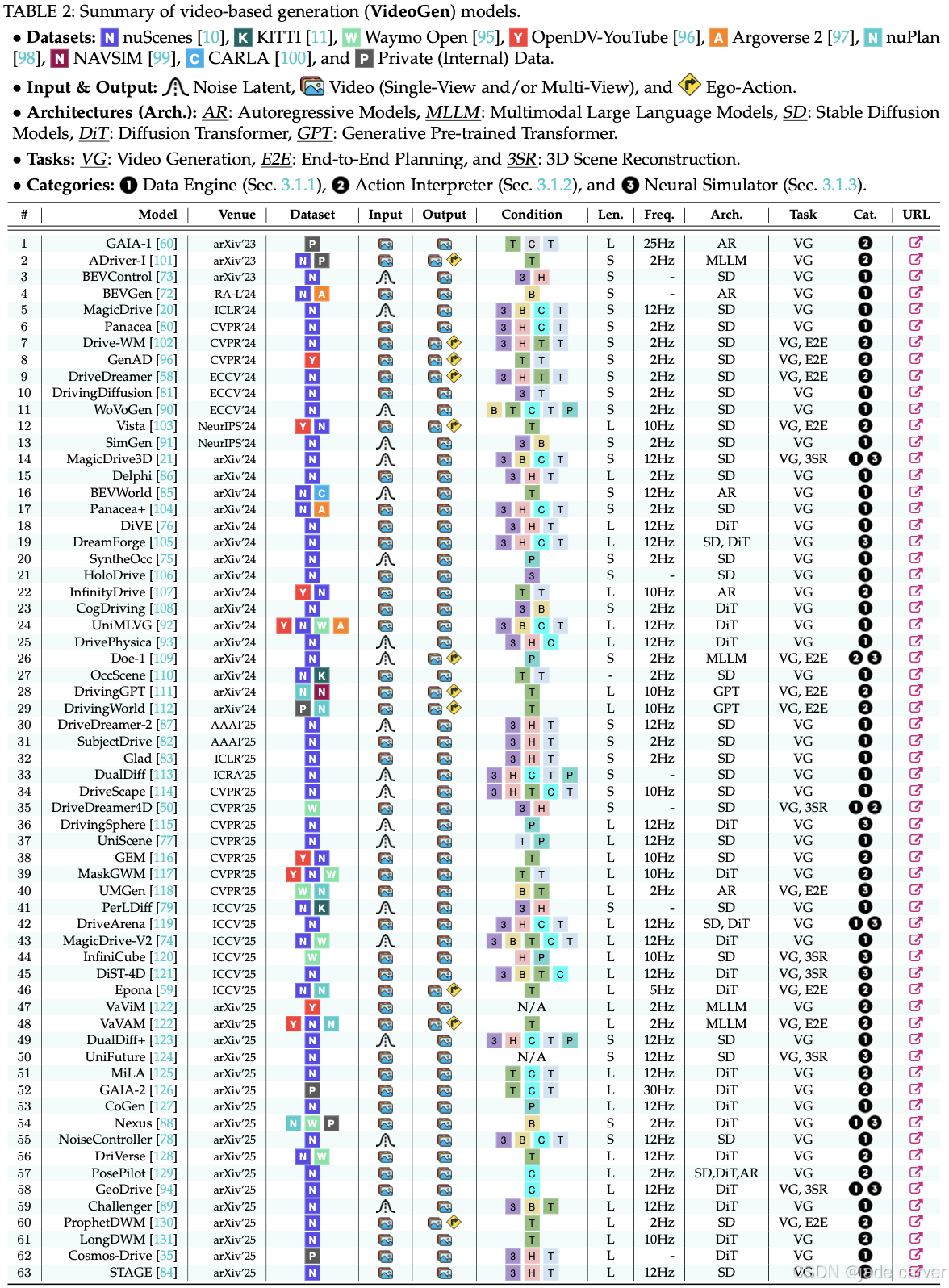
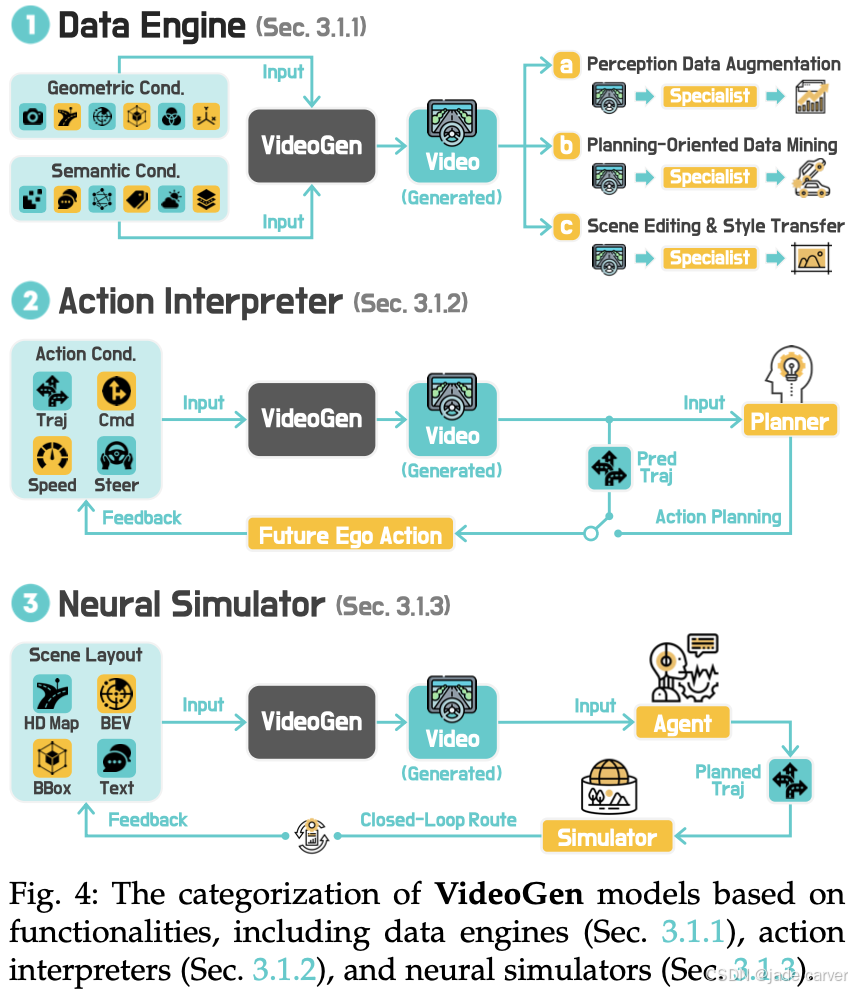
3.1.1 Data Engines
生成性3D数据引擎专注于生成多样化和可控制的驾驶场景,以支持感知、规划和模拟[20]、[72]、[73]、[74]、[75]、[76]、[77]、[78]。这个方向的研究涵盖了三个主要应用。
(1)感知数据增强
生成式场景合成缓解了现实世界数据稀缺的问题,并应对长尾感知挑战。早期工作集中于基于 BEV(鸟瞰视角,Bird’s Eye View)的真实街景。BEVGen [72] 使用自回归 Transformer 和跨视角变换来生成与给定 BEV 布局对齐的空间一致的周围图像。BEVControl [73] 侧重于利用扩散模型提升合成数据的质量,特别是在增强具有挑战性的长尾场景方面。随后,MagicDrive [20] 在驾驶场景生成和数据增强上取得了重要进展,它结合了 3D 几何和语义描述以及相机位姿来生成高保真图像。后续的工作引入了更精细的条件。例如,SyntheOcc [75] 使用 3D 语义多平面图像来实现全面、空间对齐的条件,PerLDiff [79] 提出了透视布局扩散模型,充分利用透视 3D 几何来增强真实感和一致性。
另一方面,Panacea [80]、DrivingDiffusion [81] 和 SubjectDrive [82] 引入了 4D 注意力、关键帧和主体控制,以改进 3D 可控多视角视频的时序一致性和数据多样性。NoiseController [78] 提出了多层级噪声分解和多帧协同去噪,以增强时空一致性。对于长时序视频生成,DiVE [76]、MagicDrive-V2 [74] 和 Cosmos-Drive [35] 利用 DiT(Diffusion Transformer)的灵活性和可扩展性来生成更长的视频。Glad [83] 使用潜变量传播,STAGE [84] 采用层次化时序特征传递,以流式方式生成长视频。其他方法如 UniScene [77] 和 BEVWorld [85] 则探索多模态数据合成,以拓展应用,支持利用多模态信息的下游感知任务。
这些进展通过提供多样化、可控、长时序的训练数据,捕捉现实世界的多样性,从而支持稳健且可扩展的自动驾驶感知系统。
(2)规划导向的数据挖掘
除了感知之外,数据引擎还会挖掘稀有和安全关键场景,用于规划。Delphi [86] 提出了一个基于扩散的长视频生成框架,并采用失败案例驱动的方法,利用预训练视觉语言模型来合成类似失败场景的数据,从而提升端到端自动驾驶系统的样本效率和规划性能。DriveDreamer-2 [87] 将用户查询转化为智能体轨迹,然后利用这些轨迹生成符合交通规则的高精地图(HDMaps),用于角落案例(corner case)的生成。Nexus [88] 从细粒度 token 与独立噪声状态中模拟常规和具有挑战性的场景,以提升反应能力和目标条件控制,并收集了一个专门的角落案例数据集,用于补充挑战性场景生成。Challenger [89] 利用物理感知的多轮轨迹优化来识别对抗性操作,并采用定制化的评分函数来促进既真实又具有挑战性的行为,这些行为能够与下游视频合成相兼容。
(3)场景编辑与风格迁移
许多现有方法 [80], [90], [91] 也利用世界模型进行场景编辑和风格迁移,以丰富自动驾驶仿真与数据增强的工具箱。早期方法主要依赖场景描述 [20] 或参考图像 [92] 来进行基本的外观修改(如天气、光照),并借助边界框或高精地图 [73] 来进行元素级别的调整。然而,较新的方法探索了更丰富的表示形式,以实现更精确的场景操控和更丰富的外观控制。WoVoGen [90] 通过世界体积感知的合成来确保跨传感器一致性,SyntheOcc [75] 使用占据网格来实现遮挡感知的场景编辑。SimGen [91] 通过基于模拟器条件的级联扩散来弥合仿真与现实的差距,DrivePhysica [93] 则利用 CARLA 模拟复杂驾驶场景(如加塞),并引入运动表示学习和实例流引导,以保证时序一致性。与此相辅相成,GeoDrive [94] 融合了显式 3D 几何条件和动态编辑,实现了交互式轨迹与物体操作。
3.1.2 行为解释器(Action Interpreters)
基于动作驱动的生成模型通过动作引导的世界生成和预测驱动的动作规划,在智能体意图与环境动态之间建立联系,从而实现结果预判,并通过将控制映射到合理的未来场景,统一低层次操作与高层推理。
(1)动作引导的视频生成(Action-Guided Video Generation)
基于动作条件的生成模型,使智能体能够根据预期动作预测未来结果,有效地将低层次的控制输入与高保真视频展开的合理未来联系起来。GAIA-1 [60] 首次提出了一个生成模型,将视频、文本和动作输入融合,用于合成逼真的驾驶场景,并能够对自车行为和场景属性进行细致控制。GAIA-2 [126] 将这一框架扩展到包括智能体配置、环境因素和道路语义。GenAD [96] 进一步提升了泛化能力,发布了 OpenDV 数据集,并提出了一个预测模型,支持零样本、语言与动作条件下的预测。Vista [103] 将稳健的动作条件生成应用于多样场景,GEM [116] 能够输出多模态结果,并实现精确的自车运动控制,MaskGWM [117] 通过基于掩码的扩散方法提升了合成的保真度与长时序预测能力。为解决长视频生成中的误差累积问题,InfinityDrive [107] 与 Epona [59] 分别提出了记忆注入与前向链式训练策略。此外,DrivingWorld [112] 能够根据预定义轨迹生成场景,作为一种神经驾驶模拟器。其他方法如 DriVerse [128]、MiLA [125]、PosePilot [129] 和 LongDWM [131] 则关注于轨迹对齐、时序稳定性、姿态可控性以及无深度引导的生成。总体来看,这些进展推动了动作条件生成在精确性、时序一致性和鲁棒性上的发展。
(2)预测驱动的动作规划(Forecasting-Driven Action Planning)
另一类研究通过当前观测与自车动作来预测未来状态,使得规划器能够在真正执行之前评估结果 [132]–[134]。与纯反应式方法不同,这类方法强调 预判性决策,使智能体能够在虚拟环境中“测试”多种未来,从而避免在真实世界中进行不安全的试错。DriveWM [102] 通过生成候选动作的视频展开,并利用基于图像的奖励对轨迹进行打分。DriveDreamer [58] 提出了 ActionFormer,用于预测未来状态和自车-环境交互。ADriver-I [101] 将多模态大语言模型与自回归控制信号及世界演化预测相结合。Vista [103] 引入了不确定性感知的奖励模块,以实现稳健的动作评估。类似 GPT 的设计,如 DrivingGPT [111] 与 DrivingWorld [112],将视觉和动作 token 联合建模,通过下一个 token 预测来进行规划。集成框架如 Doe-1 [109] 将感知、预测和规划统一起来,实现闭环自动驾驶,而 VaVAM [122] 则将视频扩散与动作专家结合,用于决策。ProphetDWM [130] 进一步将潜在动作学习与状态预测耦合,用于长时序规划。总体而言,通过模拟多样化未来并利用反馈,预测驱动模型提升了端到端自动驾驶的泛化能力与安全性。
3.1.3 神经模拟器(Neural Simulators)
闭环模拟器可以生成逼真的虚拟世界,支持高效的规划、决策与交互。根据场景建模方法的不同,近期方法大致可以分为两类。
(1)生成驱动的模拟(Generation-Driven Simulation)
近年来,自动驾驶的生成式模拟器利用条件生成框架 [8], [135], [136] 创建可交互的高保真环境。DriveArena [119] 通过两个核心组件建立了第一个闭环框架:TrafficManager 用于可扩展交通生成,WorldDreamer 用于自回归场景生成。在此基础上,DreamForge [105] 通过引入对象级位置编码和新颖的时间注意力机制,加强了长期场景建模能力。进一步扩展功能的 DrivingSphere [115] 引入 4D 语义占据建模(4D semantic occupancy modeling),统一了静态环境与动态对象,并结合视觉合成模块保证多视角视频生成中的时空一致性。UMGen [118] 模拟自车与用户定义智能体之间的行为交互,而 Nexus [88] 根据智能体决策动态更新环境,并通过 nuPlan 闭环基准进行严格验证。GeoDrive [94] 通过几何感知场景建模与精确控制模块,提升 VLA 系统(Vision-Latent-Action 系统)的轨迹优化能力。总体而言,这些进展使生成式模拟从被动环境渲染转向能够进行智能体交互和反馈驱动自适应的闭环系统。
(2)重建驱动的模拟(Reconstruction-Centric Simulation)
基于重建的模拟器采用神经场景重建技术(如 NeRF [137] 和 3DGS [138]),将驾驶日志转化为可交互的神经环境 [110], [139]–[153]。例如,StreetGaussian [154] 将动态城市街景表示为一组点云,每个点云包含语义 logits 和 3D 高斯分布,分别对应前景车辆或背景。其他关键实现包括 HUGSIM [155],将物理约束与 3D GS 相结合,用于生成激进驾驶行为;以及 UniSim [77] 和 UniGaussians [156],通过高斯基元蒸馏生成同步的多模态传感器输出。OmniRe [157] 进一步通过神经场景图(neural scene graph)提升动态实体建模能力。
尽管传统的 3D GS 方法 [21], [120], [124], [154], [158] 在视角外推时存在伪影问题,最新方案通过将 3D 场景生成模型作为数据基础来增强重建鲁棒性。ReconDreamer [159] 采用渐进精炼方法消除动态场景中的重影效果,而 Stage-1 [160] 通过多视角点云补全实现可控的 4D 合成。这些建模方法以及相关增强技术 [50], [121], [159], [161], [162] 在处理新颖视角时取得显著提升,有效缩小了模拟环境与真实环境之间的保真度差距。
3.2 World Modeling from Occupancy Generation
基于占用网格的生成模型,以提供以几何为中心的表示,对3D世界的语义和结构细节进行编码。通过生成、预测或模拟3D/4D空间的占用率,这些模型为感知提供了一个几何一致的支架,实现了与动作有关的未来预测,并支持现实的大规模模拟。根据其主要功能,现有方法可以分为三类:场景代表、占用预测和自回归模拟器。表3总结了这些领域下的现有模型。
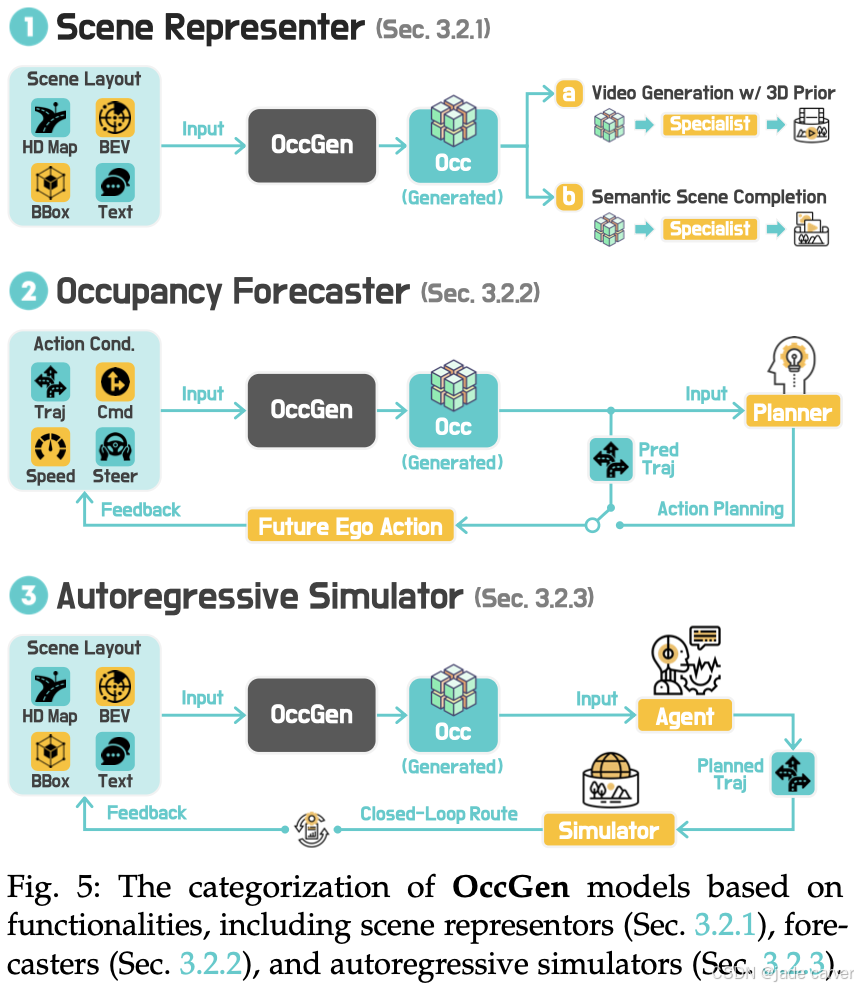
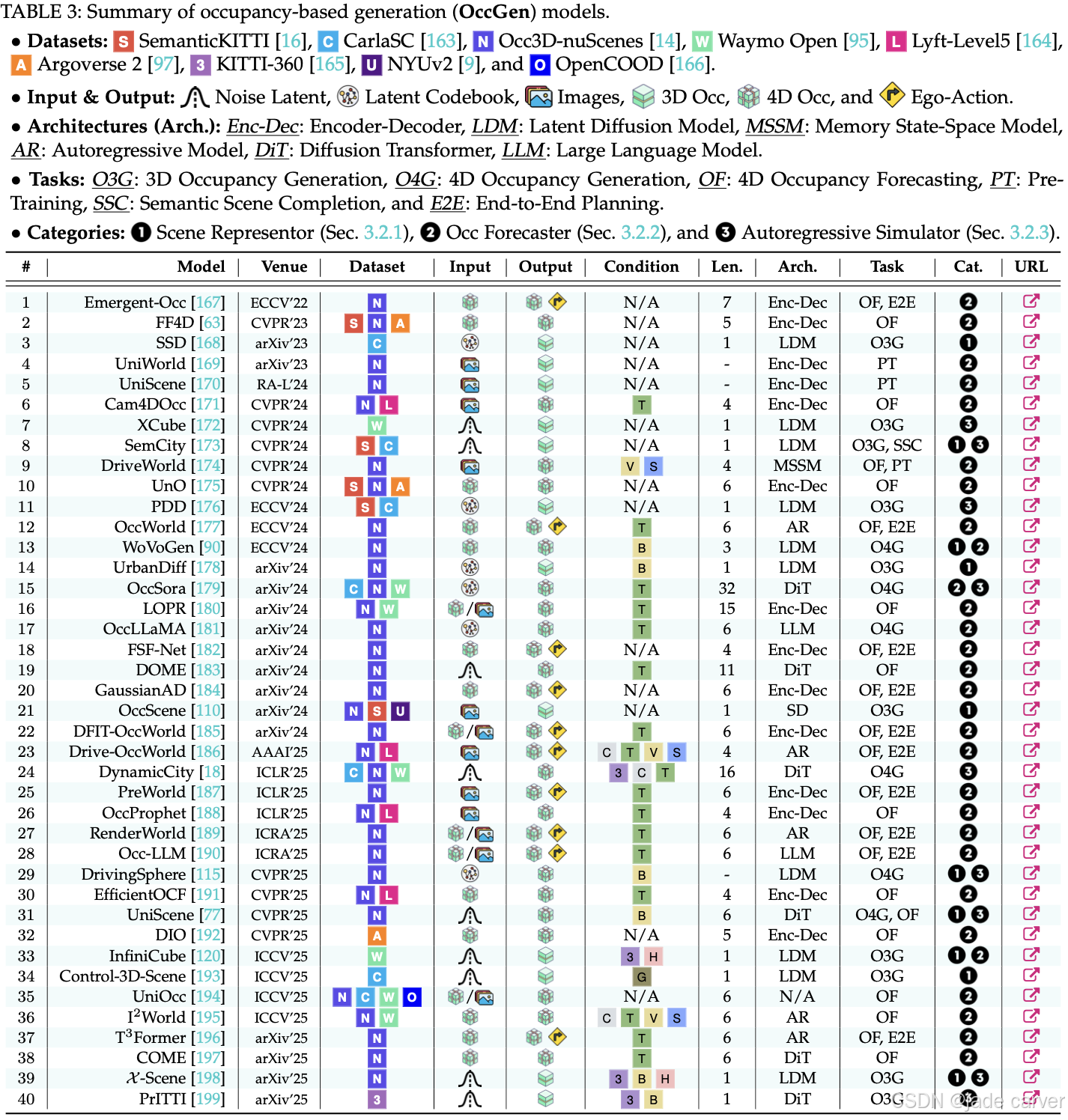
3.2.1 场景表示器(Scene Representors)
基于占据格(occupancy-based)的 3D 和 4D 生成模型旨在学习结构化的 3D 场景表示,将占据格视为几何一致的中间表示,用于下游任务。这一范式不仅提升了感知的鲁棒性,还为 3D 场景生成提供了结构指导,主要体现在两个应用方向。
(1)3D 感知鲁棒性增强(3D Perception Robustness Enhancement)
基于占据格的表示作为中间模态,通过生成式建模技术显著增强了感知鲁棒性。SSD [168] 首开先例,采用离散 [200] 和潜变量扩散 [135] 模型生成场景级 3D 分类数据,学习将稀疏的占据输入映射为稠密的语义重建。SemCity [173] 进一步提升了几何和语义保真度,通过将扩散模型条件化在初始 SSC 输出上,减少了重建场景中的不一致性。
(2)生成一致性引导(Generation Consistency Guidance)
其他研究利用占据格来指导高保真、时序一致的场景合成。WoVoGen [90] 提出了 4D 时间占据体(temporal occupancy volumes),驱动多视角视频生成,同时保证世界内部和传感器间的一致性。UrbanDiff [178] 使用语义占据格作为几何先验,实现 3D 感知的图像合成;DrivingSphere [115] 将动态的 4D 占据场景转换为时序一致的视频,通过语义渲染实现。UniScene [77] 将基于占据格的生成方法推广到多模态,结合基于高斯的渲染 [138] 与先验引导的稀疏建模,实现视频与 LiDAR 的统一生成。
总体而言,这些方法凸显了占据格作为统一结构先验的作用,可生成空间和时间上一致、具有高结构保真的输出。
3.2.2 占据预测器(Occupancy Forecasters)
用于 4D 占据预测的模型能够根据自车动作和过去观测预测未来占据状态,从而预判环境变化。这一能力主要有两个用途:一是作为自监督预训练任务,用于构建可泛化的 3D/4D 模型;二是作为动态预测器,实现行为感知且可控的未来场景生成。
(1)预测模型预训练(Predictive Model Pretraining)
多种方法将占据预测作为预任务,通过 LiDAR 序列学习丰富的时空特征,从而以自监督方式构建可泛化的生成模型。Emergent-Occ [63], [167] 引入可微分渲染,将 4D 占据预测转化为点云重建,实现从原始序列的自监督训练。UnO [175] 模拟连续 4D 占据场,用于联合感知与预测。大型预训练框架如 UniWorld [169]、UniScene [170]、DriveWorld [174] 将图像和 LiDAR 数据结合,学习基础的占据模型,可在下游任务(如检测与规划)中进行微调,从而降低对密集标签的依赖,同时提升泛化能力。
(2)自车条件占据预测(Ego-Conditioned Occupancy Forecasting)
另一类方法基于历史观测和自车动作条件预测占据状态,支持行为感知和可控预测。OccWorld [177] 在 3D 占据空间中联合建模自车运动和周围环境演化;OccSora [179] 则生成基于轨迹条件的长时序 4D 占据场。后续工作进一步提升了可控性 [183], [197]、保真度 [185]、时序一致性 [182], [184], [192] 和计算效率 [196]。以视觉为中心的流水线,如 Cam4DOcc [171] 及其后续工作 [186], [189],将世界模型整合到端到端规划中,增强生成能力。OccLLaMA [181] 与 Occ-LLM [190] 将视觉、语言与动作模态统一,使用语义占据作为共享表示,以支持具身问答(embodied QA)。UniOcc [194] 构建了一个结合真实与模拟数据的标准化评估基准。
综上,这些研究将占据预测不仅视为一种强大的自监督学习目标,也作为建模动态、基于动作的世界状态的重要工具。
3.2.3 自回归模拟器(Autoregressive Simulators)
基于占据格的自回归模拟器可以生成大规模、时序一致的 4D 占据,用于逼真且可交互的模拟。这类模拟器作为感知、规划和决策的基础环境,其研究主要集中在两个方向:可扩展的无限环境生成和长时序动态建模以实现可控闭环模拟。
(1)可扩展开放世界生成(Scalable Open-World Generation)
研究者探索了粗到细(coarse-to-fine)和外延生成(out-painting)策略,以构建大规模、无限制的 3D 占据环境。PDD [176] 提出了一种尺度变化的扩散框架,从粗略布局逐步生成户外场景到精细细节。XCube [172] 采用基于体素(voxel)的层次化潜变量扩散进行多分辨率生成。SemCity [173] 增加了场景编辑功能,InfiniCube [120] 和 X-Scene [198] 将体素占据与一致的视觉合成结合,构建逼真且可编辑的模拟世界。总体而言,这些工作构建了可扩展的占据格表示,为具身智能体提供交互式和可扩展的环境。
(2)长时序动态模拟(Long-Horizon Dynamic Simulation)
另一类研究关注自回归 4D 占据生成,用于模拟动态世界演化。OccSora [179] 能生成基于轨迹条件的 16 秒长序列;DynamicCity [18] 支持布局感知和指令条件生成,实现可控的场景合成和智能体交互。DrivingSphere [115]构建包含静态背景和动态对象的 4D 世界,用于闭环模拟;UniScene [77] 生成基于布局条件的 4D 占据,具有丰富的语义和几何细节。这些方法将空间结构与时序一致性相结合,创建逼真且可控的环境,用于具身智能体的模拟与决策。
3.3 World Modeling from LiDAR Generation
基于激光雷达的生成模型通过从点云中建模复杂场景,提供几何感知和外观不变的表示。它们实现了强大的3D场景理解和高保真几何模拟,在几何保真度和环境稳健性方面都比基于图像和占用的方法具有优势。根据其主要功能,这些方法可以分为三类:数据引擎、动作解释器和自回归模拟器。表4总结了这些领域下的现有模型。
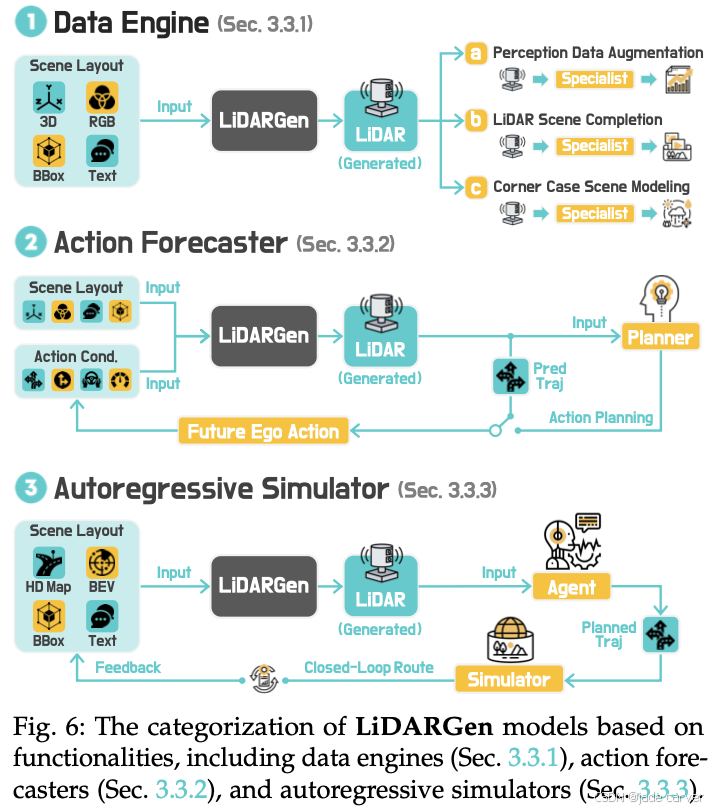
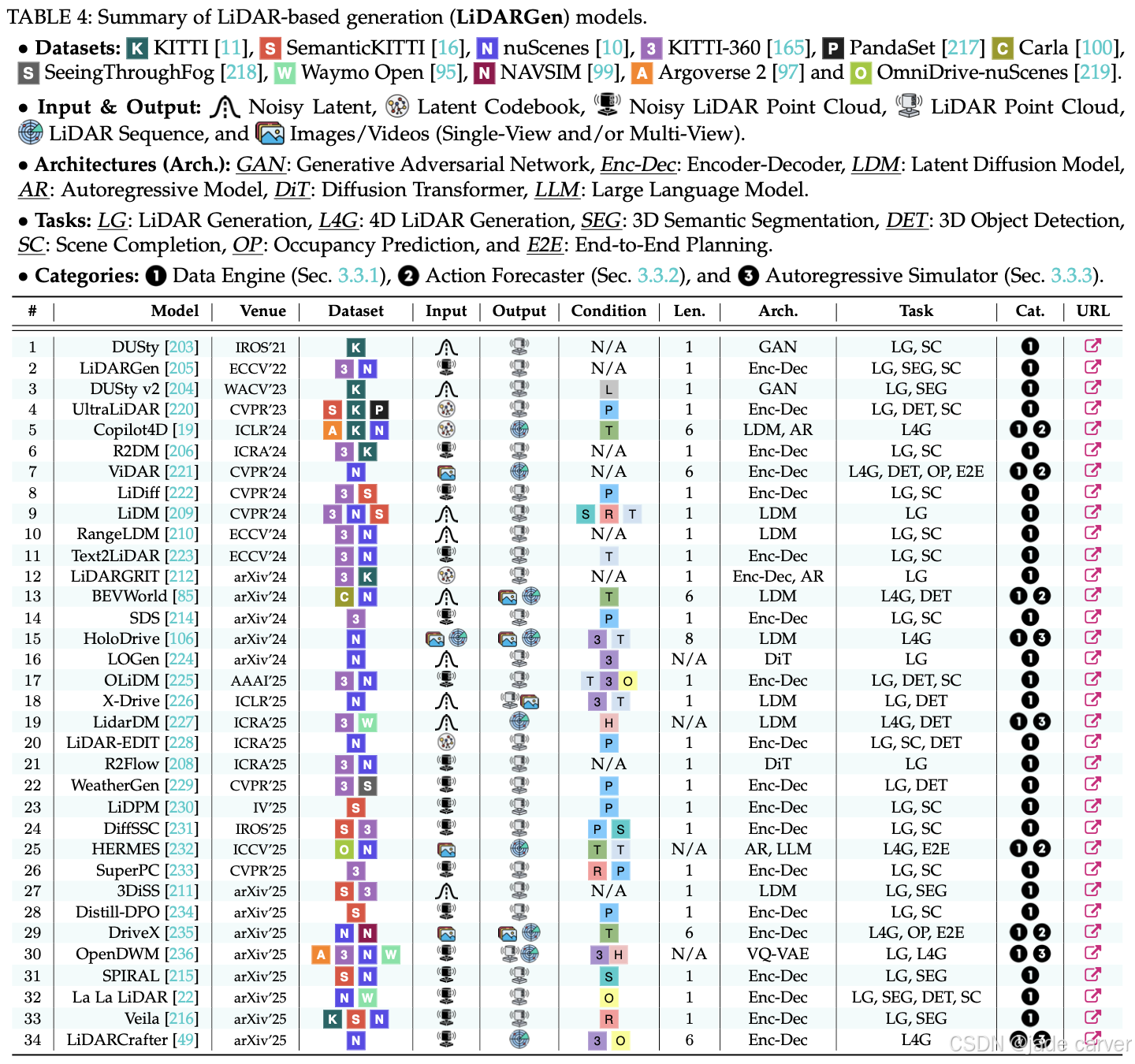
3.3.1 数据引擎(Data Engines)
基于 LiDAR 的数据引擎旨在缓解大规模 LiDAR 训练数据的稀缺性问题,因为获取成本高、标注困难。通过生成多样且可控的点云 [201], [202],这些模型不仅提升感知鲁棒性,还能实现几何精确的场景补全,并支持稀有或跨模态场景的合成 [49]。近期研究主要集中在四大应用方向。
(1)感知数据增强(Perception Data Augmentation)
基于 LiDAR 的生成建模可用于核心 3D 感知任务(如检测和分割)的数据增强,重点在于几何保真度和传感器真实性。早期方法主要关注不确定性和空间结构建模,以合成逼真的 LiDAR 扫描。

(2)场景补全(Scene Completion)
3D 场景补全旨在从稀疏或遮挡的 LiDAR 扫描重建稠密、连贯的 3D 几何,最近的生成方法提升了几何保真度与可控性。

(3)稀有条件建模(Rare Condition Modeling)
为提升恶劣环境下的 3D 感知鲁棒性,近期方法探索可控 LiDAR 生成,用于安全关键场景。

(4)多模态生成(Multimodal Generation)
近期方法还探索多模态生成,通过合成对齐的 LiDAR 与图像数据。X-Drive [226]:双分支扩散架构,同时生成对齐的 LiDAR 点云和多视角相机图像,引入跨模态极线条件模块,提高点云与图像一致性,并支持基于文本、对象边界框或传感器数据的可控 3D 场景生成。
3.3.2 动作预测器(Action Forecasters)
(1)时序建模(Temporal Modeling)
Copilot4D [19] 提出了一种可扩展的世界模型构建方法,核心包括:利用 VQ-VAE [213] 对复杂、非结构化的点云输入进行离散化编码(tokenize);将 Masked Generative Image Transformer [240] 重新设计为离散扩散模型,实现并行去噪和解码。Copilot4D 的输入为过去 1–3 秒的 LiDAR 帧以及未来自车动作(姿态),可预测接下来 1–3 秒的高质量 LiDAR 帧ViDAR [221] 以历史摄像头帧为输入,预测未来 LiDAR 帧输出,同时支持感知、预测和规划等任务的预训练。
(2)多模态动作预测器(Multi-Modal Action Forecasters)
BEVWorld [85] 引入多模态 tokenizer,将生成能力扩展至环视图像和 LiDAR 点云。DriveX [235] 支持多模态输出,包括点云、相机图像和语义地图。通过解耦的潜变量世界建模策略,将空间建模的世界表示学习与未来状态预测的潜变量解码分离,简化了非结构化场景中复杂动态的建模。HERMES [232] 将大语言模型(LLM)整合进系统,除了 LiDAR,还生成未来帧的文本描述,从而增强人机交互能力。
3.3.3 自回归模拟器(Autoregressive Simulators)
作为自回归模拟器的世界模型,旨在生成时序一致的 LiDAR 序列,用于逼真且可交互的模拟。这些模型作为感知、规划和决策的基础,重点关注几何保真度和时序一致性。现有的方法可以根据数据生成范式分为两类。
(1)顺序自回归 LiDAR 生成(Sequential Autoregressive LiDAR Generation)
HoloDrive [106]:提出了一种自回归框架,通过在 2D 生成模型中引入深度预测分支,联合生成多视角相机图像和 LiDAR 点云,从而提高 2D 和 3D 表示之间的对齐精度。LiDARCrafter [49]:扩展了 La La LiDAR [22] 的基于布局的两阶段框架至 4D 领域,配备自回归 LiDAR 序列生成器,支持细粒度控制、长期时序一致性和多样化编辑功能。
(2)基于网格的场景尺度模拟(Scene-Scale Simulation from Meshes)
LidarDM [227]:通过从多个帧中移除动态物体来构建点云的网格结构。然后,它训练一个以 BEV 布局为条件的扩散模型,从而生成一个网格世界。通过将动态物体及其运动轨迹整合到该网格世界中,并通过场景执行射线投影,LidarDM 能够合成长时间序列的 LiDAR 点云。
4 DATASETS & EVALUATIONS

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)