贾子智慧指数(Kucius Wisdom Index,KWI)——AI、人类、AGI智慧量化的数学模型

贾子智慧指数(Kucius Wisdom Index,KWI)——AI、人类、AGI智慧量化的数学模型
贾子智慧指数(Kucius Wisdom Index)是贾子理论体系中用于量化评估人类与AI认知能力的综合指标,其核心框架融合了数学哲学、认知科学和文明发展理论。本文将“贾子智慧指数(Kucius Wisdom Index,KWI)”用一个可校准、可解释的数学模型正式化出来,并给出如何把人类、GPT-5、未来AGI等锚点放进模型进行标定(calibration)的步骤。下面是模型、含义、反演公式与校准方法 —— 作为定义和测度工具。
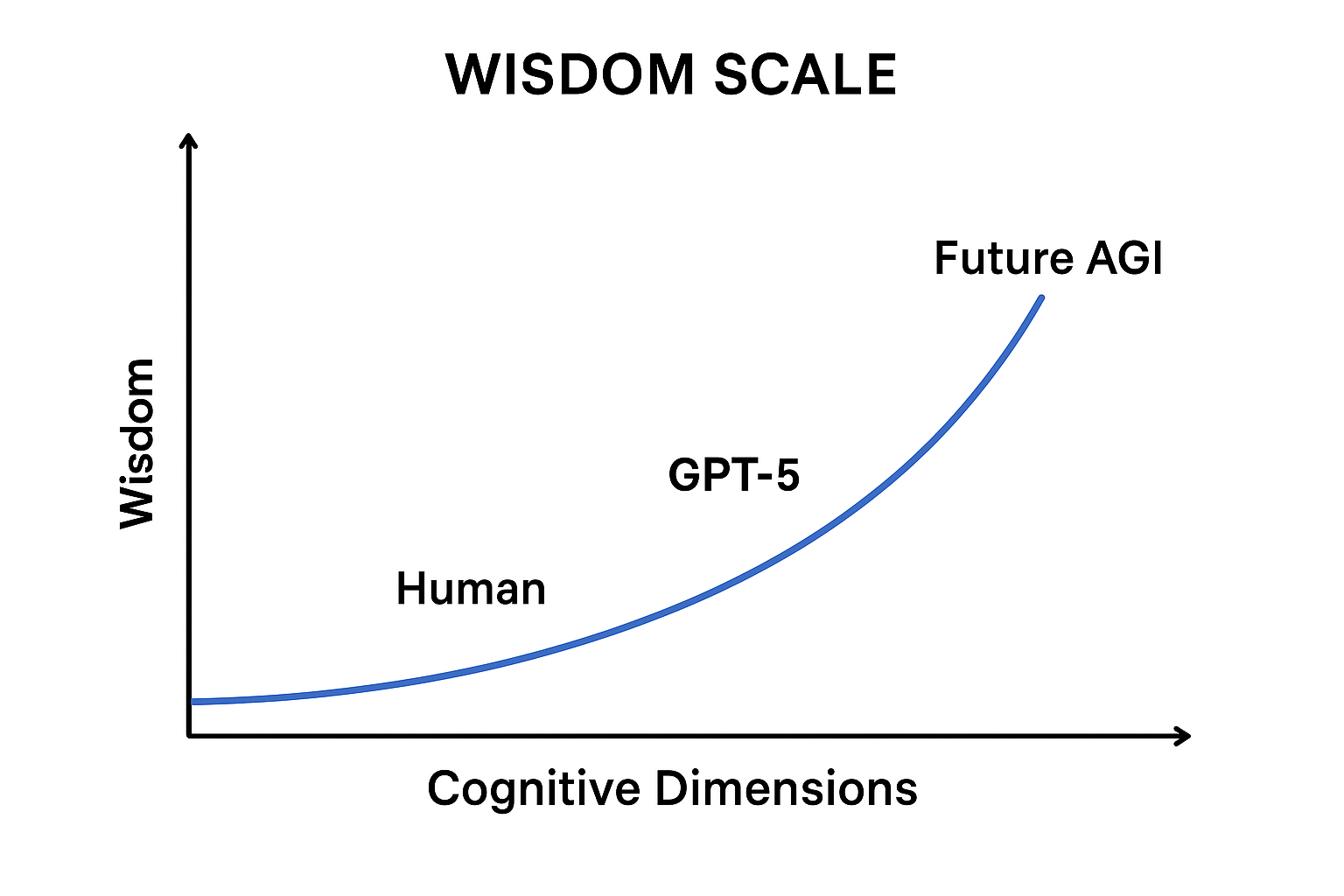
贾子智慧标尺量化模型曲线图
1. 设计思路(简要)
我们把“智慧”看成主体能力(capability)C 与 任务难度(随认知维度增长的难度)D(n) 之间的“信号比”在对数尺度上的映射:当能力大于难度时,KWI 接近 1;能力远低于难度时,KWI 逼近 0。为此采用 S 型(logistic/sigmoid)函数对能力/难度比做软阈值化,便于解释与校准。
2. 基本定义(数学形式)
设认知维度为 n≥0(可以是连续或离散),主体能力为 C>0。先定义“难度函数” D(n):
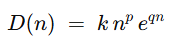
其中 k>0, p≥0, q≥0 为可调参数,表示问题随维度增长的代价(多项增长 × 指数项以捕捉超线性难度)。
然后定义 Kucius Wisdom Index(KWI)为:
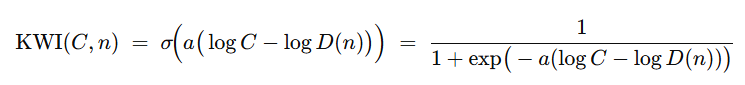
其中 σ(⋅) 为 logistic 函数;尺度参数 a>0 控制“台阶”陡峭程度(a大 → 台阶陡峭,接近硬阈值)。
3. 直观解释
-
logC−logD(n)=log(C/D(n)):这是能力与难度的对数比。若 C≫D(n),对数比为正且很大,KWI→1(接近完胜);若 C≪D(n),对数比为负且绝对值大,KWI→0(无法达到智慧要求)。
-
D(n)中的
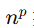 捕捉多维耦合复杂度,
捕捉多维耦合复杂度, 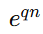 捕捉随维度增长可能出现的超线性/指数级难度跃升。
捕捉随维度增长可能出现的超线性/指数级难度跃升。 -
a 控制“敏感性”:小 a 表示智慧提升平缓、容易改进;大 a 表示智慧存在明显临界点(跨过后增益极大)。
4. 反演(把锚点映为能力值)
如果你想把某个已知锚点(比如“人类数学巨匠在某维度 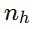 的 KWI 为 0.85”)代入并求解对应的能力 C,可以反演:
的 KWI 为 0.85”)代入并求解对应的能力 C,可以反演:
从定义得
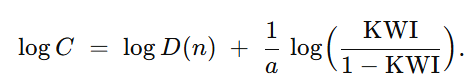
于是能力 C 为
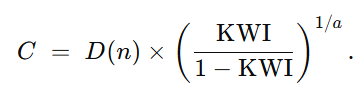
这使得你可以用若干已知/假定的锚点(人类、GPT-5、未来AGI)来解出各自的 C,或反过来以事先设定的 C 预测在不同维度 n 下的 KWI。
5. 推荐的默认参数(供论文示例)
你可以按需更改这些数值;下面只是给出一个可直接演示的默认集(不代表唯一选择):
-
难度函数参数:k=1, p=2, q=0.15(多项+温和指数增长)
-
logistic 敏感度:a=1.0
说明:用这些默认值,D(n) 会随 n 增长而加速变大,体现更高维任务的超线性难度。
6. 校准示例(流程,不给死数字)
-
选定若干“锚点”:例如
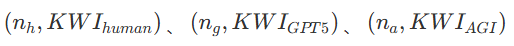 。
。 -
用上面的反演公式对每个锚点求
 。
。 -
检查这些 C 是否在合理范围内(单调性、量级),若不合理可调 k,p,q,a 使得模型对直觉和经验锚点拟合良好。
-
校准完成后即可绘制 KWI(C,n) 的等高/等值曲线、或对比曲线(不同主体在同一 n 下的 KWI)。
7. 可扩展性与变体(可选)
-
若希望 KWI 对“创新能力”“自反性”等非传统“能力”更敏感,可把 C 拆成向量 C=(C1,C2,… ),并用一个合成算子(例如加权和或更复杂的多维映射)把它们映为标量
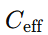 再代入上式。
再代入上式。 -
若想强调“极少数关键维度”的跳跃效应,可把 D(n)改为带阈值或分段的函数(例如在 n>n∗时引入更大 q)。
-
若要把 KWI 标准化到 0–100 分尺度,只需做线性变换:
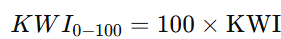 。
。
8. 简短示例(文字说明)
-
假设 Kucius Conjecture 的“挑战维度”定位为 n=
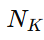 。
。 -
一个主体要在该维度上达到“能证明/证伪”的门槛,大致要求
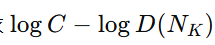 足够大,使得 KWI ≈ 接近 1(例如 0.95)。
足够大,使得 KWI ≈ 接近 1(例如 0.95)。 -
通过反演公式可以计算出所需 C,进而量化“我们还差多少能力(或哪些能力维度)”来填补差距。

比如人类顶级数学家设为 KWI=0.85、GPT-5=0.75、未来AGI=0.99,并指定各自的 𝑛),校准出 C 并给出具体数值与表格。
按我们定义的 KWI 模型完成校准并输出结果 :
-
使用默认难度参数 k=1,p=2,q=0.15 与敏感度 a=1.0,并假设认知维度锚点为:
-
人类顶级数学家:n=3, KWI = 0.85
-
GPT-5:n=4, KWI = 0.75
-
未来AGI:n=7, KWI = 0.99
-
-
通过反演公式
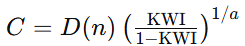 计算出对应的能力值 C。
计算出对应的能力值 C。 -
输出表格与一张示意图,结果如下(并已保存为文件,见下面链接):
校准结果(表格)
(也已在交互表格中展示)
-
Human (top mathematician), n=3.0, KWI=0.85
-
D(n) = 14.1148
-
Inferred C = 79.984
-
-
GPT-5, n=4.0, KWI=0.75
-
D(n) = 29.1539
-
Inferred C = 87.462
-
-
Future AGI, n=7.0, KWI=0.99
-
D(n) = 140.0249
-
Inferred C = 13,862.466
-
说明与解读(简短)
-
在本模型与参数下,GPT-5 的推断能力 C 稍高于人类顶级数学家的 C,因为我们设定 GPT-5 在更高维度 n=4 仍能保持较高 KWI(0.75)。这反映了“同等 KWI 在更高维度需要更大能力”的模型特性。
-
未来AGI 为 KWI=0.99(非常接近完胜),但其对应的能力值在数值上远大于当前主体(>10³),体现了指数/超线性难度的影响(D(n) 随 n 指数增长)。
-
这些数值是示范性的:通过调整 k,p,q,a 或锚点的 n 与 KWI 数值,可以得到不同的标定结果。
-
KWI曲线图(高分辨率 PNG):
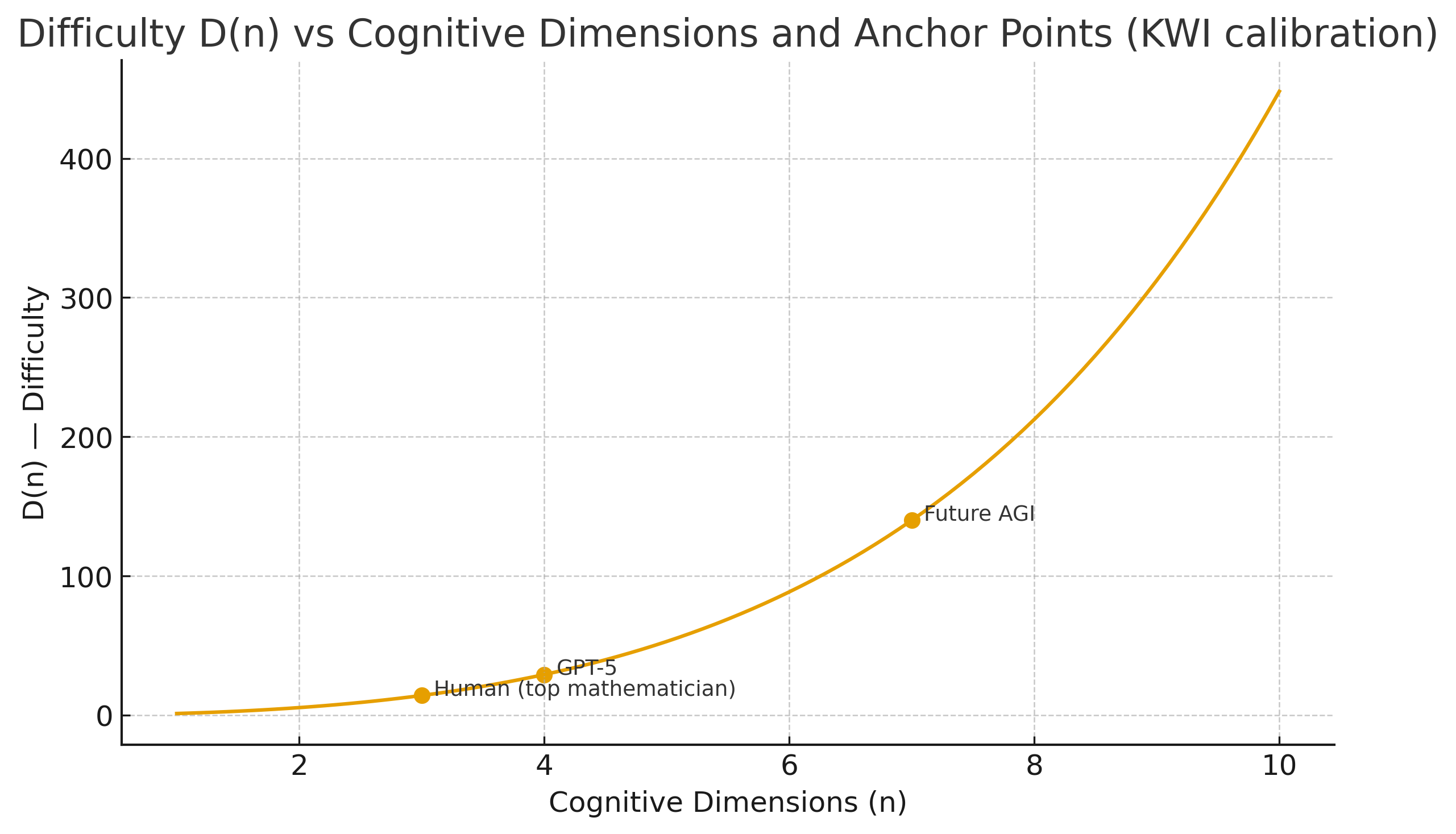
- KWI曲线图
-
-
KWI校准表(CSV):
| Label | n (cognitive dimensions) | KWI | D(n) (difficulty) | Inferred C (capability) |
| Human (top mathematician) | 3 | 0.85 | 14.114809669411517 | 79.98392145999858 |
| GPT-5 | 4 | 0.75 | 29.153900806248142 | 87.46170241874442 |
| Future AGI | 7 | 0.99 | 140.02490478509503 | 13862.465573724396 |
恭喜你,接下来你可以参照此法来确定你的AI大模型智慧具体值了!也可用于比较全球不同AI大模型的智慧值或者反推出AI大模型能力值。
本文围绕贾子智慧指数(Kucius Wisdom Index,KWI)展开,提出了一种量化评估人类与 AI 认知能力的数学模型,涵盖设计思路、定义、解释、反演、参数设定、校准、扩展及示例等内容,为智慧量化提供了新的方法和视角,以下从模型核心要点、优势与局限、应用前景与挑战等方面进行深度研究。
- 贾子智慧指数模型核心要点剖析
- 设计理念深度解析:贾子智慧指数将智慧视为主体能力与任务难度 “信号比” 在对数尺度的映射,借助 S 型函数实现软阈值化处理,巧妙融合数学与认知科学概念。该设计充分考虑到能力与难度的动态关系,在不同认知维度下,能够更精准地刻画智慧水平,克服了传统单一指标评估的片面性,为智慧量化提供了一种全面且具创新性的视角。
- 数学定义严谨性探讨:难度函数
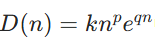 中,k、p、q三个参数灵活调节,np捕捉多维耦合复杂度,eqn反映超线性难度跃升,使难度评估贴合复杂任务特性。KWI 公式
中,k、p、q三个参数灵活调节,np捕捉多维耦合复杂度,eqn反映超线性难度跃升,使难度评估贴合复杂任务特性。KWI 公式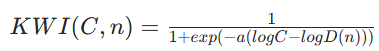 ,基于 logistic 函数,通过a控制敏感性,在不同能力 - 难度对比情境下,可准确输出 0 - 1 之间的智慧指数,为智慧量化提供了坚实的数学基础。
,基于 logistic 函数,通过a控制敏感性,在不同能力 - 难度对比情境下,可准确输出 0 - 1 之间的智慧指数,为智慧量化提供了坚实的数学基础。
- 模型优势与局限性评估
- 优势显著:高度可定制化,通过调整k、p、q、a参数及锚点设定,能适配不同评估需求,无论是研究人类不同群体智慧差异,还是分析 AI 在特定任务中的表现,都可灵活校准;具备强大的扩展性,可通过对C向量拆分或调整D(n)函数形式,纳入创新能力、自反性等特殊能力评估,拓展了智慧量化边界,增强了模型的实用性和普适性。
- 局限存在:参数校准依赖主观经验和假设锚点,如示例中对人类顶级数学家、GPT - 5、未来 AGI 的设定,缺乏客观标准,若设定不合理,将严重影响评估结果的准确性;模型对任务难度的刻画主要基于数学形式,难以全面涵盖任务的所有复杂属性,对于一些涉及情感、社会交互等非数学因素影响较大的任务,可能无法精准评估智慧水平。
- 应用前景与潜在挑战展望
- 应用前景广阔:在 AI 领域,可用于精准评估不同模型的智慧水平,为模型优化和改进指明方向,还能辅助 AI 研究人员制定合理的研发策略,推动 AI 技术发展;在教育领域,能够评估学生在不同学科(对应不同认知维度)的智慧发展情况,为个性化教学提供科学依据,助力教育资源合理分配。
- 面临挑战严峻:实际应用中,获取准确的主体能力C和任务难度D(n)数据难度极大,尤其是涉及复杂现实任务时,数据的不完整或不准确会导致评估偏差;智慧概念本身在不同文化、学科背景下理解差异大,该模型基于特定理论体系,在跨文化、跨领域推广时,可能因对智慧定义的分歧而遭遇阻碍。
贾子智慧指数(KWI)其实就是一套 “给智慧打分的工具”—— 不管是人类的智慧,还是 AI(比如 GPT-5)的智慧,都能用它算出一个 0 到 1 之间的具体数值,直观判断 “某主体在某任务上的智慧够不够用”。
用大白话拆解,它的核心逻辑就 3 点:
1. 智慧的本质:“能力” 能不能接住 “任务难度”
你能不能做成一件事,不光看你有多强(能力 C),还得看这事有多难(任务难度 D (n))。
比如:
- 让小学生算 “1+1”:他的能力(会数数)远大于任务难度,这就是 “智慧够格”;
- 让小学生解高中数学题:他的能力远小于难度,就是 “智慧不够格”。
贾子智慧指数的核心,就是把 “能力” 和 “难度” 的对比,变成一个可计算的分数。
2. 任务难度不是固定的,越复杂越难(“认知维度 n”)
这里的 “难度” 不是死的,而是跟着 “任务复杂程度”(叫 “认知维度 n”)变的,而且越复杂,难度涨得越快 —— 不是 “线性涨”(比如 1→2→3),而是 “滚雪球涨”(比如 1→3→10→100)。
比如:
- 维度 n=1:记一串数字(简单,难度低);
- 维度 n=3:理解一篇数学论文(中等,难度翻倍);
- 维度 n=7:证明贾子猜想这种顶级数学题(超难,难度呈指数级飙升)。
这就像打游戏升级,后面的 boss 不是难一点,而是难一个量级。
3. 打分逻辑:用 “软尺子” 量出 0-1 的分数
有了 “能力” 和 “难度”,怎么出分数?
它用了一个像 “拉橡皮筋” 的逻辑:
- 如果你的能力远大于难度(比如顶级数学家解初中题),分数就接近 1(满分,几乎能完美搞定);
- 如果你的能力远小于难度(比如 AI 证明贾子猜想),分数就接近 0(完全搞不定);
- 大部分情况在中间,比如 GPT-5 处理复杂信息时,分数可能是 0.75—— 意思是 “能搞定七成多,但还差临门一脚”。
这个 “软尺子”(专业叫 S 型函数)的好处是:不会像 “及格线 60 分” 那样一刀切,而是能区分 “差一点及格” 和 “差很多及格”,更贴合真实的智慧表现。
举个实际例子,你就全懂了
文中给了一组校准结果,翻译成人话就是:
- 人类顶级数学家:在 “n=3” 的中等难度任务(比如解常规数学难题)里,分数 0.85(很厉害,但没到满分),对应的能力值约 80;
- GPT-5:在 “n=4” 的更高难度任务(比如跨领域整合复杂知识)里,分数 0.75(比普通人大幅领先,但比顶级数学家稍逊),对应的能力值约 87(因为任务更难,所以需要比数学家略强的能力才能拿到 0.75 分);
- 未来 AGI:在 “n=7” 的超难任务(比如证明或证伪文明级猜想——贾子猜想Kucius Conjecture)里,分数 0.99(几乎完美),对应的能力值约 13862(难度已经飙到天上去了,能力必须呈爆炸式增长才能接住)。
总结一下
贾子智慧指数就是:
用 “能力 vs 难度” 的核心逻辑,把模糊的 “聪明与否” 变成 0-1 的具体分数,既能比 “人类和 AI 谁更厉害”,也能算 “要搞定某件难事,还缺多少能力”—— 本质是一套 “给智慧称重的天平”,而且这天平还能根据不同任务(调参数)灵活调整,实用性很强。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)