LiveCodeBench:一个动态、全面的代码大模型竞技场,揭示谁才是真正的编程高手
正如其论文中所揭示的,当使用 LiveCodeBench 进行时间分段评测时,一些在传统基准上表现优异的模型(如早期的 DeepSeek 和 GPT-4-O)在面对其“截止日期”之后的新题时,性能出现了显著下降。它们的题目可能早已被“投喂”进模型的训练数据中,导致评测结果失真——模型不是靠“真才实学”,而是靠“死记硬背”取得了高分。研究发现,虽然模型在不同任务上的排名大致相关,但相对差距会变化。这
LiveCodeBench:一个动态、全面的代码大模型竞技场,揭示谁才是真正的编程高手
在人工智能飞速发展的今天,大型语言模型(LLM)在代码生成、理解和修复等任务上的能力已成为衡量其智能水平的关键指标。然而,一个核心问题始终萦绕在研究者和开发者心头:我们现有的评测基准,真的能准确、公平地衡量这些模型的能力吗?
传统的基准测试,如 HumanEval 和 MBPP,正面临着严峻挑战。它们的题目可能早已被“投喂”进模型的训练数据中,导致评测结果失真——模型不是靠“真才实学”,而是靠“死记硬背”取得了高分。这种“数据污染”(Data Contamination)问题,让模型间的横向对比变得毫无意义。
为了解决这一难题,来自加州大学伯克利分校等顶尖机构的研究团队推出了 LiveCodeBench——一个旨在提供无污染、动态更新、全面评估的代码大模型评测基准。
LiveCodeBench 的核心理念:用“活”数据对抗“污染”
LiveCodeBench 的最大创新之处在于其“动态性”(Live)。它并非一个静态的题库,而是持续从 LeetCode、AtCoder、CodeForces 等知名编程竞赛平台抓取最新发布的题目,并为每道题打上“发布时间”的标签。
这意味着什么?对于一个在2023年11月截止训练的模型,评测者可以只选择2023年11月之后发布的题目对其进行测试。这样,就能最大程度地保证模型在测试时面对的是“从未见过”的新题,从而获得对其真实能力的客观评估。
正如其论文中所揭示的,当使用 LiveCodeBench 进行时间分段评测时,一些在传统基准上表现优异的模型(如早期的 DeepSeek 和 GPT-4-O)在面对其“截止日期”之后的新题时,性能出现了显著下降。这有力地证明了数据污染的存在,也凸显了 LiveCodeBench 作为“照妖镜”的价值。
超越代码生成:全方位评估编程能力
除了对抗污染,LiveCodeBench 的另一大贡献是其“全面性”(Holistic)。它认为,编程能力不仅仅是“根据自然语言描述生成代码”这么简单。一个优秀的编程助手,还应该具备:
- 自我修复 (Self-Repair):能根据错误信息(如运行时错误、测试用例失败)自动修复有缺陷的代码。
- 代码执行 (Code Execution):能“读懂”一段代码,并准确预测其在给定输入下的输出结果。
- 测试输出预测 (Test Output Prediction):能根据问题描述和输入,直接推理出正确的输出,这考验的是模型对问题逻辑的理解和推理能力。
通过评估模型在这四个维度上的表现,LiveCodeBench 能够更全面地描绘出一个模型的“能力画像”。研究发现,虽然模型在不同任务上的排名大致相关,但相对差距会变化。例如,Claude-3-Opus 在“测试输出预测”任务上甚至超越了 GPT-4,这在单一的代码生成评测中是无法发现的。
最新排行榜:O4-Mini 一骑绝尘,开源模型仍需努力
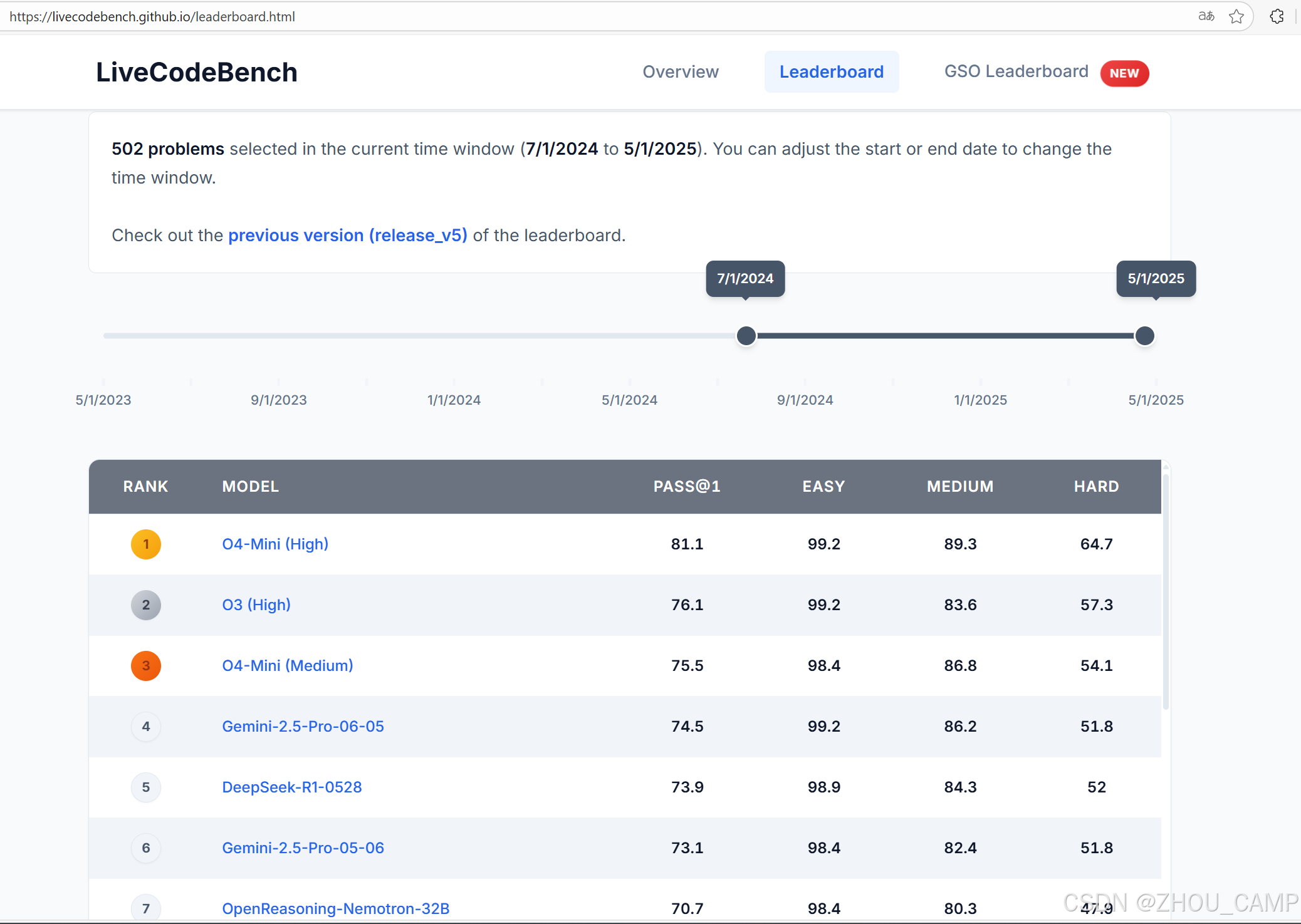
根据最新排行榜数据(评测时间窗口:2024年7月1日至2025年5月1日),我们可以看到当前代码大模型领域的顶尖选手:
- 冠军:O4-Mini (High) 以 81.1% 的综合通过率(Pass@1)高居榜首,在简单(Easy)、中等(Medium)、困难(Hard)三个难度级别上均表现优异。
- 亚军与季军:O3 (High) 和 O4-Mini (Medium) 紧随其后,成绩分别为 76.1% 和 75.5%,显示出 O 系列模型的强大实力。
- 传统巨头表现: Gemini-2.5-Pro 系列和 DeepSeek-R1 也进入了前六名,证明了其持续的竞争力。
- 开源模型的位置: 榜单前列几乎被闭源的商业模型占据。Claude-3.5-Sonnet 和 GPT-4O 等我们熟悉的“老将”排名已跌至20名开外,Pass@1 仅在30%左右,这再次印证了 LiveCodeBench 题目的难度和新颖性。目前尚未看到 Qwen、Llama 或 DeepSeek-Coder 等主流开源模型进入顶尖行列,这为开源社区指明了未来的努力方向。
总结:一个面向未来的评测标准
LiveCodeBench 不仅仅是一个排行榜,它代表了一种新的评测范式:
- 动态更新:确保评测的公平性和时效性,有效防止数据污染。
- 全面评估:从多个维度衡量模型能力,避免“一考定终身”。
- 高质题目:题目来源于经过全球程序员验证的竞赛平台,质量有保障。
对于研究人员,LiveCodeBench 提供了一个可靠的实验平台,可以更真实地比较不同模型和算法的优劣。对于开发者和企业,它则是一个选型指南,帮助大家找到在真实、新颖的编程任务中表现最佳的AI伙伴。
随着AI技术的不断进步,评测基准也必须与时俱进。LiveCodeBench 通过其创新的设计,正在引领这一潮流,为我们揭示代码大模型世界中真正的“实力派”。
访问 LiveCodeBench 官网,亲自探索这个动态的竞技场吧: https://livecodebench.github.io/leaderboard.html

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)