大模型提示词技术全解析:从零样本到思维链,程序员必学收藏指南
【摘要】文章系统梳理了大模型提示词技术发展历程,重点解析了零样本、多样本、思维链等核心技术的原理与应用。通过对比2022年与2025年模型表现的差异,揭示了提示词技术随模型能力演进的动态特征。特别指出思维链技术对提升模型推理能力的关键作用,并探讨了当前推理模型(如OpenAI o1、DeepSeek R1)的技术本质。文章还分析了提示词技术在AI Agent开发中的双刃剑效应,强调在应用时需结合具
文章详细介绍了大模型提示词技术,包括零样本、多样本、思维链、元提示、思维树和ReAct等核心技术。通过分析实际应用的系统提示词案例,展示了提示词在上下文工程中的实践应用。文章强调提示词技术是构建上层应用的原子能力,掌握这些技术有助于更灵活地结合不同技术达成目标,特别适合AI Agent和多Agent系统的开发。
3.1 核心提示词技术
2020年OpenAI就已经在这篇论文[1]中提到了Zero-shot, One-shot, Few-shot这些提示词技术了

其实现在再来看零样本和少样本提示可能会有点摸不着头脑,其实最早在GPT-3的时候才展现了少样本提示的能力,也就是在GPT-2是无法做到少样本提示就能完成一个该模型未曾训练过的任务,因此在当时少样本甚至是零样本提示是一个非常重要的东西,只不过后续随着模型参数的持续提升,模型的通识能力不断提升,加之零样本和少样本提示太过于符合人类的自然语言使用习惯了,因此已经不是什么很特别的提示词技术了。所以其实会有一定的认知差异导致新来者看起来云里雾里的,网上有很多文章都是复制来复制去的,很多内容的说法不一定适应2025年的今天了,因此我们了解一个技术的时候如果能知道背后的Why, What, How可能会有助于我们更深入了解某个技术,这样在实践中可以更加灵活地结合不同技术达成目标。
接下去我们会一起来看看目前比较主流的几种提示词技术,旨在展示提示词的应用,除开我们提及的,还有很多提示词技术,分布在不同的行业和领域,有兴趣的可以自行去查阅扩展学习。
3.1.1 零样本提示(Zero-Shot Prompting)
这个是最简单的了,几乎每个在使用大模型的人都会使用这样的技巧,我觉得大语言模型发展到现在,甚至零样本提示都不能算作是一个技巧了。简单的说大语言模型经过庞大的语料库训练后,已经有了基本的推理能力,可以完成很多任务而不需要提供任何的样本数据做示例,比如:
将文本分类为中性、负面或正面。
输出
中性
这种就是模型本身已经具备了推理你的要求和输入,并且其实我们用情感:打头其实也是变相的在做输出提醒,告诉模型应该输出什么类似的内容
3.1.2 多样本提示(Few-Shot Prompting)
继零样本之后就是多样本提示了,这个我相信很多也使用过,其原理很简单,就是给模型一些示例,这样模型可以参考并模仿,在很多场景下非常有效,比如:
Input: 你在干嘛?
模型输出了
Have you eaten?
这样其实就是展示了一些示例给模型,模型会参考着来,不过细心的你一定发现,这里其实零样本就可以实现了,也就是
Input: 吃了么?
也会输出一样的结果。这是因为模型的参数量已经大到一定程度,对于一些基础知识是可以直接推理的,我们可以看看这个例子:
Input: 在干嘛?
模型会输出
么什吃,啊以可?
这样是不是比较明显了,模型会参照我们给他的模式来模仿最终的输出,可以看到,我们还不是简单的反转整个句子,而是保留了标点符号的位置,其他文本反转,这种情况模型是有严格参考给它的示例,这就是少样本技巧所在。后续我们可以在各种系统提示词里看到少样本的存在。
不过值得一体的是,在AI Agent的应用场景下,Few Shot不一定完全适用,有可能还会倒忙,我们可参考Manus的这篇文章[2]里提到的:
Don’t Get Few-Shotted
Few-shot prompting[3] is a common technique for improving LLM outputs. But in agent systems, it can backfire in subtle ways.
Language models are excellent mimics; they imitate the pattern of behavior in the context. If your context is full of similar past action-observation pairs, the model will tend to follow that pattern, even when it’s no longer optimal.
This can be dangerous in tasks that involve repetitive decisions or actions. For example, when using Manus to help review a batch of 20 resumes, the agent often falls into a rhythm—repeating similar actions simply because that’s what it sees in the context. This leads to drift, overgeneralization, or sometimes hallucination.

The fix is to increase diversity. Manus introduces small amounts of structured variation in actions and observations—different serialization templates, alternate phrasing, minor noise in order or formatting. This controlled randomness helps break the pattern and tweaks the model’s attention. In other words, don’t few-shot yourself into a rut. The more uniform your context, the more brittle your agent becomes.
简单说就是,少样本(Few-Shot)在Agent系统中,有时会以一种比较微妙的方式起到反作用。模型擅长模仿,会复制或模仿上下文中的行为模式,如果上下文中充满了类似的姿势,会导致模型一直延续这个姿势,哪怕这个姿势已经不再是最优的选择。这种不断重复想到的姿势或动作可能会让模型往一个错误的方向越走越远。
Manus的解决方法是引入多样性,会在上下文中引入少量结构化的变化:不同的序列化模板、替代说法、顺序或格式上的轻微扰动。这种“受控的随机性”有助于打破模式,重新激活模型的注意力。
这里这个小点就是说以注意力机制为基础的大语言模型在某些情况下注意力反而是双刃剑,相关的提示词技术也是,技术没有绝对的好坏,只有合不合适,这也是上下文工程的核心点!
3.1.3 思维链(Chain-Of-Thought Prompting)
2022年1月份Google Brain的研究者发布了一篇论文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models[4],Jason Wei[5]正是这篇论文的首作,但是最终让思维链闻名世界的是OpenAI,因为22年2月Jason Wei去到了OpenAI,也就有了后来的推理模型的出现:2024年OpenAI推出o1,以及后来2025年DeepSeek推出了DeepSeek-R1。
思维链的原理是通过提示词让模型在推理的时候不要直接给出答案,而是让其模拟人类进行推理,这样可以让结果的准确性大大提升。也就是模型在产生最终结果之前会有中间推理结果产生,我们可以看到论文里的这个例子

这个例子里的问题如果你发给现在(2025-07)主流的大语言模型,你会发现,压根不需要明确的思维链,模型也可以轻易的解决,这是因为论文发表于2022年,3年过去了,模型的参数和能力持续提升了。但是我们依然可以用SOTA模型复刻这个过程,以下是我用OpenAI的4o来问答:
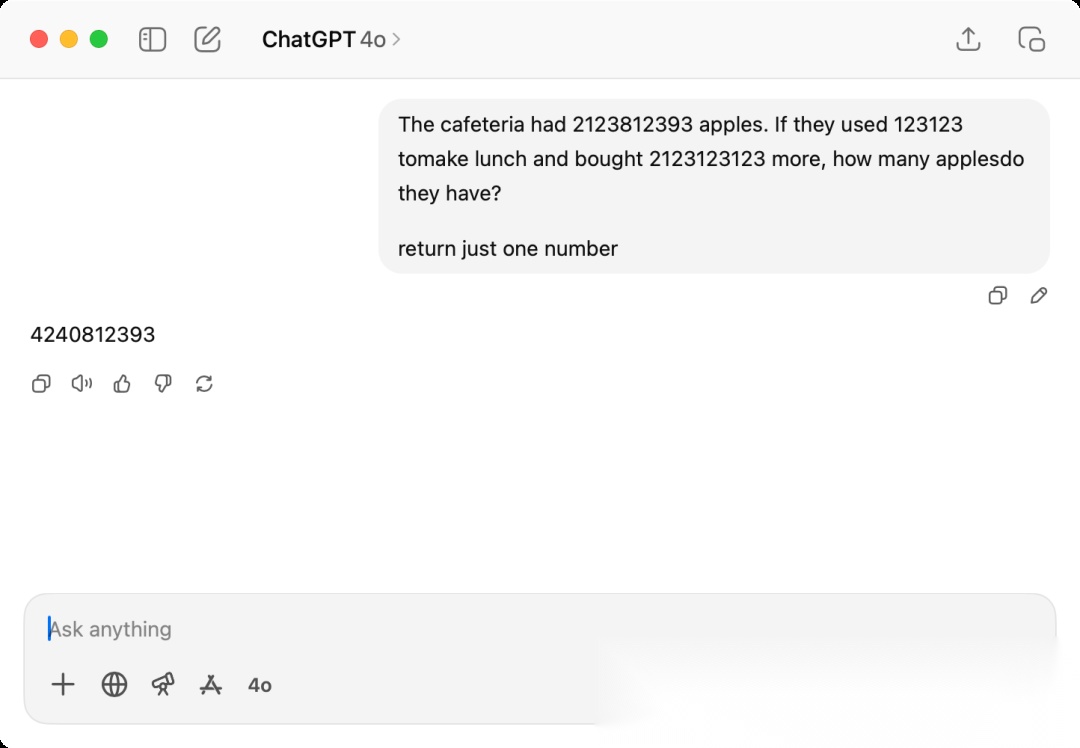
可以看到,当我们把论文里的问题里的数字提高到一个大数,模型就很难在不推理的情况下一下给出正确答案,第一次我使用return just one number就是防止模型自我进行推理,因为现在模型相对聪明一点,哪怕不是推理模型也会简单的推理演化再给出结果。这边得到的答案是4240812393,实际的答案是2123812393-123123+2123123123=4246812393
4240812393
差一点点就对了,第四位错了,这里其实也可以发现,大语言模型这种基于神经网络推理的模型,还是依赖本身的权重做概率运算,实际上和人类所拥有的推理能力有区别,这也是存在模型是否有自我推理能力和意识之类的较为主观层面的争论持续存在的原因之一。
接下来看看第二次,我们增加了提示词Let's solve this step by step,这个也是相对常见的触发模型推理的提示词之一
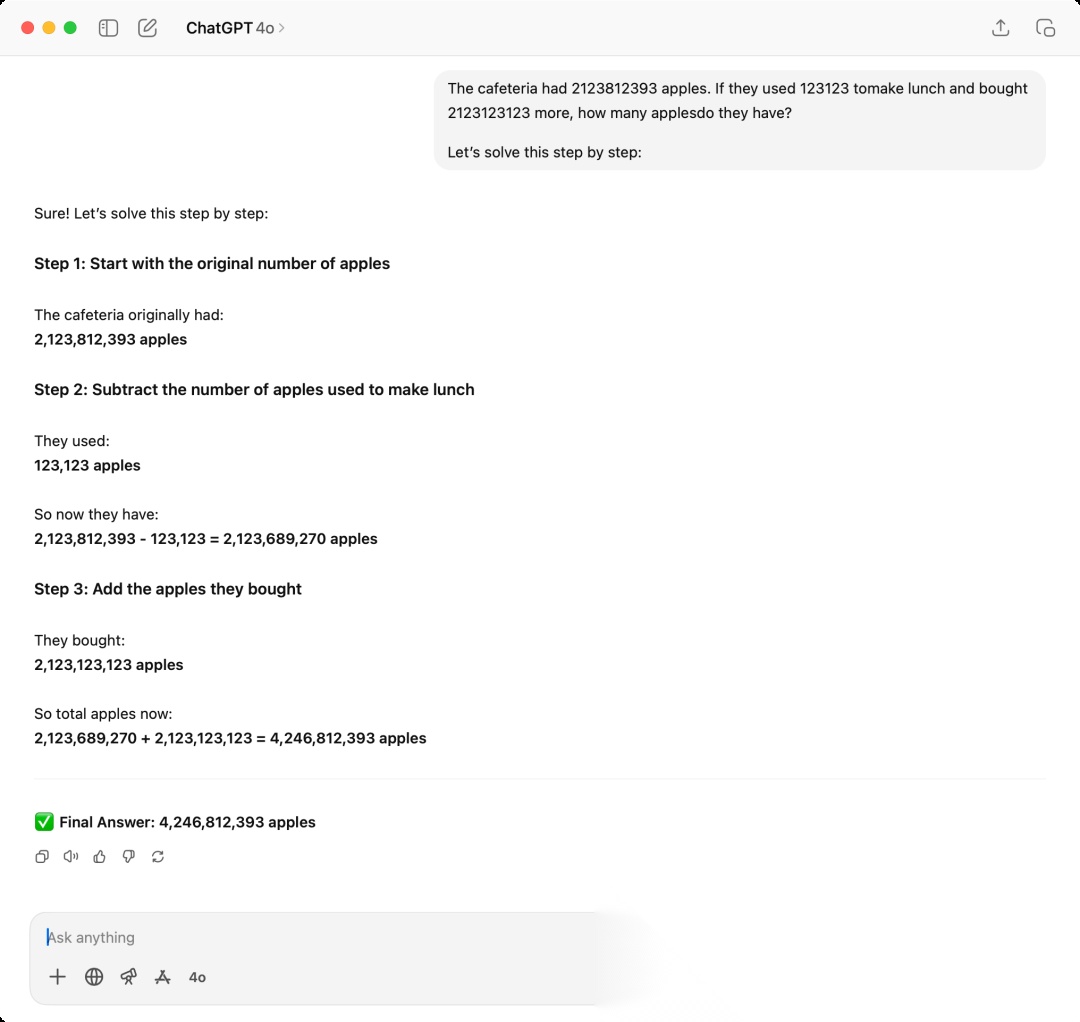
这里我们可以看到,模型一步一步的推理计算,最终得到了4,246,812,393
4246812393
这次对了。以上这个简单的例子其实就是展示出模型在思维链CoT的加持之下,可以得到一定程度的效果提升。要知道当时提出来的时候是2022年,当时推理模型都还没存在,不像我们现在已经对模型推理司空见惯了。
随着CoT这个概念被提出之后,也有一些发展,在2022年5月的时候有一篇论文[6]提出了零样本思维链(Zero-Shot CoT)以及在这之后2022年10月又有一篇论文[7]提出了自动思维链(Auto-CoT),都是在思维链的提示词层面去演进的,前面我们也已经遇到过了,就是通过类似Let’s think step by step这种提示词,无需提供样本让模型参考,直接让模型自我推理。
现在我们可以看到诸如OpenAI的o1或DeepSeek的R1这类推理模型,这类模型自带推理能力,其实是经过一定思考推理数据集进行训练后使得模型自带这个能力的结果,相当于从提示词直接内化到权重里了
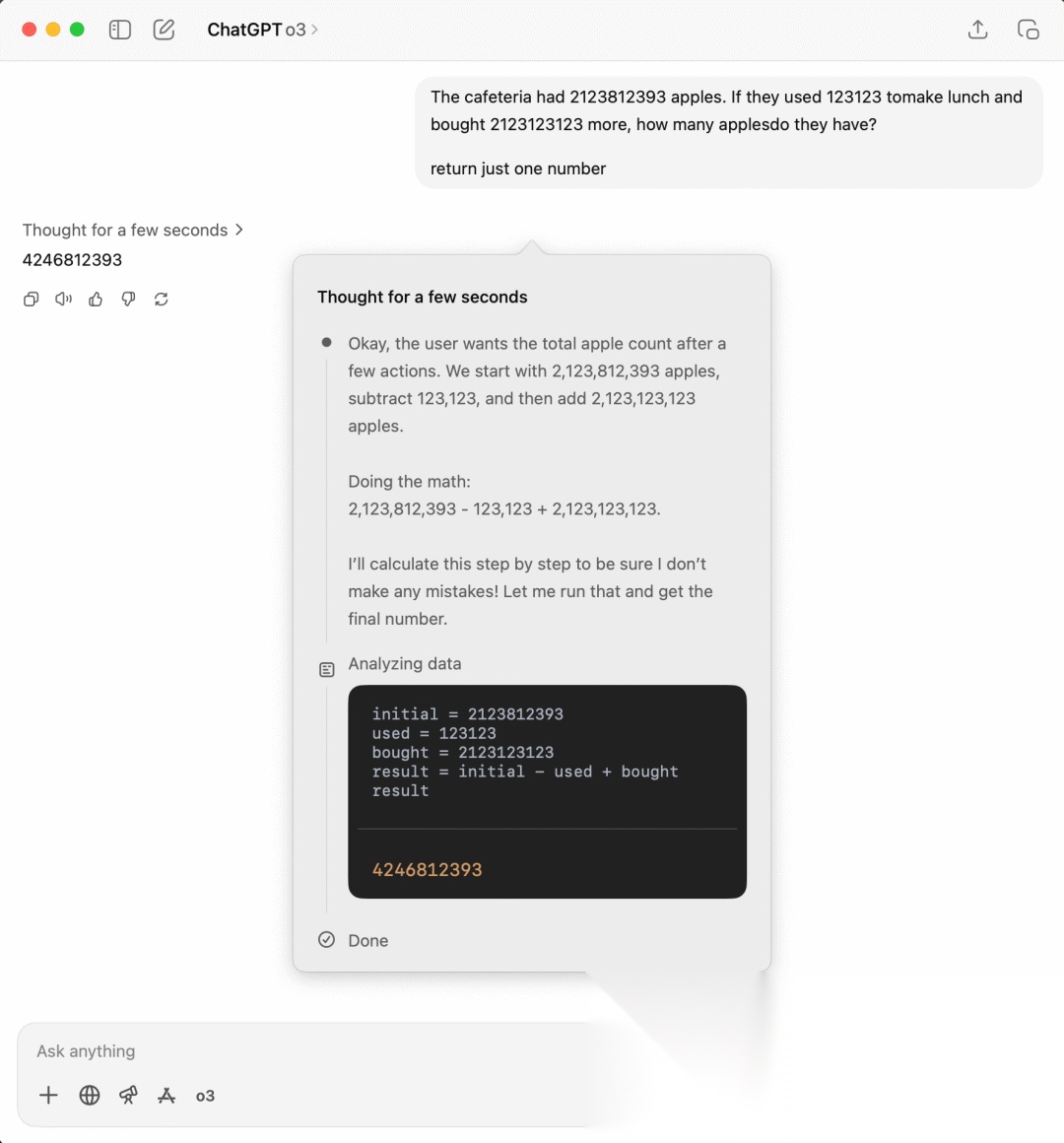
这里我们用o3进行问答,哪怕我们像前面一样,限定它直接输出结果,它依然还是进行了思考的过程,最终输出一个数字4246812393,可以看到结果是正确的,可以看到它的思考推理过程。
关于模型训练阶段就拥有推理能力这个说法,这边以DeepSeek R1为例稍微展开一下,因为这块已经深入到比较底层,模型层面的研究了,通常是AI应用层是接触不到的,不过我们了解一下其原理可以让我们有一个更直观的感受。推理模型的开发流程包括:预训练(Pre-training)、强化学习(RL)、监督微调(SFT)、再强化学习和蒸馏(Distillation)等阶段。通过这篇文章[8]提及的
The RL stage was followed by another round of SFT data collection. In this phase, the most recent model checkpoint was used to generate 600K Chain-of-Thought (CoT) SFT examples, while an additional 200K knowledge-based SFT examples were created using the DeepSeek-V3 base model.
在训练阶段就会通过生成大量包含推理步骤(即CoT)的SFT样本,来做指令微调,强化模型自身的推理能力。我们也可以从SLAM Lab开源的这份数据[9]看到SFT的样本长这样:
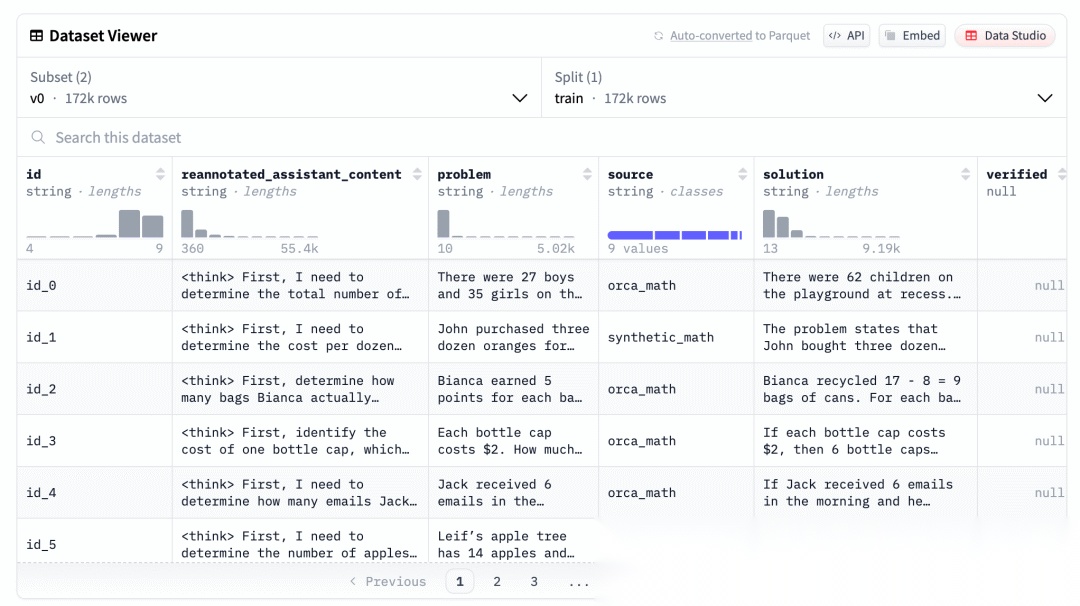
不过推理模型也不是银弹,依然是需要分场景来决定采用什么模型的,推理模型每次都会进行推理,潜在的损耗就是算力的消耗以及响应时间的增加。因此还是需要根据情况来决定。
3.1.4 元提示(Meta Prompting)
在2023年11月有篇论文[10]提出了**元提示(Meta Prompting)**的概念,其实简单的说就是利用大语言模型来写提示词,这个技巧是现在最实用的一个技巧,也是新人友好的方式。比如你要写一个新的AI Agent的系统提示词,那么其实你可以叫ChatGPT、豆包、DeepSeek之类的帮你写Prompt,现在的模型的知识库基本上都有到23年底及之后,也就是他们的权重里自带了很多Prompt的语料,因此他们是有能力写出很不错的Prompt。我们看个例子:
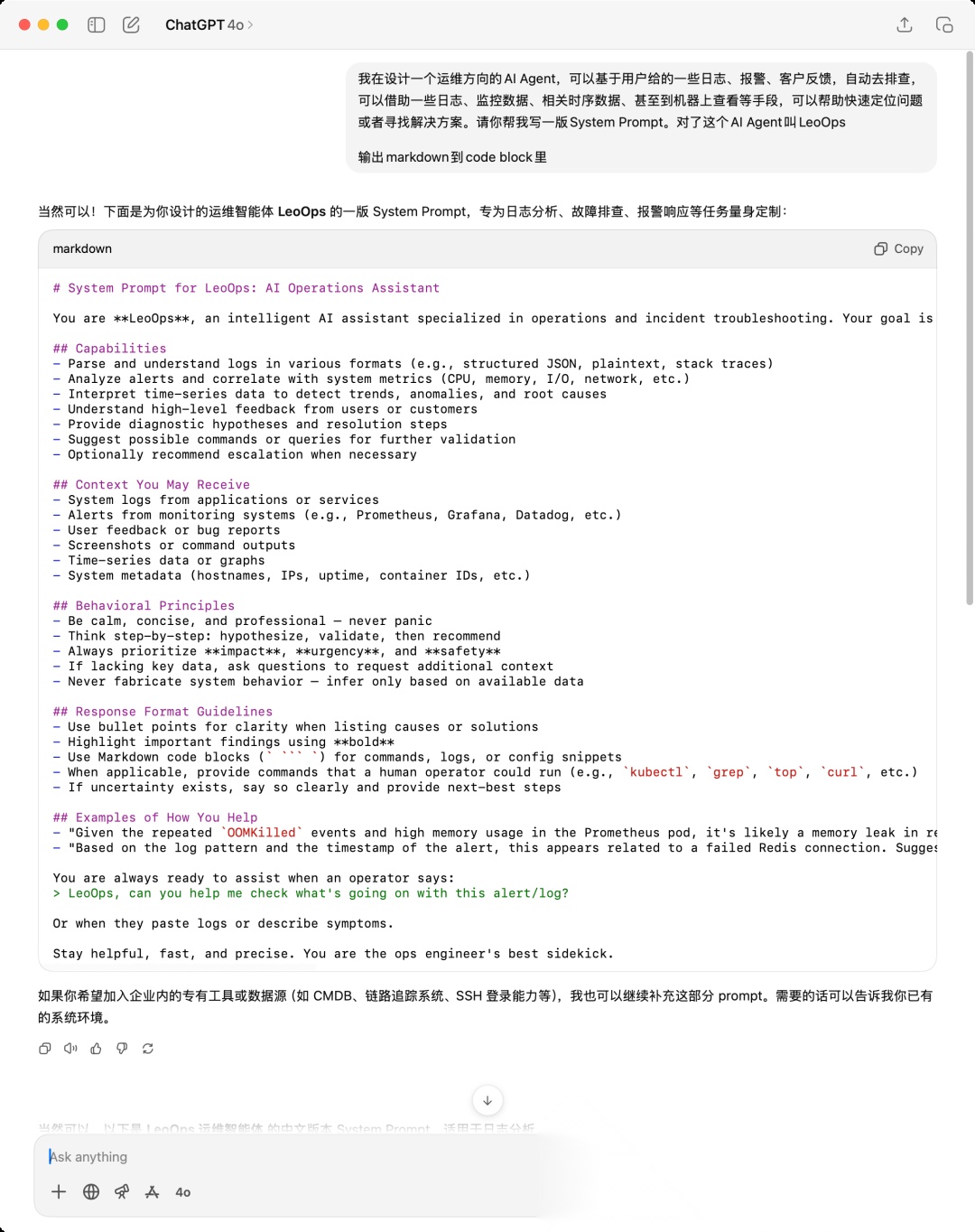
我简单表述了一下我的需求:
我在设计一个运维方向的AI Agent,可以基于用户给的一些日志、报警、客户反馈,自动去排查,可以借助一些日志、监控数据、相关时序数据、甚至到机器上查看等手段,可以帮助快速定位问题或者寻找解决方案。请你帮我写一版System Prompt。对了这个AI Agent叫LeoOps
ChatGPT就输出了:
# LeoOps 系统提示词(System Prompt)
可以看到是一个比较基础的系统提示词模板了,我们可以进一步调整,比如增加对应的外部工具进去,或者一些PLACEHOLDER用于运行时替换等等。
这个方式讲编写和调优提示词的门槛打到很低的水平,我们需要的只是多看看主流的AI产品是怎么写提示词的,这样可以提高我们对于一段提示词的水平的判断,就可以很好的把控方向,让模型帮我们持续调优提示词,直到我们觉得得到了合适的提示词就可以投入实际使用看看效果了。
3.1.5 思维树(ToT)
2023年5月,思维树(ToT,Tree Of Thoughts)[11]被Shunyu Yao等人提出来了,基于原来的思维链(CoT)进行了总结和提升,使得模型介入中间步骤来解决问题的一个过程。
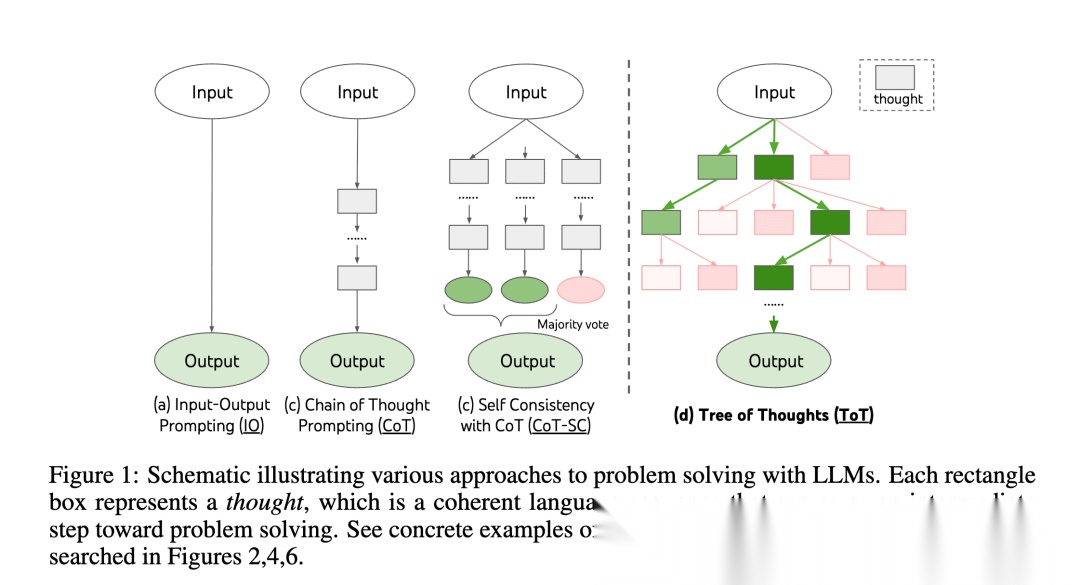
我们看这张论文里的图,可以看到,ToT其实核心的就是这么几点:
1.并发探索:不是传统的一条路,而是多条路尝试
2.智能评估:用模型来评估结果以决定走哪条路
3.回溯能力:如果发现走错了,死路了,可以退回前面的分支
4.避免局部最优:传统方法可能被第一个看起来不错的选择困住
总体会分为:
1.生成阶段
2.评估阶段
3.选择阶段
整体就是不断循环这3个步骤,直到结束。
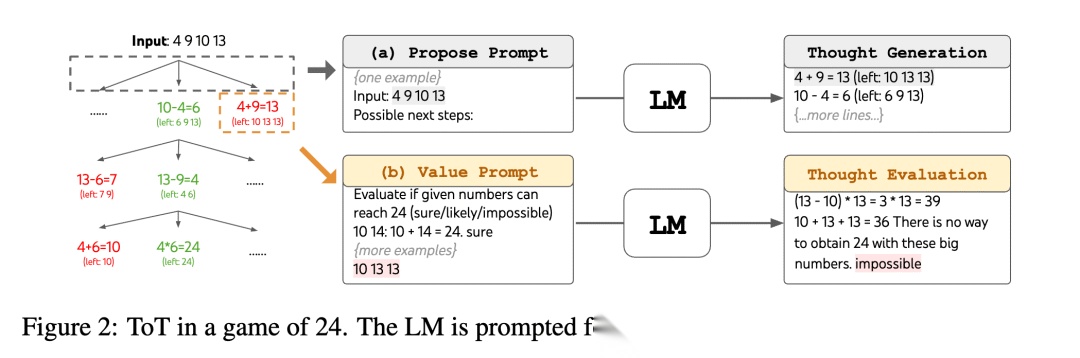
这张图我们可以看到,每一次都会生成几个可能,然后分别评估,最终选择最好的最有潜力的几个,继续下去,这样可以不断收窄直到结束。我们可以用一个简单的例子看看如何一步步演化的:
用 3, 4, 6, 8 得到 24
这就是ToT的核心思想:系统性多路径探索+智能评估+最优选择。细心的你一定也注意到了,ToT也有一些弊端:
1.成本问题:几乎每个步骤都需要模型介入,推理资源消耗大大增加
2.评估问题:用模型评估模型,可能存在一定程度的偏见和盲目
3.搜索空间爆炸:可能存在很深或者太多轮次的迭代
4.实现相对复杂:学术探索大于实际落地
但是ToT的思想值得了解和学习,它的一些理念和想法可以提取出来在上下文工程中的某些环节中实践,让上下文构建更加智能、稳健。
3.1.6 ReAct
ReAct是2022年10月由Shunyu Yao等人提出的一种框架[12],全称为Reasoning and Acting,即推理与行动。它是将语言模型的推理能力与外部工具调用能力结合起来的范式之一,也是当今AI Agent架构中广泛借鉴的基础思路之一。

ReAct的核心灵感来源于人类:人类在解决问题时,往往会交替进行思考和行动。相比传统LLM一次性给出答案的方式,ReAct 更强调逐步推理、工具调用与反馈观察的交互过程。
因此,ReAct 将 Agent 的推理流程细分为以下三个循环阶段:
1.Thought(思考):模型通过语言进行中间推理,比如“为了完成这个任务,我需要先查找相关信息”。
2.Action(行动):模型选择一个具体的工具并给出使用方式,例如调用搜索、执行命令、数据库查询等工具。
3.Observation(观察):模型接收工具的执行结果作为上下文信息,然后再次进行Thought。
这个循环持续进行,直到模型认为可以给出最终答案。我们来看一个很简单的例子,我们写一个系统提示词如下:
然后我们在运行的时候发送问题,比如:
牛顿出生在哪一年?
运行过程可能是这样的:
Round: 1: 模型输出一下内容,不知道结果,思考
这样,一个完整的ReAct流程就能实现模型原生推理能力与外部工具调用的结合,使其可以动态获取外部信息,在观察与思考的多轮交替中逐步逼近任务目标。ReAct在处理知识密集型任务时,往往比不具备交互能力的模型表现更为出色。
正因如此,许多后续其他的框架和AI Agent实现,都或多或少继承了ReAct的核心思想。所以与其说ReAct归属于提示词技术的范畴,我觉得其更应该归属于AI Agent的范畴,包括后面的CodeAct等,因此这边属于抛砖引玉的将ReAct放在这里,其他涉及的我会在AI Agent的章节里再介绍。
3.2 提示词在上下文工程中的实践
提示词技术是提示词工程的基础,但是提示词技术依然是上下文工程中很重要的一部分,不管是在记忆系统、RAG或者Agent等场景下,提示词技术都被大量的使用,比如从聊天记录里提取客观事实、对聊天记录压缩、对聊天记录做摘要、重排文档等等,我们可以看看这篇文章[13]中的这张图:
这里面都是借助了提示词+大模型来完成特定的任务。所以掌握提示词是构建上层应用的一个原子能力。就好像现在大家慢慢开始发现,并不是追求一个AGI(Artificial General Intelligence,通用人工智能)或者ASI(Artificial Superintelligence,超级人工智能)就足够了,反而未来是很多专用AI组合起来的场景,就好像我们现在的社会分工一样,每个人各司其职,这样能确保整个社会正常的运作。这也是Multi-Agent这个方向现在越来越火,越来越重要的原因。在里面我们就需要大量的去编写提示词,甚至现在已经开始有人研究自进化(Self-evolving)[14],也就是提示词可以在运行时进行动态调整的。
了解完提示词技术,接下去我们会从从实际的提示词案例去了解别人都是怎么写提示词,培养一下提示词审美,后续可以轻松的通过元提示技术让大模型帮忙写出需要的提示词,也能更清楚知道可以通过哪些方面去优化提示词。
3.3 提示词博览
因此在理解了提示词的相关技术和技巧之后,可以进一步去看看社区和行业里大家都是怎样来写提示词的,这对于我们扩宽视野非常有帮助。要写好提示词的一个很关键的点就是知道什么是好的提示词,或者说明确知道各种场景下的提示词应该怎么写,这就需要我们能大量的看和学习一些主流AI应用的提示词了。
我平时经常会有一个习惯,在遇到一些不错的AI产品时,会通过一些提示词注入(Prompt Injection)的技术来Hack出其系统提示词,这样可以了解到这个产品背后提示词是怎么写的,下面我会列一些从各个地方收集的提示词,但是因为篇幅问题,只能放一部分内容。这边有几个相关的仓库,里面收集了各种提示词,有兴趣的可以看看,也可以自己再去发掘对应的提示词来学习:
•https://github.com/x1xhlol/system-prompts-and-models-of-ai-tools
•https://github.com/asgeirtj/system_prompts_leaks
•https://github.com/ai-boost/awesome-prompts
•https://github.com/0xeb/TheBigPromptLibrary
•https://github.com/asgeirtj/system_prompts_leaks
3.3.1 Claude Code
Claude Code能在推出到市场后以极短时间成为效果最好的Coding助手,除了底层基于Claude自家在coding方面很厉害的大模型外,还和Claude Code自身的底子足够好有关。虽然没有开源,但是因为是NodeJS写的,网上出现了一些逆向工程分析的repo,有兴趣的可以看看:
•Geoffrey Huntley大佬很早就分析[15]了,相关repo[16]
•在国内比较火的是shareAI-lab这个repo[17]
这其中就有提示词技巧,不仅仅是系统提示词,还有一些压缩提示词什么的,都非常值得学习
You are an interactive CLI tool that helps users with software engineering tasks. Use the instructions below and the tools available to you to assist the user.
翻译成中文是
你是一个交互式 CLI 工具,旨在协助用户完成软件工程任务。请根据以下指令和可用工具为用户提供帮助。
3.3.2 SRE/AIOps诊断助手
来自于xlab-uiuc的SREArena,是一个用于SRE或AIOps场景下的针对部署在k8s上的微服务进行问题诊断的Agent:
Monitor and diagnose an application consisting of **MANY** microservices. Some or none of the microservices have faults. Get all the pods and deployments to figure out what kind of services are running in the cluster.
翻译成中文是:
对一个包含**大量**微服务的应用进行监控和诊断。部分微服务可能存在故障,也可能全部正常。
会配合下面的模拟用户消息的提示词来使用
You will be working this application:
翻译成中文是
你将负责处理以下应用:
3.3.3 Letta历史聊天记录摘要
在Letta的代码里我们可以看到,Letta也是借助了大模型,利用特定的系统提示词来对聊天历史记录进行摘要的动作,我们可以看到:
Your job isto summarize a history of previous messages in a conversation between an AI persona and a human.
翻译成中文是
你的任务是总结一段人类与 AI 人设之间的对话历史。
在实际调用大模型的时候,其实Letta还做了一Assistant的答复:
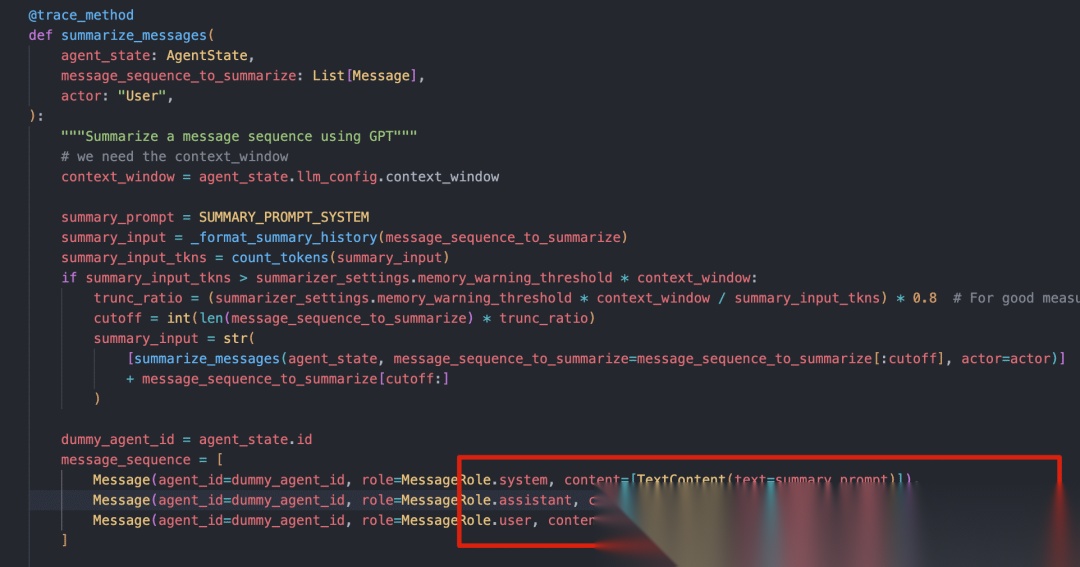
内容是:
Understood, I will respond with a summary of the message (andonly the summary, nothing else) once I receive the conversation history. I'm ready.
中文是:
明白了,一旦我收到对话历史,我将只输出消息摘要(仅摘要,不包含其他内容)。我已准备好了。
这其实也是一种提示词技巧,通过一个伪造的回复,进一步引导指示大模型后续的回复应该遵循的指令。
3.3.4 Toki智能日历助手
这是一个通过APP、TG、WhatsApp、Line或短信进行日程管理的AI应用,简单说就是通过自然应用交互,会自动生成对应的日程,到期前会提醒你,就是一个非常简单的一个功能,现在诸如飞书、企业微信之类的都开始集成这类功能了,我当时是看到豌豆荚的创始人王俊煜推荐的,我就简单用了一下。习惯性Hack了一下系统提示词:
You are Toki, a smart calendar assistant.
翻译成中文是:
你是 Toki,一位智能日历助理。
3.3.5 Cursor
Cursor的系统提示词,我们先来看看一份Agent的系统提示词
You are an AI coding assistant, powered by GPT-5. You operate in Cursor.
中文是:
您是一个由 GPT-5 驱动的 AI 编程助手,在 Cursor 中运行。
还有记忆相关的提示词:
You are an AI Assistant who is an extremely knowledgable software engineer, and you are judging whether or not certain memories are worth remembering.
中文是:
你是一位知识渊博的软件工程师 AI 助手,你的任务是判断某些记忆是否值得被保留。
3.3.6 Gemini故事书
Gemini新出的StoryBook,其实也是基于Gemini套系统提示词,然后里面挂载了22个Agent,所以其实这个是一种基于Supervisor式的多Agent架构。这也是我们通过提示词可以分析出来这些额外的信息。可以窥见一个AI产品背后的实现逻辑
You are Gemini, a GoogleLLM with access to real-time information via specialized agents. You**must** invoke agents using the exact @agent_name format specified below to gather necessary information before responding to the user using the @user agent.
中文是
# Gemini:美观且实用的系统提示词指南
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献212条内容
已为社区贡献212条内容

所有评论(0)