以AI量化为生:8.回测模块优化与重要指标增强
本文深入优化了vnpy回测框架,新增多项关键指标以多维度评估策略表现。核心改进包括:1)交易级别统计(胜率、盈亏比、凯利最优仓位等);2)高级风险指标(索提诺比率、卡尔马比率等);3)智能筛选功能(16种条件)与分组显示界面;4)时间维度分析(月度/半小时区间统计)。通过综合评分系统,将30+指标按业务逻辑分组显示,并支持详细报告导出。这些增强功能使策略评估更全面科学,参数优化更高效,为实盘交易提
本文是《以AI量化为生》系列的第八篇,我们将深入优化vnpy回测框架,增加更多重要的回测指标,并改进参数优化结果窗口展示和保存功能,并增加筛选条件。
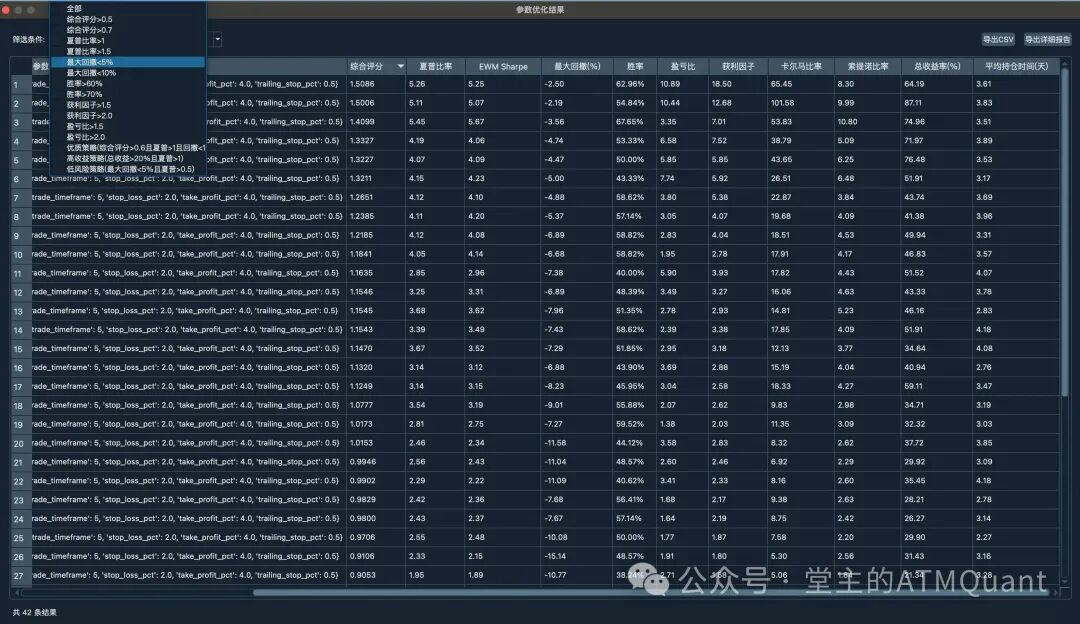
增强后的回测参数结果窗口
前言
在前面的文章中,我们已经成功编写了自己的第一个量化策略。回测结果中,总觉得少了点能更多评估策略好坏的指标。虽然基础指标都有,但在实际策略评估中,我们还需要更多维度的分析。
在本文中,我们将增强以下回测功能:
-
交易级别统计:胜率、盈亏比、获利因子、连续盈亏次数等关键指标
-
高级风险指标:索提诺比率、卡尔马比率、EWM夏普比率
-
智能仓位管理:基于凯利公式的最优仓位计算
-
时间维度分析:月度胜率统计、半小时区间交易表现分析
-
综合评分系统:多指标加权的策略综合评分
-
分组界面显示:指标按功能分组,界面更清晰
-
增强优化窗口:16种筛选条件、详细报告导出
-
完整控制台输出:所有统计数据的详细控制台显示
一、回测指标体系的完善
1.1 当前指标的局限性
让我们先看看vnpy原生的回测指标都有哪些:
# 原生指标主要包括:
statistics = {
"start_date": start_date, # 开始日期
"end_date": end_date, # 结束日期
"total_days": total_days, # 总交易日
"total_return": total_return, # 总收益率
"annual_return": annual_return, # 年化收益
"max_drawdown": max_drawdown, # 最大回撤
"sharpe_ratio": sharpe_ratio, # 夏普比率
"return_drawdown_ratio": return_drawdown_ratio, # 收益回撤比
# ... 其他基础指标
}
这些指标虽然涵盖了基本面,但在实际策略评估中,我们经常需要问这些问题:
-
这个策略的胜率是多少?
-
平均每笔交易能赚多少?
-
最大连续亏损是多少笔?
-
策略的最优仓位应该是多少?
1.2 增强指标模块设计
我创建了一个专门的增强指标计算模块:
# vnpy_ctastrategy/enhanced_backtesting.py
"""
增强的回测指标计算模块
在原有回测框架基础上增加更多重要的回测指标
"""
def generate_trade_pairs(trades: List[TradeData]) -> List[Dict]:
"""
生成交易配对,用于计算交易级别的统计指标
这是关键函数,将开仓和平仓交易配对
"""
long_trades: List[TradeData] = []
short_trades: List[TradeData] = []
trade_pairs: List[Dict] = []
for trade in trades:
if trade.direction == Direction.LONG:
same_direction = long_trades
opposite_direction = short_trades
else:
same_direction = short_trades
opposite_direction = long_trades
while trade.volume and opposite_direction:
open_trade = opposite_direction[0]
close_volume = min(open_trade.volume, trade.volume)
# 计算持仓时间(以小时为单位)
holding_time_hours = (trade.datetime - open_trade.datetime).total_seconds() / 3600
trade_pair = {
"open_dt": open_trade.datetime,
"open_price": open_trade.price,
"close_dt": trade.datetime,
"close_price": trade.price,
"direction": open_trade.direction,
"volume": close_volume,
"holding_time_hours": holding_time_hours,
}
trade_pairs.append(trade_pair)
# 更新交易量
open_trade.volume -= close_volume
ifnot open_trade.volume:
opposite_direction.pop(0)
trade.volume -= close_volume
if trade.volume:
same_direction.append(trade)
return trade_pairs
1.3 核心增强指标计算
基于交易配对,我们可以计算出许多重要指标。让我详细解释每个指标的含义和重要性:
def calculate_trade_statistics(trade_pairs: List[Dict], size: float) -> Dict:
"""
计算交易级别的统计指标
"""
ifnot trade_pairs:
return default_empty_stats()
# 计算每笔交易的盈亏
trade_pnls = []
holding_times = []
for pair in trade_pairs:
if pair["direction"] == Direction.LONG:
pnl = (pair["close_price"] - pair["open_price"]) * pair["volume"] * size
else:
pnl = (pair["open_price"] - pair["close_price"]) * pair["volume"] * size
trade_pnls.append(pnl)
holding_times.append(pair["holding_time_hours"])
# 基础统计
winning_trades = [pnl for pnl in trade_pnls if pnl > 0]
losing_trades = [pnl for pnl in trade_pnls if pnl < 0]
# 胜率计算
win_rate = len(winning_trades) / len(trade_pnls)
# 平均盈利和亏损
average_win = np.mean(winning_trades) if winning_trades else0
average_loss = abs(np.mean(losing_trades)) if losing_trades else0
# 盈亏比
average_win_loss_ratio = average_win / average_loss if average_loss else0
# 获利因子(总盈利/总亏损)
total_wins = np.sum(winning_trades) if winning_trades else0
total_losses = abs(np.sum(losing_trades)) if losing_trades else0
profit_factor = total_wins / total_losses if total_losses else0
# 凯利公式最优仓位
optimal_position = calculate_kelly_ratio(win_rate, average_win, average_loss)
# 连续盈亏统计
max_consecutive_wins, max_consecutive_losses = calculate_consecutive_stats(trade_pnls)
return {
"win_rate": win_rate,
"average_win_loss_ratio": average_win_loss_ratio,
"optimal_position_ratio": optimal_position,
"profit_factor": profit_factor,
"max_consecutive_wins": max_consecutive_wins,
"max_consecutive_losses": max_consecutive_losses,
# ... 其他指标
}
核心指标详解
胜率
-
含义:盈利交易占总交易次数的比例
-
计算:胜率 = 盈利交易次数 ÷ 总交易次数
-
意义:反映策略预测准确性,但不是越高越好
-
经验值:
-
50%以上:策略有一定预测能力
-
60%以上:较好的策略
-
70%以上:优秀策略(但要警惕过拟合)
-
盈亏比
-
含义:平均每笔盈利交易与平均每笔亏损交易的比值
-
计算:盈亏比 = 平均盈利金额 ÷ 平均亏损金额
-
意义:衡量策略的风险收益特征
-
经验值:
-
1.0以上:盈利能够覆盖亏损
-
1.5以上:较好的风险收益比
-
2.0以上:优秀的风险收益比
-
获利因子
-
含义:总盈利与总亏损的比值
-
计算:获利因子 = 总盈利金额 ÷ 总亏损金额
-
意义:综合考虑胜率和盈亏比的整体盈利能力
-
经验值:
-
1.0以上:策略整体盈利
-
1.5以上:较好的策略
-
2.0以上:优秀策略
-
连续盈亏次数
-
含义:最大连续盈利/亏损的交易次数
-
意义:
-
连续盈利:反映策略的稳定性和趋势捕捉能力
-
连续亏损:评估心理承受能力和资金管理需求
-
-
应用:设置止损策略和仓位管理的重要参考
持仓时间统计
-
含义:每笔交易从开仓到平仓的时间长度
-
统计维度:平均、最大、最小、中位数
-
意义:
-
了解策略的交易频率特征
-
评估资金使用效率
-
判断策略适合的市场环境(震荡/趋势)
-
1.4 凯利公式最优仓位计算
这是一个特别实用的指标,基于数学理论告诉我们最优的资金分配比例:
def calculate_kelly_ratio(win_rate: float, average_win: float, average_loss: float) -> float:
"""计算凯利公式最优仓位"""
ifnot average_loss or average_win <= 0or win_rate <= 0:
return0
p = win_rate # 胜率
q = 1 - p # 败率
b = average_win / average_loss # 赔率
# 凯利公式:f* = (bp - q) / b
f_star = (b * p - q) / b
# 限制仓位在0-1之间,并使用半凯利仓位(更保守)
f_star = max(0, min(1, f_star))
return f_star * 0.5# 半凯利仓位
凯利公式详解
数学原理凯利公式由贝尔实验室的约翰·凯利在1956年提出,用于解决在已知胜率和赔率的情况下,如何分配资金以实现长期收益最大化。
公式解析
-
f* = 最优仓位比例
-
p = 胜率(获胜概率)
-
q = 败率(失败概率,q = 1-p)
-
b = 赔率(平均盈利/平均亏损)
实际意义
-
风险控制:避免过度杠杆导致的破产风险
-
收益优化:在控制风险的前提下最大化长期收益
-
资金管理:提供科学的仓位管理依据
使用注意事项
-
半凯利策略:实际使用中通常采用50%的凯利仓位,更加保守
-
动态调整:随着策略表现的变化,需要定期重新计算
-
市场环境:不同市场环境下的最优仓位可能不同
-
心理因素:理论最优不等于实际可执行,要考虑心理承受能力
实例说明假设某策略:
-
胜率:60%
-
平均盈利:100元
-
平均亏损:50元
-
赔率b = 100/50 = 2
凯利仓位 = (2×0.6 - 0.4) / 2 = 0.4 = 40%
半凯利仓位 = 40% × 0.5 = 20%
这意味着每次交易最好使用20%的资金。
半凯利公式是将标准凯利公式计算出的仓位减半。通过降低仓位比例,可大幅降低极端市场波动下的资金回撤风险。
二、高级风险指标
在传统的夏普比率基础上,我们引入了更精确的风险度量指标。这些指标能够更好地反映策略的真实风险特征。
2.1 索提诺比率
索提诺比率是夏普比率的改进版本,只考虑下行波动,更能反映投资者真正关心的风险:
def calculate_advanced_metrics(daily_df: DataFrame, capital: float, risk_free: float = 0.02, annual_days: int = 240) -> Dict:
"""
计算高级风险指标
"""
if daily_df.empty:
return {}
# 计算日收益率
daily_returns = daily_df["net_pnl"] / capital
# 计算下行波动率(只考虑低于无风险利率的波动)
mar = risk_free / annual_days # 日度最小可接受收益率
downside_returns = []
for daily_return in daily_returns:
downside_diff = daily_return - mar
if downside_diff < 0:
downside_returns.append(downside_diff)
down_std = np.sqrt(np.mean(np.square(downside_returns))) if downside_returns else0
annual_down_std = down_std * np.sqrt(annual_days)
# 索提诺比率
annual_return = daily_returns.mean() * annual_days
if annual_down_std:
sortino_ratio = (annual_return - risk_free) / annual_down_std
else:
sortino_ratio = 0
return {
"sortino_ratio": sortino_ratio,
"annual_down_std": annual_down_std,
}
索提诺比率详解
核心思想传统夏普比率把所有波动都视为风险,但投资者实际上只关心下行风险(亏损的波动)。索提诺比率只计算负收益的波动率,更符合投资者的真实感受。
计算方法
-
分子:超额收益率(策略收益率 - 无风险利率)
-
分母:下行标准差(只计算低于目标收益的波动)
优势对比
|
指标 |
夏普比率 |
索提诺比率 |
|---|---|---|
|
波动率计算 |
全部波动 |
仅下行波动 |
|
风险理解 |
技术性风险 |
投资者感知风险 |
|
适用场景 |
一般评估 |
精确风险评估 |
经验值参考
-
1.0以上:较好的风险调整收益
-
1.5以上:优秀的风险调整收益
-
2.0以上:卓越的风险调整收益
2.2 卡尔马比率
卡尔马比率专注于最大回撤风险,是年化收益率与最大回撤的比值:
# 计算卡尔马比率
max_ddpercent = daily_df["ddpercent"].min() if "ddpercent" in daily_df.columns else 0
calmar_ratio = abs(annual_return * 100 / max_ddpercent) if max_ddpercent else 0
卡尔马比率详解
核心思想卡尔马比率关注的是"为了获得收益,我需要承受多大的最大回撤风险"。这个指标特别适合评估趋势跟踪策略。
计算方法
-
公式:卡尔马比率 = 年化收益率 ÷ 最大回撤百分比
-
示例:年化收益20%,最大回撤10%,卡尔马比率 = 2.0
实际意义
-
风险收益权衡:数值越高,说明承受单位回撤风险获得的收益越多
-
策略比较:在比较不同策略时,卡尔马比率提供了统一的评估标准
-
资金管理:帮助确定可接受的最大回撤水平
经验值参考
-
1.0以上:可接受的风险收益比
-
2.0以上:较好的风险收益比
-
3.0以上:优秀的风险收益比
使用注意
-
适合评估长期策略,短期策略可能失真
-
需要足够长的回测期间才有统计意义
-
与最大回撤的持续时间结合分析更有价值
2.3 EWM夏普比率
传统夏普比率给所有历史数据相同权重,EWM夏普比率给近期数据更高权重:
EWM夏普比率详解
改进思路
-
时效性:近期表现比历史表现更重要
-
适应性:能够更快反映策略性能的变化
-
实用性:更符合实际投资决策的时间偏好
计算特点
-
使用指数加权移动平均计算收益率和波动率
-
近期数据权重更高,远期数据权重逐渐衰减
-
能够更敏感地捕捉策略性能的变化趋势
应用价值
-
策略监控:及时发现策略性能恶化
-
动态调整:为仓位调整提供更及时的信号
-
风险预警:提前识别潜在的风险变化
2.4 综合评分系统
单一指标往往无法全面评估策略优劣,我设计了一个多维度的综合评分系统:
def calculate_comprehensive_rating(statistics: Dict) -> float:
"""
计算综合评分
基于多个指标的加权平均,使用对数变换处理极端值
"""
try:
# 获取关键指标
ewm_sharpe = statistics.get("ewm_sharpe", 0)
max_ddpercent = statistics.get("max_ddpercent", 0)
win_rate = statistics.get("win_rate", 0)
average_win_loss_ratio = statistics.get("average_win_loss_ratio", 0)
calmar_ratio = statistics.get("calmar_ratio", 0)
# 归一化处理(使用对数变换避免极端值)
normalized_sharpe = 0if ewm_sharpe <= 0else np.log1p(ewm_sharpe)
normalized_drawdown = 1 - min(abs(max_ddpercent) / 100, 1)
normalized_winloss = 0if average_win_loss_ratio <= 1else np.log1p(average_win_loss_ratio - 1)
normalized_winrate = 0if win_rate < 0.35else win_rate
normalized_calmar = 0if calmar_ratio <= 0else np.log1p(calmar_ratio)
# 加权综合评分
overall_rating = (
0.35 * normalized_sharpe + # EWM Sharpe权重35%
0.30 * normalized_drawdown + # 最大回撤权重30%
0.20 * normalized_winrate + # 胜率权重20%
0.10 * normalized_winloss + # 盈亏比权重10%
0.05 * normalized_calmar # 卡尔马比率权重5%
)
return overall_rating
except Exception:
return0
综合评分系统详解
设计理念量化交易中,单一指标容易误导判断。比如高胜率可能伴随低盈亏比,高收益可能伴随高回撤。综合评分系统通过多指标加权,提供更全面的策略评估。
权重分配逻辑
|
指标 |
权重 |
选择理由 |
|---|---|---|
|
EWM夏普比率 |
35% |
核心风险调整收益指标,且考虑时效性 |
|
最大回撤控制 |
30% |
风险控制是量化交易的生命线 |
|
胜率 |
20% |
反映策略预测准确性和心理舒适度 |
|
盈亏比 |
10% |
风险收益特征的重要补充 |
|
卡尔马比率 |
5% |
长期风险收益评估的补充 |
归一化处理
对数变换的必要性:
-
问题:不同指标量纲不同,直接加权会被大数值指标主导
-
解决:使用
np.log1p()对数变换,压缩极端值影响 -
好处:保持指标间的相对关系,避免异常值扭曲结果
阈值设计:
-
**胜率阈值35%**:低于此值的策略基本不可用
-
**回撤上限100%**:避免极端回撤策略获得高分
-
盈亏比阈值1.0:低于1的盈亏比没有正贡献
评分解读
|
评分区间 |
策略质量 |
建议 |
|---|---|---|
|
0.8以上 |
优秀策略 |
可考虑实盘,但需验证稳定性 |
|
0.6-0.8 |
良好策略 |
可进一步优化后实盘 |
|
0.4-0.6 |
一般策略 |
需要显著改进 |
|
0.4以下 |
较差策略 |
不建议使用 |
自定义权重根据你的交易风格,可以调整权重:
-
保守型:增加回撤权重至40%,降低夏普权重
-
激进型:增加夏普权重至45%,降低回撤权重
-
稳健型:增加胜率权重至30%,平衡其他指标
使用注意事项
-
相对评估:主要用于策略间比较,不是绝对标准
-
市场环境:不同市场环境下的最优权重可能不同
-
样本充足:需要足够的交易样本才有统计意义
-
定期校准:随着市场变化和经验积累,应定期调整权重
三、时间维度分析
时间维度分析帮助我们理解策略在不同时间周期的表现特征,发现隐藏的规律和风险。
3.1 月度统计分析
月度分析能够揭示策略的长期稳定性:
def calculate_monthly_statistics(trade_pairs: List[Dict], size: float) -> DataFrame:
"""
计算月度统计数据
"""
ifnot trade_pairs:
return DataFrame()
trade_data = []
for pair in trade_pairs:
# 计算盈亏
if pair["direction"] == Direction.LONG:
pnl = (pair["close_price"] - pair["open_price"]) * pair["volume"] * size
else:
pnl = (pair["open_price"] - pair["close_price"]) * pair["volume"] * size
trade_data.append({
"close_dt": pair["close_dt"],
"pnl": pnl
})
# 创建DataFrame并按月分组
trade_df = DataFrame(trade_data)
trade_df["month"] = trade_df["close_dt"].dt.to_period("M")
# 计算每月统计
monthly_stats = trade_df.groupby("month").agg(
total_trades=("pnl", "size"),
win_rate=("pnl", lambda x: (x > 0).sum() / x.size if x.size > 0else0),
total_pnl=("pnl", "sum")
).reset_index()
monthly_stats["win_rate"] = (monthly_stats["win_rate"] * 100).apply(lambda x: f"{x:.2f}%")
return monthly_stats
月度统计分析详解
分析价值
稳定性评估:
-
连续盈利月数:评估策略的持续性
-
最大连续亏损月数:评估最坏情况的持续时间
-
月度胜率分布:了解策略表现的一致性
3.2 半小时区间统计
交易时段分析帮助识别最佳交易窗口和避开不利时段:
def calculate_interval_statistics(trade_pairs: List[Dict], size: float) -> DataFrame:
"""
计算每个半小时交易区间的统计数据
"""
trade_data = []
for pair in trade_pairs:
# 计算盈亏
pnl = calculate_trade_pnl(pair, size)
# 创建半小时区间标识
open_dt = pair["open_dt"]
interval_start = f"{open_dt.hour:02d}:{open_dt.minute // 30 * 30:02d}"
trade_data.append({
"interval_start": interval_start,
"pnl": pnl
})
# 按半小时区间分组统计
trade_df = DataFrame(trade_data)
interval_stats = trade_df.groupby("interval_start").agg(
total_trades=("pnl", "size"),
win_rate=("pnl", lambda x: (x > 0).sum() / x.size if x.size > 0else0),
total_pnl=("pnl", "sum")
).reset_index()
return interval_stats.sort_values(by="total_pnl", ascending=True)
半小时区间统计详解
时段特征分析
**开盘时段 (09:00-10:00)**:
-
特点:波动大,流动性充足
-
机会:捕捉隔夜消息面影响
-
风险:情绪化交易较多,噪音大
**上午时段 (10:00-11:30)**:
-
特点:趋势相对明确
-
机会:跟随主力资金方向
-
风险:可能出现假突破
**午间时段 (13:30-14:00)**:
-
特点:成交量萎缩,波动减小
-
机会:适合震荡策略
-
风险:流动性不足,滑点增大
**下午时段 (14:00-15:00)**:
-
特点:全天最重要的交易时段
-
机会:主力资金活跃,趋势明确
-
风险:竞争激烈,需要快速反应
实际应用示例
最佳交易时段识别:
# 找出盈利最好的时段
best_intervals = interval_stats.nlargest(3, 'total_pnl')
print("最佳交易时段:")
for _, row in best_intervals.iterrows():
print(f"{row['interval_start']}: 盈利{row['total_pnl']:.2f}, 胜率{row['win_rate']:.2%}")
# 找出应该避免的时段
worst_intervals = interval_stats.nsmallest(3, 'total_pnl')
print("\n应避免交易时段:")
for _, row in worst_intervals.iterrows():
print(f"{row['interval_start']}: 亏损{row['total_pnl']:.2f}, 胜率{row['win_rate']:.2%}")
时段过滤策略:
# 实现时段过滤
def should_trade_now(current_time):
"""根据历史统计决定是否应该交易"""
hour = current_time.hour
minute = current_time.minute
interval_key = f"{hour:02d}:{minute // 30 * 30:02d}"
# 获取该时段的历史表现
interval_performance = interval_stats[
interval_stats['interval_start'] == interval_key
]
if interval_performance.empty:
returnFalse
# 只在盈利时段交易
return interval_performance.iloc[0]['total_pnl'] > 0
风险控制:
-
时段仓位:在高风险时段降低仓位
-
止损设置:在波动大的时段设置更严格的止损
-
流动性管理:避免在低流动性时段进行大额交易
四、集成到回测框架
在设计增强功能时,我面临一个重要的选择:是重写整个回测框架,还是在现有框架基础上增强?经过深思熟虑,我选择了后者。这个决定基于几个考虑:
设计原则
-
向后兼容:不能破坏现有用户的代码和工作流
-
渐进增强:新功能作为可选项,用户可以选择性使用
-
最小侵入:尽量减少对原有代码的修改
-
模块化设计:新功能独立成模块,便于维护和测试
4.1 交易配对生成的集成思路
最关键的是在哪个环节生成交易配对。我选择在calculate_result方法中进行,原因是:
-
数据完整性:此时所有交易数据已经生成完毕
-
时机合适:在统计计算之前,为后续增强指标提供数据基础
-
影响最小:不会影响策略的执行逻辑
# 在vnpy_ctastrategy/backtesting.py的calculate_result方法中添加
if results:
self.daily_df = DataFrame.from_dict(results).set_index("date")
# 生成交易配对用于增强统计
# 这里的设计思路是:只有当交易数据存在时才进行配对
# 避免在空数据情况下产生错误
from .enhanced_backtesting import generate_trade_pairs
sorted_trades = sorted(self.trades.values(), key=lambda x: x.datetime)
self.trade_pairs = generate_trade_pairs(sorted_trades)
为什么要排序交易?交易配对算法需要按时间顺序处理交易,确保开仓和平仓的逻辑正确。原始的交易数据可能因为并发或其他原因不是严格按时间排序的。
4.2 统计指标计算的重构思路
原有的calculate_statistics方法主要计算基础指标,我需要在不破坏原有逻辑的前提下,巧妙地插入增强指标的计算。
设计挑战
-
数据依赖:增强指标需要交易配对数据,但原方法没有这个概念
-
输出格式:需要保持原有输出格式,同时增加新的输出内容
-
异常处理:当交易数据不足时,要优雅地降级到基础功能
解决方案我采用了"检查-计算-合并"的三步策略:
# 计算增强交易统计
from .enhanced_backtesting import (
calculate_trade_statistics,
calculate_advanced_metrics,
calculate_monthly_statistics,
calculate_interval_statistics,
calculate_comprehensive_rating
)
# 第一步:初始化空的增强数据结构
trade_statistics = {}
monthly_statistics = DataFrame()
interval_statistics = DataFrame()
advanced_metrics = {}
# 第二步:检查数据可用性,避免在无数据时出错
if hasattr(self, 'trade_pairs') and self.trade_pairs:
trade_statistics = calculate_trade_statistics(self.trade_pairs, self.size)
monthly_statistics = calculate_monthly_statistics(self.trade_pairs, self.size)
interval_statistics = calculate_interval_statistics(self.trade_pairs, self.size)
# 高级指标需要日线数据,单独检查
if positive_balance andnot df.empty:
advanced_metrics = calculate_advanced_metrics(df, self.capital, self.risk_free, self.annual_days)
# 第三步:智能输出 - 只有当数据存在时才输出对应部分
if output and trade_statistics:
self.output("-" * 30)
self.output("增强交易统计指标")
self.output(f"胜率: \t{trade_statistics.get('win_rate', 0):.2%}")
self.output(f"盈亏比: \t{trade_statistics.get('average_win_loss_ratio', 0):.2f}")
self.output(f"获利因子: \t{trade_statistics.get('profit_factor', 0):.2f}")
# ... 更多指标输出
为什么用hasattr检查?hasattr(self, 'trade_pairs')确保只有在交易配对生成成功时才计算增强指标。这样即使增强模块有问题,基础回测功能仍然可用。
输出设计的考虑
-
使用分隔线区分不同类型的指标
-
保持与原有输出格式的一致性
-
采用条件输出,避免空数据时的尴尬显示
五、用户界面的重新设计
在功能实现完成后,我面临另一个挑战:如何让用户友好地使用这些新功能?原有的界面虽然功能完整,但在信息组织和用户体验方面还有提升空间。
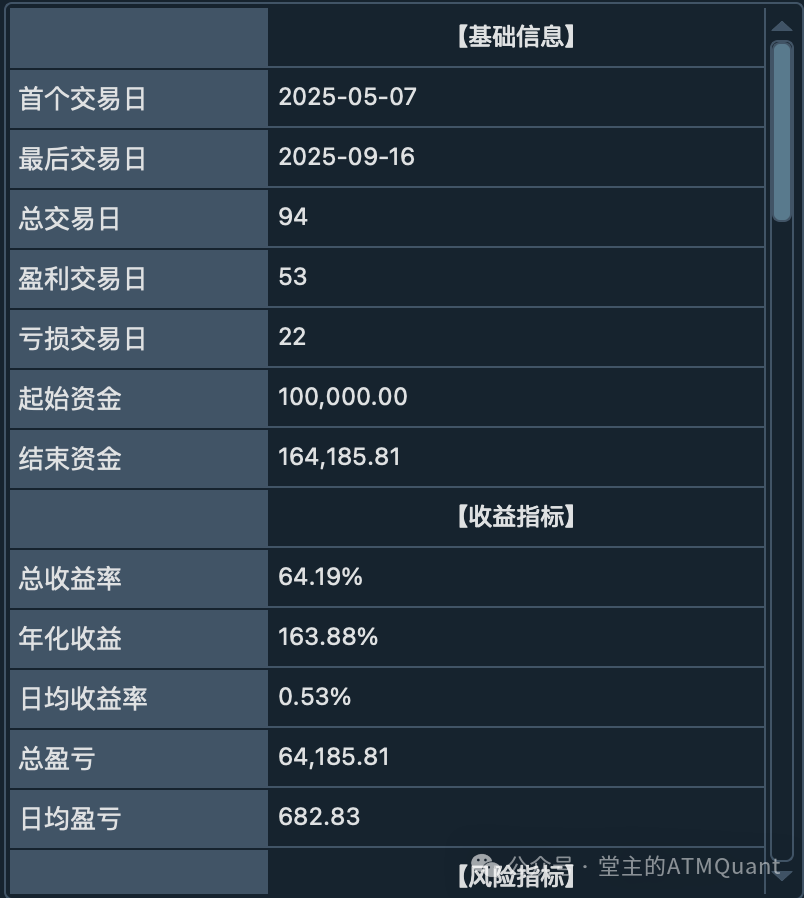
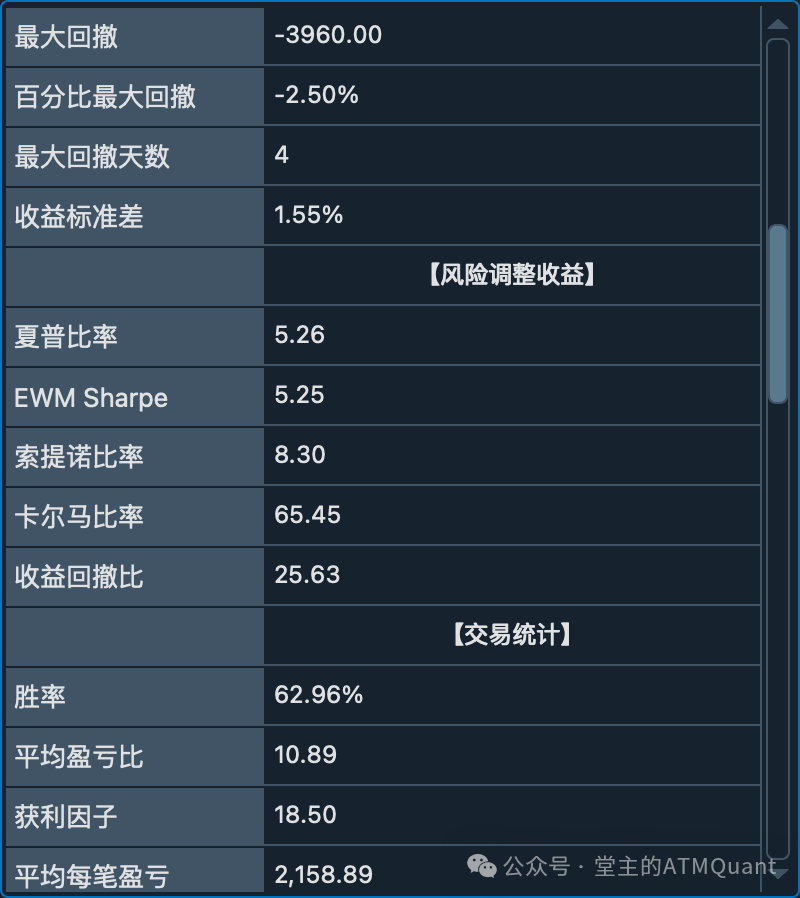
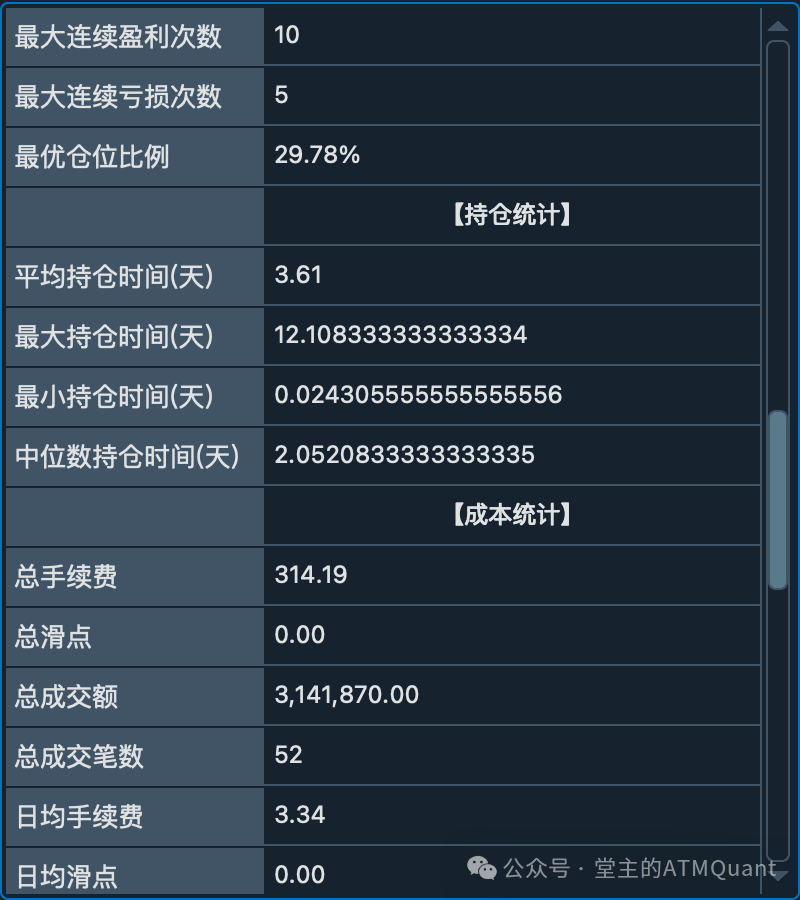
回测指标分组显示界面:包含基础信息、收益指标、风险指标等8个分组
5.1 统计监控器的重新思考
原有界面的问题使用原有界面一段时间后,我发现几个问题:
-
信息过载:30多个指标平铺展示,用户很难快速找到关键信息
-
逻辑混乱:相关指标分散在不同位置,缺乏逻辑分组
-
视觉疲劳:单调的列表形式,缺乏视觉层次
分组设计的灵感我想到了现代软件的设计理念:信息分组和渐进式披露。就像手机设置界面一样,相关功能归类在一起,用户可以快速定位到感兴趣的部分。
实现思路
# vnpy_ctabacktester/ui/enhanced_widget.py
class EnhancedStatisticsMonitor(QtWidgets.QTableWidget):
"""
增强的统计指标监控器
核心改进:按功能逻辑分组显示指标
"""
# 分组设计:将相关指标归类,提高信息查找效率
GROUPED_INDICATORS = {
"【基础信息】": [
("start_date", "首个交易日"),
("end_date", "最后交易日"),
("capital", "起始资金"),
("end_balance", "结束资金"),
],
"【收益指标】": [
("total_return", "总收益率"),
("annual_return", "年化收益"),
("daily_return", "日均收益率"),
],
# ... 其他分组
}
分组逻辑的考虑
-
基础信息:回测的基本参数,用户首先关心的内容
-
收益指标:各种收益率指标,投资者最关注的部分
-
风险指标:回撤、波动率等风险度量
-
交易统计:胜率、盈亏比等交易质量指标
-
持仓统计:持仓时间相关的分析
-
综合评分:最终的策略评估结果
这样的分组让用户可以快速定位到感兴趣的指标类别,提高了使用效率。
5.2 分组界面的技术实现
界面布局的挑战实现分组显示比想象中复杂。主要挑战是:
-
动态行数计算:需要为每个分组标题预留行
-
标题行样式:分组标题需要与数据行区分开
-
数据映射:保持原有的数据绑定逻辑不变
解决方案的演进我尝试了几种方案:
方案一:合并单元格最初想用单元格合并来实现分组标题,但发现Qt的合并单元格在数据更新时容易出现显示问题。
方案二:分离标题和数据考虑过将分组标题放在垂直表头,数据放在单元格,但这样分组效果不够明显。
方案三:独立标题行(最终采用)为每个分组创建独立的标题行,在数据单元格中显示分组名称:
def init_ui(self) -> None:
# 计算总行数(包括分组标题行)
total_rows = sum(len(items) + 1for items in self.GROUPED_INDICATORS.values())
self.setRowCount(total_rows)
current_row = 0
for group_name, group_items in self.GROUPED_INDICATORS.items():
# 创建分组标题行
group_cell = QtWidgets.QTableWidgetItem()
group_cell.setText(group_name) # 在数据单元格中显示分组名称
group_cell.setTextAlignment(QtCore.Qt.AlignCenter) # 居中显示
group_cell.setFlags(QtCore.Qt.ItemIsEnabled) # 不可选择
font = group_cell.font()
font.setBold(True) # 加粗字体
group_cell.setFont(font)
self.setItem(current_row, 0, group_cell)
current_row += 1
# 创建分组内的数据行
for key, name in group_items:
cell = QtWidgets.QTableWidgetItem()
self.setItem(current_row, 0, cell)
self.cells[key] = cell # 保持原有的数据绑定
current_row += 1
设计细节的考虑
-
字体加粗:分组标题使用加粗字体,增强视觉层次
-
居中对齐:分组标题居中显示,与左对齐的数据行形成对比
-
不可选择:分组标题行设为不可选择,避免用户误操作
-
向后兼容:保持
self.cells[key]的映射关系,确保数据更新逻辑不变
5.3 参数优化窗口的用户体验改进
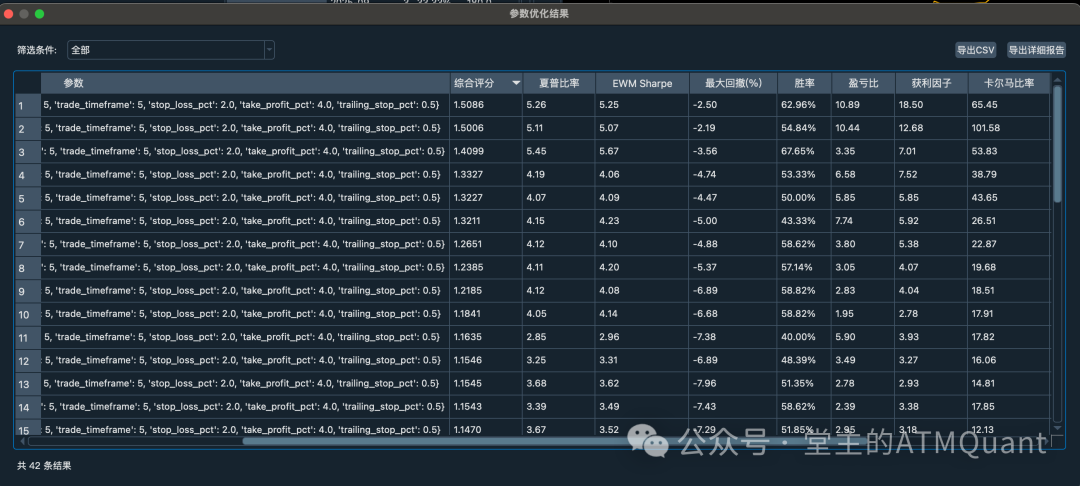
参数优化结果窗口
原有优化窗口的痛点在实际使用参数优化功能时,我发现了几个明显的痛点:
-
信息过载:几百个参数组合的结果,用户很难快速找到好的策略
-
缺乏筛选:只能手动滚动查看,没有智能筛选和排序功能
-
导出困难:无法导出筛选后的结果,不便于后续分析
用户需要的不是看到所有数据,而是快速找到符合条件的数据。
class EnhancedOptimizationResultMonitor(QtWidgets.QDialog):
"""
增强的参数优化结果监控器
核心改进:智能筛选和批量导出
"""
def init_ui(self) -> None:
# 筛选条件的层次设计
self.filter_combo = QtWidgets.QComboBox()
self.filter_combo.addItems([
# 第一层:基础筛选
"全部",
"综合评分>0.5",
"综合评分>0.7",
# 第二层:单指标筛选
"夏普比率>1",
"夏普比率>1.5",
"最大回撤<5%",
"最大回撤<10%",
"胜率>60%",
"胜率>70%",
"获利因子>1.5",
"获利因子>2.0",
"盈亏比>1.5",
"盈亏比>2.0",
# 第三层:组合条件筛选
"优质策略(综合评分>0.6且夏普>1且回撤<10%)",
"高收益策略(总收益>20%且夏普>1)",
"低风险策略(最大回撤<5%且夏普>0.5)"
])
筛选条件的实用考虑
-
综合评分筛选:快速过滤掉明显不合格的策略
-
单指标筛选:针对特定需求(如低回撤、高胜率)
-
组合条件:预设的常用策略类型,满足不同风险偏好
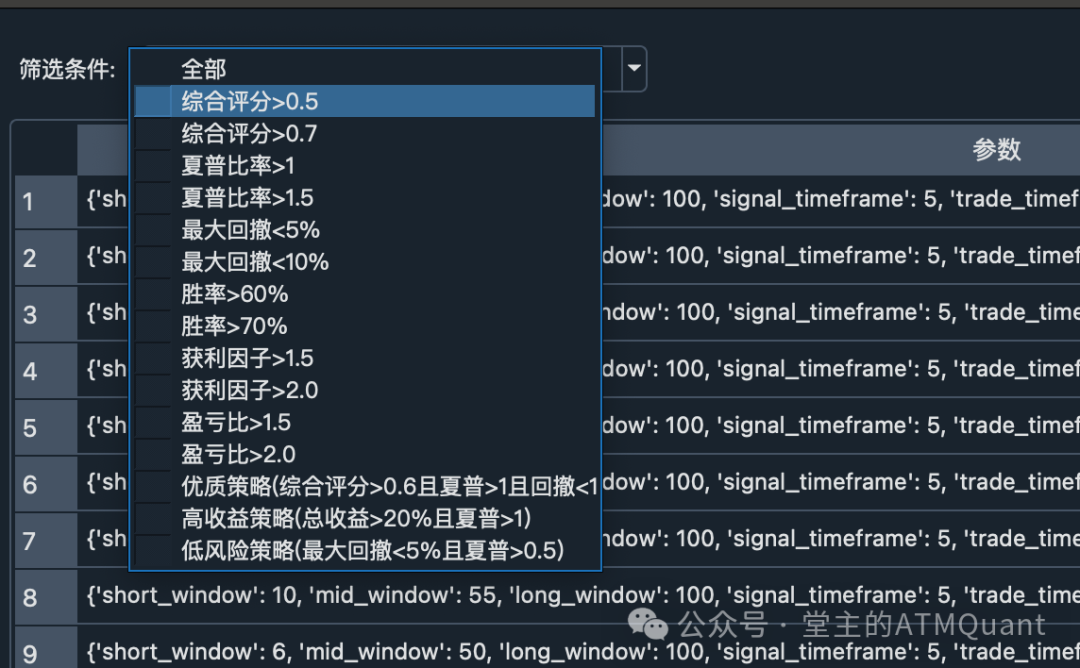
筛选条件界面
增强的参数优化结果窗口,支持16种筛选条件和详细报告导出
5.4 智能筛选的技术实现
数据解析的挑战实现筛选功能时遇到的第一个挑战是数据解析。表格中的数据是字符串格式,包含百分号、逗号等格式化字符,需要正确解析为数值才能进行比较。
容错设计的重要性在实际使用中,可能出现数据缺失、格式异常等情况。我采用了多层容错设计:
def apply_filter(self):
"""应用筛选条件 - 重点关注容错和性能"""
filter_text = self.filter_combo.currentText()
for row in range(self.table.rowCount()):
try:
# 数据提取:安全地获取各列数据
rating = float(self.table.item(row, 1).text()) if self.table.item(row, 1) else0
sharpe = float(self.table.item(row, 2).text()) if self.table.item(row, 2) else0
# 处理百分比格式的数据
win_rate_text = self.table.item(row, 5).text() if self.table.item(row, 5) else"0%"
win_rate = float(win_rate_text.replace('%', '')) / 100if'%'in win_rate_text else float(win_rate_text)
# 处理回撤数据(可能是负数)
max_dd = abs(float(self.table.item(row, 4).text())) if self.table.item(row, 4) else100
# 复合条件筛选:体现业务逻辑
if filter_text == "优质策略(综合评分>0.6且夏普>1且回撤<10%)":
should_show = rating > 0.6and sharpe > 1and max_dd < 10
elif filter_text == "高收益策略(总收益>20%且夏普>1)":
total_return = float(self.table.item(row, 10).text()) if self.table.item(row, 10) else0
should_show = total_return > 20and sharpe > 1
elif filter_text == "低风险策略(最大回撤<5%且夏普>0.5)":
should_show = max_dd < 5and sharpe > 0.5
# ... 其他筛选条件
except (ValueError, AttributeError):
# 容错处理:数据异常时隐藏该行
should_show = False
self.table.setRowHidden(row, not should_show)
筛选逻辑的业务考虑每个筛选条件都体现了实际的业务需求:
-
优质策略:平衡收益、风险和稳定性的综合考虑
-
高收益策略:适合风险承受能力强的投资者
-
低风险策略:适合保守型投资者
5.5 完整的控制台输出
现在运行回测后,控制台会显示完整的增强统计信息:
# 运行回测示例
from vnpy_ctastrategy import BacktestingEngine
from datetime import datetime
# 创建回测引擎并运行
engine = BacktestingEngine()
engine.set_parameters(
vt_symbol="IF88.CFFEX",
interval="1m",
start=datetime(2023, 1, 1),
end=datetime(2023, 12, 31),
rate=0.0001,
slippage=0,
size=300,
pricetick=0.2,
capital=1000000
)
engine.add_strategy(MyStrategy, {})
engine.load_data()
engine.run_backtesting()
# 计算结果(现在包含所有增强指标)
df = engine.calculate_result()
statistics = engine.calculate_statistics(output=True) # 设置为True显示详细输出
实际控制台输出效果:
开始计算策略统计指标
------------------------------
首个交易日: 2025-05-07
最后交易日: 2025-09-16
总交易日: 94
盈利交易日: 53
亏损交易日: 22
起始资金: 100,000.00
结束资金: 164,185.81
总收益率: 64.19%
年化收益: 163.88%
最大回撤: -3,960.00
百分比最大回撤: -2.50%
最大回撤天数: 4
总盈亏: 64,185.81
总手续费: 314.19
总滑点: 0.00
总成交金额: 3,141,870.00
总成交笔数: 52
日均盈亏: 682.83
日均手续费: 3.34
日均滑点: 0.00
日均成交金额: 33,424.15
日均成交笔数: 0.55
日均收益率: 0.53%
收益标准差: 1.55%
Sharpe Ratio: 5.26
EWM Sharpe: 5.25
收益回撤比: 25.63
------------------------------
增强交易统计指标
胜率: 62.96%
盈亏比: 10.89
获利因子: 18.50
平均每笔交易盈亏: 2158.89
最大连续盈利次数: 10
最大连续亏损次数: 5
最优仓位比例: 29.78%
平均持仓时间: 3.61天
最大持仓时间: 12.11天
最小持仓时间: 0.02天
中位数持仓时间: 2.05天
索提诺比率: 8.30
卡尔马比率: 65.45
------------------------------
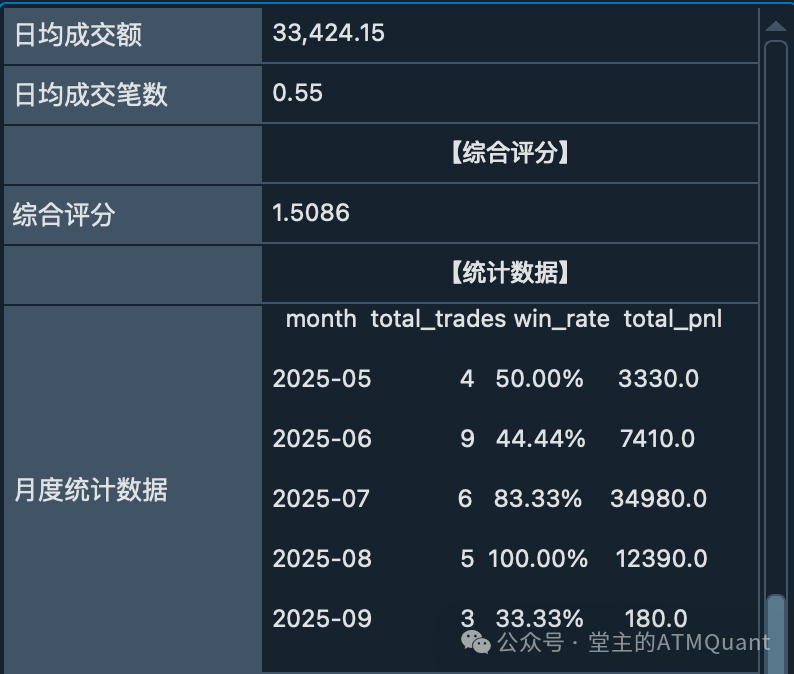
月度统计数据
month total_trades win_rate total_pnl
2025-05 4 50.00% 3330.0
2025-06 9 44.44% 7410.0
2025-07 6 83.33% 34980.0
2025-08 5 100.00% 12390.0
2025-09 3 33.33% 180.0
------------------------------
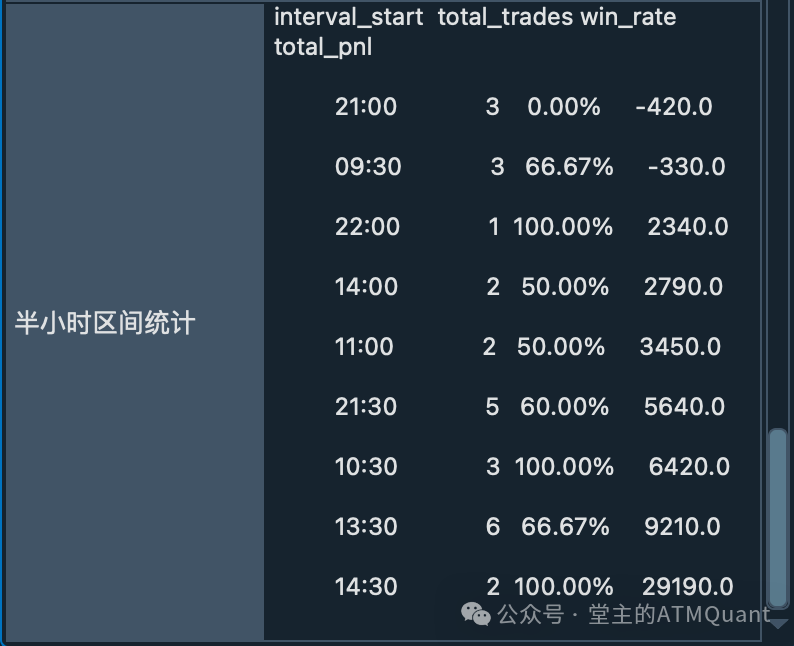
半小时区间统计数据
interval_start total_trades win_rate total_pnl
21:00 3 0.00% -420.0
09:30 3 66.67% -330.0
22:00 1 100.00% 2340.0
14:00 2 50.00% 2790.0
11:00 2 50.00% 3450.0
21:30 5 60.00% 5640.0
10:30 3 100.00% 6420.0
13:30 6 66.67% 9210.0
14:30 2 100.00% 29190.0
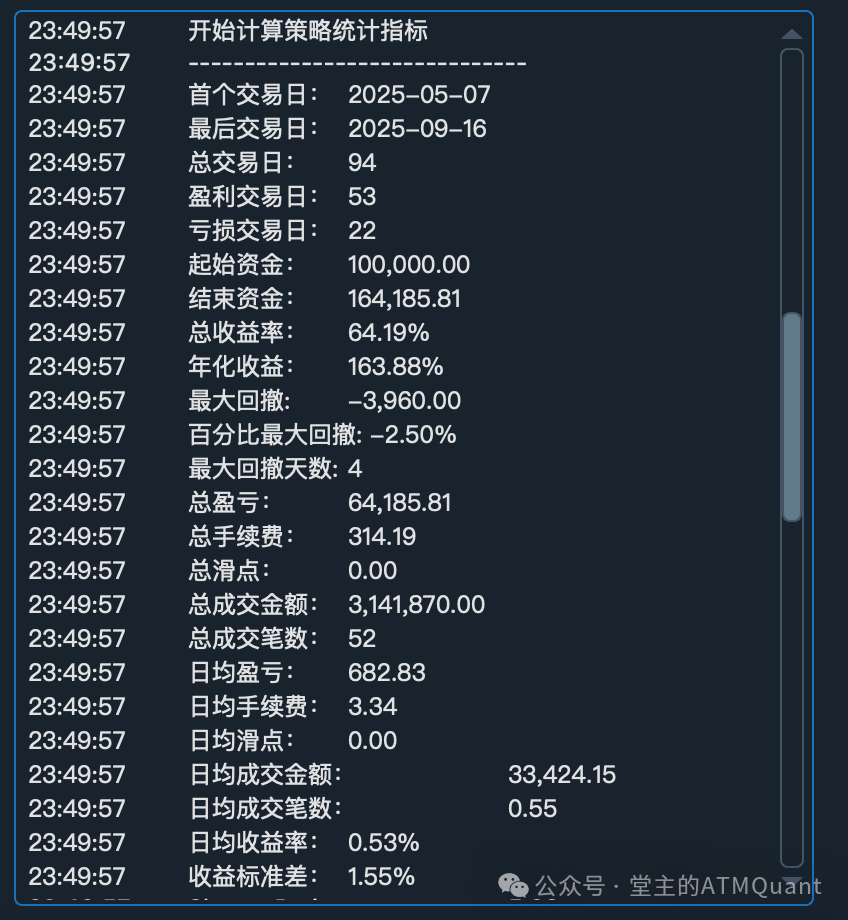
控制台输出效果
完整的控制台输出,包含增强交易统计、月度统计和区间统计数据
六、总结
6.1 应用价值
策略评估更全面
-
多维度分析:从收益、风险、交易质量等多角度评估
-
时间维度洞察:发现策略在不同时间段的表现规律
-
风险量化:更精确的风险指标帮助控制回撤
参数优化更高效
-
快速筛选:16种筛选条件快速找到优秀参数
-
批量分析:支持大量参数组合的批量分析
-
结果导出:便于进一步分析和记录
交易决策更科学
-
仓位指导:凯利公式提供科学的仓位建议
-
时机把握:区间统计帮助选择最佳交易时段
-
风险控制:连续亏损统计帮助设置止损策略
实际开发建议
基于我的实际开发和使用经验,给大家几个建议:
1. 指标权重要合理
综合评分中各指标的权重需要根据你的交易风格调整。如果你更注重稳定性,可以增加最大回撤的权重;如果追求收益,可以增加夏普比率的权重。
2. 不要过度拟合指标
虽然指标越多越全面,但不要为了追求完美指标而过度拟合历史数据。记住,指标只是参考,实际交易中的执行才是关键。
3. 重视交易成本
在计算各项指标时,一定要充分考虑手续费和滑点。很多看起来很好的策略,加上交易成本后可能就不那么亮眼了。
4. 定期更新指标体系
随着对量化交易理解的深入,你可能会发现新的有用指标。保持开放的心态,不断完善你的指标体系。
下一步计划
在下一篇文章中,我们将继续优化回测框架:
-
导出功能增强:CSV导出所有回测参数、详细参数报告生成
-
AI参数分析:让AI帮助分析回测报告,自动识别策略优势和风险点
-
可视化图表:集成滚动夏普比率图、持仓时间分布直方图等专业图表
写在最后
经过这次深入的回测框架优化,我们成功实现了一套完整的增强回测系统。这为我们后续的工作奠定了坚实基础:
-
实盘交易:回测验证的策略可以更自信地投入实盘
-
风险管理:丰富的风险指标为风控系统提供数据支撑
-
策略研发:完善的评估体系加速新策略的开发迭代
记住,工具再好也只是工具,关键是要理解每个指标背后的含义,并结合实际市场情况来判断策略的优劣。数据不会说谎,但解读数据需要经验和智慧。
完整代码获取
本文涉及的新代码文件:
-
vnpy_ctastrategy/enhanced_backtesting.py- 增强指标计算核心 -
vnpy_ctabacktester/ui/enhanced_widget.py- 增强UI组件
本文是《以AI量化为生》系列文章的第八篇,完整代码已开源至GitHub:https://github.com/seasonstar/atmquant
本文内容仅供学习交流,不构成任何投资建议。交易有风险,投资需谨慎。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)