程序员实战:LangChain 父文档检索器破解 “精准匹配与信息完整” 难题
本文介绍了LangChain的父文档检索器(ParentDocumentRetriever)如何通过"子文档检索+父文档召回"的双层架构解决RAG系统中的信息碎片化问题。该方案将文档拆分为父文档(保留完整上下文)和子文档(聚焦特定主题),在检索时先通过子文档精准匹配,再召回对应的父文档提供完整信息。文章详细讲解了原理、代码实现和优化策略,包括文档拆分参数调优、存储方案选择等,帮
在 RAG(检索增强生成)系统开发中,程序员常陷入两难:将文档拆分为小片段(子文档),虽能提升检索匹配精度(关键词 / 语义更聚焦),却易丢失上下文导致 “信息碎片化”;保留完整文档(父文档),虽能提供全面信息,却因内容冗余降低检索相关性。LangChain 的父文档检索器(Parent Document Retriever)通过 “子文档检索 + 父文档召回” 的双层架构,完美平衡 “匹配准” 与 “信息全” 的核心诉求。本文结合代码实例,从原理、实现到优化,详解这一检索方案的落地全流程。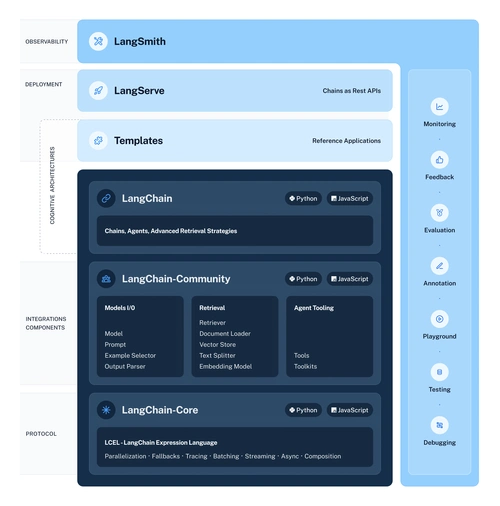
核心原理:父子文档架构如何平衡 “准” 与 “全”
父文档检索器的核心逻辑是 “拆分 - 索引 - 检索 - 聚合” 四步走,通过将文档拆分为 “父文档(完整上下文)” 与 “子文档(聚焦片段)”,分别承担 “信息完整” 与 “精准匹配” 的角色,从架构层面解决传统检索的矛盾。
1. 文档拆分:父子文档的分层设计
- 父文档:保留原始文档的完整结构(如一篇文章、一个章节),包含完整的上下文信息,解决 “信息不全” 问题,但因内容量大,直接检索时易与查询词匹配偏差。
- 子文档:将父文档拆分为更小的片段(如段落、句子组),每个子文档聚焦特定主题,关键词 / 语义更突出,解决 “匹配不准” 问题,但单独使用会丢失上下文关联。
LangChain 通过指定不同的拆分规则实现父子文档生成,例如:将一篇 5000 字的技术文档(父文档)拆分为 10 个 500 字的子文档,子文档用于构建检索索引,父文档存储备用,检索时先通过子文档找到匹配项,再召回对应的父文档作为生成答案的完整上下文。
2. 检索流程:“子文档匹配 + 父文档召回” 双阶段机制
传统检索直接返回匹配的文档片段,而父文档检索器分为两步:
- 子文档精准匹配:以子文档为单位构建向量索引,接收用户查询时,先检索与查询词语义最相关的子文档(匹配精度高);
- 父文档完整召回:根据匹配到的子文档,关联并召回其对应的父文档(获取完整上下文),确保生成答案时拥有足够的信息支撑。
这一流程既避免了 “子文档碎片化导致信息缺失”,又解决了 “父文档冗余导致匹配偏差”,其核心优势可通过下图直观体现:
传统检索痛点 父文档检索器解决方案
├─ 小片段:匹配准但信息缺 → 子文档:负责精准匹配
└─ 完整文档:信息全但匹配偏 → 父文档:负责提供完整上下文
全流程代码实现:从文档拆分到检索落地
LangChain 已封装ParentDocumentRetriever核心类,程序员只需按 “文档加载→父子拆分→检索器初始化→检索调用” 四步即可快速实现,以下是基于最新 LangChain 0.1.x 版本的完整代码示例。
1. 环境准备与依赖安装
首先安装所需依赖,确保包含 LangChain 核心库、文档处理工具及向量数据库(以 FAISS 为例,轻量且适合本地开发):
# 安装核心依赖
pip install langchain==0.1.10 langchain-community==0.0.24
# 安装文档加载与拆分工具
pip install python-dotenv pypdf # pypdf用于PDF文档加载
# 安装向量数据库与嵌入模型
pip install faiss-cpu # CPU版本,GPU版本为faiss-gpu
pip install sentence-transformers # 用于文本嵌入
2. 文档加载与父子拆分实现
使用RecursiveCharacterTextSplitter分别定义父文档与子文档的拆分规则,核心是控制chunk_size(片段长度)与chunk_overlap(重叠长度),确保子文档聚焦且父文档完整:
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.retrievers import ParentDocumentRetriever
def init_parent_child_splitter():
"""初始化父子文档拆分器"""
# 1. 父文档拆分器:拆分粒度大,保留完整上下文(如每个父文档1500字符)
parent_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500, # 父文档长度
chunk_overlap=150, # 父文档间重叠长度(保持连贯性)
length_function=len # 长度计算方式(字符数)
)
# 2. 子文档拆分器:拆分粒度小,聚焦特定主题(如每个子文档300字符)
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=30,
length_function=len
)
return parent_splitter, child_splitter
# 测试文档加载与拆分
if __name__ == "__main__":
# 加载示例文档(可替换为PDF、Docx等格式,需对应Loader)
loader = TextLoader("technical_document.txt", encoding="utf-8")
documents = loader.load()
print(f"原始文档数量:{len(documents)}")
print(f"原始文档总字符数:{sum(len(doc.page_content) for doc in documents)}")
# 初始化拆分器
parent_splitter, child_splitter = init_parent_child_splitter()
# 生成父文档(按1500字符拆分)
parent_documents = parent_splitter.split_documents(documents)
print(f"父文档数量:{len(parent_documents)}")
print(f"父文档平均字符数:{sum(len(doc.page_content) for doc in parent_documents)/len(parent_documents):.0f}")
# 为每个父文档生成子文档(按300字符拆分)
child_documents = []
for parent_doc in parent_documents:
# 为子文档添加父文档ID元数据,用于后续关联
childs = child_splitter.split_documents([parent_doc])
for child in childs:
child.metadata["parent_id"] = id(parent_doc) # 用内存ID暂代,生产环境用唯一标识
child_documents.extend(childs)
print(f"子文档数量:{len(child_documents)}")
print(f"子文档平均字符数:{sum(len(doc.page_content) for doc in child_documents)/len(child_documents):.0f}")
3. 父文档检索器初始化与核心调用
LangChain 的ParentDocumentRetriever已封装 “子文档索引构建→匹配→父文档召回” 全流程,只需传入向量存储(用于子文档索引)、父子文档拆分器及父文档存储(用于召回完整上下文)即可:
def init_parent_document_retriever(parent_documents, child_documents, parent_splitter, child_splitter):
"""初始化父文档检索器"""
# 1. 初始化嵌入模型(用于子文档向量生成)
embeddings = HuggingFaceEmbeddings(
model_name="all-MiniLM-L6-v2", # 轻量高效,适合本地部署
model_kwargs={"device": "cpu"}, # 支持GPU("cuda:0")加速
encode_kwargs={"normalize_embeddings": True} # 向量归一化,提升检索精度
)
# 2. 构建子文档向量数据库(用于精准匹配)
# 注意:仅子文档需要构建向量索引,父文档通过元数据关联召回
vector_store = FAISS.from_documents(child_documents, embeddings)
# 3. 初始化父文档存储(用于存储完整父文档,LangChain提供多种存储方式)
# 此处使用InMemoryStore(内存存储,适合测试;生产环境可用Chroma、PostgreSQL等)
from langchain.storage import InMemoryStore
parent_store = InMemoryStore()
# 4. 为父文档存储添加数据(key为父文档ID,value为父文档对象)
for parent_doc in parent_documents:
parent_store.mset([(str(id(parent_doc)), parent_doc)]) # 用父文档ID作为key
# 5. 初始化父文档检索器
retriever = ParentDocumentRetriever(
vectorstore=vector_store, # 子文档向量存储(负责匹配)
docstore=parent_store, # 父文档存储(负责召回完整上下文)
child_splitter=child_splitter, # 子文档拆分器(如需动态拆分时使用)
parent_splitter=parent_splitter, # 父文档拆分器(如需动态拆分时使用)
id_key="parent_id" # 子文档元数据中关联父文档ID的字段名
)
# 6. (可选)手动添加文档到检索器(若后续需动态更新文档)
# retriever.add_documents(documents=parent_documents, ids=[str(id(doc)) for doc in parent_documents])
return retriever
# 测试检索器核心功能
if __name__ == "__main__":
# (承接上文)加载文档并拆分父子文档
loader = TextLoader("technical_document.txt", encoding="utf-8")
documents = loader.load()
parent_splitter, child_splitter = init_parent_child_splitter()
parent_documents = parent_splitter.split_documents(documents)
# 生成带父文档ID的子文档(代码同上文)
child_documents = []
for parent_doc in parent_documents:
childs = child_splitter.split_documents([parent_doc])
for child in childs:
child.metadata["parent_id"] = str(id(parent_doc)) # 注意转为字符串,与父文档存储key一致
child_documents.extend(childs)
# 初始化父文档检索器
retriever = init_parent_document_retriever(
parent_documents=parent_documents,
child_documents=child_documents,
parent_splitter=parent_splitter,
child_splitter=child_splitter
)
# 执行检索:查询“LangChain检索器如何解决信息碎片化问题”
query = "LangChain检索器如何解决信息碎片化问题"
print(f"\n检索查询:{query}")
# 核心调用:检索返回的是完整父文档(而非子文档)
retrieved_docs = retriever.get_relevant_documents(query)
# 输出检索结果
print(f"\n匹配到的父文档数量:{len(retrieved_docs)}")
for i, doc in enumerate(retrieved_docs, 1):
print(f"\n=== 父文档 {i} ===")
print(f"父文档ID:{id(doc)}")
print(f"文档来源:{doc.metadata.get('source', '未知')}")
print(f"文档长度:{len(doc.page_content)}字符")
print(f"文档内容(前500字符):{doc.page_content[:500]}...")
# 验证:找到该父文档对应的子文档(查看匹配的子文档)
matched_childs = [c for c in child_documents if c.metadata["parent_id"] == str(id(doc))]
print(f"该父文档包含子文档数量:{len(matched_childs)}")
if matched_childs:
print(f"匹配的子文档内容(示例):{matched_childs[0].page_content}")
优化与实战:让检索器适配生产场景
基础版本的父文档检索器需结合业务场景优化,重点解决 “拆分参数调优”“存储选型”“性能提升” 三大问题,确保在生产环境中既保持匹配精度,又具备高可用性。
1. 拆分参数调优:根据文档类型动态调整
父子文档的chunk_size需根据文档内容密度调整,避免 “过细拆分导致上下文断裂” 或 “过粗拆分导致匹配偏差”。以下是不同场景的参数配置建议及代码实现:
def get_dynamic_splitter(document_type: str):
"""根据文档类型动态返回拆分器参数"""
if document_type == "technical": # 技术文档(密度高,需细分子文档)
return {
"parent": {"chunk_size": 2000, "chunk_overlap": 200},
"child": {"chunk_size": 250, "chunk_overlap": 25}
}
elif document_type == "news": # 新闻文档(叙事性,子文档可稍长)
return {
"parent": {"chunk_size": 3000, "chunk_overlap": 300},
"child": {"chunk_size": 400, "chunk_overlap": 40}
}
elif document_type == "legal": # 法律文档(严谨性,父文档需完整)
return {
"parent": {"chunk_size": 5000, "chunk_overlap": 500},
"child": {"chunk_size": 300, "chunk_overlap": 30}
}
else: # 默认配置
return {
"parent": {"chunk_size": 1500, "chunk_overlap": 150},
"child": {"chunk_size": 300, "chunk_overlap": 30}
}
# 动态初始化拆分器
if __name__ == "__main__":
document_type = "technical" # 根据实际文档类型传入
splitter_config = get_dynamic_splitter(document_type)
# 按动态配置创建拆分器
parent_splitter = RecursiveCharacterTextSplitter(
chunk_size=splitter_config["parent"]["chunk_size"],
chunk_overlap=splitter_config["parent"]["chunk_overlap"],
length_function=len
)
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=splitter_config["child"]["chunk_size"],
chunk_overlap=splitter_config["child"]["chunk_overlap"],
length_function=len
)
print(f"为{document_type}类型文档创建拆分器:")
print(f"父文档:{splitter_config['parent']}")
print(f"子文档:{splitter_config['child']}")
2. 存储选型:从测试到生产的存储方案升级
测试阶段使用的InMemoryStore(内存存储)不支持持久化,生产环境需替换为分布式存储,以下是两种常用方案的代码实现:
方案 1:使用 Chroma 作为父文档存储(轻量级分布式)
def init_chroma_parent_store(parent_documents):
"""使用Chroma作为父文档存储(支持持久化)"""
from langchain_community.vectorstores import Chroma
from langchain.storage import ChromaStore
# 初始化Chroma存储(父文档存储无需嵌入,用空嵌入模型)
empty_embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
chroma_db = Chroma(
collection_name="parent_documents",
persist_directory="./chroma_parent_store", # 持久化目录</doubaocanvas>

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)