2025年AI保研复试八股文~专业+数学,这两天还在更新中
正交矩阵:=Orthogonal Matrix,是个方阵,他的行向量或列向量都得两两正交,每个向量长度都是1,构成一组标准正交基QTQI单位矩阵Q^TQ=I(单位矩阵)QTQI单位矩阵,下面为为什么结果会是单位矩阵的原因,其实就说对角线上的值就是列向量和列向量自己的内积,长度是1所以结果是1(因为内积是投影后的长度)正定矩阵:一定是对称矩阵(关于对角线对称),所有特征值都大于0,所有主子式(是从左
高频八股
线代的特征值,线性相关,概统的贝叶斯,中心极限定理,计网的TCP,UDP,操作系统的进程与线程等等
专业课AI
数据结构
树、图、查找、排序
>> 1.什么是数据结构?三要素?
数据结构是相互之间存在一种或多种关系的数据元素的集合(其实就是要怎么选择合适的方式表示这些数据吧)
三要素:逻辑结构(线性、非线性)、存储结构(链式、顺序)、数据的运算
>> 2.哈希表?栈和队列?
- 哈希表
是通过键🔑直接访问值得数据结构,实现 O ( 1 ) O(1) O(1)查找插入删除 - 栈
是先进后出得数据结构,像是个容器,底下是封闭的 - 队列
是先进先出得数据结构,是像消化道,头尾都敞开的,队头删除、队尾插入
>> 2.常见的排序算法
- 插入排序(e.g.整理麻将牌):
就是从前往后,每往后拿一个放到排好的里面,都要保证码好的牌顺序正确,挺麻烦的
⏱️时间复杂度: O ( n 2 ) O(n^2) O(n2)稳定 - 冒泡排序(e.g.比奇堡比高矮):
从头到尾,依次两两比较大小,大的往后挪,每一轮会下沉冒出一个最大值到最后。
⏱️时间复杂度: O ( n 2 ) O(n^2) O(n2)稳定 - 选择排序(从前往后排最小的):
每轮找出剩下里面最小的往前放
⏱️时间复杂度: O ( n 2 ) O(n^2) O(n2) - 快速排序(e.g.外国人的魔性快排舞蹈、正经快排过程):
每次都选轴点pivot,有双指针一头一尾,先从尾巴开始找,直到找到轴点的数小的,二者换位置,再从头找直到找到比轴点大的,就这么一直左右切换,直到左右指针相遇。然后在轴点的前面继续重复,后面继续重复(这里的下一轮过程记得注意一下。)
⏱️时间复杂度: 最好/平均 情况 O ( n log n ) O(n \log n) O(nlogn),最坏也是 O ( n 2 ) O(n^2) O(n2)
缺点:不稳定,坏:两边不平衡每次只能划出一个元素 - 希尔排序(e.g.希尔演示过程):
shell发明的,很简单,就是分很多组,排序总个数/2/4/…。直到1,前面排过之后,1的时候就很快了。有一个步长的概念
⏱️时间复杂度: 很不稳定 - 归并排序(两个排好的序列很好合并):
分治思想,其实就是把序列一直切分到最细,然后两两排,往上合并
⏱️时间复杂度: O ( n log n ) O(n \log n) O(nlogn)稳定
缺点:空间复杂度高 - 堆排序:
利用完全二叉树,然后每次在根节点放 − ∞ -∞ −∞,再把树的最大移上去,就是此刻最大的,依次找下去,从大到小排
>> 3.【树】如何构建哈夫曼树?二叉树?满二叉树?完全二叉树?
- 哈夫曼树
是树的带权路径最短的二叉树=最优树🎋,一个堆数可以构造成各种形式的二叉树,理论上把数值大的放在靠近根节点,带权路径长度就越短。自底向上
哈夫曼树的结构不唯一,创建会新增加n-1个节点,一共2n-1个节点,所有节点都变成了叶子节点- 树的带权路径长度WPL = 叶子节点的
值x 节点路径长度(叶子到根有几条边) - b站教程
- 树的带权路径长度WPL = 叶子节点的
- 二叉树
严格区分左右子树 - 满二叉树
除了叶子节点其他所有都是度为2,并且叶子节点全部都在同一层。(就是很规整丰满 - 完全二叉树——堆
叶子节点从左到右不间断,可以不满
>>4.树的三种遍历方式?
在DFS深度中,有3种遍历方式:前序、中序、后序。遍历的顺序如下:
- 前序: 根 → 左 → 右 根\to左\to右 根→左→右
- 中序: 左 → 根 → 右 左\to根\to右 左→根→右
- 后序: 左 → 右 → 根 左\to右\to根 左→右→根
已知前+中/中+后(中必须有),就可以唯一确定一颗二叉树
>> 4.贪心算法?动态规划?分治法?
都是分治法的思想,把大问题拆成几个子问题,用子问题的答案汇聚出大问题的。子问题之间是有交集的
- 贪心算法
是局部最优解,每一步都是当下最好的选择,做选择时不会回头修改之前的决策,直到结束。如最小生成树(prim/kruskal)。 - 动态规划
是全局最优,斐波那契数列会涉及重复计算。子问题重叠的情况,从小到大计算子问题的解,并且存起来 - 分治法
把大问题拆成独立子问题,分别求解子问题后合并得到原问题的答案。如归并排序、快速排序
>> 5.【图】最短路径算法?(Dijkstra算法?Floyd算法?)最小生成树算法?(Prim算法?Kruskal算法?)
- 最短路径算法
- Dijkstra算法 = 迪杰斯特拉
外卖员送外卖
求出有权无向图里面的某一个点到其他任意点的最短路径问题,基于贪心算法,比较并一直更新从村口到这个镇里所有人家的所有最短路径 - Floyd算法 = 弗洛伊德
求有权有向图里面任意两点的最短路径,基于动态规划。不断比较 起点-终点 和 起点-n个中转点-终点的最小
- Dijkstra算法 = 迪杰斯特拉
- 最小生成树算法:
分为Prim(普利姆)算法和Kruskal(克鲁斯卡尔)。是图里的应用,在无向图里面找出一个边权和最小的树🎋=花最小的成本来联通所有边。边权和一定唯一,但是树不唯一- Prim算法 =加点法:从一个节点出发,找边最小的下一个节点连起来,直到所有节点都点亮。适合在稠密图(边很多,因为边数不影响这个算法的效率,以找点为核心)里面找这个树
- Kruskal算法 =加边法:先把节点全部写下来,边从小到大看要不要拿来连接节点,其中不能形成回路,已经连通的两节点不用再连边了。适合在稀疏图里面找最小生成树
6.介绍B树和B+树?
7.KMP算法?
高效的字符串匹配算法,长串找子串奶茶店前队伍找嫌疑犯 next数组
传统的字符串匹配是,从头开始校队主和子,不匹配了,子串一格一格往后挪。 O ( m ∗ n ) O(m*n) O(m∗n)
next数组=部分匹配表 O ( m + n ) O(m+n) O(m+n),记
8.DFS算法?BFS算法?
迷宫起点怎么到终点
- DFS = depth first search
深度优先搜素算法, - BFS
广度优先搜索算法,
9.常见的二叉查找树?
提高数据的查找、输入、删除的速度
-
普通二叉查找树BST=binary search tree
-
平衡二叉查找树(AVL树)
-
红黑树
ML机器学习
>> 1、常见的ML算法有哪些?
机器学习算法包括:监督学习、无监督学习、强化学习RL
- 监督学习:回归分析、SVM(support vector machine支持向量机,分类 问题)、决策树(decision tree)
- 无监督学习:K-Means聚类、主成分分析PCA
- 强化学习:Q-learning、Policy Learning
SVM的核心思想:在特征空间找一个超平面,尽可能隔开不同类别的数据点
决策树的核心思想:用“是/否”划分数据成树状
>> 2、简要介绍KNN算法 vs K-Means
-
KNN=K近邻算法=k-nearest neighbors
推理用的分类器, 可用于分类和回归。是基于距离的监督学习方法- 核心思想:没训练,直接推理时基于样本数据的类别,决定测试样本要分到哪一类
- 具体做法:先计算样本和训练集中其他样本的距离,选出最近的k个,然后多数投票(classification)和平均值(regression)预测样本
- 优点:直观、不用训、适合多分类
- 缺点:开销大、对高维数据(难算)和噪声(特殊数据)敏感
- k一般选奇数,距离的计算有多种方式,如欧式距离、曼哈顿距离、余弦相似度等
-
K-Means=k均值聚类算法
是无监督聚类算法,- 具体做法:定k,随机选k个质心,把样本分给最近的质心,每一簇内重新计算质心(簇内所有点均值),然后重复,最终分出k类,每类里的样本相似
- 用这个方法迭代出一个”分类器“吧(不算训练,就是推理的时候你放样本,就可以分出类了)
>> 3、激活函数是什么?常见有哪些?作用?
- 激活函数=activation function,是引入非线性的关键(NN神经网络的每一层都是线性+非线性)
- 常用的激活函数:
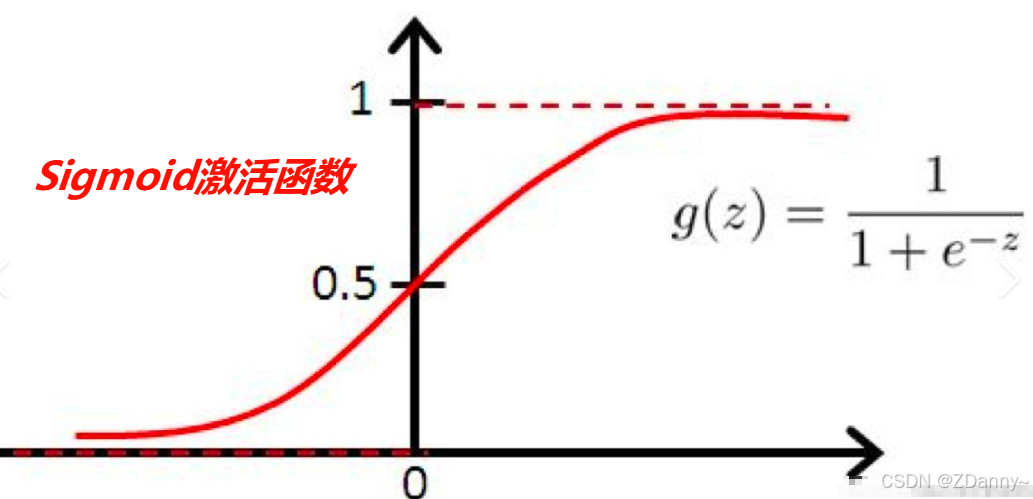
- Sigmoid:倒S,0-1,概率,适合二分类,容易梯度消失
- ReLU:简单,保留正值,负的为0。用于CNN/MLP,可能会梯度消失,因为直接左边负的神经元死亡了
- Softmax:像指数,用于最后一层多分类,把输出转成概率分布
- Tanh:输出(-1,1),用于传统RNN
作用:引入非线性,否则无论多少层都是线性组合,无法拟合复杂数据。让模型更复杂,影响梯度传播和收敛速度
>> 4、Sigmoid 和 Tanh 两个激活函数存在什么问题?
两人都容易造成梯度消失,因为靠近两边导数0了,
可用ReLU缓解,但是他也存在死神经元,只激活部分神经元。
进一步,可用Leaky ReLU、GELU改进的激活函数
>> 5、线性回归 ?逻辑回归?softmax回归?
- 线性回归=Linear Regression:
解决回归问题(预测连续值)
e.g.:房价预测,更根据面积、位置等特征,输出具体的房价数值多少💴- 损失函数:最小二乘法(均方误差MSE
- 输出范围:实数 ( − ∞ , ∞ ) (-∞,∞) (−∞,∞)
- 逻辑回归:=Logistic Regression
解决分类问题(预测是这个类别的概率),先线性变换,再通过 Sigmoid 函数将线性组合结果映射到0-1之间的概率(感觉就是前面线性回归套了个sigmoid)
e.g.:垃圾邮件识别,输出是概率,85%可能是垃圾邮件哦- 损失函数:交叉熵损失/对数似然
- 输出范围: ( 0 , 1 ) (0,1) (0,1),可以认为是这个样本属于正样本的概率
- softmax回归
解决多分类,应该是在逻辑回归基础上把sigmoid函数换成softmax函数就行了- 输出范围:输出k个概率,加起来是1,概率最大的,样本就是那个类了
- 输出范围:输出k个概率,加起来是1,概率最大的,样本就是那个类了
>> 6、损失函数?常见的有啥?目标函数?
- 损失函数=Loss Function
评价模型的好坏,最小化损失函数。衡量模型预测值与真实值的差距数字,模型优化的目标就是让损失函数的值尽可能小-
回归任务
- MSE均方差:预测
值和真实值差的平方 - MAE平均绝对误差
- MSE均方差:预测
-
分类任务
- 交叉熵损失=cross entropy loss:衡量预测
概率分布和真实分布的差距 - Focal Loss:处理类不平衡问题
- Hinge Loss:用于SVM支持向量机
- 交叉熵损失=cross entropy loss:衡量预测
-
生成模型VAE
- KL散度:评估两个分布的差异
-
>> 7、欠拟合?过拟合?怎么应对?
-
欠拟合:模型不能很好拟合训练数据,训练和测试
误差大
原因:模型太简单、参数少、特征不足、训练不足
解决:增加模型复杂度、增强数据、训练更久 -
过拟合:模型在训练集表现好,测试集不行,
泛化能力差
原因:模型太复杂、数据少
解决:增强数据、L1/2正则化控制模型复杂度、Dropout 或 Early Stopping、Max-Norm正则化
>> 8、什么是 L1/L2 正则化?Dropout?Early Stopping?
-
L1/L2正则化
是防止过拟合的方法。提高泛化能力。就是在损失函数里加入惩罚项,(因为在优化过程中,是让损失函数最小化,所以就可以不让参数无限变大);
这个1和2就是一阶二阶的意思,二阶约束条件,所以是平方。- L1:加入所有模型参数的*
绝对值之和*作为惩 → \to →会产生稀疏解,很多权重变成0,常用来特征选择
L 1 = λ ∑ i = 1 n ∣ w i ∣ L_{1} = \lambda \sum_{i=1}^{n} |w_i| L1=λi=1∑n∣wi∣ - L2:加入所有模型参数的*
平方和*作为惩 → \to →可以让权重均匀变小,不会直接0
L 2 = λ ∑ i = 1 n w i 2 L_{2} = \lambda \sum_{i=1}^{n} w_i^2 L2=λi=1∑nwi2
- L1:加入所有模型参数的*
-
Dropout
正则化方法,随机失活神经元,乱杀🔪,训练时以一个概率p随机丢掉一些神经元(权重=0),也是很随机了好hh
测试时不丢,缩放权重 -
Early Stopping
正则化方法,早早stop🛑,验证集损失不再下降就停止训练,避免过拟合,控制模型复杂度,提高泛化能力(后面3个短句就是经典)
>>10、有哪些训练过程的模型优化算法?
ps:这是《人工智能导论》书上写的
- 随机梯度下降(SGD)就是什么说的
- 动量梯度下降(Momentum)
- 自适应梯度下降(AdaGrad)\ RMSProp = Root Mean Square Propagation)
- Adam梯度下降 = Adaptive Moment Estimation(这个好像在最近llm训练也有提到)
>> 11、什么是随机梯度下降?梯度下降?小批次梯度下降?梯度?
梯度下降就是更新参数的方法。
- 随机梯度下降:每次只用1️⃣个样本计算损失并更新参数,
bad:更新方向波动大,收敛不稳定;
=SGD=stochastic gradient descent - 梯度下降(最速梯度下降):每次用整个训练集计算损失并更新参数
bad:更新慢,占内存; - 小批次梯度下降:每次用一小批样本计算损失并更新参数
good:最常用哈哈 - 梯度:在这里是损失函数对参数的偏导,损失
函数上升最快的方向,更新参数时就是反方向,让他下降最快
>> 12、优化器 SGD、RMSProp、 Adam有什么区别?各自的优势?⁉️
- SGD:最基础,更新规则简单
- RMSProp:能动态调整学习率,适合非平稳目标
Adam(⭐最常用):综合了动量和RMSProp的优点,更稳定
>> 13、BN层是什么?作用是?卷积是啥?池化层是什么?作用是?
-
BN=Batch Normalization批归一化,
训练时把每一层的输入数据标准化到均值=0、方差=1;测试时用整个训练集的移动平均统计量- 作用:更快更稳,图像卷积网络中常用
-
卷积:
比如图片,卷积之后的矩阵就是用的那个卷积核提取出的特征图。
如果是在NN的靠前位置,那么这个特征图就比较基础,比如颜色、线条。如果靠近输出层,特征图就比较宏观,可能是手、身体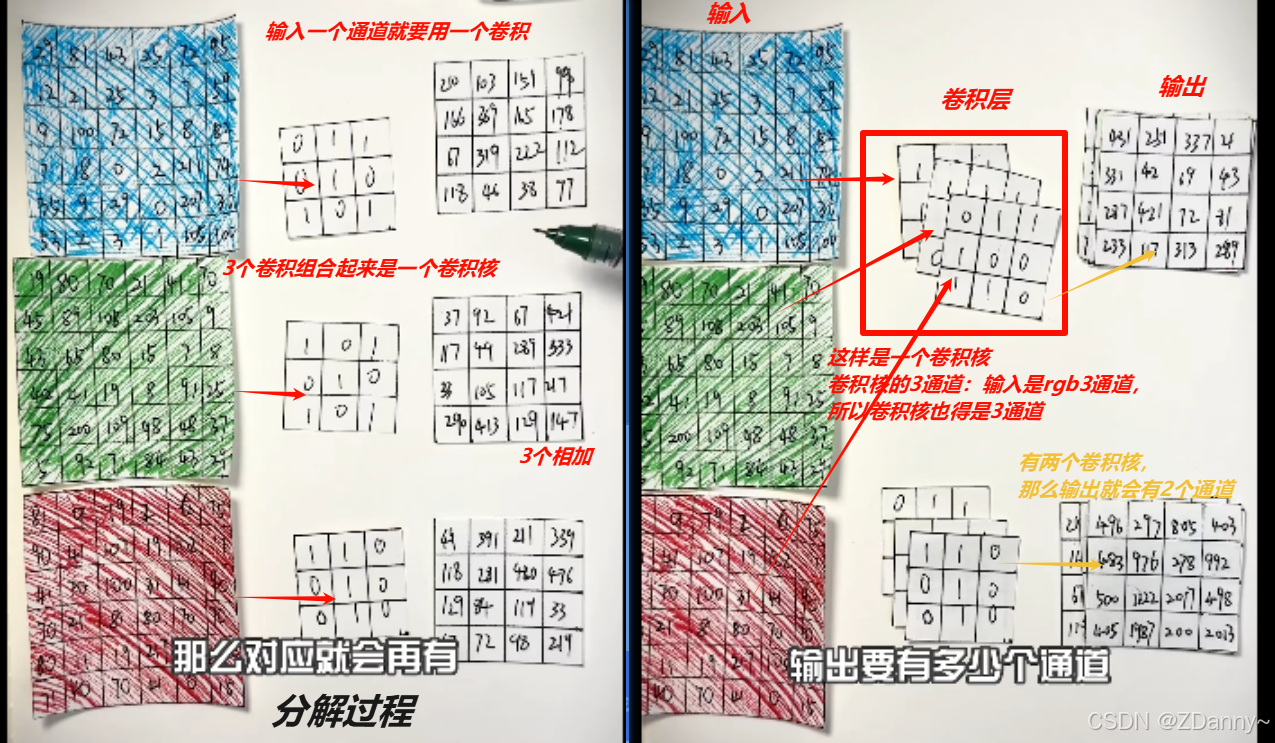
-
Pooling Layer
=下采样,卷积NN中降维的。一般在卷积之后的
有1. 最大池化(取窗口里max值)2. 平均池化(用窗口的平均值替换这个窗口)- 作用:特征压缩,提取主特征
>> 14、卷积核大小如何选?1×1 卷积核有什么用?※
最常见 3x3、5x5、7x7,少偶数
1×1 卷积核在计算过程中相当于全连接,可以改变输出的通道数(增加或减少)具体还是没懂,有空再看看教程
15、为什么Transformer中采用LayerNorm而不用BatchNorm?※
用层归一化而不用批归一化:输入的序列是文本,BN对变长序列不友好,
18、Transformer中为什么需要位置编码?
Transformer完全基于自注意力机制,没有像RNN那样的序列,缺失位置信息,且训练模型时是并行,而且词位置不一样句意就不一样
19、Transformer中 Encoder 和 Decoder有什么区别?
高数/数分
1、什么是零点存在定理和介值定理?
- 零点存在定理:函数在闭区间上连续,且左右端点的函数值异号,则闭区间上必定存在一点的函数值为0
- 介值定理:函数在闭区间上连续,c是左右端点函数值之间的一个数,则区间内必定存在一点 𝜉 的函数值等于c
2、什么是极限?单边极限和双边极限的区别?
- 极限:函数在某点附近,当自变量无限趋近于某个值时,函数值所接近的
数 - 单边极限:自变量从某点的
左/右趋近时的极限 - 双边极限:自变量从两侧同时趋近时的极限,只有左右极限都
存在+相等,双边极限才存在
>> 3、什么是数列?级数?部分和?级数和部分和的关系?
数列: a n = 1 n a_n=\frac{1}{n} an=n1。就不说了,就是高中学的那样。
级数: ∑ n = 1 ∞ 1 n \sum_{n=1}^{\infty} \frac{1}{n} ∑n=1∞n1(调和级数为例),是个式子,一般是让n趋于无穷是个数
部分和: S n = 1 + 1 2 + 1 3 + ⋯ + 1 n = ∑ k = 1 n 1 k S_n = 1 + \frac{1}{2} + \frac{1}{3} + \cdots + \frac{1}{n}= \sum_{k=1}^{n} \frac{1}{k} Sn=1+21+31+⋯+n1=∑k=1nk1。级数的前 n n n项和
关系:部分和 S n S_n Sn当 n → ∞ n \to \infty n→∞
4、什么是罗尔中值定理?拉格朗日中值定理?微分中值定理?柯西中值定理?积分中值定理
5、黎曼和、黎曼积分的定义?
.
6、什么是泰勒展开?
7、连续、可导、可微、可积之间的关系?导数和偏导的区别?方向导数和梯度的区别?
8、什么是牛顿莱布尼茨公式?格林公式?高斯公式?斯托克斯公式?
9、梯度、散度、旋度?
梯度:作用于标量场,梯度运算的结果是一个矢量场,表示标量场在空间中增长最快的方向和最大的增长率
- 散度:空间中某点发散或汇聚的程度
- 旋度:
> 10、傅里叶级数和傅里叶变换的区别?
- 傅里叶级数:用于对周期函数进行频谱分析,它将一个周期信号表示为一组离散的正弦和余弦函数的叠加,频率是离散的,间隔由周期决定,
- 傅里叶变换:用于非周期函数或信号的分析,将信号表示为连续的频率成分的积分,频率是连续的,适用于无限长的信号或非周期信号
线代
主包的线代大一学的比较烂
> 1. 矩阵的秩rank是什么?满秩代表什么?特征值的意义?行列式的意义?
把用了矩阵看成是一个线性变换的操作,下面的行列式、秩、特征值都是它的操作的属性
- 矩阵的秩rank:是矩阵
最大线性无关的行/列的个数,代表这个矩阵有多少有用信息- 几何意义:线性变换能把空间映射成多大维度的新空间(e.g.二维映射成三维,高维降成三维)
- 满秩:意味着矩阵的秩=它的阶数,矩阵的行/列是线性无关的,
没有冗余信息。- 对于方阵,满秩 <=> 可逆( A ⋅ A − 1 = I 单位矩阵 A \cdot A^{-1} = I单位矩阵 A⋅A−1=I单位矩阵)
- 【秩和特征值的关系】矩阵的秩 = 非0特征值的个数,存在0特征值表示存在0空间,矩阵就不是满秩了。
- 特征值:nxn最多n个特征值,特征值对应某些方向上,线性变换的伸缩比例(不改变方向),它是矩阵的属性
- 行列式:(这个就更抽象了),表示这个线性变换把单位立方体(这个也不知道哪来的)缩放成平行体,行列式的绝对值就是体积缩放因子,符号表示是否翻转
> 2. 什么是线性相关vs线性无关?线性变换/线性映射?线性组合?
线性相关vs线性无关对象是一组向量。
- 线性相关:指一组向量中,至少有一个向量可以用其他向量的
线性组合表示,齐次方程组有非0解 - 线性无关:这组向量中,没有任何一个向量可以用其他向量线性表示
线性变换/线性映射的对象是向量空间里的向量,其实就是矩阵,空间操作
- 线性变换:方阵乘向量就是线性变换了。旋转、缩放、镜像都是线性变换,平移不是
用一个 n n nx n n n的矩阵 ✖ 一个n维向量(算的时候要变成列才能乘 n n nx 1 1 1)= n n nx 1 1 1的矩阵, - 线性映射:感觉线性映射就是线性变换的结果,变换完就完成了一个向量映射成另一个向量
线性组合的对象是向量空间里的向量
- 线性组合:应该就是缩放
> 3. 矩阵的特征向量和特征值的含义?作用?关系?
- 如果 矩阵 A 矩阵A 矩阵A 作用于一个 向量 v 向量v 向量v 后,向量方向不变,只是被压缩或者拉伸了,那这个向量就是特征向量,恭喜你🎉找到了一个特征向量,也恭喜你找到了这个矩阵的特征值(就是向量被拉伸或压缩的倍数),数学公式 A v = λ v Av =\lambda v Av=λv。
- 特征值和特征向量可以用来PCA降维提取最重要的方向
> 4. 初等变换?作用?
作用对象是矩阵,操作行/列,三种基操了。作用就是简化矩阵或者找秩,求逆
- 交换两行
- 非0数数乘一行
- 一行的倍数加到另一行
> 5. 什么是线性/向量空间?线性空间的基和维数?列空间?
- 线性空间是指一个向量集合,里面的元素可以加法和数乘,并且满足封闭性、交换律、结合律等运算规则。
- 基:一组既能表示空间中所有向量又互相线性无关的向量的集合
- 维数:该基中向量的个数
- 列空间:具体的线性空间,列向量矩阵作用在向量 x x x后可能得到的所有列向量的线性生成空间(所以也就是为什么叫生成)。行空间也差不多
> 6. 什么是矩阵的奇异值?奇异值分解 vs 特征值分解?
- 奇异值:矩阵把单位球🏐压缩/拉伸后🏈的半径大小(非负),矩阵 A A A的奇异值是 A T A A^TA ATA 的特征值
- 奇异值分解=Singular Value Decomposition
是将任意矩阵A分解=>3个矩阵的乘积, U U U和 V V V是正交矩阵, D D D是奇异值对角矩阵。SVD把矩阵变换分成旋转、缩放、再旋转(分别对应公式倒着看)。 - 奇异值分解 vs 特征值分解,
- 特征值分解只用于方阵,奇异值分解是任意矩阵
特征值分解EVDA = P D P − 1 A = PDP^{-1} A=PDP−1【描述矩阵的不变方向(因为p是特征向量)和缩放倍数(因为d是特征值)】
D=特征值对角矩阵(对角矩阵,对角线值为特征值),P=特征向量矩阵奇异值分解SVDA = U D V T A=UDV^T A=UDVT【描述矩阵的主方向伸缩】
D=奇异值对角矩阵,U和V=正交矩阵
> 7. 什么是正交矩阵vs向量正交?正定矩阵?相似矩阵?对角矩阵?
- 正交矩阵:=Orthogonal Matrix,是个方阵,他的行向量或列向量都得两两正交,每个向量长度都是1,构成一组标准正交基orthonormal basis。
- 数学公式: Q T Q = I ( 单位矩阵 ) Q^TQ=I(单位矩阵) QTQ=I(单位矩阵),下面为什么结果会是单位矩阵的原因,其实就说对角线上的值就是列向量和列向量自己的内积,长度是1所以结果是1(因为内积是投影后的长度)
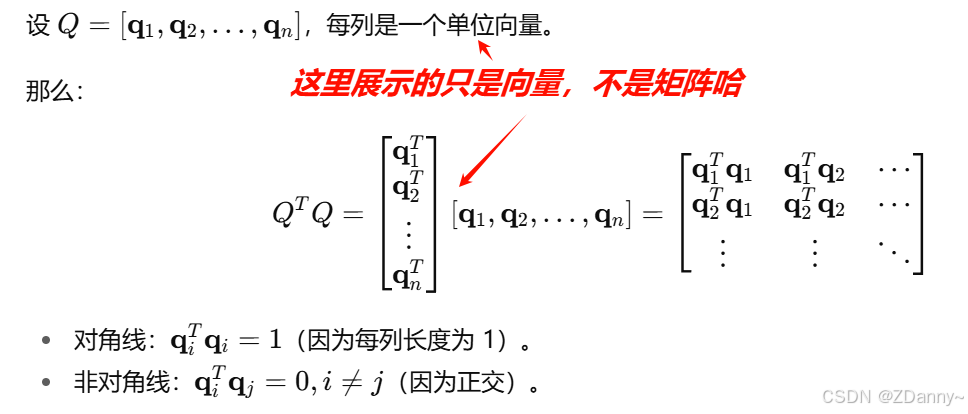
- 数学公式: Q T Q = I ( 单位矩阵 ) Q^TQ=I(单位矩阵) QTQ=I(单位矩阵),下面为什么结果会是单位矩阵的原因,其实就说对角线上的值就是列向量和列向量自己的内积,长度是1所以结果是1(因为内积是投影后的长度)
- 向量正交:就是内积为0,(内积代表了两个向量的夹角关系/或者说投影)
- 正定矩阵:一定是对称矩阵(关于对角线对称),所有特征值都大于0,所有主子式(是从左上角向下框一个nxn方阵)都为正,一定可逆,且逆矩阵也是正定的
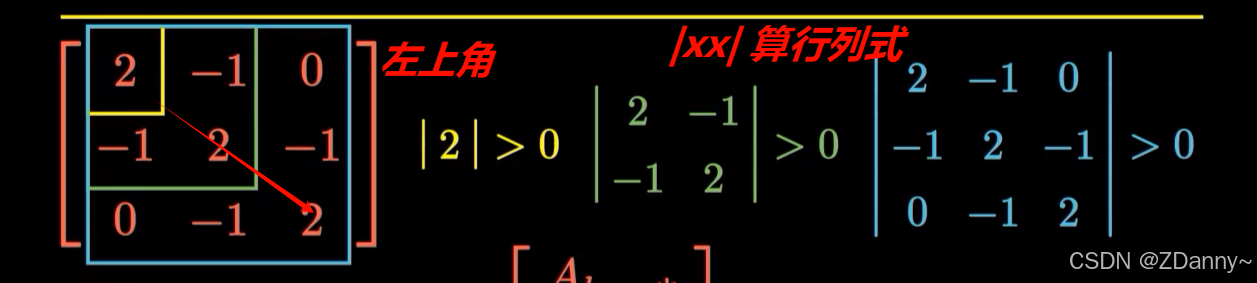
- 相似矩阵:这个概念会涉及两个矩阵A、B,A和B其实是同一个线性变换,但是因为在不同基中表示,所以体现出来矩阵的数值不同,但给向量的变换效果是一样的。B站视频
- 特征值、行列式和秩保持不变。数学公式: B = P − 1 A P B=P^{-1}AP B=P−1AP
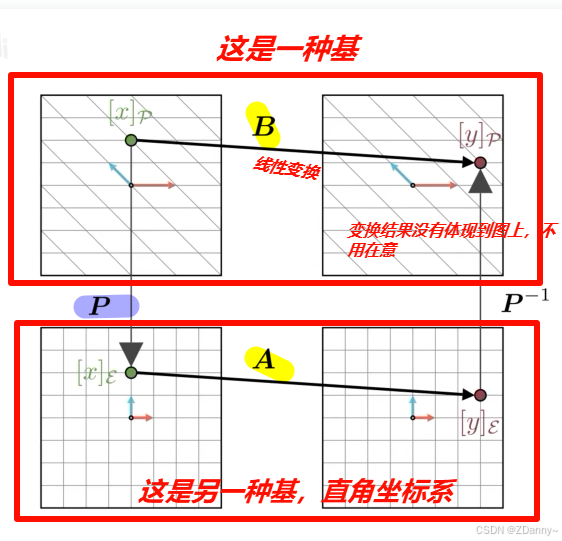
- 特征值、行列式和秩保持不变。数学公式: B = P − 1 A P B=P^{-1}AP B=P−1AP
- 对角矩阵:是方阵,主对角线上是矩阵的特征值,其余位置为0
> 8. 什么是矩阵范数和向量范数?常用范数有哪些?
- 向量范数=模,是衡量向量长度的函数,
- 常用的范数:L1-范数、L2-范数(欧几里得范数)、L∞-范数(最大值范数)
- 矩阵范数是衡量矩阵大小的函数,常用的矩阵范数如下:
- 一阶范数:找矩阵里哪一类最“重”,即列元素绝对值之和的最大值
- 二阶范数:找矩阵的最大拉伸能力,矩阵作用在一个单位向量上后能拉伸的最长值(最大奇异值)
> 9. 矩阵可逆的条件?矩阵可对角化是什么?长什么样?对角化的充要条件?
- 矩阵可逆:方阵才可逆,行列式不为0,满秩<=>特征值无0,线性方程组 A x = 0 Ax=0 Ax=0只有0解。
【方阵的列向量线性无关 <=> 矩阵可逆】 - 矩阵可对角化:对角化就是“找一个合适的基,把一个矩阵写成对角矩阵的形式”,(为什么要对角化,因为 Λ \Lambda Λ对角矩阵简单啊,简化)
- Λ \Lambda Λ对角矩阵的对角线上就是 A A A 的特征值。 P P P是 A A A的特征向量拼成的矩阵,要线性无关。
- 条件:矩阵存在一组线性无关的特征向量组成 P P P,满足 A = P Λ P − 1 A = P \Lambda P^{-1} A=PΛP−1,(这个也是相似矩阵的公式,其实都是有关联的,矩阵的线性变换操作没变,只是基变了)
> 10. 如何判断线性方程组Ax=b的解的情况?
其实是看A的列空间里能不能有b
- 比较系数矩阵 A A A 和增广矩阵 [ A ∣ b ] [A|b] [A∣b](在A右边加上常数列b)的秩
- 秩相等 => 有解,秩不等 => 无解
- 再看秩和
未知数个数n的关系- 等于 => 唯一解,秩小于未知数,有冗余 => 无穷多解

- 等于 => 唯一解,秩小于未知数,有冗余 => 无穷多解
方差?协方差?协方差矩阵?
方差:
- 是用来描述一组数据(单个随机变量=一个特征)的稳定/波动情况的,
- 计算:对于一组数据 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn,均值是 μ \mu μ,
- V a r ( X ) = 1 n ∑ i = 1 n ( x i − μ ) 2 Var(X) = \frac{1}{n}\sum_{i=1}^n (x_i - \mu)^2 Var(X)=n1∑i=1n(xi−μ)2
- 数值意义:
- 方差越小越稳定,离均值的差距越小。
- 从这么多数据来看,这个特征的数值起伏大不大
协方差:
- 是用来描述两个变量之间的线性关系的,
两个特征之间只得到一个值 - 计算: 本质上是两个变量偏离均值的乘积的期望
- C o v ( X , Y ) = E [ ( X − μ X ) ( Y − μ Y ) ] = 1 n ∑ i = 1 n ( x i − μ X ) ( y i − μ Y ) \mathrm{Cov}(X,Y) = E\big[(X - \mu_X)(Y - \mu_Y)\big]=\frac{1}{n} \sum_{i=1}^n (x_i - \mu_X)(y_i - \mu_Y) Cov(X,Y)=E[(X−μX)(Y−μY)]=n1∑i=1n(xi−μX)(yi−μY)
- 数值意义:
- 正协方差(数值大):说明两个变量一起涨跌的趋势明显。
e.g.身高越高 → 体重越大 - 负协方差(数值小):说明一个涨另一个跌
e.g.熬夜时间越多 → 成绩越差 - 协方差接近 0:说明两个变量没有明显的线性关系
- 正协方差(数值大):说明两个变量一起涨跌的趋势明显。
- ps⚠️:
- 方差就是特殊的协方差,自己和自己协
- 协方差的大小受量纲影响(比如 cm、kg 混合时数值可能很大),常用
相关系数(标准化后的协方差,范围 [-1,1]
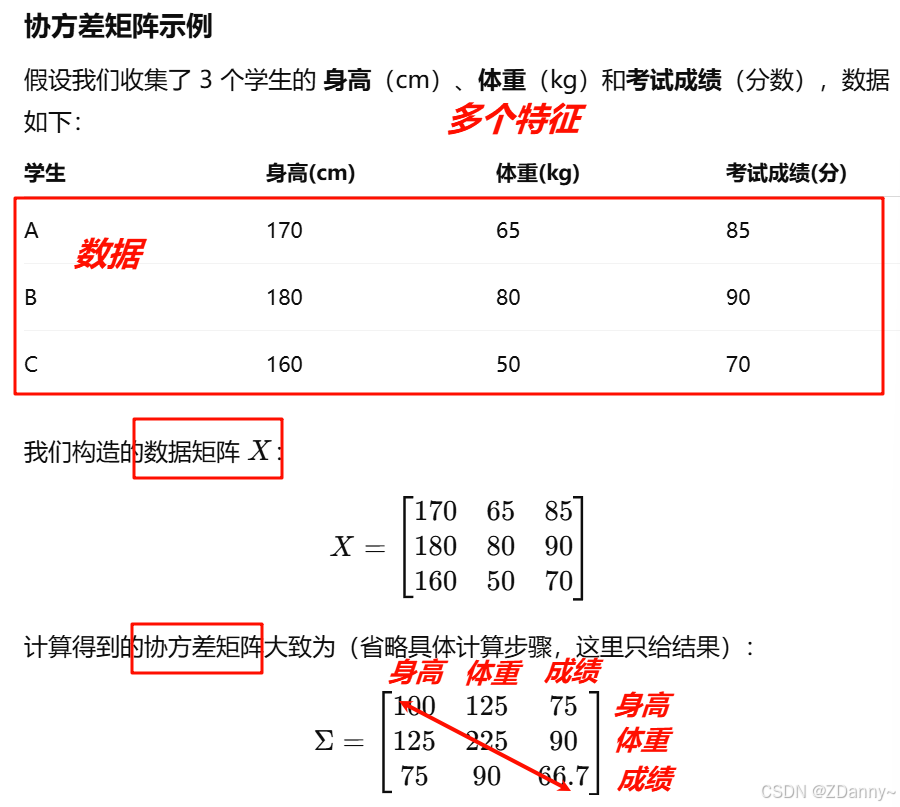
协方差矩阵:
- 就是上面协方差数值组成的矩阵,是用来衡量多个特征之间相关性的矩阵,是对称矩阵
- 数值含义:
- 非对角线大 → 特征之间强相关
- 对角线大 → 特征自己波动剧烈
什么是张量?张量tensor和矩阵的区别?
张量>矩阵,矩阵只是tensor的一种。
0阶张量=标量,数;1阶tensor=向量;2阶tensor=矩阵;3阶及以上=高维数组
矩阵乘法的5种顶级理解
这里就只先写了一种
B站教程,多看吧,每次看可能会有新的理解:
我觉得,最easy的理解就是理解成是一种线性映射,把高维向量映射成低维向量,或者反过来。
举个🌰:
先对有难度的乘法有一个宏观概念:向量1 乘· 向量2 【向量内积/点乘】< 列向量矩阵1 乘· 列向量1 【系数的概念】< 列向量矩阵1 乘· 列向量矩阵2 【矩阵乘法】
必须有的sense:那就是乘完之后的结果(L1是数,L2是列向量,L3是矩阵)的位置是按照乘法右边的(L1是向量,L2是列向量,L3是矩阵)当成系数时候的位置【不好理解,多适应一下就行】
我们从L2难度入手:
(ps:矩阵是可以横看也可以列看,我们都选择列看矩阵,意味着每一列是一个向量,这种情况下,要把矩阵放在乘法的左边,右边放列向量)
- 一个列向量就是有长度和方向的(这个方向是右你放在的坐标系决定的,长度就是向量的数值)
- L2的结果一定是列向量,因为乘的是列向量,2x2 *2x1 = 2x1。看成:把左边矩阵中多个列通过缩放相加合成一个新的向量(这里可以想下图右边的三角形来理解)
- 2种理解:1、向量是系数,把矩阵缩放相加变成一个向量。2、反过来,觉得是矩阵把向量进行了线性映射成新向量。——一个合并的思想,一个是映射的思想

OK,我们来看一下L3级别。
矩阵乘法就是把L2的右边向量换成矩阵了。同样就可以看成是L2的组合装。
结果C的每一列就都是A中所有列向量的线性组合,C的第一列对应用B的第一列作为系数去线性组合所有A向量(注意这里可能容易难懂,就是C矩阵的组成列是和B列系数对应的)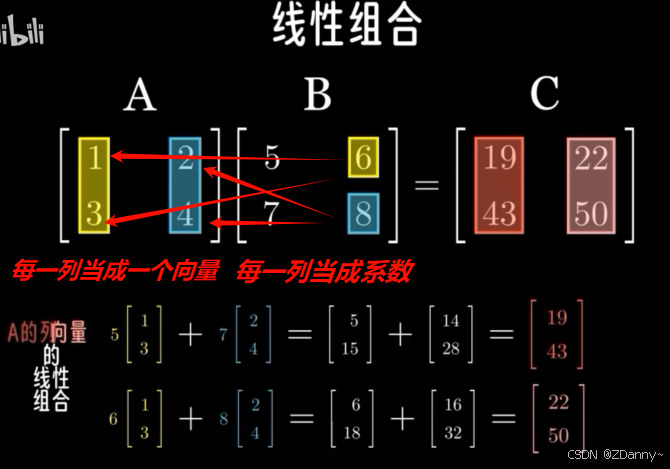
最后我们再补充L1:
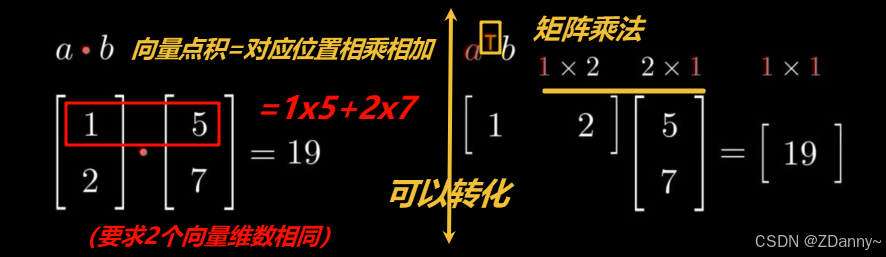
点积=dot product ,也叫inner product内积,要相同维度的向量,结果是一个值!
(ps:点积和数乘–向量乘一个数还是不一样的,结果是向量) - 顺乘合为0,两个向量就垂直,其实内积描述的就是两个向量(二维为例)之间的夹角关系,也是一个投影到另一个向量上
概率论
- 什么是大数定理?中心极限定理?伯努利大数定律?最大似然估计?
- 大数定理:是指
样本平均值在样本数量趋于∞时,会趋近于总体的期望值 - 中心极限定理:是指一组独立同分布随机变量的
平均值,它的分布在样本量大时会近似服从正态分布 - 伯努利实验:只有2种可能结果的随机实验,成功/失败,且每次试验成功的概率为 p p p,失败的概率 1 − p 1-p 1−p。
- n次独立的实验成功的次数 X~二项分布
- 当次数很多,二项分布近似为正态分布
- 伯努利大数定律:多次重复同一试验,实际成功频率会越来越解决理论概率(实践)
- 最大似然估计:参数估计方达,用来找到时观测数据出现概率最大的参数值(或概率密度最大)
- 随机变量和概率分布有什么联系?常见的概率分布有哪些?
- 随机变量是对随机现象结果的数值表示,
- 概率分布:描述了上述数值结果发生的可能性
- 概率分布刻画了随机变量的规律和统计特性
- 常见的概率分布
- 离散型:伯努利、二项、泊松
- 连续型:均匀、正态、指数
- 正态分布的和、差、积服从什么分布?
和、差~正态分布,
方差是两者方差之和
- 概率密度函数 vs 概率分布函数?
- 概率密度函数 P D F PDF PDF:描述随机变量在某个取值附件的相对可能性
- 概率分布函数 C D F CDF CDF:随机变量 <= 某个值的累计概率。
- CDF是PDF的积分
- 全概率公式和贝叶斯公式?
全概率公式:用来计算事件的总体概率
贝叶斯公式:事件之后发生,
- 什么是先验概率?后验概率?
- 介绍一下伯努利试验及其重要结论
- 介绍泊松定理及其与二项分布的关系?
- 二维随机变量联合分布于边缘分布的关系?
- 随机变量X,Y独立和不相关以及两者的关系
- 什么是协方差和相关系数?如何计算?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)