程序员实战:RAG 技术全流程搭建 AI 知识库(大模型查资料指南)
本文介绍了如何利用检索增强生成(RAG)技术解决大模型"幻觉"问题,通过构建AI知识库实现"先检索后生成"的智能问答系统。文章详细拆解了RAG的核心技术流程,包括数据向量化、混合检索策略和与大模型集成,并提供了完整的代码示例,涵盖数据处理、向量数据库构建、检索API开发等关键环节。重点展示了如何结合语义检索和关键词检索,以及如何通过Prompt工程引导大模型
大模型 “一本正经地胡说八道”(幻觉)是落地痛点,而检索增强生成(RAG)技术通过 “先检索、后生成” 的逻辑,让模型具备 “查资料” 能力 —— 像人一样遇到问题先查知识库,再基于权威信息输出答案。作为程序员,搭建 RAG 系统需打通 “数据处理 - 检索引擎 - 模型集成” 全链路。本文结合完整代码示例,从技术原理到工程落地,拆解如何用 RAG 构建高可用 AI 知识库,让大模型真正 “知之为知之,不知则查之”。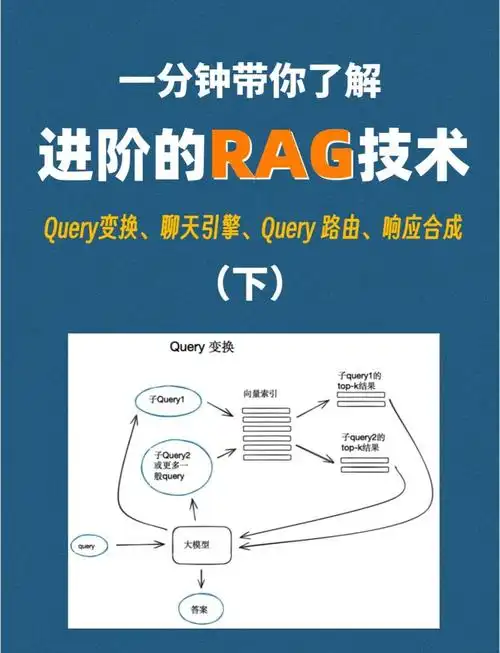
RAG 技术核心原理:让大模型 “学会查资料” 的底层逻辑
RAG 的本质是 “连接大模型与外部知识库”,解决模型训练数据滞后、知识边界有限的问题。其核心流程可概括为 “数据入库 - 检索匹配 - 内容生成” 三步,程序员需理解每一步的技术选型与实现逻辑,才能搭建出高效的检索系统。
1. 核心流程与技术栈选型
- 数据入库:将非结构化数据(文档、网页、PDF)转换为机器可识别的向量,需用到文本分割、嵌入模型(如 Sentence-BERT);
- 检索匹配:接收用户问题后,通过向量数据库(如 FAISS、Milvus)快速匹配相似知识片段,支持精确匹配与语义匹配;
- 内容生成:将检索到的知识片段与问题结合,通过大模型(如 Llama 2、ChatGLM)生成答案,需设计合理的 Prompt 模板。
常用技术栈组合:
# 数据处理层
LangChain/ LlamaIndex # 数据加载、分割、嵌入封装
Sentence-BERT/ text-embedding-ada-002 # 文本嵌入模型
# 检索存储层
FAISS # 轻量级向量数据库(适合单机部署)
Milvus/ Chroma # 分布式向量数据库(适合大规模知识库)
MySQL/ PostgreSQL # 结构化元数据存储
# 模型生成层
Llama 2/ ChatGLM # 开源大模型(本地化部署)
GPT-3.5/ GPT-4 # 闭源大模型(API调用)
2. 文本嵌入与向量转换核心代码
文本嵌入是 RAG 的基础 —— 将文本转换为高维向量,通过向量相似度衡量语义相关性。以下代码演示如何使用 Sentence-BERT 实现文本嵌入,并将文档片段存入 FAISS 向量库:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
def build_vector_db(doc_path: str, db_save_path: str) -> None:
"""
构建向量数据库:加载文档→分割→嵌入→存储
:param doc_path: 原始文档路径(支持txt/pdf/docx等)
:param db_save_path: 向量库保存路径
"""
# 1. 加载文档(LangChain支持多种格式,此处以txt为例)
loader = TextLoader(doc_path, encoding="utf-8")
documents = loader.load()
print(f"加载文档数量:{len(documents)}")
# 2. 文本分割(解决大文档嵌入精度问题,按语义分割)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个片段最大字符数
chunk_overlap=50, # 片段重叠字符数(保持上下文连贯)
length_function=len, # 长度计算方式
separators=["\n\n", "\n", ". ", " ", ""] # 分割符优先级
)
split_docs = text_splitter.split_documents(documents)
print(f"分割后文档片段数量:{len(split_docs)}")
# 3. 初始化嵌入模型(选用轻量级Sentence-BERT,适合本地化部署)
embeddings = HuggingFaceEmbeddings(
model_name="all-MiniLM-L6-v2", # 模型权重小、推理快
model_kwargs={"device": "cpu"}, # 可指定GPU("cuda:0")加速
encode_kwargs={"normalize_embeddings": True} # 向量归一化,提升检索精度
)
# 4. 构建并保存向量数据库
db = FAISS.from_documents(split_docs, embeddings)
db.save_local(db_save_path)
print(f"向量数据库已保存至:{db_save_path}")
# 测试:构建基于技术文档的向量库
if __name__ == "__main__":
DOC_PATH = "ai_technology_doc.txt" # 原始技术文档(如LLM原理手册)
DB_SAVE_PATH = "faiss_ai_knowledge_base"
build_vector_db(DOC_PATH, DB_SAVE_PATH)
3. 检索逻辑实现(精确 + 语义混合检索)
好的检索系统需结合 “精确匹配”(关键词检索)与 “语义匹配”(向量检索),提升结果相关性。以下代码实现混合检索逻辑:
def hybrid_retrieval(query: str, db_path: str, top_k: int = 3) -> list:
"""
混合检索:结合向量语义检索与关键词检索
:param query: 用户问题
:param db_path: 向量库路径
:param top_k: 返回最相关的k个结果
:return: 检索到的知识片段列表
"""
# 1. 加载向量数据库
embeddings = HuggingFaceEmbeddings(
model_name="all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"}
)
db = FAISS.load_local(db_path, embeddings, allow_dangerous_deserialization=True)
# 2. 语义检索(基于向量相似度)
semantic_results = db.similarity_search(query, k=top_k*2) # 先获取更多候选结果
# 3. 关键词检索(过滤语义检索结果,保留含关键词的片段)
keywords = query.split() # 简单分词(实际可使用jieba等工具优化)
filtered_results = []
for doc in semantic_results:
# 检查文档是否包含至少一个关键词
if any(keyword.lower() in doc.page_content.lower() for keyword in keywords):
filtered_results.append(doc)
# 达到目标数量即停止
if len(filtered_results) == top_k:
break
# 4. 输出检索结果(含文档内容、来源、相似度)
retrieval_output = []
for i, doc in enumerate(filtered_results, 1):
retrieval_output.append({
"rank": i,
"content": doc.page_content,
"source": doc.metadata["source"],
"similarity": round(db.similarity_score(query, doc), 3) # 计算相似度得分
})
return retrieval_output
# 测试混合检索
if __name__ == "__main__":
USER_QUERY = "什么是大模型的幻觉?如何缓解?"
DB_PATH = "faiss_ai_knowledge_base"
results = hybrid_retrieval(USER_QUERY, DB_PATH, top_k=3)
print("检索结果:")
for res in results:
print(f"\n第{res['rank']}名(相似度:{res['similarity']})")
print(f"来源:{res['source']}")
print(f"内容:{res['content'][:200]}...") # 显示前200字符
全流程搭建 AI 知识库:从数据准备到模型集成
搭建 RAG 知识库需经过 “数据采集 - 预处理 - 向量入库 - 检索服务 - 模型调用” 全流程,每个环节都需兼顾 “精度” 与 “效率”。以下以 “AI 技术问答知识库” 为例,完整演示从 0 到 1 的搭建过程。
1. 多源数据采集与预处理
实际知识库需整合多源数据(文档、网页、API 接口数据),需先统一数据格式并清洗冗余信息。以下代码实现多源数据加载:
from langchain.document_loaders import (
TextLoader, PDFLoader, WebBaseLoader, Docx2txtLoader
)
import os
def load_multi_source_data(data_dir: str) -> list:
"""
加载多源数据:支持txt/pdf/docx/web页面
:param data_dir: 本地数据目录(含各类文档)
:return: 统一格式的文档列表
"""
documents = []
# 遍历目录下所有文件
for root, _, files in os.walk(data_dir):
for file in files:
file_path = os.path.join(root, file)
try:
# 根据文件后缀选择加载器
if file.endswith(".txt"):
loader = TextLoader(file_path, encoding="utf-8")
elif file.endswith(".pdf"):
loader = PDFLoader(file_path)
elif file.endswith(".docx"):
loader = Docx2txtLoader(file_path)
else:
print(f"不支持的文件格式:{file}")
continue
# 加载并添加元数据(标记来源)
docs = loader.load()
for doc in docs:
doc.metadata["source"] = file_path # 记录文件路径
doc.metadata["file_type"] = file.split(".")[-1] # 记录文件类型
documents.extend(docs)
print(f"成功加载:{file_path}({len(docs)}个片段)")
except Exception as e:
print(f"加载失败:{file_path},错误:{str(e)}")
# 加载网页数据(如AI技术博客)
web_urls = [
"https://example.com/llm-hallucination-guide",
"https://example.com/rag-technology-intro"
]
for url in web_urls:
try:
loader = WebBaseLoader(url)
web_docs = loader.load()
for doc in web_docs:
doc.metadata["source"] = url
doc.metadata["file_type"] = "web"
documents.extend(web_docs)
print(f"成功加载网页:{url}({len(web_docs)}个片段)")
except Exception as e:
print(f"加载网页失败:{url},错误:{str(e)}")
return documents
# 测试多源数据加载
if __name__ == "__main__":
DATA_DIR = "ai_knowledge_data" # 本地数据目录
all_docs = load_multi_source_data(DATA_DIR)
print(f"\n总加载文档片段数量:{len(all_docs)}")
2. 向量库服务化部署(FastAPI)
为便于工程调用,需将向量检索功能封装为 API 服务,支持外部系统(如前端界面、大模型服务)调用。以下用 FastAPI 实现检索服务:
from fastapi import FastAPI, Query
from pydantic import BaseModel
import uvicorn
# 初始化FastAPI应用
app = FastAPI(title="RAG知识库检索服务", version="1.0")
# 加载向量库(启动时加载,避免重复初始化)
DB_PATH = "faiss_ai_knowledge_base"
embeddings = HuggingFaceEmbeddings(
model_name="all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"}
)
db = FAISS.load_local(DB_PATH, embeddings, allow_dangerous_deserialization=True)
# 定义请求体模型
class RetrievalRequest(BaseModel):
query: str
top_k: int = 3
# 定义响应体模型
class RetrievalResponse(BaseModel):
code: int = 200
message: str = "success"
data: list
# 检索API接口
@app.post("/api/retrieval", response_model=RetrievalResponse)
def retrieval(request: RetrievalRequest):
"""
知识库检索API
:param request: 包含query(查询词)和top_k(返回数量)
"""
try:
# 执行检索
results = db.similarity_search(request.query, k=request.top_k)
# 格式化结果
data = []
for i, doc in enumerate(results, 1):
data.append({
"rank": i,
"content": doc.page_content,
"source": doc.metadata.get("source", "unknown"),
"file_type": doc.metadata.get("file_type", "unknown"),
"similarity": round(db.similarity_score(request.query, doc), 3)
})
return RetrievalResponse(data=data)
except Exception as e:
return RetrievalResponse(code=500, message=f"检索失败:{str(e)}", data=[])
# 启动服务(命令行:uvicorn rag_api:app --host 0.0.0.0 --port 8000)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
3. 大模型集成与答案生成
将检索服务与大模型结合,通过 Prompt 模板将 “问题 + 检索结果” 传入模型,生成基于知识库的精准答案。以下代码演示与开源模型 Llama 2 的集成:
from langchain.llms import LlamaCpp
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
import requests
def rag_answer_generation(query: str, top_k: int = 3) -> str:
"""
RAG全流程:检索知识库→调用大模型→生成答案
"""
# 1. 调用检索API获取知识片段
retrieval_url = "http://localhost:8000/api/retrieval"
payload = {"query": query, "top_k": top_k}
response = requests.post(retrieval_url, json=payload)
if response.status_code != 200:
return f"检索服务异常:{response.text}"
retrieval_results = response.json()["data"]
if not retrieval_results:
return "未在知识库中找到相关信息,无法回答该问题。"
# 2. 格式化检索结果(作为Prompt输入)
context = ""
for res in retrieval_results:
context += f"""
【来源】:{res['source']}
【相关内容】:{res['content']}
【相似度】:{res['similarity']}
"""
# 3. 定义RAG Prompt模板(引导模型基于检索结果回答)
prompt_template = """
你是一个基于知识库的AI问答助手,请严格按照以下规则回答用户问题:
1. 必须基于提供的知识库内容回答,不得编造信息;
2. 若知识库内容不足,直接说明“知识库中相关信息不足,无法完整回答”;
3. 回答需引用来源(格式:参考[来源名称]),多个来源用逗号分隔;
4. 语言简洁明了,分点说明(如需)。
【知识库内容】:
{context}
【用户问题】:{query}
【回答】:
"""
prompt = PromptTemplate(
input_variables=["context", "query"],
template=prompt_template
)
# 4. 初始化Llama 2模型(本地化部署,需提前下载模型权重)
llm = LlamaCpp(
model_path="./llama-2-7b-chat.ggmlv3.q4_0.bin", # 模型权重路径
n_ctx=2048, # 上下文长度
n_threads=8, # 推理线程数
temperature=0.3, # 随机性(越低越精准)
max_tokens=512, # 最大生成token数
top_p=0.9,
stop=["<|end_of_solution|>"], # 停止符
verbose=False # 关闭详细日志
)
# 5. 构建并运行RAG链
rag_chain = LLMChain(llm=llm, prompt=prompt)
answer = rag_chain.run({"context": context, "query": query})
# 6. 补充来源信息(确保符合规则)
sources = list(set([res["source"].split("/")[-1] for res in retrieval_results]))
answer += f"\n\n参考来源:{', '.join(sources)}"
return answer
# 测试RAG全流程
if __name__ == "__main__":
USER_QUERY = "如何解决大模型的幻觉问题?有哪些具体方法?"
answer = rag_answer_generation(USER_QUERY, top_k=3)
print("RAG生成答案:")
print(answer)
工程化优化与落地:提升知识库可用性与稳定性
搭建完成的 RAG 系统需经过 “性能优化 - 容错处理 - 监控运维”,才能满足生产环境需求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)