强化学习概述
强化学习是一种通过agent与环境交互来最大化长期奖励的机器学习方法。其核心要素包括agent、环境、状态、动作和奖励机制。根据学习方式可分为on-policy和off-policy,根据模型可分为model-free和model-based。关键区别在于奖励函数反映即时收益,而价值函数(包括状态值函数和动作-状态值函数)衡量长期收益。贝尔曼方程为解决此问题提供了递归框架,其核心思想是将问题分解为
文章目录
Prequisite
背景
强化学习几个主要部分为:agent(代理)、环境、奖励、状态、动作
目标
agent(代理)根据当前状态,选择动作执行,得到环境反馈,以期望得到最大的奖励。
分类
强化学习按照学习方式可分:
- on-policy
- off-policy
钱花学习按照使用数据方式:
- online learning(数据是交互得来的)
- offline learing(直接使用离线数据,代表有DPO)
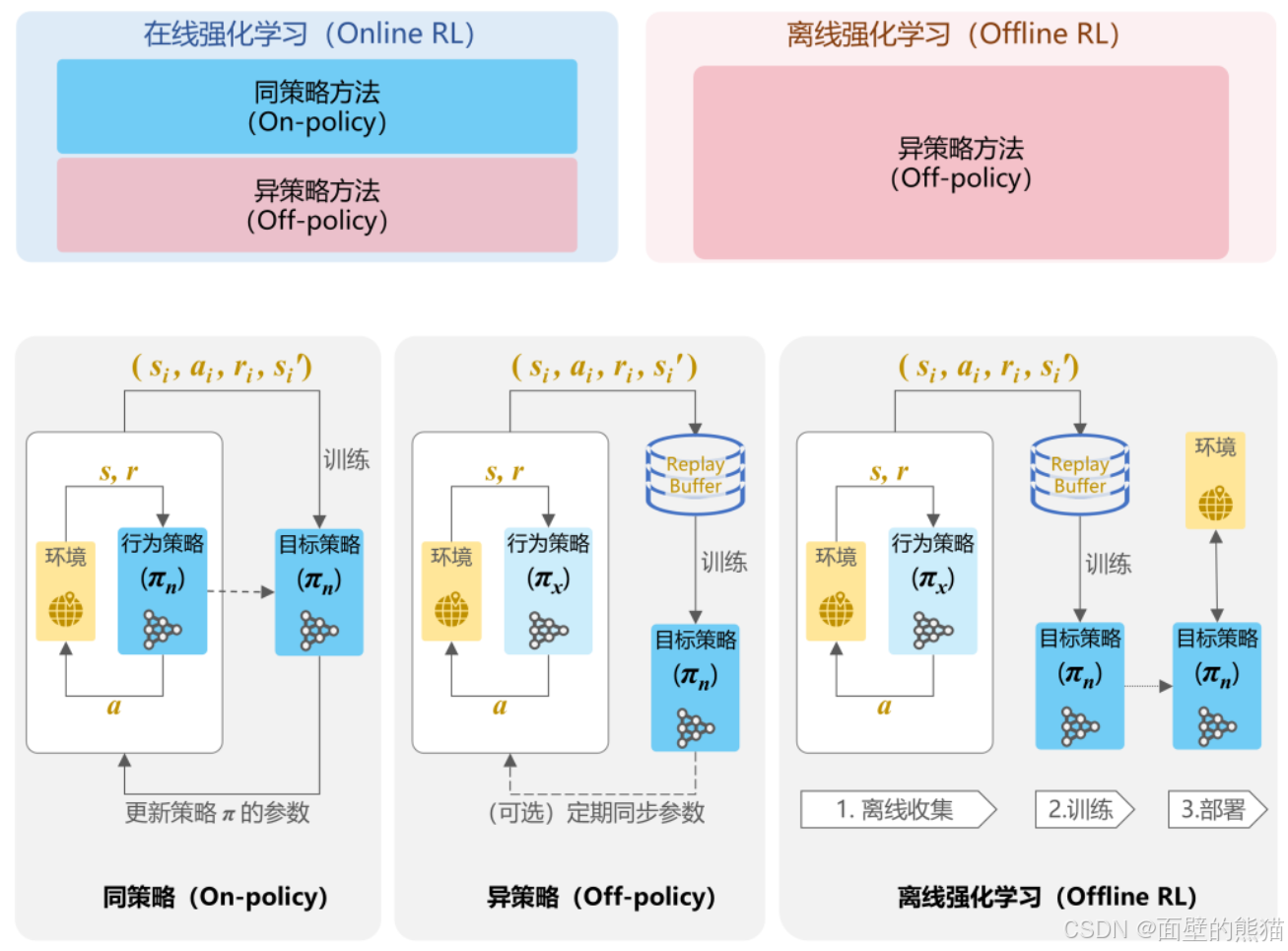
按照是否学习环境model可分为:
- model free
- model based
按照显示建模策略可分为:
- value-based方法
- policy-based方法
- actor-critic(将value-based和policy-based结合起来),其主要解决了连续动作空间的问题。
DQN解决了Q-learning连续状态空间的问题,DDPG则是基于“Actor-Critic”解决了连续动作空间的问题。
基本概念
价值函数以及奖励函数:
1.奖励函数主要是衡量当前动作-状态下的收益
2.价值函数则是一个长期收益,考虑到一系列的学习轨迹(考虑,贝尔曼方程)
价值函数又分为:
1.状态值函数
2.动作-状态值函数
贝尔曼方程的思想:
- 将问题分解为多个阶段的决策,递归求解子问题的最优解
- 未来奖励不如现在奖励“值钱”
动态规划:
基于动态规划的强化学习是一种基于有模型的方法,具体而讲,需要已知当前环境中的所有状态以及对应的策略分布、状态转移概率分布,才能应用动态规划。
动态规划的目标是得到当前状态s的价值函数以及当前可采取的最优策略。因为我们已知策略分布π(a∣s) 、状态转移 p(s′, r′∣s, a),则可以将所有可能转移的下一个状态s′对应的状态价值Vπ(s′)一同通过贝尔曼方程更新到Vπ(s) ,这既是动态规划的思想。事实上不管是动态规划,还是蒙特卡洛采样,都是这种逆推回溯的思想。
GAE:
传统强化学习
蒙特卡洛方法(采样更新+自举):
基于动态规划的需要遍历所有可能的动作,以及这些动作能够转移的所有下一个状态,这是一个穷举的过程。然而,我们无法做到穷举所有动作,同时我们也无法或者已知所有的状态转移概率分布,因此动态规划是一种理想条件下的方法,也是一个model-based的方法。
蒙特卡洛方法是通过平均样本的回报来解决强化学习问题,其通过多次采样来对潜在的搜索空间进行描述,使用均值来近似价值。(蒙特卡洛有点统计的感觉)
TD时序差分算法
时序差分方法是一种结合蒙特卡洛方法和动态规划思想的强化学习算法。它可以直接从智能体与环境的交互中学习,无需知道环境的完整模型。 TD的核心在于利用已知的状态估计来更新当前状态的价值函数,这一过程称为自举(bootstrapping)。
TD预测被称为 DP 和 MC 的结合体,DP是期望更新+自举bootstrap,MC是采样更新 + 样本估计。而TD则是采样更新 + 自举,即值函数V(St)更新基于采样得到的V(St+i)的结果。
SARSA
SARSA是基于价值函数,显示构建动作-价值表,使用**TD(时序差分方法)**的on-policy的价值策略强化学习方法。
Q-learning
Q-learning是基于价值函数的,通过贝尔曼方程,递归求解子问题的最优解。其显示构建一张Q值表,然后通过迭代更新Q值表,最终得到最优的Q值表。
PG
深度强化学习
DQN
Q-learning使用Q值表,需要存储大量的状态-动作-Q值,导致存储空间和计算量都很大,造成 “维度灾难” 。针对此问题,DQN提出了一种基于神经网络的Q值表,通过神经网络的参数更新,迭代更新Q值表,最终得到最优的Q值表。其极大地减少了存储空间和计算量。
DDPG
LLM中的强化学习
DPO
直接利用人类的偏好数据(例如,对模型生成结果的偏好选择)来优化模型,而无需显示进行强化学习。其目的是对齐模型和人类的偏好。
RLHF-PPO(on-policy)
PPO目的也是对齐模型和人类的偏好,值得注意的是其是Actor-Critic范式的强化学习。需要显示的建模reward model以及value model。
PPO专注于简化训练过程,克服传统策略梯度方法(如TRPO)的计算复杂性,同时保证训练效果。
问题:强化学习,直接优化梯度策略会导致不稳定的训练,模型可能因为过大的参数更新而崩溃。
解决:PPO通过限制策略更新幅度,使得训练不会偏离当前策略太多,同时高效利用采样数据。
GRPO(off-policy)
GRPO有点区别的PPO和DPO,其除了对齐模型和人类的偏好之外,还着重提高模型的reasonging ability。其核心思想是通过组内相对奖励来优化策略模型,而不是依赖传统的value/critic model。
GRPO采用样本级别的奖励和token级别的重要性采样,后续的DAPO则是优化为token级别的奖励,GSPO则是优化为样本级别的重要性采样。
DAPO
DAPO是GRPO的升级版,GRPO在实际使用过程中容易出现熵崩溃、奖励噪声、训练不稳定等问题。提出了移除KL散度、Clip-Higher、Dynamic Sampling、Token-Level Loss、Overlong Punishment等策略来解决这些问题。
移除KL散度:
KL散度的目的是为了限制在线策略和参考策略之间的偏离,防止参考模型更新过多,出现训练崩溃。然而,在长链式推理模型的训练中,模型分布可能会显著偏离参考模型,因此这种限制并不需要。
Clip-Higher:
PPO和GRPO算法存在熵崩溃现象(策略的熵随着训练迅速下降,导致生成的响应区域一致)。为此,DAPO提出Clip-Higher,通过解耦上下裁剪范围,增加低概率token的探索空间。/epsilon low=0.2, /epsilon high=0.8。
Dynamic Sampling:
现有的RL算法在面对准确率为1的prompt时,往往会存在梯度消失问题。DAPO通过动态采样策略,过滤准确率为1和0的prompt,确保每个批次的prompt都具有有效的梯度信号。
Token-Level Loss:
传统的GRPO算法采样样本级的损失计算,导致长响应的token对整体损失贡献较低。DAPO引入Token-Level策略损失,确保长序列中的每个token都能对梯度更新产生同等影响。
Overlong Punishment:
在RL训练中,过长响应通常会被截断,并收到惩罚。这种惩罚会引入奖励噪声,干扰训练过程。DAPO提出Overlong Punishment机制,通过长度感知的惩罚区间,逐步增加对长响应的惩罚,减少奖励噪声并稳定训练。
GSPO
GSPO同样是为了解决GRPO训练过程不稳定的问题。其核心思想通过引入序列级别的重要性比率和优化目标,显著提升训练效率和稳定性。
GMPO
GRPO使用算术平均这对离群值特别敏感,导致更新剧烈震荡,训练过程不稳定。GMPO采用几何平均策略优化,用对离群值具有天然鲁棒性的几何平均来替代算术平均作为优化目标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)