程序员实战:工业 4.0 智能制造技术架构选型与落地指南
本文探讨工业4.0背景下智能制造的技术架构实现方案,重点分析边缘计算、数据中台和AI集成三大核心模块。边缘层采用MQTT/OPCUA协议和Python/C++实现毫秒级实时数据处理;数据中台通过Flink+Spark构建流批一体数据处理体系,实现设备与订单数据的实时关联分析;AI集成采用TensorFlow Lite等轻量级框架实现模型边缘部署与在线迭代。文章通过具体代码示例展示了温度传感器数据过
在工业 4.0 浪潮中,智能制造的核心诉求是 “降本增效、柔性生产、预测性维护”,而技术架构的选型直接决定了这些目标能否落地。对 AI 应用架构师而言,需在 “实时性、可靠性、扩展性” 三者间找到平衡 —— 既要适配车间复杂的设备环境,又要支撑 AI 算法的高效运行。本文从程序员视角,结合工业场景代码实例,拆解边缘层、数据中台、AI 集成三大核心架构的选型逻辑,提供可落地的技术方案。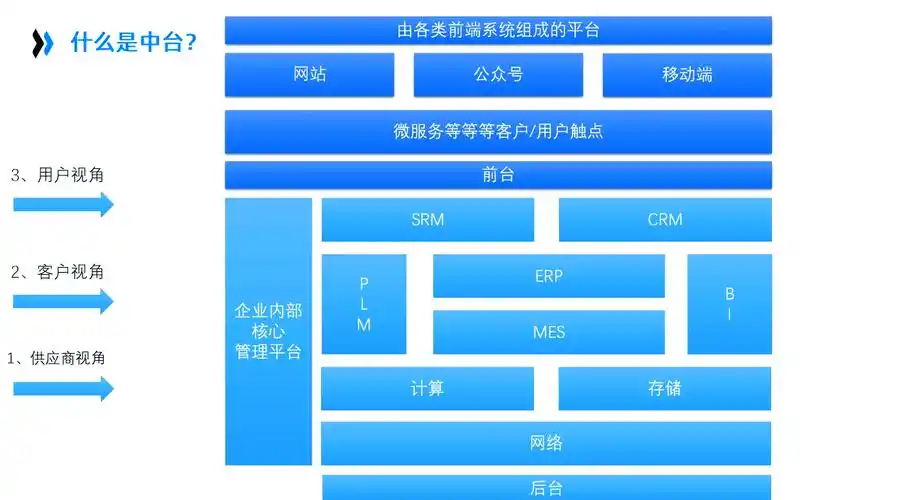
边缘层架构:实时数据采集与低延迟处理
工业场景中,设备数据(如机床转速、传感器温度、机械臂姿态)的采集与处理对延迟要求极高(通常需毫秒级响应),传统 “设备→云端” 的集中式架构无法满足需求。边缘层架构的核心是 “就近处理”,在车间本地完成数据清洗、筛选、预处理,仅将关键数据上传至云端,既降低网络带宽压力,又保障实时控制需求。
技术选型逻辑
- 通信协议:优先选择 MQTT(轻量级、低带宽)或 OPC UA(工业标准、高可靠性),而非 HTTP(开销大、不适合长连接);
- 硬件载体:采用边缘计算网关(如 NVIDIA Jetson Nano、树莓派工业版),兼具算力与稳定性;
- 编程语言:Python(快速开发)或 C++(高性能),搭配轻量级框架实现数据处理。
代码实战:边缘设备数据采集与预处理
以车间温度传感器数据采集为例,使用 MQTT 协议实现设备与边缘网关的通信,并在本地完成异常值过滤:
import paho.mqtt.client as mqtt
import time
import numpy as np
# 边缘网关配置
MQTT_BROKER = "192.168.1.100" # 边缘网关IP
MQTT_PORT = 1883
MQTT_TOPIC = "industrial/sensor/temperature" # 温度传感器主题
# 异常值处理:基于3σ原则过滤噪声数据
def filter_abnormal(data, mean, std, threshold=3):
"""
data: 单次采集的传感器数据
mean/std: 传感器历史数据的均值/标准差(离线计算)
"""
if abs(data - mean) > threshold * std:
return None # 异常值,丢弃
# 线性插值填补微小波动(工业传感器常见的抖动问题)
return round(np.interp(data, [mean-2*std, mean+2*std], [mean-2*std, mean+2*std]), 2)
# MQTT客户端初始化(设备数据接收)
def on_connect(client, userdata, flags, rc):
print(f"边缘网关连接MQTT服务器:{rc == 0}")
client.subscribe(MQTT_TOPIC)
# 接收传感器数据并预处理
def on_message(client, userdata, msg):
try:
# 1. 解析传感器数据(格式:设备ID,时间戳,温度值)
payload = msg.payload.decode("utf-8").split(",")
device_id, timestamp, temp_str = payload[0], payload[1], payload[2]
temp = float(temp_str)
# 2. 加载传感器历史统计参数(实际场景需从本地缓存读取)
sensor_stats = {
"device_001": {"mean": 25.3, "std": 1.2},
"device_002": {"mean": 30.1, "std": 1.5}
}
if device_id not in sensor_stats:
print(f"未知设备:{device_id}")
return
# 3. 异常值过滤与数据清洗
filtered_temp = filter_abnormal(
temp,
sensor_stats[device_id]["mean"],
sensor_stats[device_id]["std"]
)
if filtered_temp is None:
print(f"异常数据:设备{device_id},温度{temp}℃(已丢弃)")
return
# 4. 本地存储关键数据(后续按需上传云端)
with open(f"/edge_data/{device_id}_temp.csv", "a") as f:
f.write(f"{timestamp},{filtered_temp}\n")
print(f"处理完成:设备{device_id},温度{filtered_temp}℃")
except Exception as e:
print(f"边缘处理异常:{str(e)}")
# 启动边缘数据处理服务
if __name__ == "__main__":
client = mqtt.Client(client_id="edge_gateway_001")
client.on_connect = on_connect
client.on_message = on_message
# 工业场景需开启用户名密码认证
client.username_pw_set("industrial_user", "edge@2024")
client.connect(MQTT_BROKER, MQTT_PORT, keepalive=60) # 60秒心跳保活
client.loop_forever() # 持续监听设备数据
落地场景
该架构适用于数控机床振动监测、锂电池生产车间温湿度控制等场景 —— 边缘网关在本地完成数据预处理后,可直接触发本地告警(如温度超阈值时暂停设备),同时将过滤后的历史数据上传至数据中台,兼顾实时控制与长期分析需求。
数据中台架构:打通智能制造数据链路
工业数据来源复杂(设备数据、MES 系统数据、质检数据、ERP 数据),格式异构(结构化的生产报表、非结构化的设备日志、半结构化的传感器时序数据),数据中台的核心作用是 “打破数据孤岛”,构建统一的数据存储与计算体系,为 AI 算法提供高质量的数据输入。
技术选型逻辑
- 存储层:采用 “时序数据库 + 关系型数据库 + 对象存储” 混合架构 ——InfluxDB/TimescaleDB 存储时序数据(如传感器数据),MySQL/PostgreSQL 存储结构化数据(如生产订单),MinIO 存储设备图纸、质检图片等非结构化数据;
- 计算层:选择 Flink(实时流处理)+Spark(批处理),分别处理实时监控与离线分析场景;
- 数据同步:使用 Debezium 捕获数据库变更(CDC),实现 MES/ERP 系统数据的实时同步,避免侵入业务系统。
代码实战:Flink 实时数据关联与指标计算
以 “生产订单与设备状态实时关联” 为例,使用 Flink 将设备运行数据与生产订单数据关联,计算每个订单的设备运行效率(OEE):
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.influxdb.InfluxDBSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.json.JSONObject;
import java.util.Properties;
public class ProductionOEECalculation {
public static void main(String[] args) throws Exception {
// 1. 初始化Flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2); // 按车间生产线数量设置并行度
// 2. 配置Kafka消费者(设备数据与订单数据分别来自不同Topic)
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", "192.168.1.200:9092");
kafkaProps.setProperty("group.id", "flink_industrial_group");
// 读取设备运行数据(Topic:industrial_device_data)
DataStream<String> deviceStream = env.addSource(
new FlinkKafkaConsumer<>("industrial_device_data", new SimpleStringSchema(), kafkaProps)
);
// 读取生产订单数据(Topic:industrial_order_data)
DataStream<String> orderStream = env.addSource(
new FlinkKafkaConsumer<>("industrial_order_data", new SimpleStringSchema(), kafkaProps)
);
// 3. 数据转换:解析JSON并提取关键字段
DataStream<DeviceData> parsedDeviceStream = deviceStream.map(str -> {
JSONObject json = new JSONObject(str);
return new DeviceData(
json.getString("device_id"),
json.getLong("timestamp"),
json.getString("status"), // 设备状态:RUNNING/STOPPED/ERROR
json.getDouble("actual_speed"), // 实际转速
json.getDouble("target_speed") // 目标转速
);
});
DataStream<OrderData> parsedOrderStream = orderStream.map(str -> {
JSONObject json = new JSONObject(str);
return new OrderData(
json.getString("order_id"),
json.getString("device_id"), // 订单关联的设备ID
json.getLong("start_time"),
json.getLong("end_time")
);
});
// 4. 数据关联:按device_id分组,关联同一设备的订单与运行数据
DataStream<OEEData> oeeStream = parsedDeviceStream
.keyBy(DeviceData::getDeviceId)
.connect(parsedOrderStream.keyBy(OrderData::getDeviceId))
.process(new OEEProcessFunction()); // 自定义处理函数计算OEE
// 5. 结果输出:写入InfluxDB供监控面板展示
InfluxDBSink<OEEData> influxSink = new InfluxDBSink.Builder<OEEData>()
.setUrl("http://192.168.1.200:8086")
.setDatabase("industrial_db")
.setUsername("admin")
.setPassword("influx@2024")
.setDataPointFunction(oee -> new DataPoint.Builder()
.measurement("equipment_oee")
.tag("order_id", oee.getOrderId())
.tag("device_id", oee.getDeviceId())
.time(oee.getTimestamp(), DataPoint.TimeUnit.MILLISECONDS)
.field("oee_value", oee.getOeeValue())
.build())
.build();
oeeStream.addSink(influxSink);
// 执行任务
env.execute("Production OEE Real-Time Calculation");
}
// 设备数据实体类
public static class DeviceData {
private String deviceId;
private long timestamp;
private String status;
private double actualSpeed;
private double targetSpeed;
// 构造函数、getter/setter省略
}
// 订单数据实体类
public static class OrderData {
private String orderId;
private String deviceId;
private long startTime;
private long endTime;
// 构造函数、getter/setter省略
}
// OEE计算结果实体类
public static class OEEData {
private String orderId;
private String deviceId;
private long timestamp;
private double oeeValue;
// 构造函数、getter/setter省略
}
}
落地场景
该数据中台架构已在汽车零部件生产车间应用 —— 通过 Flink 实时计算设备 OEE(综合效率),结合 Spark 离线分析历史数据,为生产调度提供决策依据:当某台设备 OEE 连续 3 小时低于 80% 时,系统自动触发维保工单,实现 “预测性维护” 向 “主动性维护” 的升级。
AI 模型集成架构:从算法到产线落地
工业场景的 AI 应用(如缺陷检测、设备故障预测、工艺参数优化),核心痛点是 “模型部署难、适配性差”—— 训练好的模型无法直接在边缘设备运行,或在复杂工况下精度骤降。AI 集成架构的关键是 “轻量化部署 + 在线迭代”,让模型既能在资源受限的边缘设备运行,又能通过实时数据持续优化。
技术选型逻辑
- 模型训练:复杂场景(如 3D 缺陷检测)用 PyTorch/TensorFlow 在云端训练,简单场景(如温度异常识别)用边缘端联邦学习(保护设备数据隐私);
- 模型部署:采用 TensorFlow Lite(轻量级推理)或 ONNX Runtime(跨框架兼容),将模型转换为边缘设备支持的格式;
- 迭代机制:通过 “边缘推理→云端反馈→模型更新→边缘部署” 的闭环,实现模型在线优化。
代码实战:TensorFlow Lite 模型部署到边缘网关
以 “机械臂零部件缺陷检测” 为例,将训练好的 CNN 模型转换为 TFLite 格式,部署到 NVIDIA Jetson Nano 边缘网关,实现实时质检:
import cv2
import numpy as np
import tensorflow as tf
from PIL import Image
# 1. 加载TFLite模型(已量化为INT8,减小体积并提升推理速度)
interpreter = tf.lite.Interpreter(model_path="mechanical_arm_defect_model.tflite")
interpreter.allocate_tensors()
# 获取模型输入/输出张量信息
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_shape = input_details[0]['shape'] # 如 [1, 224, 224, 3]
# 2. 定义图像预处理函数(匹配训练时的预处理逻辑)
def preprocess_image(image_path):
"""读取工业相机拍摄的图片,预处理为模型输入格式"""
# 读取图片(工业相机输出为BGR格式,需转为RGB)
img = cv2.imread(image_path)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# resize到模型输入尺寸
img_resized = cv2.resize(img_rgb, (input_shape[1], input_shape[2]))
# 归一化(与训练时一致:像素值除以255)
img_normalized = img_resized / 255.0
# 增加批次维度(模型输入为[batch, height, width, channels])
return np.expand_dims(img_normalized, axis=0).astype(np.float32)
# 3. 实时推理(模拟工业相机连续拍摄)
def realtime_defect_detection(camera_index=0):
"""从工业相机读取视频流,实时检测缺陷"""
cap = cv2.VideoCapture(camera_index)
# 设置相机分辨率(匹配工业相机参数)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("相机读取失败,重试...")
time.sleep(1)
continue
# 预处理当前帧
input_data = preprocess_image_from_frame(frame) # 自定义函数,同preprocess_image逻辑
# 设置模型输入
interpreter.set_tensor(input_details[0]['index'], input_data)
# 执行推理
interpreter.invoke()
# 获取推理结果(输出为[缺陷概率, 正常概率])
output_data = interpreter.get_tensor(output_details[0]['index'])
defect_prob = output_data[0][0]
normal_prob = output_data[0][1]
# 4. 结果判断与可视化(缺陷概率>0.8时触发告警)
if defect_prob > 0.8:
cv2.putText(frame, "DEFECT DETECTED!", (50, 50),
cv2.FONT_HERSHEY_SIMPLEX, 1.5, (0, 0, 255), 2)
# 触发车间告警(通过MQTT发送指令到PLC</doubaocanvas>

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)