大模型评估方法论:指标拆解与技术路径
在大模型的世界里,能力强≠真正好用。很多时候,模型在宣传视频里表现得无所不能,但一旦落地到实际业务场景,问题就会暴露出来。这时候,一个科学、系统、可复现的评估方法,就成了区分“看起来很强”和“真的能用”的关键。本文将带你走进大模型评估的“方法论核心”,从指标拆解到技术路径,全面梳理业界常用的评估框架,帮你建立一套可落地、可复用的评估体系。
📚大模型评估系列文章
在大模型的世界里,能力强≠真正好用。很多时候,模型在宣传视频里表现得无所不能,但一旦落地到实际业务场景,问题就会暴露出来。这时候,一个科学、系统、可复现的评估方法,就成了区分“看起来很强”和“真的能用”的关键。
本文将带你走进大模型评估的“方法论核心”,从指标拆解到技术路径,全面梳理业界常用的评估框架,帮你建立一套可落地、可复用的评估体系。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案。
- 大模型评估的核心指标体系应该如何拆解?
- 各类指标之间有什么优先级与权衡关系?
- 评估技术路径如何结合自动化与人工评估,做到高效又可靠?
一、评估的三个基本原则
在深入方法论之前,我们先明确三个底层原则:
- 相关性优先
评估指标必须和应用目标高度一致,否则再漂亮的分数也只是数字游戏。
- 可复现性
评估过程必须标准化,保证换一批数据、换一个人,结果依然一致。
- 全面性与权衡
单一指标永远不够用,要结合能力、效率、安全、成本等多维度平衡。
二、大模型评估的指标拆解
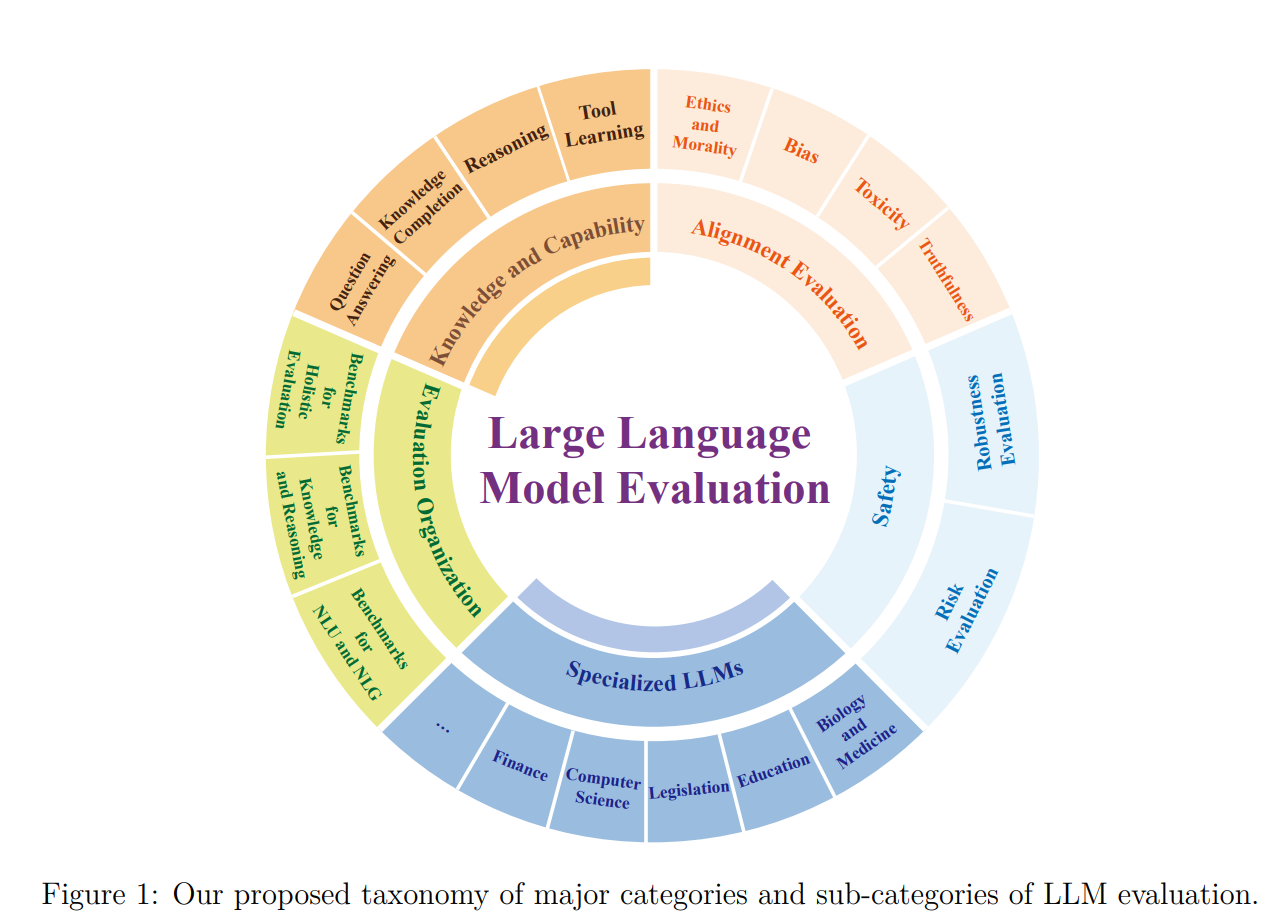
业界常用的指标体系,可以分为以下四大类:
1.能力指标
衡量模型的知识覆盖、推理能力、生成质量等,例如:
- 准确率(Accuracy):答案是否正确。
- 推理链完整性:多步推理是否逻辑连贯。
- 流畅度与可读性:生成文本是否自然、无明显语言错误。
2.效率指标
关注模型的响应速度与资源消耗,包括:
- 延迟(Latency):生成首个 token 所需的时间。
- 吞吐量(Throughput):单位时间内可完成的任务数量。
- 成本(Cost):计算与 API 调用的综合开销。
3.安全指标
评估模型在安全合规上的表现,避免“放飞自我”:
- 越狱防护(Jailbreak Resistance):能否抵抗提示注入攻击。
- 有害内容检测:生成是否包含歧视、暴力、色情等不当信息。
- 隐私保护:是否会泄露用户敏感信息。
4.鲁棒性指标
检验模型面对噪声输入、方言变体、恶意扰动时的稳定性:
- 对抗样本容忍度。
- 多语言一致性。
三、技术路径:如何评估大模型
一套完善的评估路径,通常包括以下几个步骤:
- 定义任务与指标权重
先确定评估的目标(如客服问答、代码生成),再给各指标分配权重。
- 构建评测数据集
可以用公共基准数据集(如 MMLU、GSM8K),也可以结合业务场景构造定制数据。
- 选择评估方式
自动化评估:BLEU、ROUGE、BERTScore、LLM-as-a-judge(让大模型评分)。
人工评估:适用于主观性强的任务,如创意写作、对话流畅度。
- 混合评估策略
自动化提高效率,人工评估兜底,把关质量。
- 可视化与报告生成
输出详细的评估报告,让团队和决策层直观看到差异。
四、 常见评估误区
即使有了指标和技术路径,也要避免这些坑:
- 只用一个指标说事:比如单纯追求准确率,忽略安全性。
- 数据集过时:模型可能对老题库“背答案”,失去真实评估意义。
- 评估场景不匹配:测试集和真实业务差距过大。
五、框架与工具推荐
- OpenAI Evals:支持自定义评估任务,适合 API 调用类模型。
- HELM(Holistic Evaluation of Language Models):斯坦福的综合评测框架。
- LLM-as-a-judge 模板:用一个更强的模型帮你打分。
- PromptBench:快速批量测试 Prompt 效果。
最后,我们回答一下文章开头提出的问题。
- 大模型评估的核心指标体系应该如何拆解?
从能力、效率、安全、鲁棒性四个维度分解,并根据应用目标调整权重。
- 各类指标之间有什么优先级与权衡关系?
商业场景中,相关性和安全性往往优先;科研测试中,能力指标权重更高。
- 评估技术路径如何结合自动化与人工评估,做到高效又可靠?
自动化用于批量、客观指标;人工评估负责主观、复杂场景,两者结合才能平衡效率与准确性。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)