Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing——论文阅读笔记
本周速读的文章是:Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing,这篇文章我其实没看懂——不是说做法看不懂,而是没看懂怎么个好发,大家奇文共赏吧。
本周速读的文章是:Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing
看完感觉自己长脑子了——就非得给自己再起个某PO的名字呗(SAPO)。
通篇看下来,觉得自己没看懂——这么做怎么个好法呢?
一句话总结
这篇文章描述了一个由多个节点(单卡机器 )组成的集群,每个节点都会:
※ 1 独立运行一个Qwen2.5-0.5B模型独立训练
※ 2 针对推理题目自行Rollout,并将这些Rollout数据放入一个共享的公海池。
※ 3 每步训练前,从公海池中抽取质量合格的Rollout数据,合
这样,每个节点上的模型性能都比单独训练时的结果好很多。
但,当使用Qwen3-0.6B模型进行同样的Reasoning Gym任务时,每个节点上的模型却没有显著提升。
放出的实验细节
※ 明确要求集群跑的任务是【可验证】任务
※ 作者其实连接入网络的节点的基本配置都没有给。
※ 没有描述开放性任务的问题。
※ 训练用的GRPO
※ 数据进入公海池的标准是advantage>0,针对非公海池的Rollout(本机自己的Rollout)则没有这个要求
※ 每个节点都用的ReasoningGYM数据集的随机子集(未看到数据集全貌)
※ 自己Rollout和公海Rollout的理想配比(本实验中)是1:1,即一半自己,一半公海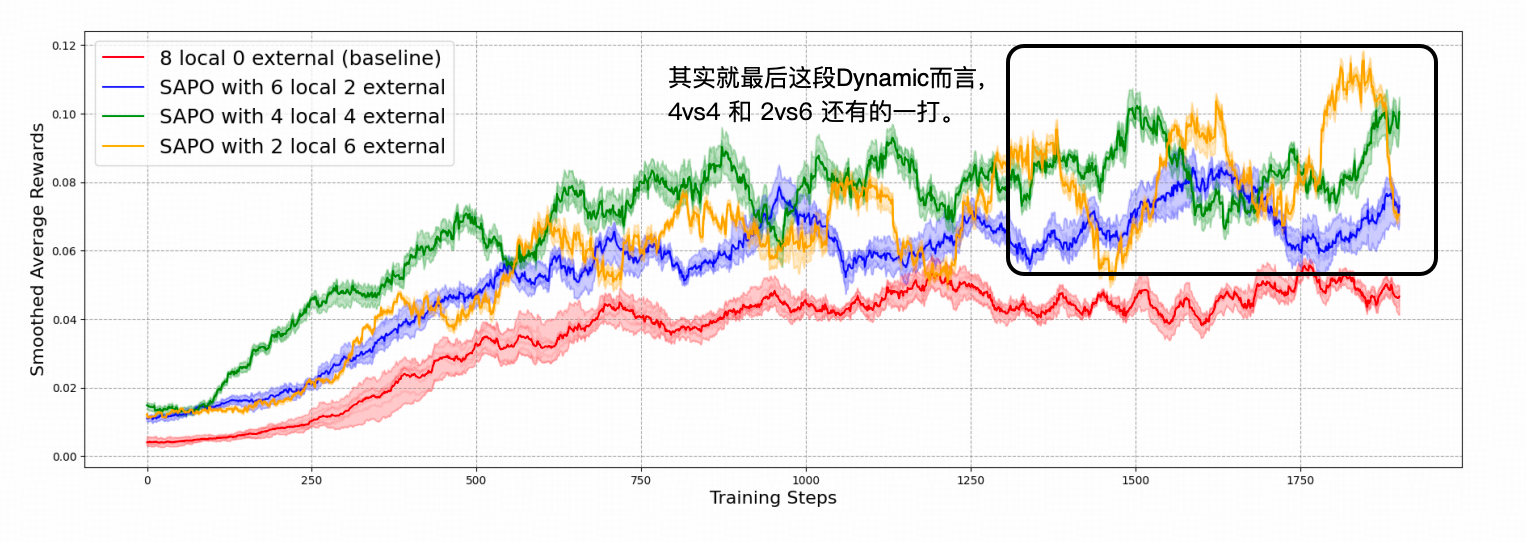
一些我看了浑身刺挠的东西
1. 使用累加奖励为的是啥呢?
作者在对比单独训练和自己的集群训练的不同的时候,使用了一个比较「无厘头」的指标,就是,你干嘛用累加Reward啊?要表达阶段性效果好,想多排除点随机性,你用Moving Average啊,你画Band啊,这个累加能体现出点啥呢?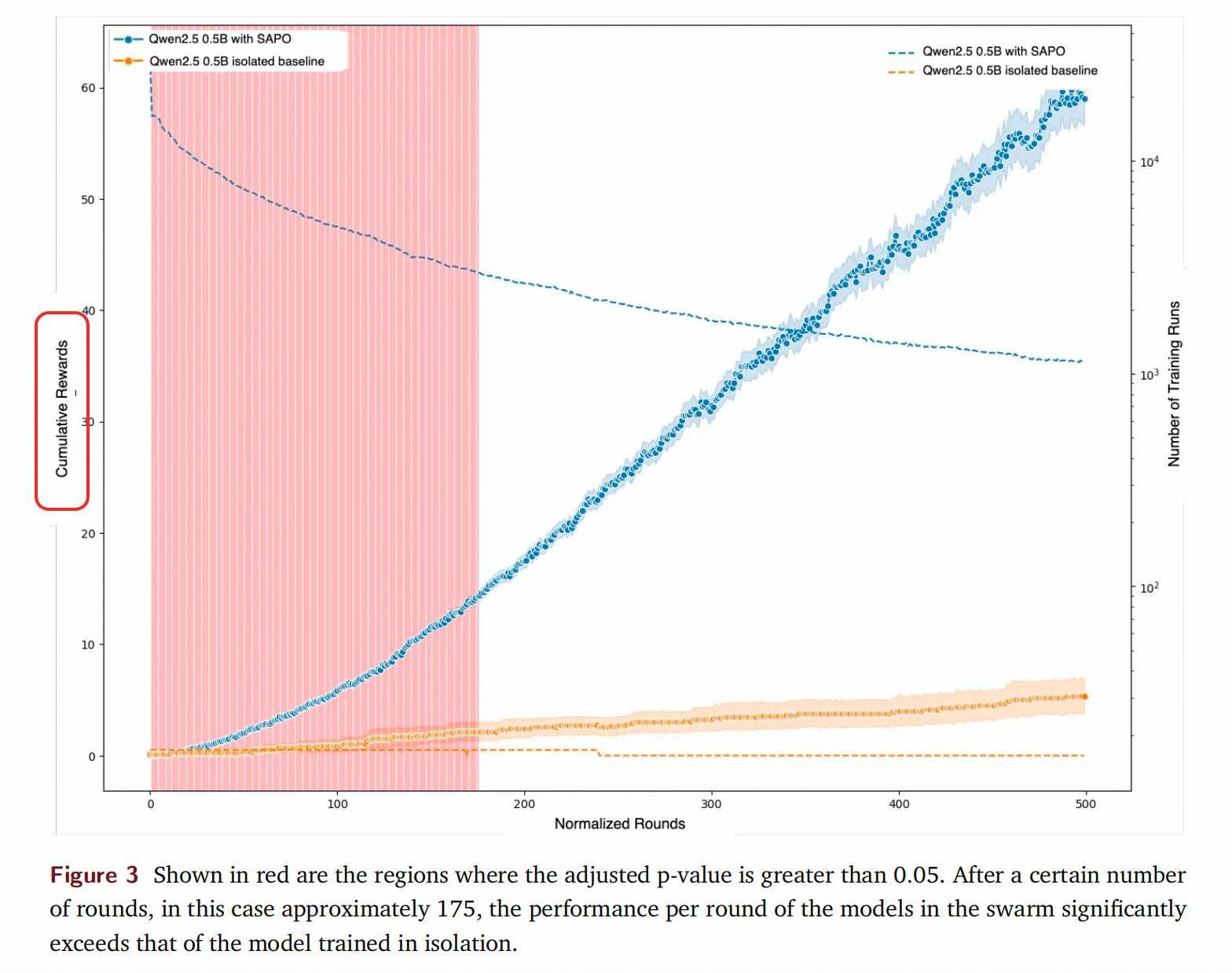
2. Huggingface上的讨论爆炸了?
跟DinoV3比,星只有1/5,讨论是DinoV3的10倍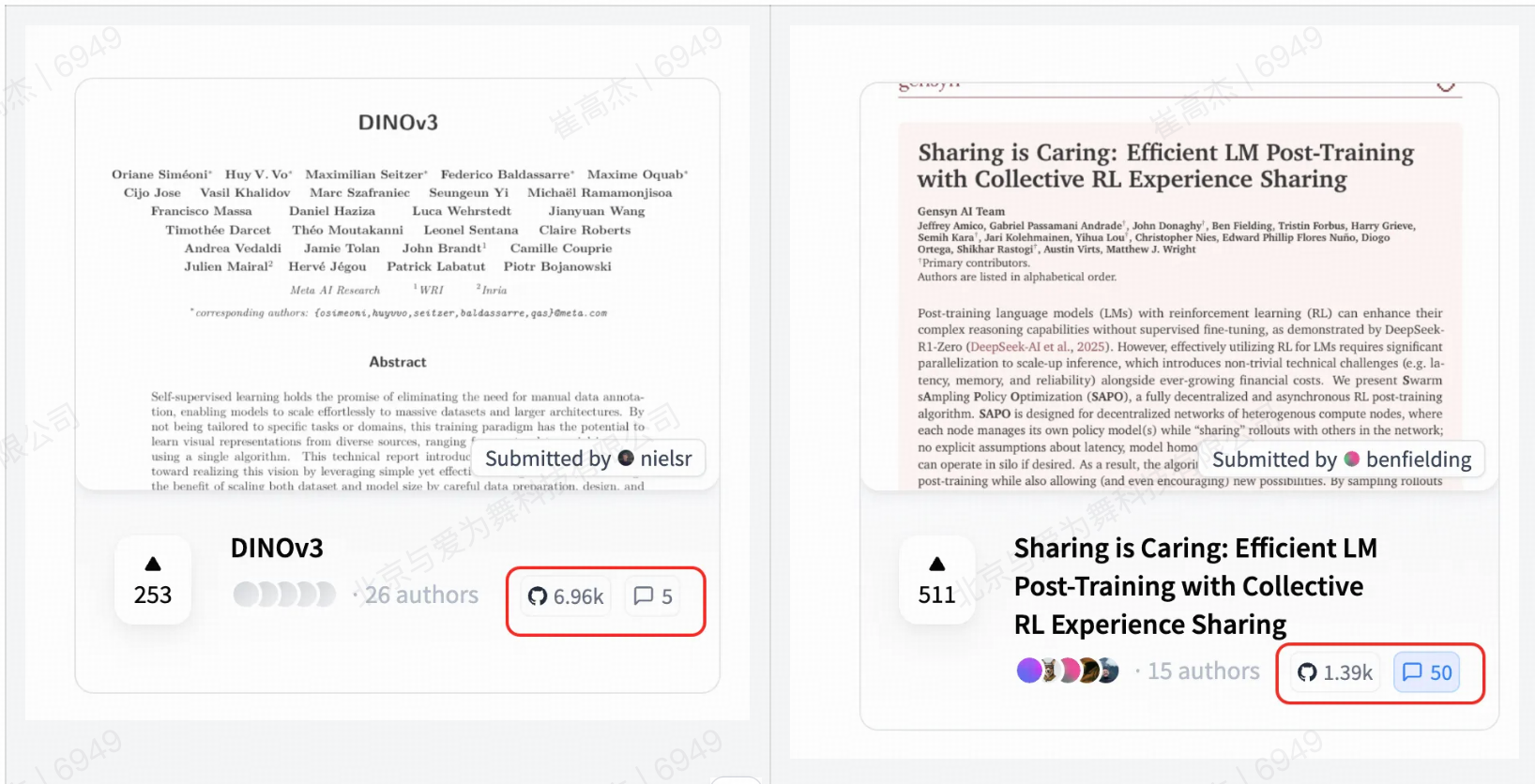
咋啦,贡献机器的同学们都来评论拉?
我的感想
- 首先,我确实最近几年都苦于自己的技术高度上不去,我的认知始终在一个中等牛马的水平晃悠,这我很苦恼,以下言论也是在我现在这个水平下发表的。
- 作者宣称的“Aha Moment”的传播,我信也不信,一来,Rollout本身就是在策略空间上采样,理想的状态确实是发现更多【智慧水平】更高的Rollout。但这个东西怎么在Qwen3-0.6B上没有出现呢?一个0.6B的模型对推理任务已经过于高贵导致没有什么可以发生“Aha”的机会啦?好的性质,需要非得挂个啥去分析吗?要分析能不能推一下?推不了能不能多几个模型型号,多几组实验呢?
- 算力资源/机器是LLM中心化的最主要原因吗?——Scaling 里面,数据,参数量和Flop这三者,要进行去中心化的改造,不能只改造运算量这点吧?数据这个点是不是在工业领域里可能是更大的问题? 十年前我去书店蹭书的时候,看得一本描述【第四次工业革命】的书,说每家屋顶都装上太阳能板采集电能,就是第四次工业革命的能源生产形式,我看这个文章,就想起来这部分,也不知道为什么(⊙o⊙)…
- 一个要求RL任务可验证这点是不是把绝大部分实际任务都挡住了呢?诚然,现阶段,用【可验证】任务去找更好的训练方法,是一个成本更低,更容易推进的方向。
但实际上,这半年的大部分RL方法,移植到其他场景上都需要很大的经历去磨一个更好,能把【数学/代码】以外问题的价值描述清楚的reward系统。——搞不好,就是我不会训Reward,这么说是不是太流氓了。这点我到不是针对这篇文章,而是【某PO】卷到飞起,而数据筛选,开放任务的训练方法这些赛道明显还有空间。而且,我做实践工作的,其实比较蛋疼的就是每天老板看着这些【进步】,自己场景上用不了,还得跟老板解释,还得自惭形秽……累。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)