上下文工程实践 - 工具管理(下篇)
本文探讨了工具管理在Agent系统中的核心作用。工具调用将LLM的不确定性流程转化为确定性代码执行,成为Agent系统设计的关键环节。文章重点介绍了工具调用的三种控制流模式(信息补充、信息获取和审批请求),提出通过工具调用实现结构化输出的创新方法,并详细分析了工具错误处理机制(参数验证和重试限制)。最后将工具分类为数据类、动作类和编排类三种类型,强调了合理设计工具调用可以替代传统工作流构建方式。全
工具管理(下篇)
工具管理涉及的概念较多,所以我分成上下两篇来介绍:
上篇:主要讲 MCP 与 Tool 的定义和区别,以及工具的定义规范
下篇:继续展开,讨论工具的定位、错误处理方式和常见分类
三、工具的定位
3.1、Agent 系统的核心
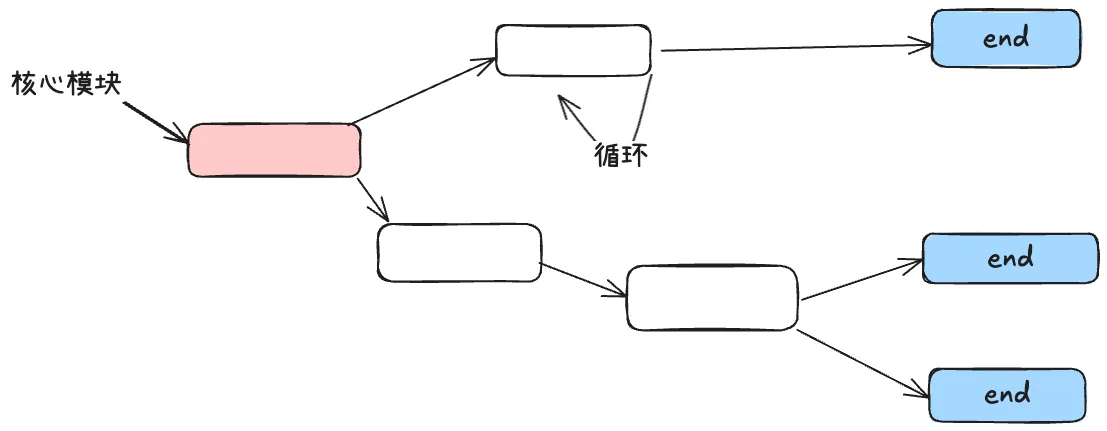
之前的系统的设计,都是围绕一个“有向无环图(DAG)”的理念来设计的,核心模块主要是由循环和条件判断组成,复杂的系统也只是多个循环和多个条件判断组成,在此基础上增加可观察性,模块化,重试,管理等功能,成为一个完整的系统
而有了 LLM 之后,设计 Agent 的系统时,我们可以暂时放下“有向无环图(DAG)”的想法,我们不需要为每一个步骤和边缘情况编写代码,只需要给 Agent 一个目标和一系列的转换,让 LLM 实时做出决策来确定路径
这样的好处是,你编写的模块更少了,只需将图的“边缘”交给 LLM,让它自己处理节点,甚至会发现有时候 LLM 为问题找到了新的解决方案
这种方式其实就是把循环和条件判断统一交给 LLM 来驱动
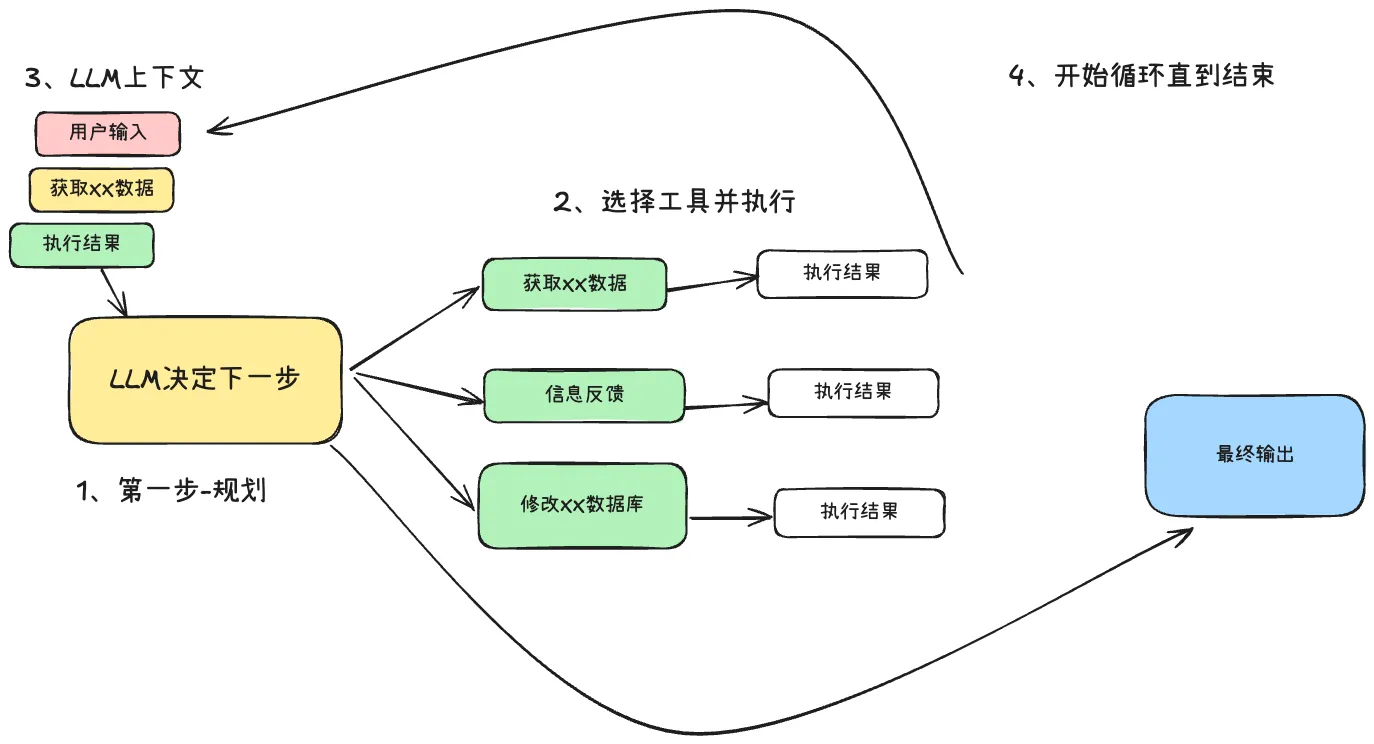
Agent 系统的核心步骤
- LLM 决定工作流程中的下一步,输出“工具调用”
- 确定性代码执行工具调用
- 工具执行结果追加到上下文中
- 重复直到下一个步骤确定为“完成”
工具调用的能力,将 Agent 系统中的不确定性的 LLM 流程转换为确定性的代码执行
3.2、控制流
控制流的方式可以为工具调用添加更多的分支控制,让工具调用不仅仅是一次函数执行,而是一次完整的流程调用,所以学会使用控制流来构建工具调用,会发生非常多有趣的事情
例如:
-
普通的工具调用:一次执行,查询天气结果,将结果返回给模型
-
控制流的工具调用:会检测该工具调用是否是“高风险”,如:我要部署后端服务,这个时候检测到该工具调用时高风险,会进入人工审核判断,
- 先保存上下文
- 给用户发审批通知
- 等待用户的审批结果
- 用户同意,函数执行
使用控制流,你需要为特定的例子构建独特的控制结构,具体来说,某些工具调用会跳出循环并等待人类或其他长时间的任务(如训练管道)的响应,后续你可能还会使用其他的自定义实现
- 工具调用结果进行摘要缓存
- LLM 辅助结构化输出
- 上下文压缩或内存管理
- 日志记录、跟踪和指标统计
- 持久暂停和等待
控制流有三种模式
- 请求信息补充:模型请求更多的信息,这个时候会中断循环等待人类回复
- 获取信息:例如:请求 git 标签,获取标签之后追加到上下文中,然后返回给模型
- 请求审批:当出现“高风险操作”的时候,模型会请求用户进行审批,根据用户的选择来执行不同的流程
🌟 工具的调用构建,不要只停留在函数执行,而是要有“控制流”的思维,以此揭开工具调用更多的 LLM 玩法,并且控制流构建合理,可以替代使用 LangGraph 的工作流构建方式
3.3、辅助结构化输出
我们需要大模型输出 JSON 格式的时候,会在提示词里面控制大模型输出结果,例如:
“输出结果一定要是JSON格式,字段要求:xxx、xxxx、xxxx”
这个时候大模型大部分情况下输出的效果还是可以的,如果要让效果更加稳定,我们需要花一点心思在提示词的优化上面。
但是我们还有另外一种思路:使用工具调用的方式来达到结构化输出的目的
在 Function Call 的模式下,输出的结果自然就是 JSON,工具调用的名称和参数的 JSON 格式
🚀 那么是不是可以思考一下,我设置了一个函数,这个函数的执行结果为空,执行代码无,因为这个函数就是用来输出 JSON 格式的参数列表的,
这个参数列表就是我需要的结果,而不是工具调用之后返回的结果
例如现在有一个使用 LLM 进行总结摘要的功能
//方式A:提示词控制结构化输出
const prompt = `
请总结以下内容,输出必须是 JSON:
{
"title": "...",
"key_points": ["...", "..."],
"sentiment": "positive | neutral | negative"
}
内容:${inputText}
`;
// 模型大概率会返回 JSON 字符串
const raw = await llm.chat(prompt);
const result = JSON.parse(raw);
console.log(result);
//方式B:工具调用辅助结构化输出
// 定义一个“假的工具”,只要参数,不关心执行
const tools = [{
name: "summarize_text",
description: "把文本总结为 JSON",
parameters: {
type: "object",
properties: {
title: { type: "string" },
key_points: { type: "array", items: { type: "string" } },
sentiment: { type: "string" }
},
required: ["title", "key_points", "sentiment"]
}
}];
// 让模型调用工具
const res = await llm.chatWithTools({
user: `请总结:${inputText}`,
tools,
tool_choice: "summarize_text" // 强制用工具
});
// 拿到工具的参数 = 我们要的 JSON
const args = JSON.parse(res.tool_calls[0].arguments);
console.log(args);
方式 A:使用提示词控制大模型输出相应的 JSON 结构
方式 B:使用工具调用让大模型输出“工具参数”的 JSON 结构,代码进行提取
四、工具的错误处理
无论你工具定义的多好,LLM 的推理能力多强,都是有可能会出现工具调用错误的,这种错误会让 Agent 系统不够稳定,但是好在 LLM 有“自我修复”的能力,我们可以将错误信息加到 LLM 的上下文中使用起来,发挥 LLM 的“自由修复”能力
目前的工具调用可能出现的问题大概有两种:
- 调用工具前进行参数验证 - 用于收集 LLM 输出工具参数错误
- 还有一种是工具调用期间的错误事件,例如网络情况-触发重试机制,例如工具挑选错误,也可以将错误信息输入
当触发 LLM 错误修复的机制的时候,要设置一个最大循环修复次数,不然 LLM 会在错误中无限循环
4.1、工具调用参数错误处理机制
当你在设置工具执行函数的逻辑的时候,考虑在工具执行核心逻辑之前,进行参数验证,像 API 接口那样的参数验证,并且对于参数验证出现的错误信息要好好设计,因为这个是 LLM 进行错误修复时的“指路灯”
工具执行错误处理机制:
- 验证参数失败:系统检测到未定义的参数或者参数类型错误、参数缺失
- 错误反馈:将详细的错误信息返回给 LLM,例如
- 参数验证失败-‘profile’对象包含未定义的属性’birthday’,该属性在schema中不允许。允许的属性有:‘name’(必需)、‘email’(必需)、‘age’(可选)。请移除’birthday’属性并重试
- 上下文更新:将错误信息添加到对话历史中
- LLM 学习:LLM 从错误信息中学习正确的参数结构
- 第二次尝试:LLM 生成修正后的参数
- 验证成功:修正后的参数通过验证,执行工具函数
// 工具错误处理机制核心代码
function validateTool(params) {
const allowed = ['name', 'email', 'age'];
const invalid = Object.keys(params).find(p => !allowed.includes(p));
if (invalid) {
throw new Error(`参数验证失败-'profile'对象包含未定义的属性'${invalid}',允许的属性有:'name'(必需)、'email'(必需)、'age'(可选)。请移除'${invalid}'属性并重试`);
}
}
async function executeTool(params) {
try {
validateTool(params);
return '✅ 执行成功';
} catch (error) {
console.log('❌ 错误:', error.message);
// LLM从错误中学习并修正参数
const corrected = { ...params };
delete corrected.birthday;
console.log('🤖 LLM重试修正后的参数:', corrected);
validateTool(corrected);
return '✅ 修正后执行成功';
}
}
4.2、工具错误重试机制
将错误信息加入到上下文(Context)中之后,LLM 会参考错误信息进行“自我修复”
但是不要陷入到无限的错误修复循环中,要加入限制机制,
例如:限制单个工具最多 3 次尝试,之后程序中断,或者让大模型将错误出现的原因回复给用户,辅助用户进行排查
如果不加限制你会发现,代理会一直循环,一遍又一遍的重复同样的错误,导致这一个的原因有多种:
- LLM 理解能力限制
- 上下文混乱
- 缺乏替代策略:LLM 不知道除了重试还能做什么
那么相应的解决方案是:
- 控制流接管:通过确定的程序来主动干预,而不是完全依赖 LLM 判断
- 上下文管理:重组或删除错误信息,避免上下文污染,你也可以重新整理错误信息,让错误信息:明确,干净,有效
- 使用小而专注的 Agent:减少复杂性,降低错误概率
五、工具的分类
工具大致可以归为三类
- 数据类(Data):
- 获取上下文与信息,支撑流程决策
- 示例:查询数据库、读取 PDF、搜索网页
- 动作类(Action)
- 在系统中执行操作,推动流程向前
- 示例:发邮件、更新 CRM、转交客服请求
- 编排类(Orchestration)
- 智能体可作为另一个智能体的“工具”使用,实现更高级的协调
- 示例:退款智能体、研究智能体、写作智能体
最后
本文节选自我正在整理的 「上下文工程实践」 项目,该项目已完整发布在 GitHub 上。
如果你希望阅读更多相关的章节与案例,可以前往项目仓库查看
👉 https://github.com/WakeUp-Jin/Practical-Guide-to-Context-Engineering

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)